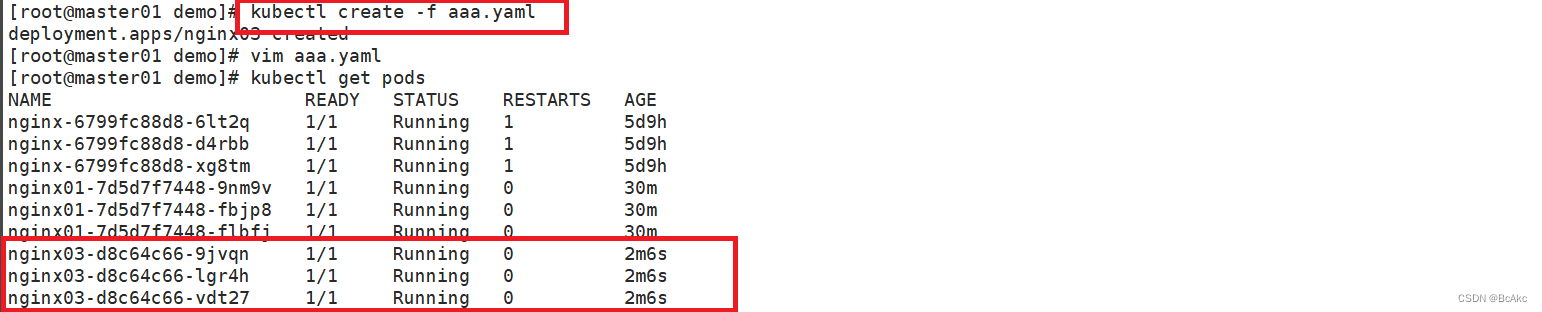
当一个主从配置中的master失效后,sentinel可以选举出一个新的master,用于自动接替原master的工作,主从配置中的其他redis服务器自动指向新的master同步数据。是如何具体做的呢,主要有以下4步。
一般建议sentinel 采取奇数台.
1.SDown 主观下线(Subjectively Down)
SDown 主观不可用,是单个sentinel 自己主观上检测到的关于master的状态,从sentinel 的角度来看,如果发送了PING心跳后,在一定时间内没有收到合法的回复,就达到了Sdown的条件。
sentinel 配置文件中的down-after-milliseconds 设置了判断主观下线的时间长度
2.ODown 主观下线(Objectively Down)
ODown 客观不可用,ODown需要一定数量的sentinel。多个sentinel 达成一致意见(master不可用),才能认为master客观上已经宕机。
3.选举sentinel(leader)
当主节点被认为客观下线以后,各个哨兵会进行协商,先选举出一个sentinel,并由seneitnel进行故障转移(failover)
3.1sentinel.log解释过程
//6379 客观下线
+sdown master mymaster 192.168.8.170 6379
//6379 主观下线
+odown master mymaster 192.168.8.170 6379 #quorum 2/2
// 开始选举
+new-epoch 20
// 尝试故障转移
+try-failover master mymaster 192.168.8.170 6379
Sentinel new configuration saved on disk
// sentinel 投票选择一个sentienl,由sentinel 进行故障转移
+vote-for-leader aea80c02b08119887d4291d9363deef140642060 20
cc67a7ca194afb25553c515f8afb4afe90d9023e voted for aea80c02b08119887d4291d9363deef140642060 20
93cb0306c9539a801a8f22f8ce9cdbfd081701b2 voted for aea80c02b08119887d4291d9363deef140642060 20
// 选举新master 开始
+elected-leader master mymaster 192.168.8.170 6379
// 故障转移
+failover-state-select-slave master mymaster 192.168.8.170 6379
// 选择一个从节点作为master
+selected-slave slave 192.168.8.186:6381 192.168.8.186 6381 @ mymaster 192.168.8.170 6379
// 故障转移到 192.168.8.186:6381
+failover-state-send-slaveof-noone slave 192.168.8.186:6381 192.168.8.186 6381 @ mymaster 192.168.8.170 6379
+failover-state-wait-promotion slave 192.168.8.186:6381 192.168.8.186 6381 @ mymaster 192.168.8.170 6379
...
//保存配置文件
Sentinel new configuration saved on disk
//故障转移结束
+failover-end master mymaster 192.168.8.170 6379
// 切换master
+switch-master mymaster 192.168.8.170 6379 192.168.8.186 6381
//为新master 配置从节点
+slave slave 192.168.8.170:6379 192.168.8.170 6379 @ mymaster 192.168.8.186 6381
3.2上面提到过当master 下线后,各个sentinel会协商,选出一个sentinel 来进行故障转移,那这个sentinel 是如何选出来的呢?
raft算法
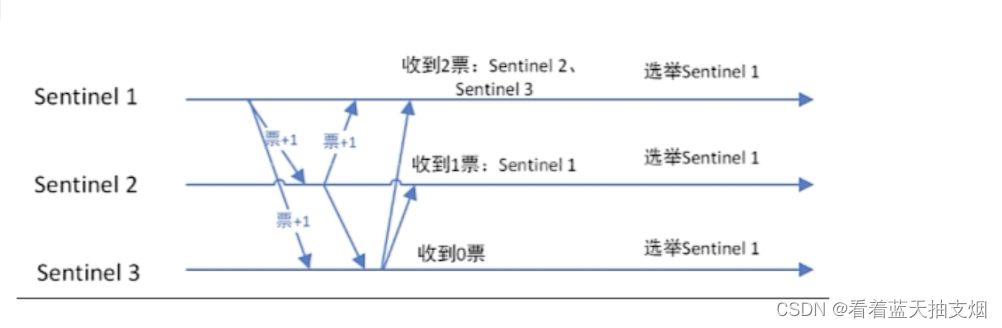
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法,Raft算法的基本思路是先到先得,即:
在一轮选举中,哨兵A向哨兵B发送称为领导者申请,如果哨兵B 没有同意过其他哨兵,则会同意A
称为领导者。
对应的日志为:
+vote-for-leader 哨兵A 20
哨兵B voted for 哨兵B 20
哨兵C voted for 哨兵A 20
4.上面提到用ratf算法选出一个sentinel,由这个sentinel 选出master进行故障转移,那是如何选出master的呢?
主要分为3步
-
新主登基
选出新的master的规则,剩余节点健康的前提下。 first 优先级比较:优先级高的则被选为master 在conf配置文件中,replica-proority 来设置,数字越小,优先级越高。 sencond 偏移量比较:如果优先级一样,则选择偏移量最大最大的 third RunID比较:如果优先级,偏移量都一致,则比较RunID,则选择RunId小的 -
群臣俯首
一朝天子一天臣
sentinel leader会对选出的新的master执行slave no one操作, 将其提升为master节点
sentinel leader向其他slave 发送命令,让剩余的slave称为新节点的slave -
旧主拜服
老master会来也要服
当老master重新上线后,他会成为新master的slave
sentinel leader会将老master降级为slave并恢复正常工作。
补充
故障转移操作均由sentinel自己独立完成,无需人工干预。
使用哨兵模式的建议
1.哨兵节点的数量为多个且为奇数,哨兵本身应该集群,保证高可用
2.各个哨兵节点的配置应该一致(比如 监控的master)
3.哨兵集群+主从复制 并不能保证数据不丢失