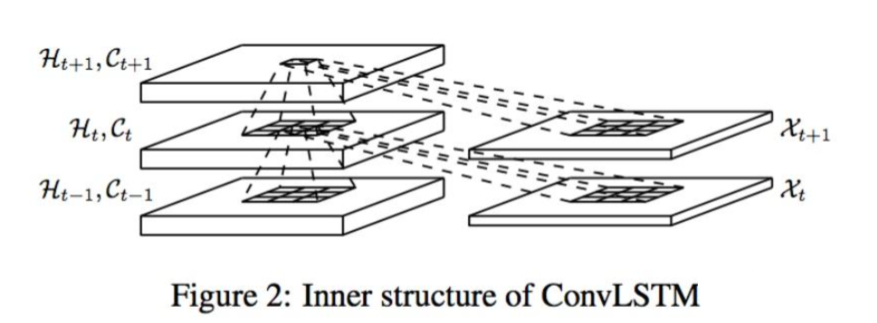
最近在研究时序图像分类问题,需要用到convLSTM层提取特征,所以在此仔细分析一下keras.layers.ConvLSTM2D层的使用方法。深度学习框架是tensorflow
官方文档:recurrent/#convlstm2d - Keras 中文文档
下面这部分内容摘自官方文档
ConvLSTM2D
keras.layers.ConvLSTM2D(filters,
kernel_size,
strides=(1, 1),
padding='valid',
data_format=None,
dilation_rate=(1, 1),
activation='tanh',
recurrent_activation='hard_sigmoid',
use_bias=True,
kernel_initializer='glorot_uniform',
recurrent_initializer='orthogonal',
bias_initializer='zeros',
unit_forget_bias=True,
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
return_sequences=False,
go_backwards=False,
stateful=False,
dropout=0.0,
recurrent_dropout=0.0)
卷积 LSTM。
它类似于 LSTM 层,但输入变换和循环变换都是卷积的。
参数
- filters: 整数,输出空间的维度 (即卷积中滤波器的输出数量)。
- kernel_size: 一个整数,或者 n 个整数表示的元组或列表, 指明卷积窗口的维度。
- strides: 一个整数,或者 n 个整数表示的元组或列表, 指明卷积的步长。 指定任何 stride 值 != 1 与指定
dilation_rate值 != 1 两者不兼容。 - padding:
"valid"或"same"之一 (大小写敏感)。 - data_format: 字符串,
channels_last(默认) 或channels_first之一。 输入中维度的顺序。channels_last对应输入尺寸为(batch, time, ..., channels),channels_first对应输入尺寸为(batch, time, channels, ...)。 它默认为从 Keras 配置文件~/.keras/keras.json中 找到的image_data_format值。 如果你从未设置它,将使用"channels_last"。 - dilation_rate: 一个整数,或 n 个整数的元组/列表,指定用于膨胀卷积的膨胀率。 目前,指定任何
dilation_rate值 != 1 与指定 stride 值 != 1 两者不兼容。 - activation: 要使用的激活函数 (详见 activations)。 如果传入 None,则不使用激活函数 (即 线性激活:
a(x) = x)。 - recurrent_activation: 用于循环时间步的激活函数 (详见 activations)。
- use_bias: 布尔值,该层是否使用偏置向量。
- kernel_initializer:
kernel权值矩阵的初始化器, 用于输入的线性转换 (详见 initializers)。 - recurrent_initializer:
recurrent_kernel权值矩阵 的初始化器,用于循环层状态的线性转换 (详见 initializers)。 - bias_initializer:偏置向量的初始化器 (详见initializers).
- unit_forget_bias: 布尔值。 如果为 True,初始化时,将忘记门的偏置加 1。 将其设置为 True 同时还会强制
bias_initializer="zeros"。 这个建议来自 Jozefowicz et al.。 - kernel_regularizer: 运用到
kernel权值矩阵的正则化函数 (详见 regularizer)。 - recurrent_regularizer: 运用到
recurrent_kernel权值矩阵的正则化函数 (详见 regularizer)。 - bias_regularizer: 运用到偏置向量的正则化函数 (详见 regularizer)。
- activity_regularizer: 运用到层输出(它的激活值)的正则化函数 (详见 regularizer)。
- kernel_constraint: 运用到
kernel权值矩阵的约束函数 (详见 constraints)。 - recurrent_constraint: 运用到
recurrent_kernel权值矩阵的约束函数 (详见 constraints)。 - bias_constraint: 运用到偏置向量的约束函数 (详见 constraints)。
- return_sequences: 布尔值。是返回输出序列中的最后一个输出,还是全部序列。
- go_backwards: 布尔值 (默认 False)。 如果为 True,则向后处理输入序列并返回相反的序列。
- stateful: 布尔值 (默认 False)。 如果为 True,则批次中索引 i 处的每个样品的最后状态 将用作下一批次中索引 i 样品的初始状态。
- dropout: 在 0 和 1 之间的浮点数。 单元的丢弃比例,用于输入的线性转换。
- recurrent_dropout: 在 0 和 1 之间的浮点数。 单元的丢弃比例,用于循环层状态的线性转换。
输入尺寸
- 如果 data_format=‘channels_first’, 输入 5D 张量,尺寸为:
(samples,time, channels, rows, cols)。 - 如果 data_format=‘channels_last’, 输入 5D 张量,尺寸为:
(samples,time, rows, cols, channels)。
输出尺寸
- 如果return_sequences =true
- 如果 data_format=‘channels_first’,返回 5D 张量,尺寸为:
(samples, time, filters, output_row, output_col)。 - 如果 data_format=‘channels_last’,返回 5D 张量,尺寸为:
(samples, time, output_row, output_col, filters)。
- 如果 data_format=‘channels_first’,返回 5D 张量,尺寸为:
- 否则,
- 如果 data_format =‘channels_first’,返回 4D 张量,尺寸为:
(samples, filters, output_row, output_col)。 - 如果 data_format=‘channels_last’,返回 4D 张量,尺寸为:
(samples, output_row, output_col, filters)。
- 如果 data_format =‘channels_first’,返回 4D 张量,尺寸为:
o_row 和 o_col 取决于 filter 和 padding 的尺寸。
为了更深度了解ConvLSTM2D层的用法,我在Keras官方仓库里找到了ConvLSTM2D层的测试程序:
keras/conv_lstm_test.py at master · keras-team/keras · GitHub
下面我们基于官方例程,看一下如何调用此网络层
测试例程1
def test_conv_lstm(self, data_format, return_sequences):
# 卷积核的长和宽
num_row = 3
num_col = 3
# 卷积核的数量=输出的通道数
filters = 2
# 样本数量
num_samples = 1
# 输入数据的通道数C
input_channel = 2
# 输入图像的大小H*W
input_num_row = 5
input_num_col = 5
# 输入图像时间序列的长度S
sequence_len = 2
# 参数:data_format: 字符串, "channels_last" (默认) 或 "channels_first"
# 代表输入数据维度的顺序,channels_last代表通道维在最后一维
if data_format == "channels_first":
inputs = np.random.rand(
num_samples,
sequence_len,
input_channel,
input_num_row,
input_num_col,
)
else:
inputs = np.random.rand(
num_samples,
sequence_len,
input_num_row,
input_num_col,
input_channel,
)
# test for return state:
x = keras.Input(batch_shape=inputs.shape)
# 参数:return_sequences,布尔值。是返回输出序列中的最后一个输出,还是全部序列
# 参数:stateful,布尔值 (默认 False)。 如果为 True,
# 则批次中索引 i 处的每个样品的最后状态 将用作下一批次中索引 i 样品的初始状态。
# 参数:return_state:,布尔值。除了输出之外是否返回最后一个状态。
kwargs = {
"data_format": data_format,
"return_sequences": return_sequences,
"return_state": True,
"stateful": True,
"filters": filters,
"kernel_size": (num_row, num_col),
"padding": "valid",
}
layer = keras.layers.ConvLSTM2D(**kwargs)
layer.build(inputs.shape)
outputs = layer(x)
# 返回输出和状态变量
_, states = outputs[0], outputs[1:]
self.assertEqual(len(states), 2)
# states[0] 表示整个神经网络中的第一个状态变量
model = keras.models.Model(x, states[0])
state = model.predict(inputs)
self.assertAllClose(
keras.backend.eval(layer.states[0]), state, atol=1e-4
)
# test for output shape:
test_utils.layer_test(
keras.layers.ConvLSTM2D,
kwargs={
"data_format": data_format,
"return_sequences": return_sequences,
"filters": filters,
"kernel_size": (num_row, num_col),
"padding": "valid",
},
input_shape=inputs.shape,
)
测试例程2
def test_conv_lstm_statefulness(self):
# Tests for statefulness
num_row = 3
num_col = 3
filters = 2
num_samples = 1
input_channel = 2
input_num_row = 5
input_num_col = 5
sequence_len = 2
inputs = np.random.rand(
num_samples,
sequence_len,
input_num_row,
input_num_col,
input_channel,
)
with self.cached_session():
model = keras.models.Sequential()
# "return_sequences" = False,只返回最后一个预测结果
# "stateful": True, 上次预测得到的记忆输出作为下次记忆的输入
kwargs = {
"data_format": "channels_last",
"return_sequences": False,
"filters": filters,
"kernel_size": (num_row, num_col),
"stateful": True,
"batch_input_shape": inputs.shape,
"padding": "same",
}
layer = keras.layers.ConvLSTM2D(**kwargs)
model.add(layer)
model.compile(optimizer="sgd", loss="mse")
out1 = model.predict(np.ones_like(inputs))
# train once so that the states change
model.train_on_batch(
np.ones_like(inputs), np.random.random(out1.shape)
)
out2 = model.predict(np.ones_like(inputs))
# 如果状态变量没有重置,2个的输出结果是不同的
self.assertNotEqual(out1.max(), out2.max())
# 重置层的状态,再次进行预测,输出结果应该是相同的
layer.reset_states()
out3 = model.predict(np.ones_like(inputs))
self.assertNotEqual(out3.max(), out2.max())
# check that container-level reset_states() works
model.reset_states()
out4 = model.predict(np.ones_like(inputs))
self.assertAllClose(out3, out4, atol=1e-5)
# check that the call to `predict` updated the states
out5 = model.predict(np.ones_like(inputs))
self.assertNotEqual(out4.max(), out5.max())
测试例程3
def test_conv_lstm_regularizers(self):
# check regularizers
num_row = 3
num_col = 3
filters = 2
num_samples = 1
input_channel = 2
input_num_row = 5
input_num_col = 5
sequence_len = 2
inputs = np.random.rand(
num_samples,
sequence_len,
input_num_row,
input_num_col,
input_channel,
)
# 添加权值矩阵的L2正则化函数
#
with self.cached_session():
kwargs = {
"data_format": "channels_last",
"return_sequences": False,
"kernel_size": (num_row, num_col),
"stateful": True,
"filters": filters,
"batch_input_shape": inputs.shape,
"kernel_regularizer": keras.regularizers.L1L2(l1=0.01),
"recurrent_regularizer": keras.regularizers.L1L2(l1=0.01),
"activity_regularizer": "l2",
"bias_regularizer": "l2",
"kernel_constraint": "max_norm",
"recurrent_constraint": "max_norm",
"bias_constraint": "max_norm",
"padding": "same",
}
layer = keras.layers.ConvLSTM2D(**kwargs)
layer.build(inputs.shape)
self.assertEqual(len(layer.losses), 3)
layer(keras.backend.variable(np.ones(inputs.shape)))
self.assertEqual(len(layer.losses), 4)
测试例程4
def test_conv_lstm_with_initial_state(self):
num_samples = 32
sequence_len = 5
encoder_inputs = keras.layers.Input((None, 32, 32, 3))
encoder = keras.layers.ConvLSTM2D(
filters=32,
kernel_size=(3, 3),
padding="same",
return_sequences=False,
return_state=True,
)
_, state_h, state_c = encoder(encoder_inputs)
encoder_states = [state_h, state_c]
decoder_inputs = keras.layers.Input((None, 32, 32, 4))
decoder_lstm = keras.layers.ConvLSTM2D(
filters=32,
kernel_size=(3, 3),
padding="same",
return_sequences=False,
return_state=False,
)
decoder_outputs = decoder_lstm(
decoder_inputs, initial_state=encoder_states
)
output = keras.layers.Conv2D(
1, (3, 3), padding="same", activation="relu"
)(decoder_outputs)
model = keras.Model([encoder_inputs, decoder_inputs], output)
model.compile(
optimizer="sgd",
loss="mse",
run_eagerly=test_utils.should_run_eagerly(),
)
x_1 = np.random.rand(num_samples, sequence_len, 32, 32, 3)
x_2 = np.random.rand(num_samples, sequence_len, 32, 32, 4)
y = np.random.rand(num_samples, 32, 32, 1)
model.fit([x_1, x_2], y)
model.predict([x_1, x_2])
总结
对于例程和例程4目前我还不是很理解,没有实际用过。但是按照我个人的理解ConvLSTM2D有如下几个重要的参数:
-
filters: 整数,输出空间的维度
-
kernel_size: 一个整数,或者 n 个整数表示的元组或列表, 指明卷积窗口的维度
-
return_sequences,布尔值。是返回输出序列中的最后一个输出,还是全部序列
-
return_state:,布尔值。除了输出之外是否返回最后一个状态。
假设输入图像的维度为(T*H*W*C),基于上述参数总结了3个如下用法:
-
预测:输出图像时间序列的下一张图像预测结果(H*W*C1)
x = ConvLSTM2D(filters=32, kernel_size=(3, 3), padding='same', return_sequences= return_sequences=False) -
多层网络:构建多层convLSTM网络(T*H*W*C1)
x = ConvLSTM2D(filters=32, kernel_size=(3, 3), padding='same', return_sequences=True)(inputs) x = ConvLSTM2D(filters=32, kernel_size=(3, 3), padding='same', return_sequences=True)(x) -
特征提取:提取输入影像的时间维度特征,使用记忆变量C作为输出(H*W*C1)
_, _, state_c = ConvLSTM2D(filters=32, kernel_size=(1, 1),activation='relu',padding='same',return_sequences=False,return_state=True)(input_tensor)