文章目录
- 前言
- 1. Pandas库的引用
- 2. Pandas库的数据类型
- 2.1 Series类型
- 2.2 Series创建方式
- 2.3 Series类型的基本操作
- 2.3.1 Series类型的切片和索引
- 2.3.2 Series类型的对齐操作
- 2.3.3 Series类型的name属性
- 2.3.4 Series类型的修改
- 2.4 DataFrame类型
- 2.5 DataFrame类型创建
- 2.6 DataFrame的索引
- 2.6.1 loc 通过标签索引数据
- 2.6.2 iloc 通过位置获取数据
- 2.6.3 bool索引
- 2.6.4 DataFrame整体情况查询
- 2.7 DataFrame的基础属性
- 3. 缺失数据的处理
- 3.1 处理NaN数据
前言
❓为什么要学习pandas❓
NumPy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢?
NumPy能够帮我们处理处理数值型数据,但是这还不够,很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等,所以,NumPy能够帮助我们处理数值,但是pandas除了处理数值之外(基于NumPy),还能够帮助我们处理其他类型的数据。
1. Pandas库的引用
Pandas是Python第三方库,提供高性能易用数据类型和分析工具。
import pandas as pd
▫️Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用.
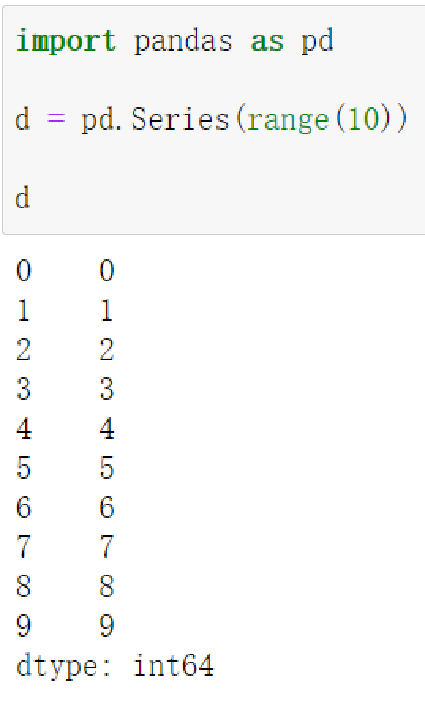
🔹计算前N项累加和
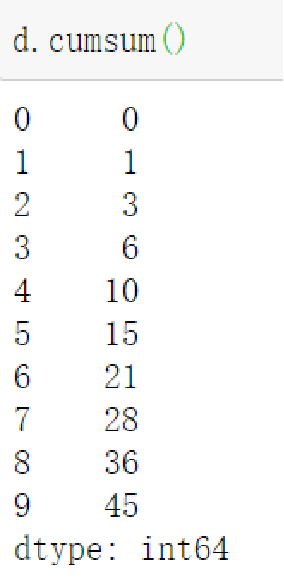
Series DataFrame
▫️基于上述数据类型的各类操作
▫️基本操作、运算操作、特征类操作、关联类操作
NumPy
- 基础数据类型
- 关注数据的结构表达
- 维度:数据间的关系
Pandas
- 扩展数据类型
- 关注数据的应用表达
- 数据与索引之间的关系
2. Pandas库的数据类型
2.1 Series类型
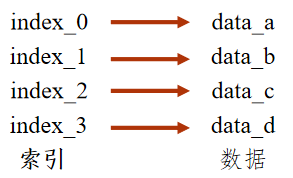
Series类型由一组数据及与之相关的数据索引组成.
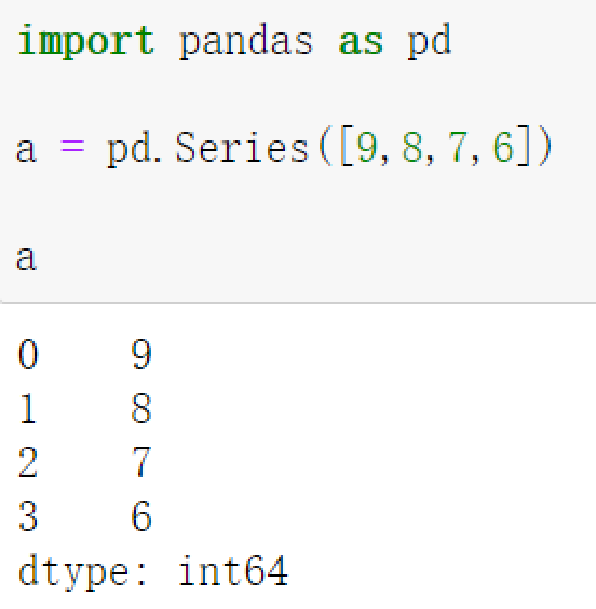
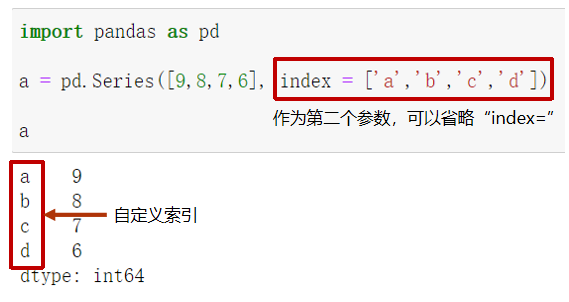
2.2 Series创建方式
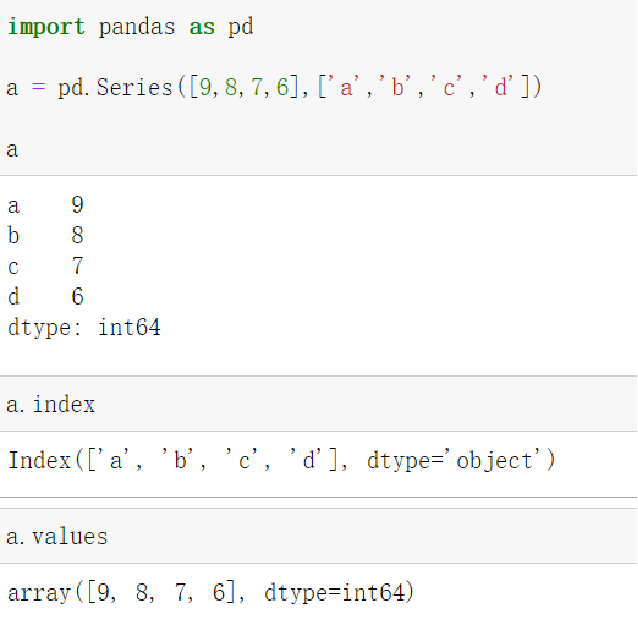
- Python列表
- 标量值
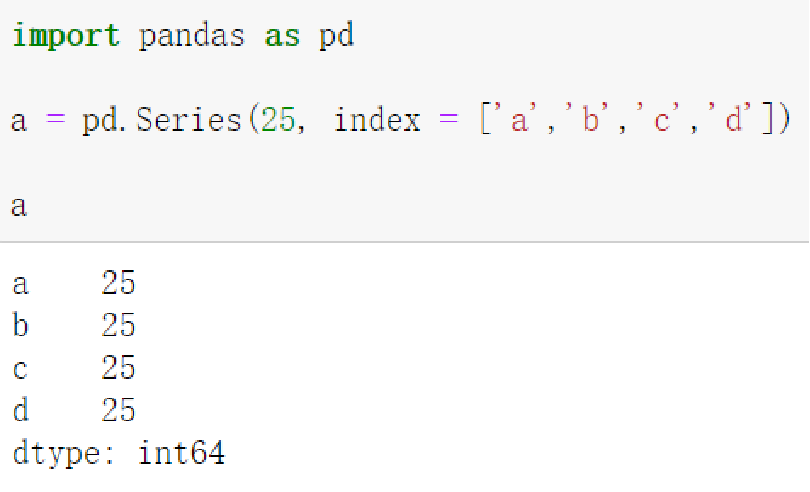
- Python字典
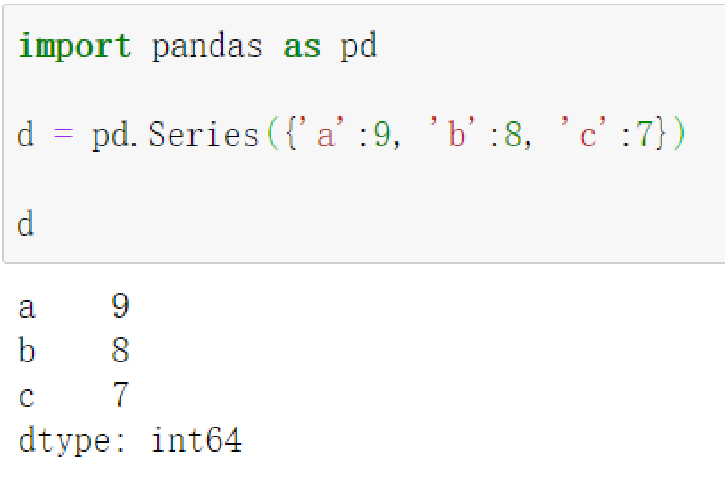


NumPy中NaN为float,pandas会自动根据数据类型更改series的dtype类型
- ndarray
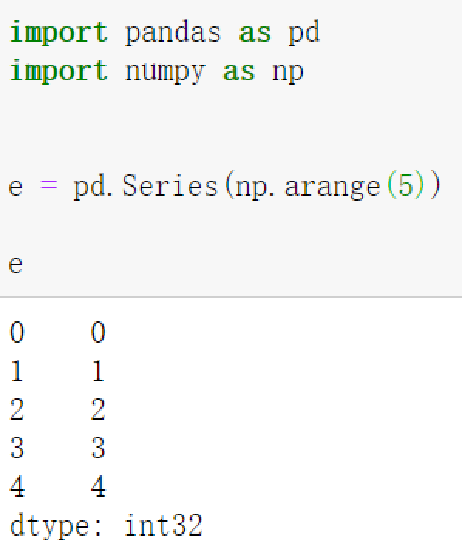
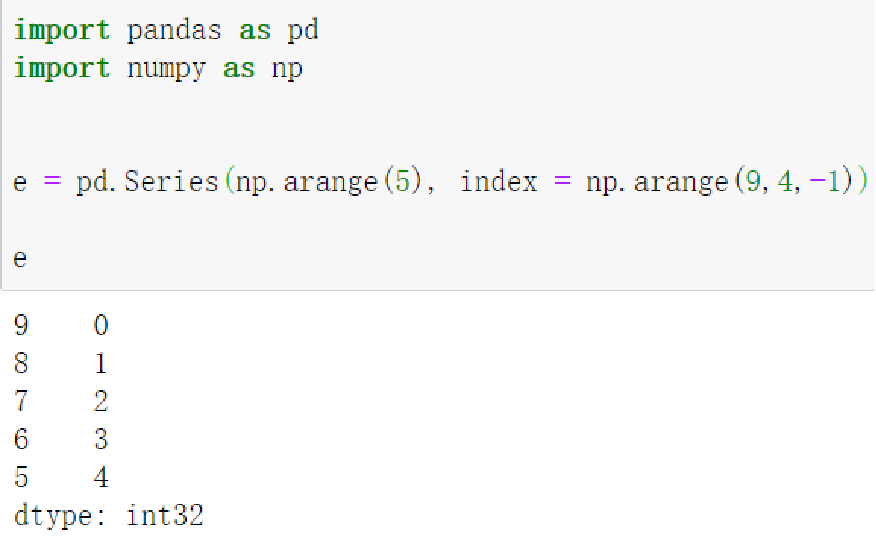
- 其他函数
range()等
2.3 Series类型的基本操作
-
Series类型包括index和values两部分
-
Series类型的操作类似ndarray类型
-
Series类型的操作类似Python字典类型
- 通过自定义索引访问
- 保留字典in操作
- 使用.get()方法


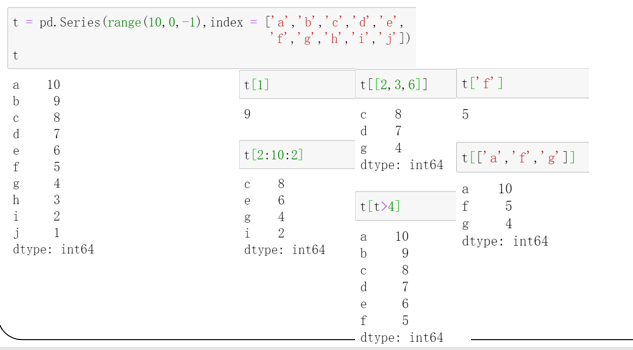
2.3.1 Series类型的切片和索引
-
索引方法采用[ ]
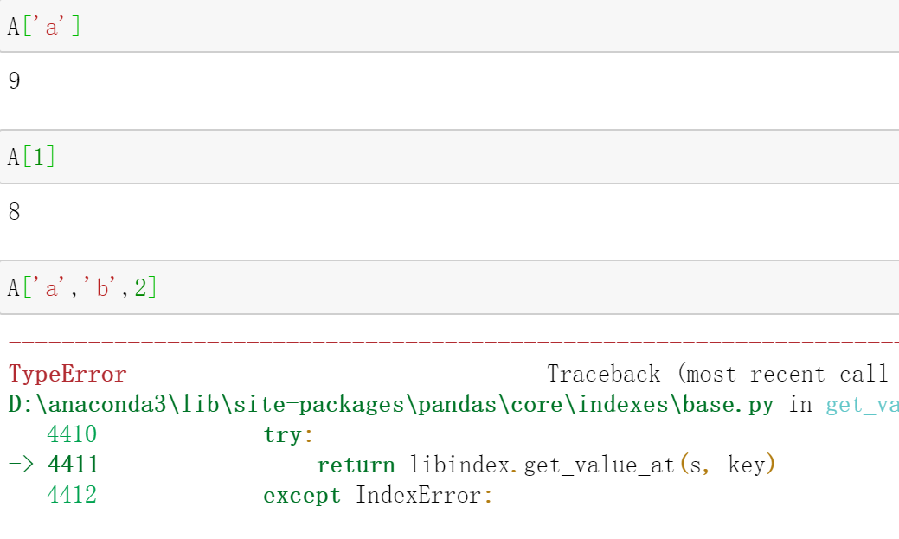
-
NumPy中运算和操作可用于Series类型
-
可以通过自定义索引的列表进行切片
-
可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
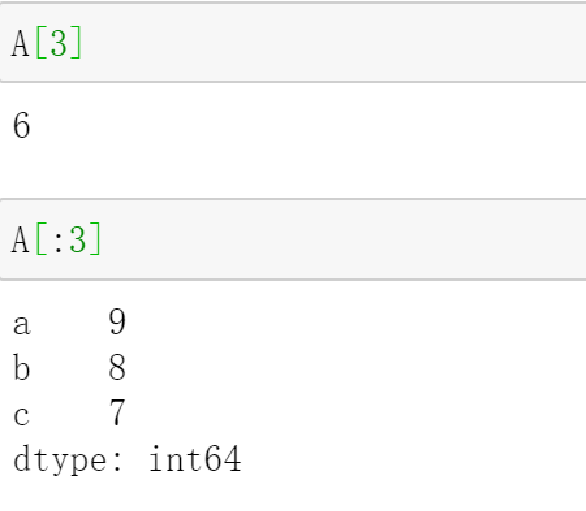
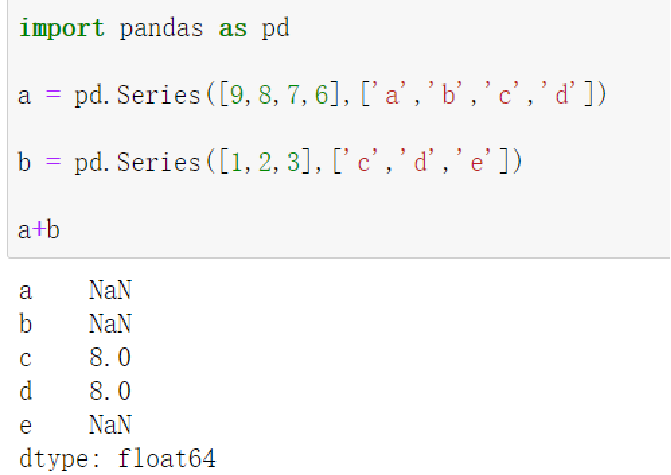
2.3.2 Series类型的对齐操作
Series类型在运算中会自动对齐不同索引的数据。
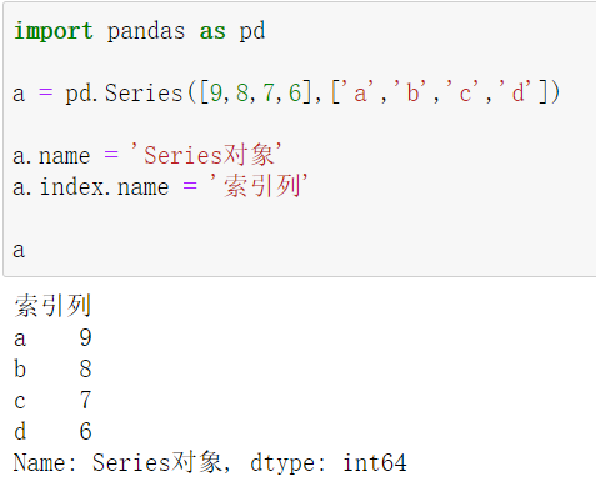
2.3.3 Series类型的name属性
Series对象和索引都可以有一个名字,存储在属性.name中
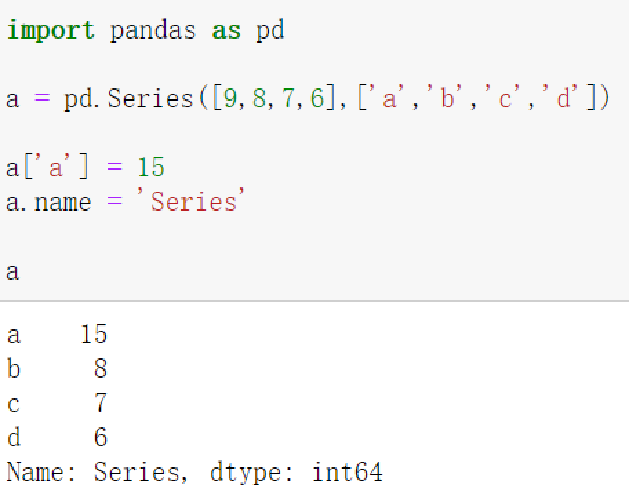
2.3.4 Series类型的修改
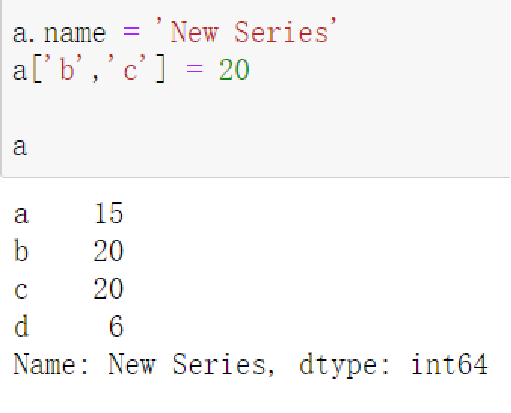
Series对象可以随时修改并即刻生效
2.4 DataFrame类型
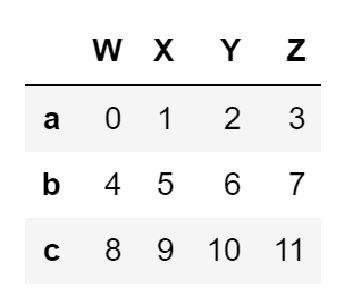
DataFrame类型由共用相同索引的一组列组成。

DataFrame对象既有行索引,又有列索引
- 行索引,表明不同行,叫index,0轴,axis=0
- 列索引,表名不同列,叫columns,1轴,axis=1

DataFrame是一个表格型的数据类型,每列值类型可以不同
DataFrame既有行索引、也有列索引
DataFrame常用于表达二维数据,但可以表达多维数据

问题:
-
DataFrame和Series有什么关系呢? -
Series能够传入字典,那么
DataFrame能够传入字典作为数据么? -
对于一个DataFrame类型,既有行索引,又有列索引,我们能够对他做什么操作呢
2.5 DataFrame类型创建
-
二维ndarray对象
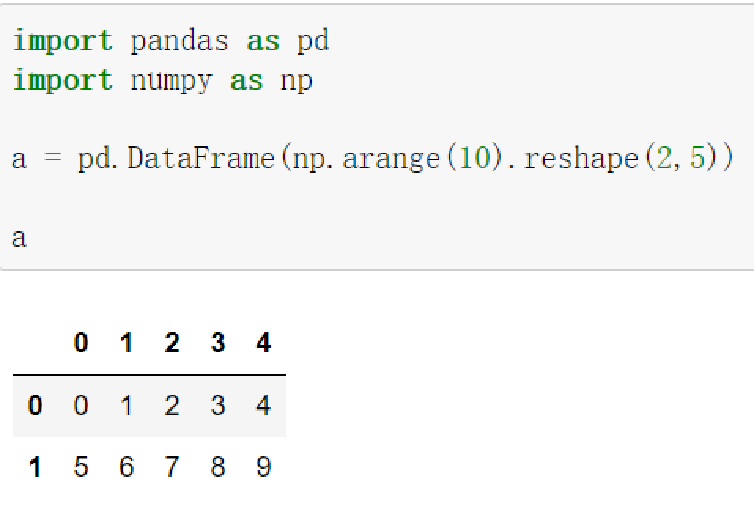
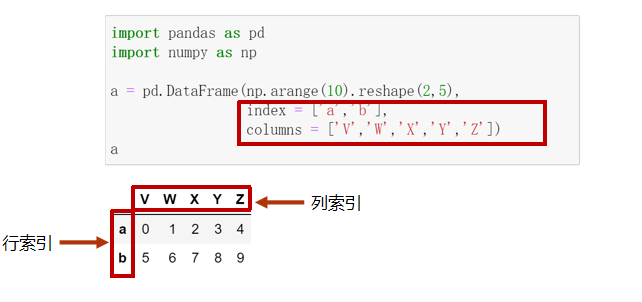
-
由一维ndarray、列表、字典、元组或Series构成的字典
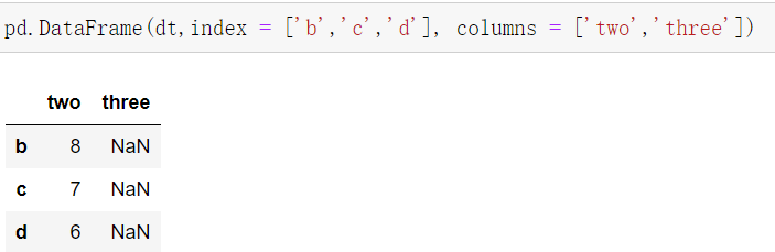
- 从Series类型的字典创建

- 从列表类型的字典创建
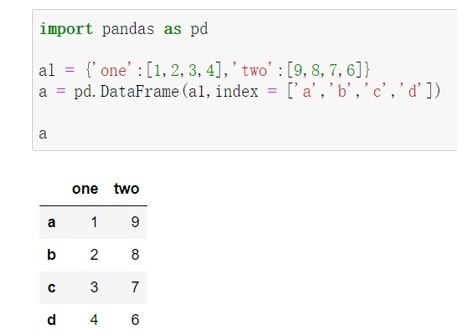
- 从列表类型的字典创建
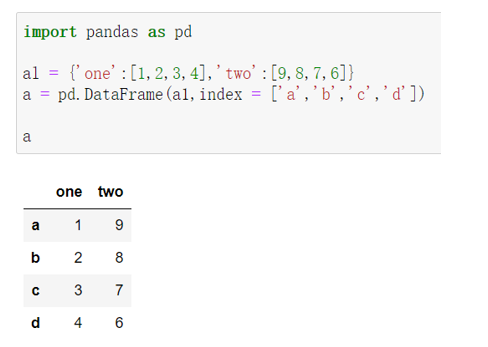
- 从Series类型的字典创建
-
Series
-
其他的DataFrame类型
🔹实例
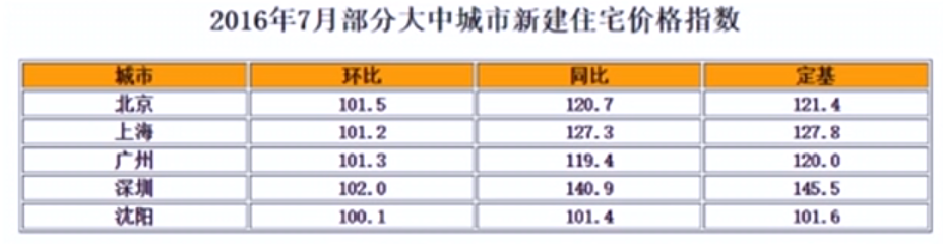
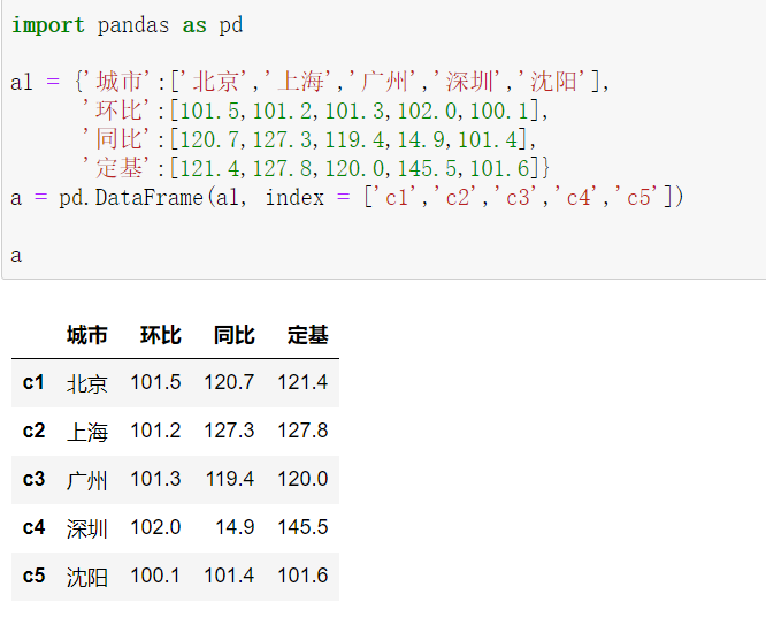
2.6 DataFrame的索引
- 方括号里为数,则表示取行,对行进行操作
- 方括号里为字符串,表示取列行,先对列后对行进行操作
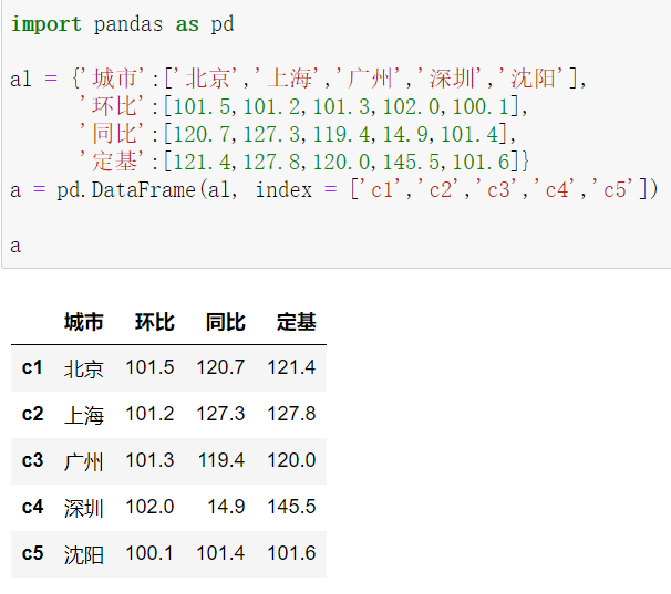
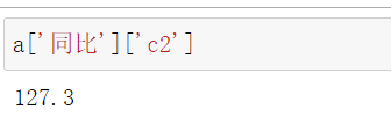
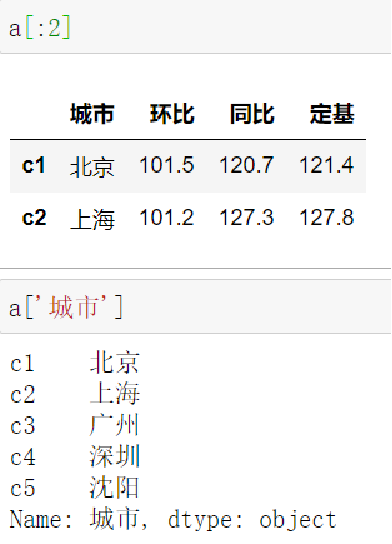

2.6.1 loc 通过标签索引数据
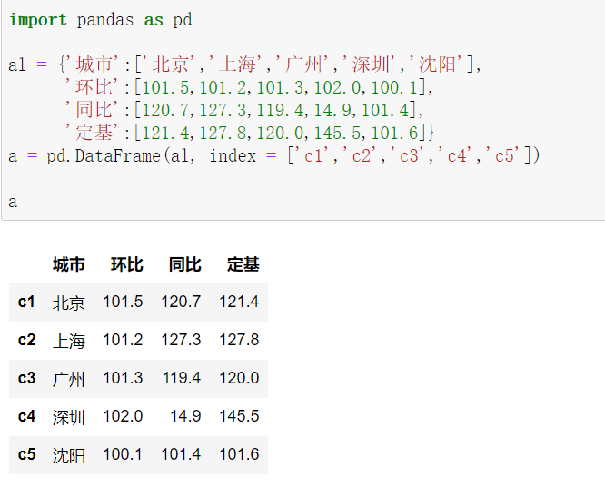

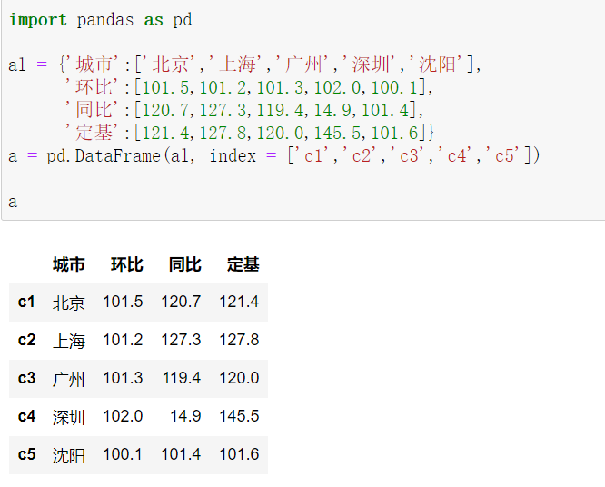
2.6.2 iloc 通过位置获取数据
2.6.3 bool索引
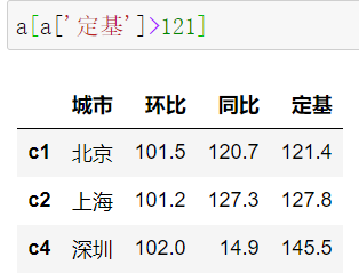
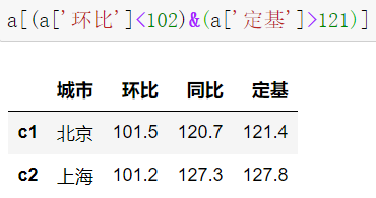
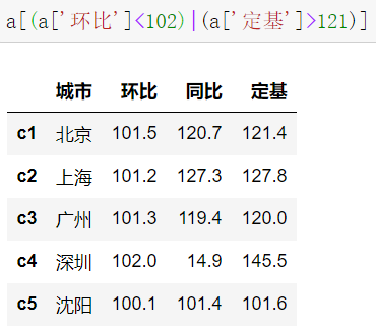
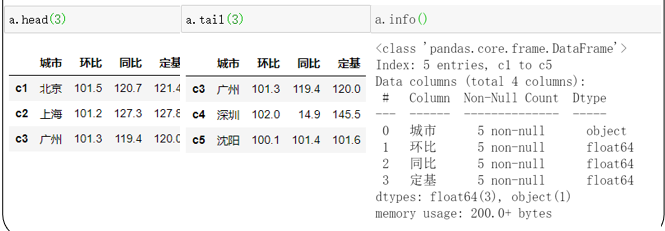
2.6.4 DataFrame整体情况查询
- .head(3) # 显示头部几行,默认5行
- .tail(3) # 显示末尾几行,默认5行
- .info() # 相关信息概览:行数,列数,列索引,列非空值个数,列类型,内存占用
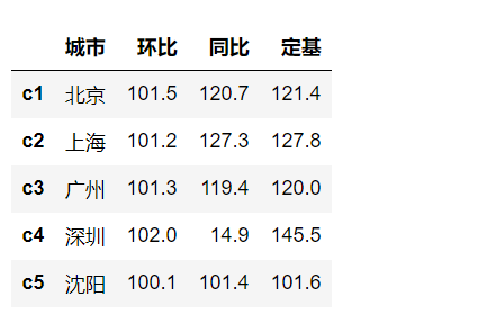
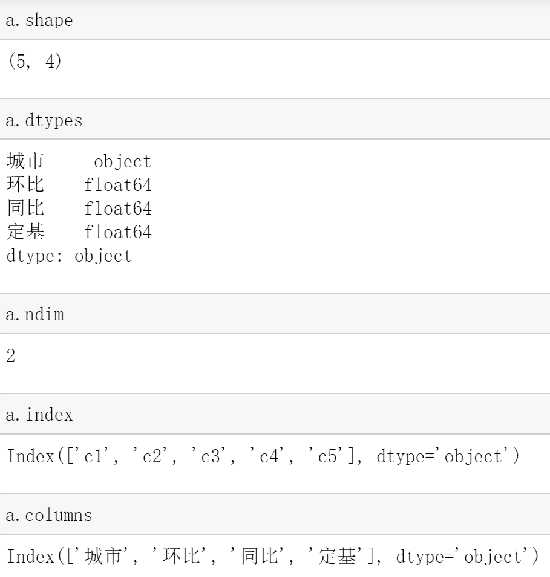
2.7 DataFrame的基础属性
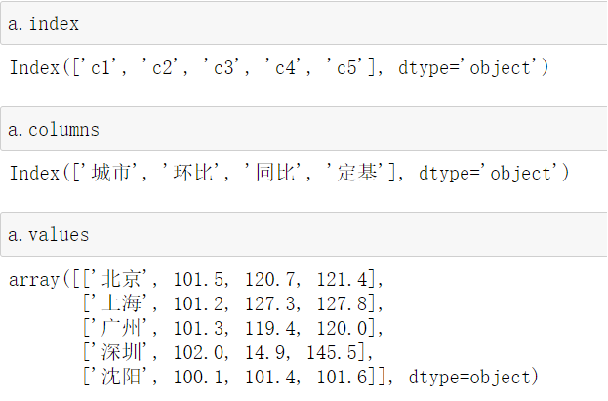
- .shape # 行数 列数
- .dtypes # 列数据类型
- .ndim # 数据维度
- .index # 行索引
- .columns # 列索引
- .values # 对象值,二维ndarray数组

3. 缺失数据的处理
我们的数据缺失通常有两种情况:
1️⃣一种就是空,None等,在pandas是NaN(和np.nan一样)
2️⃣另一种是我们让其为0
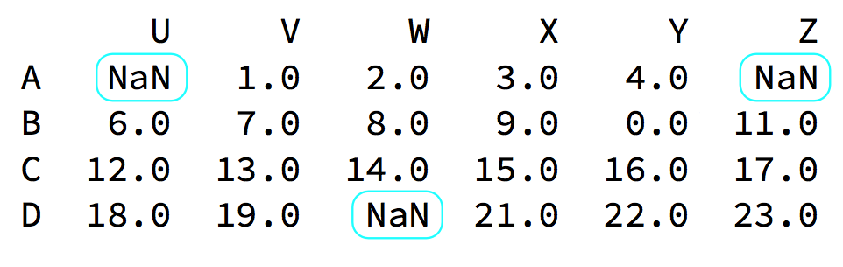
3.1 处理NaN数据
对于NaN的数据,在numpy中我们是如何处理的?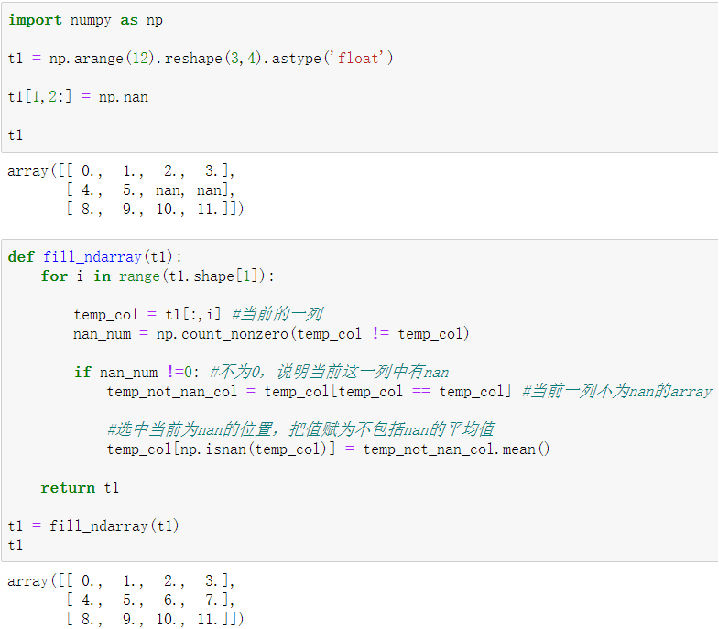
在pandas中处理起来非常容易
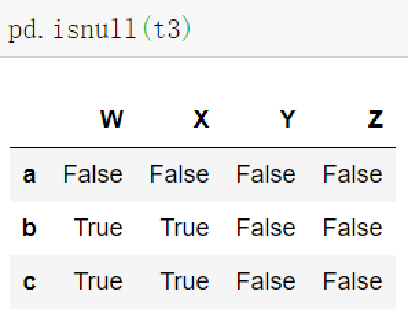
判断数据是否为NaN:
pd.isnull(df),pd.notnull(df)
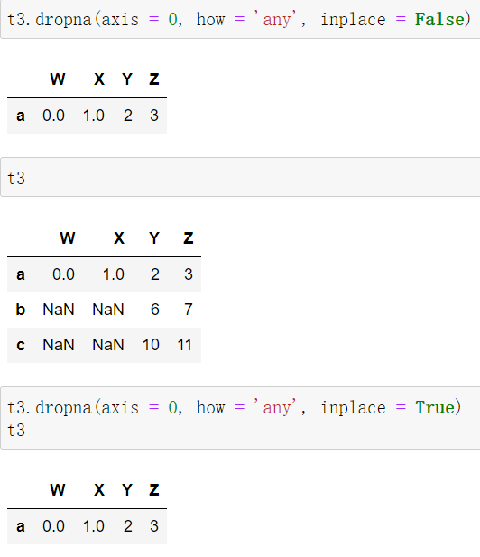
处理方式1:删除NaN所在的行列
dropna (axis=0, how='any', inplace=False)
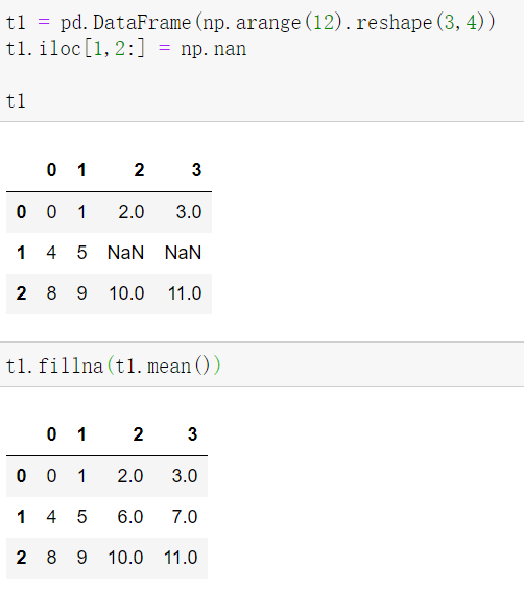
处理方式2:填充数据,计算平均值等情况,nan是不参与计算的
t.fillna(t.mean()),t.fillna(t.median()),t.fillna(0)
🔹实例: