事务ID
pg中每个事务都会分配事务ID,事务ID分为虚拟事务ID和持久化事务ID(transactionID)。pg的事务ID非常重要,是理解事务、数据可见性、事务ID回卷等等的重要知识点。
虚拟事务ID
只读事务不会分配事务ID,事务ID是很宝贵的资源,比如简单的select语句不会申请事务ID。本身不需要把事务ID持久化到磁盘,但是为了在共享锁等情况下对事务进行标识,需要一种非持久化的事务ID,这个就是虚拟事务ID(vxid)
VXID由两部分组成:backendID 和backend本地计数器。
源码:src/include/storage/lock.h
typedef struct
{
BackendId backendId; /* backendId from PGPROC */
LocalTransactionId localTransactionId; /* lxid from PGPROC */
} VirtualTransactionId;
(PGPROC是一种存储进程信息的结构体,后面会介绍)
pg_locks可以看到vxid,查询pg_locks本身就是一个sql,会产生vxid
lzldb=# begin;
BEGIN
lzldb=*# select locktype,virtualxid,virtualtransaction,mode from pg_locks;
locktype | virtualxid | virtualtransaction | mode
------------+------------+--------------------+-----------------
relation | | 4/16 | AccessShareLock
virtualxid | 4/16 | 4/16 | ExclusiveLock
(2 rows)
lzldb=*# savepoint p1;
SAVEPOINT
lzldb=*# select locktype,virtualxid,virtualtransaction,mode from pg_locks;
locktype | virtualxid | virtualtransaction | mode
------------+------------+--------------------+-----------------
relation | | 4/16 | AccessShareLock
virtualxid | 4/16 | 4/16 | ExclusiveLock
lzldb=*# rollback;
ROLLBACK
lzldb=# select locktype,virtualxid,virtualtransaction,mode from pg_locks;
locktype | virtualxid | virtualtransaction | mode
------------+------------+--------------------+-----------------
relation | | 4/17 | AccessShareLock
virtualxid | 4/17 | 4/17 | ExclusiveLock
此时\q退出会话再立即登录,计数仍然继续4/19
另开一个窗口,backendID+1
lzldb=# select locktype,virtualxid,virtualtransaction,mode from pg_locks;
locktype | virtualxid | virtualtransaction | mode
------------+------------+--------------------+-----------------
relation | | 5/3 | AccessShareLock
virtualxid | 5/3 | 5/3 | ExclusiveLock
从以上测试能看出:
- VXID的backendID不是真正的进程号PID,也只是一个简单的递增的编号
- VXID的bakendID和命令编号都是递增的
- 子事务没有自己的VXID,他们用父事务的VXID
- VXID也有回卷,不过问题不严重,因为没有持久化,实例重启后VXID从头开始计数
永久事务ID
当发生数据变化的事务开始时,事务管理器会为事务分配一个唯一标识TransactionId。txid是32位无符号整型,总共可以存储
232=4294967296,42亿多个事务。32位无符号整型能存储的数据范围为:0~2^32-1
3个特殊的事务ID
src/include/access/transam.h中宏定义几个事务ID
#define InvalidTransactionId ((TransactionId) 0)
#define BootstrapTransactionId ((TransactionId) 1)
#define FrozenTransactionId ((TransactionId) 2)
#define FirstNormalTransactionId ((TransactionId) 3)
#define MaxTransactionId ((TransactionId) 0xFFFFFFFF)
-
0 代表无效TransactionID
-
1 代表启动事务ID,只在初始化数据库时才会使用。比所有正常事务都旧
-
2 代表冻结事务ID。比所有正常事务都旧
#define TransactionIdIsNormal(xid) ((xid) >= FirstNormalTransactionId)
事务ID>=3时是正常事务id。
最大事务ID MaxTransactionId是0xFFFFFFFF=4294967295=2^32-1
所以正常事务id能分配到的范围为:3~2^32-1
事务ID分配
做几个小实验来看下事务id是怎么分配的。其中用到两个返回事务id的function
pg_current_xact_id ():返回当前事务id,如果当前事务还没有分配事务id,那么分配一个事务id。pg12及以前用txid_current ()
pg_current_xact_id_if_assigned () :返回当前事务id,如果当前事务还没有分配事务id,那么返回NULL。pg12及以前用txid_current_if_assigned ()
事务id顺序分配
lzldb=# select pg_current_xact_id();
pg_current_xact_id
--------------------
612
lzldb=# select pg_current_xact_id();
pg_current_xact_id
--------------------
613
lzldb=# select pg_current_xact_id();
pg_current_xact_id
--------------------
614
begin不会立即分配事务id
lzldb=# begin; --显示开启事务
BEGIN
lzldb=*# select pg_current_xact_id_if_assigned () ; --begin不会立即分配事务id
pg_current_xact_id_if_assigned
--------------------------------
(1 row)
lzldb=*# select * from lzl1; --begin后立即查询
a
---
(0 rows)
lzldb=*# select pg_current_xact_id_if_assigned () ; --查询不会分配事务id
pg_current_xact_id_if_assigned
--------------------------------
(1 row)
lzldb=*# insert into lzl1 values(1); --插入数据,做一个数据变更
INSERT 0 1
lzldb=*# select pg_current_xact_id_if_assigned () ; --begin后的第一个非查询语句分配事务id
pg_current_xact_id_if_assigned
--------------------------------
611
lzldb=*# commit;
COMMIT
lzldb=# select xmin, pg_current_xact_id_if_assigned () from lzl1; --insert事务写入到xmin
xmin | pg_current_xact_id_if_assigned
------+--------------------------------
611
系统表中的有些记录,在数据库初始化时分配了BootstrapTransactionId=1
postgres=# select xmin,count(*) from pg_class where xmin=1 group by xmin;
xmin | count
------+-------
1 | 184
以上实验得出以下结论
- 数据库初始化时分配特殊事务id 1,可以在系统表中看到
- 事务id是递增分配的
- begin不会立即分配事务id,begin后的第一个非查询语句分配事务id
- 当一个事务插入了一tuple后,会将事务的txid写入这个tuple的xmin。
事务ID对比
pg事务新旧通过事务ID来对比。在src/backend/access/transam/transam.c定义了4种事务ID对比函数,分别是<,<=,>,>=
bool TransactionIdPrecedes()
bool TransactionIdPrecedesOrEquals()
bool TransactionIdFollows()
bool TransactionIdFollowsOrEquals()
内容都差不多,拿TransactionIdPrecedes()代表来看
bool
TransactionIdPrecedes(TransactionId id1, TransactionId id2)
{
/*
* If either ID is a permanent XID then we can just do unsigned
* comparison. If both are normal, do a modulo-2^32 comparison.
*/
int32 diff;
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 < id2);
diff = (int32) (id1 - id2);
return (diff < 0);
}
该段源码的知识点
TransactionIdIsNormal()是已经在header中宏定义了的判断正常事务的函数,FirstNormalTransactionId是常量3。也就是说正常事务ID是>=3的
#define TransactionIdIsNormal(xid) ((xid) >= FirstNormalTransactionId)
- int32是有符号的整型,第一位0表示正数,第一位-1表示负数,取值范围-2*31~2^31-1
- 数值溢出,意思数值超过数据存储范围,比如2^31对于int32是刚好数值溢出的。为了保证数据在范围内,对数值加减模长
对比事务ID源码分为2段理解
非正常事务ID对比:
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 < id2);
当id1=2,id2=100时,return(2<100),precede为真,正常事务较新
当id1=100,id2=2时,return (100<2),precede为假,正常事务较新
所以,txid为1、2时比正常事务要旧
正常事务ID对比:
diff = (int32) (id1 - id2);
return (diff < 0);
id1-id2可以是负数,所以diff不能是unsign int,转换有符号型的int。然后最关键的来了
由于int32是-2*31~2^31-1,
当id1=231+99,id2=100,id1-id2=2^31-1。这没问题,int32刚好可以存放 =>大txid较新
当id1=231+100,id2=100,id1-id2=231。这有问题,刚好超出int32存储范围,此时的值为231-232=-2^31<0 =>小txid较新
当id1=100,id2=231+100,id1-id2=-2^31。这没问题,int32刚好可以存放 =>大txid较新
当id1=100,id2=231+101,id1-id2=-231-1。这有问题,刚好超出int32存储范围,此时的值为-231-1+232=2^31-1>0 =>小txid较新
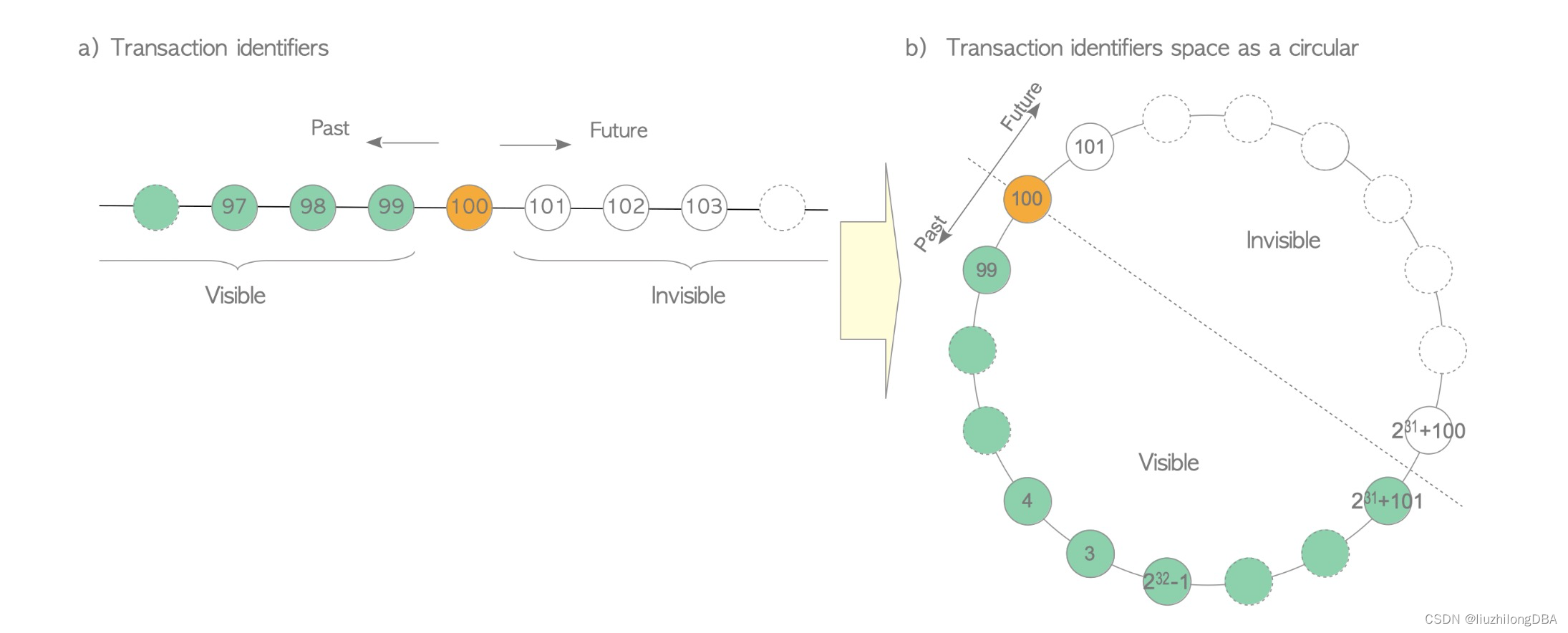
以上分析可以看出,当发生数值溢出时,txid大的事务看不见更小的txid事务,本身数值溢出是一个异常事件,这无可厚非。为了解决这个问题,pg将40亿事务id分成两半,一半事务是可见的,另一半事务是不可见的。
比如,txid 100的事务,它过去的20亿事务是它可见的,它未来的20亿事务是它不可见的。所以,在pg数据库中最大事务和最小事务(数据库年龄)之差最大为|-231|=2^31,20亿左右
事务ID回卷
什么是事务ID回卷?
理解事务ID回卷本身不难,但是刚开始了解回卷时,发现了事务ID回卷有两种定义:
pg官方定义:
由于事务ID的大小有限(32位),一个长时间运行的集群(超过40亿个事务)将遭受事务ID的缠绕:XID计数器回卷到零,突然之间,过去的事务似乎在未来,这意味着它们变得不可见。简而言之,就是灾难性的数据丢失。(事实上,数据仍然存在,但如果你无法获得数据。)
interdb解释:
元组中t_xmin记录了当前元组的最小事务,如果这个元组一直没有变化,这个t_xmin不会变。假如一个元组tuple_1由txid=100事务创建,它的t_xmin=100。如果数据库事务向前推进了231个,到了231+100,此时tuple_1是可见的。此时再启动一个事务,txid推进至2^31+101,txid=100的事务属于未来,tuple_1是不可见的,此时便发生了严重的数据丢失问题,这就是事务回卷。
是的,对事物回卷的定义,官方文档与有些经典文章不太一样,不过他俩的行为是不冲突的。但是如果重新思考“回卷”(wraparound)的含义。其实它俩都发生了回卷。
不过回卷形势还是有些区别:前者是事务ID(232)全部用完,回卷到0重新计数;后者是把事务ID分成两半,“最老的事务ID“与”最新的事务ID“只差大于2^31。两者都会发生数据可见性的异常。
42亿的事务ID用完,这个问题比较严重,是个炸弹,目前没有比较好的办法解决。
21亿的事务ID差,有解决办法,也就是事务冻结机制。
42亿事务到底要跑多久?
42亿个事务看上去是挺多,但是仍然可能用完。
比如一个tps为100的pg库(不算select语句,因为单纯的select不会分配事务id),1天会使用8640000个事务,只需要历时4294967296/8640000≈497天就可以把42亿个事务id耗尽发生事务回卷;如果每秒1000个事务,不到两个月时间就可以把42亿事务用完。所以事务回卷问题是pg数据库中必须要关注的。
事务id冻结
为了解决事务回卷引起严重的数据丢失问题,pg引入事务冻结的概念。
之前介绍了冻结事务id FrozenTransactionIdn=2,并且比所有正常事务都旧。也就是说txid=2对于所有正常事务(txid>=3)都是可见的。当t_xmin比当前txid-vacuum_freeze_min_age(默认5000w)更旧时,该元组将重写为冻结事务id 2。在9.4及以后的版本,用t_infomask中的xmin_frozen来表示冻结元组,而不是重写t_xmin为2。
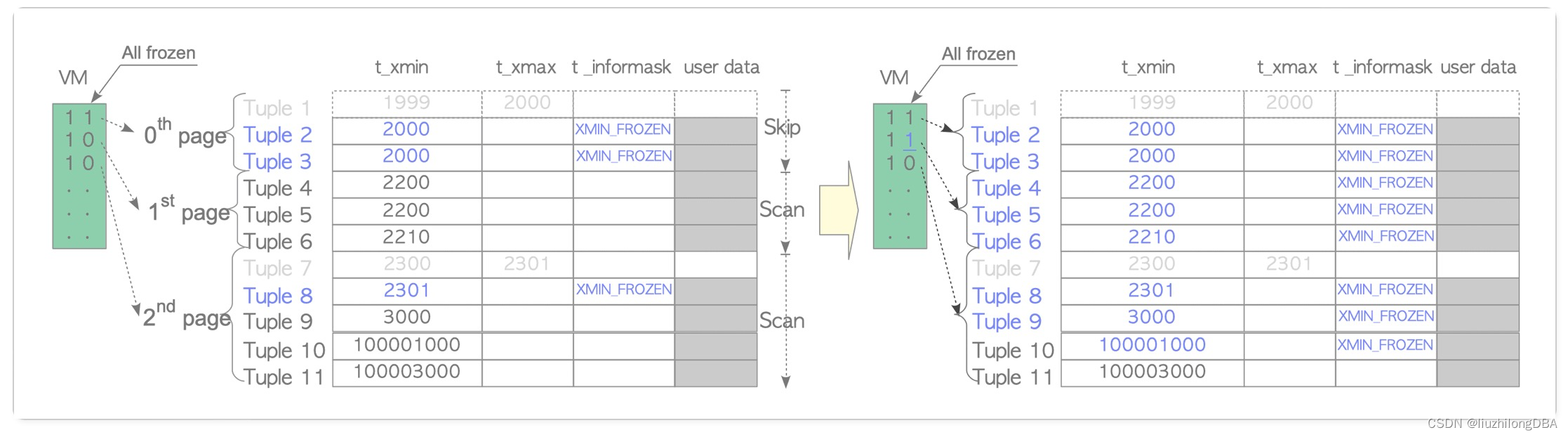
事务ID回卷问题有许多优化方案,不过都绕不过事务冻结处理回卷问题,而事务冻结这个操作,会有非常大的IO消耗以及cpu消耗(所有表的所有行读一遍,重置标记)无从避免回卷,甚至数据库会拒绝所有操作,直至冻结操作结束,这也是俗称的“冻结炸弹”。业务系统越繁忙,事务越多的库,越容易触发。
64位的事务id
事务id耗尽回卷问题终极解决方案就是使用64位的事务ID。32位事务id有232个,64位事务id有2^64个。即使每秒10000个事务,每天864000000个事务,也要5849万年才能把事务id消耗光。如果拥有64位事务id,事务id几乎是取之不尽用之不竭,就不需要考虑事务id回卷问题,也不需要事务冻结操作,也就没有“冻结炸弹”的概念…
为什么还没有实现64位事务id?
xmin,xmax可以简单理解为插入事务和删除事务的事务id,保存在每个元组的header中(元组结构章节将介绍该部分内容),而header空间是有限的。32位事务id有8个字节,64为事务有16个字节,存储xmin、xmax两个事务id将需要额外的16字节空间,目前header无法保存这么大的数据。社区讨论过两种实现方案
1.扩展header。直接将64位事务id存储进去
2.header大小不变。内存中保留64为事务id,增加epoch概念来位移转换两者的关系。
第一种方案已基本放弃,对比其他系统,pg的tuple header已经够大了。
第二种方案还在路上。
其实源码中已经有64位FullTransactionId的定义(pg12及以后)
/*
*一个64位值,包含一个epoch和一个TransactionId。它被封装在一个结构中,以防止隐式转换为TransactionId。
*并非所有值都表示有效的正常XID。
*/
typedef struct FullTransactionId
{
uint64 value;
} FullTransactionId;
不过这完全实现没有那么容易,参考社区邮件
https://www.postgresql.org/message-id/CAEYLb_UfC+HZ4RAP7XuoFZr+2_ktQmS9xqcQgE-rNf5UCqEt5A@mail.gmail.com
https://www.postgresql.org/message-id/flat/DA1E65A4-7C5A-461D-B211-2AD5F9A6F2FD%40gmail.com
2014年社区就提出了64为xid永久解决freeze问题,并于2017年开始讨论如何实践64位事务id,不过经过了多个pg版本也只是只闻其声不见其人。由于数据库对于数据的敏感性和重要性,而事务id的改造对于数据库来说牵扯的东西太多,稍微不注意可能导致数据丢失或者触发未知bug,64位事务id改造的问题pg走的很谨慎。不过社区还是在考虑这个问题,期待有一天在某个pg版本中事务id回卷问题彻底解决。
事务id参考
《Postgresql指南 内幕探索》
https://www.interdb.jp/pg/pgsql05.html
https://www.interdb.jp/pg/pgsql06.html
https://www.modb.pro/db/427012
https://www.postgresql.org/docs/13/routine-vacuuming.html
https://blog.csdn.net/weixin_30916255/article/details/112365965
https://wiki.postgresql.org/wiki/FullTransactionId
http://mysql.taobao.org/monthly/2019/08/01/
https://github.com/digoal/blog/blob/master/201605/20160520_01.md