一)进行测试Sentinel池:
集群的定义:所谓的集群,就是通过增加服务器的数量,提供相同的服务,从而让服务器达到一个稳定、高效的状态
之前的哨兵模式是存在着一些问题的,因为如果主节点挂了,那么sentinel集群会选举新的sentinel兵王来去进行故障修复操作,一旦此时受到了客户端的写的请求,就有可能会造成数据丢失的情况
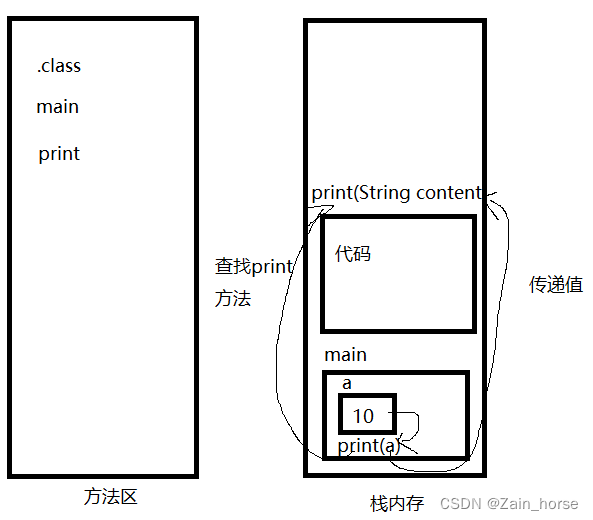
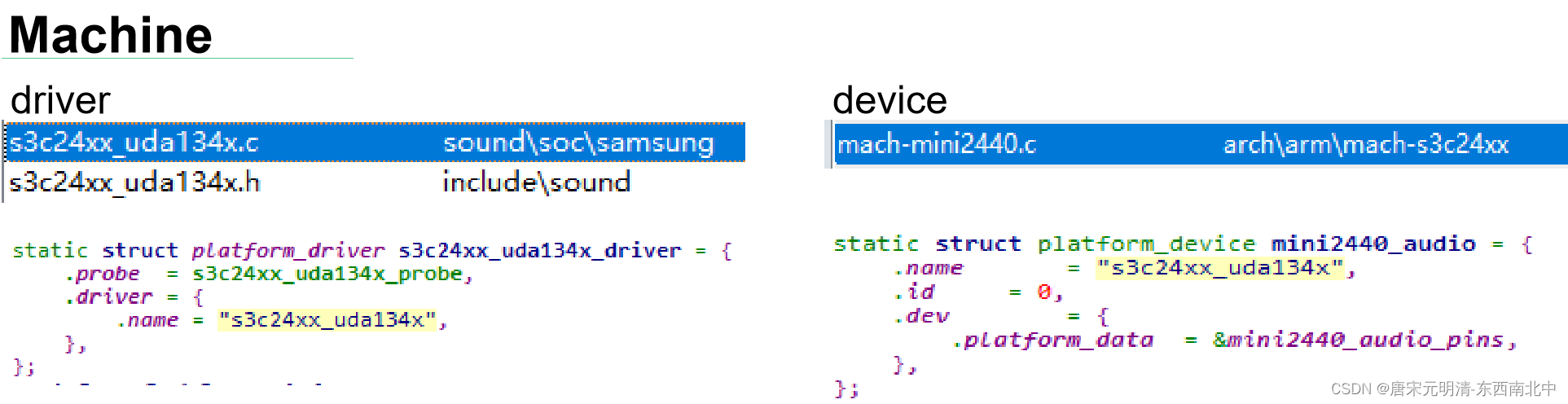
@Controller public class RestController { @RequestMapping("/Java100") @ResponseBody public String start(){ //1.配置信息 HashSet<String> set=new HashSet<>(); // 连接信息 ip:port // set.add("127.0.0.1:27001"); set.add("124.71.136.248:27001"); //2.创建Sentinel连接池 JedisSentinelPool pool = new JedisSentinelPool("mymaster", set, "12503487"); //3.获取到Jedis客户端 Jedis jedis=pool.getResource(); //4.设置元素 jedis.set("name","zhangsan"); String value=jedis.get("name"); return value; } }public static void main(String[] args) { RedisURI redisURI = RedisURI.builder() .withHost("124.71.136.248") .withPort(6379) .withPassword("12503487") .build(); RedisClient redisClient = RedisClient.create(redisURI); // // 创建 RedisClient // RedisClient redisClient = RedisClient.create("redis://124.71.136.248:7001"); // 获取与 Redis 单节点的连接 StatefulRedisConnection<String, String> connection = redisClient.connect(); // 获取同步命令 RedisCommands<String, String> syncCommands = connection.sync(); // 执行 Redis 命令 syncCommands.set("key", "value"); String value = syncCommands.get("key"); System.out.println("Value: " + value); // 关闭连接 connection.close(); redisClient.shutdown(); }二)Redis分片集群
主从集群可以应对高并发读的问题,我们的单节点的内存设置不要太高,如果内存占用的过高,那么在做RDB的持久化或者全量同步的时候就会导致大量的IO,性能下降
1)如果写的并发也很多怎么办呢?
2)如果需要进行存储的数据仍然是很多怎么办呢?
主从模式和哨兵模式可以解决高并发读,高可用的问题,但是仍然存在着海量数据存储的问题和高并发写的问题
3)分片集群的特征:
3.1)集群中有多个master,每一个master保存着不同的数据,这样进行存储的数据总量取决于master结点的数量;
3.2)每一个master本身都有多个slave节点
3.3)master相互之间可以做ping命令来进行检测检测彼此的健康状态
1)Redis集群支持多个Master,每一个Master又可以挂载个Slave,这样可以实现读写分离
支持数据的高可用,支持海量数据的读写存储操作;
2)由于Cluster自带的Sentinel的故障转移机制,内置了高可用的支持,这是无需再次使用哨兵模式;
3)客户端和Redis的节点相连,不再需要连接集群中的所有节点,只需要进行任意连接集群中的一个可用节点即可
4)槽位slot负责分配到各个物理服务节点,有对应的集群来负责维护节点,插槽和数据之间的关系


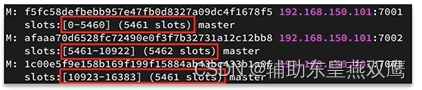
Redis会把每一个master节点映射到0-16383一共是16384个插槽上面,查看集群信息的时候就可以看到:
Redis中的key不是和master节点进行绑定的,而是和插槽进行绑定的,redis会根据key的有效部分来进行计算插槽的值,主要是分成两种情况:
1)key中包含{},况且大括号中至少包含一个字符,那么大括号中的部分就是有效部分
2)key中不包含大括号,整个key都是有效部分
假设如果key是num,那么key的有效部分就是num,但是假设key是{kkk}num,那么有效部分就是kkk,计算方法就是利用CRC16算法得到一个哈希值,针对这个16384取余,最后得到的结果一定是在0-16373之间,然后得到一个solt值;
3)因为redis的主节点是有可能出现宕机的情况的,或者是集群扩容增加了节点,或者是集群伸缩,删除了节点,如果一个节点宕机了,那么这个节点上面的数据也就丢失了,而数据如果是和插槽绑定的,那么当节点宕机的时候,我们可以把这个节点对应的插槽转移到正常的节点,集群扩容的时候,也可以将插槽进行转移,这样数据跟着插槽走,就永远可以找到数据的位置;
一)Redis是如何进行判断Key在哪一个实例上面?
1)将16384个插槽分配到不同的实例节点上面
2)当存储一个key或者取出一个key的时候会,根据key的有效部分来计算哈希值,对16384进行取余操作;
3)将余数作为插槽,寻找到插槽所在的实例节点即可
二)如何将同一类数据固定的保存到同一个Redis实例中呢
假设我现在有不同的商品,空调洗衣机手机,各种类型不同的产品,就是将相同的商品放到同一个节点上面,因为将来用户搜索手机的时候,我就可以去同一个节点查询,避免出现请求重定向,因为重定向还要重新建立连接,性能上会有一定的损耗,
所以说这一类数据使用相同的有效部分,例如说key都是以{typeID}为前缀
三)redis集群的分片
3.1)分片的定义:在使用redis集群的时候,我们会将存储的数据分散到多台Redis机器上面,这就称之为是分片,简而言之集群中的每一个Redis实例都被认为是整个数据的一个分片
3.2)如何找到给定的key的分片:为了找到给定的key的分片,我们对key进行CRC16(key)算法处理并通过对总分片数量进行取模,然后使用确定性哈希函数,这就意味着给定的key将多次始终映射到一个分片,我们可以进行推断并且读到key的位置
四)slot槽位映射:
1)不一致哈希取余分区:2亿条记录就是2亿个K,V,我们单机是存储不下这些数据的,必须要使用分布式机器,假设有三台机器构成一个集群,用户每一次的读写操作都是根据公式:
hash(key)%机器数,来进行计算出哈希值,用来决定数据映射到哪一个机器上面
1.1)优点:简单粗暴,直接有效,只需要预估好数据,规划好节点,使用哈希算法让固定的一部分请求落在同一台服务器上面,这样每一台服务器来固定处理一部分请求,并且维护这些请求的信息,起到负载均衡和分而治之的作用;
1.2)缺点:原来规划好的节点,进行扩容和缩招就比较麻烦,因为映射关系要重新进行计算,除非服务器永远不会变化,在服务器固定个数不变的时候没有问题,但是如果需要进行弹性扩容或者故障停机的情况下,原来的取模公式就会发生变化,Hash(Key)/3就会变成Hash(Key)/2,甚至于说如果某一台Redis直接宕机了,由于台数发生变化,就会导致哈希取余全部数据重新洗牌;
二)一致性哈希算法分区:设计目标是为了解决分布式缓存数据变动和映射问题,如果某一台机器宕机了,分母数量改变了,自然取余数就不OK了,就是为了当服务器的个数发生变动的时候,要尽量减少客户端到服务器的映射关系
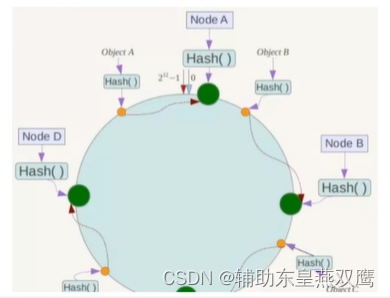
2.1)哈希取余分区:一致性哈希是将整个哈希值空间组织成一个虚拟的圆环,比如说假设某一个哈希值的值空间是0-2^32-1,那么他的整个哈希环空间如下,也就是说所有的输入值都被映射到0-2^32之间,组成了一个圆环,前面介绍的算法是针对服务器的数量进行取余,而一致性哈希算法是针对2^32进行取余;
2.2)下一步将各个服务器使用Hash函数进行一个哈希, 具体可以选择服务器的ip或主机名或者其他业务属性作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用ip地址哈希后在环空间的位置如下:
2.3)将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并且将该键值对存储到该节点上面







五)搭建分片集群
1)在/myredis目录下面创建9001 9002 9003 9004 9005 9006 9007目录,并分别写入redis.conf文件
2)在redis.conf文件中配置下面的信息
port 9001 # 开启集群功能 cluster-enabled yes # 集群的配置文件名称,不需要我们创建,只需要程序员指定位置即可这个文件将来由redis自己维护 cluster-config-file /myredis/9001/nodes.conf # 节点心跳失败的超时时间,如果集群之间相互做心跳的时候超过5s没有心跳,就认为是疑似宕机了 cluster-node-timeout 5000 # 持久化文件存放目录 dir /myredis/9001 # 绑定地址,任何地址都可以访问 bind 0.0.0.0 # 让redis后台运行 daemonize yes # 注册的实例ip replica-announce-ip 127.0.0.1 # 保护模式 protected-mode no # 数据库数量 databases 1 # 日志 logfile /myredis/9001.log3)启动各个目录下面的redis,虽然此时6个redis实例,全部启动起来了,但是它们彼此之间并没有相互联系起来,因为并没有进行指定谁和谁之间是有联系的
创建集群:
1)redis-cli --cluster create 127.0.0.1:9001 127.0.0.1:9002 127.0.0.1:9003 127.0.0.1:9004 127.0.0.1:9005 127.0.0.1:9006
2)redis-cli -p 9001 cluster nodes1.1)这里面的redis-cli --cluster代表的是集群操作命令
1.2)create代表的是创建集群
1.3)--cluster-replicas 1代表指定集群中每一个master得副本是1,此时节点总数/(replicas+1)得到的就是master得数量,因此上面的节点列表的前n个就是master,其他节点的都是slave节点,被随机分配到不同的master节点
3)在我们进行连接集群中的某一个节点的时候,直接输入命令
redis -c -p 具体的端口号
port 9001 # 开启集群功能 cluster-enabled yes cluster-node-timeout 5000 cluster-announce-ip 127.0.0.1 cluster-announce-port 9001 # 集群的配置文件名称,不需要我们创建,由redis自己维护 cluster-config-file /myredis/9001/nodes.conf # 节点心跳失败的超时时间 cluster-node-timeout 5000 # 持久化文件存放目录 dir /myredis/9001 # 绑定地址 bind 0.0.0.0 # 让redis后台运行 daemonize yes # 注册的实例ip replica-announce-ip 127.0.0.1 # 保护模式 protected-mode no # 数据库数量 databases 1 # 日志 logfile /myredis/9001.log ~
所以当你进行操作任意一个key的时候,会先进行计算插槽值,再进行判断你在哪一个节点,在完成一个请求的路由,所以你进行访问任意一个数据,都可以重定向到具体的节点;

集群伸缩
redis-cli --cluster提供了很多可以进行操作集群的命令,可以通过以下方式来进行查看:
1)如果想要进行新增节点,需要指明新的IP地址和新的端口号,还要进行指明集群中已经存在的IP和端口号(为了新增节点的时候通知每一个集群中每一个角色,从而联系上这个集群)
2)下面的--cluster-slave和--cluster--master-ip默认是没有进行添加的,如果没有添加这两个节点,那么这个节点默认就是一个主节点,如果你添加了这两个信息,那么默认就成为了指定节点的从节点了

需求:向集群中添加一个新的master节点,并向其中存储num=10
1)启动一个新的redis实例,端口号是1000
2)添加1000到之前的集群,并作为一个master节点
3)给7004节点分配插槽,使得num这个key可以存储到7004这个主节点上面
1.1)添加新节点到集群中
redis-cli --cluster add-node 127.0.0.1:1000 127.0.0.1:9001
1.2)通过命令查看集群状态
redis-cli -p 1000 cluster nodes
1.3)查看集群状态可知,1000的插槽数量是0,因此没有任何节点可以成功存储到1000这个主节点
1.4)先进行查看num的插槽值是多少,可以看到num的插槽值是2765,也就是说只要2765这个插槽能够成功分配到1000,那么1000这个主节点就可以成功的存储到num值了
1.5)先查看以下分配插槽的命令:
1.6)建立连接: redis-cli --cluster reshard 127.0.0.1:9001
1.7)当你输入命令成功之后,redis会想你进行询问你想要那一部分的插槽,我们需要转移3000个插槽就足够了
1.8)接下来redis有会向你进行询问,你需要将插槽转移到哪里去?所以我们需要直接输入插槽对应的ID即可
1.9)然后redis还是会向你进行询问,你这些插槽,从哪一个主节点开始进行拷贝,请输入主节点的ID,当然是从9001开始呀,于是输入9001对应的ID即可,然后输入done即可
2.0)再次进行查看redis-cli -p 1000 cluster nodes节点信息




故障转移:
1)先实现将节点断开连接redis -p 对应节点的端口号 shutdown
2)将这个节点重启,发现这个节点已经变成了从节点
当一个集群中有一个master宕机会发生什么呢?
1)首先是该实例会和其他实例断开连接
2)然后是疑似宕机
3)最后是确认下线,自动提升一个该节点的slave节点为新的master节点
从上面的日志信息我们可以看出,当我们把9001这个进程给干掉之后,9005就成为了主节点,如果我们再次启动9001,那么它会变成分片集群中的从节点
手动故障转移:
1)利用cluster master命令可以让集群中的某一个master宕机,切换到cluster master命令的这个slave节点,实现无感知的数据迁移
2)具体的替换流程如下:现在我想让这个slave节点替换master节点
2.1)当我们去执行命令的这一刻,slave节点回向master节点发送一个消息,和master说我要替换你了,这个时候主节点为了避免消息的丢失,这个master节点就会拒绝客户端的一切请求,所有进来的命令都会进行阻塞;
2.2)master会返回一个offset给slave
2.3)slave也会等地啊当前的数据和master一致,如果不一致赶紧做主从同步
2.4)开始做故障迁移
2.5)让slave充当master,master来充当slave
2.6)这个新的master结点开始做一个广播,通知自己是新的节点
3)这种Failover支持三种不同版本的参数
3.1)不加任何参数,按照默认的流程来进行节点替换
3.2)fource,省略了对offset的一致性校验
3.3)takeover:直接执行2.6,忽略数据一致性,忽略master状态和其他master的意见


需求:将9001这个slave节点手动进行故障转移,重新夺回master地位
1)需要使用redis-cli连接这个7002节点
2)执行cluster failover命令

StringRedisTemplate访问分片集群:
1)引入redis的依赖
2)配置分片集群的地址
3)配置读写分离