激光点云3D目标检测算法之CenterPoint
本文首发于公众号【DeepDriving】,欢迎关注。
前言
CenterPoint是CVPR 2021的论文《Center-based 3D Object Detection and Tracking》中提出的一个激光点云3D目标检测与跟踪算法框架,与以往算法不同的是,该算法不用边界框而是提出用关键点来表示、检测和跟踪3D目标:在检测流程中,第一阶段先用一个关键点检测器去检测目标的中心点,然后再用中心点特征回归出目标的3D尺寸、朝向和速度等属性,第二阶段再基于该目标额外的点特征去对这些属性进行优化;目标跟踪则被简化为一个简单的最近点匹配过程。CenterPoint提出的3D目标检测与跟踪算法非常简单而高效,在nuScenes和Waymo数据集上都取得了SOTA的性能表现。
论文链接:https://arxiv.org/pdf/2006.11275.pdf
代码链接:https://github.com/tianweiy/CenterPoint
本文将对CenterPoint算法进行简要的解读。
预备知识
3D目标检测
假设用
P
=
{
(
x
,
y
,
z
,
r
)
i
}
\mathcal{P} =\left \{ (x,y,z,r)_{i} \right \}
P={(x,y,z,r)i}来表示一帧无序的点云,其中
(
x
,
y
,
z
)
(x,y,z)
(x,y,z)表示3D位置,
r
r
r表示反射强度。3D目标检测的目的是从点云中预测一系列在鸟瞰图视角下用于表示3D目标的边界框
B
=
{
b
k
}
\mathcal{B}=\left \{b_{k}\right \}
B={bk},每个边界框可以表示为
b
=
(
u
,
v
,
d
,
w
,
l
,
h
,
α
)
b=(u,v,d,w,l,h,\alpha)
b=(u,v,d,w,l,h,α),其中
(
u
,
v
,
d
)
(u,v,d)
(u,v,d)表示目标相对于地平面的中心点位置,
(
w
,
l
,
h
)
(w,l,h)
(w,l,h)表示目标的3D尺寸,
α
\alpha
α表示目标的朝向角。
目前主流的3D目标检测算法一般都是先通过一个3D特征编码器将无序的点云划分为规则的单元格(Voxel或Pillar),然后用基于点的网络(PointNet/PointNet++)去提取每个单元格中所有点的特征,再通过池化操作保留最主要的特征。接下来这些特征被送入一个骨干网络(VoxelNet或PointPillars)用于生成特征图
M
∈
R
W
×
L
×
F
\mathbf{M} \in \mathbb{R} ^{W\times L\times F}
M∈RW×L×F,其中
W
,
L
,
F
W,L,F
W,L,F分别表示宽、长和通道数,基于这个特征图,一个单阶段或者二阶段的检测头就可以从中生成目标检测结果了。之前anchor-based的3D目标检测算法(比如PointPillars)都需要基于预定义的anchor去回归目标的位置,但是3D物体通常具有各种各样的尺寸和朝向,这就导致需要定义数量众多的anchor用于模型的训练和推理,从而增加大量的计算负担。另外,基于anchor的方法也不能很精确地回归出3D目标的尺寸和朝向。

如果对3D目标检测流程不了解的可以先看一下PointPillars,算法的结构如下图所示:
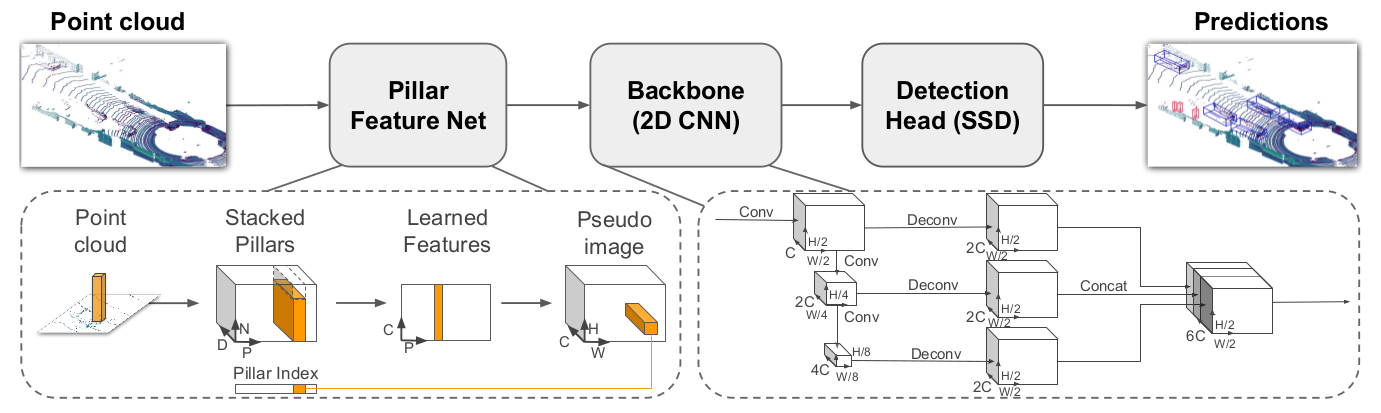
算法解读可以参考我之前写的这篇文章:
激光点云3D目标检测算法之PointPillars
基于中心点的2D目标检测算法CenterNet
CenterPoint延续了CenterNet基于中心点做目标检测的思想。CenterNet将2D目标检测当做一个标准的关键点估计问题,将目标表示为一个在其边界框中心位置的单独点,其他的一些属性比如目标尺寸、维度、朝向和姿态等则直接从这个中心点位置的图像特征中进行回归。该模型将图像输入到一个全卷积网络中用来生成热力图,热力图的峰值位置即为目标的中心,每个峰值位置的图像特征用来预测目标边界框的宽度和高度。
如果对CenterNet目标检测算法还不了解可以先看一看我之前写的这篇文章,这里就不做过多介绍了。
经典的目标检测算法:CenterNet
CenterPoint模型
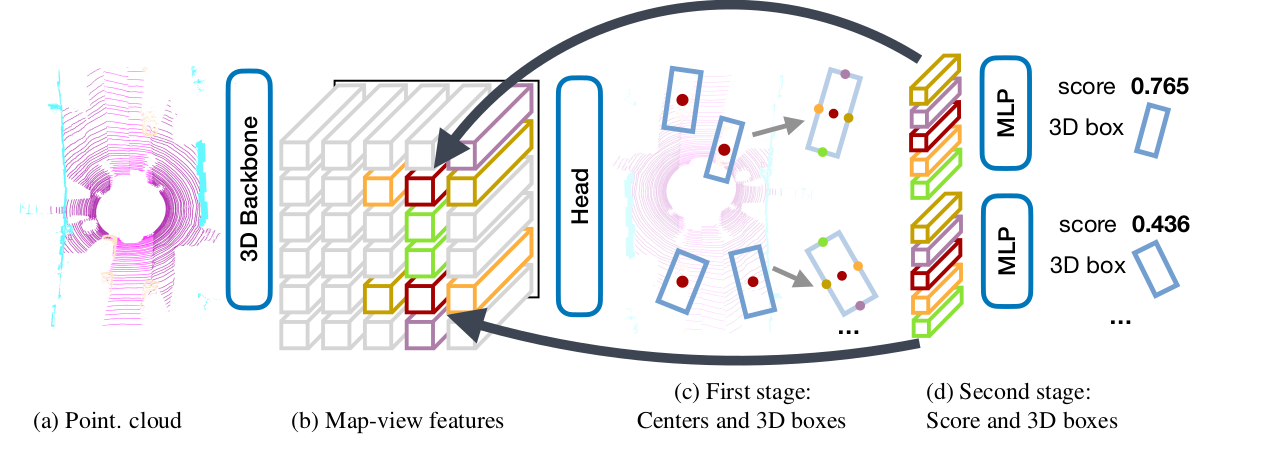
下图是CenterPoint算法的框架,首先通过VoxelNet或PointPillars等标准的3D骨干网络从点云中提取鸟瞰图下的特征图,然后用基于2D卷积神经网络实现的检测头去找到目标的中心并用中心特征回归出3D边界框的属性。
中心点热力图
CenterPoint中心点热力图的生成方式与CenterNet基本类似,这个回归分支会生成K个通道的热力图
Y
^
\hat{Y}
Y^,每个通道表示一个类别。在训练过程中,用一个2D高斯函数将标注的目标的真实3D中心映射到鸟瞰图上去,损失函数用的是Focal Loss。与图像相比,在鸟瞰图上的目标要稀疏很多而且一个目标所占的面积很小,不存在因透视变换引起的近大远小的现象(一个近处的物体可能就占了一大半的图像区域)。为了解决这个问题,作者扩大了在每个目标中心呈现的高斯峰值来增加对目标热图
Y
Y
Y的正向监督,设置高斯函数的半径为
δ = m a x ( f ( w l ) , τ ) \delta = max(f(wl),\tau ) δ=max(f(wl),τ)
其中
τ
=
2
\tau=2
τ=2是最小允许的半径,
f
f
f是在CornerNet中定义的半径计算函数。
目标属性回归
除了中心点,还需要3D尺寸和朝向等信息才能完整地构成一个3D边界框来表示一个目标。CenterPoint从中心特征中去回归下面的几个目标属性:
- 位置修正值
o
∈
R
2
o \in \mathbb{R}^2
o∈R2,用于减少由于体素化和骨干网络中的
stride引起的量化误差。 - 离地面的高度
h
g
∈
R
h_{g} \in \mathbb{R}
hg∈R,用于帮助在
3D空间中定位目标和添加因为映射到鸟瞰图而丢失的高度信息。 3D尺寸 s ∈ R 3 s \in \mathbb{R}^3 s∈R3,目标的长宽高信息,回归时用对数函数表示,因为实际的物体可能会有各种大小的尺寸。- 朝向角 ( s i n ( α ) , c o s ( α ) ) ∈ R 2 (sin(\alpha),cos(\alpha))\in \mathbb{R}^2 (sin(α),cos(α))∈R2,用朝向角的正弦和余弦值作为连续的回归目标。
速度估计与目标跟踪
为了对目标进行跟踪,CenterPoint添加了一个额外的回归分支用于预测每个检测到的物体的二维速度
v
∈
R
2
\mathbf{v} \in \mathbb{R} ^2
v∈R2。与其他属性不同的是,速度估计需要前一帧和当前帧的特征图作为输入,目的是预测目标在当前帧与在前一帧中的位置偏移。与回归其他目标属性一样,速度估计也使用
L
1
L_{1}
L1损失函数用于监督训练。
在推理阶段,把目标在当前帧中的中心点通过负速度估计的方法映射回前一帧中,然后用最近距离匹配的方式将它们与已跟踪的目标进行匹配。与SORT目标跟踪算法一样,如果一个目标连续3帧没有匹配成功就将其删除。下图是跟踪算法的伪代码,整个流程比较简单。


SORT目标跟踪算法的原理可以参考我之前写的这篇文章:
多目标跟踪算法之SORT
二阶段CenterPoint
前面介绍的一阶段CenterPoint算法用基于中心点的方法去检测目标并回归得到目标的属性信息,这种检测头非常简单而且效果比基于anchor的检测方法效果好。但是由于目标所有的属性信息都是从目标中心的特征推断出来的,因此可能因缺少足够的特征信息对目标进行精准的定位,因此作者又设计了一个轻量级的点特征提取网络对目标的属性进行二阶段的优化。
在这个阶段中,需要从第一个阶段预测出的边界框每个面的3D中心去提取点特征。考虑到边界框的中心、顶部和顶部的中心在鸟瞰图中会被投影到同一个点,因此作者仅考虑边界框的中心和四个向外面的中心。首先从骨干网络输出的特征图
M
\mathbf{M}
M中通过双线性插值来提取每个点的特征,然后将提取的特征堆叠起来送入一个MLP网络中用来对前一阶段预测出的边界框进行优化。
这个阶段还会预测一个置信度分数,训练过程中的计算公式如下:
I = m i n ( 1 , m a x ( 0 , 2 × I o U t − 0.5 ) ) I=min(1,max(0,2 \times IoU_{t}-0.5)) I=min(1,max(0,2×IoUt−0.5))
其中
I
o
U
t
IoU_{t}
IoUt表示第
t
t
t个候选框与ground-truth之间的3D IoU值。损失函数采用二值交叉熵损失,公式如下:
L s c o r e = − I t l o g ( I ^ t ) − ( 1 − I t ) l o g ( 1 − I ^ t ) L_{score} = -I_{t}log(\hat{I}_{t}) - (1-I_{t})log(1-\hat{I}_{t}) Lscore=−Itlog(I^t)−(1−It)log(1−I^t)
其中
I
^
t
\hat{I}_{t}
I^t表示预测的置信度分数。在推理过程中,置信度分数
的计算方式如下:
Q ^ t = Y ^ t ∗ I ^ t \hat{Q}_{t}=\sqrt{\hat{Y}_{t}*\hat{I}_{t}} Q^t=Y^t∗I^t
其中 Y ^ t = m a x 0 ≤ k ≤ K Y ^ p , k \hat{Y}_{t}=max_{0\le k \le K}\hat{Y}_{p,k} Y^t=max0≤k≤KY^p,k和 I ^ t \hat{I}_{t} I^t分别表示第一阶段和第二阶段对目标 t t t预测出的置信度分数。
总结
CenterPoint可以说是CenterNet在3D目标检测任务上的延续,继续沿用简单而优雅的方式来解决目标检测问题,所提出的center-based检测头可以直接替换之前VoxelNet和PointPillars等anchor-based算法中的检测头,极大地简化训练和推理过程,并且检测效果更好。
参考资料
- Center-based 3D Object Detection and Tracking