背景
SambaNova和Together这2家公司于2023.05.19开源了可商用的支持多语言的微调模型BLOOMChat。
SambaNova这家公司专注于为企业和政府提供生成式AI平台,Together专注于用开源的方式打造一站式的foundation model,赋能各个行业。
OpenAI的GPT-4和Google的PaLM2对多语言的支持已经做得很不错了,但这两者都是闭源的,而开源的大语言模型主要有以下痛点无法解决:
- 第一,大多数不能商用。比如Meta开源的LLAMA,以及基于LLAMA衍生的Vicuna等无法商用,只能用于学术研究。清华和智谱AI开源的ChatGLM的模型权重也不能商用。
- 第二,对非英语支持一般。大部分开源模型的训练语料以英文为主,非英文的对话效果一般。然而,世界上有超过80%左右的人是不讲英语的,如何解决这部分人的使用痛点也很关键。
国内很多企业和公司也在调研如何基于开源模型进行微调,打造一个支持中文的大语言模型,应用到自己的业务场景里。
由BigScience开源的Bloom基座模型是很多互联网公司的首选,因为这个模型可商用,支持包括中文在内的46种语言,而且模型参数够多,有1760亿参数。
有些公司就是直接拿基于Bloom做过微调后的Bloomz模型,来进一步微调,打造一个垂直领域的LLM。
SambaNova和Together联合开源的BLOOMChat,其目的就是打造一个开源的、支持多语言、可商用的聊天LLM,实验表明BLOOMChat对多语言的支持明显优于其它开源模型。
BLOOMChat
BLOOMChat是在SambaNova提供的AI计算平台RDUs(Reconfigurable Dataflow Units)上进行训练的。
由各个语言的native speaker来评测模型的回答效果。
对于英语、中文、法语、阿拉伯语、西班牙语、印度语这6种语言的回答效果,相比于GPT-4的54.75%胜率,BLOOMChat获得了45.25%的胜率,弱于GPT-4。
但是,与其它主流的开源聊天LLM相比,它有66%的时间表现更优。
在WMT翻译任务中同样表现出色,领先于其它基于BLOOM的微调模型和其它主流开源聊天模型。
BLOOMChat的思路来源于先前工作的启发,即在一个语言中进行指令微调可以提升多语言模型在另一种语言中的效果表现,BLOOMChat使用了包括OpenChatKit的OIG、Dolly 2.0和OASST1数据集在内的以英语为主的对话数据集来进行BLOOM(176B)的模型微调。
尽管只在英语数据集上进行了微调,作者观察到BLOOMChat在非英语场景下的聊天质量也得到了显著提高。
数据收集
BLOOMChat微调的指令数据有2类。
- 第一种,是由程序自动合成的对话数据集OpenChatKit,数据量大。OpenChatKit训练数据集就是由Together公司联合LAION和Ontocord开源出来的。
- 第二种,是人工写出来的高质量问答数据集Dolly 2.0和OASST1,数据量小。
指令微调(fine tune)
整个微调是在SambaNova公司的RDU(Reconfigurable Dataflow Units) AI平台进行,基座模型是BLOOM-176B。
微调分2步进行:
- 第一步,对OpenChatKit的每个数据源按照100k数据量进行采样,然后训练一轮。这是由于OpenChatKit包含多种数据源,而且数据量比较大,所以对OpenChatKit的每个数据源先进行采样,得到很多子数据集,然后完整fine tune一遍所有子数据集。
- 第二步,对Dolly 2.0和OASST1结合在一起的数据集做3轮fine tune。
所有数据集相关的数据和代码、微调和推理的脚本都免费开源在GitHub上,开源地址参考文末链接。
实验效果
BLOOMChat团队做了3种不同场景的实验测评,评测了英语、中文、阿拉伯语、法语、西班牙语和印度语。
实验1:人类评估
以OpenAssistant Conversations里的22个英文问题作为基准,让其它语言的native speaker把这22个英文问题翻译为其它语言,然后找另外的native speaker来评价模型给出的回答。
评测了以下3种开源模型:
- OpenAssistant-30B: an open-source state-of-the-art chat-aligned LLM。
- LLaMA-Adapter-V2-65B: an open-source state-of-the-art chat-aligned LLM。
- BLOOMZ (176B): an open-source LLM instruction tuned from BLOOM (176B)。
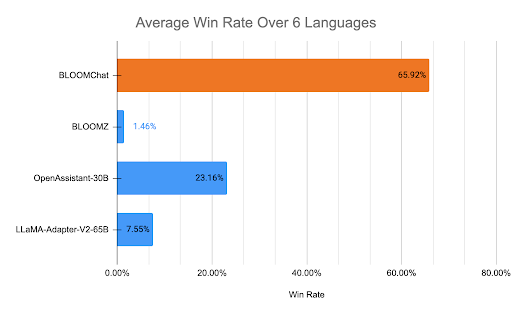
看上图就知道,BLOOMChat明显优于其它几个开源模型。
和GPT-4相比,还是略逊一筹,GPT-4在评测记录中,55%的评测记录是优于BLOOMChat的。
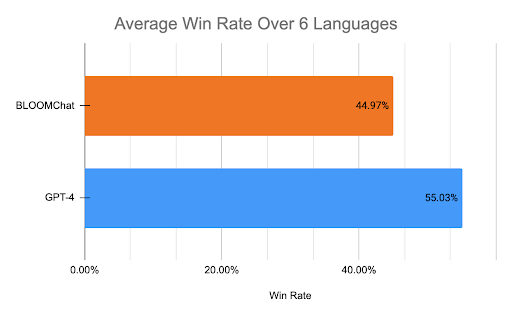
实验2:模型质量评估
对BLOOMChat的回答数据,让native speaker进行评测。
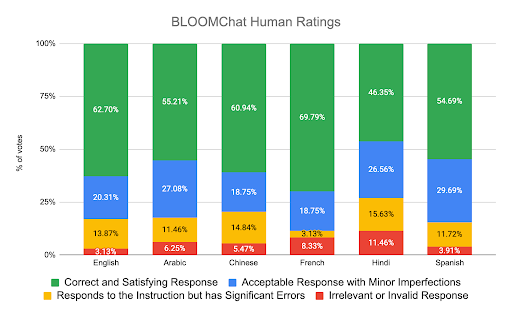
上图可以看出,尽管只在英语数据集上进行了微调,但是对于每个语言的回答,超过70%都是正确或者可接受的。
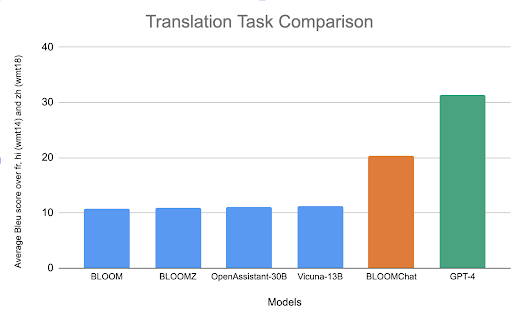
实验3:WMT翻译任务
对比了多个开源模型在WMT翻译任务上的表现,总体而言,BLOOMChat优于其它开源模型,但是明显弱于GPT-4。
BLOOMChat的局限性
与大多数聊天语言模型(LLM)一样,BLOOMChat也有一些局限性:
-
BLOOMChat有时可能会生成听起来合理但事实不正确或与主题无关的回复信息。
-
BLOOMChat可能在单个回复中无意间切换语言,影响输出的连贯性和可理解性。
-
BLOOMChat可能会产生重复的短语或句子,导致回复内容缺乏吸引力和有效信息。
-
BLOOMChat在生成代码或解决复杂数学问题方面的效果还相对 一般。
-
BLOOMChat可能无意中生成含有不适当或有害内容的回复。
总结
BLOOMChat是第一个完全开源、参数超千亿、专门针对多语言支持的聊天LLM。
文章和示例代码开源在GitHub: GPT实战教程,可以看到所有主流的开源LLM。
公众号:coding进阶。关注公众号可以获取最新GPT实战内容。
个人网站:Jincheng’s Blog。
知乎:无忌。
References
- https://sambanova.ai/blog/introducing-bloomchat-176b-the-multilingual-chat-based-llm/
- https://huggingface.co/spaces/sambanovasystems/BLOOMChat
- https://github.com/sambanova/bloomchat





![[iOS开发]<多线程-NSOperation操作队列NSOperationQueue>](https://img-blog.csdnimg.cn/cb200747bfdd46f6865b4fb78ea17bd7.png)