外部排序
外部排序的基本内容
前面介绍过的排序方法都是在内存中进行的(称为内部排序)。外部排序是一种无法全部装入内存的大规模数据集的排序算法。与在内存中处理数据的内部排序相比,外部排序要复杂的多,主要因为是其需要解决的问题更多。主要的挑战之一就是I/O操作,因为硬盘或其他外部存储设备的数据访问速度通常比内存要慢得多。
外部排序的一般方法
文件在磁盘上的存储和操作系统的读写操作,一般来说,确实是按块进行的。块的大小可以根据系统的配置和需求进行设定。而由于磁盘读/写操作的机械动作所需的时间远远超过内存中数据处理的时间,因此外部排序中最大的时间消耗通常来自于对磁盘的读写操作,也就是I/O操作。
外部排序的常用方法包括归并排序和置换-选择排序。其中,归并排序是最常用的一种,它包括两个阶段:
- 分阶段:根据内存缓冲区的大小,将存储在外部存储设备上的大文件分成若干长度为l的子文件。每个子文件被单独读入内存,并使用内部排序方法进行排序。排序后,每个子文件变成一个有序的子文件,也被称为归并段或顺串。这些有序的子文件随后被写回到外部存储设备中。
- 合并阶段:在此阶段,多个归并段被逐个合并,每次合并产生一个更大的有序归并段,这个过程被称为归并。通过反复的归并操作,最终所有的归并段都会被合并成一个完整的有序文件。
在这个过程中,内存的大小会影响到子文件的长度,进而影响到整个排序过程需要的归并次数。而归并次数则直接关联到了需要进行的I/O操作的次数。因此,内存的大小是影响外部排序效率的重要因素。
举例:
我们首先考虑内存和磁盘块的配置。假设我们有2000个记录要排序,并且每个磁盘块可以容纳125个记录。由于这个文件太大无法全部加载到内存中,我们必须采取一种分块处理的策略。我们的内存可以容纳两个输入缓冲区和一个输出缓冲区,每个都可以容纳一个磁盘块。
在开始排序前,我们首先需要对大文件进行预处理,生成一些初级的有序段,这个过程通常被称为"分阶段"。在这个阶段,我们一次处理两个磁盘块(250条记录),并使用内部排序算法(如快速排序,堆排序等)将其排序,形成一个有序的子文件或称之为归并段。这样我们将得到8个归并段(R1到R8),每个段都含有250个记录。
然后我们进入"合并阶段",在这个阶段,我们会逐步将小的归并段合并成大的归并段,直到得到一个完全有序的大文件。这个阶段的操作是,首先从两个输入归并段(如R1和R2)中分别读入一个块,放在输入缓冲区1和输入缓冲区2中。然后,执行两路归并操作,将最小的记录依次取出并放入输出缓冲区。当输出缓冲区满时,我们把它写回到磁盘中,形成一个新的归并段(如R1’)。如果某个输入缓冲区的记录已经取完,那么就从相应的归并段中读入下一块。这样进行下去,直到所有的记录都被处理完。通过这样的方式,我们首先将R1和R2归并成R1’,然后依次归并R3和R4成R2’,R5和R6成R3’,R7和R8成R4’。
在完成一趟归并后,我们再次进行归并操作,将上一趟归并得到的结果进一步合并。首先,我们将R1’和R2’归并成R1",然后将R3’和R4’归并成R2"。在第三趟归并中,我们将R1"和R2"归并,最终得到一个完全有序的大文件。
在整个过程中,我们通过内存缓冲区的巧妙使用,实现了对磁盘I/O操作的最小化,大大提高了外部排序的效率。这就是使用多路归并进行外部排序的一个典型例子,它体现了如何利用有限的内存资源处理大文件排序的问题。

在外部排序实现两两归并时,由于不可能将两个有序段及归并结果同时存放在内存中,因此需要不停地将数据读出、写入磁盘、而这会消耗大量的时间。一般情况下:外部排序的总时间 = 内部排序所需时间 + 外部排序读写时间 + 内部归并所需的时间。
显然,外存信息读写的时间远大于内部排序和内部归并的时间,因此应着力减少I/O次数。由于外存信息的读/写是以“磁盘块”为单位的,可知每一趟归并需进行16次“读”和16次“写”,3趟归并加上内存排序时所需进行的读/写,使得总共需要进行32*3+32=128次读写。
若改用4路归并排序,则只需两趟归并,外部排序时的总读/写次数便减少至32*2+32=96.因此,增加归并路数,可减少归并趟数,进而减少总的磁盘的I/O次数。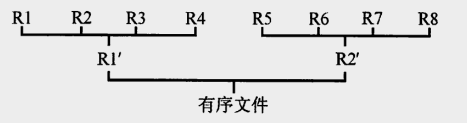
路数越大,每趟归并处理的数据越多,总的归并趟数就越少,从而减少了I/O操作次数。然而,增大归并路数也会使得内存的负载增加,因为每一趟归并都需要将多个数据块加载到内存中。
多路平衡归并与败者树
多路平衡归并的核心思想在于增加归并路数k,以减少归并趟数S,从而降低I/O次数。这在处理大数据时极为重要。然而,增大归并路数k的同时,普通的内部归并排序算法的时间复杂度也会随之增大,因为每趟归并需要在k个元素中选择关键字最小的记录,需要做(k-1)次比较。
为了解决这个问题,我们引入了败者树,它是树形选择排序的一种变种,可以看作是一棵完全二叉树。在败者树中,k个叶节点分别存放k个归并段的当前比较记录,内部节点用来存储“失败者”,胜者继续上升进行比较,直到根节点。这样,根节点就指向了关键字最小的记录。
通过使用败者树,我们可以在log2k的深度下完成一次关键字最小记录的选择,大大降低了比较的次数。这样,我们就可以在内存允许的情况下,通过增大归并路数k来降低归并树的高度,减少I/O次数,提高外部排序的速度。
然而,归并路数k并不是越大越好。因为增大k意味着需要增加输入缓冲区的数量,这会占用更多的内存空间。如果内存空间固定,那么每个输入缓冲区的容量就需要减小,导致内存和外存之间的数据交换次数增加。当k值过大时,尽管归并趟数减少,但是读写外存的次数可能会增加,这反而可能降低排序的效率。
置换-选择排序
置换-选择排序是一种生成初始归并段的算法,它在内存不足以对所有数据进行排序时特别有用。它的核心思想是:通过维护一个内存工作区,从中选择关键字最小的记录输出到初始归并段,同时不断从输入文件中读入新的记录到工作区,以此方式生成尽可能长的初始归并段。这种方式能有效减少后续归并操作的次数,提升外部排序的效率。
以下是置换-选择排序的详细步骤:
- 初始化:首先,从待排序文件(FI)中读取w个记录到内存工作区(WA)。w是由内存大小决定的一个值,也可以理解为内存工作区的容量。此时,初始归并段输出文件(FO)为空。
- 选择最小记录:在内存工作区(WA)中选择关键字最小的记录,我们称其为MINIMAX记录。
- 输出最小记录:将选中的MINIMAX记录输出到初始归并段输出文件(FO)中。
- 读入新记录:如果待排序文件(FI)还有未读取的记录,那么从FI中读取下一个记录到内存工作区(WA)中。
- 选择新的最小记录:在WA中,选出关键字大于刚才输出到FO中的MINIMAX记录关键字的所有记录中,关键字最小的那个记录,作为新的MINIMAX记录。
- 重复输出和读入:然后重复步骤3至5,直到无法在WA中选出新的MINIMAX记录,这就形成了一个初始归并段。
- 生成所有初始归并段:接着,重新读入w个新记录到WA,然后重复步骤2至6,直到处理完FI中的所有记录,得到所有的初始归并段。
这里要注意的是,置换-选择排序允许新加入的记录的关键字小于当前归并段的最大关键字,只要这个记录的关键字大于刚才输出的MINIMAX记录的关键字。这种方法的灵活性使得置换-选择排序能够生成长度更长的初始归并段,比简单的内部排序生成的初始归并段长度要大。
最佳归并树
在处理大量数据时,我们常常需要进行排序操作。但是,如果数据量超过了内存的容量,我们就不能使用一般的内部排序算法了,此时,我们需要使用外部排序算法。其中,归并排序是一种非常常见的外部排序方法。归并排序的基本思想是将多个已排序的子序列合并为一个有序的总序列。
然而,如何优化归并排序的效率是一个重要的问题。我们知道,归并排序的主要时间消耗在于读取和写入数据,即I/O操作。为了减少I/O操作的次数,我们引入了最佳归并树的概念。
在最佳归并树中,每个节点代表一个归并段,归并段的长度就是节点的权值。根据哈夫曼树的原理,我们知道树的带权路径长度最小的二叉树是最优二叉树,即哈夫曼树。所以,我们可以应用哈夫曼树的原理到k叉树中,使得每个归并段的长度(权值)乘以其在树中的路径长度最小,这样可以最小化总的I/O操作次数。
这就是最佳归并树的基本概念。然而,实际上,我们可能会遇到一些问题。比如说,我们有的时候无法正好构成一个严格的k叉树。这个时候,我们就需要引入“虚段”的概念。虚段是一个长度为0的归并段,可以作为额外的叶节点添加到归并树中,以保持其严格的k叉形态。我们可以通过一个简单的公式来判断需要添加多少个虚段。
设度为0的节点有n0个,度为k的节点有nk个。对于一个严格的k叉树,有n0 = (k-1) * nk + 1。这个公式告诉我们,如果叶节点的数量减1后不能被(k-1)整除,那么就说明我们有一些叶节点是多余的,不能被包含在k叉归并树中。为了让所有的叶节点都能被包含在k叉归并树中,我们需要再增加一个内节点,并添加k-u-1个虚段,其中u是(n0-1)%(k-1)的余数。
举个例子,假设我们有8个初始归并段,想要构成一个3叉树。我们计算(8-1)%(3-1) = 1,说明7个归并段刚好可以构成一棵严格的3叉树。但是我们还有一个多余的归并段,为了包含这个归并段,我们将一个叶节点变成内节点,然后添加3-1-1=1个虚段,就可以构成一棵严格的3叉树。