目录
- 前言
- 一、Http协议状态码301和302的区别
- 二、Time Wait状态的作用是什么?
- 三、ConcurrentHashMap在JDK1.7和JDK1.8的区别
- 四、MySQL的优化:怎么优化SQL、用过MySQL的性能分析工具吗?
- 五、反转数组的算法
- 六、JDBC怎么使用的,什么是SQL注入?
- 七、一致性哈希算法
- 八、抽象类和接口的区别
- 九、select和epoll的区别
- 十、Java中变量存储的位置
- 十一、从100W个数中选出第1、3、5、7、9大的数字?选出第50W大的数字?范围1~300的100W个数,51排在第几?
- 十二、给你一个单词表,然后给你一个单词,判断是不是合法?
- 十三、JVM内存管理
- 十四、Java的垃圾回收是怎样的?为什么新生代中内存的比例是8:1:1?为什么会有新生代老年代?新生代怎么变到老年代?
- 十五、算法:给你n种不同面值的硬币(每种硬币数量不限),求组成面值M的最少的硬币个数。
- 十六、Linux常用指令
- 十七、MySQL的锁机制
- 十八、MVCC机制实现的原理
- 十九、索引的最左匹配原则
- 二十、InnoDB和MyISAM的区别?
- 二十一、稀疏索引和聚簇索引的区别
- 二十二、MVCC在四种隔离级别下都有吗?undo日志什么时候会被删除?
- 二十三、一个事务中读取了A数据还未提交,另外一个事务处理了A数据,那么此时第一个事务读A会改变吗?
- 二十四、Java NIO
- 二十五、Redis的跳表
- 二十六、分布式事务的二阶段提交
- 二十七、分布式事务的三阶段提交
- 二十八、Paxos算法
- 二十九、TCP和UDP的区别
- 三十、从篮子里拿出100个苹果,每次只能拿1个或者2个,有多少种拿法?
- 后记
前言
“实战面经”是本专栏的第二个部分,本篇博文是第四篇博文,如有需要,可:
- 点击这里,返回本专栏的索引文章
- 点击这里,返回上一篇《【Java校招面试】实战面经(三)》
一、Http协议状态码301和302的区别
3XX表示重定向
- 301: 永久重定向
- 302: 临时重定向
302重定向可能会发生URL劫持问题。
二、Time Wait状态的作用是什么?
在TCP的四次挥手中,主动关闭方在发送了最后一次ACK之后进入Time Wait状态,持续时间为2MSL,它的作用是:
1. 如果被动方没有收到最后一次ACK,会重发FIN,最终确保两方都正常终止连接。
2. 等待上一次连接的报文在网络中消失,避免新旧两次连接的混淆。
三、ConcurrentHashMap在JDK1.7和JDK1.8的区别
1. 数据结构: 1.7中用了分段,也就有了锁分段技术,将大表分成一个个小表来分段加锁,而1.8中将分段换成了Node。为了避免链表过长,还引入了红黑树。
2. 锁: 1.7中使用ReentrantLock,1.8中使用synchronized
四、MySQL的优化:怎么优化SQL、用过MySQL的性能分析工具吗?
优化方面用过MySQL的Explain关键字。我说一下我目前的经验
1. 查询方面: 就是尽量让查询走索引,然后如果能限定范围就最好。我们实验室的项目里面,有一次我发现一部分学弟写的查询的代码特别慢,最后发现他循环得对一个长度可能很长的varchar字段进行全表扫描,因为我们的记录是每组7、8行有联系的,所以我进行了分表,将这个长度很长的字段分到单独的表中,在原表中存放它的Id。并将每次循环中查询的行数限定在7、8行内,这样极大地提高了查询效率。
2. 插入方面: 我们要插入到数据库的数据量很大,基本上都是3、40万条,所以如果插入一次commit一下,频繁的IO导致效率很低,于是我使用了批量插入,每1千或1万条插入一次,这样也大大提升了效率,把原来一个小时多的效率优化到了几十秒。
五、反转数组的算法
数组头尾各一个指针,相向而行,交换两个指针处的值,直到左指针 >= 右指针,时间复杂度O(n),空间复杂度O(1)。
public static void reverseArray(int[] arr) {
int start = 0;
int end = arr.length - 1;
while (start < end) {
int temp = arr[start];
arr[start] = arr[end];
arr[end] = temp;
start++;
end--;
}
}
六、JDBC怎么使用的,什么是SQL注入?
1. 因为现在都是用Hibernate框架,所以JDBC一般配置给数据库连接池,然后调用SessionFactory获得连接。
2. SQL注入是指当SQL语句是通过拼接字符串来构造的时候,恶意攻击者可以通过构造恶意语句绕开原来的SQL语义,进行爆库、插入恶意用户等操作。SQL注入可以通过构造
3. 可以通过PerparedStatement来避免SQL注入攻击,其主要提供了以下功能:
1) 预编译: 当你创建 PreparedStatement 对象并提供 SQL 语句时,数据库驱动会将其发送到数据库服务器进行预编译。这样,在执行 SQL 语句之前,数据库可以提前知道执行计划,优化性能。
2) 参数化查询: PreparedStatement 支持参数化查询,这意味着可以在 SQL 语句中使用占位符(例如?),并在运行时设置参数的实际值。这让我们的代码更加安全和清晰。
4. 使用 PreparedStatement 的安全代码示例:
String query = "SELECT * FROM users WHERE username = ? AND passwordHash = ?";
try(Connection connection = dataSource.getConnection()){
PreparedStatement pstmt = connection.prepareStatement(query);
pstmt.setString(1, username);
pstmt.setString(2, passwordHash);
ResultSet rs = pstmt.executeQuery();
// ...
}
在上面的示例中,我们使用?占位符代替实际的参数值,并使用setString方法为参数赋值。这种做法可以确保参数值被正确地转义,无论给定的参数值是什么,都不会导致 SQL 注入攻击。
如果不使用PreparedStatement,而是使用字符串拼接的方法拼接 SQL 语句,则插入恶意 SQL 代码的风险会大大增加。
七、一致性哈希算法
1. 传统哈希取模的缺点: 不利于扩展和容错,增加和删除节点时需要进行大量的数据转移。
2. 一致性哈希算法: 将哈希值空间组织成一个圆环,对要查询的数据的键求哈希值,它将被定为哈希环上顺时针紧邻的节点上。
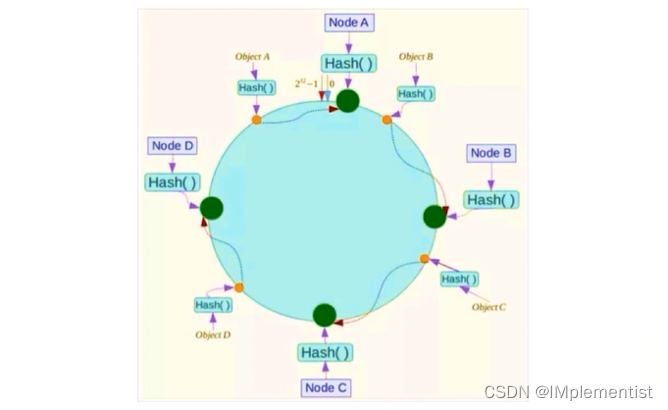
- 增加节点时: 新节点分担顺时针下一个节点的一部分负载;
- 删除节点时: 顺时针下一个节点分担被删除节点的负载;
3. 数据倾斜问题: 当环上的节点较少时,可能会出现有的节点承担了大部分负载的情况,这时候可以比较均匀的构造一些虚拟节点,定位数据时多加一步虚拟节点到真实节点的映射即可。
八、抽象类和接口的区别
1. 因为Java是单继承,所以只能继承一个抽象类,但是可以实现多个接口
2. 抽象类里面可以定义非抽象函数,但是接口的函数只能默认是abstract public
3. 抽象类的函数不一定要覆盖,但是接口的函数必须实现。
九、select和epoll的区别
select和epoll是Linux中的IO多路复用技术。
1. select
1) 通过轮询的方式判断一个通道是否可以执行IO操作;
2) 支持的文件描述符fd是有限的。
2. epoll
1) 基于事件,不需要轮询,当IO设备准备就绪时,调用回调函数进行处理;
2) 在内存足够的情况下,fd的数量没有限制。
十、Java中变量存储的位置
1. 对象存储在堆中
2. 常量存储在常量池中
3. String类型的对象调用intern方法可以将其引用从堆区加载进常量池
十一、从100W个数中选出第1、3、5、7、9大的数字?选出第50W大的数字?范围1~300的100W个数,51排在第几?
1. 先Hash分块,100万分为100块,每块用小根堆选前1、3、5、7、9,然后对合并的100、200、500、700和900个数字排序求第1、3、5、7、9大。
2. 大数据求中位数
1) 把数据分100组,分批装入内存
2) 因为有符号32位整形的范围是[
−
2
31
-2^{31}
−231,
2
31
−
1
2^{31}-1
231−1],总共有4294967296个取值,因此将它划分成100000组,即43000个数映射到一个组。
3) 循环装入100个分组,统计每个数值分组的出现的频率
4) 遍历100000个数值分组,统计所有数字出现的频率直到发现到第i组, s u m i − 1 + g r o u p [ i ] sum_{i-1}+group[i] sumi−1+group[i]大于50W,那么第50万个数一定出现在第i组中。
5) 再循环装入100个分组,设置一个长度位43000的数组targets,统计第i个 分组中的每一个数字出现的频率。
6) 遍历targets的每一位,从
s
u
m
i
−
1
sum_{i-1}
sumi−1开始累加,直到发现sum > 50W,就找到了 目标。
3. 先Hash分块,每块统计小于51的数字出现的频率,合并各块的统计结果,51排在统计结果 + 1的位置
十二、给你一个单词表,然后给你一个单词,判断是不是合法?
用单词表构建前缀树(Trie Tree),然后在前缀术中查找这个单词。
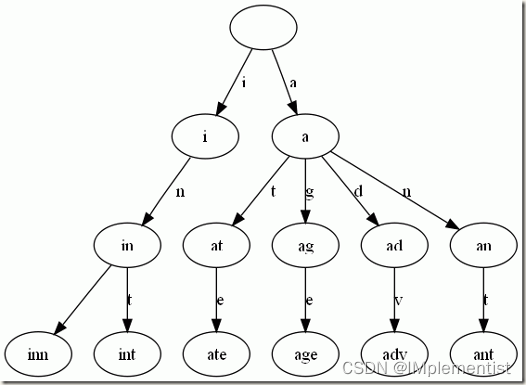
1. 定义前缀树节点TrieNode类
class TrieNode {
public TrieNode[] children;
public boolean isEndOfWord;
public TrieNode() {
children = new TrieNode[26]; // 假设只使用小写字母 a 到 z
isEndOfWord = false;
}
}
2. 创建Trie类,实现insert和search方法
public class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
public void insert(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
int index = word.charAt(i) - 'a';
if (node.children[index] == null) {
node.children[index] = new TrieNode();
}
node = node.children[index];
}
node.isEndOfWord = true;
}
public boolean search(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
int index = word.charAt(i) - 'a';
if (node.children[index] == null) {
return false;
}
node = node.children[index];
}
return node.isEndOfWord;
}
}
3. 在主类中测试Trie功能
public class Main {
public static void main(String[] args) {
Trie trie = new Trie();
trie.insert("apple");
trie.insert("banana");
trie.insert("orange");
// 应输出 true
System.out.println("Searching 'apple': " + trie.search("apple"));
// 应输出 true
System.out.println("Searching 'banana': " + trie.search("banana"));
// 应输出 false
System.out.println("Searching 'grape': " + trie.search("grape"));
}
}
上述代码实现了一个简单的 Trie(前缀树),并演示了如何向树中插入单词以及在树中搜索单词。Trie 类中的 insert 方法用于向树中插入单词,而 search 方法用于检查给定单词是否在树中。
注意,此实现仅支持由小写字母 a 到 z 组成的单词。 若要支持更多字符,可以调整 TrieNode 类的 children 数组长度。
十三、JVM内存管理
见《实战面经(一)》第六题
十四、Java的垃圾回收是怎样的?为什么新生代中内存的比例是8:1:1?为什么会有新生代老年代?新生代怎么变到老年代?
1. Java的垃圾回收使用分代收集算法,将堆内存分为新生代和老年代,其中新生代又分为Eden区和Survivor区,Survivor又分为From和To区,他们的比例是8:1:1。
2. 一项统计学的研究测算出来超过90%的对象会在一次Minor GC中被回收,因此设定了新生代的比例为8:1:1.
3. 由于各个对象存活周期不同,因此需要区分开来,减少因为GC带来的性能消耗。
4. 新生代的对象经过一定次数的Minor GC会晋升到老年代;新生代放不下的大对象会直接晋升到老年代。
十五、算法:给你n种不同面值的硬币(每种硬币数量不限),求组成面值M的最少的硬币个数。
1. 算法
public static int minCoinChange(int[] coins, int targetValue) {
int[] dp = new int[targetValue + 1];
dp[0] = 0;
for (int i = 1; i <= targetValue; i++) {
dp[i] = Integer.MAX_VALUE;
for (int coin : coins) {
if (i - coin >= 0 && dp[i - coin] != Integer.MAX_VALUE) {
dp[i] = Math.min(dp[i], dp[i - coin] + 1);
}
}
}
return dp[targetValue] == Integer.MAX_VALUE ? -1 : dp[targetValue];
}
2. 在主类中测试该算法
public class MinimumCoinChange {
public static void main(String[] args) {
int[] coins = {1, 5, 10, 20, 50};
int targetValue = 83;
System.out.println("Minimum coins required: " + minCoinChange(coins, targetValue));
}
}
算法说明:
- 在
minCoinChange函数中,我们使用dp数组来存储不同面值硬币组合的最佳解。dp[i]代表组成面值 i 的最少硬币个数。我们首先将dp[0]设置为0,然后在循环中为数组的其他索引赋值。- 对于
0 < i <= targetValue的每个索引,我们遍历硬币数组。如果当前硬币面值小于或等于 i,我们更新 dp[i] 的值为dp[i]和dp[i - coin] + 1中的较小值。这个过程将使我们逐步找到达到目标面值所需的最少硬币个数。- 最后,我们返回
dp[targetValue]。如果dp[targetValue]为Integer.MAX_VALUE,则意味着我们无法组合出目标面值,返回 -1。否则,返回找到的最少硬币个数。
在该代码示例中,硬币面值分别为 1、5、10、20 和 50,目标面值为 83。运行程序,它将输出最少硬币个数 5(1个50硬币、1个20硬币、1个10硬币和2个1硬币)。
十六、Linux常用指令
见《实战面经(一)》第十八题
十七、MySQL的锁机制
1. 从共享和独占的方面划分: 共享锁和独占锁
2. 从锁住的对象划分: 行级锁、表级锁、页级锁
其中行级锁又分为:
1) Record Lock(记录锁): 在索引上上锁
2) Gap Lock(间隙锁): 锁住一个范围
3) Next-Key: 是记录锁和间隙锁的组合,用于避免幻读。
十八、MVCC机制实现的原理
见《实战面经(三)》第五题
十九、索引的最左匹配原则
1. 最左前缀匹配原则是非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。比如a = 3 and b = 4 and c > 5 and d = 6,如果建立(a,b,c,d)顺序的索引,则d用不到索引,如果建立(a,b,d,c)的索引,则都可以用到,索引中a,b,d的顺序可任意调整。
2. =和IN可以乱序,比如a = 1 and b = 2 and c = 3,建立(a,b,c)的索引可以任意顺序,mysql查询优化器会自动优化成索引可以识别的形式。
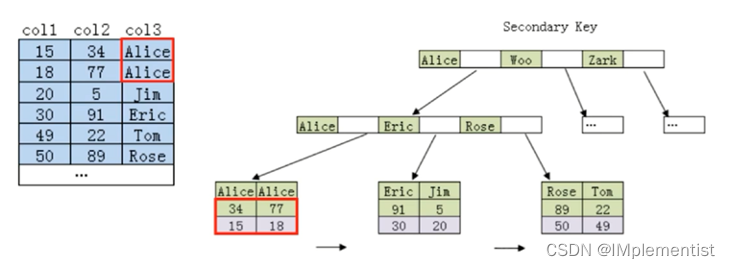
3. 一个联合索引的例子(索引顺序为(col3,col2))
二十、InnoDB和MyISAM的区别?
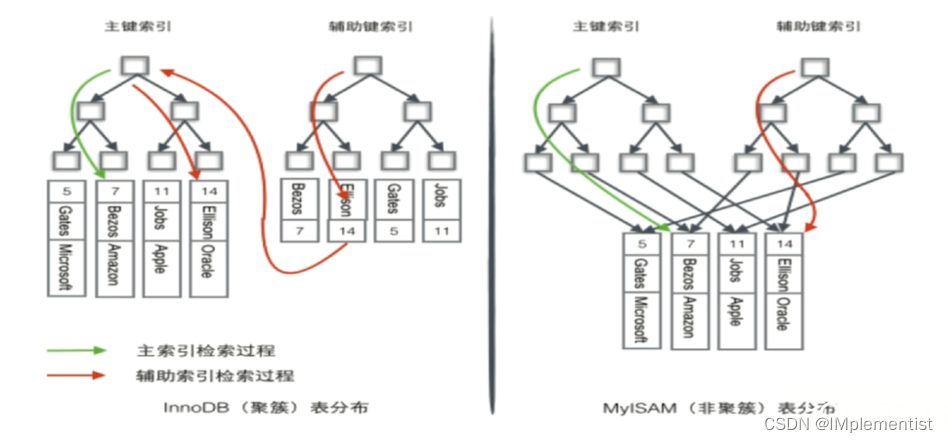
1. MyISAM不支持行级锁,InnoDB支持行级锁;
2. MyISAM只支持稀疏索引,InnoDB支持聚簇索引;
3. MyISAM不支持事务管理,InnoDB支持事务管理。
二十一、稀疏索引和聚簇索引的区别
1. 密集索引文件中的每个搜索码值都对应一个索引值,稀疏索引文件只为索引码的某些值建立索引项;
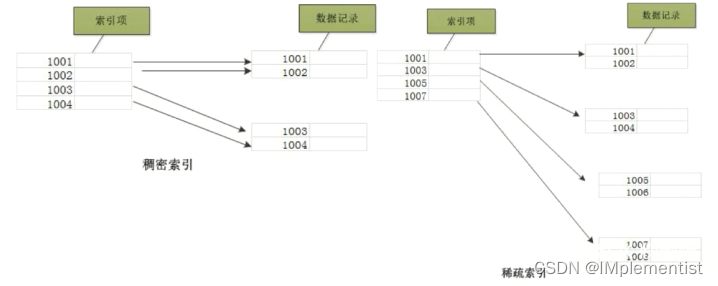
2. 密集索引的叶子节点中不止存储了键,还保存了对应记录的其他属性。稀疏索引的叶子结点仅存储了键,以及对应记录的地址。
3. 密集索引表示了一个表的物理排序,因此一个表只能建立一个密集索引;
二十二、MVCC在四种隔离级别下都有吗?undo日志什么时候会被删除?
1. MVCC只有在RC和RR隔离级别下有;
2. undo日志在事务提交后就会被删除。
二十三、一个事务中读取了A数据还未提交,另外一个事务处理了A数据,那么此时第一个事务读A会改变吗?
RC隔离级别下第一个事务会读出A数据的新值,RR隔离级别下第一个事务会读出A数据的原值。
二十四、Java NIO
见《实战面经(一)》第十一题
二十五、Redis的跳表
跳跃表是一种随机化的数据结构,在查找、插入和删除这些字典操作上,其效率可比拟于平衡二叉树,跳跃表基于有序单链表,在链表的基础上,每个结点不只包含一个指针,还可能包含多个指向后继结点的指针,这样就可以跳过一些不必要的结点,从而加快查找、删除等操作。

1. Redis使用跳跃表作为有序集合键的底层实现之一,若一个有序集合包含的元素数量比较多,或者有序集合中的成员是比较长的字符串时,Redis就会使用跳跃表来作为有序集合键的底层实现。
2. Redis的跳跃表实现有三点不同:
1) 允许重复的score;
2) 排序不只根据分数,还可能根据成员对象(当分数相同时);
3) 有一个前驱指针,便于从表尾向表头遍历。
二十六、分布式事务的二阶段提交
为了解决分布式一致性问题,提出了很多典型的协议和算法,比较著名的是二阶段提交协议,三阶段提交协议。
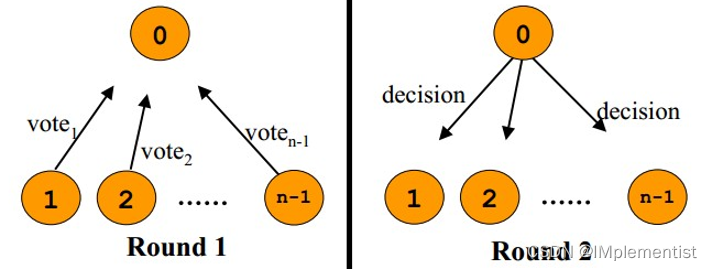
1. 请求阶段(表决): 事务协调者通知每个参与者准备提交或取消事务,然后进入表决过程,参与者在本地执行事务,写本地的redo和undo日志,但不提交。请求阶段,参与者将告知协调者自己的决策: 同意(本地作业执行成功)或取消(本地作业执行故障)
2. 提交阶段(执行): 在该阶段,协调者将基于第一个阶段的投票结果进行决策: 提交或取消。当且仅当所有的参与者同意提交事务,协调者才通知所有的参与者提交事务,否则协调者将通知所有的参与者取消事务。参与者在接收到协调者发来的消息后将执行相应的操作。
3. 缺点
1) 同步阻塞: 执行过程中,所有参与节点都是事务阻塞型的;
2) 单点故障: 由于协调者的重要性,一旦协调者发生故障,参与者会一直阻塞下 去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的 状态中,而无法继续完成事务操作;
3) 数据不一致: 在阶段二中,当协调者向参与者发送commit请求之后,发生了局 部网络异常或者在发送commit请求过程中协调者发生了故障,这会导致只有一部分参 与者接收到了commit请求。
二十七、分布式事务的三阶段提交
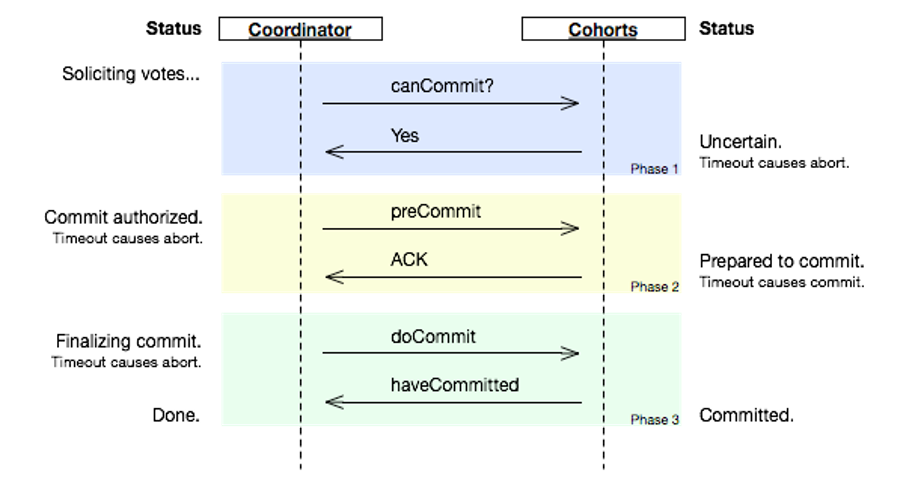
三阶段提交协议在协调者和参与者中都引入超时机制,并且把两阶段提交协议的第一个阶段分成了两步: 询问,然后再锁资源,最后真正提交。
1. canCommit阶段: 协调者向参与者发送commit请求,参与者如果可以提交就返回yes响应,否则返回no响应。
2. preCommit阶段: 协调者根据参与者canCommit阶段的响应来决定是否可以继续事务的preCommit操作。根据响应情况,有下面两种可能:
1) 所有参与者的反馈都是yes: 进行事务的预执行,协调者向所有参与者发送 preCommit请求,并进入prepared阶段。参与者和接收到preCommit请求后会执行事 务操作,并将undo和redo信息记录到事务日志中。如果一个参与者成功地执行了事 务操作,则返回ACK响应,同时开始等待最终指令
2) 有一个是No或是等待超时: 中断事务,协调者向所有的参与者发送abort请 求。参与者在收到来自协调者的abort请求,或超时后仍未收到协调者请求,执行事 务中断。
3. doCommit阶段: 协调者根据参与者preCommit阶段的响应来决定是否可以继续事务的doCommit操作。根据响应情况,有下面两种可能:
1) 协调者从参与者得到了ACK的反馈: 协调者从预提交状态进入到提交状态,并 向所有参与者发送doCommit请求。参与者接收到doCommit请求后,执行正式的事务 提交,并在完成事务提交之后释放所有事务资源,并向协调者发送haveCommitted的 ACK响应。那么协调者收到这个ACK响应之后,完成任务。
2) 协调者没有得到ACK的反馈, 或者收到非ACK响应,或者响应超时: 执行事 务中断。
4. 优点
1) 非阻塞式的;
2) 引入了超时机制。
二十八、Paxos算法
角色: 提议者、接受者、学习者,每个节点都可以担任以上角色。
1. 选举: 提议者向所有的Monitor节点发出提案,Monitor节点在收到提案后,如果同意就回复ack,提议者统计收到的ack数,如果超过了 n 2 + 1 \frac{n}{2}+1 2n+1,当选领导者,向其他节点发送victory消息宣布赢得了选举并开始同步消息。
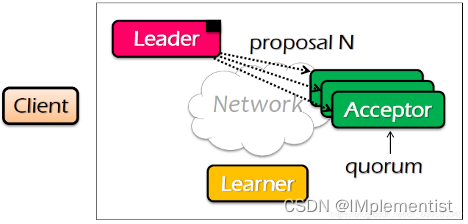
2. 领导者创建提议N,发送给其他节点(N比该提议者之前任何提议的编号都大)
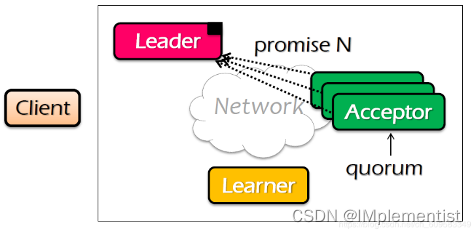
3. 接受者收到提议,如果提议N比之前提议大,那么回复领导者过去提议最高的编号和值,并承诺忽视所有小于N的提议;如果提议N比之前的提议小,直接忽略掉,提议被拒绝。
4. 领导者如果收到了足够的允诺,则设定提议的值为V,V可以是决定好的也可以是最新的值,并发送带有N和V的接收请求给其他节点。
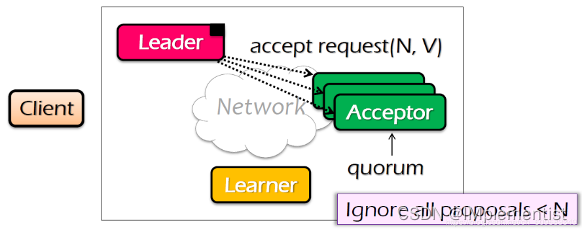
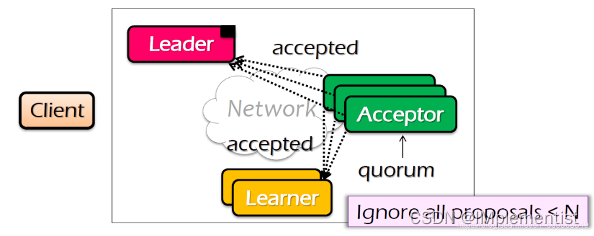
5. 对于接受者,如果提议仍然保留,注册V值,发送已接收信息给提议者和学习者。
二十九、TCP和UDP的区别
| 协议 | 是否面向连接 | 可靠性 | 有序性 | 速度 | 量级 | 适用场景 |
|---|---|---|---|---|---|---|
| TCP | 是 | 可靠 | 有序 | 慢 | 重量级 | 上传、下载文件等需要传输的数据具有高可靠性的场景 |
| UDP | 否 | 不可靠 | 无序 | 快 | 轻量级 | 视频流、音频流传输这类要求快、流畅、但数据可靠性要求不是很高的场景 |
三十、从篮子里拿出100个苹果,每次只能拿1个或者2个,有多少种拿法?
实际上就是斐波那契数列,f(n) = f(n - 1) + f(n - 2)
public class FibonacciRecursive {
public static void main(String[] args){
int n = 100;
System.out.printf("Methods to pick 100 apples: %d", fibonacci(n));
}
public static int fibonacci(int n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
}
后记
这份面经也考的非常全面。在这篇的后面几道题中,我们补齐了Redis中跳表和分布式相关的知识点。



![[Nacos] Nacos Client向Server发送注册请求和心跳请求 (二)](https://img-blog.csdnimg.cn/8bfbea59897d4b9bba55edd9e44931df.png)