4.程序的机器级表示
4.1(🏫 CMU补充 )x86-64 Linux 寄存器使用
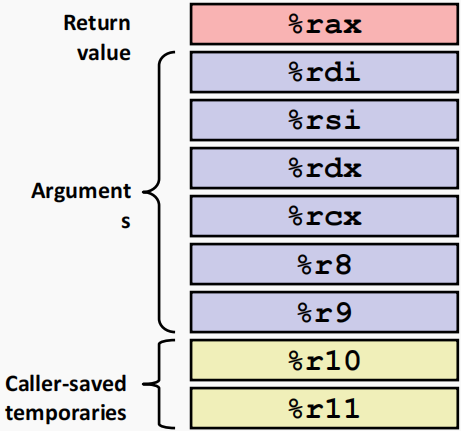
%rax- 返回值
- 调用函数保存
- 可以通过程序修改
rdi,…,%r9- 传入参数(arguments)
- 调用函数保存
- 可通过程序进行修改
%r10,%r11- 调用函数保存
- 可通过程序进行修改
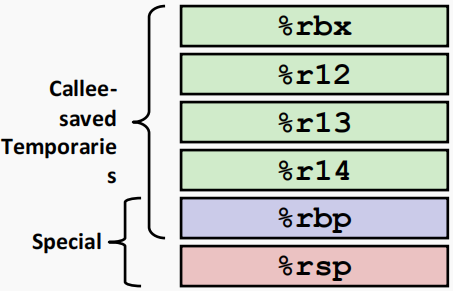
%rbx,%r12,%r13,%r14- 被调用函数保存
- 可通过程序进行修改
%rbp- 被调用函数保存
- 被调用函数必须保存和恢复
- 可能被用作栈帧的指针
rsp- 被被调用函数以一种特殊形式保存
- 在退出过程时恢复到原始值
4.2传送指令
4.2.1mov 指令
-
一般传送(
mov)-

实现等宽的两个数据之间的传送,源数据和目的数据都是n位。
-
-
零扩展传送(
movz)-

把源数据当作是无符号整数,用于实现无符号整数的数据传送。
源数据复制到目的空间中的低n位部分,在高位部分补充0。
-
-
符号扩展传送(
movs)-

把源数据看成是带符号整数,用于实现带符号整数的数据传送。
源数据复制到目的空间的低 n 位部分;高位补充源数据的最高有效位,即源数据的符号位。
-
-
指定宽度传送(
movswl、movzwl)b、w、l:表示数据传送的宽度;b表示8位,w表示16位,l表示32位,q表示 64位。-
例1:
movswl -0x16(%ebp), %eax**说明:**源数据是16位,目的数据是32位,要做符号扩展。
表示含义:将 -0x16(%ebp) 地址开始的16位存储器内容符号扩展到32位后,送到寄存器eax中。
-
例2:
movzwl -0x1 6(%ebp), %eax**说明:**源数据是16位,目的数据是32位,要做零扩展。
**表示含义:**将 -0x16(%ebp) 地址开始的16位存储器内容零扩展到32位以后,送入寄存器eax中。
-
mov 指令示例代码
主要是写汇编指令对代码实现以下语句:

y = x:等宽传送
q = x:符号扩展传送
z = p:截断,低16位保存
- 示例代码
#include <stdio.h>
void main()
{
short x = 0x8543,y = 1,z = 2;
int p = 0x12345678,q = 3;
asm( // -> 代表赋给,根据实际编译情况修改
"movzwl -0xe(%rbp),%eax\n\t" // x -> eax(零扩展)
"mov %ax,-0xc(%rbp)\n\t" // ax -> y
"movswl -0xe(%rbp),%eax\n\t" // x -> eax(符号扩展)
"mov %eax,-0x4(%rbp)\n\t" // (符号扩展后的)x -> q
"mov -0x8(%rbp),%eax\n\t"// p -> eax
"mov %ax,-0xa(%rbp)\n\t" //ax -> z
);
printf("x=%d,y=%d,z=%d\n",x,y,z);
printf("p=%d,q=%d\n",p,q);
return;
}
-
调试
-
查看栈帧范围
(gdb) i r rsp rbp rsp 0x7ffffffeddd0 0x7ffffffeddd0 rbp 0x7ffffffedde0 0x7ffffffedde0 -
运行到 6 行
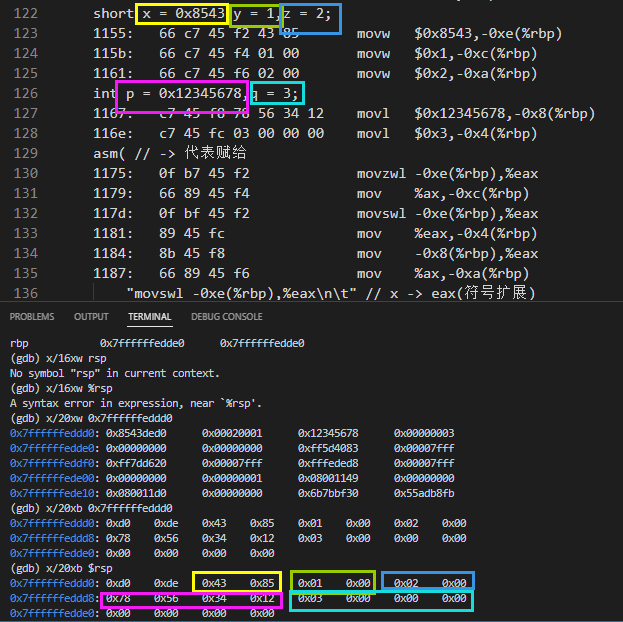
-
剩下的就是分析赋值以后对应寄存器和栈帧中值的变化。
-
mov 与 lea
lea:Load Effect Address,加载有效地址。
lea指令:地址传送指令。寻址方式计算出来的地址 -> 寄存器
mov指令:

( 🏫 CMU补充 )为什么要用 LEA?
-
CPU设计者的预期用途:计算一个指向一个对象的指针
-
例如,只将一个数组元素传递给另一个函数

-
-
编译器的作者喜欢用它来进行普通的算术
-
它可以在一条指令中进行复杂的计算
-
这是x86仅有的三个操作数指令之一

-
mov 与 lea 示例程序
以视频为例:

汇编前两句:
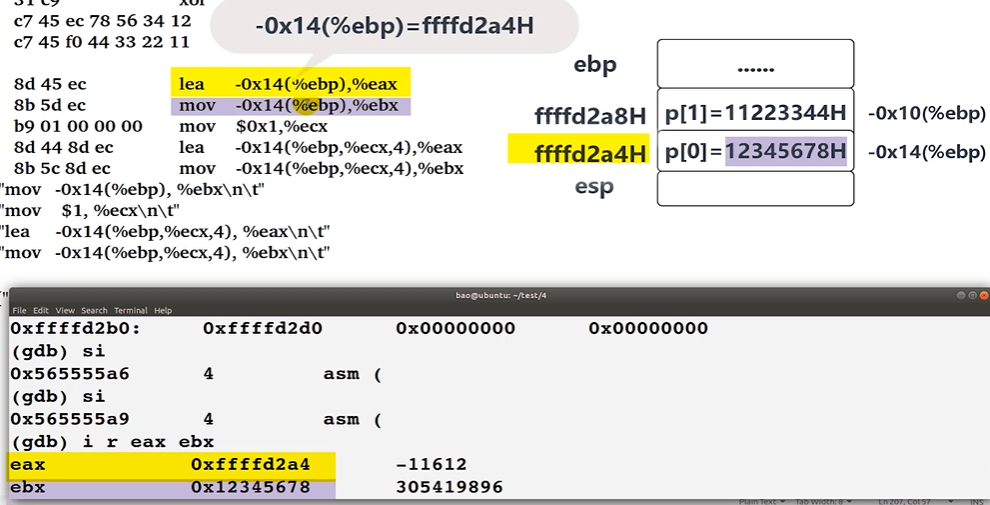
汇编最后两句:
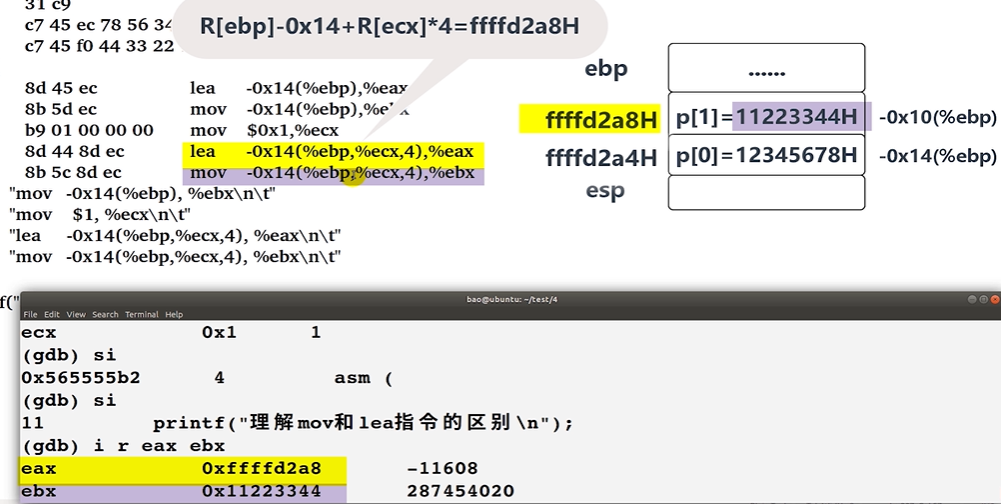
C语言中的整数之间赋值运算实现
-
情况一:
n = m编译器直接用
mov指令,将X的机器数赋值给Y。 -
情况二:
n < mX定义为无符号整数,编译器用movz指令,将X的机器数传送给Y。 -
情况三:
n < mX定义为带符号整数,则编译器用movs指令,将X的机器数传送给Y。 -
情况四:
n > m仅将
X的低m位传送给Y。




C语言中的整数之间赋值运算实现示例代码
#include <stdio.h>
void main()
{
int ix = -0x25432,iy,iz;
short sx;
unsigned uix,uiy,uiz;
unsigned short usx;
uix = ix;
sx = ix;
usx = ix;
iy = usx;
uiy = usx;
iz = sx;
uiz = sx;
printf("整数赋值运算的机器级表示\n");
printf("ix = %d\n", ix);
printf("uix = %u\n",uix);
printf("sx = %d\n",sx);
printf("usx = %u\n",usx);
printf("iy = %d\n",iy);
printf("uiy = %u\n",uiy);
printf("iz = %d\n",iz);
printf("uiz = %u\n",uiz);
return;
}
- 反编译后调试
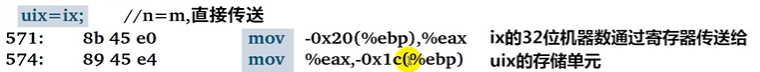
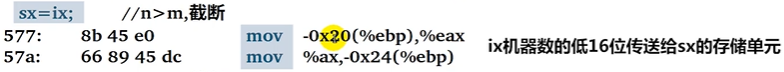
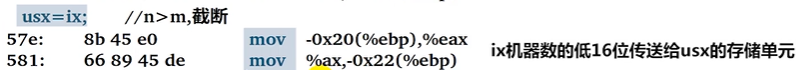


( 🏫 CMU补充 )关于各类寻址方式
-
简单内存寻址模式
(R)⟺ \iff ⟺Mem[Reg[R]]- 类似 C 中的指针引用取值
- 寄存器
R表示内存地址 - 例如:
movq (%rcx),%rax就是将rcx的地址内容赋值给rax
D(R)⟺ \iff ⟺Mem[Reg[R]+D]- 寄存器
R指定内存区域的开始位置 - 常量位移
D指定偏移量 - 例如:
movq 8(%rbp),%rdx就是将rbp的地址+ 8 的内容赋值给rax
-
完整的内存寻址模式
D(Rb,Ri,S)⟺ \iff ⟺Mem[Reg[Rb]+S*Reg[Ri]+D]-
D: 常数偏移量。1、2或4个字节 -
Rb:基址寄存器(Base register):16个整数寄存器中的任何一个 -
Ri:索引寄存器:任何,%rsp除外 -
S: 倍数。1,2,4 或者8(为啥这些数? 😕 ) -
一些具体案例:

-
一些形象的举例:
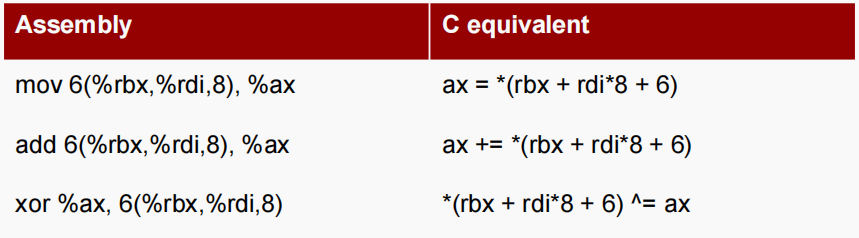
-
加减运算指令
对于带符号整数
说明:数据被定义为带符号整数,后续指令可以根据 OF 状态标志位来判断结果是否溢出;
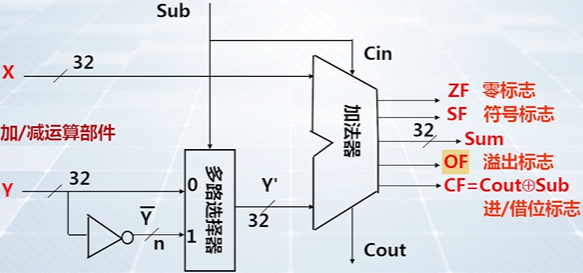
对于无符号整数
说明:数据被定义为无符号整数,后续指令可以根据 CF 状态标志位来判断结果是否有进位或借位。
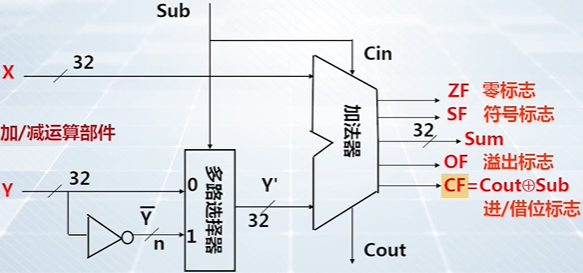
示例代码
#include<stdio.h>
int addition(int x,int y){
asm(
"mov -0x4(%rbp),%eax\n\t" //此处代码要参考 x 这个形参存放的地址
"add -0x8(%rbp),%eax\n\t"//此处代码要参考 y 这个形参存放的地址
); //函数默认返回 eax
}
int substraction(int x,int y){
asm(
"mov -0x4(%rbp),%eax\n\t"//此处代码要参考 x 这个形参存放的地址
"sub -0x8(%rbp),%eax\n\t"//此处代码要参考 y 这个形参存放的地址
);//函数默认返回 eax
}
void main()
{
int ix = 10,iy = 4,az,sz,z;
unsigned ux = 10,uy = 4,auz,suz,uz;
az = addition(ix,iy); auz = addition(ux,uy);
printf("%d + %d = %d,%u + %u = %u\n",ix,iy,az,ux,uy,auz);
az = substraction(ix,iy); auz = substraction(ux,uy);
printf("%d - %d = %d,%u - %u = %u\n",ix,iy,az,ux,uy,auz);
z = addition(2147483647,1);
printf("2147483647 + 1:%d, %u\n",z,z);
uz = substraction(3,4);
printf("3 - 4:%d,%u\n",uz,uz);
return;
}
-
运行结果
./addsum 10 + 4 = 14,10 + 4 = 14 10 - 4 = 6,10 - 4 = 6 2147483647 + 1:-2147483648, 2147483648 3 - 4:-1,4294967295 -
调试
- 对于
addition
执行到 24 行
z = addition(2147483647,1);以后,跳转到第 2 行addition,查看赋值到内存区域后,以下是两个加数。
执行完
asm里面的程序以后,查看返回的eax寄存器的值,以及eflags的情况
可以看到
OF为 1,说明如果是带符号数,则溢出了,结果有误。- 对于
substraction
执行到 26 行
uz = substraction(3,4);以后,跳转到第 9 行,查看赋值到内存区域后,以下是两个加数。
执行完
asm里面的程序以后,查看返回的eax寄存器的值,以及eflags的情况
可以看到
CF为 1,说明如果是无符号数,则溢出了,结果有误。 - 对于
cmp 比较指令
-
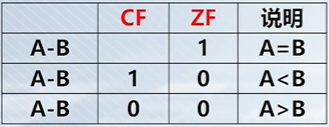
假设 A 和 B 是无符号整数:
-
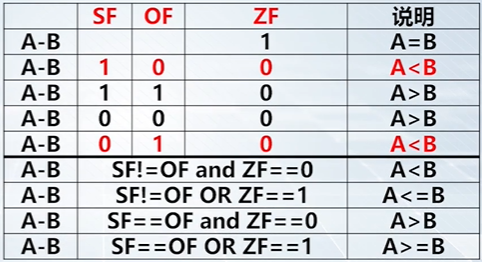
假设 A 和 B 是带符号整数:
-
示例程序

( 🏫 CMU补充 )判断条件码 eflags
-
基本的标志
CF进位标志:Carry Flag (for unsigned)SF符号标志:Sign Flag (for signed)ZF零标志:Zero FlagOF溢出标志:Overflow Flag (for signed)
-
标志位 置1的情况
-
ZF置 1
-
SF置 1
-
CF置 1
-
OF置 1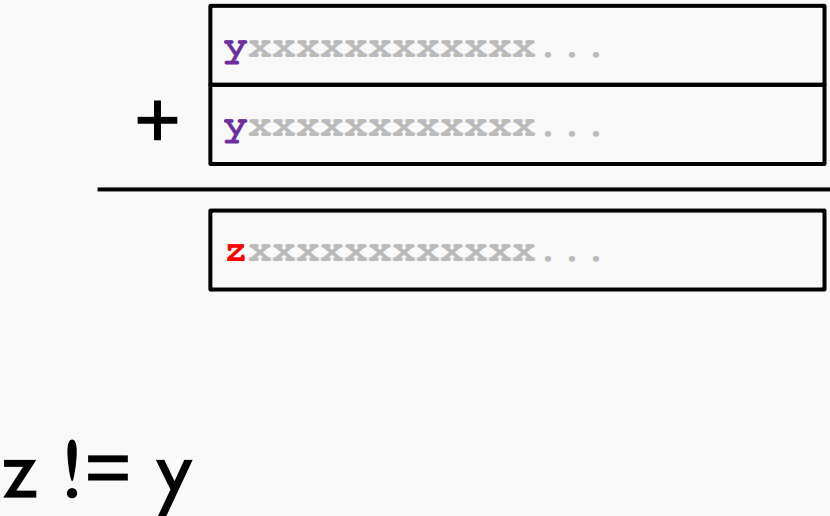
-
-
关于设置标志位
SetX Condition Description seteZFEqual / Zero setne~ZFNot Equal / Not Zero setsSFNegative setns~SFNonnegative setg~(SF^OF)&~ZFGreater (Signed) setge~(SF^OF)Greater or Equal (Signed) setl(SF^OF)Less (Signed) setle`(SF^OF) ZF` seta~CF&~ZFAbove (unsigned) setbCFBelow (unsigned)
( 🏫 CMU补充 )关于 test 指令
test a,b- 计算𝑏^𝑎(就像
and一样) - 根据结果设置条件代码(仅限
SF和ZF),但不改变b。
- 计算𝑏^𝑎(就像
- 最常见的用途:
test %rX, %rX——%rx和 0 比较 - 第二种最常见的用途:
test %rX, %rY—— 测试在%rY的任何一位在%rX中也是 1。(反之亦然)
整数乘法指令
C语言中整数乘法的实现
- 示例代码(
mulc.c)
#include<stdio.h>
void main()
{
int x = 3,y = 4,z1,z2,z3,z4;
unsigned ux = 3,uy = 4,uz;
z1 = x * y;
uz = ux * uy;
z2 = x * 3;
z3 = x * 1024;
z4 = x*x + 4 *x + 8;
printf("z1 = %d,z2 = %d,z3 = %d,z4 = %d\n",z1,z2,z3,z4);
return;
}
-
编译后反汇编分析
-
对于带符号数

M[R[ebp]-0x28]*R[eax]-> R[eax]实现两个 32 位整数的乘法运算,虽然乘法电路中产生的结果有 64 位,但指令仅保存低32位到寄存器eax中。 -
对于无符号整数

无符号整数的乘法运算用带符号的乘法指令imul实现的原因:仅取乘积的低 32 位作为结果保存给变量
uz;得到的uz的二进制序列,与运用mul指令时一致。 -
变量与常量乘法
-

整数的乘法运算在电路层中通过加法和移位的迭代运算实现,乘法指令的执行时间远远长于加指令的执行时间,所以遇到变量与常量的乘法运算时,编译器常常不用乘法指令,而是使用加法指令或移位指令实现。
-
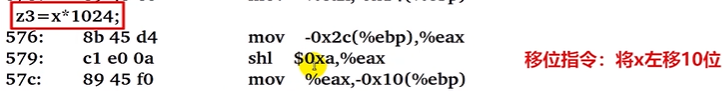
-
-
多项式(此处和视频教学情况有所不同,笔者是在 64 位
ubuntu上进行测试)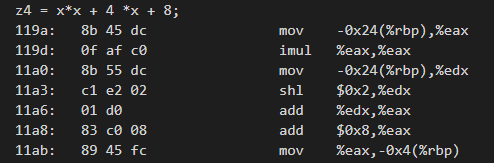
-
整数乘法指令(mul 与 imul)
- 示例代码(
mul2.c)
#include <stdio.h>
unsigned umul(unsigned x,unsigned y){
asm(
"mov -0x4(%rbp),%eax\n\t"//此处要换上具体编译的地址
"mov -0x8(%rbp),%ecx\n\t"//此处要换上具体编译的地址
"mul %ecx\n\t"
);
}
int imul(int x,int y){
asm(
"mov -0x4(%rbp),%eax\n\t" //此处要换上具体编译的地址
"mov -0x8(%rbp),%ecx\n\t"//此处要换上具体编译的地址
"mul %ecx\n\t"
);
}
void main()
{
int x = -1610612735, y = 8; //x=0xa0000001
unsigned ux = 2684354561, uy = 8; //ux=0xa0000001
int z;
z = imul(x, y);
printf("%d * %d = %xH = %d\n",x,y,z,z);
z = umul(ux, uy);
printf("%u * %u = %xH = %u\n",ux,uy,z,z);
return;
}
-
调试
-
在
imul中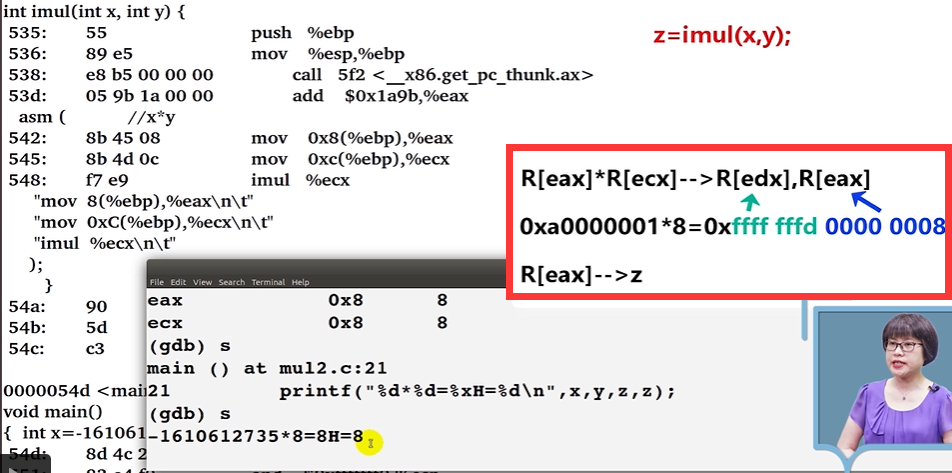
两个
32位的有符号数字相乘超出了32位(溢出了),但是输出结果只输出低32位。返回结果由eax存放 -
在
umul中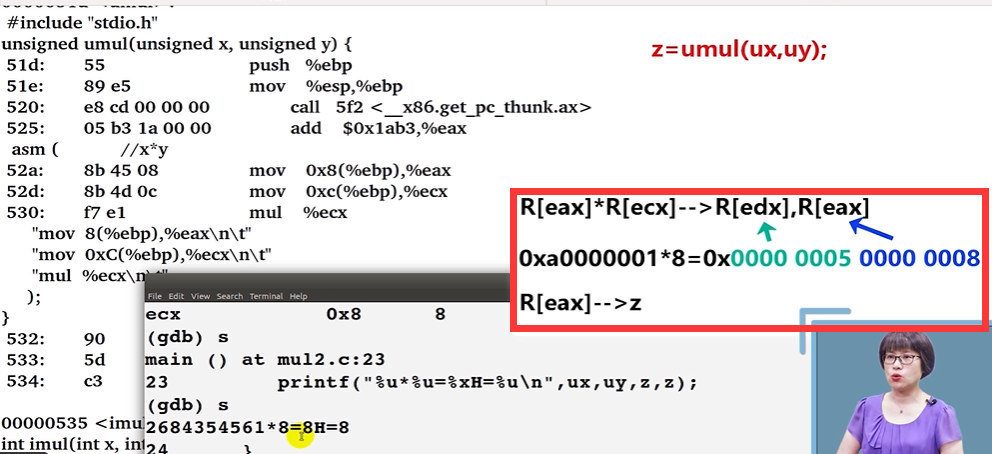
两个
32位的无符号数字相乘超出了32位(溢出了),但是输出结果只输出低32位。返回结果由eax存放。注意: 虽然输出结果与无符号数相同,因为二者的低
32位相同。但是高32位不同。
-
整数乘法的溢出问题
-
对于带符号整数

-
对于无符号整数

控制转移指令
指令执行顺序:
CS和EIP寄存器确定。EIP寄存器: 程序计数器
PC,用于存储下一条要执行的指令地址。(64 位系统是rip)指令执行转移: 修改
CS和EIP,或仅修改EIP。
转移指令的分类和功能
-
分类
-
**无条件转移指令
JMP**无条件转移到目标地址处执行
-
条件转移指令
一种分支转移的情况,以
eflgas寄存器中的状态标志位或状态标志位的逻辑运算结果为转移条件,如果满足转移条件,则转移到目标转移地址处执行,如果不满足转移条件,则顺序执行下一条指令。
-
-
指令类别
-
过程调用指令
CALL一种无条件转移指令,将控制转移到被调用的子程序执行。
-
过程返回指令
RET一种无条件转移指令,子程序的最后条指令,将控制从子程序返回到主程序继续执行。
-
中断指令
调用中断服务程序,使程序的执行从用户态转移到内核态。
-
相对转移地址的计算
目标转移地址=
R[PC]+ 偏移量 = 当前转移指令地址 + 转移指令字节数 + 偏移量
-
示例程序(
jmp.c)#include<stdio.h> int sum(int a[],int n) { int i,sum = 0; for(i = 0;i < n;i++) sum += a[i]; return sum; } void main() { int a[4] = {1,2,3,4},n=3,x; x = sum(a,n); printf("sum=%d\n",x); } -
编译
gcc -O0 -g -no-pie -fno-pic jmp.c -o jmp2-pie: 位置无关可执行程序-no-pie: 不采用位置无关可执行程序-pic: 位置无关代码,程序可以加载到虚拟空间的任意位置-fno-pic: 不采用位置无关的方式编译代码
关于 call
两个功能:
- call指令的返回地址入栈
- 目标转移地址送入
eip( 64 位系统是rip)

-
关于
call 8048466的计算(相对转移的偏移量)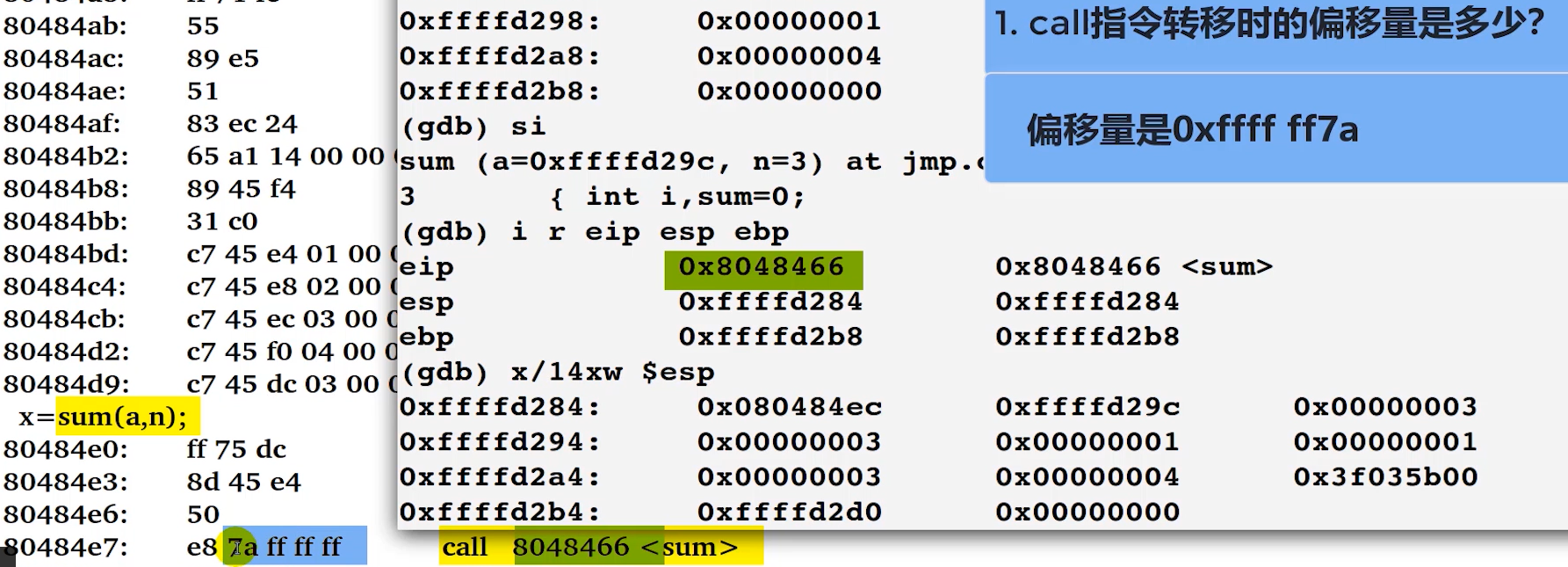
上图说明偏移量占 4 个字节,为
7a、ff、ff、ff。e8为 执行指令本身,也占了 1 个字节。说明执行这个操作占了 5 个字节。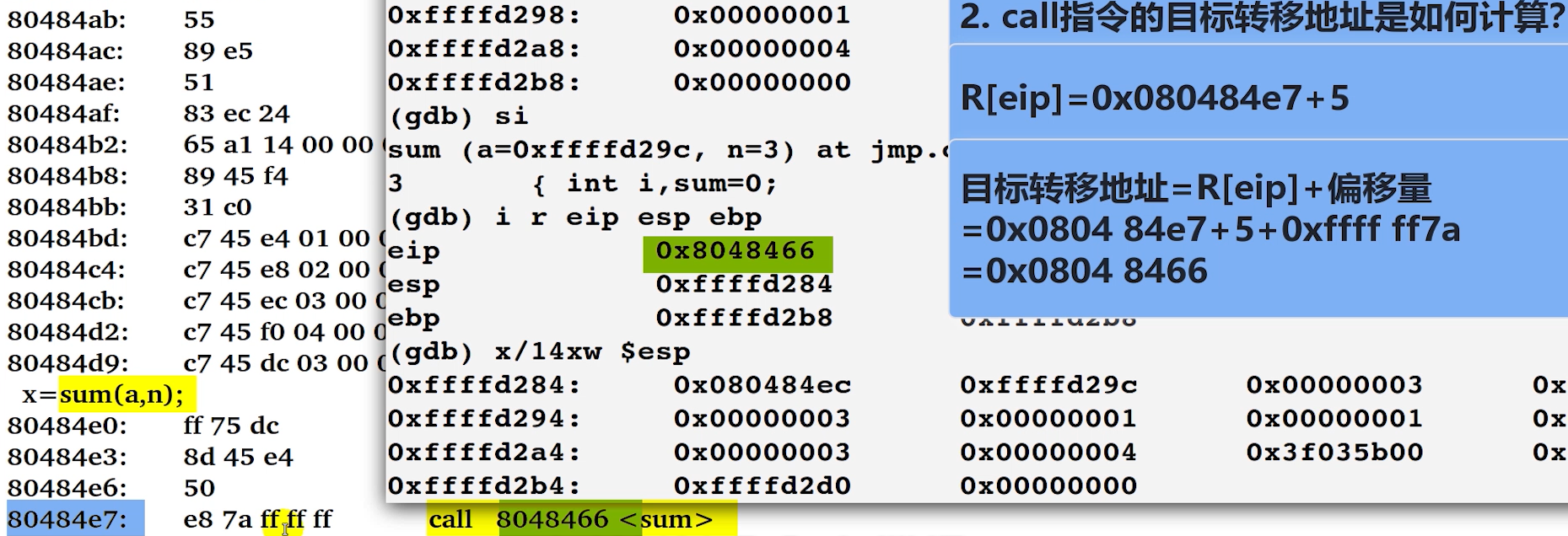
上图说明了
call 8048466的由来。
关于 jmp
jmp指令的功能:目标转移地址送入eip(64 位 系统为rip)
-
jmp指令的目标转移地址是如何计算 ?
关于 jl
jl指令的转移条件:SF!=OFandZF=0
jl指令的功能: 满足转移条件,将目标转移地址送入eip,否则继续执行后续指令(64 位 系统为rip)
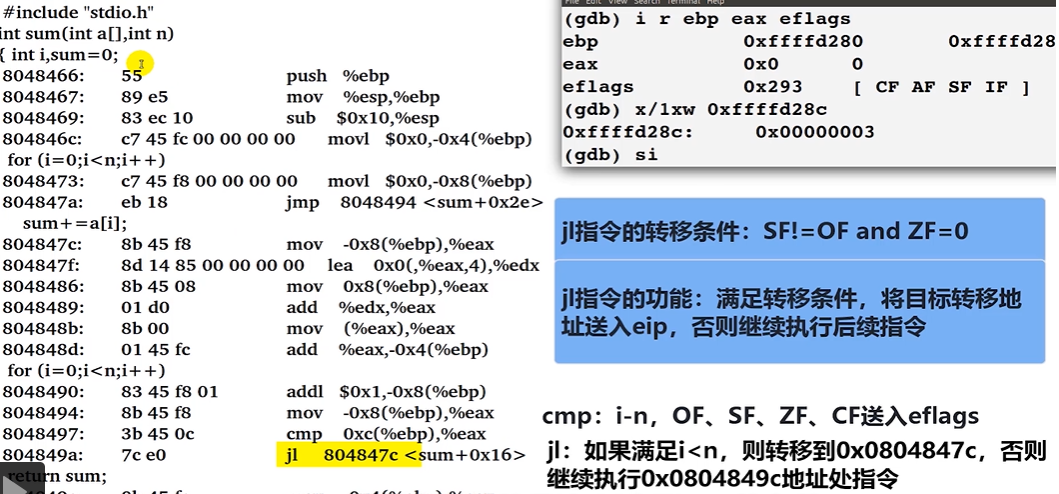
上图,
cmp对比的就是i与n,如果满足上述条件,则将804847c转移到rip寄存器中。
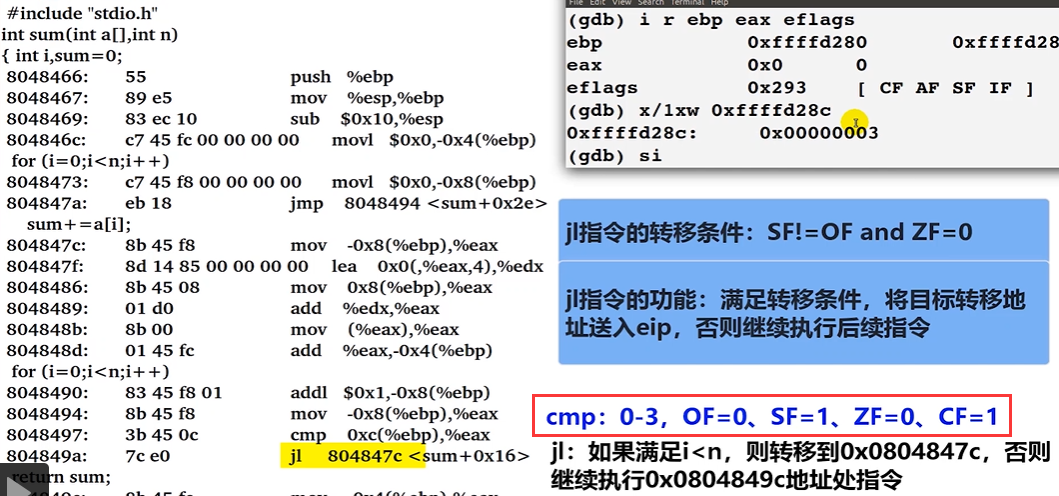
上图,当执行完
cmp语句以后,发现eflags提供的标志位满足条件
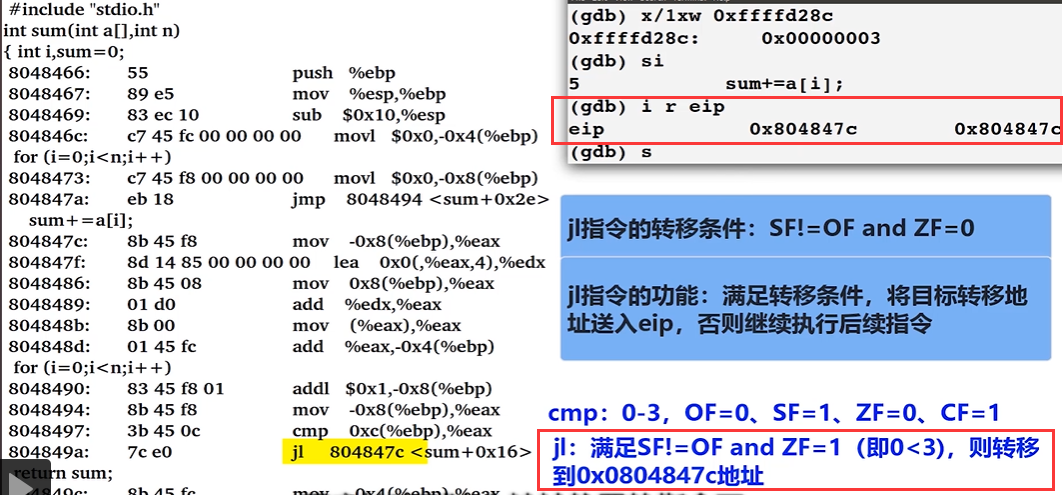
上图,完成以后,将
804847c这个地址转移到rip寄存器中。
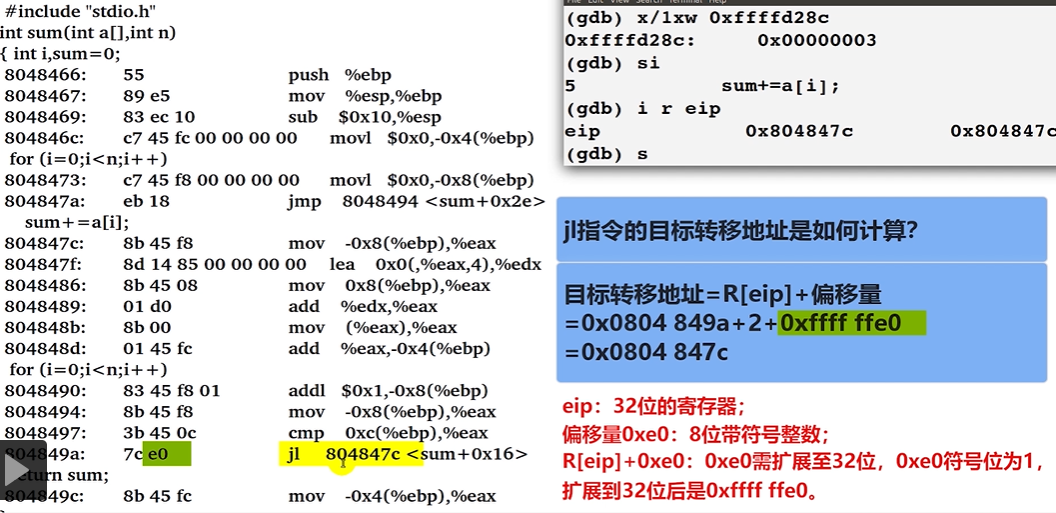
上图,说明了
084847c的计算方式
关于 ret
ret指令的功能 : 返回地址送入eip返回地址是call指令压入栈帧中的 (相当于pop,执行的是call调用之后的语句)
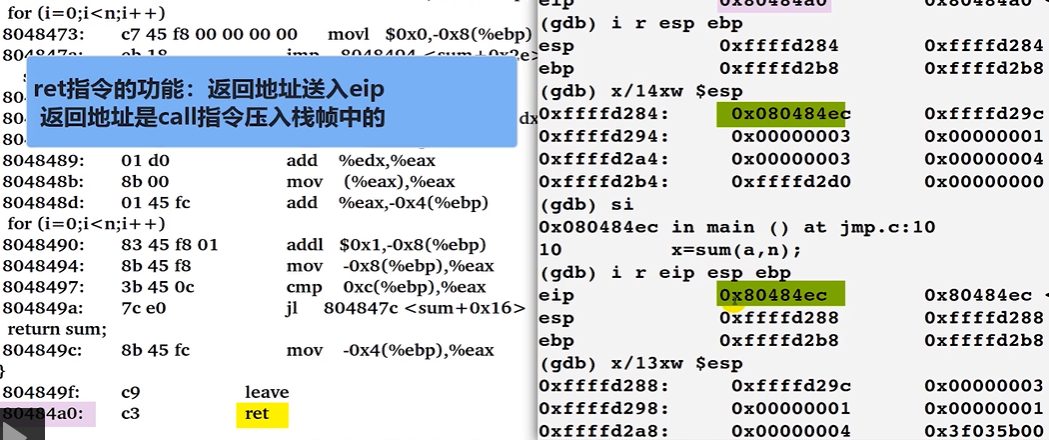
上图,注意观察
eip这个80484ec这个值是esp弹出的内容,这个值指向的是主函数调用call指令之后的语句。
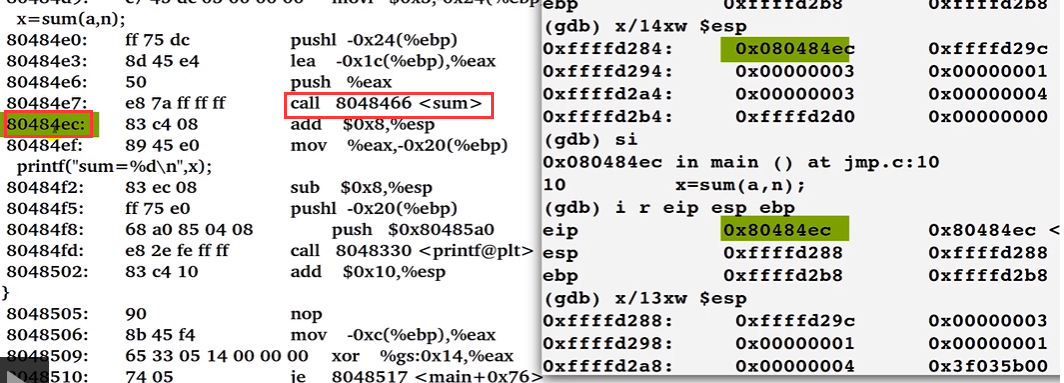
可以确认这个值指向的是主函数调用
call指令之后的语句。
栈和过程调用
总体调用关系以及寄存器使用

上图:P 是调用函数,Q 是被调用函数
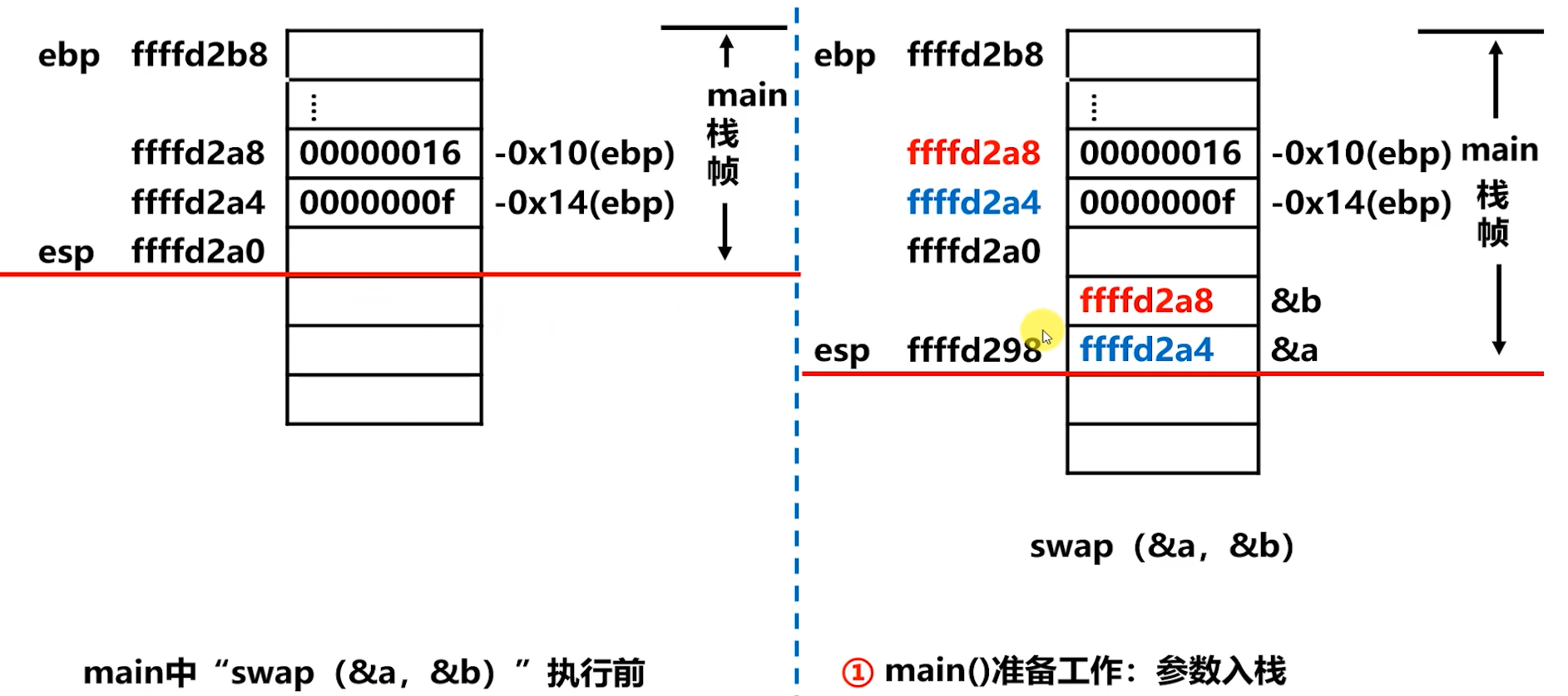
示例程序
#include <stdio.h>
int swap(int *x,int *y)
{
int t = *x;
*x = *y;
*y = t;
}
void main()
{
int a = 15,b = 22;
swap(&a,&b);
printf("a=%d\tb=%d\n",a,b);
}
step1️⃣:相关寄存器入栈
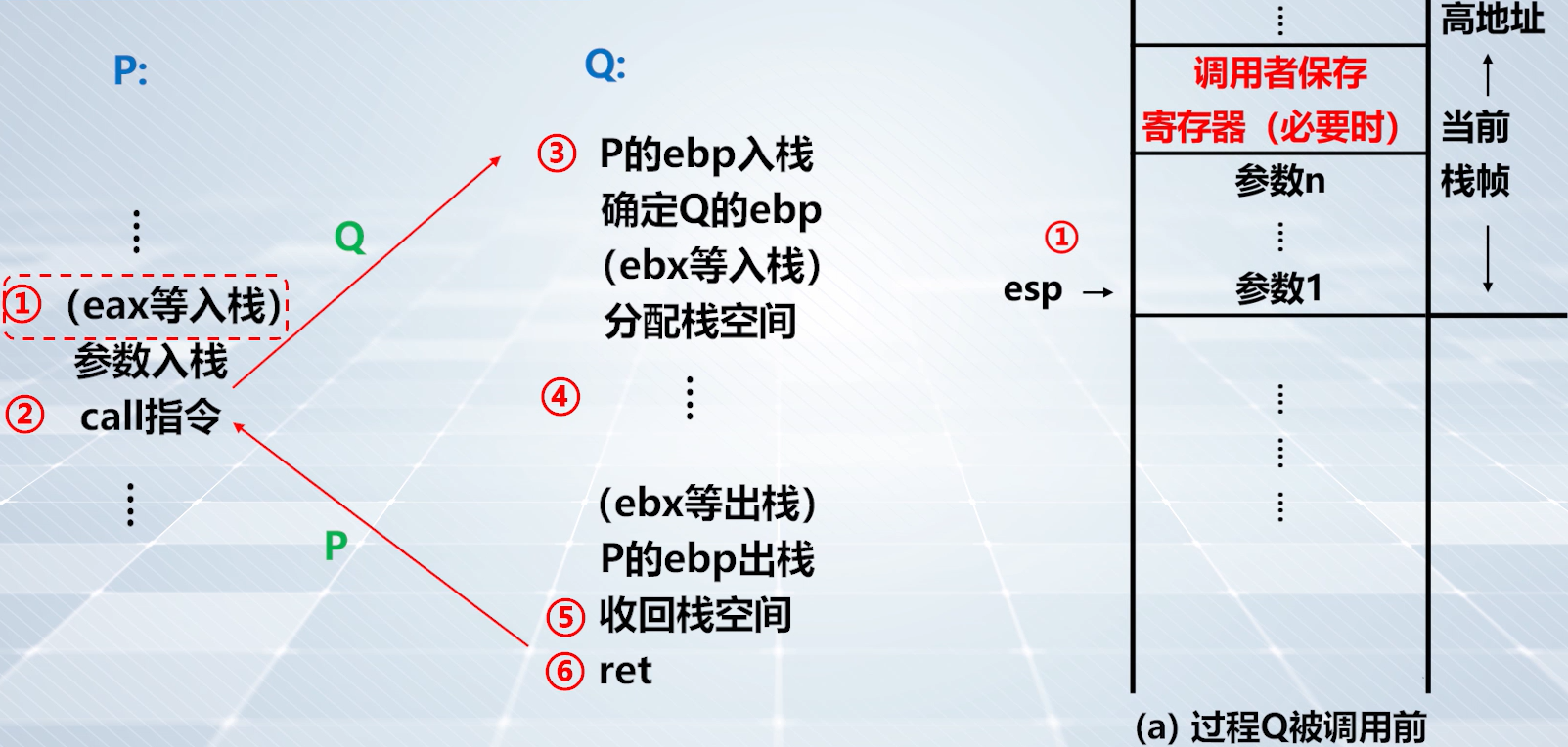
上图:
eax等 P 保存的寄存器入栈(如果这些寄存器被使用了)。
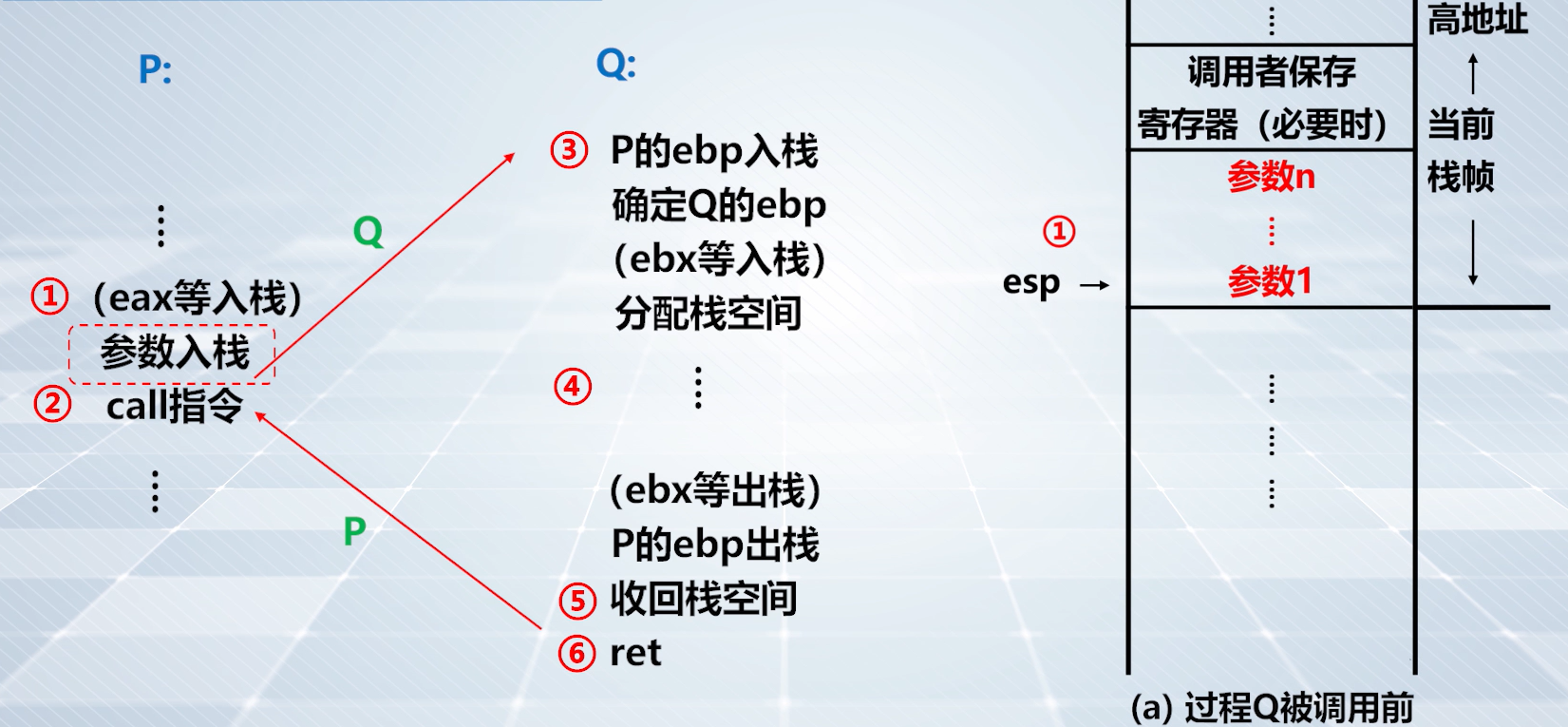
上图:P 把过程调用的参数值送入栈中。

上图,过程调用的准备工作,示例代码反汇编
上图,step1️⃣ 的栈帧情况
step2️⃣:call 指令
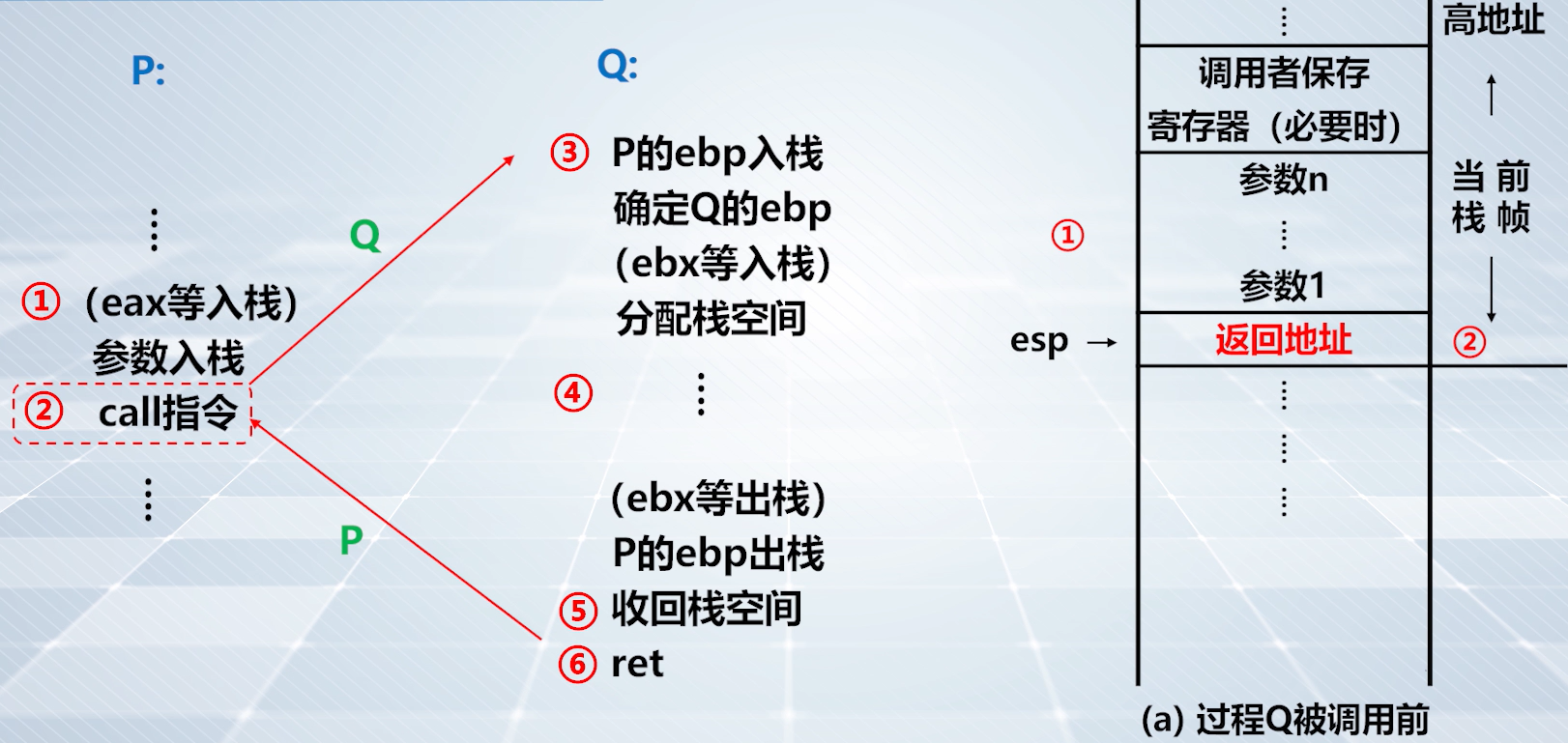
上图:
call指令将call指令的下一条指令(也就是返回地址)压入栈中。

上图,
call指令实现swap过程调用。示例代码反汇编
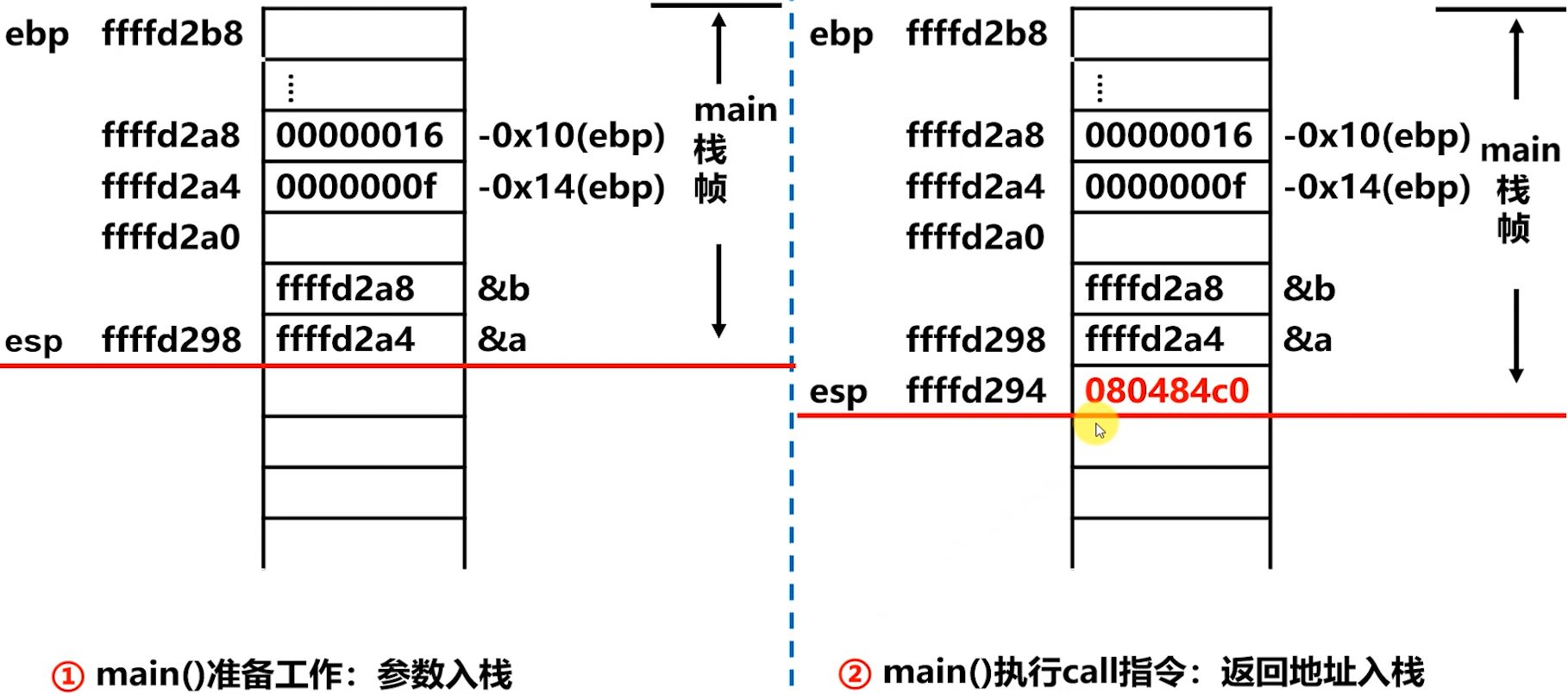
上图,step2️⃣ 的栈帧情况,
call指令执行后,将main函数返回地址入栈
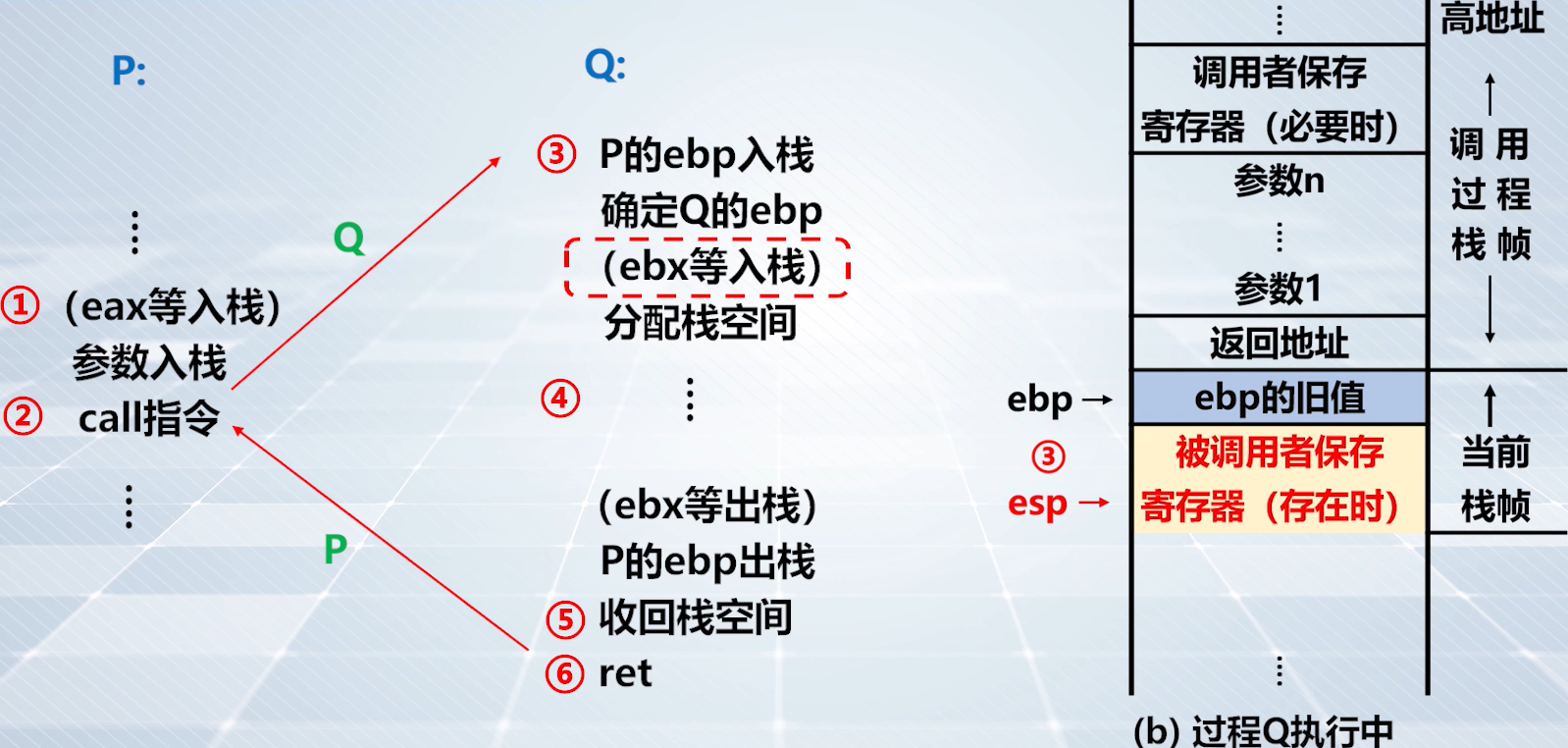
step3️⃣:设置被调用函数 Q 的寄存器
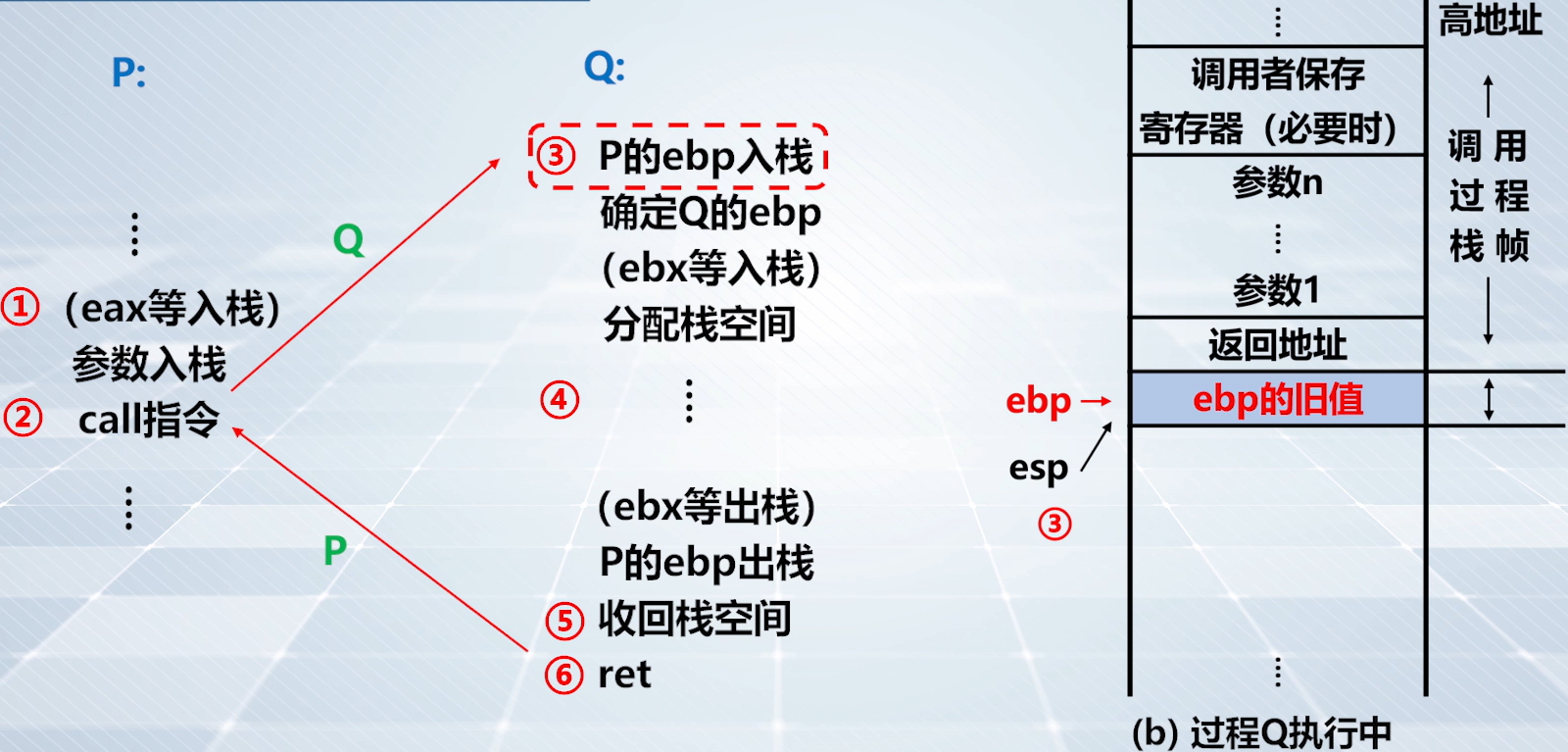
上图,建立 Q 的当前栈帧,将当前
ebp内容压入栈中。

上图,保存
edp。在示例代码反汇编中。
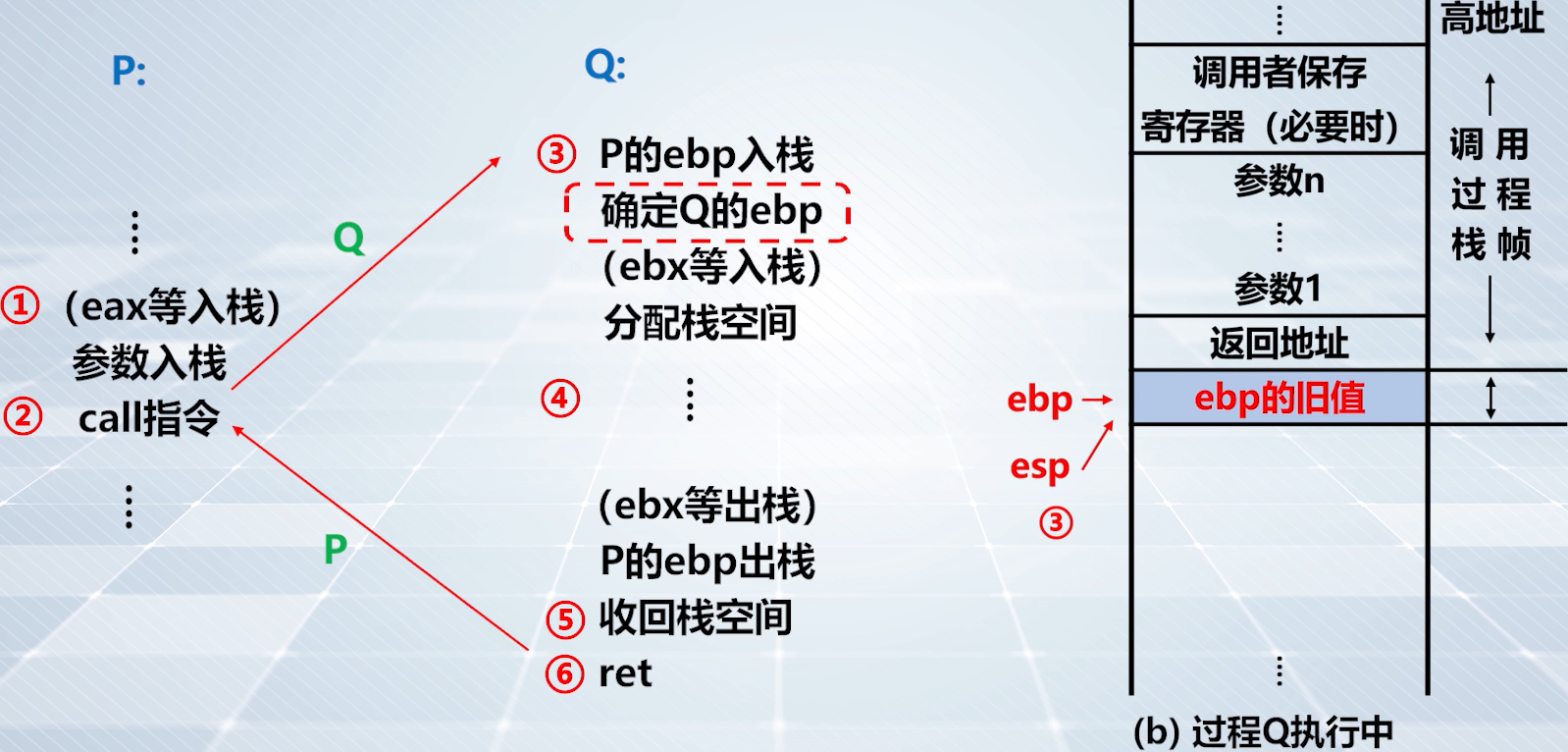
上图,将
esp寄存器内容传送给ebp。ebp与esp指向了统一地址单元,建立了 Q 的栈帧。

上图,建立自己的栈空间。示例代码反汇编。
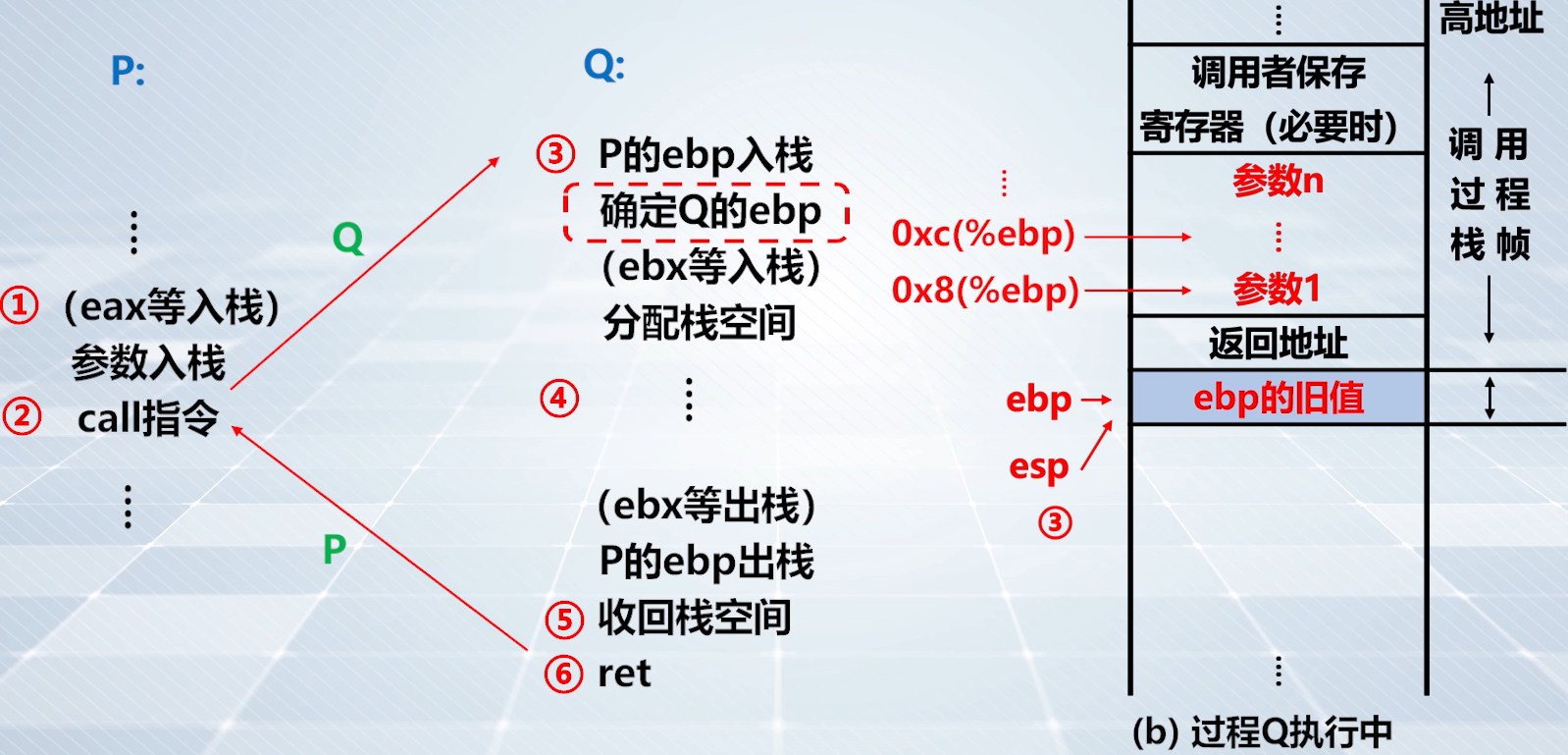
上图,要访问 P 传递的值,通过
0xc(%ebp)和0x8(%ebp)访问,就是访问实参
上图,
ebx等寄存器如果被 Q 使用,则压入栈中。
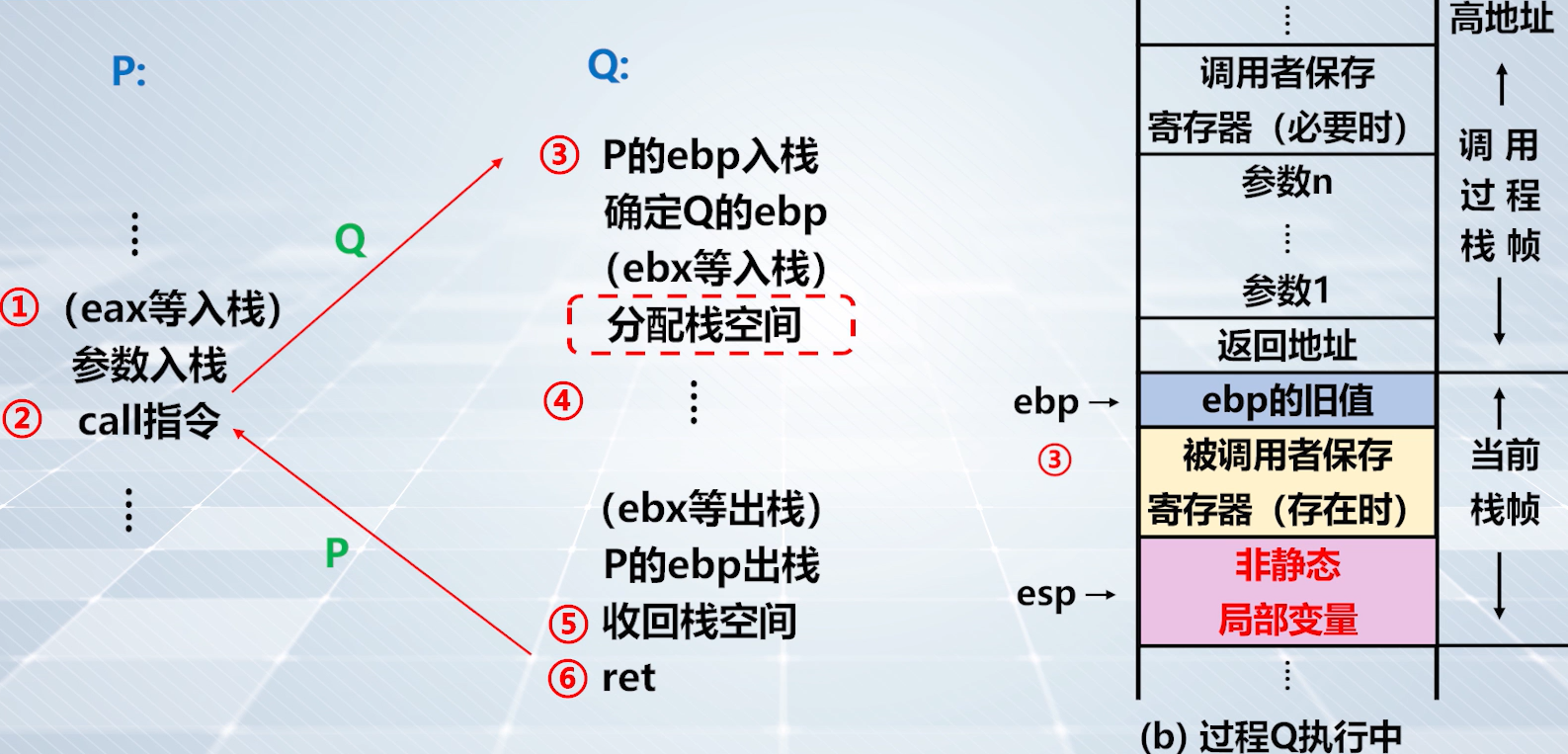
上图,保存非静态局部变量后移动
esp
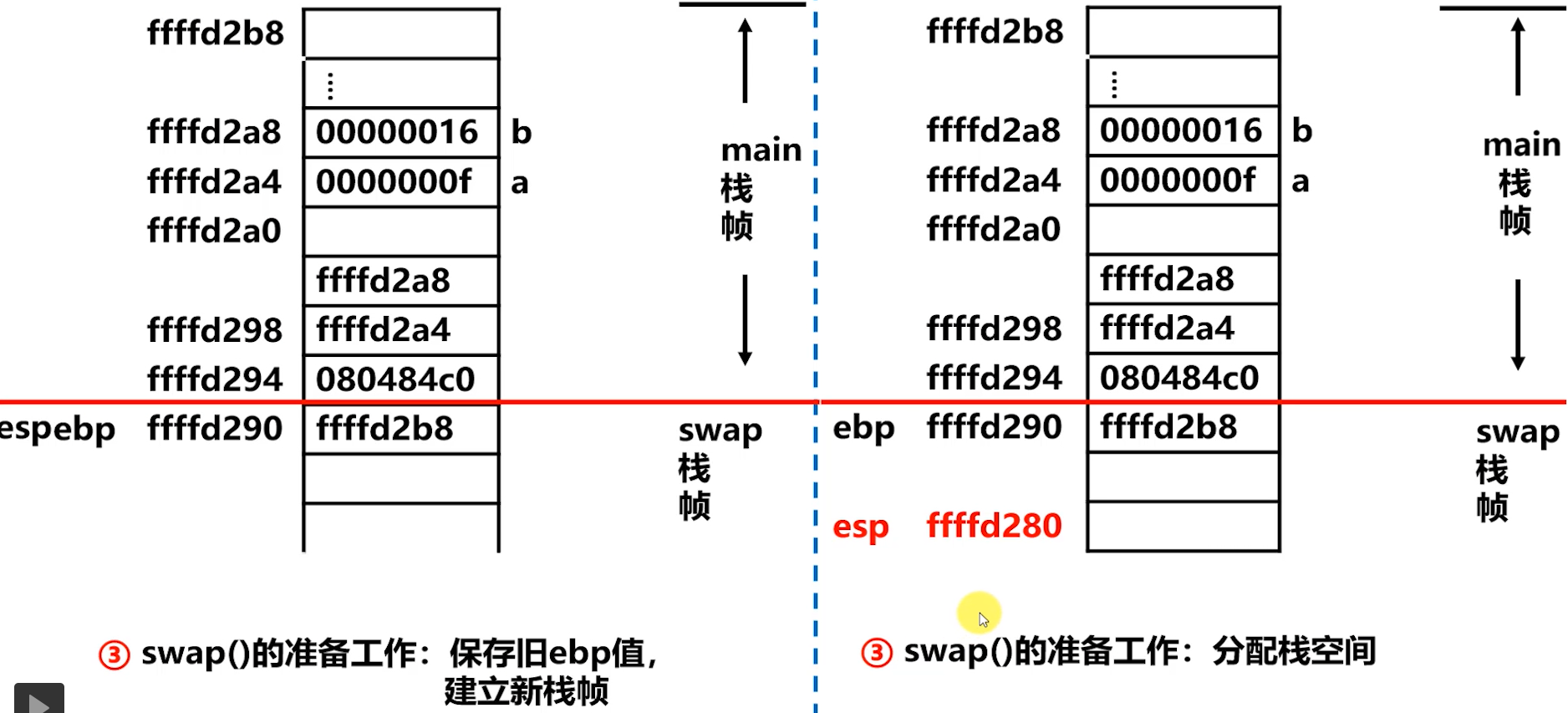
上图:step3️⃣ 的栈帧情况(左),保存旧
ebp的值,建立新的栈帧。step3️⃣ 的栈帧情况(右),分配栈空间
step4️⃣:执行 Q 的过程体

上图,执行过程反汇编
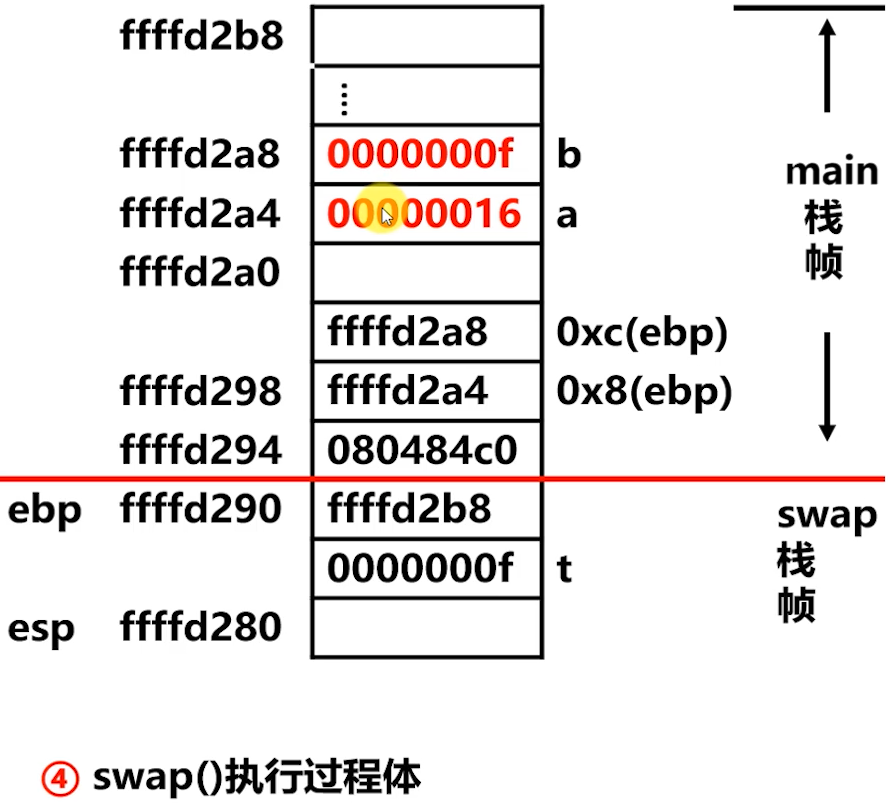
上图,执行过程栈帧示意图
step5️⃣: 收回栈空间
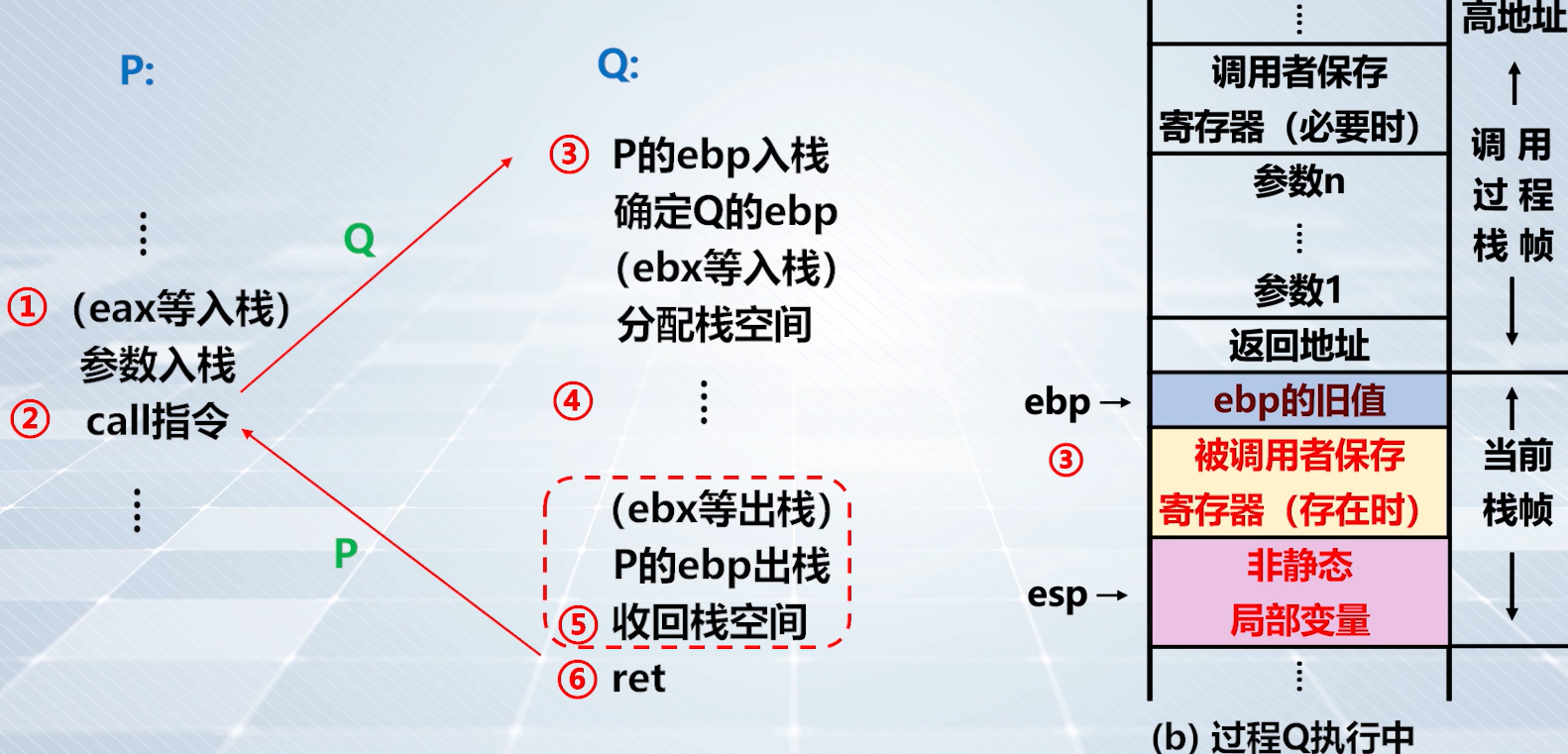
上图,将寄存器
ebx等使用过的寄存器出栈,收回栈空间,IA32 中提供leave指令回收栈空间

上图,
leave指令回收栈空间。
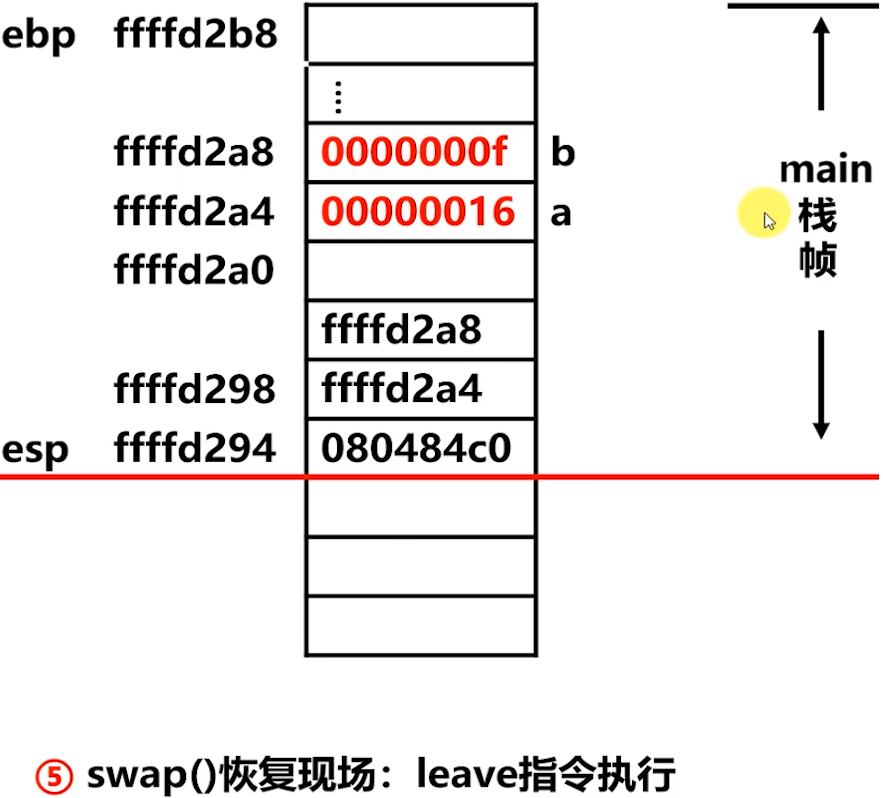
上图,step5️⃣ 栈帧情况图,指令回收栈空间
step6️⃣: ret
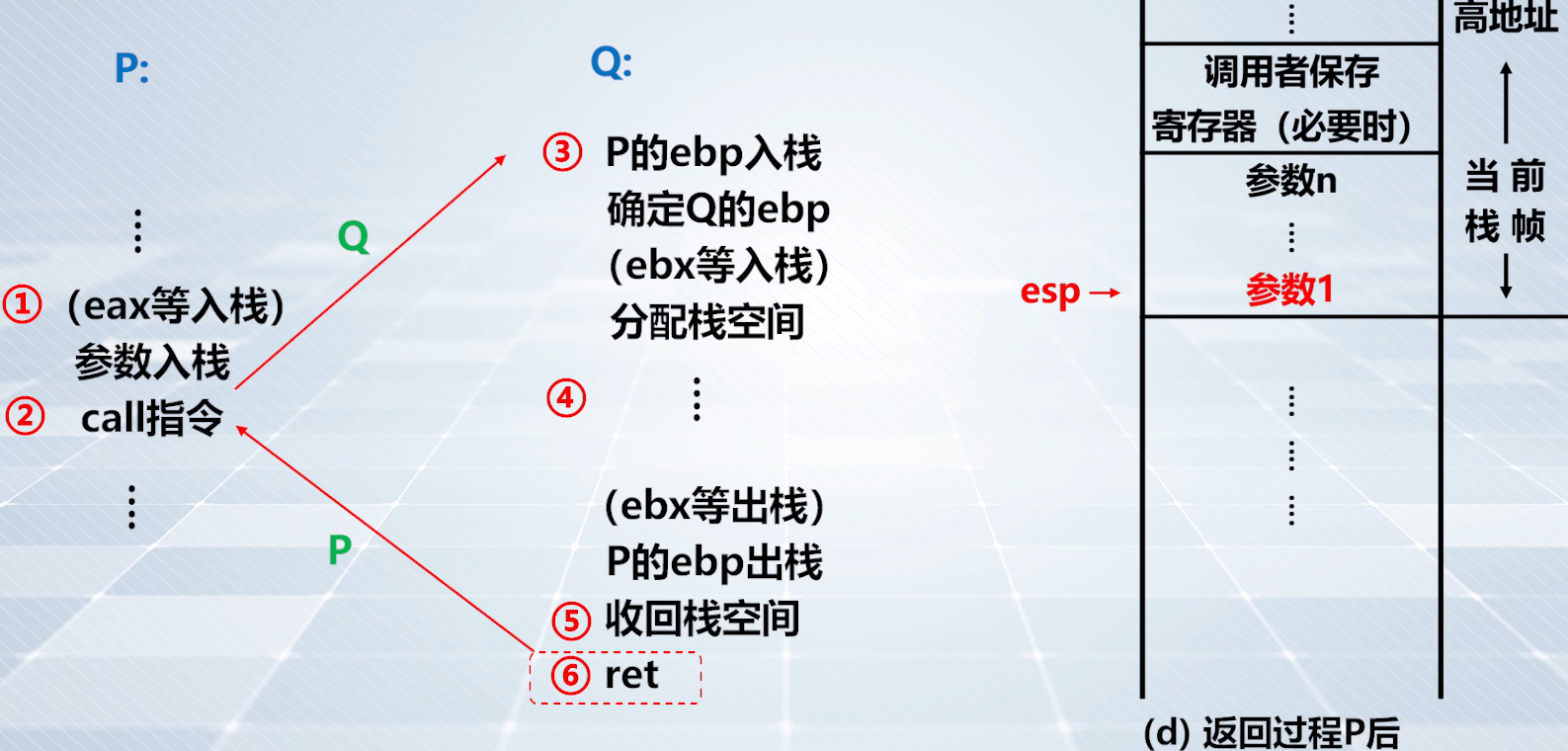
上图,通过
ret指令返回 P,此时esp指向参数 1 的单元。

上图,
ret返回调用者。
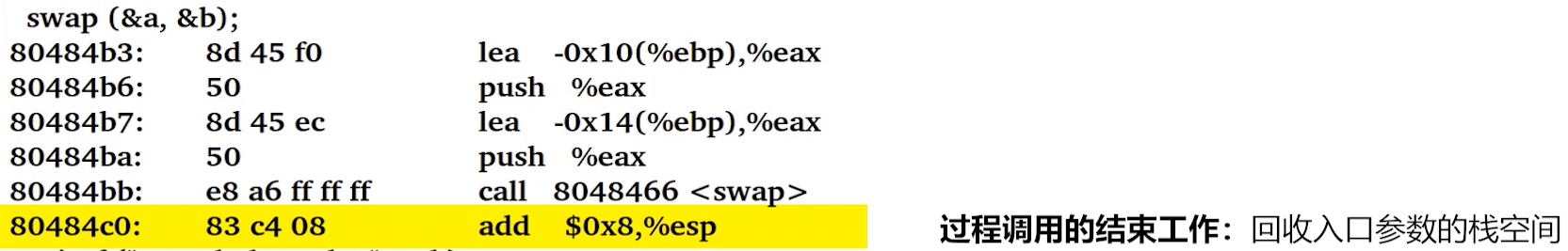
上图,过程调用的结束工作。示例代码反汇编。
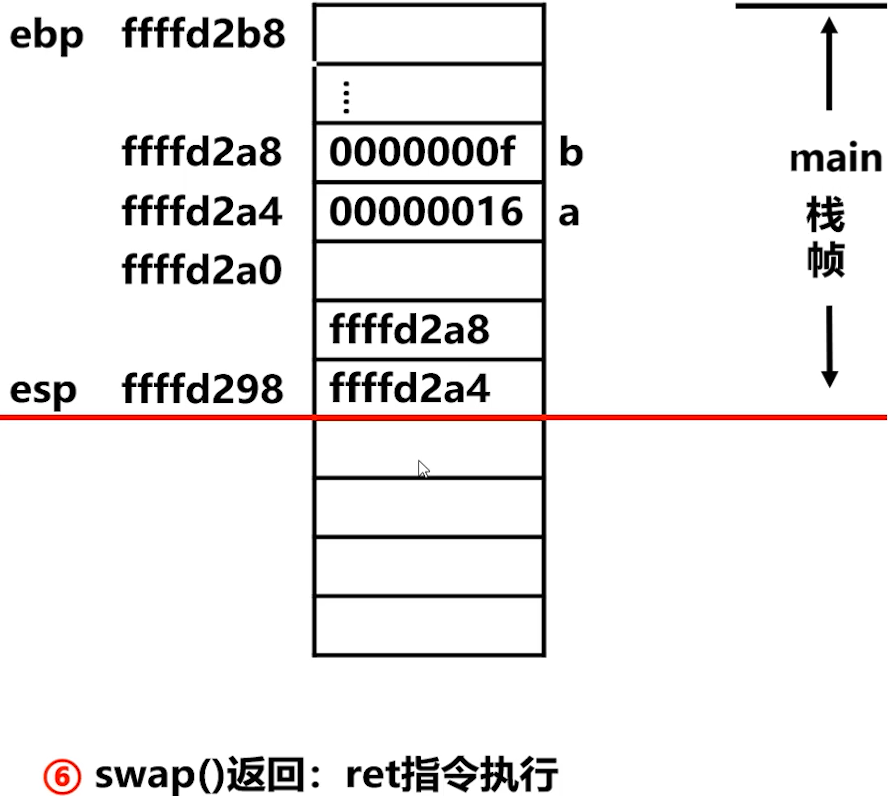
上图,step6️⃣ 栈帧情况图,返回到主函数的下一条指令。
( 🏫 CMU补充 )画程序栈图补充
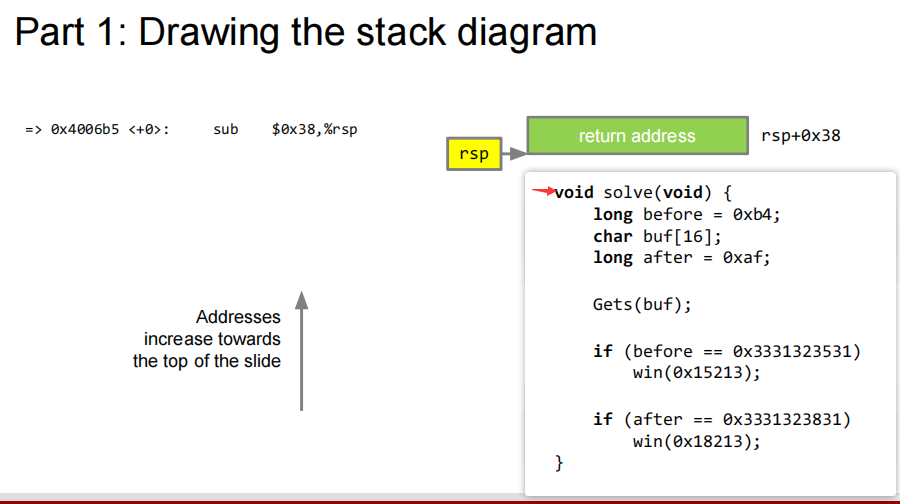
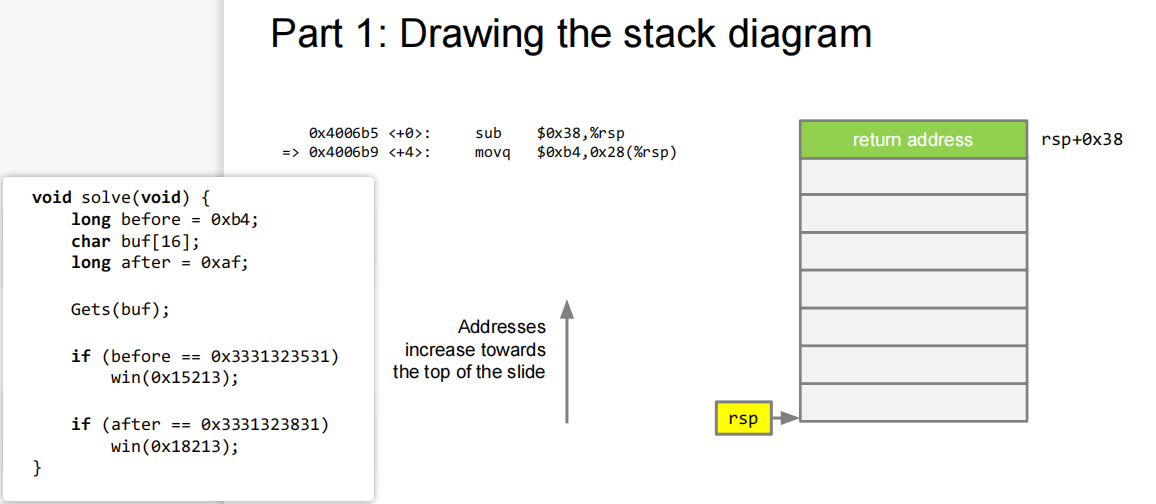
上图,设置返回地址
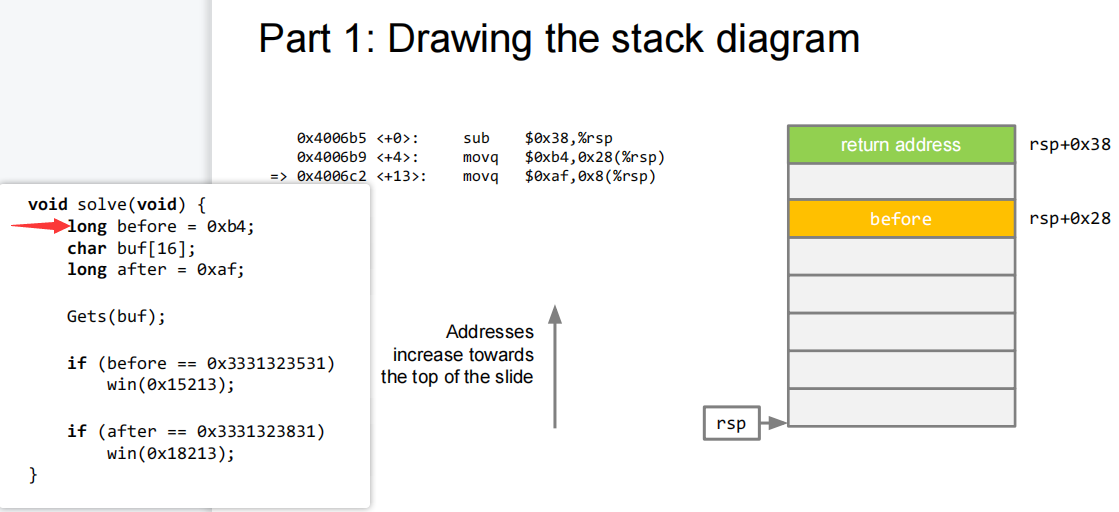
上图,存储
before
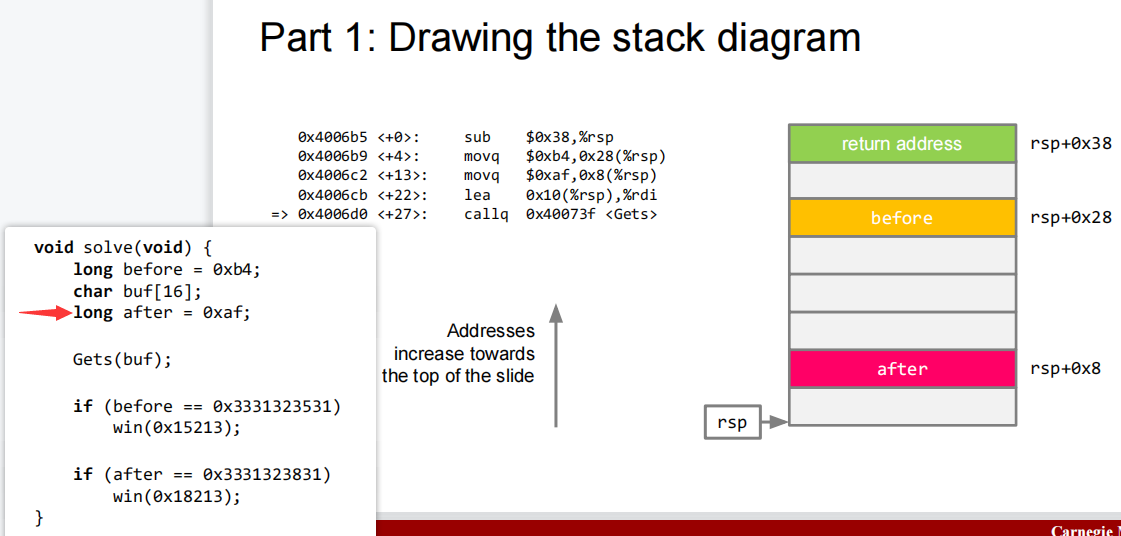
上图,存储
after
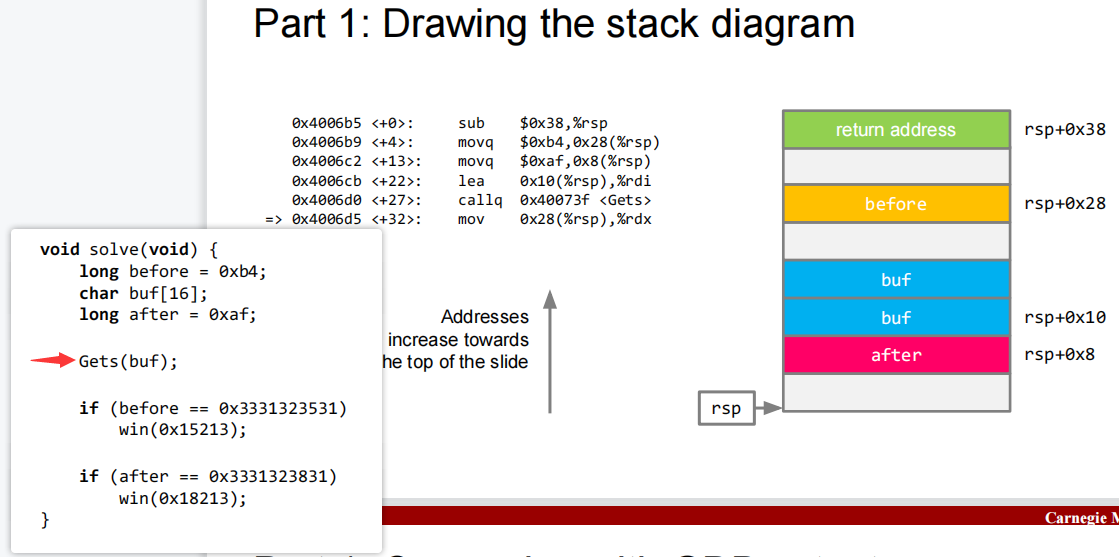
上图,存储
buf
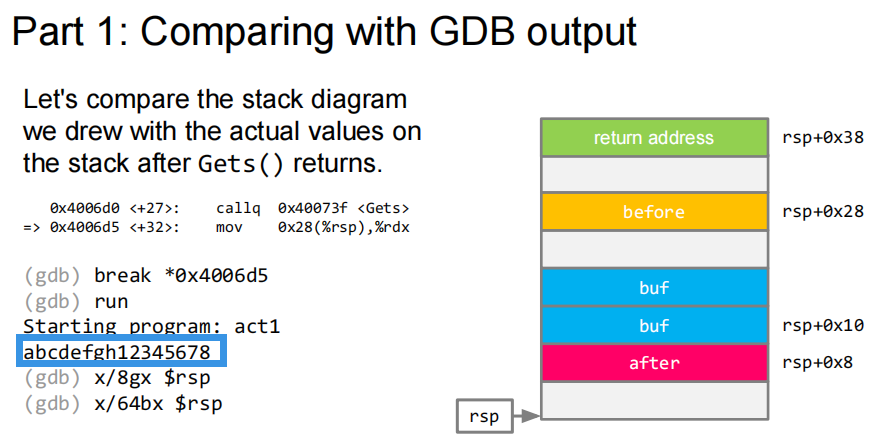
上图,使用 GDB 调试
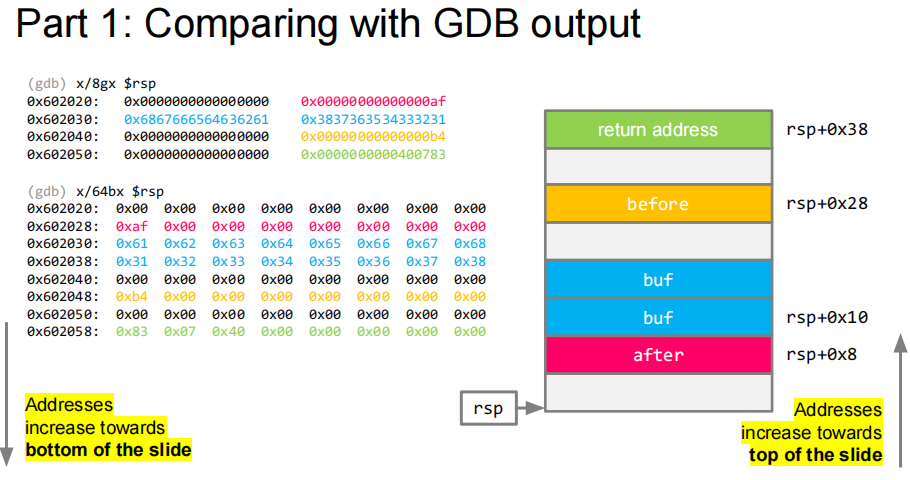
上图,调试效果

上图,x86-64 的栈帧结构
( 🏫 CMU补充 )递归函数的调用过程

上图,左边为 C 语言代码,右边为汇编代码

上图,设置
eax初始值为 0 ,如果rdi(也就是x)为 0 ,直接ret,返回rax

上图,
rbx为暂存值。

上图,执行
&操作和逻辑右移操作。

上图,调用
pcount_r函数

上图,执行求和操作。

上图,在用完暂存变量
rbx,在程序返回前,弹出rbx
栈与过程调用实验:缓冲区溢出攻击
原理示意图
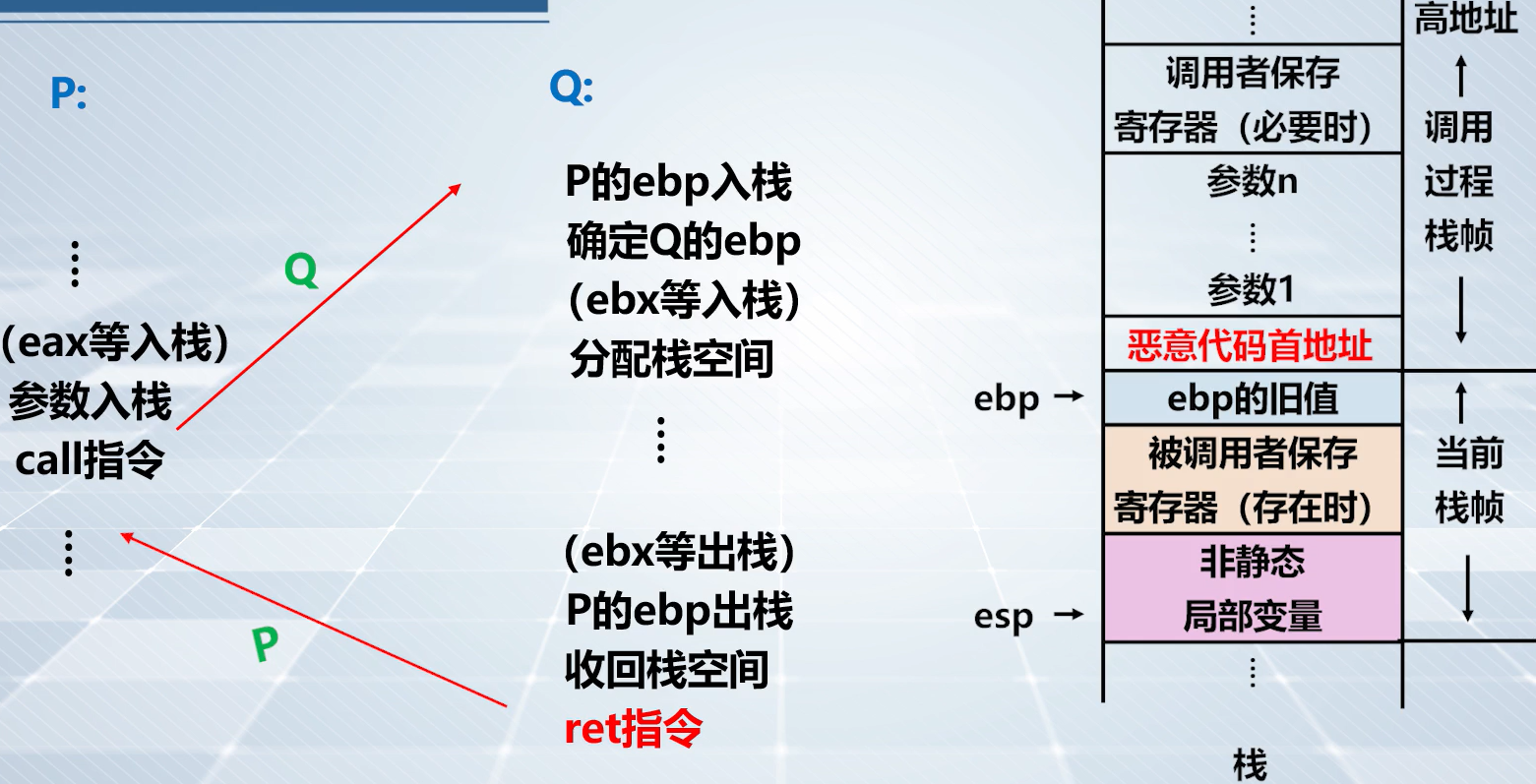
就是让本应该是
main函数的下一条指令改为恶意代码首地址。
实施过程
-
攻击示例代码(
a.c)#include<stdio.h> #include<string.h> char code[]="0123456789abcdef"; int main() { char *arg[3]; arg[0] = "./b"; arg[1] = code; arg[2] = NULL; execve(arg[0],arg,NULL); return 0; } -
被攻击示例代码(
b.c)#include<stdio.h> #include<string.h> void outputs(char *str) { char buffer[16]; strcpy(buffer,str); printf("%s\n",buffer); } void hacker(void) { printf("being hacked\n"); } int main(int argc,char *argv[]) { outputs(argv[1]); printf("yes\n"); return 0; } -
关闭栈的随机化
sudo sysctl -w kernel.randomize_va_space=0 -
编译
gcc -o0 -g -fno-stack-protector -z execstack -no-pie -fno-pic a.c -o a gcc -o0 -g -fno-stack-protector -z execstack -no-pie -fno-pic b.c -o b