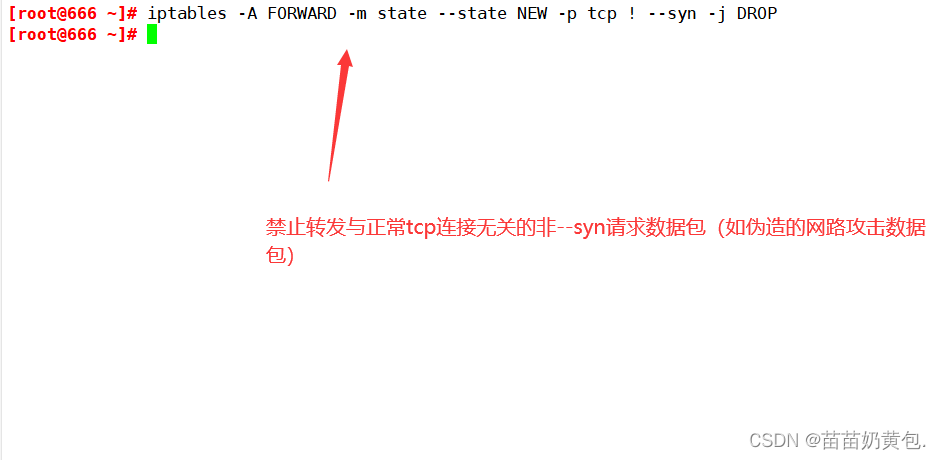
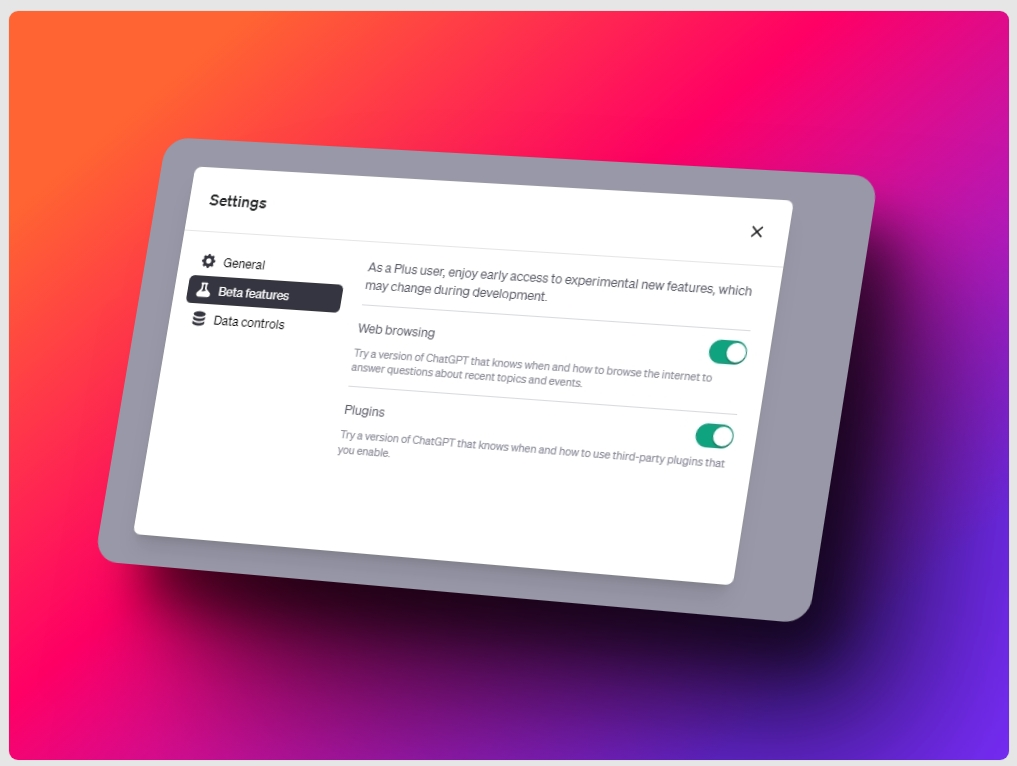
本周,OpenAI 向所有 ChatGPT Plus 用户开放了两个重要功能:
Web Browsing 和 Plugins
它俩都需要用户自己开启,才能使用,如下:
作为对数据库论文的爱好者,我第一款挑选的 Plugin 便是 ChatWithPDF,毕竟真的那么厉害的话,原先1年才能看完的论文,现在1天就能搞定啦
废话不多说,看看开箱体验
1/ 它真的读完了论文
找了一篇 NoSQL/NewSQL 的在线论文给它,它层次分明地组织好了论文的主要观点:
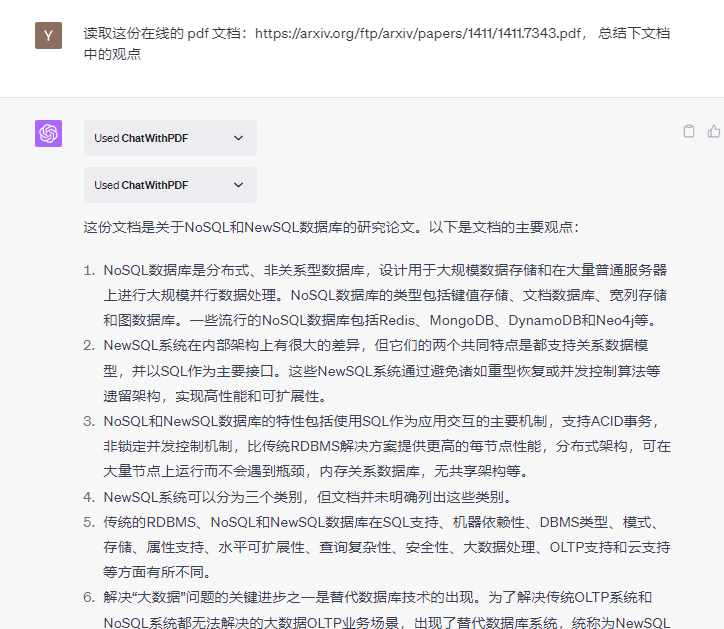
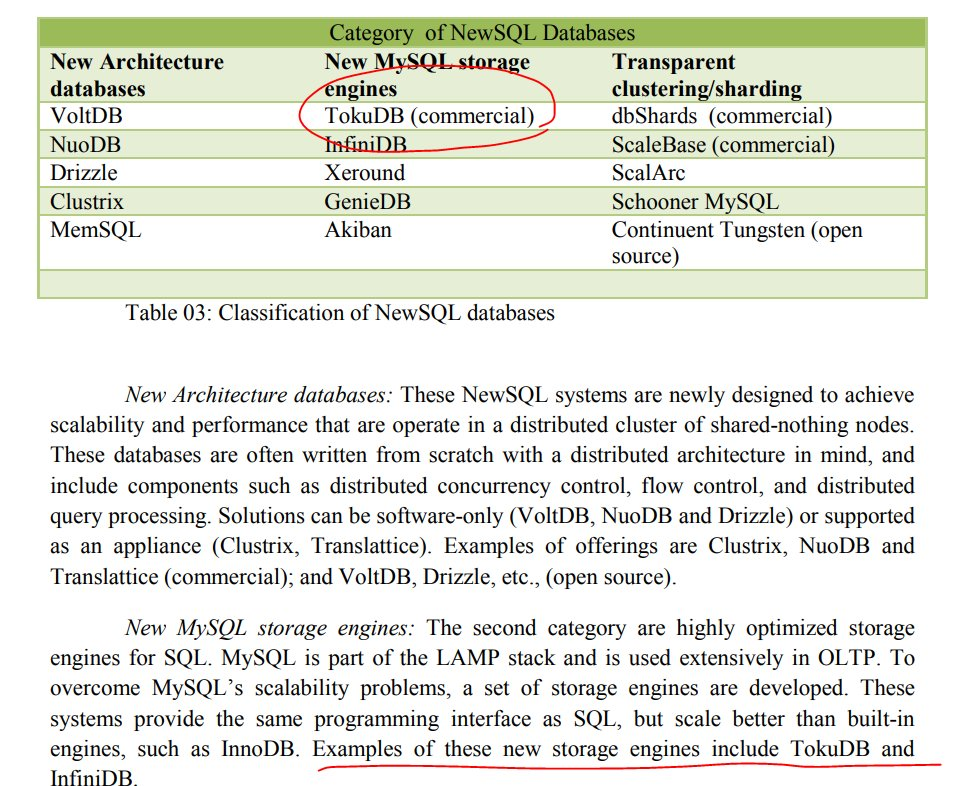
为了验证内容的有效性,我提出了要他罗列文中提到的 NewSQL 产品,它说到了 TokuDB,经查证,正确
当然,同时也验证了其他的关键词:ScalArc
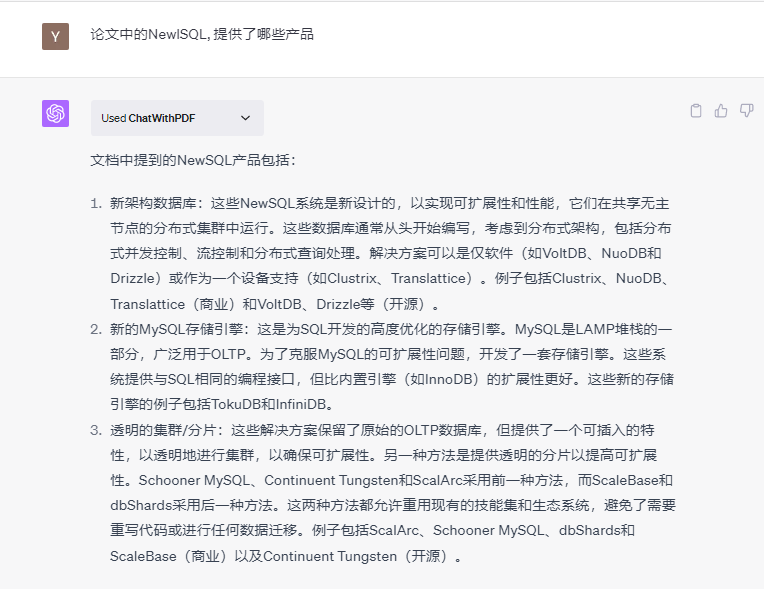
2/ 读文的质量
面对陌生的论文,尤其内含的知识背景超越我已有的框架,着实无法正确判断这个 PlugIn 的质量
于是,我又重新拿了一篇古老的 RDBMS 的论文给它。再它正确读取全部内容后,我重新开了对论文内容的询问
同时我打开了ChatGPT4, 在不使用插件的情况下,看它怎么回答
两相对比,结构与细节都有差异
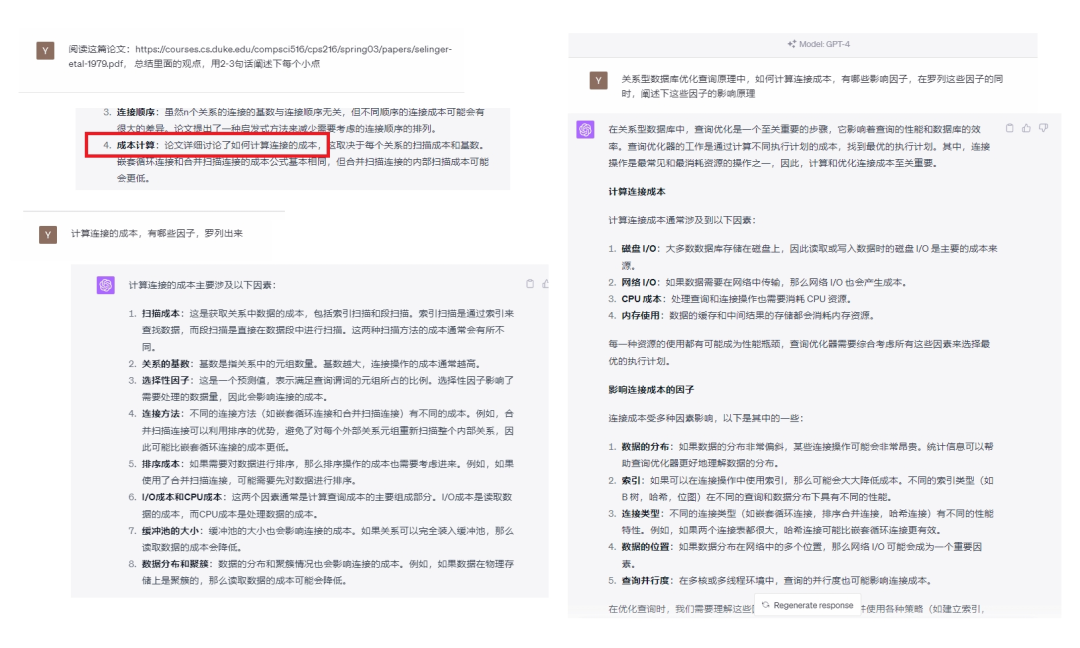
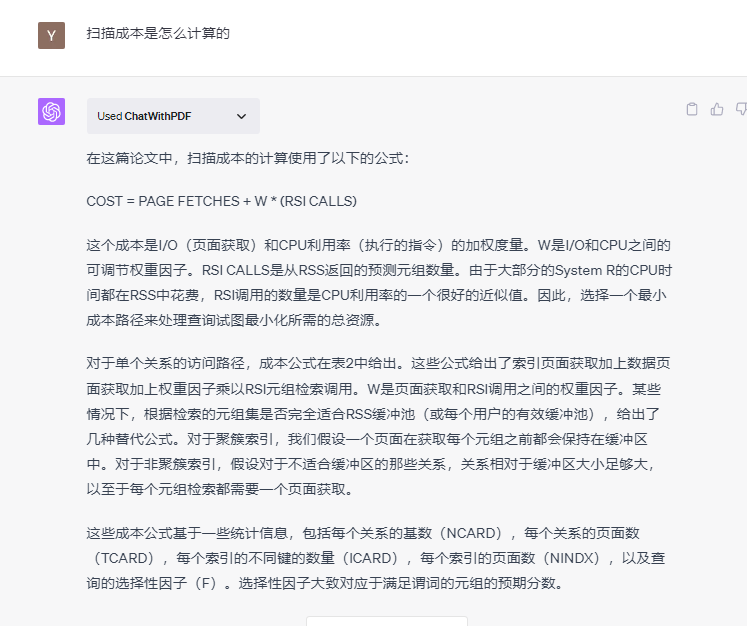
作为数据库从业人员,这篇《Access Path Selection in a RDBMS》论文,真还是值得读一读。很多资深(年纪很大)开发,也不一定知道“聚簇”有啥好处,“连接顺序”会怎么影响性能

3/ 真正与 PDF 论文对话
在反复测试中发现,ChatGPT 有时的回答,并不是论文中的内容。
该如何判断 Plugin 到底是否真的去读了 PDF,并引用其中的论据,来回答问题,还是基于 ChatGPT 的训练语料来回答的?
于是我又做了两个尝试:
1)直接开问;
2)引导它去读论文,比如“用论文中的例子”,“重读论文”,等等
仔细看,当它引用论文时,它的插件有反应,点击便可看到它的动作,即query
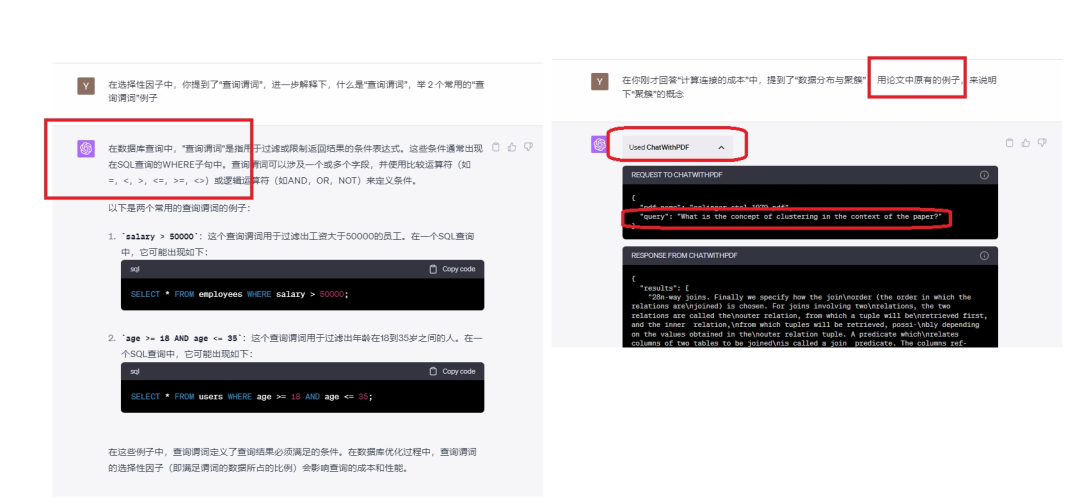
那么,每次提问,都要重发“读原论文”指令,就特别麻烦。怎样更省事?
于是,我加了这么个 Prompt:
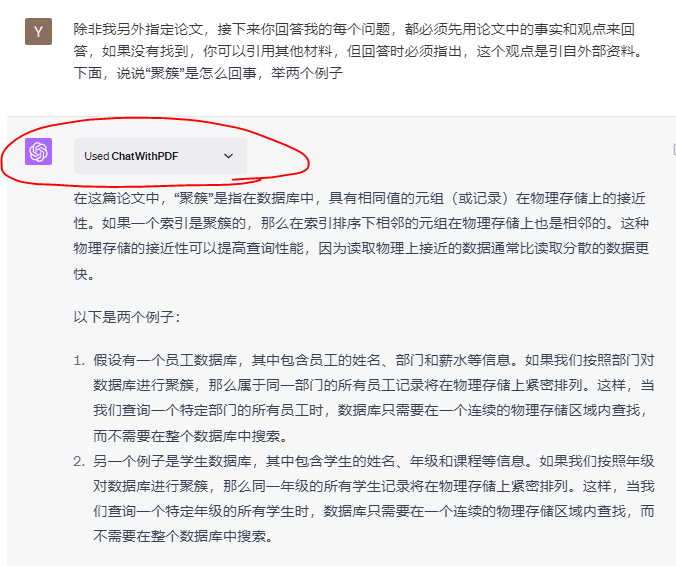
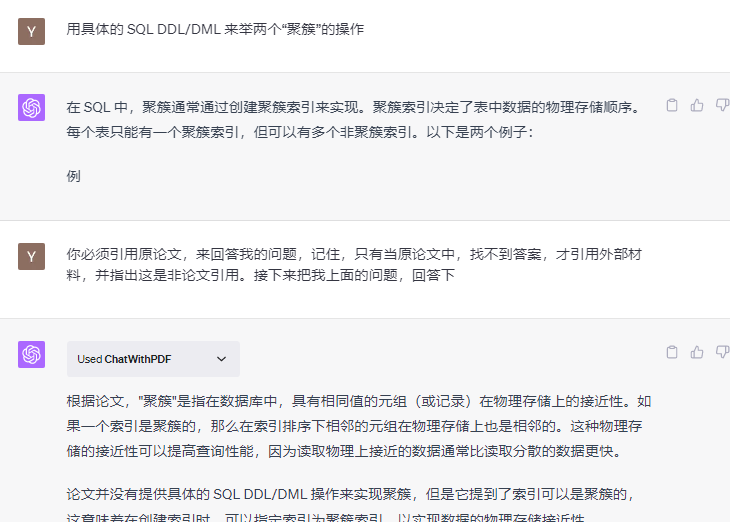
除非我另外指定论文,接下来你回答我的每个问题,都必须先用论文中的事实和观点,如果没有找到,你可以引用其他材料,但回答时必须指出,这个观点是引自外部资料。
提示2边后,它习惯直接搜索PDF
以上就是调教 ChatGPT Plugin 之 ChatWithPDF 的全步骤了。在逐步调教的过程中,慢慢学会摸熟 Plugin 的脾气,知道它的边界,它才能更好的服务于我。
唯一不足的是,在晚上的效率不高,时不时断网。我猜,正好大洋彼岸的人开始摸鱼,造成资源紧张而引起的。
这款 ChatWithPDF值得 5 星推荐
--完--
往期精彩:
本号精华合集(三)
外企一道 SQL 面试题,刷掉 494 名候选人
我在面试数据库工程师候选人时,常问的一些题
零基础 SQL 数据库小白,从入门到精通的学习路线与书单