4-《安卓进阶》
- 1 Okhttp
- 2 Retrofit
- 3 Android常用图片库对比
- 4 Glide原理+手写图片加载框架思路
- 5 Rxjava
- 6 Android IPC机制(面试八股文之一)
- 6.1.Android中进程和线程的区别
- 6.2.IPC概念
- 6.3.Android序列化与反序列化
- 6.3.Android如何开启多进程?多进程通信可能会出现的问题?
- 6.4. Android进程间通信方式
- 6.5. Android为何新增binder来作为主要的IPC方式
- 6.6.什么是binder
- 6.7.binder工作原理
- 6.8.AIDL是什么
- 6.9.AIDL支持哪些数据类型
- 6.10.AIDL的关键类,方法和工作流
- 6.11.如何优化多模块都使用AIDL的情况
- 6.12.使用Binder传输数据的最大限制是多少,被占满后会导致什么问题
- 7 组件化/插件化/热更新(热修复)
- 8 jetpack
- 9.Bitmap
- 10.ANR及ANR如何排查?
- 11.LeakCanary 源码分析
java进阶
1 Okhttp
OkHttpClient相当于配置中心, 所有的请求都会共享这些配置(例如出错是否重试、共享的连接池) 。

1.OkHttpCLient中的配置主要有:
- Dispatcher dispatcher:调度器,用于调度后台发起的网络请求,有后台总请求数和单主机总请求数的控制。
- List protocols:支持的应用层协议,即HTTP/1.1、HTTP/2等。
- ListconnectionSpecs:应用层支持的Socket设置,即使用明文传输(用于HTTP)还是某个版本的TLS(用于HTTPS) 。
- Listinterceptors:大多数时候使用的Interceptor都应该配置到这里。
- ListnetworkInterceptors:直接和网络请求交互的Interceptor配置到这里,例如如果你想查看返回的301报文或者未解压的ResponseBody,需要在这里看。
- CookieJar cookieJar:管理Cookie的控制器。Ok Http提供了Cookie存取的判断支持(即什么时候需要存Cookie,什么时候需要读取Cookie,但没有给出具体的存取实现。如果需要存取Cookie,你得自己实现,例如用Map存在内存里,或者用别的方式存在本地存储或者数据库。
- Cachecache:Cache存储的配置。默认是没有,如果需要用,得自己配置出- - Cache存储的文件位置以及存储空间上限。
- int connectTimeout:建立连接(TCP或TLS)的超时时间
- int readTimeout:发起请求到读到响应数据的超时时间
- int writeTimeout:发起请求并被目标服务器接收的超时时间
…
2.newCall(Request)方法会返回一个RealCall对象,它是Call接口的实现。当调用RealCall.execute()的时候,RealCall.getResponsewithInterceptorChain会被调用,它会发起网络请求并拿到返回的响应,装进一个Response对象并作为返回值返回;RealCall.enqueue()被调用的时候大同小异,区别在于enqueue()会使用Dispatcher的线程池来把请求放在后台线程进行,但实质上使用的同样也是getResponsewithInterceptorChain()方法。
3.getResponsewithInterceptorChain方法做的事:把所有配置好的Interceptor放在一个List里,然后作为参数,创建一个RealInterceptorChain对象,并调用chain.proceed(request)来发起请求和获取响应。
4.在RealInterceptorChain中,多个Interceptor会依次调用自己的intercept()方法。这个方法会做三件事:
-
对请求进行预处理
-
预处理之后,重新调用RealIntercepterChain.proceed() 把请求交给下一个Interceptor
-
在下一个Interceptor处理完成并返回之后,拿到Response进行后续处理。
当然了,最后一个Interceptor的任务只有一个:做真正的网络请求并拿到响应。
5.从上到下,每级Interceptor做的事:
- 首先是开发者使用addInterceptor(Interceptor)所设置的,它们会按照开发者的要求,在所有其它Interceptor处理之前,进行最早的预处理工作,以及在收到Response之后,做最后的善后工作。如果你有统一的header要添加,可以在这里设置;
- 然后是RetryAndFollowUpInterceptor:它会对连接做一些初始化工作,并且负责在请求失败时的重试,以及重定向的自动后续请求。它的存在,可以让重试和重定向对于开发者是无感知的;
- BridgeInterceptor:它负责一些不影响开发者开发,但影响HTTP交互的一些额外预处理。例如,Content-Length的计算和添加、gzip的支持(Accept-Encoding:gzip)、gzip压缩数据的解包,都是发生在这里;
- CacheInterceptor:它负责Cache的处理。把它放在后面的网络交互相关Interceptor的前面的好处是,如果本地有了可用的Cache,一个请求可以在没有发生实质网络交互的情况下就返回缓存结果,而完全不需要开发者做出任何的额外工作,让Cache更加无感知;
- ConnectInterceptor:它负责建立连接。在这里,OkHttp会创建出网络请求所需要的TCP连接(如果是HTTP),或者是建立在TCP连接之上的TLS连接(如果是HTTPS),并且会创建出对应的HttpCodec对象(用于编码解码HTTP请求);
- 然后是开发者使用addNetworkInterceptor(Interceptor)所设置的,它们的行为逻辑和使用addInterceptor(Interceptor)创建的一样,但由于位置不同,所以这里创建的Interceptor会看到每个请求和响应的数据(包括重定向以及重试的一些中间请求和响应),并且看到的是完整原始数据,而不是没有加Content-Length的请求数据,或者Body还没有被gzip解压的响应数据。多数情况,这个方法不需要被使用,不过如果你要做网络调试,可以用它。
- CallServerInterceptor:它负责实质的请求与响应的l/O操作,即往Socket里写入请求数据,和从Socket里读取响应数据。
okhttp主要实现了异步、同步的网络操作,创建了不同的call对象,这里的call对象是一个个的runnable对象,由于我们的任务是很多的,因此这里有Dispatcher包装了线程池来处理不同的call,其中该类中创建了三种队列,分别用于存放正在执行的异步任务,同步队列,以及准备的队列。最后在执行每个任务的时候,采用队列的先进先出原则,处理每一个任务,都是交给了后面的各种拦截器来处理,有请求准备的拦截器、缓存拦截器、网络连接的拦截器,每一个拦截器组成了一个责任链的形式。到最后返回response信息。
OkHttp的底层是通过Java的Socket发送HTTP请求与接受响应的(这也好理解,HTTP就是基于TCP协议的),但是OkHttp实现了连接池的概念,即对于同一主机的多个请求,其实可以公用一个Socket连接,而不是每次发送完HTTP请求就关闭底层的Socket,这样就实现了连接池的概念。而OkHttp对Socket的读写操作使用的OkIo库进行了一层封装。
常见问题
责任链模式?
interceptors和networkInterceptors的区别?
2 Retrofit
retrofit利用了工厂模式配置各种参数,分为
生产网络请求执行器(callFactory)、
回调方法执行器(callbackExecutor)、
网络请求适配器(CallAdapterFactory)、
数据转换器(converterFactory)
等几种工厂。
callFactory负责生产okHttp的call,大家都知道okHttp通过生成call对象完成同步和异步的http请求。
callbackExecutorr通过判断不同的平台,生成对应平台的数据回调执行器。其中android端的回调执行器是通过handler回调数据。
CallAdapterFactory是数据解析工厂,一般我们配置json的数据解析适配器就行。
converterFactory是数据转换的工厂,一般我们配置Rxjava的数据转换就行。
-
retrofit通过动态代理模式将接口类配置的注解、参数解析成HTTP对象,最后通过okHttp实现网络请求。
-
简单使用

4.原理解析
通过Retrofit.create(Class)方法创建出Service interface实例,是Retrofit的核心
Retrofit.create(Class)方法内部,使用的是Proxy.newProxyInstance()方法来创建interface实例,这个方法会为interface
创建一个对象,该对象实现了interface的每个方法,调用对面实例内部的一个InvocationHandler成员变量的invoke()方法,
并把自己的方法信息传递进去,就实现了代理逻辑。这些方法的具体实现,是在运行时生成的interface实例时才确定的,而不是
在编译时,这就是动态代理机制。
invoke()中的逻辑,就是Retrofit创建Service实例的关键,有三行关键代码
ServiceMethod的创建:
loadServiceMethod(method)
这行代码读取interface原方法的信息,返回的是一个CallAdapted
OkHttpCall的创建
new OkHttpCall<>(requestFactory, args, callFactory, responseConverter)
OkHttpCall是retrofit2.Call的子类。这行代码将ServiceMethod解读到的信息封装进OkHttpCall,在需要时(如enqueue()被调用时)
创建一个okhttp3.Call对象,并利用okhttp3.Call发起网络请求,然后利用ResponseConvert对结果处理,交回给retrofit的CallBack.
adapt()方法
callAdapter.adapt(call);
这个方法会使用一个CallAdapter对象来把okhttpCall对象进行转换,生成一个新的对象。默认返回的是 ExecutorCallbackCall,它的作用是
把操作切回主线程后再交给Callback。另外,如果有自定义的CallAdapter,这里也可以生成别的对象,如RxJava的Observable,来让Retrofit
可以和RxJava结合。
关于动态代理:一个Java Interface是不可以直接创建一个对象的,所以动态代理所做的是在运行时生成一个实现了该Interface的类的Class对象。
3 Android常用图片库对比
主要对比Glide跟Picasso,然后了解Fresco
Glide:
图片+媒体缓存:Glide不仅是图片缓存,还适用于更多的内容表现形式(如Gif、WebP、缩略图、Video)
生命周期集成:根据Activity或者Fragment的生命周期管理图片加载请求。
高效处理Bitmap:使用Bitmap Pool使bitmap复用,主动调用recycle回收需要回收的Bitmap,减少系统回收压力。
高效的缓存策略:灵活(Picasso只会缓存原始尺寸的图片,Glide缓存的是多种规格:比如imageVIew大小是200200,原图是400400,glide会缓存200200规格的,而Picasso只会缓存400400规格的图),加载速度快且内存开销小(默认Bitmap格式的不同,Glide默认的Bitmap格式是RGB_565,Picasso是ARGB_8888,使得内存开销是Picasso的一半)。
还有一点, Picasso 是加载了全尺寸的图片到内存,下次在任何ImageView中加载图片的时候,全尺寸的图片将从缓存中取出,重新调整大小,然后加载。而 Glide 是按 ImageView 的大小来缓存的,它会为每种大小的ImageView缓存一次。尽管一张图片已经缓存了一次,但是假如你要在另外一个地方再次以不同尺寸显示,需要重新下载,调整成新尺寸的大小,然后将这个尺寸的也缓存起来。具体说来就是:假如在第一个页面有一个200x200的ImageView,在第二个页面有一个100x100的ImageView,这两个ImageView本来是要显示同一张图片,却需要下载两次,使用的使用不需要调整大小直接读取缓存加载。结论:Glide的这种方式优点是加载显示非常快,但同时也需要更大的空间来缓存。
Picasso:
Picasso库的大小大概100k,而Glide的大小大概500k。单纯这个大小还好,更重要的是Picasso和Glide的方法个数分别是840和2678个,这个差距还是很大的,对于DEX文件65535个方法的限制来说,2678是一个相当大的数字了,建议在使用Glide的时候开启ProGuard。
Picasso与Square 公司的其他开源库如 Retrofit 或者 OkHttp搭配使用兼容性会更好些,占用体积也会少些。
Glide能做到Picasso所能做到的一切,只是图像质量可能比Picasso低,xu两者的区别是 Picasso 比 Glide 体积小很多且图像质量比 Glide 高,但Glide 的速度比 Picasso 更快,Glide 的长处是处理大型的图片流,如 gif、video,如果要制作视频类应用,Glide 当为首选。F
Fresco:
最大的优势在于5.0以下(最低2.3)的bitmap加载。在5.0以下系统,Fresco将图片放到一个特别的内存区域(Ashmem区)
大大减少OOM(在更底层的Native层对OOM进行处理,图片将不再占用App的内存)
适用于需要高性能加载大量图片的场景
对于一般App来说,Glide完全够用,而对于图片需求比较大的App,为了防止加载大量图片导致OOM,Fresco 会更合适一些。并不是说用Glide会导致OOM,Glide默认用的内存缓存是LruCache,内存不会一直往上涨。
4 Glide原理+手写图片加载框架思路
Glide考察的频率挺高的,常见的问题有:
Glide和其他图片加载框架的比较?
如何设计一个图片加载框架?
Glide缓存实现机制?
Glide如何处理生命周期?
建议阅读:1.郭霖:Glide最全解析
建议阅读:.面试官:简历上最好不要写Glide,不是问源码那么简单
Glide基本使用:
Glide.with(this).load(url).into(imageView);
with()方法可以接收Context、Activity或者Fragment类型的参数。注意with()方法中传入的实例会决定Glide加载图片的生命周期,如果传入的是Activity或者Fragment的实例,那么当这个Activity或Fragment被销毁的时候,图片加载也会停止。如果传入的是ApplicationContext,那么只有当应用程序被杀掉的时候,图片加载才会停止。
除了加载字符串网址外,还能
// 加载本地图片
File file = new File(getExternalCacheDir() + "/image.jpg");
Glide.with(this).load(file).into(imageView);
// 加载应用资源
int resource = R.drawable.image;
Glide.with(this).load(resource).into(imageView);
// 加载二进制流
byte[] image = getImageBytes();
Glide.with(this).load(image).into(imageView);
// 加载Uri对象
Uri imageUri = getImageUri();
Glide.with(this).load(imageUri).into(imageView);
加载占位图:
.placeholder(R.drawable.loading)
异常占位图:
.error(R.drawable.error)
假如让你自己写个图片加载框架,你会考虑哪些问题?
首先,梳理一下必要的图片加载框架的需求:
异步加载:线程池
切换线程:Handler,没有争议吧
缓存:LruCache、DiskLruCache
防止OOM:软引用、LruCache、图片压缩、Bitmap像素存储位置
内存泄露:注意ImageView的正确引用,生命周期管理
列表滑动加载的问题:加载错乱、队满任务过多问题
当然,还有一些不是必要的需求,例如加载动画等。
异步加载:
线程池,多少个?
缓存一般有三级,内存缓存、硬盘、网络。
由于网络会阻塞,所以读内存和硬盘可以放在一个线程池,网络需要另外一个线程池,网络也可以采用Okhttp内置的线程池。
读硬盘和读网络需要放在不同的线程池中处理,所以用两个线程池比较合适。
Glide 必然也需要多个线程池,看下源码是不是这样
public final class GlideBuilder {
...
private GlideExecutor sourceExecutor; //加载源文件的线程池,包括网络加载
private GlideExecutor diskCacheExecutor; //加载硬盘缓存的线程池
...
private GlideExecutor animationExecutor; //动画线程池
Glide使用了三个线程池,不考虑动画的话就是两个。
5 Rxjava
官方介绍: RxJava:a library for composing asynchronous and event-based programs using observable sequences for the Java VM
(RxJava 是一个在 Java VM 上使用可观测的序列来组成异步的、基于事件的程序的库)
简单说:RxJava是一个基于事件流、实现异步操作的库。
框架结构
RxJava的整体结构是一条链,其中:
- 链的最上游:生产者Observable
- 链的最下游:观察者Observer
- 链的中间:各个中介节点,既是下游的Observable,又是上游的Observer
操作符(map等)的本质
- 基于原Observable创建一个新的Observable
- Observable内部创建一个Observer
- 通过定制Observable的subscribeActual()方法和Observer的onXxx()方法,来实现自己的中介角色(例如数据转换、线程切换等)
dispose工作原理
可以通过dispose()方法来让上游或内部调度器(或两者都有)停止工作,达到「丢弃」的效果。
下面分别讲一下这几种情况:
- Single.just 无后续,无延迟
- Observable.interval 有后续,有延迟
- Single.map无后续,无延迟,有上下游
- Single.delay 无后续,有延迟
- Observable.map 有后续,无延迟
- Observable.delay 无后续,有延迟
这几种情况已经足够把所有dispose的情况都说明完整了
线程切换
1.subscribeOn
-
切换起源Observable的线程
-
当多次调用subscribeOn()的时候,只有最上面的会对起源Observable起作用
2.observeOn -
切换observeOn下面的Observer的回调所在的线程
-
当多次调用observerOn()的时候,每个都好进行一次线程切换,影响范围是它下面的每个Observer(除非又遇到新的obServeOn())
Scheduler的原理
是用来控制控制线程的,用于将指定的逻辑在指定的线程中执行。
其中Schedulers.newThread()里面是创建了一个线程池Executors.newScheduledThreadPool(1, factory)来执行任务,但是这个线程池里面的线程不会得到重用,每次都是新建的线程池。当 scheduleDirect() 被调用的时候,会创建一个 Worker,Worker 的内部 会有一个 Executor,由 Executor 来完成实际的线程切换;scheduleDirect() 还会创建出一个 Disposable 对象,交给外层的 Observer,让它能执行 dispose() 操作,取消订阅链;
Schedulers.io()和Schedulers.newThread()差别不大,但是io()这儿线程可能会被重用,所以一般io()用得多一些。
AndroidSchedulers.mainThread()就更简单了,直接使用Handler进行线程切换,将任务放到主线程去做,不管再怎么花里胡哨的库,最后要切到主线程还得靠Handler。
rxjava背压
指在异步场景中,被观察者发送事件速度远快于观察者的处理速度的情况下,一种告诉上游的被观察者降低发送速度的策略,简而言之,背压是流速控制的一种策略。
需要强调两点:
背压策略的一个前提是异步环境,也就是说,被观察者和观察者处在不同的线程环境中。
背压(Backpressure)并不是一个像flatMap一样可以在程序中直接使用的操作符,他只是一种控制事件流速的策略。
rxjava常用操作符:
map 转换事件,返回普通事件
flatMap 转换事件,返回 Observable
conactMap concatMap 与 FlatMap 的唯一区别就是 concatMap 保证了顺序
subscribeOn 规定被观察者所在的线程
observeOn 规定下面要执行的消费者所在的线程
interval 每隔一定时间执行一些任务
timer 定时任务,多少时间以后发送事件
Zip 专用于合并事件,该合并不是连接(连接操作符后面会说),而是两两配对,也就意味着,最终配对出的 Observable 发射事件数目只和少的那个相同。不影响Observable的发射,Observable 被观察者会一直发射,不会停,只是Observer 接收不到
merge 多个 Observable 发射的数据随机发射,不保证先后顺序
Concat 多个 Observable 组合以后按照顺序发射,保证了先后顺序,不过最多能组合4个 Observable ,多的可以使用 contactArray
如何解决 RxJava 内存泄漏
订阅的时候拿到 Disposable ,主动调用 dispose
使用 RxLifeCycle
使用AutoDispose
map和 flatmap 的区别
Map和flatMap的区别 前者是严格按照1.2.3.4.5顺序发的,经过map以后还是按照这个顺序,后者是1.2.3.4.5发送完到 flatMap 里面,然后经过flatmap进行组装以后再发出来,顺序可能会打乱,使用 contactMap 可以保证转换后的事件发射顺序
6 Android IPC机制(面试八股文之一)
6.1.Android中进程和线程的区别
1.进程是什么?
它是系统进行资源分配和调度的一个独立单位,也就是说进程是可以独立运行的一段程序。
2.线程又是什么?
线程是进程的一个实体,是CPU调度和分派的基本单位,他是比进程更小的能独立运行的基本单位,线程自己基本上不拥有系统资源。在运行时,只是暂用一些计数器、寄存器和栈 。
3.进程和线程的区别
进程有不同的代码和数据空间,而多个线程则共享数据空间,每个线程有自己的执行堆栈和程序计数器为其执行上下文。
进程间相互独立,同一进程的各线程间共享。
进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅 助,以保证数据的一致性。
6.2.IPC概念
IPC(Inter-Process Communication,进程间通信)
IPC在不同操作系统中有不同的实现,常见的有:
- Windows:剪贴板、管道、邮槽
- Linux:命名管道、共享内存、信号量
- Android是一种基于Linux内核的移动操作系统,但是Android的IPC机制并不能完全继承自Linux,相反,它有自己的IPC机制:Binder和Socket。
IPC基础还有以下:
Serializable接口、Parcelable接口以及Binder,只有熟悉这三方面的内容后,我们才能更好地理解跨进程通信的各种方式。Serializable和Parcelable接口可以完成对象的序列化过程,当我们需要通过Intent和Binder传输数据时就需要使用Parcelable或者Serializable。
6.3.Android序列化与反序列化
简单来说:
- 序列化:把对象转换为字节序列的过程称为对象的序列化。
- 反序列化:把字节序列恢复为对象的过程称为对象的反序列化。
序列化的应用场景:
- 性保存对象,保存对象的字节序列到本地文件中;
- 通过序列化对象在网络中传递对象;
- 通过序列化在进程间传递对象;
两种序列化方式的区别:
我们知道Serializeble 是 java 的序列化方式,Parcelable 是 Android 特有的序列化方式;使用Serializeble 简单,继承一个接口就好了,parcelable 复杂一点,还需要重写里面的方法。
两者最大的区别在于存储媒介的不同,Serializable使用IO读写存储在硬盘上,而Parcelable是直接在内存中读写,很明显内存的读写速度通常大于IO读写,所以在Android中通常优先选择Parcelable。(如果要将数据存储在磁盘上,还是要用Serializable)
Serializable 的序列化过程使用了反射技术,并且期间产生临时对象,容易造成GC,优点:代码少。
Parcelable 可以将序列化之后的数据写入到一个共享内存中,其他进程通过Parcelable 可以从这块共享内存中读出字节流,并反序列化成对象。优点:内存中实现,快!不会有大量临时变量
6.3.Android如何开启多进程?多进程通信可能会出现的问题?
通过给四大组件指定android:process属性可以开启多进程模式,在内存允许的条件下可以开启N个进程。(还有一种非常规的多进程方法,通过JNI在native层fork一个新的进程,这种方法暂不讨论)
多进程可能出现的问题:
- 静态成员和单例模式完全失效:独立的虚拟机造成。
- 线程同步机制完全失效:独立的虚拟机造成。
- SharedPreferences的可靠性下降:这是因为Sp不支持两个进程并发进行读写,有一定几率导致数据丢失。
- Application会多次创建:Android系统在创建新的进程时会分配独立的虚拟机,所以这个过程其实就是启动一个应用的过程,自然也会创建新的Application。
对于前两个问题,可以这么理解,在Android中,系统会为每个应用或进程分配独立的虚拟机,不同的虚拟机自然占有不同的内存地址空间,所以同一个类的对象会产生不同的副本,导致共享数据失败,必然也不能实现线程的同步。 由于SharedPreferences底层采用读写XML的文件的方式实现,多进程并发的的读写很可能导致数据异常。 Application被多次创建和前两个问题类似,系统在分配多个虚拟机时相当于把同一个应用重新启动多次,必然会导致 Application 多次被创建,为了防止在 Application 中出现无用的重复初始化,可使用进程名来做过滤,只让指定进程才进行全局初始:
public class MyApplication extends Application{
@Override
public void onCreate() {
super.onCreate();
String processName = "com.shh.ipctest";
if (getPackageName().equals(processName)){
// do some init
}
}
}
6.4. Android进程间通信方式
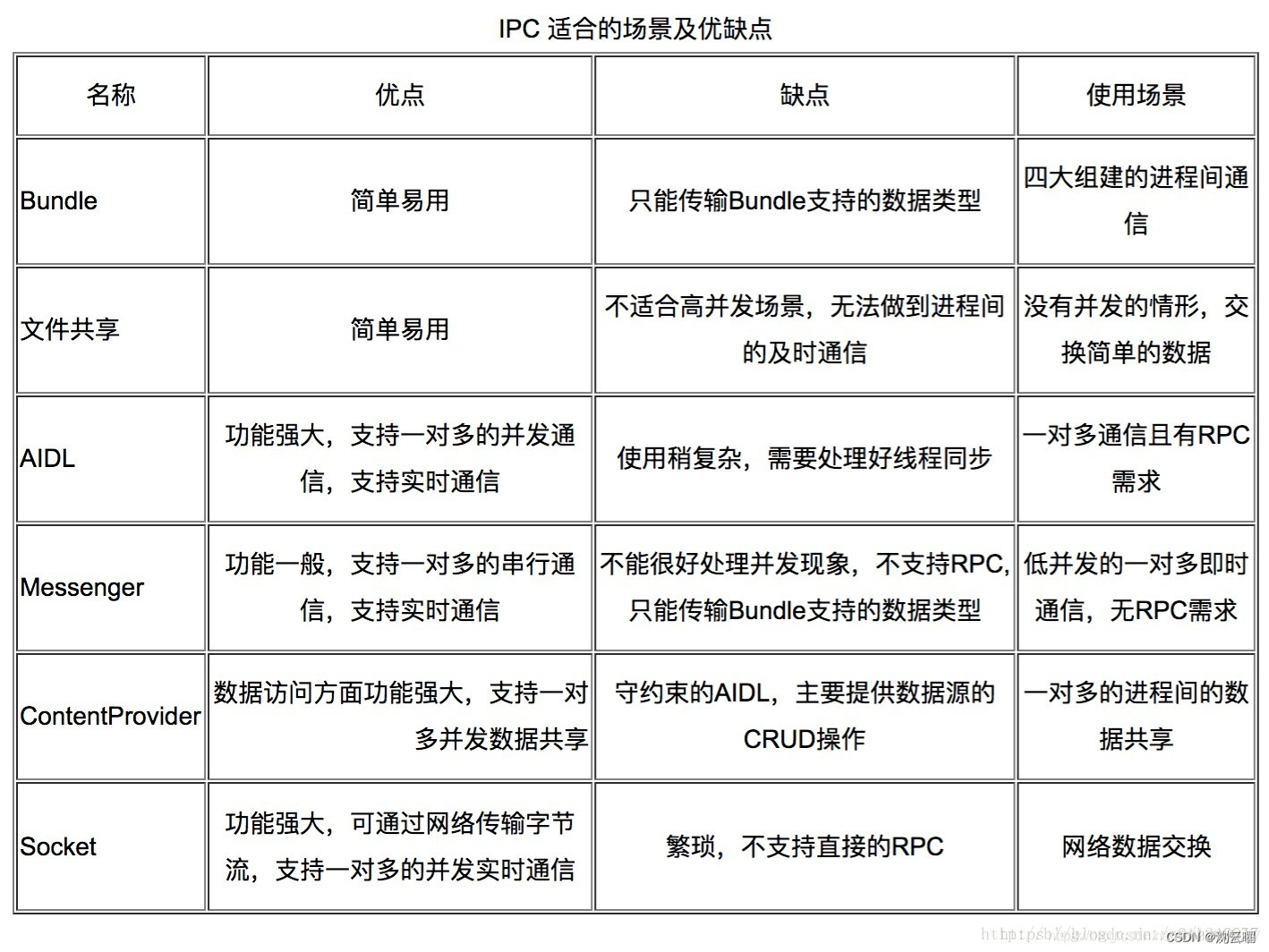
Bundler实现了Parcelable接口,所以它可以方便的在不同进程中传输数据。四大组件中的三大组件Activity、Service、Receiver都支持在Intent中传递Bundle。
而Bundle、ContentProvider、AIDL(Messenger的底层其实是AIDL)等,其底层原理其实都是依赖Binder实现,下面用一张图来说明:
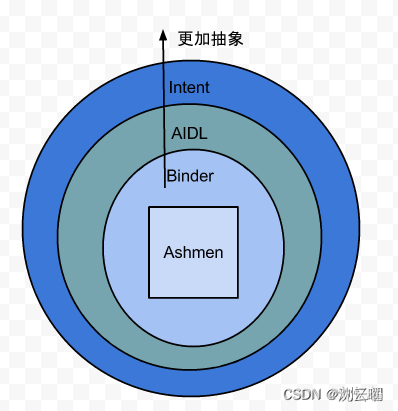
图中最里层是Android系统匿名共享内存Ashmem(Anonymous Shared Memory),其作用之一即通过Binder进程间通信机制来实现进程间的内存共享。
AIDL是Binder机制向外提供的接口,目的就是为了方便对Binder的使用;Intent是最高层级的封装,实质是封装了对Binder的使用,当然Intent也常常在同一进程中调用,只是把两种方式封装在一起了。 而进程间发送消息或者broadcast,并不是直接把intent发过去,而是把intent打包到Parcel中,通过binder机制传递消息。
为什么搞这么复杂呢,目的还是为了最大发挥系统效率与方便开发者使用。
其实最终来看,除了极少数场景使用文件共享,特定的网络数据交换场景使用socket,Android中绝大多数跨进程通信最终都是依赖binder实现。
6.5. Android为何新增binder来作为主要的IPC方式
Android也是基于Linux内核,Linux现有的进程通信手段有管道/消息队列/共享内存/套接字/信号量。
既然有现有的IPC方式,为什么重新设计一套Binder机制呢?
主要是出于以上三个方面的考量:
- 效率:传输效率主要影响因素是内存拷贝的次数,拷贝次数越少,传输速率越高。从Android进程架构角度分析:对于消息队列、Socket和管道来说,数据先从发送方的缓存区拷贝到内核开辟的缓存区中,再从内核缓存区拷贝到接收方的缓存区,一共两次拷贝。
一次数据传递需要经历:用户空间 –> 内核缓存区 –> 用户空间,需要2次数据拷贝,这样效率不高。
而对于Binder来说,数据从发送方的缓存区拷贝到内核的缓存区,而接收方的缓存区与内核的缓存区是映射到同一块物理地址的,节省了一次数据拷贝的过程 (共享内存不需要拷贝,Binder的性能仅次于共享内存。 ) - 稳定性:上面说到共享内存的性能优于Binder,那为什么不采用共享内存呢,因为共享内存需要处理并发同步问题,容易出现死锁和资源竞争,稳定性较差。 Binder基于C/S架构 ,Server端与Client端相对独立,稳定性较好。
- 安全性:传统Linux IPC的接收方无法获得对方进程可靠的UID/PID,从而无法鉴别对方身份;而Binder机制为每个进程分配了UID/PID,且在Binder通信时会根据UID/PID进行有效性检测。
6.6.什么是binder
- 从进程间通信的角度看,Binder是一种进程间通信的机制;
- 从Server进程的角度看,Binder指的是Server中的 Binder 实体对象(Binder类 IBinder);
- 从Client进程的角度看,Binder指的是对Binder代理对象,是Binder实体对象的一个远程代理
- 从传输过程的角度看,Binder是一个可以跨进程传输的对象;Binder驱动会自动完成代理对象和本地对象之间的转换。
- 从Framework角度来说,Binder是ServiceManager连接各种Manager和相应ManagerService的桥梁
Binder跨进程通信机制:基于C/S架构,由Client、Server、ServerManager和Binder驱动组成。
Binder框架中ServiceManager的作用:ServiceManager使得客户端可以获取服务端binder实例对象的引用 。
进程空间分为用户空间和内核空间。用户空间不可以进行数据交互;内核空间可以进行数据交互,所有进程共用一个内核空间。Client、Server、ServiceManager均在用户空间中实现,而Binder驱动程序则是在内核空间中实现的
6.7.binder工作原理
Binder Driver 如何在内核空间中做到一次拷贝的?
首先,进程空间分为用户空间和内核空间。用户空间不可以进行数据交互;内核空间可以进行数据交互,所有进程共用一个内核空间。那么应用程序不能直接操作设备硬件地址,如果用户空间需要读取磁盘的文件, 如果不采用内存映射, 需要两次拷贝(磁盘–>内核空间–>用户空间)
什么是内存映射?
内存映射将用户空间的一块内存区域映射到内核空间。映射关系建立后,内核空间对这段区域的修改也能直接反应到用户空间,少了一次拷贝。 Binder 驱动使用 mmap() 在内核空间创建数据接收的缓存空间。 mmap(NULL,MAP_SIZE,PROT_READ,MAP_PRIVATE,fd,0)的返回值是内核空间映射在用户空间的地址
binder工作原理:
- Binder 驱动在内核空间创建一个数据接收缓存区。
- 在内核空间开辟一块内核缓存区,建立内核缓存区和数据接收缓存区之间的映射关系,以及数据接收缓存区和接收进程用户空间地址的映射关系。
- 发送方进程通过系统调用 copyfromuser() 将数据 copy 到内核空间的内核缓存区,由于内核缓存区和接收进程的用户空间存在内存映射,因此也就相当于把数据发送到了接收进程的用户空间,这样便完成了一次进程间的通信
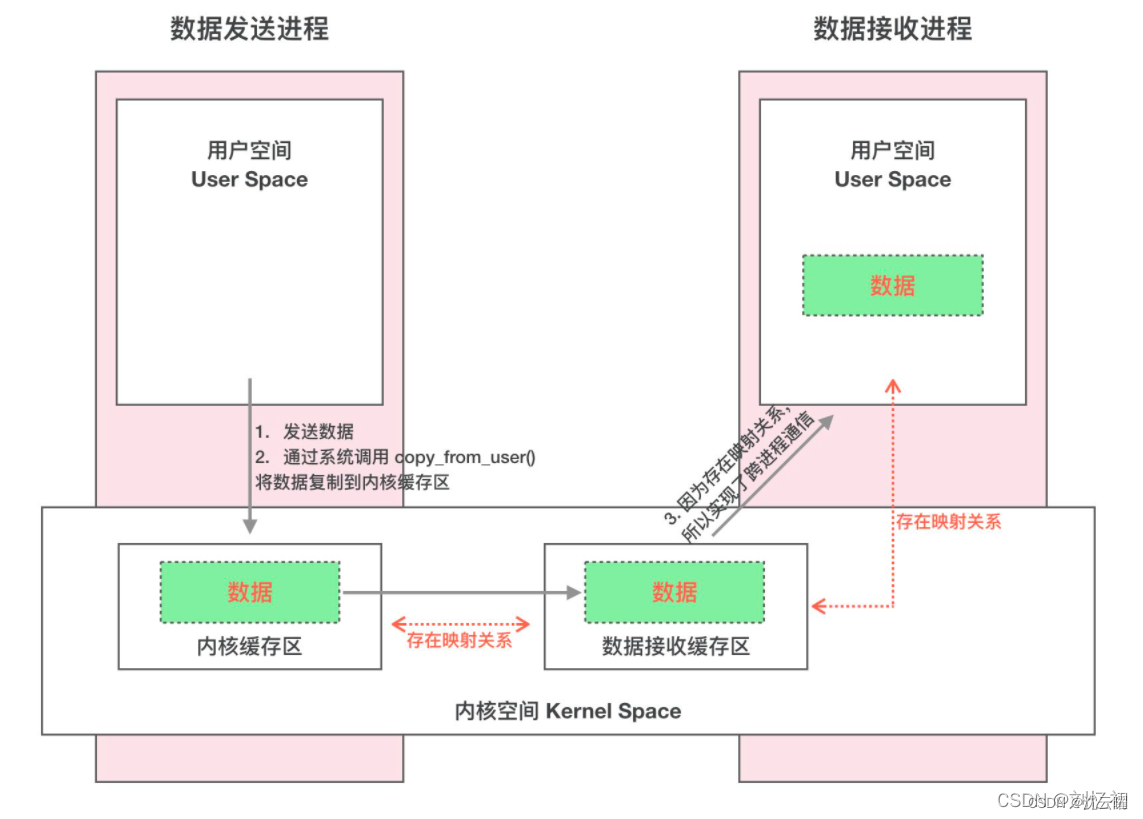
使用Binder进行数据传输的具体过程
6.8.AIDL是什么
全称是Android Interface Definition Language,即Android接口定义语言。简化Binder的使用,轻松地实现IPC进程间通信机制。 AIDL会生成一个服务端对象的代理类,通过它客户端可以实现间接调用服务端对象的方法。
AIDL的使用:
书写AIDL
-
创建要操作的实体类,实现Parcelable接口,以便序列化或反序列化
-
新建aidl文件夹,在其中创建接口 aidl文件以及实体类的映射aidl文件
-
Make project ,生成Binder的Java 文件
编写服务端 -
创建Service,在Service中创建生成的Stub实例,实现接口定义的方法
-
在 onBind() 中返回Binder实例
编写客户端 -
实现ServiceConnection接口,在其中通过asInterface拿到 AIDL 类
-
bindService()
-
调用AIDL类中定义好的操作请求
6.9.AIDL支持哪些数据类型
- Java八种基本数据类型(int、char、boolean、double、float、byte、long), 但不支持short
因为parcel不支持short,而AIDL的底层需要parcel传数据,所以AIDL也不支持short - String、CharSequence
- List和Map,List接收方必须是ArrayList,Map接收方必须是HashMap
- 实现Parcelable的类
6.10.AIDL的关键类,方法和工作流
Client和Server都使用同一个AIDL文件,在AIDL 编译后会生成java文件 ,其中有Stub服务实体和Proxy服务代理两个类。
- AIDL接口:编译完生成的接口继承IInterface。
- Stub类: 服务实体,Binder的实现类,服务端一般会实例化一个Binder对象,在服务端onBind中绑定,客户端asInterface获取到Stub。这个类在编译aidl文件后自动生成,它继承自Binder,表示它是一个Binder本地对象;它是一个抽象类,实现了IInterface接口,表明它的子类需要实现Server将要提供的具体能力(即aidl文件中声明的方法)。
- Stub.Proxy类: 服务的代理,客户端asInterface获取到Stub.Proxy。它实现了IInterface接口,说明它是Binder通信过程的一部分;它实现了aidl中声明的方法,但终还是交由其中的mRemote成员来处理,说明它是一个代理对象,mRemote成员实际上就是BinderProxy。
- asInterface():客户端在ServiceConnection通过Person.Stub.asInterface(IBinder),会根据是同一进行通信,还是 不同进程通信,返回Stub()实体,或者Stub.Proxy()代理对象transact():运行在客户端,当客户端发起远程请求时,内部会把信息包 装好,通过transact()向服务端发送。并将当前线程挂起, Binder驱动完成一系列的操作唤醒 Server 进程 ,调用 Server 进程本地对象的onTransact()来调用相 关函数 。 到远程请求返回,当前线程继续执行。
- onTransact():运行在服务端的Binder线程池中,当客户端发起跨进程请求时, onTransact()根据 Client传来的code 调用相关函数 。调用完成后把数据写入Parcel,通过reply发送给Client。 驱动唤醒 Client 进程里刚刚挂起的线程并将结果返回。
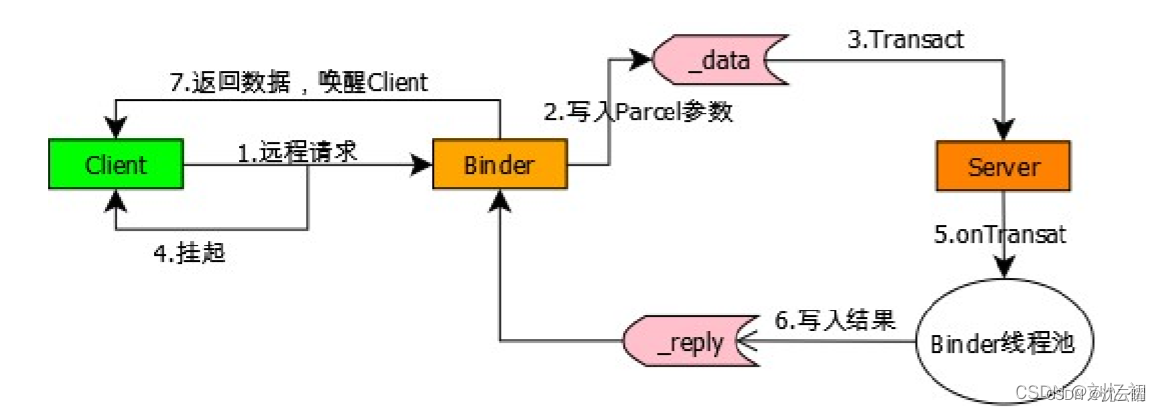
6.11.如何优化多模块都使用AIDL的情况
每个业务模块创建自己的AIDL接口并创建Stub的实现类,向服务端提供自己的唯一标识和实现类。
服务端只需要一个Service,创建Binder连接池接口,根据业务模块的特征来返回相应的Binder对象。客户端调用时通过Binder连接池, 即将每个业务模块的Binder请求统一转发到一个远程Service中去执行, 从而避免重复创建Service。
6.12.使用Binder传输数据的最大限制是多少,被占满后会导致什么问题
因为Binder本身就是为了进程间频繁而灵活的通信所设计的,并不是为了拷贝大数据而使用的。比如在Activity之间传输BitMap的时候,如果Bitmap过大,就会引起问题,比如崩溃等,这其实就跟Binder传输数据大小的限制有关系。mmap函数会为Binder数据传递映射一块连续的虚拟地址,这块虚拟内存空间其实是有大小限制。
普通的由Zygote孵化而来的用户进程,所映射的Binder内存大小是不到1M的,准确说是
#define BINDER_VM_SIZE ((1*1024*1024) - (4096 *2))
特殊的进程ServiceManager进程,它为自己申请的Binder内核空间是128K,这个同ServiceManager的用途是分不开的,ServcieManager主要面向系统Service,只是简单的提供一些addServcie,getService的功能,不涉及多大的数据传输,因此不需要申请多大的内存:
bs = binder_open(128*1024);
当服务端的内存缓冲区被Binder进程占用满后,Binder驱动不会再处理binder调用并在c++层抛出 DeadObjectException到binder客户端
7 组件化/插件化/热更新(热修复)
模块化/组件化/插件化/热修复等,都不是官方定义的技术栈,可以理解为黑科技。作为技术延伸了解即可,只要基础扎实,项目用到任何一种,都可以快速上手。
4.7.1 组件化
网上关于模块化/组件化的东西很多,然而组件化和模块化根本上其实是⼀回事
组件化:组件化就是基于可重用为目的的,将一个大的软件系统按照分离关注点的形式,拆分多个独立的组件,减少耦合。
定义:
拆成多个 module 开发就是组件化
以前的 Android 开发不是现在这样⽤ gradle 的,⽤的是 ant,做模块拆分⽐较麻烦
现在有了 gradle,拆模块⾮常⽅便了。不过模块化开发是在 gradle 到来之前就有了的
组件化开发的好处:
组件,既可以作为library,又可以单独作为application,便于单独编译单独测试,大大的提高了编译和开发效率;
(业务)组件,可有自己独立的版本,业务线互不干扰,可单独编译、测试、打包、部署
各业务线共有的公共模块开发为组件,作为依赖库供各业务线调用,减少重复代码编写,减少冗余,便于维护
通过gradle配置文件,可对第三方库的引入进行统一管理,避免版本冲突,减少冗余库
通过gradle配置文件,可对各组件实现library与application间便捷切换,实现项目的按需加载
4.7.2 插件化
App 的部分功能模块在打包时并不以传统⽅式打包进 apk ⽂件中,⽽是以另⼀种形式⼆次封装进 apk 内部,或者放在⽹络上适时下载,在需要的时候动态对这些功能模块进⾏加载,称之为插件化。
这些单独⼆次封装的功能模块 apk ,就称作「插件」,初始安装的 apk 称作「宿主」。
插件化的基础:Android类加载机制和反射机制
反射的目的?java提供反射的功能合不合理?
Java 既然提供了可⻅性关键字 public private 等等,⽤来限制代码之间的可⻅性,为什么⼜要提供反射功能?
可⻅性特性的⽀持不是为了代码不被坏⼈使⽤,⽽是为了程序开发的简洁性。安全性的话,可⻅性的⽀持提供的是 Safety 的安全,⽽不是 Security 的安全。即,可⻅性的⽀持让程序更不容易写出 bug,⽽不是更不容易被⼈⼊侵。
反射的⽀持可以让开发者在可⻅性的例外场景中,可以突破可⻅性限制来调⽤⾃⼰需要的 API。这是基于对开发者「在使⽤反射时已经⾜够了解和谨慎」的假设的。
所以,可⻅性的⽀持不是为了防御外来者⼊侵,因此反射功能的⽀持并没有什么不合理。
关于 DEX:
class:java 编译后的⽂件,每个类对应⼀个 class ⽂件
dex:Dalvik EXecutable 把 class 打包在⼀起,⼀个 dex 可以包含多个 class ⽂ 件
odex:Optimized DEX 针对系统的优化,例如某个⽅法的调⽤指令,会把虚拟的调⽤转换为使⽤具体的 index,这样在执⾏的时候就不⽤再查找了
oat:Optimized Android file Type。使⽤ AOT 策略对 dex 预先编译(解释)成本地指令,这样再运⾏阶段就不需再经历⼀次解释过程,程序的运⾏可以更快
AOT:Ahead-Of-Time compilation 预先编译
插件化原理:动态加载
通过⾃定义 ClassLoader 来加载新的 dex ⽂件,从⽽让程序员原本没有的类可以被
使⽤,这就是插件化的原理。
例如:把 Utils 拆到单独的项⽬,打包 apk 作为插件引⼊
插件化有什么⽤?
早期:解决 dex 65535 问题。⾕歌后来也出了 multidex ⼯具来专⻔解决
⼀说:懒加载来减少软件启动速度:有可能,实质上未必会快
⼀说:减⼩安装包⼤⼩:可以
⼀说:项⽬结构拆分,依赖完全隔离,⽅便多团队开发和测试,解决了组件化耦
合度太⾼的问题:这个使⽤模块化就够了,况且模块化解耦不够的话,插件化也
解决不了这个问题
动态部署:可以
Android App Bundles:属于「模块化发布」。未来也许会⽀持动态部署,但肯定会需要结合应⽤商店(即 Play Store,或者未来被更多的商店所⽀持)
bug 热修复:可以
4.7.3 热更新/热修复
不安装新版本的软件,直接从⽹络下载新功能模块来对软件进⾏局部更新
热更新和插件化的区别
-
插件化的内容在原 App 中没有,⽽热更新是原 App 中的内容做了改动
-
插件化在代码中有固定的⼊⼝,⽽热更新则可能改变任何⼀个位置的代码
热更新的原理 -
ClassLoader 的 dex ⽂件替换
-
直接修改字节码
前置知识:loadClass() 的类加载过程
宏观上:是⼀个带缓存的、从上到下的加载过程(即⽹上所说的「双亲委托机制」)
对于具体的⼀个 ClassLoader:
-
先从⾃⼰的缓存中取
-
⾃⼰没有缓存,就找⽗ ClassLoader 要(parent.loadClass())
-
⽗ View 也没有,就⾃⼰加载(findClass())
BaseDexClassLoader 或者它的⼦类(DexClassLoader、PathClassLoader等)的 findClass(): -
通过它的 pathList.findClass()
-
它的 pathList.loadClass() 通过 DexPathList 的 dexElements 的 findClass()
-
所以热更新的关键在于,把补丁 dex ⽂件加载放进⼀个 Element,并且插⼊到 dexElements 这个数组的前⾯(插⼊到后⾯的话会被忽略掉,缓存的原因)
手写热更新思路
因为⽆法在更新之前就指定要更新谁;所以不能定义新的 ClassLoader,⽽只能选择对 ClassLoader 进⾏修改,让它能够加载补丁⾥⾯的类
因为补丁的类在原先的 App 中已经存在,所以应该把补丁的 Element 对象插入到 dexElements 的前⾯才行,插⼊到后⾯会被忽略掉。
具体的做法:反射
- ⾃⼰⽤补丁创建⼀个 PathClassLoader
- 把补丁 PathClassLoader ⾥⾯的 elements 替换到旧的⾥⾯去
- 注意:
- 尽早加载热更新(通⽤⼿段是把加载过程放在Application.attachBaseContext())
- 热更新下载完成后在需要时先杀死程序才能让补丁⽣效
- 优化:热更新没必要把所有内容都打过来,只要把改变的类拿过来就行了。⽤ d8 把指定的 class 打包进 dex
- 完整化:从网上加载
- 再优化:把打包过程写⼀个 task,方便打包
8 jetpack
Android Jetpack 组件是库的集合,这些库是为协同工作而构建的,不过也可以单独采用。
包含:
1.Foundation(基础组件)
AppCompat
Android KTX
Mutidex
Test
基础组件提供了跨领域的功能,如向后兼容性、测试和Kotlin语言支持
2.Architecture(架构组件)(非常重要)
架构组件这个比较关键,是我们要学习的重点包括:
Data Binding 数据绑定
Lifecycle 管理Activity和Fragment生命周期
LiveData 感知数据变化更新ui
Navigation 字意为导航。多Fragment转场,栈管理
Paging 分页处理
Room 数据库管理
ViewModel ui界面的数据管理
WorkManager 后台工作管理
3.Behavior(行为组件)
行为组件可帮助开发者的应用与标准 Android 服务(如通知、权限、分享和 Google 助理)相集成。
CameraX:帮助开发者简化相机应用的开发工作。它提供一致且易于使用的 API 界面,适用于大多数 Android 设备,并可向后兼容至 Android 5.0(API 级别 21)
DownloadManager(下载管理器):可处理长时间运行的HTTP下载,并在出现故障或在连接更改和系统重新启动后重试下载。
Media & playback(媒体&播放):用于媒体播放和路由(包括 Google Cast)的向后兼容 API
Notifications(通知):提供向后兼容的通知 API,支持 Wear 和 Auto。
Permissions(权限):用于检查和请求应用权限的兼容性 API。
Preferences(偏好设置):提供了用户能够改变应用的功能和行为能力。
Sharing(共享):提供适合应用操作栏的共享操作。
Slices(切片):创建可在应用外部显示应用数据的灵活界面元素。
4.UI(界面组件)
界面组件可提供各类view和辅助程序,让应用不仅简单易用,还能带来愉悦体验。它包含如下组件库:
Animation & Transitions(动画&过度):提供各类内置动画,也可以自定义动画效果。
Emoji(表情符号):使用户在未更新系统版本的情况下也可以使用表情符号。
Fragment:组件化界面的基本单位。
Layout(布局):xml书写的界面布局或者使用Compose完成的界面。
Palette(调色板):从调色板中提取出有用的信息。
所以,重点是AAC架构(Adroid Architecture Components,即Android系统架构组件)
Lifecycle :能够帮我们轻松的管理 Activity/Fragment 的生命周期问题,能够让我们以一种更加解耦的方式处理生命周期的变化问题,以及轻松避免内存泄露;
原理:
1.Lifecycle 库通过在 SupportActivity 的 onCreate 中注入 ReportFragment 来感知发生命周期;
2.Lifecycle 抽象类,是 Lifecycle 库的核心类之一,它是对生命周期的抽象,定义了生命周期事件以及状态,通过它我们可以获取当前的生命周期状态,同时它也奠定了观察者模式的基调;
LiveData :基于观察者模式,并且感知生命周期、可观察的数据持有类,它被设计成 ViewModel 的一个成员变量;可以以一个 更解耦 的方式来共享数据。
1.LiveData 的实现基于观察者模式;
2.LiveData 跟 LifecycleOwner 绑定,能感知生命周期变化,并且只会在 LifecycleOwner 处于 Active 状态(started/resumed)下通知数据改变(避免不必要的数据刷新);
3.LiveData 会自动在 destroyed的状态下移除 Observer ,取消订阅,所以不用担心内存泄露;
ViewModel:管理跟UI相关的数据, 并且能够感知生命周期;另外 ViewModel 能够在配置改变的情况下让数据得以保留。ViewModel 重在以感知生命周期的方式 管理界面相关的数据。
我们知道类似旋转屏幕等配置项改变会导致我们的 Activity 被销毁并重建,此时 Activity 持有的数据就会跟随着丢失,而ViewModel 则并不会被销毁,从而能够帮助我们在这个过程中保存数据,而不是在 Activity 重建后重新去获取。并且 ViewModel 能够让我们不必去担心潜在的内存泄露问题,同时 ViewModel 相比于用onSaveInstanceState() 方法更有优势,比如存储相对大的数据,并且不需要序列化以及反序列化。
ViewModel 原理总结:
通过注入一个 retainInstance 为true 的 HolderFragment ,利用 Fragment 的特性来保证在 Activity 配置改变后依然能够存活下来,并且保证了 HolderFragment 内部的 ViewModelStore 的存活,最终保证了 ViewModelStore 内部储存的 ViewModel 缓存存活,从而实现 ViewModel 在 Activity 配置改变的情况下不销毁的功能。
ViewModel 的使用注意事项:
不要持有 Activity :ViewModel 不会因为 Activity 配置改变而被销毁,所以绝对不要持有那些跟 Activity 相关的类,比如Activity 里的某个 View,让 ViewModel 持有 Activity 会导致内存泄露,还要注意的是连 Lifecycle 也不行;
不能访问 UI :ViewModel 应该只负责管理数据,不能去访问 UI,更不能持有它;
9.Bitmap
在Android开发过程中,Bitmap往往会给开发者带来一些困扰,因为对Bitmap操作不慎,就容易造成OOM(Java.lang.OutofMemoryError - 内存溢出)
Bitmap常用方法
Bitmap是Android系统中的图像处理的最重要类之一。用它可以获取图像文件信息,进行图像剪切、旋转、缩放等操作,并可以指定格式保存图像文件。
recycle() // 回收位图占用的内存空间,把位图标记为Dead
isRecycled() //判断位图内存是否已释放
getWidth() //获取位图的宽度
getHeight() //获取位图的高度
getScaledWidth(Canvas canvas) //获取指定密度转换后的图像的宽度
getScaledHeight(Canvas canvas) //获取指定密度转换后的图像的高度
compress(CompressFormat format, int quality, OutputStream stream) //按指定的图片格式以及画质,将图片转换为输出流。
format:压缩图像的格式,如Bitmap.CompressFormat.PNG或 Bitmap.CompressFormat.JPEG
quality:画质,0-100.0表示最低画质压缩,100以最高画质压缩。对于PNG等无损格式的图片,会忽略此项设置。
createBitmap(Bitmap src) //以src为原图生成不可变得新图像
createScaledBitmap(Bitmap src, int dstWidth, int dstHeight, boolean filter) //以src为原图,创建新的图像,指定新图像的高宽以及是否可变。
createBitmap(int width, int height, Config config) //创建指定格式、大小的位图
createBitmap(Bitmap source, int x, int y, int width, int height) //以source为原图,创建新的图片,指定起始坐标以及新图像的高宽。
BitmapFactory工厂类:
Option 参数类:
inJustDecodeBounds //如果设置为true,不获取图片,不分配内存,但会返回图片的高度宽度信息。如果将这个值置为true,那么在解码的时候将不会返回bitmap,只会返回这个bitmap的尺寸。这个属性的目的是,如果你只想知道一个bitmap的尺寸,但又不想将其加载到内存时。这是一个非常有用的属性。
public int inSampleSize //图片缩放的倍数, 这个值是一个int,当它小于1的时候,将会被当做1处理,如果大于1,那么就会按照比例(1 / inSampleSize)缩小bitmap的宽和高、降低分辨率,大于1时这个值将会被处置为2的倍数。例如,width=100,height=100,inSampleSize=2,那么就会将bitmap处理为,width=50,height=50,宽高降为1 / 2,像素数降为1 / 4。
Bitmap加载方式
Bitmap的加载方式有Resource资源加载、本地(SDcard)加载、网络加载等加载方式。
为什么Bitmap会导致OOM?
图片分辨率越高,消耗的内存越大,当加载高分辨率图片的时候,将会非常占用内存,一旦处理不当就会OOM。例如,一张分辨率为:1920x1080的图片。如果Bitmap使用 ARGB_8888 32位来平铺显示的话,占用的内存是1920x1080x4个字节,占用将近8M内存,可想而知,如果不对图片进行处理的话,就会OOM。在使用ListView, GridView,RecyclerView等这些大量加载view的组件时,如果没有合理的处理缓存,大量加载Bitmap的时候,也将容易引发OOM
Bitmap基础知识
一张图片Bitmap所占用的内存 = 图片长度 x 图片宽度 x 一个像素点占用的字节数
而Bitmap.Config,正是指定单位像素占用的字节数的重要参数。
其中,A代表透明度;R代表红色;G代表绿色;B代表蓝色。
ALPHA_8:表示8位Alpha位图,即A=8,一个像素点占用1个字节,它没有颜色,只有透明度
ARGB_4444:表示16位ARGB位图,即A=4,R=4,G=4,B=4,一个像素点占4+4+4+4=16位,2个字节
ARGB_8888:表示32位ARGB位图,即A=8,R=8,G=8,B=8,一个像素点占8+8+8+8=32位,4个字节
RGB_565:表示16位RGB位图,即R=5,G=6,B=5,它没有透明度,一个像素点占5+6+5=16位,2个字节
BitmapFactory解析Bitmap的原理
Bitmap decodeFile(...)
Bitmap decodeResource(...)
Bitmap decodeStream(...)
Bitmap decodeByteArray(...)
Bitmap decodeFileDescriptor(...)
其中常用的三个:decodeFile、decodeResource、decodeStream。decodeFile和decodeResource其实最终都是调用decodeStream方法来解析Bitmap
在不配置Options的情况下:
- decodeFile、decodeStream在解析时不会对Bitmap进行一系列的屏幕适配,解析出来的将是原始大小的图
- decodeResource在解析时会对Bitmap根据当前设备屏幕像素密度densityDpi的值进行缩放适配操作,使得解析出来的Bitmap与当前设备的分辨率匹配,达到一个最佳的显示效果,并且Bitmap的大小将比原始的大
Bitmap的优化策略:如何对Bitmap进行优化加载呢
我们将Bitmap优化的策略总结为以下3种:
- 对图片质量进行压缩
- 对图片尺寸进行压缩
- 使用libjpeg.so库进行压缩
对图片质量进行压缩
public static Bitmap compressImage(Bitmap bitmap){
ByteArrayOutputStream baos = new ByteArrayOutputStream();
//质量压缩方法,这里100表示不压缩,把压缩后的数据存放到baos中
bitmap.compress(Bitmap.CompressFormat.JPEG, 100, baos);
int options = 100;
//循环判断如果压缩后图片是否大于50kb,大于继续压缩
while ( baos.toByteArray().length / 1024>50) {
//清空baos
baos.reset();
bitmap.compress(Bitmap.CompressFormat.JPEG, options, baos);
options -= 10;//每次都减少10
}
//把压缩后的数据baos存放到ByteArrayInputStream中
ByteArrayInputStream isBm = new ByteArrayInputStream(baos.toByteArray());
//把ByteArrayInputStream数据生成图片
Bitmap newBitmap = BitmapFactory.decodeStream(isBm, null, null);
return newBitmap;
}
对图片尺寸进行压缩
BitmapFactory提供的加载图片的四个类方法都支持BitmapFactory.Options参数,通过它就可以很方便对一个图片进行采样缩放。
通过BitmapFactory.Options来缩放图片,主要用到了它的inSampleSize参数,即采样率。当inSampleSize为1时,采样后的图片大小为图片的原始大小;当inSampleSize大于1时,比如2,那么采样后的图片宽高均为原图大小的1/2,像素数为原图的1/4,其占有的内存大小也为原图的1/4。
采样率必须是大于1的整数,图片才会有缩小的效果,并且采样率同时作用于宽和高,缩放比例为1/(inSampleSize的2次方),比如inSampleSize为4,那么缩放比例就是1/16。官方文档指出,inSampleSize的取值为2的指数:1、2、4、8、16等等。
通过采样率可以优化加载图片,那么如何获采样率呢?通过以下4个步骤:
- 将BitmapFactory.Options的inJustDecodeBounds参数设为true并加载图片;
- 从BitmapFactory.Options中取出图片的原始宽高信息,它们对应于outWidth和outHeight参数;
- 根据采样率的规则并结合目标View的所需大小计算出采样率inSampleSize;
- 将BitmapFactory.Options的inJustDecodeBounds参数设为false,然后重新加载图片。
/**
* 按图片尺寸压缩 参数是bitmap
* @param bitmap
* @param pixelW
* @param pixelH
* @return
*/
public static Bitmap compressImageFromBitmap(Bitmap bitmap, int pixelW, int pixelH) {
ByteArrayOutputStream os = new ByteArrayOutputStream();
bitmap.compress(Bitmap.CompressFormat.JPEG, 100, os);
if( os.toByteArray().length / 1024>512) {//判断如果图片大于0.5M,进行压缩避免在生成图片(BitmapFactory.decodeStream)时溢出
os.reset();
bitmap.compress(Bitmap.CompressFormat.JPEG, 50, os);//这里压缩50%,把压缩后的数据存放到baos中
}
ByteArrayInputStream is = new ByteArrayInputStream(os.toByteArray());
BitmapFactory.Options options = new BitmapFactory.Options();
//第一次采样
options.inJustDecodeBounds = true;//只加载bitmap边界,占用部分内存
options.inPreferredConfig = Bitmap.Config.RGB_565;//设置色彩模式
BitmapFactory.decodeStream(is, null, options);//配置首选项
//第二次采样
options.inJustDecodeBounds = false;
options.inSampleSize = computeSampleSize(options , pixelH > pixelW ? pixelW : pixelH ,pixelW * pixelH );
is = new ByteArrayInputStream(os.toByteArray());
//把最终的首选项配置给新的bitmap对象
Bitmap newBitmap = BitmapFactory.decodeStream(is, null, options);
return newBitmap;
}
/**
* 动态计算出图片的inSampleSize
* @param options
* @param minSideLength
* @param maxNumOfPixels
* @return
*/
public static int computeSampleSize(BitmapFactory.Options options, int minSideLength, int maxNumOfPixels) {
int initialSize = computeInitialSampleSize(options, minSideLength, maxNumOfPixels);
int roundedSize;
if (initialSize <= 8) {
roundedSize = 1;
while (roundedSize < initialSize) {
roundedSize <<= 1;
}
} else {
roundedSize = (initialSize + 7) / 8 * 8;
}
return roundedSize;
}
private static int computeInitialSampleSize(BitmapFactory.Options options, int minSideLength, int maxNumOfPixels) {
double w = options.outWidth;
double h = options.outHeight;
int lowerBound = (maxNumOfPixels == -1) ? 1 : (int) Math.ceil(Math.sqrt(w * h / maxNumOfPixels));
int upperBound = (minSideLength == -1) ? 128 :(int) Math.min(Math.floor(w / minSideLength), Math.floor(h / minSideLength));
if (upperBound < lowerBound) {
return lowerBound;
}
if ((maxNumOfPixels == -1) && (minSideLength == -1)) {
return 1;
} else if (minSideLength == -1) {
return lowerBound;
} else {
return upperBound;
}
}
}
使用libjpeg.so库进行压缩(进阶,亮点,掌握最好)
除了通过设置simpleSize根据图片尺寸压缩图片和通过Bitmap.compress方法通过压缩图片质量两种方法外,我们还可以使用libjpeg.so这个库来进行压缩。
Bitmap的内存优化详解
-
同一张图片,放在不同资源目录下,其分辨率会有变化,
-
bitmap分辨率越高,其解析后的宽高越小,甚至会小于图片原有的尺寸(即缩放),从而内存占用也相应减少
-
图片不特别放置任何资源目录时,其默认使用mdpi分辨率:160
-
资源目录分辨率和设备分辨率一致时,图片尺寸不会缩放
解决方案 -
使用低色彩的解析模式,如RGB565,减少单个像素的字节大小
-
资源文件合理放置,高分辨率图片可以放到高分辨率目录下
-
图片质量压缩,图片尺寸压缩
-
设置图片缓存
第一种方式,大约能减少一半的内存开销。Android默认是使用ARGB8888配置来处理色彩,占用4字节,改用RGB565,将只占用2字节,代价是显示的色彩将相对少,适用于对色彩丰富程度要求不高的场景。
第二种方式:(图片适配)和图片的具体分辨率有关,建议开发中,高分辨率的图像应该放置到合理的资源目录下,注意到Android默认放置的资源目录是对应于160dpi,目前手机屏幕分辨率越来越高,此处能节省下来的开销也是很可观的。理论上,图片放置的资源目录分辨率越高,其占用内存会越小,但是低分辨率图片会因此被拉伸,显示上出现失真。另一方面,高分辨率图片也意味着其占用的本地储存也变大。
第三种方式:(参考尺寸和质量压缩)理论上根据适用的环境,是可以减少十几倍的内存使用的,它基于这样一个事实:源图片尺寸一般都大于目标需要显示的尺寸,因此可以通过缩放的方式,来减少显示时的图片宽高,从而大大减少占用的内存。
第四种方式:

总结:
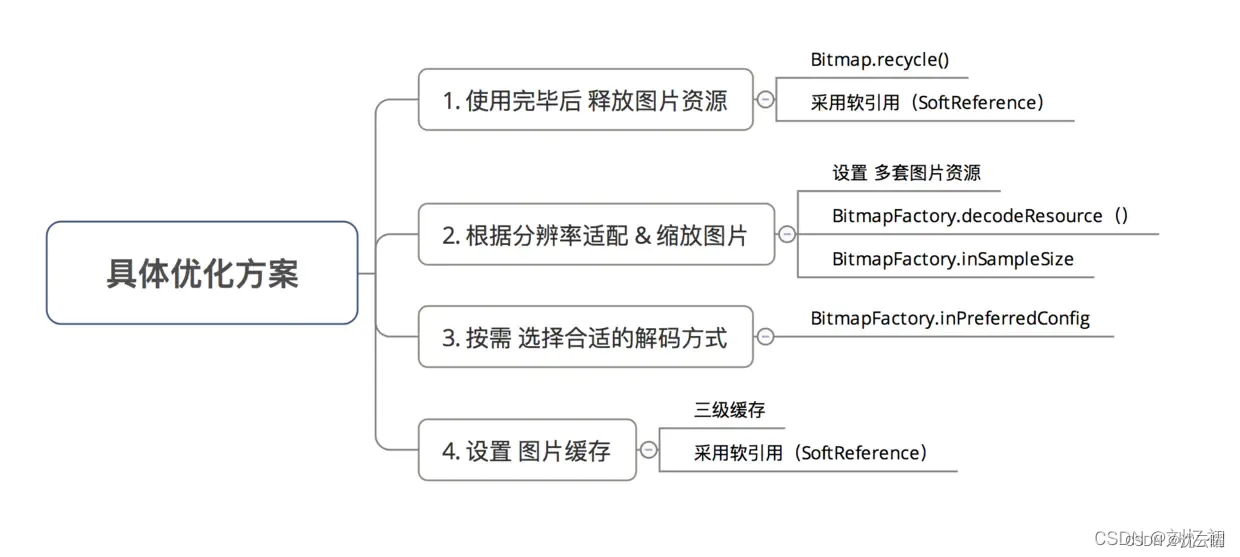
其它问题:
如何加载一张超大图片?
对于普通的图片,我们加载的思路很简单就是压缩大小,用Options来获得大小然后和当前屏幕大小进行比较,然后以一定的值压缩。
但对于超大图片,Android提供了BitmapRegionDecoder来进行图片的局部解析。
10.ANR及ANR如何排查?
Application Not Responding,字面意思就是应用无响应.
ANR的四种场景:
- Service TimeOut:service 未在规定时间执行完成:前台服务 20s,后台 200s
- BroadCastQueue TimeOut:未在规定时间内未处理完广播:前台广播 10s 内, 后台 60s 内
- ContentProvider TimeOut:publish 在 10s 内没有完成
I4. nput Dispatching timeout:5s 内未响应键盘输入、触摸屏幕等事件
我们可以看到,Activity的生命周期回调的阻塞并不在触发 ANR 的场景里面,所以并不会直接触发 ANR。只不过死循环阻塞了主线程,如果系统再有上述的四种事件发生,就无法在相应的时间内处理从而触发 ANR。
如何避免:尽量避免在主线程中进行耗时操作。
ANR问题分析
1.看Log

log清晰地记录了ANR发生的时间,以及线程的tid和一句话概括原因:WaitingInMainSignalCatcherLoop,大概意思为主线程等待异常。
最后一句The application may be doing too much work on its main thread,告知可能在主线程做了太多的工作。
2**.traces.txt**
刚才的log有第二句Wrote stack traces to ‘/data/anr/traces.txt’,说明ANR异常已经输出到traces.txt文件,使用adb命令把这个文件从手机里导出来:
- cd到adb.exe所在的目录,也就是Android SDK的platform-tools目录,例如:
cd D:\Android\AndroidSdk\platform-tools
- 到指定目录后执行以下adb命令导出traces.txt文件:
adb pull /data/anr/traces.txt
traces.txt默认会被导出到Android SDK的\platform-tools目录。一般来说traces.txt文件记录的东西会比较多,分析的时候需要有针对性地去找相关记录。在文件中使用 ctrl + F 查找包名可以快速定位相关代码。
特别注意:产生新的ANR,原来的 traces.txt 文件会被覆盖。
3.Java线程调用分析
4.DDMS分析ANR问题
使用DDMS——Update Threads工具
阅读Update Threads的输出
11.LeakCanary 源码分析
通过注册application和Fragment上的生命周期回调,来完成在Activity和Fragment销毁的时候开始观察。
watch()方法:
原理:就是通过弱引用的方式来判断队列中是否有弱引用来判断对象是否被垃圾回收了
总结一下原理:
- 弱引用与ReferenceQueue联合使用,如果弱引用关联的对象被回收,则会把这个弱引用加入到ReferenceQueue中;通过这个原理,可以看出removeWeaklyReachableReferences()执行后,会对应删除KeyedWeakReference的数据。如果这个引用继续存在,那么就说明没有被回收。
2 为了确保最大保险的判定是否被回收,一共执行了两次回收判定,包括一次手动GC后的回收判定。两次都没有被回收,很大程度上说明了这个对象的内存被泄漏了,但并不能100%保证;因此LeakCanary是存在极小程度的误差的。