大家好,我是千与千寻,你们可以叫我千寻哥,算一算写ChatGPT的技术文章已经写到第四篇了!
今天和大家介绍的一个项目属于音频领域的ChatGPT的应用实践。真没想不到,在音频领域,ChatGPT都没有放过,ChatGPT这是杀疯了呀!

现在的ChatGPT是一个实打实的风口,也希望大家跟我一起努力在风口上飞起来!
之前我曾经写过三篇ChatGPT相关的,大家可以再去看一看,今天和大家介绍的大模型应用是AudioGPT,与其他的ChatGPT的区别在于,ChatGPT属于大模型的文字对话模型。
而AudioGPT则是针对于语音领域。AudioGPT可实现的功能有以下几点,给大家总结一下。
另外大家需要注意的是AudioGPT的使用是需要基于ChatGPT基础的,为什么这么说呢?原因在于需要我们通过使用OpenAI的API key进访问权限的验证,如图为OpenAI key的获取示意图

所以大家如果还没有OpenAI的GPT账号的,自己去申请一下,然后将这个API Key放到这个AudioGPT的输入框中,即可进行运行程序。
以下是AudioGPT程序的地址:
https://github.com/AIGC-Audio/AudioGPT
以下跟大家演示一下如何在自己的电脑上去运行AudioGPT的代码程序,以及如何学会正确运用AudioGPT实现对应的功能?
首先需要实现搭建模型运行环境,然后安装requirements文件列表里面的这依赖项,以及怎么实现在我们本地的客户端去运行AudioGPT的程序。
- 创建运行程序新的conda环境
# create a new environment
conda create -n audiogpt python=3.8
- 安装环境运行所需依赖,以及下载模型文件
# prepare the basic environments
pip install -r requirements.txt
# download the foundation models you need
bash download.sh
- 导入你的OpenAI Key字符串进入代码文件
# prepare your private openAI private key
export OPENAI_API_KEY={Your_Private_Openai_Key}
- 开始运行AudioGPT程序
python audio-chatgpt.py
至此我们可以实际检验AudioGPT的实际功能。
以上的操作步骤还是似乎还是偏向于极客,可以直接使用Hugging Face社区,调用实际的API接口,使用更加方便。以下是Hugging Face社区的代码地址:
https://huggingface.co/spaces/AIGC-Audio/AudioGPT
AudioGPT效果如下图所示:
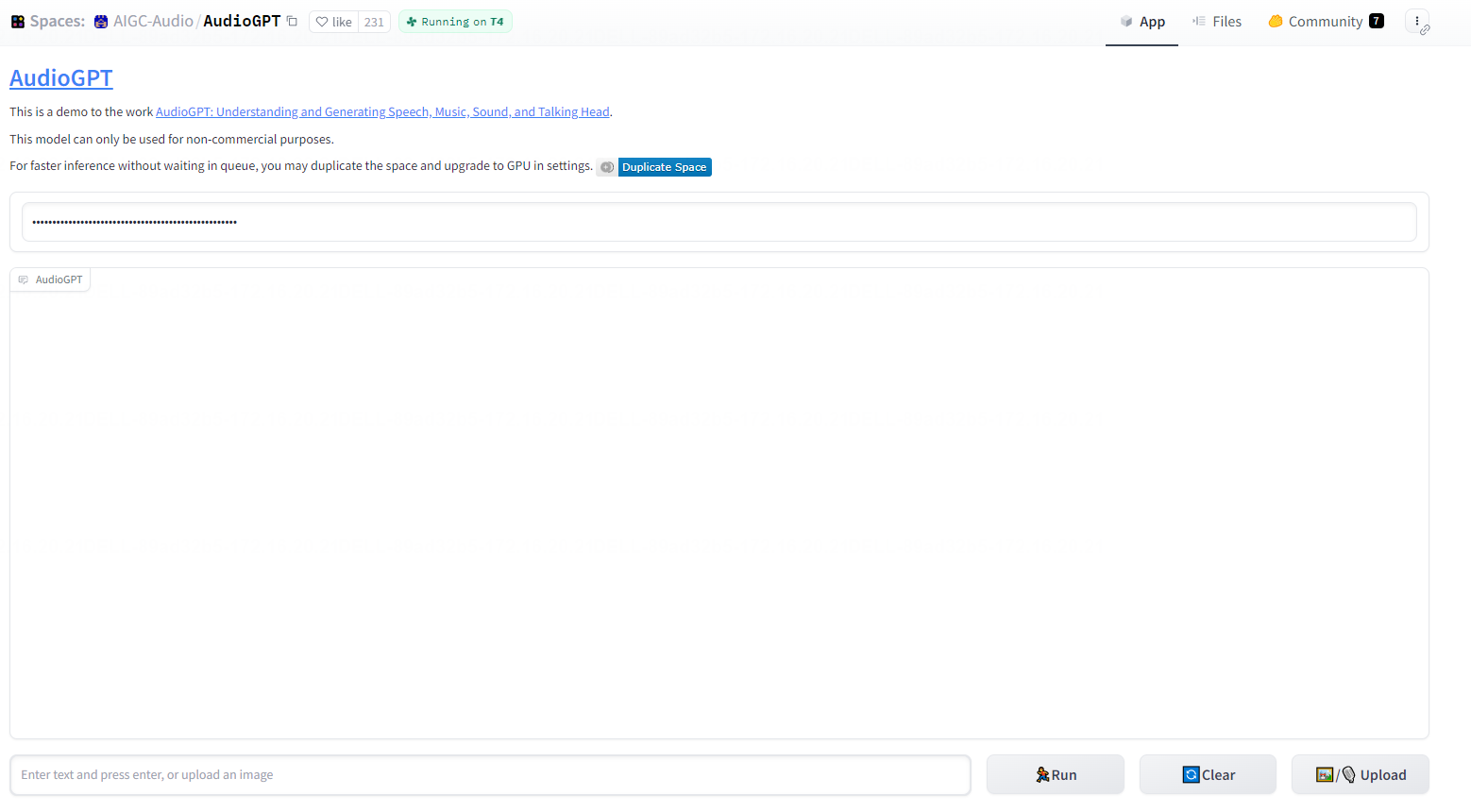
实践环节演示
AudioGPT包括以下几种功能,由于AudioGPT的模型属于语音音频方向的大模型。其功能包括以下的内容分类。
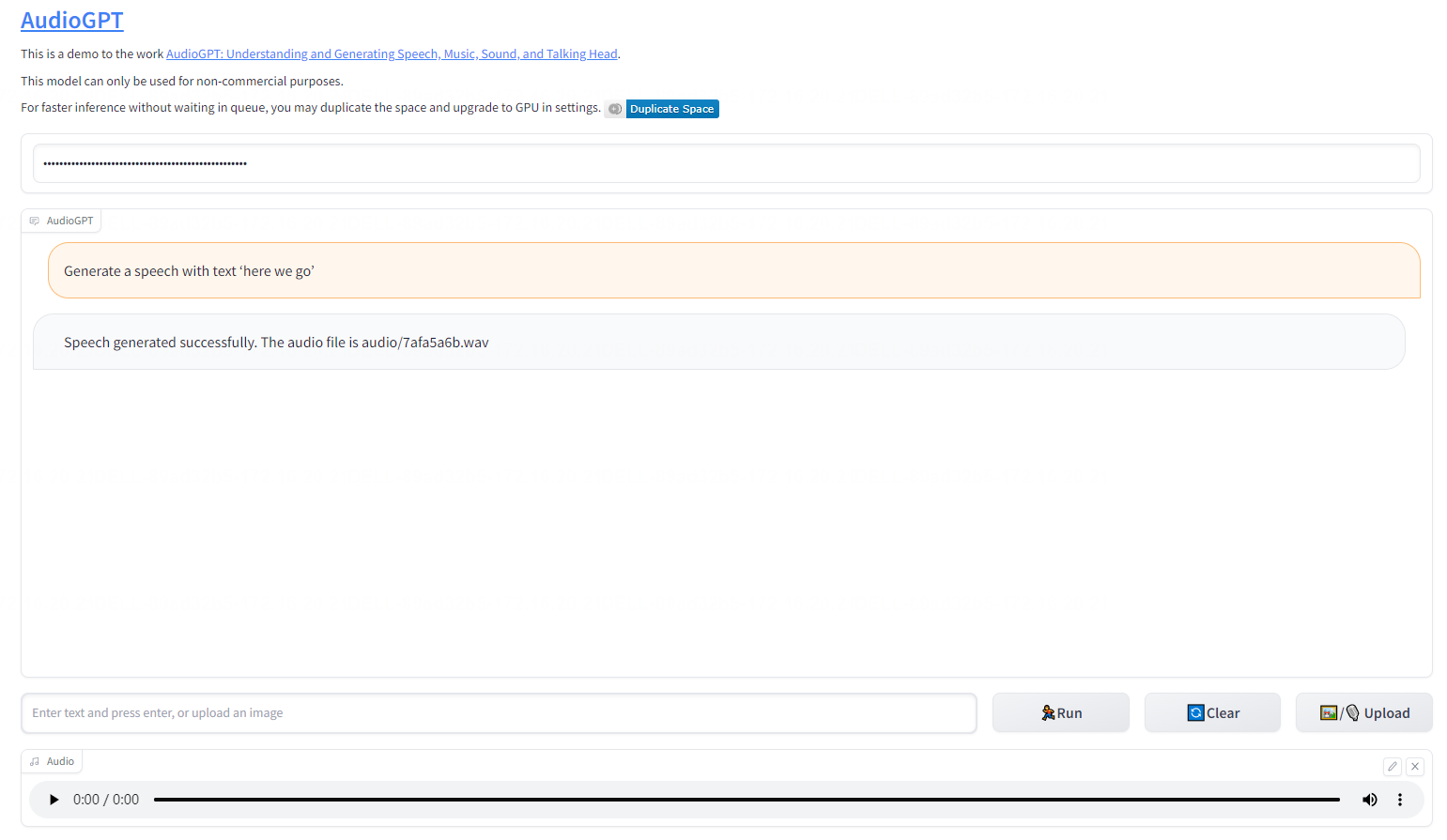
第一、实现根据输入文本转换为语音文件的语音合成
例如:生成带有文本“here we go”的语音音频
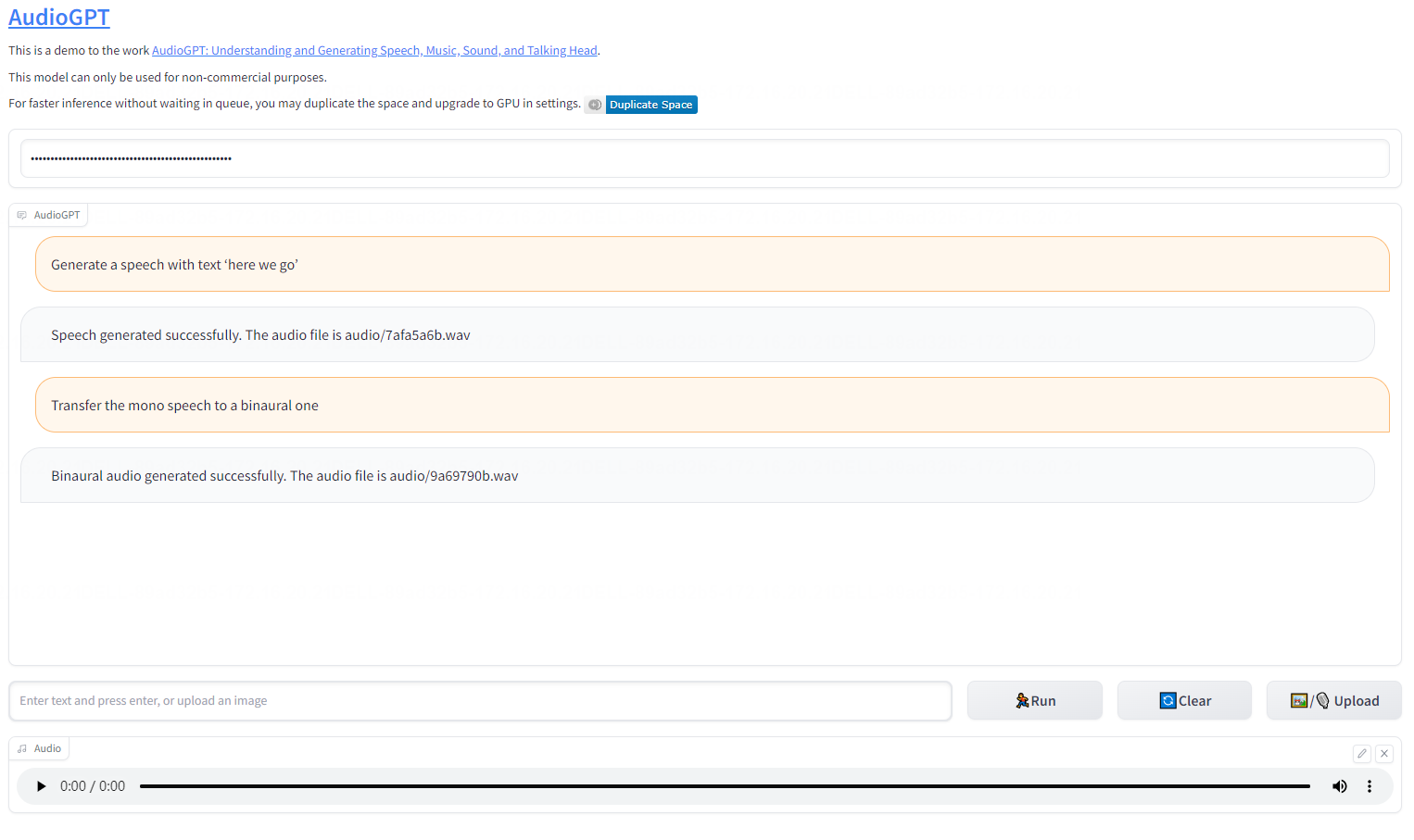
第二、实现将单通道语音转换为双通道语音
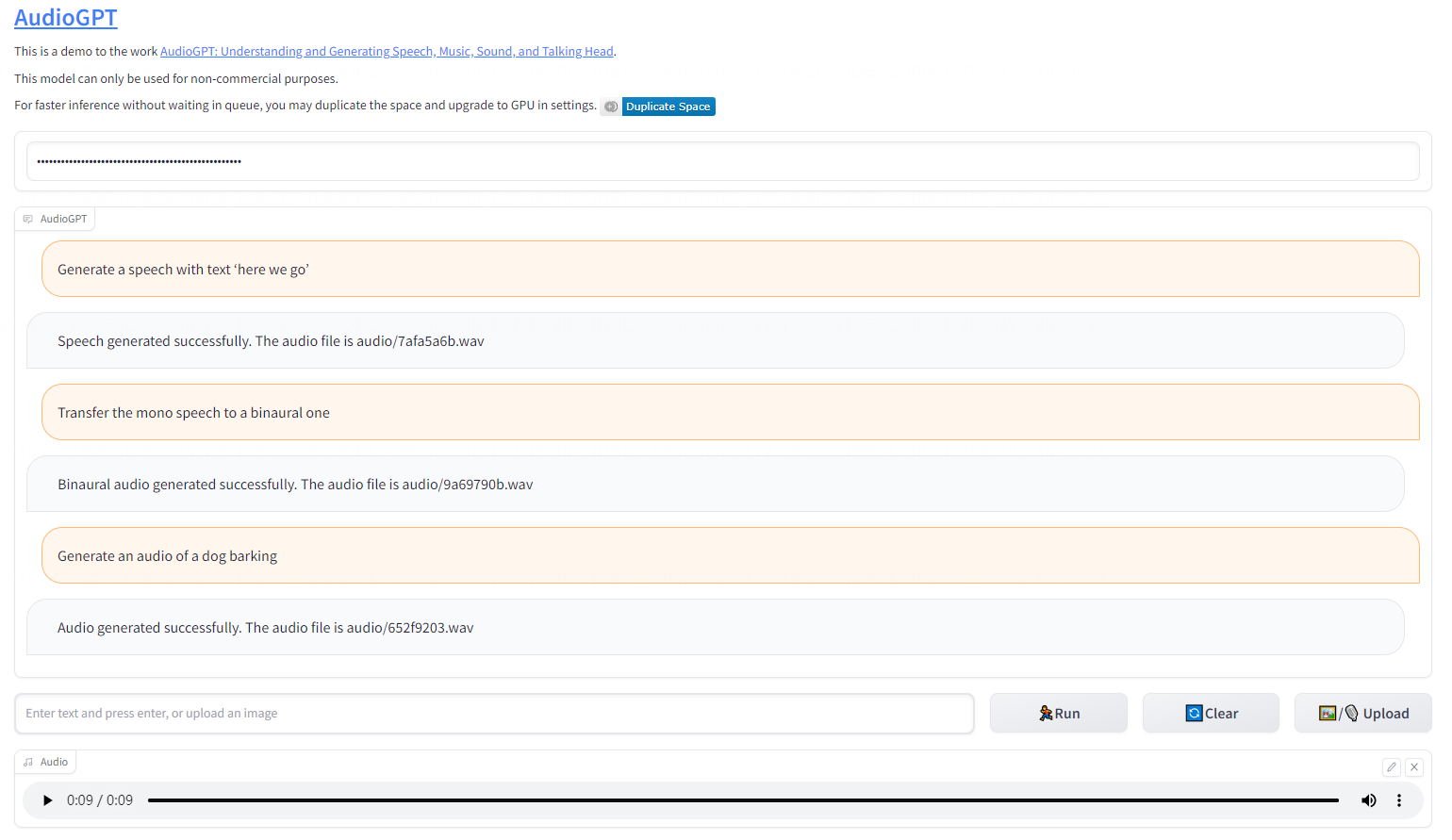
第三、根据语言的文本描述生成对应语音
例如:生成狗叫声的音频:
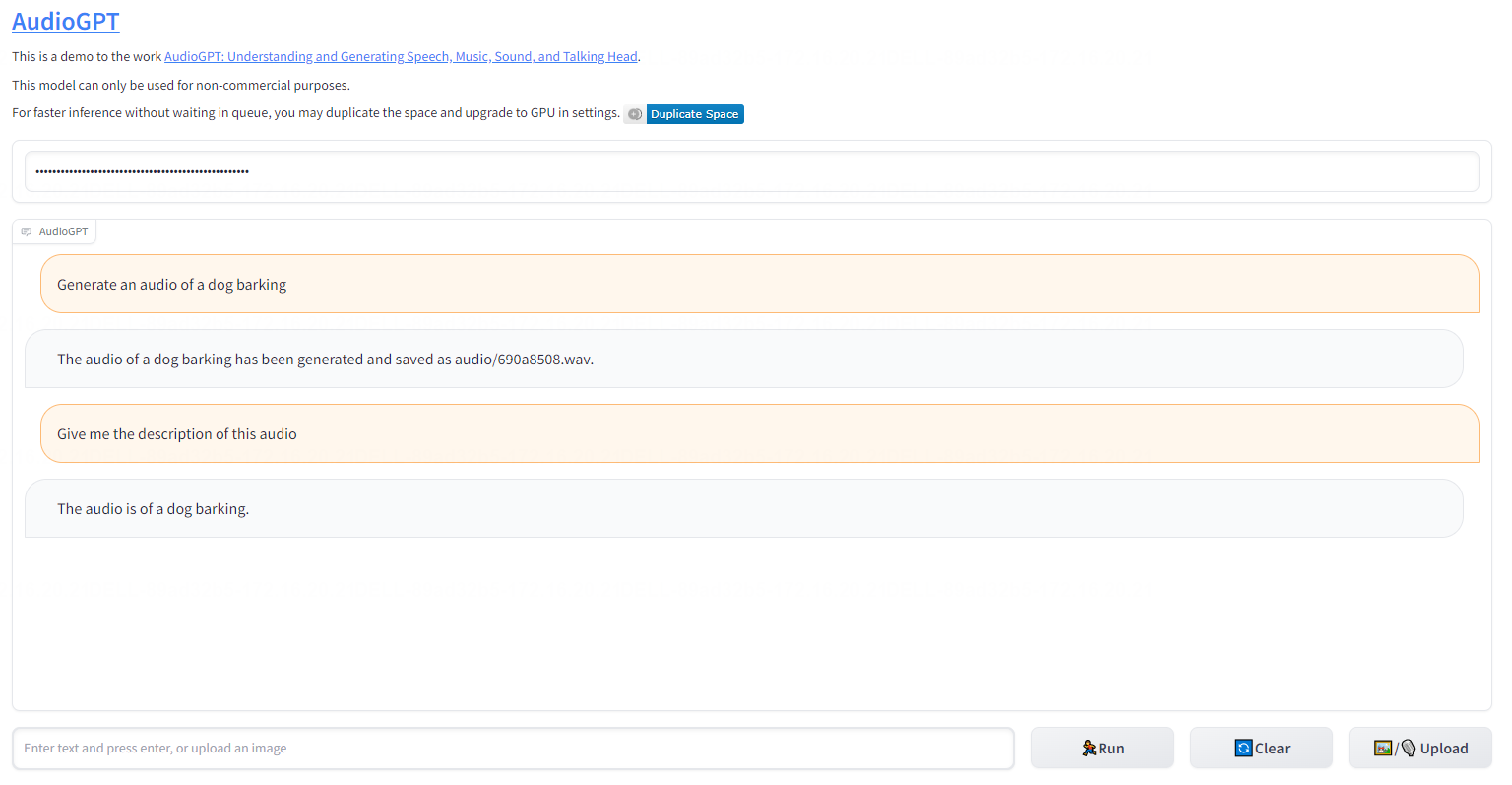
第四,根据音频输出指定文字的描述
例如:给我这个生成音频的描述
第五、根据输入语音信号转换输出其对应的频谱图
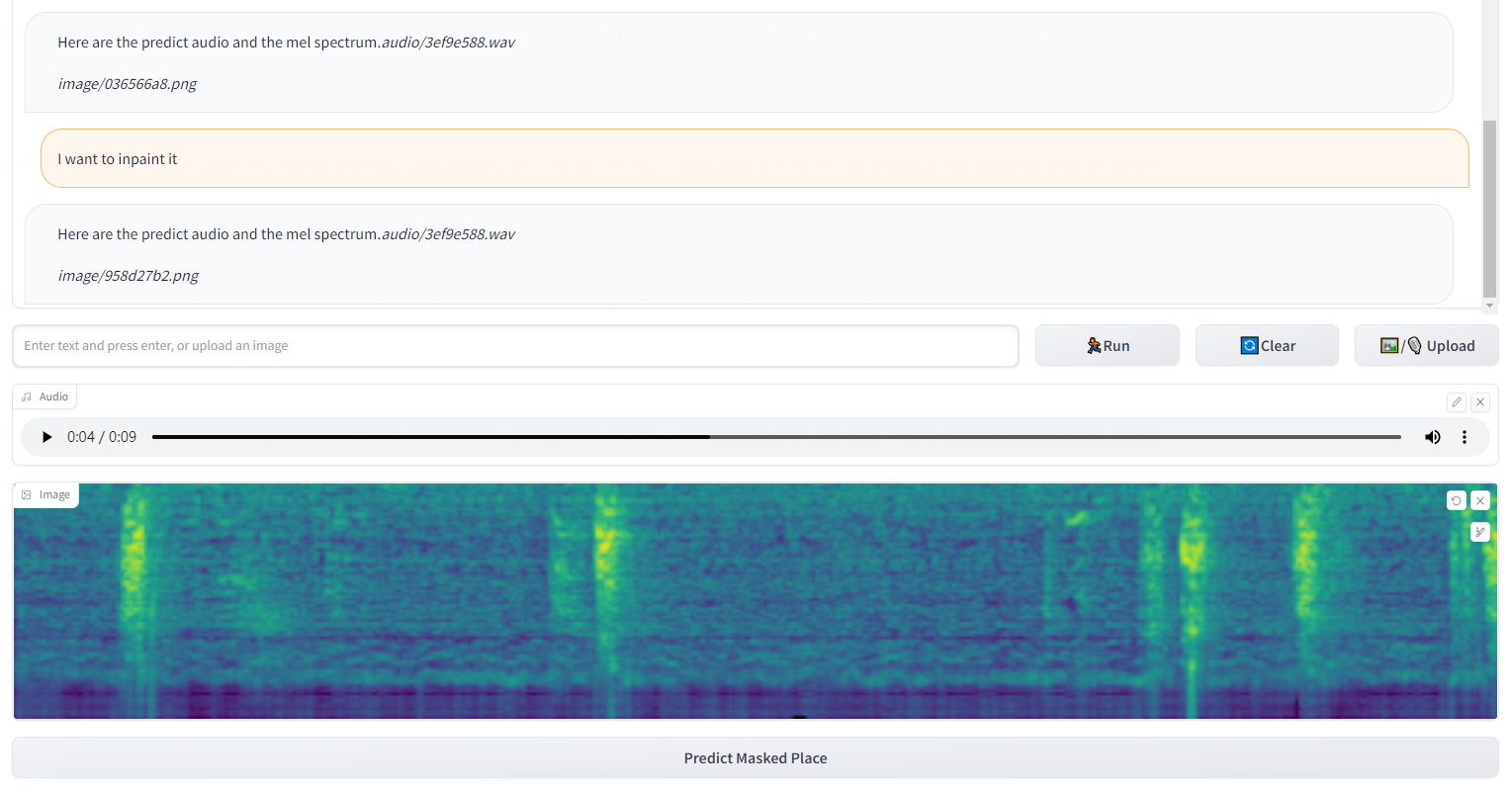
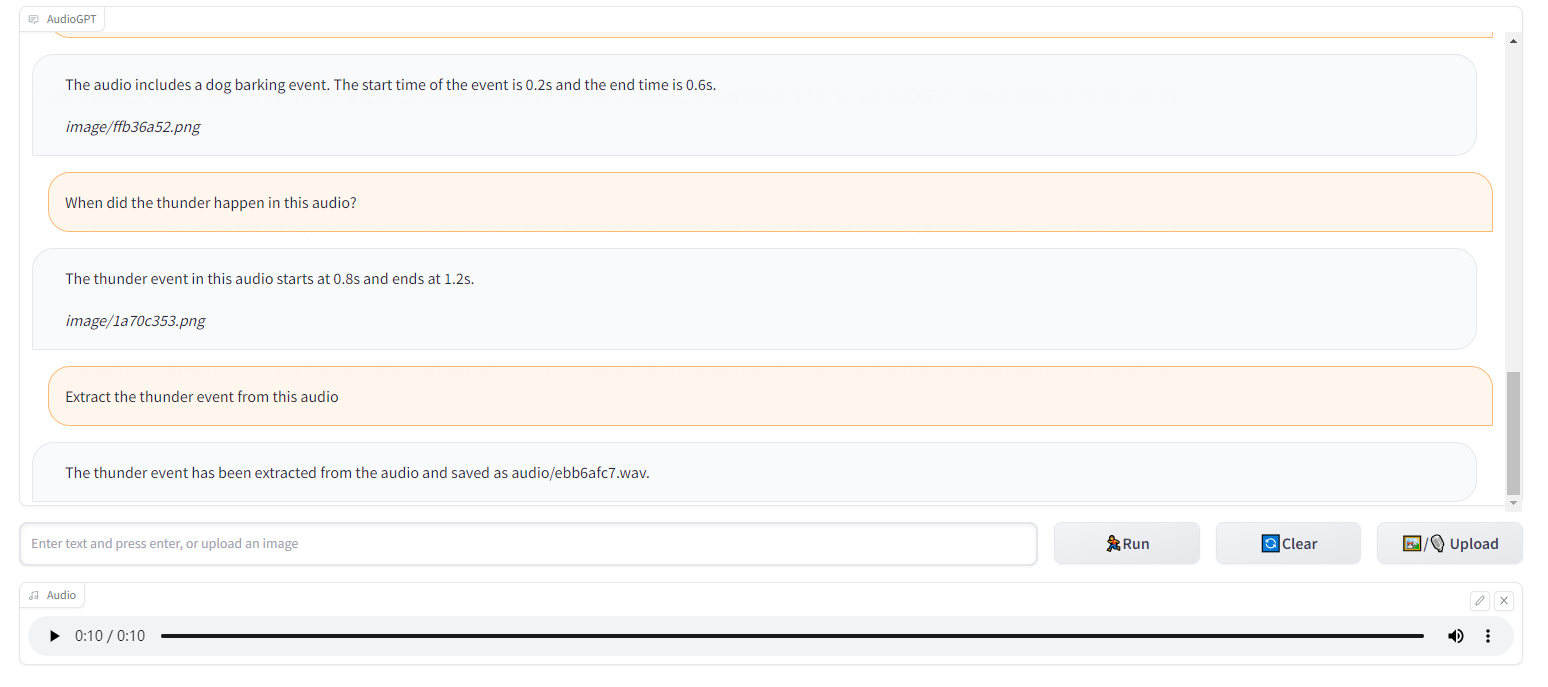
第六、说明音频内部所包含的事件以及起止时间
例如:这段音频中的雷声是什么时候发生的?
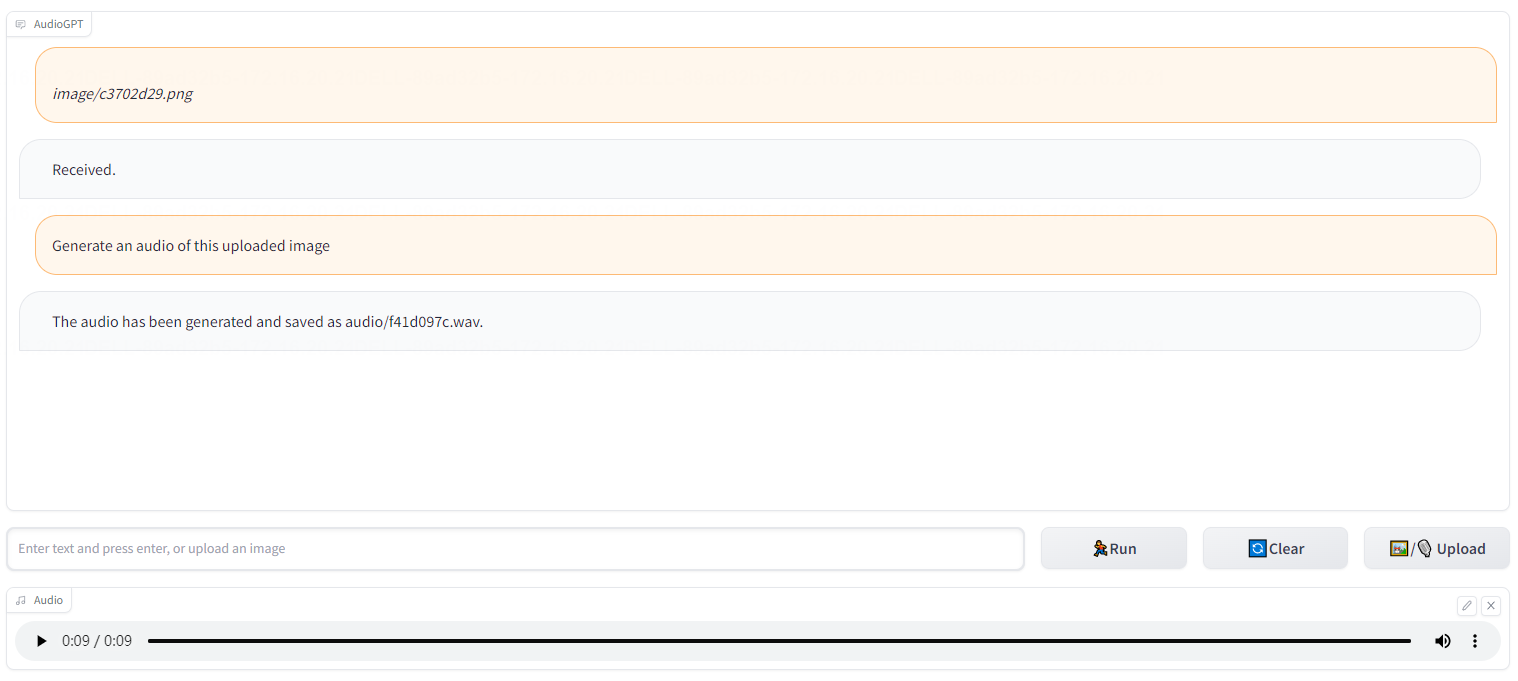
不仅如此,AudioGPT也集成了图像识别的功能,根据图片输入的上传图片生成对应的内容描述音频
例如:上传下图的江南水乡的图片

然后通过江南水乡的图片,生成的雨水声音
怎么样感觉效果如何?不过其实告诉大家一个秘密,音频信号的处理,相对来说,比较占用内存,处理音频的时间较长,可以选择不同的加速硬件GPU,如下图所示
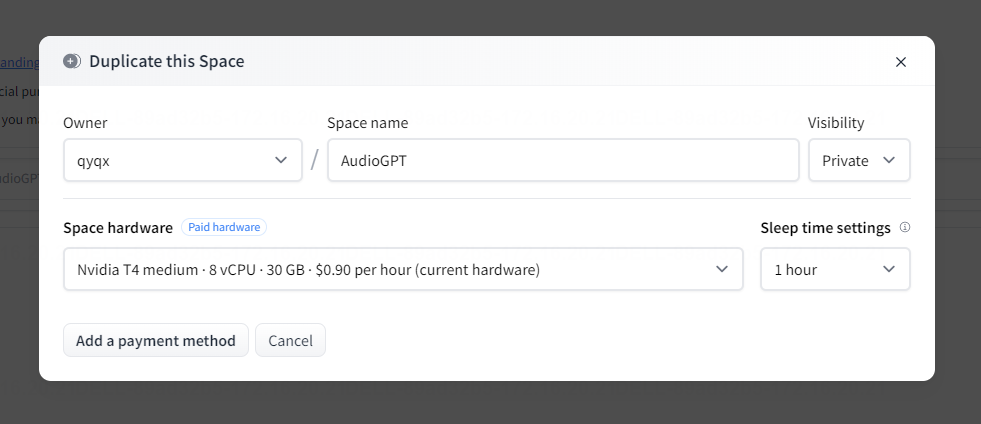
原始使用的T4显卡是免费的,其实理论上计算性能也还不错,免费的,还要啥自行车!
不过如果有更多的需要,当然也可以按需购买。