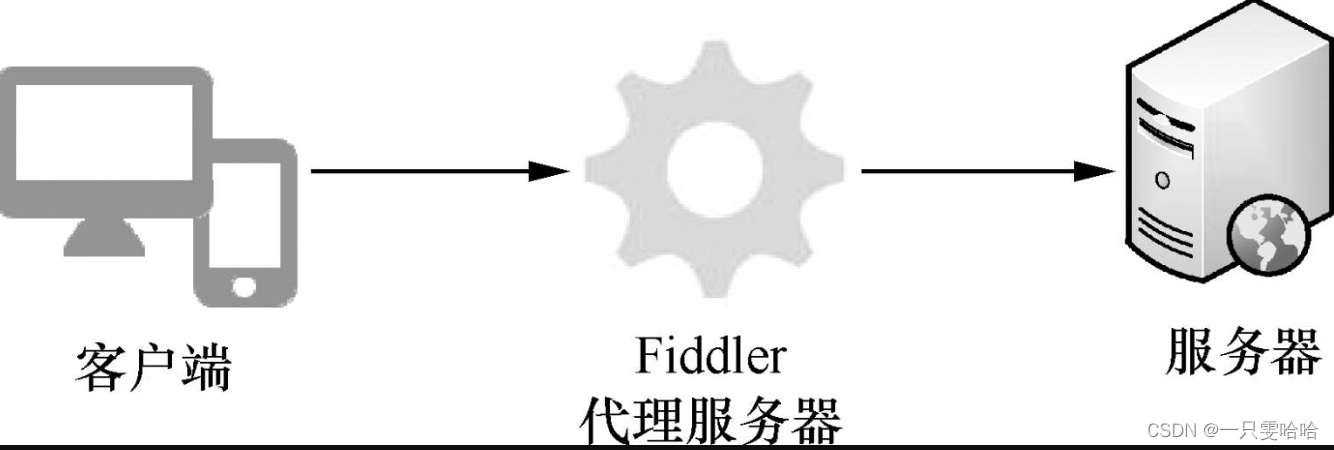
文章目录
- 概述
- 论文翻译CONDITIONAL SOUND GENERATION USING NEURAL DISCRETE TIME-FREQUENCY REPRESENTATION LEARNING
- Abstract
- SampleRNN是啥?
- Introduction
- 个人总结(省流)
- 补充
- 个人感想
- Approach
- 2.1 Discrete time-frequency
- 省流总结
- 2.1.1 Multi-scale convolutional scheme in the encoder
- several strided convolutional layers(SCLs)的具体构成
- 2.1.2 Model architecture
- 2.2 Conditional sound generation
- 省流总结
- Experiments
- 3.1 Dataset
- 3.2 Spectrogram compution
- 问题
- 3.3 Details of model implementation
- 3.3.1 VQ-VAE
- 3.3.2 Autoregression model
- 3.3.3 Waveform synthesis module
- 3.4 Baseline system
- 3.5 Evaluation methods
- 3.5.1 Generation quality
- 3.5.2 Generation diversity
- 3.6 Evaluation results
- 3.6.1 Generation quality
- 3.6.2 Generation diversity
- 3.7 Ablation study
- Conclution
- 阅读总结
概述
- 这部分准备先复现项目,看看能不能跑起来,只要能跑起来,就剩下看论文了,然后根据论文讲讲代码,这个任务基本上就算是完成了,至少下周的课程没啥问题了。
- 项目的地址
- 论文地址
论文翻译CONDITIONAL SOUND GENERATION USING NEURAL DISCRETE TIME-FREQUENCY REPRESENTATION LEARNING
Abstract
- 在语音生成和音乐合成领域,深度生成模型已经取得了很大成就,但是对于一般常见声音(警笛声、枪声等)的生成的研究,鲜有人关注,虽然这些东西很有用。之前的工作中,尝试使用了SampleRNN模型在时间领域进行声音的生成。但是,SampleRNN并不能获取声音中的长依赖,因为他只能通过有限的样本进行反向传播。在本文中,我们提出一种声音生成的新方法,该方法是以声音类别为条件的,神经离散时频表示学习实现的。这个方法能够对声音片段中的长依赖进行有效建模,并且还能保存局部细粒度结构(什么是long-dependency,什么是local fine-grained structures)。我们在UrbanSound8K数据集上进行了测试,和SampleRNN方法进行对比,通过衡量生成声音的质量和多样性来衡量模型的性能。实验结果表明,我们的方法在质量上的效果不错,但是在多样性的上效果更好
SampleRNN是啥?
- 参考连接,SampleRNN介绍
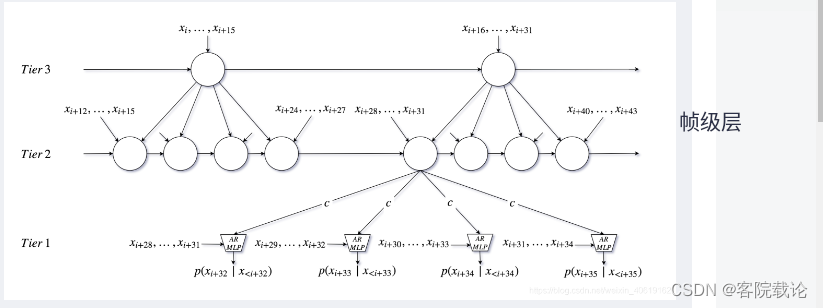
- 用于处理声音合成的层次化循环神经网络,是一个端到端的无条件合成模型,擅长处理超长序列之间的依赖关系。采用了多层RNN类神经网络在不同的分辨率下对序列进行处理和预测,最后生成一个波形样本。最上层的分辨率最低,计算量最小,处理的时间域最长,只需要接受多个输入数据帧,随后层数越低,分辨率越高,处理的时间域越短,计算量越大,最后一层仅对单个样本做处理,并输出预测波形。
- 除了最低下的是采样层,往上都是不同分辨率的帧级层
Introduction
- 一段随手录制的常规音频包含了很多关于环境的信息,从单个物理事件到整个声音的场景。常规声音生成应用还是很广泛的,比如说电影和游戏中自动产生的音效。除此之外,因为收集和标注声音相关的数据很困难,所以可以使用声音生成做数据增强。从长远来看,声音搜索引擎在在未来会整合声音生成系统,并且根据用户的个人喜好自定义声音。
- 在语音合成和音乐生成领域,因为深度生成模型,已经可以实现很好的效果。但是在常规声音生成领域,确实没啥进步,因为这种声音没啥固定的结构,并且差异很大,除此之外,这种声音常常是包裹在噪声和混响中,很难提取。因此,直接用深度生成模型直接生成常规声音是十分困难的。在这方面做的相关的工作,主要是包括声音场景生成或者环境声合成,基本上对于常规声音合成的探索为空白。
- SampleRNN是一个用于波形生成的自回归模型,《Acoustic Scene Generation with Conditional Samplernn》这篇文章就是使用SampleRNN做语音生成的。SampleRNN只能在时间域生成声音,并且仅仅只能反向传播一秒中的几个片段。所以说,如果仅仅使用SampleRNN,仅仅依靠声音切片,很难获得长时间域下的依赖。但是,很多时候,某些声音事件发生的时间很长,比如说急救车蜂鸣需要好几秒钟。所以说,我们获取音频中的长依赖,获得的特征更加全面,更有利于生成类似的声音。
- 在时频(TF)领域对声音进行建模,能够帮助获取时间域更长的依赖,但是这需要将时频表示转成时间领域的波形。目前已经提出基于GAN的方法进行波形合成,这种方法因为其并行结构,所以计算效率很高,并且合成的音频的质量很好。合成高质量的波形,常常需要要求声谱图具有高时间分辨率,并借此保留局部和细粒度特征,这两个特征对于声音质量还是很重要的。但是,频谱图的时间分辨率越高,计算开销就越大。
- 在这篇文章中,我们提出了一种能根据类别在时间域生成对应声音的方法,这个方法使用的是矢量量化的变分自动编码器(VQ-VAE)。我们的方法能够声音的长领域依赖进行有效建模,同时还能减少在时频领域高时间分辨率的对声音建模的计算代价。更为特殊的是,VQ-VAE模型是学习声音的离散时频表示(DTFR)的。然后,将DTFR作为输入,声音类别作为条件,训练一个自回归模型去生成声音。除此之外,针对VQ-VAE中的编码器,我们提出了一个多尺度卷积模式,借此来获取不同尺度下的声音的音频信息。实验表明,这种修改使得DTFR更加紧凑,并且能对编码中局部细粒度结构进行有效编码。在我们的认知中,一般很少使用VQ-VAE去做常规声音的条件生成。我们的经验表明,我们的方法在模拟声音的长依赖方面比时域生成方法更加有优势。
- 我们使用UrbanSound8K数据集来衡量我们的生成的声音的多样性和质量。试验结果表明,我们提出的方法在声音的多样性上比SampleRNN要好很多,同时在质量上,二者差不多。
个人总结(省流)
-
这篇文章举了两种方法作为方法提出的基本点,分别是SampleRNN和基于时间域的GAN方法,然后为了互补两个方法的差别,在提出了新的方法,下面先回顾一下这两种方法的差别
- SampleRNN
- 在时间域生成声音,并且仅仅只能反向传播一秒中的几分之一,获取的依赖有效时间段太短了,很多声音都是的信息都是长领域依赖的
- 生成的time-domain,但是获取的特征仅仅只是几分之一秒的,很多声音的特征完整体现很长
- 基于GAN的方法
- 在时频领域,使用频谱图来获取表达时间比较长的特征依赖,专门针对上面的问题而言提出的对比。但是需要将时频表示转成时域的波形图。
- 如果要合成的波形图质量越高,频谱图的时间分辨率就要越高,对应的计算量越大。
- 总结就是:
- 如果获取时间跨度更长的时间特征表示,就得使用时频来做,但是用时频就得将计算波形图,但是计算量很大
- SampleRNN
-
于是乎作者提出了自己的方法,基于Vector Quantised Variational AutoEncoder(VQ-VAE)
- 目的:
- 综合上述两个方法的优点,并弥补缺点,
- 获取时间跨度较长的长依赖的同时,追求高时间分辨率的高质量图,并效减少计算量
- 具体步骤如下
- 首先,创建一个VQ-VAE模型提取声音的离散的时频特征
- 然后,训练一个自回归模型,根据类别生成声音
- 额外增加
- 将VQ-VAE模型中的编码中卷积层改为多尺度模式,获取不同尺度下的声音信息
- 目的:
-
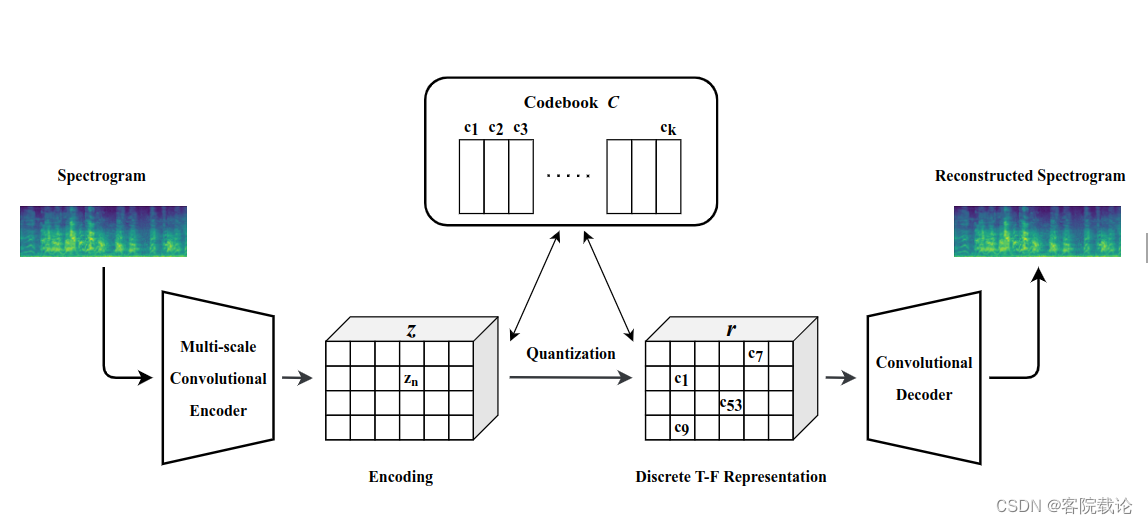
这里主要有两个图,说明网络结构。
-
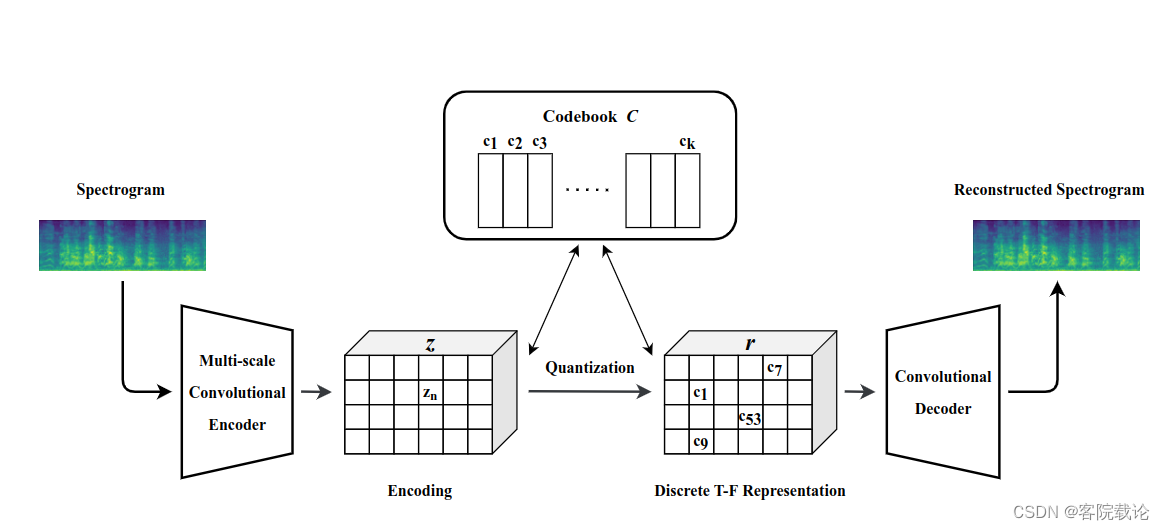
这个图是训练获取DTFR的VQ-VAE模型的
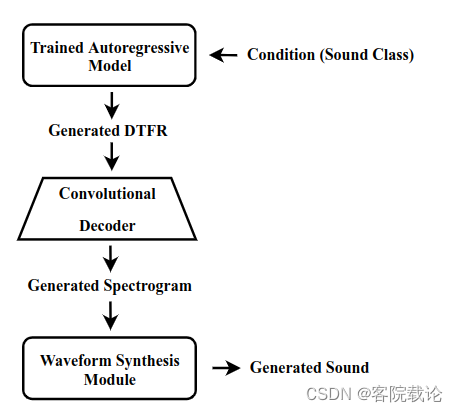
- 这个图是生成声音的流程
补充
个人感想
- 这个东西是真的难,之前一直是做图像的,第一次接触音频信号的处理,很多基础概念都不懂,但是还是要去深究。这段就停了一周,花时间去学了一些声音处理。
Approach
- 2.1节说的是 训练一个VQ-VAE模型去学习声音的DTFR
- 2.2节说的是用上一节训练的VQ-VAE提取的DTFR,生成要求的类别的声音。
2.1 Discrete time-frequency
- VQ-VAE模型是用来将频谱图转换为DTFR的,这个DTFR很小,这个模型是由编码器、解码器和码本构成。模型的输入是固定的,编码器将频谱图非线性映射成一个潜在特征空间 z z z,具体的公式如下图。其中H,W,D是对应高度,宽度和深度。其中m是压缩因子。

- 然后将特征空间中的每一个元素进行量化,基于该元素和码本中的码的距离进行量化。然后将潜在特征空间,进行压缩为一个维度为c的向量。 然后将这个离散的特征表示放进解码器进行重建。重建的频谱图由下列公式给出

- 为了学习等式2的重建过程,梯度是从解码器的输入传递到编码器的输出,损失函数定义如下

- 这个东西有三段
- 第一部分是重建损失,解码器的重建损失和原始输入的差别
- 第二部分是用来将码本和编码器的输出进行对齐
- 最后一个是贡献损失,用来减少编码器输出和码本之间的不确定性
省流总结
- 这里使用的是VQ-VAE进行频谱图的特征学习,流程了自动编码器学习的方式很相似,不过是将中间的特征空间进行了量化。但是这个量化的过程我不是很懂
- 需要学习一下VQ-VAE的生成方式,参考文献是链接
2.1.1 Multi-scale convolutional scheme in the encoder
- 传统的VQ-VAE使用的是固定核大小的,这样能够获取频谱图中的局部特征,但是不能利用时间跨度比较长的帧之间的依赖。为了能够有效获取局部特征和长依赖,我们在VQ-VAE中的自动编码器中提出了使用多尺度卷积模式。在这个模式中,我么你使用了卷积核大小不同的多尺度卷积层。这个多尺度卷积的方法已经被证明能够有效获取时频域中的全局特征和局部特征。
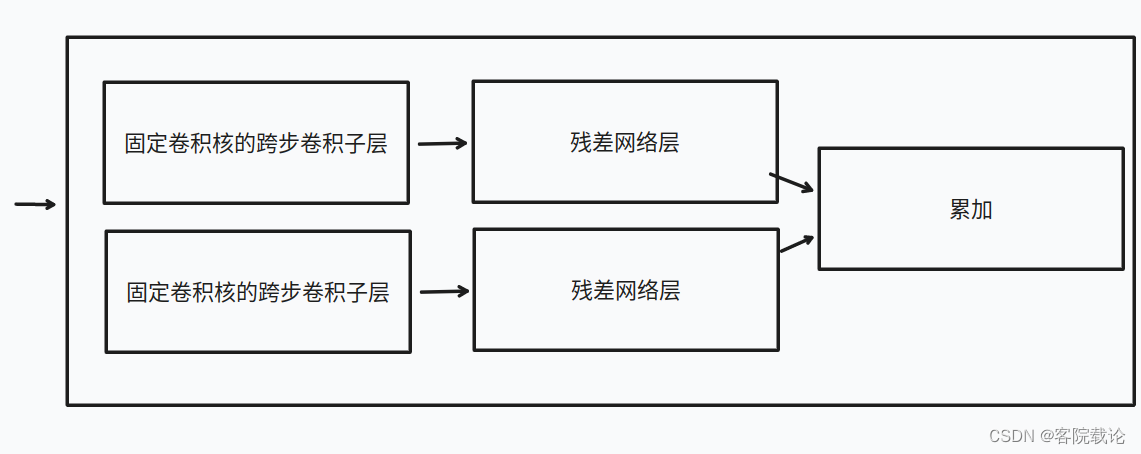
- 更准确地描述为,编码器是由多个步长不同的卷积层并行构成的。每一个多步长的卷积层拥有多个连续子层,每一个子层的卷积核是固定的,并且步长是逐渐递增的。卷积核比较小的可变步长卷积模块用来获取时间相邻的帧的局部特征,卷积核比较大的可变长卷积模块用来获取时间跨度不较长的帧的依赖关系。然后可变步长的卷积模块的输出全部都加到一块,作为编码器的输出,借此使得编码器能够获取不同的尺度下的全局特征和局部特征。
several strided convolutional layers(SCLs)的具体构成
- 不同尺度的子卷积层提取不同的特征,然后进行累加,获得最终的输出
2.1.2 Model architecture
- 使用全卷积层对DTFR进行解码,以重建频谱图。解码器的结构和编码器相似,但是没有编码器中的多尺度卷积模式。我们提出的学习声音的DTFR的结构如下图,具体细节将在3.3节进行讨论
2.2 Conditional sound generation
- 学习了声音的DTFR,根据类别生成声音的任务可以转为生成声音的DTFR,。因为DTFR是一个压缩并且是紧凑的表示,在获取声音的局部特征和长依赖的同时,消耗的计算资源很少。在2.1.2节训练的VQ-VAE的解码器是用来将生成的DTFR映射为生成的频谱图,DTFR生成的过程,具体描述如下
- 使用码字 c k c_k ck的索引表示任何DTFR的第n个部分,我们首先将DTFR表示为一系列索引
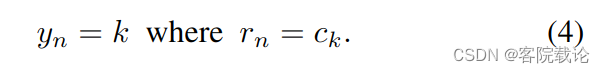
- 然后,我们使用自回归模型通过将联合分布分解为条件的乘积来构建声音 DTFR 上的分布 p(y)
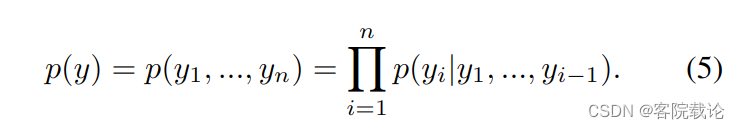
- 为了根据类表标签生成对应的声音,我们使用独热编码作为全局变量。
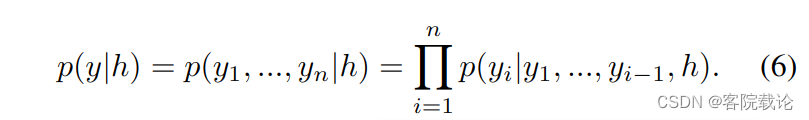
- 我们使用PixelSNAIL模型去创建 p ( y ∣ h ) p(y|h) p(y∣h),PixelSNAIL是改良过的自回归模型,这个模型能够将带有自注意力机制的因果卷积进行组合。训练了VQ-VAE之后,我们使用他的编码器去计算声音的DTFR。然后在DTFR上根据标签,训练PxelSNAIL。新的 DTFR 的生成是通过从经过训练的自回归模型之一对以所有先前变量为条件的变量进行采样来实现的。使用HiFi-GAN波形图合成模块,将频谱图转成波形图。在推理阶段的生成的管道流程图在图1右侧有展示
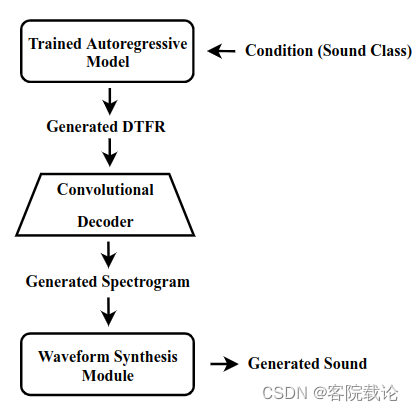
省流总结
- 这里的思路是这样的,先训练一个编码解码器,然后在将编码器生成的DTFR,用来训练PixelSNAIL,用来生成新的DELF,然后在通过解码器将之还原成频谱图。在经过HiFi-GAN,将频谱图还原成对应的波形图,转成声音进行输出,
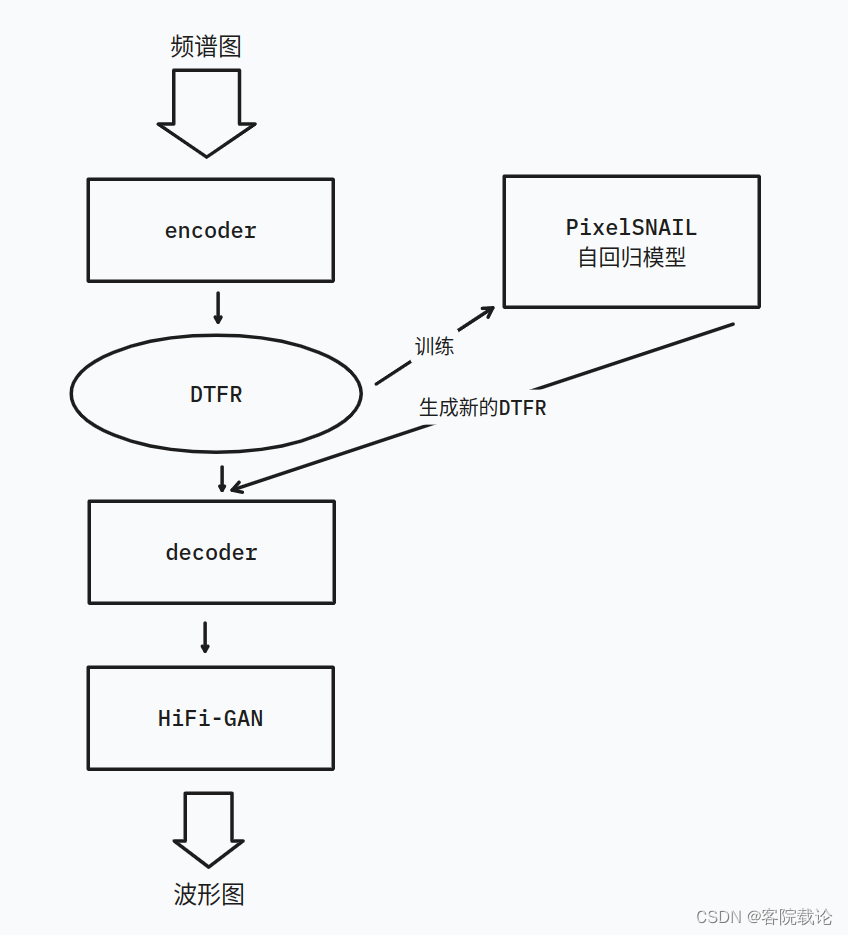
- 因果卷积,链接
Experiments
3.1 Dataset
- 我们在数据集UrbanSound8K上,测试我们提出的方法的效果。这个数据集由8732个带有标签的城市中的生活音构成,总共有10个类别。每一段声音的持续时间少于四秒钟。数据集中不同类别的声音差别很大,而且每一段声音的片段都分为前景音和背景音。因此,这个数据集完全能够衡量模型获取不同类别声音的显著特征的能力。将7916个音频用于训练,将816个声音用于测试。因为我们的方法需要保证输入音频的长度固定,所以我们将呻吟补全到4秒钟,并且将所有声音片段转换到16位,下采样到22,050kHz
3.2 Spectrogram compution
-
为了生成高质量的声音,我们使用HiFi-GAN中的使用的超参数去计算频谱图,这可以实现高保真的频谱图,更加描述将在3.3.3节。更加精确的是,我们使用一个80个维度的log梅尔频谱图,这个频谱图使用帧长为1024,步长为256的短时傅立叶变换以及一个汉明窗计算的。通过将动态范围压缩裁剪为1 × 10−5的最小值,然后应用对数变换,将动态范围压缩应用于梅尔谱图。所以,四秒钟的声音片段将会生成80x344的梅尔频谱图。
-
具体流程如下,这里面很多操作我并不懂,先总结着。
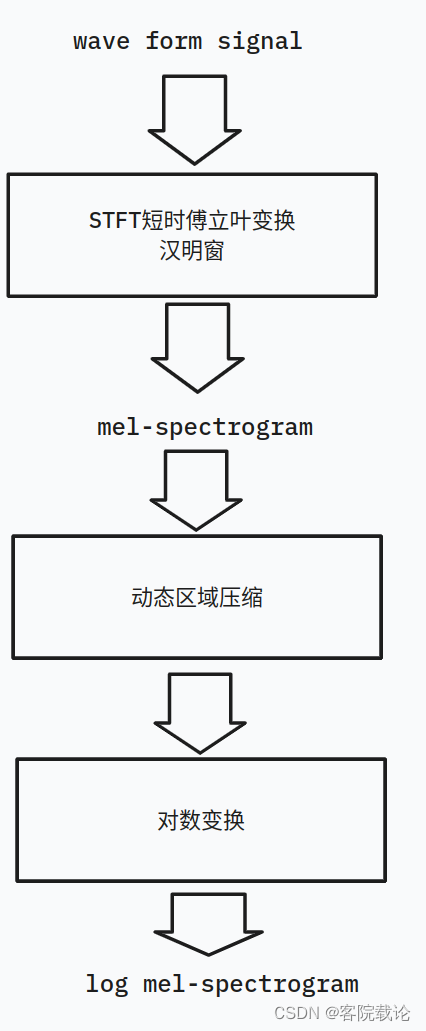
问题
- 梅尔频谱图是啥
- 汉明窗是啥
- 动态压缩
- HiFi-GAN如何实现转换
3.3 Details of model implementation
3.3.1 VQ-VAE
- 对于VQ_VAE中的编码器,我们使用可变步长的卷积模块构成,这个卷积模块是由两个步长为2的子层构成,并且后续接了一个33的残差模块。卷积核大大小分别是22,44,66,和88。除此之外,我们对于输入的80344的梅尔频谱图降采样为2086,压缩因子为2。码本的维度是512,码字的维度是64。解码器是由33的残差模块构成,然后是两个反卷积层,步长为2,核的大小为4*4。使用Adam优化其,学习率为0.0003,batch_size为64,迭代70,000次
3.3.2 Autoregression model
- PixelSNAIL模型是在20*86的DTFR上进行训练的,优化器是Adam,学习率是0.0003,batchsize是32,迭代250,000次。使用pytorch去实现
3.3.3 Waveform synthesis module
- 使用HiFi-GAN,将生成的梅尔频谱图转为波形图,这样整个系统合成的结果高保真,并且推理快速。我们在训练集上训练HiFi-GAN,用的代码是github上的,链接
3.4 Baseline system
- SampleRNN已经用于声音身成,在我们的研究中,我们将使用两层条件的SampleRNN作为对比的基础模型,基础模型直接在波形图上进行训练350,000次,使用Adam优化器,学习率是0,0003,batchsize是64.SmapleRNN的参考链接
3.5 Evaluation methods
- 关于音频生成模型,要测试模型的性能,有很多参数。但是,一般来说,对声音进行主观评价,是一件耗时的工作,并且结果很难复现。在这篇文章中,我们将生成声音的质量和差异度作为两个客观性能参数,来衡量模型的性能
3.5.1 Generation quality
- 作者是使用训练集,训练了一个VGG11的分类模型,生成声音的质量越高,模型分类的越准确,质量越差,分类的效果越差。虽然并不能直观地表示生成声音的感知质量,但是还是能够局部衡量声音的质量。VGG11的分类器是使用训练集生成的频谱图作为训练数据。
3.5.2 Generation diversity
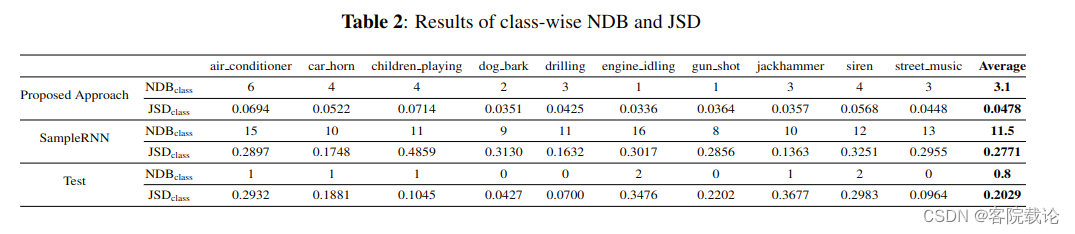
- 不同的bin的数量(NDB)是衡量生成模型的常见参数。这个训练参数首先是将训练集聚类,分到不同的bins,然后将每一个生成的声音分到最近的bin。NDB 报告为训练实例数量与双样本二项式检验生成的实例数量在统计上不同的 bin 数量。此外,如果样本数量,则训练数据分布与聚类箱上生成的数据之间的 Jensen-Shannon 散度 (JSD) 计算为评估指标足够大。较小的 NDB 和 JSD 代表更好的性能。我们采用 K-means 算法对 T-F 域中的声音数据进行聚类(如第 3.2 节所述)。然后,我们分别在类情况和全类情况(将所有类的生成的数据合并在一起并与训练数据进行比较)中计算生成的声音的 NDB 和 JSD。20 个 bin 用于类聚类,200 个 bin 用于全类聚类。我们使用 NDB 和 JSD5 的官方实现
3.6 Evaluation results
- 我们使用我们提出的方法和基础模型,每一个类别都还生成1024段声音。测试结果如下
3.6.1 Generation quality
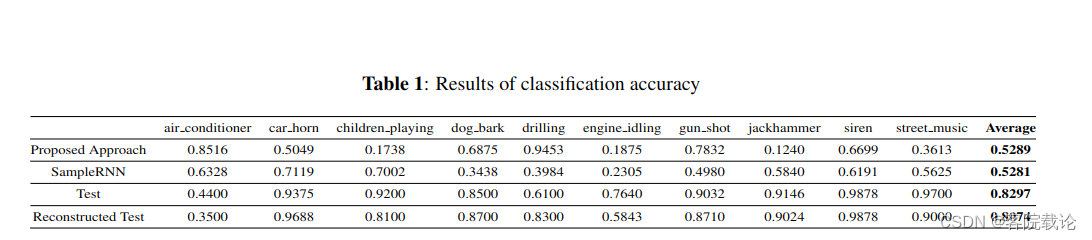
- 表 1 显示了我们提出的方法(Proposed Method)、基线生成的数据(SampleRNN)、测试数据(Test)和基于 DTFR(重建测试)重建后测试数据的 VGG11 分类精度分别为 52.89%、52.81%、82.97%、80.74%。分别基于 DTFR(重建测试)重建后的测试数据。与 SampleRNN 相比,我们提出的方法在生成质量方面取得了可比的性能。狗吠和枪手等声音类表现更好,而诸如jackhammer 和孩子们等声音类表现更差。此外,虽然 DTFR 比频谱图小四倍,但重建后测试数据的分类准确度仅下降了 2.23 个百分点,这证实了 DTFR 的有效性。
3.6.2 Generation diversity
- 生成多样性的类级和全类评估结果分别如表 2 和表 3 所示。我们提出的方法在所有声音类的 NDB 和 JSD 中显着优于 SampleRNN 基线,这意味着我们的方法生成的数据具有更大的多样性,并且其分布更接近真实数据。测试数据的 JSD 高于我们提出的方法生成的数据,因为测试数据的大小很小,类分布与训练数据不同。
3.7 Ablation study
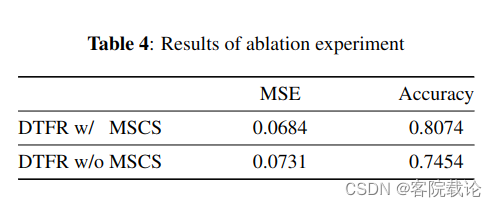
- 我们研究了多尺度卷积方案 (MSCS) 在 VQ-VAE 编码器中的影响。表 4 显示了基于有和没有 MSCS 的 DTFR 的重建测试数据的均方误差 (MSE) 和 VGG11 分类精度。实验结果表明,通过应用MSCS,MSE降低了0.0047,VGG11分类精度提高了6.2个百分点,这表明MSCS捕获了声音中更多的声学信息(即局部细粒度结构)
Conclution
- 本文提出的根据特定类别生成声音的方法是有效,这个方法使用的是神经离散时频域表示学习。该方法能够同时提取时间跨度很长的特征和局部細颗粒的特征。实验结果表明,比起SampleRNN,我们的方法在声音的多样性和声音的质量上效果更好,在未来,我们会尝试使用对抗学习和感知损失函数来学习特征表示,然后将之和基于GAN网络的生成模型进行对比
阅读总结
-
文章看是看完了,但是有太多的问题了,很多东西都不会,但是稍微理一下,还是有头绪的。
-
这篇文章主要分为三个部分
- 第一部分是VQ-VAE,这部分我是会VAE,但是并不知道如何进行矢量量化
- 参考文献,链接
- 第二部分是音频预处理,我不是很懂梅尔图,相关的基础原理并不是很懂,不过可以直接看他的代码,加到我的模型里
- 这部分没有参考文献,只能自己去学一下了
- 第三部分是自回归模型PixelSNAIL,这部分是用来生成对应的新的DTFR的,不像我们原来是随机采样,这里可以了解一下
- 参考文献,链接
- 第一部分是VQ-VAE,这部分我是会VAE,但是并不知道如何进行矢量量化
-
所以,我下一步的行动是这样的,
- 首先,看一下她图片预处理的代码,能不能应用到我们的模型中,学一下大概的基本的原理。
- 然后,需要再去看一下VQ-VAE模型的实现过程,相当于我当前的VAE模型的升级版,最好能在我当前的代码上进行修改
- 接着,学习一下PixelSNAIL,这种训练过,并且生成新的特征的毕竟要比原来随机采样的要好
- 最后,就是学习一下HiFi-GAN生成网络模型,毕竟mel图并不能直接转成对应的波形图。
-
这可能是一个漫长的过程,不过并不是感觉完全没有方向,因为我觉得有一个好的入门了,并且有自己的研究路线可以继续往下走了,而且未来有自己的方向。不像视觉那一块,没啥方向。
-
后续关于这门课的论文,我也会按照这个系列的学习顺序,完全写下来。具体如下
- 音频处理的基础知识
- 自动编码器的弊端
- 变分自动编码器的弊端
- 矢量化自动编码器的优势
- 主要就是这篇文章的内容了
-
后续,我会将这篇论文放到我的博客上,需要的可以直接下载。
-
下面我将会重点研究,VQ-VAE的具体实现。