开发环境
- Windows 10
- Rust 1.69.0

- VS Code 1.78.2
项目工程
这里继续沿用上次工程rust-demo
通用数据类型
我们使用泛型来为函数签名或结构等项目创建定义,然后我们可以将其用于许多不同的具体数据类型。让我们首先看看如何使用泛型来定义函数、结构、枚举和方法。然后我们将讨论泛型如何影响代码性能。
函数的泛型定义
当定义一个使用泛型的函数时,我们将泛型放在函数的签名中,在这里我们通常会指定参数和返回值的数据类型。这样做使我们的代码更加灵活,为我们的函数的调用者提供更多的功能,同时防止代码重复。
继续我们的最大函数,示例4显示了两个函数,它们都能找到一个片断中的最大值。然后我们将把它们合并成一个使用泛型的函数。
文件名:src/main.rs
fn largest_i32(list: &[i32]) -> &i32 { // largest_i32 函数
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn largest_char(list: &[char]) -> &char { // largest_char 函数
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest_i32(&number_list);
println!("The largest number is {}", result);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest_char(&char_list);
println!("The largest char is {}", result);
}示例4:两个函数只在名称和签名中的类型上有所不同
largest_i32函数就是我们在上一节示例3中提取的那个函数,它可以找到一个片断中最大的i32。biggest_char函数找到一个片断中最大的char。这些函数体有相同的代码,所以让我们通过在一个函数中引入一个通用类型参数来消除重复。
为了在一个新的单一函数中对类型进行参数化,我们需要对类型参数进行命名,就像我们对函数的值参数所做的那样。你可以使用任何标识符作为类型参数名。但是我们将使用T,因为按照惯例,Rust中的类型参数名很短,通常只有一个字母,而且Rust的类型命名惯例是UpperCamelCase(驼峰命名法)。T是 "类型 "的简称,是大多数Rust程序员的默认选择。
当我们在函数主体中使用参数时,我们必须在签名中声明参数名称,以便编译器知道这个名称的含义。同样地,当我们在函数签名中使用一个类型参数名时,我们必须在使用它之前声明类型参数名。为了定义通用的largest,将类型名称声明放在角括号内,<>,在函数名称和参数列表之间,像这样:
fn largest<T>(list: &[T]) -> &T {我们把这个定义理解为:函数largest在某种类型T上是通用的。这个函数有一个名为list的参数,它是一个类型为T的值的切片。largest将返回一个对同一类型T的值的引用。
示例5显示了在其签名中使用通用数据类型的组合largest定义。该清单还显示了我们如何用i32值的切片或char值调用该函数。注意,这段代码还不能编译,但我们将在本章后面修复它。
文件名: src/main.rs
fn largest<T>(list: &[T]) -> &T { // largest函数的泛型定义
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list); // 调用largest函数
println!("The largest number is {}", result);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {}", result);
}示例5:使用通用类型参数的largest,这还不能编译
编译
cargo run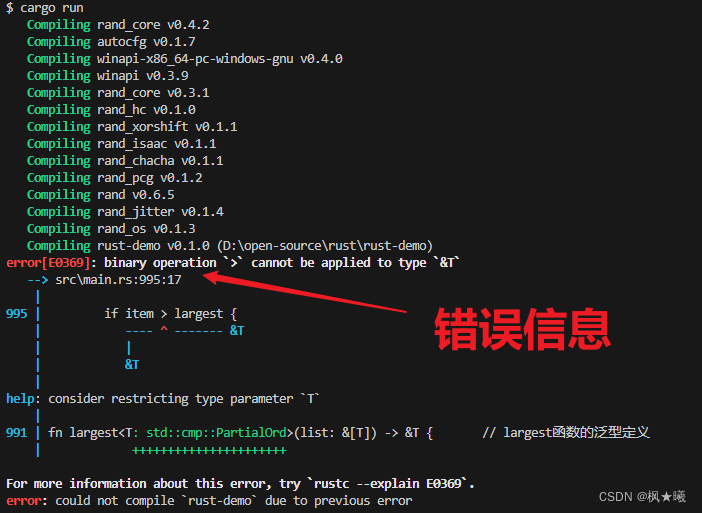
帮助信息提到了std::cmp::PartialOrd,它是一个trait,我们将在下一节讨论trait。现在,我们要知道,这个错误说明,largest对所有可能的T的类型都不起作用。因为我们想在主体中比较类型T的值,我们只能使用值可以被排序的类型。为了实现比较,标准库有std::cmp::PartialOrd特质,你可以在类型上实现它(关于这个特质的更多信息,见附录C)。按照帮助信息的建议,我们把对T有效的类型限制为只实现PartialOrd的类型,这个例子就可以编译了,因为标准库对i32和char都实现了PartialOrd。
结构体的泛型定义
我们还可以使用<>语法定义结构,在一个或多个字段中使用通用类型参数。示例6 定义了一个 Point<T> 结构来保存任何类型的 x 和 y 坐标值。
文件名: src/main.rs
struct Point<T> { // 结构体的泛型定义
x: T,
y: T,
}
fn main() {
let integer = Point { x: 5, y: 10 };
let float = Point { x: 1.0, y: 4.0 };
}示例6:一个带有T类型的x和y值的Point<T>结构
在结构体定义中使用泛型的语法与函数定义中使用的语法类似。首先,我们在结构名称之后的角括号内声明类型参数的名称。然后,我们在结构定义中使用泛型,否则我们会指定具体的数据类型。
注意,因为我们只用了一个泛型来定义Point<T>,这个定义说Point<T>结构是某个类型T的泛型,字段x和y都是同一类型,不管这个类型是什么。如果我们创建一个具有不同类型值的 Point<T> 实例,如示例7 所示,我们的代码将无法编译。
文件名:src/main.rs
struct Point<T> {
x: T,
y: T,
}
fn main() {
let wont_work = Point { x: 5, y: 4.0 };
}示例7: 字段x和y必须是相同的类型,因为两者有相同的通用数据类型T
编译
cargo run 在这个例子中,当我们把整数值5分配给x时,我们让编译器知道,对于Point<T>的这个实例,通用类型T将是一个整数。然后,当我们为y指定4.0时,我们已经定义了与x相同的类型,我们会得到一个类型不匹配的错误,像这样: 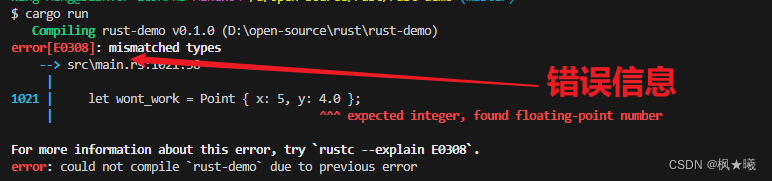
为了定义一个x和y都是泛型但可能有不同类型的Point结构,我们可以使用多个泛型参数。例如,在示例8中,我们将Point的定义改为T和U类型的泛型,其中x是T类型的,y是U类型的。
struct Point<T, U> { // 两种数据类型的结构体泛型定义
x: T,
y: U,
}
fn main() {
let both_integer = Point { x: 5, y: 10 };
let both_float = Point { x: 1.0, y: 4.0 };
let integer_and_float = Point { x: 5, y: 4.0 };
println!("both_integer.x = {}, both_integer.y= {}", both_integer.x, both_integer.y);
println!("both_float.x = {}, both_float.x = {}", both_float.x, both_float.y);
println!("integer_and_float.x = {}, integer_and_float.y = {}", integer_and_float.x, integer_and_float.y);
}
示例8:一个Point<T, U>在两种类型上的泛型,以便x和y可以是不同类型的值
编译

现在,所有显示的Point的实例都被允许了! 你可以在一个定义中使用尽可能多的泛型参数,但使用多了会使你的代码难以阅读。如果你发现你的代码中需要大量的泛型,这可能表明你的代码需要重组成小块。
枚举的泛型定义
就像我们对结构体所做的那样,我们可以定义枚举来保存其变体中的通用数据类型。让我们再看看标准库提供的Option<T>枚举,我们在之前的章节中使用过它:
enum Option<T> {
Some(T),
None,
}
这个定义现在对你来说应该更有意义了。正如你所看到的,Option<T>枚举对T类型是通用的,有两个变体: Some,它持有一个T类型的值,和一个None变体,它不持有任何值。通过使用Option<T>枚举,我们可以表达一个可选值的抽象概念,由于Option<T>是通用的,所以无论可选值的类型是什么,我们都可以使用这个抽象概念。
枚举也可以使用多个通用类型。我们在之前章节种使用的Result枚举的定义就是一个例子:
enum Result<T, E> {
Ok(T),
Err(E),
}
Result枚举在两种类型上是通用的,即T和E,并且有两个变量:Ok, 持有一个T类型的值,Err,它持有一个E类型的值。这个定义使得我们可以在任何有可能成功(返回某种类型的T的值)或失败(返回某种类型的E的错误)的操作中使用Result枚举。事实上,这就是我们在之前章节的示例中用来打开一个文件的方法,当文件被成功打开时,T被填写为std::fs::File类型,当打开文件有问题时,E被填写为std::io::Error类型。
当你发现你的代码中有多个结构或枚举的定义,而这些定义只在它们持有的值的类型上有区别时,你可以通过使用通用类型来避免重复的情况。
方法的泛型定义
我们可以在结构体和枚举上实现方法(就像我们在之前章中做的那样),也可以在它们的定义中使用通用类型。示例9显示了我们在清示例6中定义的Point<T>结构,并在其上实现了一个名为x的方法。
文件名: src/main.rs
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> { // 方法的泛型定义
fn x(&self) -> &T {
&self.x
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}示例9:在Point<T>结构上实现一个名为x的方法,该方法将返回一个对T类型的x字段的引用
编译
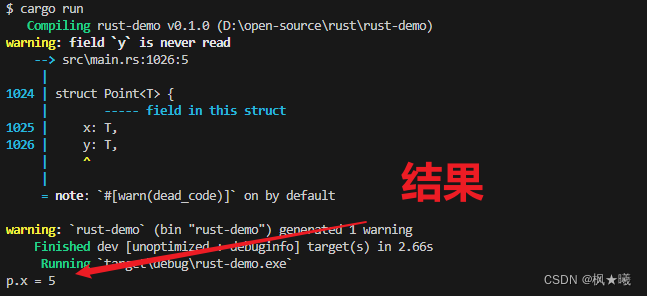
这里,我们在Point<T>上定义了一个名为x的方法,返回对字段x中数据的引用。
请注意,我们必须在impl之后声明T,这样我们就可以用T来指定我们在Point<T><T>这个类型上实现方法。通过在 impl之后将T声明为泛型,Rust 可以确定 Point 中角括号中的类型是一个泛型,而不是一个具体类型。我们可以为这个泛型参数选择一个与结构定义中声明的泛型参数不同的名字,但使用相同的名字是常规的。在声明了泛型的impl函数中编写的方法将被定义在该类型的任何实例上,无论最终用什么具体类型来替代泛型。
在定义类型上的方法时,我们也可以指定对泛型的约束。例如,我们可以只在 Point<f32> 实例上实现方法,而不是在具有任何泛型的 Point<T> 实例上。在示例10中,我们使用了具体的类型f32,这意味着我们没有在impl后面声明任何类型。
文件名: src/main.rs
impl Point<f32> {
fn distance_from_origin(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
示例10:一个impl块,它只适用于具有特定具体类型的通用类型参数T的结构
这段代码意味着Point<f32>类型将有一个distance_from_origin方法;其他Point<T>的实例,如果T不属于f32类型,则不会定义这个方法。该方法测量我们的点离坐标(0.0, 0.0)处的点有多远,并使用仅对浮点类型可用的数学运算。
结构定义中的通用类型参数并不总是与你在同一结构的方法签名中使用的参数相同。示例11在Point结构中使用了通用类型X1和Y1,在mixup方法签名中使用了X2 Y2,以使例子更加清晰。该方法创建了一个新的Point实例,其X值来自于自身的Point(类型为X1),Y值来自于传入的Point(类型为Y2)。
文件名: src/main.rs
struct Point<X1, Y1> {
x: X1,
y: Y1,
}
impl<X1, Y1> Point<X1, Y1> {
fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> {
Point {
x: self.x,
y: other.y,
}
}
}
fn main() {
let p1 = Point { x: 5, y: 10.4 };
let p2 = Point { x: "Hello", y: 'c' };
let p3 = p1.mixup(p2);
println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}示例11:一个使用不同于其结构定义的通用类型的方法
编译

在main中,我们定义了一个Point,其中i32为x(值为5),f64为y(值为10.4)。p2变量是一个Point结构,其中x是一个字符串片(值为 "Hello"),y是一个char(值为c)。在p1上调用mixup,参数为p2,得到p3,它有一个i32的x,因为x来自p1。p3变量将有一个char作为y,因为y来自p2。println!宏调用将打印p3.x = 5, p3.y = c。
这个例子的目的是演示这样一种情况:一些泛型参数与 impl 一起声明,一些则与方法定义一起声明。在这里,泛型参数X1和Y1是在impl之后声明的,因为它们与结构定义一起。泛型参数X2和Y2是在fn mixup之后声明的,因为它们只与方法相关。
使用泛型的代码的性能
你可能想知道在使用通用类型参数时是否有运行时间成本。好消息是,使用泛型不会使你的程序比使用具体类型的程序运行得更慢。
Rust通过在编译时对使用泛型的代码进行单态化来实现这一点。单态化是指通过填写编译时使用的具体类型,将泛型代码变成具体代码的过程。在这个过程中,编译器所做的与我们在示例5中创建泛型函数的步骤相反:编译器会查看所有调用泛型代码的地方,并为泛型代码所调用的具体类型生成代码。
让我们通过使用标准库的通用Option<T>枚举来看看这是如何工作的:
let integer = Some(5);
let float = Some(5.0);
当Rust编译这段代码时,它进行了单态化。在这个过程中,编译器读取了Option<T>实例中使用的值,并确定了两种Option<T>:一种是i32,另一种是f64。因此,它将Option<T>的通用定义扩展为两个专门针对i32和f64的定义,从而用特定的定义代替了通用定义。
代码的单态化版本看起来与下面类似(编译器使用的名称与我们在这里使用的不同,以示说明):
文件名: src/main.rs
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
fn main() {
let integer = Option_i32::Some(5);
let float = Option_f64::Some(5.0);
}通用的Option<T>被编译器创建的特定定义所取代。因为Rust将泛型代码编译成在每个实例中指定类型的代码,所以我们没有为使用泛型支付任何运行时成本。当代码运行时,它的表现就像我们手工复制每个定义一样。单态化的过程使得Rust的泛型在运行时非常高效。
本章重点
- 通用数据类型分类
- 函数的泛型定义
- 结构体的泛型定义
- 枚举的泛型定义
- 方法的泛型定义