# -*- coding: utf-8 -*-# @Time : 2022/12/2 15:51# @Author : bridgekiller# @FileName: 1758C.py# @Software: PyCharm# @Blog :bridge-killer.blog.csdn.netimport os
import sys
import math
import random
import threading
from copy import deepcopy
from io import BytesIO, IOBase
from types import GeneratorType
from functools import lru_cache,reducefrom bisect import bisect_left, bisect_right
from collections import Counter, defaultdict, deque
from itertools import accumulate, combinations, permutations
from heapq import nsmallest, nlargest, heapify, heappop, heappush
from typing import Generic, Iterable, Iterator, TypeVar, Union, List
defdebug(func):defwrapper(*args,**kwargs):print('----------------')
res = func(*args,**kwargs)print('----------------')return res
return wrapper
defbootstrap(f, stack=[]):defwrappedfunc(*args,**kwargs):if stack:return f(*args,**kwargs)else:
to = f(*args,**kwargs)whileTrue:iftype(to)is GeneratorType:
stack.append(to)
to =next(to)else:
stack.pop()ifnot stack:break
to = stack[-1].send(to)return to
return wrappedfunc
classSegTree:'''
支持增量更新,覆盖更新,序列更新,任意RMQ操作
基于二叉树实现
初始化:O(1)
增量更新或覆盖更新的单次操作复杂度:O(log k)
序列更新的单次复杂度:O(n)
'''def__init__(self, f1, f2, l, r, v=0):'''
初始化线段树[left,right)
f1,f2示例:
线段和:
f1=lambda a,b:a+b
f2=lambda a,n:a*n
线段最大值:
f1=lambda a,b:max(a,b)
f2=lambda a,n:a
线段最小值:
f1=lambda a,b:min(a,b)
f2=lambda a,n:a
'''
self.ans = f2(v, r - l)
self.f1 = f1
self.f2 = f2
self.l = l # left
self.r = r # right
self.v = v # init value
self.lazy_tag =0# Lazy tag
self.left =None# SubTree(left,bottom)
self.right =None# SubTree(right,bottom)@propertydefmid_h(self):return(self.l + self.r)//2defcreate_subtrees(self):
midh = self.mid_h
ifnot self.left and midh > self.l:
self.left = SegTree(self.f1, self.f2, self.l, midh)ifnot self.right:
self.right = SegTree(self.f1, self.f2, midh, self.r)definit_seg(self, M):'''
将线段树的值初始化为矩阵Matrx
输入保证Matrx与线段大小一致
'''
m0 = M[0]
self.lazy_tag =0for a in M:if a != m0:breakelse:
self.v = m0
self.ans = self.f2(m0,len(M))return self.ans
self.v ='#'
midh = self.mid_h
self.create_subtrees()
self.ans = self.f1(self.left.init_seg(M[:midh - self.l]), self.right.init_seg(M[midh - self.l:]))return self.ans
defcover_seg(self, l, r, v):'''
将线段[left,right)覆盖为val
'''if self.v == v or l >= self.r or r <= self.l:return self.ans
if l <= self.l and r >= self.r:
self.v = v
self.lazy_tag =0
self.ans = self.f2(v, self.r - self.l)return self.ans
self.create_subtrees()if self.v !='#':if self.left:
self.left.v = self.v
self.left.ans = self.f2(self.v, self.left.r - self.left.l)if self.right:
self.right.v = self.v
self.right.ans = self.f2(self.v, self.right.r - self.right.l)
self.v ='#'# push up
self.ans = self.f1(self.left.cover_seg(l, r, v), self.right.cover_seg(l, r, v))return self.ans
definc_seg(self, l, r, v):'''
将线段[left,right)增加val
'''if v ==0or l >= self.r or r <= self.l:return self.ans
# self.ans = '?'if l <= self.l and r >= self.r:if self.v =='#':
self.lazy_tag += v
else:
self.v += v
self.ans += self.f2(v, self.r - self.l)return self.ans
self.create_subtrees()if self.v !='#':
self.left.v = self.v
self.left.ans = self.f2(self.v, self.left.r - self.left.l)
self.right.v = self.v
self.right.ans = self.f2(self.v, self.right.r - self.right.l)
self.v ='#'
self.pushdown()
self.ans = self.f1(self.left.inc_seg(l, r, v), self.right.inc_seg(l, r, v))return self.ans
definc_idx(self, idx, v):'''
increase idx by val
'''if v ==0or idx >= self.r or idx < self.l:return self.ans
if idx == self.l == self.r -1:
self.v += v
self.ans += self.f2(v,1)return self.ans
self.create_subtrees()if self.v !='#':
self.left.v = self.v
self.left.ans = self.f2(self.v, self.left.r - self.left.l)
self.right.v = self.v
self.right.ans = self.f2(self.v, self.right.r - self.right.l)
self.v ='#'
self.pushdown()
self.ans = self.f1(self.left.inc_idx(idx, v), self.right.inc_idx(idx, v))return self.ans
defpushdown(self):if self.lazy_tag !=0:if self.left:if self.left.v !='#':
self.left.v += self.lazy_tag
self.left.lazy_tag =0else:
self.left.lazy_tag += self.lazy_tag
self.left.ans += self.f2(self.lazy_tag, self.left.r - self.left.l)if self.right:if self.right.v !='#':
self.right.v += self.lazy_tag
self.right.lazy_tag =0else:
self.right.lazy_tag += self.lazy_tag
self.right.ans += self.f2(self.lazy_tag, self.right.r - self.right.l)
self.lazy_tag =0defquery(self, l, r):'''
查询线段[right,bottom)的RMQ
'''if l >= r:return0if l <= self.l and r >= self.r:return self.ans
if self.v !='#':return self.f2(self.v,min(self.r, r)-max(self.l, l))
midh = self.mid_h
anss =[]if l < midh:
anss.append(self.left.query(l, r))if r > midh:
anss.append(self.right.query(l, r))returnreduce(self.f1, anss)classSortedList:def__init__(self, iterable=[], _load=200):"""Initialize sorted list instance."""
values =sorted(iterable)
self._len = _len =len(values)
self._load = _load
self._lists = _lists =[values[i:i + _load]for i inrange(0, _len, _load)]
self._list_lens =[len(_list)for _list in _lists]
self._mins =[_list[0]for _list in _lists]
self._fen_tree =[]
self._rebuild =Truedef_fen_build(self):"""Build a fenwick tree instance."""
self._fen_tree[:]= self._list_lens
_fen_tree = self._fen_tree
for i inrange(len(_fen_tree)):if i | i +1<len(_fen_tree):
_fen_tree[i | i +1]+= _fen_tree[i]
self._rebuild =Falsedef_fen_update(self, index, value):"""Update `fen_tree[index] += value`."""ifnot self._rebuild:
_fen_tree = self._fen_tree
while index <len(_fen_tree):
_fen_tree[index]+= value
index |= index +1def_fen_query(self, end):"""Return `sum(_fen_tree[:end])`."""if self._rebuild:
self._fen_build()
_fen_tree = self._fen_tree
x =0while end:
x += _fen_tree[end -1]
end &= end -1return x
def_fen_findkth(self, k):"""Return a pair of (the largest `idx` such that `sum(_fen_tree[:idx]) <= k`, `k - sum(_fen_tree[:idx])`)."""
_list_lens = self._list_lens
if k < _list_lens[0]:return0, k
if k >= self._len - _list_lens[-1]:returnlen(_list_lens)-1, k + _list_lens[-1]- self._len
if self._rebuild:
self._fen_build()
_fen_tree = self._fen_tree
idx =-1for d inreversed(range(len(_fen_tree).bit_length())):
right_idx = idx +(1<< d)if right_idx <len(_fen_tree)and k >= _fen_tree[right_idx]:
idx = right_idx
k -= _fen_tree[idx]return idx +1, k
def_delete(self, pos, idx):"""Delete value at the given `(pos, idx)`."""
_lists = self._lists
_mins = self._mins
_list_lens = self._list_lens
self._len -=1
self._fen_update(pos,-1)del _lists[pos][idx]
_list_lens[pos]-=1if _list_lens[pos]:
_mins[pos]= _lists[pos][0]else:del _lists[pos]del _list_lens[pos]del _mins[pos]
self._rebuild =Truedef_loc_left(self, value):"""Return an index pair that corresponds to the first position of `value` in the sorted list."""ifnot self._len:return0,0
_lists = self._lists
_mins = self._mins
lo, pos =-1,len(_lists)-1while lo +1< pos:
mi =(lo + pos)>>1if value <= _mins[mi]:
pos = mi
else:
lo = mi
if pos and value <= _lists[pos -1][-1]:
pos -=1
_list = _lists[pos]
lo, idx =-1,len(_list)while lo +1< idx:
mi =(lo + idx)>>1if value <= _list[mi]:
idx = mi
else:
lo = mi
return pos, idx
def_loc_right(self, value):"""Return an index pair that corresponds to the last position of `value` in the sorted list."""ifnot self._len:return0,0
_lists = self._lists
_mins = self._mins
pos, hi =0,len(_lists)while pos +1< hi:
mi =(pos + hi)>>1if value < _mins[mi]:
hi = mi
else:
pos = mi
_list = _lists[pos]
lo, idx =-1,len(_list)while lo +1< idx:
mi =(lo + idx)>>1if value < _list[mi]:
idx = mi
else:
lo = mi
return pos, idx
defadd(self, value):"""Add `value` to sorted list."""
_load = self._load
_lists = self._lists
_mins = self._mins
_list_lens = self._list_lens
self._len +=1if _lists:
pos, idx = self._loc_right(value)
self._fen_update(pos,1)
_list = _lists[pos]
_list.insert(idx, value)
_list_lens[pos]+=1
_mins[pos]= _list[0]if _load + _load <len(_list):
_lists.insert(pos +1, _list[_load:])
_list_lens.insert(pos +1,len(_list)- _load)
_mins.insert(pos +1, _list[_load])
_list_lens[pos]= _load
del _list[_load:]
self._rebuild =Trueelse:
_lists.append([value])
_mins.append(value)
_list_lens.append(1)
self._rebuild =Truedefdiscard(self, value):"""Remove `value` from sorted list if it is a member."""
_lists = self._lists
if _lists:
pos, idx = self._loc_right(value)if idx and _lists[pos][idx -1]== value:
self._delete(pos, idx -1)defremove(self, value):"""Remove `value` from sorted list; `value` must be a member."""
_len = self._len
self.discard(value)if _len == self._len:raise ValueError('{0!r} not in list'.format(value))defpop(self, index=-1):"""Remove and return value at `index` in sorted list."""
pos, idx = self._fen_findkth(self._len + index if index <0else index)
value = self._lists[pos][idx]
self._delete(pos, idx)return value
defbisect_left(self, value):"""Return the first index to insert `value` in the sorted list."""
pos, idx = self._loc_left(value)return self._fen_query(pos)+ idx
defbisect_right(self, value):"""Return the last index to insert `value` in the sorted list."""
pos, idx = self._loc_right(value)return self._fen_query(pos)+ idx
defcount(self, value):"""Return number of occurrences of `value` in the sorted list."""return self.bisect_right(value)- self.bisect_left(value)def__len__(self):"""Return the size of the sorted list."""return self._len
def__getitem__(self, index):"""Lookup value at `index` in sorted list."""
pos, idx = self._fen_findkth(self._len + index if index <0else index)return self._lists[pos][idx]def__delitem__(self, index):"""Remove value at `index` from sorted list."""
pos, idx = self._fen_findkth(self._len + index if index <0else index)
self._delete(pos, idx)def__contains__(self, value):"""Return true if `value` is an element of the sorted list."""
_lists = self._lists
if _lists:
pos, idx = self._loc_left(value)return idx <len(_lists[pos])and _lists[pos][idx]== value
returnFalsedef__iter__(self):"""Return an iterator over the sorted list."""return(value for _list in self._lists for value in _list)def__reversed__(self):"""Return a reverse iterator over the sorted list."""return(value for _list inreversed(self._lists)for value inreversed(_list))def__repr__(self):"""Return string representation of sorted list."""return'SortedList({0})'.format(list(self))
T = TypeVar('T')classSortedSet(Generic[T]):
BUCKET_RATIO =50
REBUILD_RATIO =170def_build(self, a=None)->None:"Evenly divide `a` into buckets."if a isNone: a =list(self)
size = self.size =len(a)
bucket_size =int(math.ceil(math.sqrt(size / self.BUCKET_RATIO)))
self.a =[a[size * i // bucket_size: size *(i +1)// bucket_size]for i inrange(bucket_size)]def__init__(self, a: Iterable[T]=[])->None:"Make a new SortedSet from iterable. / O(N) if sorted and unique / O(N log N)"
a =list(a)ifnotall(a[i]< a[i +1]for i inrange(len(a)-1)):
a =sorted(set(a))
self._build(a)def__iter__(self)-> Iterator[T]:for i in self.a:for j in i:yield j
def__reversed__(self)-> Iterator[T]:for i inreversed(self.a):for j inreversed(i):yield j
def__len__(self)->int:return self.size
def__repr__(self)->str:return"SortedSet"+str(self.a)def__str__(self)->str:
s =str(list(self))return"{"+ s[1:len(s)-1]+"}"def_find_bucket(self, x: T)-> List[T]:"Find the bucket which should contain x. self must not be empty."for a in self.a:if x <= a[-1]:return a
return a
def__contains__(self, x: T)->bool:if self.size ==0:returnFalse
a = self._find_bucket(x)
i = bisect_left(a, x)return i !=len(a)and a[i]== x
defadd(self, x: T)->bool:"Add an element and return True if added. / O(√N)"if self.size ==0:
self.a =[[x]]
self.size =1returnTrue
a = self._find_bucket(x)
i = bisect_left(a, x)if i !=len(a)and a[i]== x:returnFalse
a.insert(i, x)
self.size +=1iflen(a)>len(self.a)* self.REBUILD_RATIO:
self._build()returnTruedefdiscard(self, x: T)->bool:"Remove an element and return True if removed. / O(√N)"if self.size ==0:returnFalse
a = self._find_bucket(x)
i = bisect_left(a, x)if i ==len(a)or a[i]!= x:returnFalse
a.pop(i)
self.size -=1iflen(a)==0: self._build()returnTruedeflt(self, x: T)-> Union[T,None]:"Find the largest element < x, or None if it doesn't exist."for a inreversed(self.a):if a[0]< x:return a[bisect_left(a, x)-1]defle(self, x: T)-> Union[T,None]:"Find the largest element <= x, or None if it doesn't exist."for a inreversed(self.a):if a[0]<= x:return a[bisect_right(a, x)-1]defgt(self, x: T)-> Union[T,None]:"Find the smallest element > x, or None if it doesn't exist."for a in self.a:if a[-1]> x:return a[bisect_right(a, x)]defge(self, x: T)-> Union[T,None]:"Find the smallest element >= x, or None if it doesn't exist."for a in self.a:if a[-1]>= x:return a[bisect_left(a, x)]def__getitem__(self, x:int)-> T:"Return the x-th element, or IndexError if it doesn't exist."if x <0: x += self.size
if x <0:raise IndexError
for a in self.a:if x <len(a):return a[x]
x -=len(a)raise IndexError
defindex(self, x: T)->int:"Count the number of elements < x."
ans =0for a in self.a:if a[-1]>= x:return ans + bisect_left(a, x)
ans +=len(a)return ans
defindex_right(self, x: T)->int:"Count the number of elements <= x."
ans =0for a in self.a:if a[-1]> x:return ans + bisect_right(a, x)
ans +=len(a)return ans
BUFSIZE =4096classFastIO(IOBase):
newlines =0def__init__(self,file):
self._fd =file.fileno()
self.buffer= BytesIO()
self.writable ="x"infile.mode or"r"notinfile.mode
self.write = self.buffer.write if self.writable elseNonedefread(self):whileTrue:
b = os.read(self._fd,max(os.fstat(self._fd).st_size, BUFSIZE))ifnot b:break
ptr = self.buffer.tell()
self.buffer.seek(0,2), self.buffer.write(b), self.buffer.seek(ptr)
self.newlines =0return self.buffer.read()defreadline(self):while self.newlines ==0:
b = os.read(self._fd,max(os.fstat(self._fd).st_size, BUFSIZE))
self.newlines = b.count(b"\n")+(not b)
ptr = self.buffer.tell()
self.buffer.seek(0,2), self.buffer.write(b), self.buffer.seek(ptr)
self.newlines -=1return self.buffer.readline()defflush(self):if self.writable:
os.write(self._fd, self.buffer.getvalue())
self.buffer.truncate(0), self.buffer.seek(0)classIOWrapper(IOBase):def__init__(self,file):
self.buffer= FastIO(file)
self.flush = self.buffer.flush
self.writable = self.buffer.writable
self.write =lambda s: self.buffer.write(s.encode("ascii"))
self.read =lambda: self.buffer.read().decode("ascii")
self.readline =lambda: self.buffer.readline().decode("ascii")
sys.stdin = IOWrapper(sys.stdin)
sys.stdout = IOWrapper(sys.stdout)input=lambda: sys.stdin.readline().rstrip("\r\n")defI():returninput()defII():returnint(input())defMI():returnmap(int,input().split())defLI():returnlist(input().split())defLII():returnlist(map(int,input().split()))defGMI():returnmap(lambda x:int(x)-1,input().split())defLGMI():returnlist(map(lambda x:int(x)-1,input().split()))defsolve():
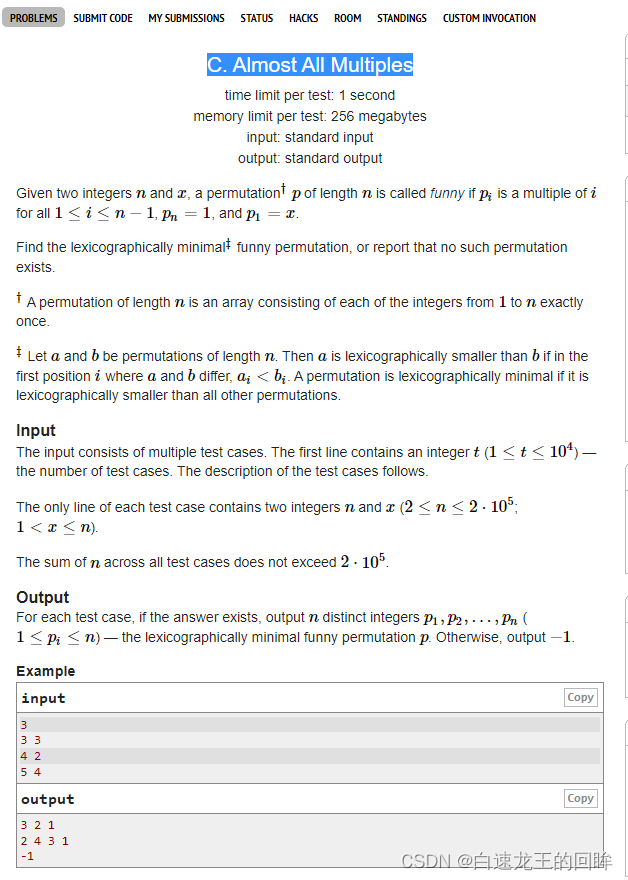
n, x = LII()if n % x:# n想放到x上returnprint(-1)
a =list(range(1, n +1))if n == x:
a[0], a[-1]= a[-1], a[0]returnprint(*a)# 1和x放了,n就放到x那里
a[0], a[-1], a[x -1]= x,1, n
x -=1# 获得最小字典序for i inrange(1, n-1):# i >= x# a[i] and a[x]是可以交换的# n能往后挪就往后挪if a[x]%(i +1)==0and a[i]%(x +1)==0:
a[i], a[x]= a[x], a[i]
x = i
print(*a)if __name__ =='__main__':for _ inrange(II()):
solve()
为了完成本关任务,你需要掌握: 1、数据库( MySQL )建表。 2、Mysql 数据导入至 HDFS 中。
数据库( MySQL )建表
用命令进入 MySQL 客户端。
mysql -uroot -p123123 -h127.0.0.1
创建数据库hdfsdb(格式默认为utf8),并在数据库内建立表student,其表结构如下:
mys…
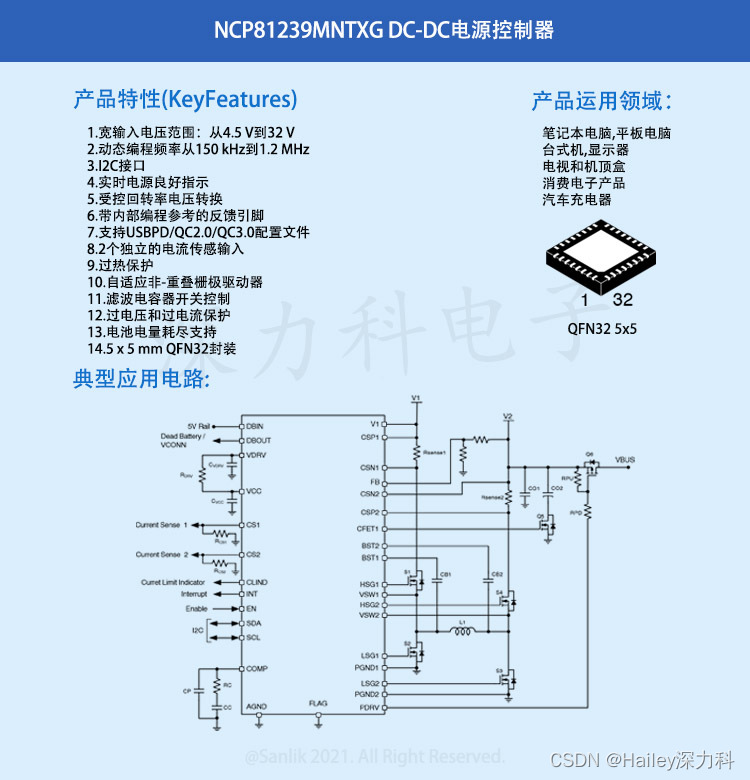
NCP81239MNTXG USB 功率传递 (PD) 控制器是一款同步降压/升压控制器,适用于为笔记本电脑、平板电脑、台式系统以及很多使用 USB PD 标准和 C−Type 线缆的其他消费设备提供电池电压或适配器电压到所需电源轨的转换。结合使用 USB PD 或 C−Type 接口控制器时完全符合…


![[Linux打怪升级之路]-秒懂进程地址空间](https://img-blog.csdnimg.cn/ac9fcdad7cff45ae857573fa26e180f4.png)

![[操作系统笔记]基本分段存储管理](https://img-blog.csdnimg.cn/7a92a4177f8145b0b7c3772d121742b5.png)