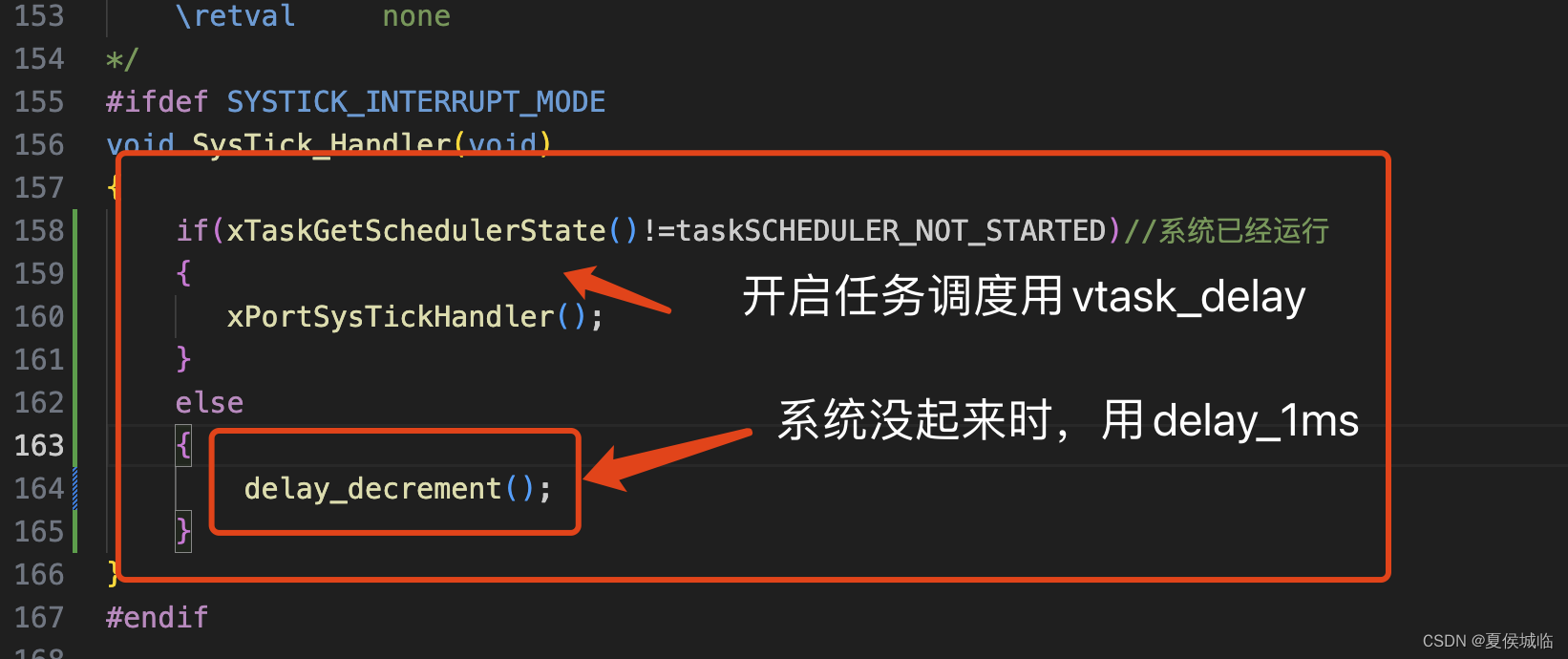
1、低功耗工具
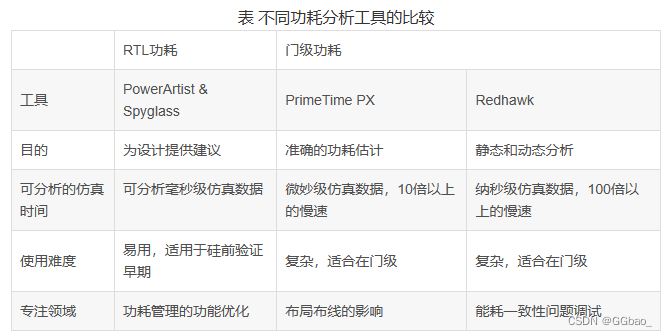
功耗分析预测分析工具包括PowerArtist(Ansys)、Spyglass Power(Synopsys)、Prime Time PX(Synopsys)和Redhawk(Ansys)等。通过对实际项目中;不同工具的比较,建议如下表:
2、综合的步骤、工具
步骤:翻译(Translation):主要把描述RTL级的HDL语言,在约束下转换成(DC)RC内部的统一用门级描述的电路,以GTECH或者没有映射的ddc形式展现。
逻辑优化(Optimization):把统一用门级描述的电路进行优化,例如调整路径,简化门的数量。
门级映射(Mapping):工具使用fab厂的工艺库把电路映射出来,得到ddc文件,包括了映射的门电路信息和网表,还能生成延时信息文件.sdf(standard delay format)。
工具:Synopsys: Design Compiler(DC)、Cadence: RTL Compiler(RC)
3、状态机
Verilog有限状态机比较 - 知乎
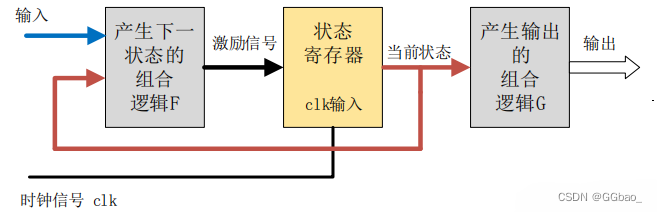
有限状态机(Finite-State Machine,FSM),简称状态机,是表示有限个状态以及在这些状态之间的转移和动作等行为的数学模型。状态机不仅是一种电路的描述工具,而且也是一种思想方法,在电路设计的系统级和 RTL 级有着广泛的应用。
Verilog 中状态机主要用于同步时序逻辑的设计,能够在有限个状态之间按一定要求和规律切换时序电路的状态。状态的切换方向不但取决于各个输入值,还取决于当前所在状态。 状态机可分为 2 类:Moore 状态机和 Mealy 状态机。
Moore 型状态机
Moore 型状态机的输出只与当前状态有关,与当前输入无关。
输出会在一个完整的时钟周期内保持稳定,即使此时输入信号有变化,输出也不会变化。输入对输出的影响要到下一个时钟周期才能反映出来。这也是 Moore 型状态机的一个重要特点:输入与输出是隔离开来的。
Mealy 型状态机
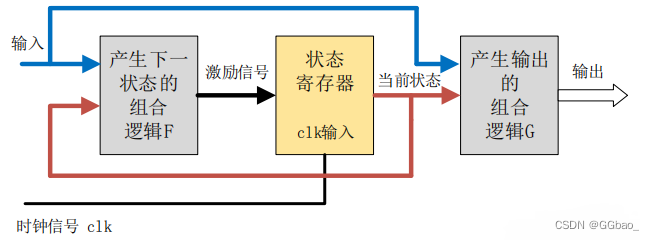
Mealy 型状态机的输出,不仅与当前状态有关,还取决于当前的输入信号。
Mealy 型状态机的输出是在输入信号变化以后立刻发生变化,且输入变化可能出现在任何状态的时钟周期内。因此,同种逻辑下,Mealy 型状态机输出对输入的响应会比 Moore 型状态机早一个时钟周期。
状态机设计
一段式状态机:有的设计者习惯将整个状态机写到1 个always 模块里面,在该模块中即描述状态转移,又描述状态的输入和输出,这种写法一般被称为一段式FSM 描述方法。
二段式状态机:还有一种写法是将用2个always 模块,其中一个always 模块采用同步时序描述状态转移;另一个模块采用组合逻辑判断状态转移条件,描述状态转移规律,这种写法被称为两段式FSM 描述方法。
三段式状态机:这种写法使用3 个always 模块,一个always模块采用同步时序描述状态转移;第二个采用组合逻辑判断状态转移条件,描述状态转移规律;第三个always 模块使用同步时序电路描述每个状态的输出。
一般而言,推荐的 FSM 描述方法是后两种,即两段式和三段式FSM 描述方法。其原因为:FSM 和其他设计一样,最好使用同步时序方式设计,以提高设计的稳定性,消除毛刺。状态机实现后,一般来说,状态转移部分是同步时序电路,而状态的转移条件的判断是组合逻辑。两段式之所以比一段式编码合理,就在于两段式编码将同步时序和组合逻辑分别放到不同的always 程序块中实现。这样做的好处不仅仅是便于阅读、理解、维护,更重要的是利于综合器优化代码,利于用户添加合适的时序约束条件,利于布局布线器实现设计。而 一段式FSM 描述不利于时序约束、功能更改、调试等,而且不能很好的表示米勒FSM 的输出,容易写出Latches,导致逻辑功能错误。
在一般两段式描述中,为了便于描述当前状态的输出,很多设计者习惯将当前状态的输出用组合逻辑实现。 但是这种组合逻辑仍然有产生毛刺的可能性,而且不利于约束,不利于综合器和布局布线器实现高性能的设计。因此如果设计运行额外的一个时钟节拍的插入 (latency),则要求尽量对状态机的输出用寄存器寄存一拍。但是很多实际情况不允许插入一个寄存节拍,此时则可以通过三段式描述方法进行解决。三段式与两段式相比,关键在于根据状态转移规律,在上一状态根据输入条件判断出当前状态的输出,从而在不插入额外时钟节拍的前提下,实现了寄存器输出。
4、异步复位同步释放
很多时候,我们都希望系统一上电以及在仿真开始的时候所有寄存器都有一个已知的状态。复位有两种方式,即同步复位和异步复位。
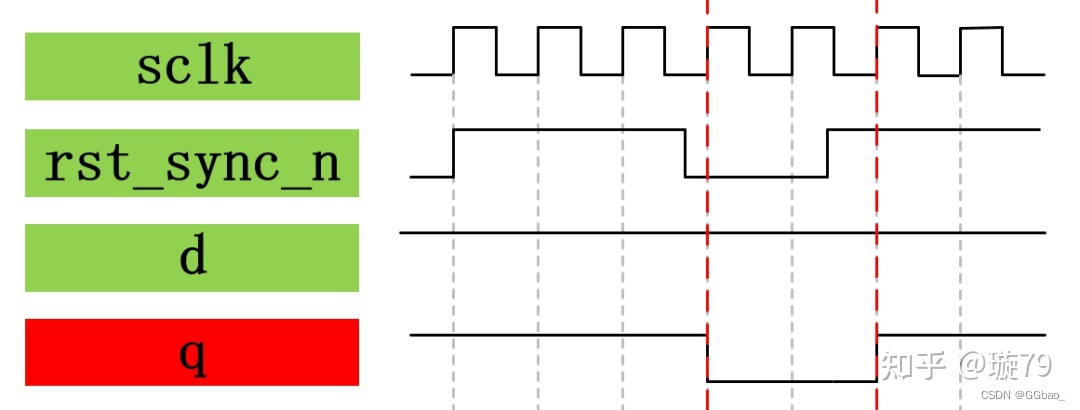
同步复位:“同步”的意思是和工作时钟同步。也就是说当时钟的上升沿(下降沿)来到时检测到按键的复位操作才有效,否则无效。如下图所示为同步低复位波形。
异步复位:“异步”的意思是和工作时钟不同步。也就是说寄存器的复位不关心时钟的上升沿(下降沿)是否到来,只要有检测到按键被按下,就立刻执行复位操作。如下图所示为异步低复位波形。
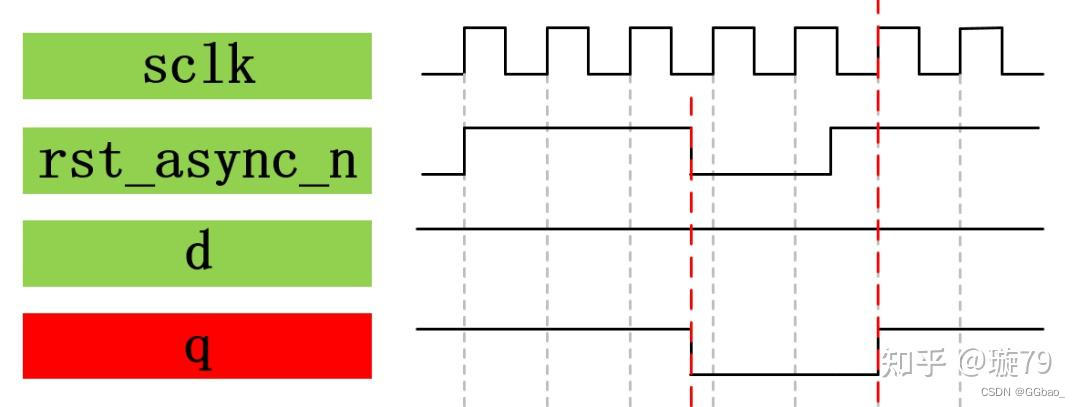
为什么很多RTL代码中使用异步复位?因为这部分资源本来就有,不需要额外创造,而如果我们使用同步高复位,就会增加额外的逻辑,需要使用LUT资源,所以同步复位D触发器比异步复位D触发器多使用了一个LUT,可以试想一下如果我们使用的很多同步复位D触发器的时候就会占用很多不必要的LUT资源,从而造成资源的浪费。
异步复位同步释放有特殊情况,就是时钟刚好采集到复位释放的不稳定状态,因为复位很多时候是和时钟异步的关系,这样就有可能引发亚稳态的产生,如果不进行处理就会使得亚稳态的向下传播,从而对电路的功能造成影响。
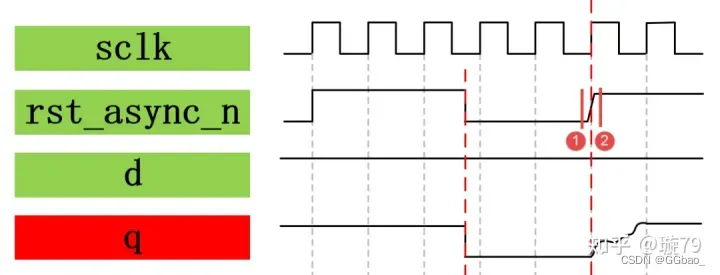
时序检查中对于异步复位电路的时序分析分别叫做恢复时间检查(recovery time)和移除时间检查(removal time)。
(1)recovery time:恢复时间撤销复位时,恢复到解复位状态的电平必须在时钟有效沿来临之前的一段时间到来,才能保证时钟能有效恢复到解复位状态,此段时间为recovery time。类似于同步时钟的setup time,也就是上图中的①所示的时间段。
(2)removal time:移除时间复位时,在时钟有效沿来临之后复位信号还需要保持的时间为移除时间removal time。类似同步时钟hold time。也就是上图中的②所示的时间段。
所以我们要将异步复位信号同步到系统时钟下。关于同步我们就比较熟悉了,对于这种情况打拍就可以了,因为还涉及到亚稳态的处理,所以这里我们在系统时钟下对复位信号进行打两拍的处理,然后再把打两拍后的信号作为系统的复位。


5、同步复位与异步复位对比
同步复位优缺点
优点:
(1)在同步复位电路下,复位和数据信号都受到时钟信号的控制,所以同步复位一般可以确保电路是一个同步电路
(2)在ASIC设计中,同步电路一般可以综合为更小的同步触发器(因为触发器没有包含复位逻辑),但是在FPGA设计中并不如此,一般FPGA的时序元件为带异步复位的触发器(也有同步触发器,视厂家而定)。如果在FPGA设计中使用同步复位,其消耗的资源相对较多。
(3)由于触发器的跳转只在时钟的边沿,所以触发器可以在一定程度上过滤电路毛刺。进而如果复位由电路内部的逻辑控制,在这种情况下可以在设计中使用同步复位:通过可以在一定程度上过滤电路毛刺的特性,过滤掉内部电路逻辑产生的毛刺,使设计更鲁棒。
缺点:
(1)同步复位需要较长的保持复位状态时间(最小也要大于时钟周期),保证同步复位信号可以到达每一个寄存器并且要在有效时钟沿之前到达(在真正设计使用的时候还需要考虑时钟偏斜、组合逻辑延时、复位延时等,即:同步复位信号时长> 时钟周期 + 时钟偏斜 + 组合逻辑延时)。
(2)在低功耗设计中,同步复位一般不能用于门控时钟控制的电路。因为同步复位电路中,主要靠时钟驱动复位和数据。当复位发出时,有可能时序电路此时并没有时钟驱动,那么此时的复位就不能完成。
(3)在fpga设计中,同步复位会消耗更多的资源。
(4)使用同步复位会使综合工具无法分辨复位信号和其他数据信号。
异步复位优缺点
异步复位的优点:
(1)异步复位的复位逻辑和数据逻辑没有任何关系,所以相比同步复位,能够使数据路径更好地收敛。(上上图对比)
(2)不用在时钟的控制下进行复位,所以对于刚才所提到的低功耗设计中,可以达到无时钟复位的效果[注意:寄存器复位后的正常状态恢复需要时钟参与]。
(3)使用异步复位优势在于只要生产方提供的库中有带异步复位的触发器,就能保证数据路径上是干净的。
异步复位的缺点:
(1)因为异步复位不受时钟的控制,所以当电路复位引脚有毛刺的时候,会引起电路的异常复位。
(2)在异步复位的时候,如果释放复位信号在时钟有效边沿周围。那么可能会引起时序单元的输出出现亚稳态,导致电路亚稳态传播。
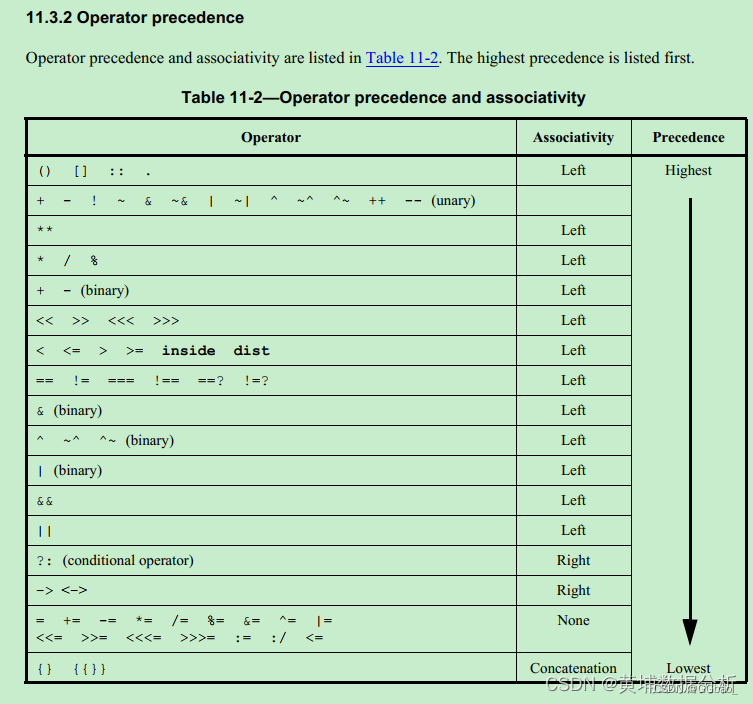
6、运算符优先级
7、FIFO深度设计
关于同步fifo和异步fifo深度设计和特殊情况 - 知乎
同步FIFO:
时钟为100M,每100个cycle可以写入80个数据,每10个cycle可以读出8个数据,fifo的深度至少为?
每100个cycle可以写入80个数据,考虑最坏的情况,背靠背模式(前100clk的后80clk写数据,下一个100clk的前80clk写数据),突发长度为160个clk写160个数据,在这160clk读侧只能读出(160/10)*8 = 128;所以没读走的160-128=32个数据为fifo的最小深度。
异步FIFO:
(1)当读写吞吐率一样:当写数据频率为100MHz,每100个写时钟写入60个数据;读数据频率为200MHz,每10个时钟读出3个数据,异步fifo的深度最小为?
- 写入的带宽为(60/100)*100M=60MHz;读出的带宽为(3/10)*200M=60MHz;读写带宽相等,继续计算;
- 考虑背靠背传输,120个数据,需要120*(1/100M)=1200ns;
- 读出3每个数据的时间:(1/200M)*10 = 50ns
- 1200ns可以读出的数据个数为:(1200/50)*3 = 72(个)
- 所以在1200ns内还没有被读走的数据个数 = 120-72 = 48(个) 因此FIFO的最小深度为48
(2)当写的吞吐率大于读的吞吐率的时候,fifo不论深度为多少总会溢出;
比如写时钟100M,读时钟80M,写侧每100个周期写60个数据,FIFO读出侧4个周期读出1个数据。则写入速率为(60/100)*100 = 60M;(1/4)*80 = 20M;所以写入吞吐率大于读出吞吐率,所以总是会溢出,类比于一个水池出水口的流速比入水口的流速满,水池迟早会溢出。
8、UVM中phase的执行顺序
UVM中主要有两种phase,包括task phase和function phase。task phase需要消耗仿真时间,function phase不消耗仿真时间。function phase有8个,task phase有12个。

function phase中,各个phase是按照顺序执行的,同一时刻只有一个phase在运行,但是task phase中各个phase是并行运行的,其又称为动态运行的phase。
UVM环境中的phase执行,不消耗时间的phase中,只有build_phase是自上而下执行,其他function phase都是自下而上执行的。function phase中各个phase中例化完以后的每个phase中的执行顺序与例化的顺序没有关系。function phase的8个phase按照顺序执行,但是每个phase中的例化成员执行时按照字典执行的。
UVM环境中的动态phase也是按照自下而上的顺序执行,但是task phase是需要消耗时间的,所以他并不是等到下面的phase执行完以后再去执行上面的phase,而是将这些run_phase同时通过fork...join_none的方式全部启动,所以可以描述为自下而上启动,同时运行。
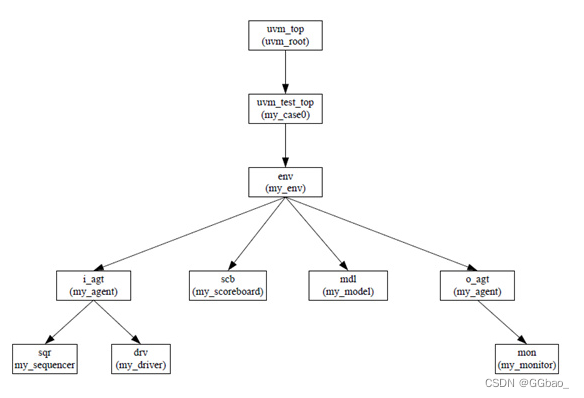
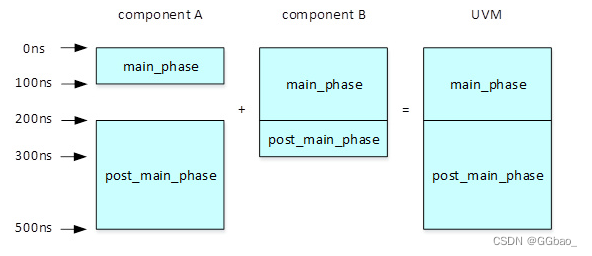
UVM树中多个同一层次的多个component而言,一个component的某个phase执行完以后,需要等待环境中的所有component的该phase都执行完成,所有component同时进入下一个phase,其执行过程为:
9、三极管
发射结正向偏置、集电结反向偏置,工作在放大状态。
发射结和集电结都正偏置,工作在饱和状态。
发射结和集电结都反向偏置,工作在截止状态。
作为开关时候,开关导通时,工作在饱和区,开关断开时工作在截止区。
10、静态时序分析
(4条消息) STA(静态时序分析) 详解:如何计算最大时钟频率,以及判断电路是否出现时钟违例(timing violation)?_weixin_43701504的博客-CSDN博客
(4条消息) STA静态时序分析——学习笔记_Zokion的博客-CSDN博客
第五章 静态时序分析入门 - 知乎 (zhihu.com)
11、跨时钟域信号处理
单比特:用两级寄存器串联同步
多比特:
MUX同步器(带数据有效标志信号的多比特数据做跨时钟域)
握手同步(带en脉冲信号的多比特数据做跨时钟域)
格雷码(连续变化的多比特信号)
格雷码+异步双口RAM(无限制场景,尤其在有大量的数据且速度要求较高时候)
异步FIFO
(4条消息) 跨时钟域信号如何处理(二、多bit信号)_luoai_2666的博客-CSDN博客
12、网表等基本知识
网表:
网表是逻辑电路设计转化为物理实现的工作产品,网表可以有各种抽象级,例如门级网表和晶体管级网表。门级网表通常用于数字电路,晶体管级网表通常用于模拟电路。
门级网表
门级网表中,描述的是门级电路的连接关系。通常后端厂商提供基本的门级基本单元库,RTL级设计转化为指定基本单元库(厂家库)中单元电路的连接,即为网表。门级网表的电路功能应该与RTL代码一致。
1、DC/DFT/SDF
DC design compiler 是综合后的网表
DFT design for testability 插入逻辑测试的网表
SDF standard delay format 是加标准延时格式文件的网表
sdf 是工具输出,反标信息,与其他工具交流用的格式,通常不修改,基本上就是给vcs用。
sdc synopsys design constraints 设计约束文件,对电路的时序,面积,功耗进行约束。
网表以phy为最小单位来替换,phy与phy之间的信号都被打平,按bit位连接。
如果phy内部端口不用,被优化,则工具会在该输出端口加SYNOPSYS_UNCONNECTED_XXXX名字,表示端口悬空。
网表仿真debug时,由于信号打平,比较难trace,可以参照rtl代码来进行debug,效率更快。
2、DC
综合就是将设计的HDL描速转化为门级网表的过程。Synopsys公司提供的综合工具DC把综合分为三个步骤进行:synthesis=translation+mapping+optimization。Translation是指把设计的HDL描述转化为 GTECH库元件组成的逻辑电路;GTECH库是Synopsys公司提供的通用的、独立于工艺的元件库。Mapping是指将GTECH库元件映射到某一特定的半导体工艺库上,此时的电路网表包含了相关的工艺参数。Optimization是根据设计者设定的时延、面积、线负载模型等综合约束条件对电路网表进一步优化的过程。从综合工具的使用流程来看,综合包括综合环境的设置,综合约束,综合优化,综合与后端流程等。
3、DFT
可测试性技术(Design For Testability-DFT)就是试图增加电路中信号的可控制性和可观测性,以便及时经济地测试芯片是否存在物理缺陷,使用户拿到良好的芯片。其中包括Ad Hoc技术和结构化设计技术。目前,任何高集成度IC设计系统都采用结构化设计技术,其中主要扫描技术和内建自测两种技术。
4、网表的不同后端阶段
网表按照不同后端阶段可以分为综合网表,DFT网表,PR网表等,由于网表仿真时可以引入实际元器件尺寸和寄生参数等带来的各种延时信息,所以对网表的仿真比对RTL的仿真更加接近真实芯片的行为。
DC网表
综合网表是前端设计完成后,通过添加时序和面积的约束,用综合工具将RTL级设计转化成的门级电路。综合网表虽然调用了厂家器件库,但是还未进行布局布线,只是初步的逻辑连接,还不用用于真正的物理实现。
DFT网表
DFT网表是在综合网表的基础上,为了检测生产制造缺陷,在综合网表中添加一些测试电路后的设计。具体包括扫描链scan,memory BIST(built in self test 内建自测试),logic BIST,ATPG(自动测试向量生成)等。
PR网表
PR网表这是在DFT网表基础上完成布局布线后的网表。是完成布局placement,时钟树综合CTS,布线routing后的网表。其功能和时序最为接近物理芯片。
5、功能验证和网表验证
功能验证,一般指在IC设计过程中,通过仿真RTL级设计,来确认其是否符合设计需求的验证。
网表验证,是对网表进行测试验证的过程。网表验证主要有三种手段:仿真验证,静态时序分析以及形式验证。
6、前仿真与后仿真
前仿真,一般指RTL级仿真验证。
后仿真,即网表验证中的仿真,也叫布局布线后的网表仿真验证。它利用动态仿真的形式来检查网表功能和时序的正确性。后仿真通常指布局布线后的门级网表的仿真,包括时序仿真和功能仿真。功能仿真不带延时信息,主要检查基本功能是否正确。时序仿真会反标上延时信息,检查时序特性。
7、网表功能仿真和时序仿真
功能仿真,即不反标延时信息的网表仿真,主要验证网表的功能正确性,包括综合网表功能仿真,DFT网表功能仿真,以及PR网表功能仿真。
时序仿真,反标延时信息的网表仿真,主要用来验证网表的时序正确性。
8、术语
ECO engineering change order 工程变更单
STA static timing analysis 静态时序分析
GLS gate level simulation 门级仿真
原文链接:https://blog.csdn.net/weixin_45270982/article/details/108111730
13、数字信号采样
采样频率是一个非常重要的参数,因为它直接影响数字信号的质量。采样频率越高,所能表示的信息越丰富,但是也会带来更大的数据量和更高的计算复杂度。根据采样定理,当采样频率大于信号中最高频率的2倍时,采样之后的数字信号完整地保留了原始信号中的信息,一般实际应用中保证采样频率为信号最高频率的5~10倍。
对数字信号做采样前添加滤波器,一般需要添加低通滤波器滤除高频,这时候再使用采样频率为Fs的采样时钟进行降采样,该滤波器的功能是抗混叠滤波,这个滤波器也叫抗混叠滤波器。
为什用低通滤波器进行降采样,达到抗混叠滤波效果?因为 ADC 采样、量化后的信号是离散的数字信号,【时域离散化对应频域周期化】,即在频域会出现多个频率分量,其中只有低频部分是我们实际需要的。
此时,若直接进行降采样,那么针对每个频率分量,将会再次进行一次周期化,D倍抽取序列的频谱为抽取前后原始序列之频谱经频移和D倍展宽后的D个频谱的叠加和,因此可能存在混叠。
14、解决亚稳态常用方法
亚稳态(semi-stable state)是指触发器无法在某个规定时间段内达到一个可确认的状态。当一个触发器进入亚稳态引时,既无法预测该单元的输出电平,也无法预测何时输出才能稳定在某个正确的电平上。在这个稳定期间,触发器输出一些中间级电平,或者可能处于振荡状态,并且这种无用的输出电平可以沿信号通道上的各个触发器级联式传播下去。
1. 降低系统时钟
2 .用反应更快的FF(filp-flop,触发器)
3. 引入同步机制,防止亚稳态传播(同步寄存器)
4. 改善时钟质量,用边沿变化快速的时钟信号
15、流水线设计优缺点
所谓流水线设计实际上是把规模较大、层次较多的组合逻辑电路分为几个级,在每一级插入寄存器组并暂存中间数据。K级的流水线就是从组合逻辑的输入到输出恰好有K个寄存器组(分为K 级,每一级都有一个寄存器组),上一级的输出是下一级的输入而又无反馈的电路。 流水线设计在性能上的提高是以消耗较多的寄存器资源为代价的。 流水线处理是提高组合逻辑设计的处理速度和吞吐量的最常用手段。
优点:可以提高系统时钟频率,增加数据吞吐量。
缺点:导致系统延迟增加,功耗增大,以及面积增大
16、验证
(4条消息) IC设计- 浅谈各种验证 - 功能验证,形式验证,原型验证_形式验证和功能验证区别_AmoreMc的博客-CSDN博客
(4条消息) 数字IC验证方法的分类_静态验证的常见方法_嗨小小小黑的博客-CSDN博客
(4条消息) 数字IC验证:几大功能验证(Functional Verification)技术有哪些?_IC Beginner的博客-CSDN博客
17、静态、动态时序分析的优缺点
静态时序分析 STA
静态时序分析是采用穷尽分析方法来提取出整个电路存在的所有时序路径,计算信号在这些路径上的传播延时,检查信号的建立和保持时间是否满足时序要求,通过对最大路径延时和最小路径延时的分析,找出违背时序约束的错误。
优点:
1.它不需要输入向量就能穷尽所有的路径;
2.运行速度很快、占用内存较少,不仅可以对芯片设计进行全面的时序功能检查,而且还可利用时序分析的结果来优化设计。因此静态时序分析已经越来越多地被用到数字集成电路设计的验证中。
缺点
静态时序分析只能对同步电路进行分析,而不能对异步电路进行时序分析。
动态时序分析 DTA
动态时序模拟就是通常的仿真
优点
比较精确,而且同静态时序相比较,它适用于更多的设计类型 。
缺点
1.分析的速度比较慢
2.需要使用输入矢量,这使得它在分析的过程中有可能会遗漏一些关键路径,着规模增大,所需要的向量数量以指数增长,且这种方法难以保证足够的覆盖率。