文章目录
- 说明
- Day51-52 KNN 分类器
- 1.KNN
- 2.代码
- 1.aff内容解读
- 2.代码理解
- Day53 knn补充
- 1.加权思路
- 2.加权代码
- 3.leave-one-out 测试思路
- 4.leave-one-out代码
说明
闵老师的文章链接: 日撸 Java 三百行(总述)_minfanphd的博客-CSDN博客
自己也把手敲的代码放在了github上维护:https://github.com/fulisha-ok/sampledata
Day51-52 KNN 分类器
今天开始学习机器学习,这是自己之前未接触过的,若在理解过程中有问题,欢迎批评指正~
1.KNN
正如物以类聚,人以群居。越是相似的东西就越有可能是一类东西。从这张图片来看,判断Xu属于那种类别,可以取Xu最近的K个邻居(距离),在这个K个点中,那一类东西的概率最高,就把他定位为那个类别。其中计算距离的方式有两种:
欧式距离(多维空间):
d
=
∑
i
=
1
n
(
x
i
−
x
j
)
2
d = \sqrt{{\sum_{i=1}^{n}}(x _{i}-x _{j} ) ^2}
d=i=1∑n(xi−xj)2
曼哈顿距离:
d
=
∣
x
1
−
x
2
∣
+
∣
y
1
−
y
2
∣
d = \mid x1 -x2 \mid + \mid y1 -y2 \mid
d=∣x1−x2∣+∣y1−y2∣
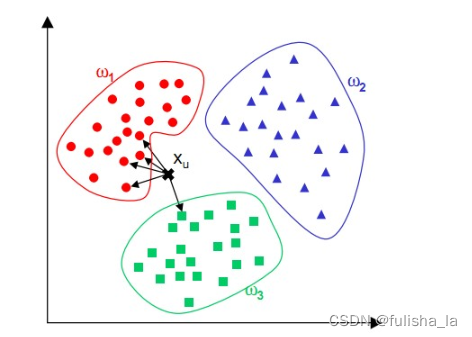
KNN算法最简单粗暴的就是将预测点与所有点距离进行计算,然后保存并排序,选出前面K个值看看哪些类别比较多。(在电商中,可以根据消费者选择的东西去推荐他们可能感兴趣的的商品,还可以在一些网站可以看到相似用户这些。)
2.代码
在写代码前要导入一个jar包。下载jar包的网址:https://mvnrepository.com/
1.aff内容解读
在aff文件中有3种类型的花(山鸢尾(Iris-setosa),变色鸢尾(Iris-versicolor),维吉尼亚鸢尾(Iris-virginica)),每一个花类有50个数据,每条记录有 4 项特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)
2.代码理解
- 解析文本内容,获取数据集
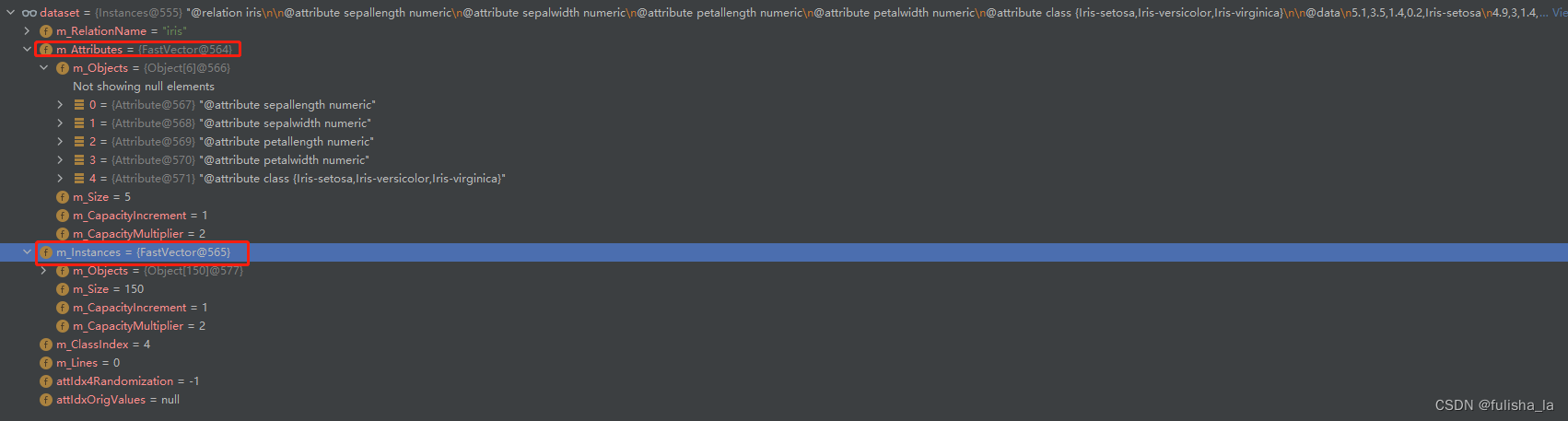
- 根据获取的数据集划分训练集和测试集,对获取的数据集先打乱数据索引位置再进行分割,以保证在取数时更有说服性trainingSet(代码中是分了120个数据集)和testingSet(30个训练集)
- 对测试集数据进行遍历预测:对每一个测试数据,计算他到所有训练集的距离,取他的k个邻居,这k个邻居是距离这个测试数据最近得k个点(代码中计算距离用的欧式距离)
- 取出测试集的预测结果与数据集中的结果进行比较,判断预测正确率
package machinelearing.knn;
import weka.core.Instance;
import weka.core.Instances;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.Arrays;
import java.util.Random;
/**
* @author: fulisha
* @date: 2023/5/15 9:43
* @description:
*/
public class KnnClassification {
/**
* Manhattan distance.
*/
public static final int MANHATTAN = 0;
/**
* Euclidean distance(欧几里得距离)
*/
public static final int EUCLIDEAN = 1;
/**
* The distance measure
*/
public int distanceMeasure = EUCLIDEAN;
/**
* a random instance
*/
public static final Random random = new Random();
/**
* The number of neighbors
*/
int numNeighbors = 7;
/**
* The whole dataset
*/
Instances dataset;
/**
* The training set. Represented by the indices of the data
*/
int[] trainingSet;
/**
* The testing set. Represented by the indices of the data.
*/
int[] testingSet;
/**
* the predictions
*/
int[] predictions;
public void setDistanceMeasure(int distanceMeasure) {
this.distanceMeasure = distanceMeasure;
}
public void setNumNeighbors(int numNeighbors) {
this.numNeighbors = numNeighbors;
}
/**
* the first constructor
* @param paraFilename The arff filename.
*/
public KnnClassification(String paraFilename) {
try {
FileReader fileReader = new FileReader(paraFilename);
dataset = new Instances(fileReader);
// the last attribute is the decision class
dataset.setClassIndex(dataset.numAttributes() - 1);
fileReader.close();
} catch (Exception e) {
System.out.println("Error occurred while trying to read \'" + paraFilename + "\' in KnnClassification constructor.\r\n" + e);
System.exit(0);
}
}
/**
* get a random indices for data randomization
* @param paraLength the length of the sequence
* @return An array of indices. eg.{4, 3, 1, 5, 0, 2} with length 6
*/
public static int[] getRandomIndices(int paraLength) {
int[] resultIndices = new int[paraLength];
//step1. Initialize
for (int i = 0; i < paraLength; i++) {
resultIndices[i] = i;
}
//step2 Randomly swap
int tempFirst, tempSecond, tempValue;
for (int i = 0; i < paraLength; i++) {
//Generate two random indices
tempFirst = random.nextInt(paraLength);
tempSecond = random.nextInt(paraLength);
//swap
tempValue = resultIndices[tempFirst];
resultIndices[tempFirst] = resultIndices[tempSecond];
resultIndices[tempSecond] = tempValue;
}
return resultIndices;
}
public void splitTrainingTesting(double paraTrainingFraction) {
int tempSize = dataset.numInstances();
int[] tempIndices = getRandomIndices(tempSize);
int tempTrainingSize = (int) (tempSize * paraTrainingFraction);
trainingSet = new int[tempTrainingSize];
testingSet = new int[tempSize - tempTrainingSize];
for (int i = 0; i < tempTrainingSize; i++) {
trainingSet[i] = tempIndices[i];
}
for (int i = 0; i < tempSize - tempTrainingSize; i++) {
testingSet[i] = tempIndices[tempTrainingSize + i];
}
}
/**
* Predict for the whole testing set. The results are stored in predictions
*/
public void predict() {
predictions = new int[testingSet.length];
for (int i = 0; i < predictions.length; i++) {
predictions[i] = predict(testingSet[i]);
}
}
/**
* Predict for given instance
* @param paraIndex
* @return
*/
public int predict(int paraIndex) {
int[] tempNeighbors = computeNearests(paraIndex);
int resultPrediction = simpleVoting(tempNeighbors);
return resultPrediction;
}
/**
* The distance between two instance
* @param paraI The index of the first instance
* @param paraJ The index of the second instance
* @return The distance
*/
public double distance(int paraI, int paraJ) {
double resultDistance = 0;
double tempDifference;
switch (distanceMeasure) {
case MANHATTAN:
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - dataset.instance(paraJ).value(i);
if (tempDifference < 0) {
resultDistance -= tempDifference;
}else {
resultDistance += tempDifference;
}
}
break;
case EUCLIDEAN:
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - dataset.instance(paraJ).value(i);
resultDistance += tempDifference*tempDifference;
}
break;
default:
System.out.println("Unsupported distance measure: " + distanceMeasure);
}
return resultDistance;
}
/**
* Get the accuracy of the classifier
* @return
*/
public double getAccuracy() {
// A double divides an int gets another double
double tempCorrect = 0;
for (int i = 0; i < predictions.length; i++) {
if (predictions[i] == dataset.instance(testingSet[i]).classValue()) {
tempCorrect++;
}
}
return tempCorrect / testingSet.length;
}
/**
* compute the nearnest k neighbors.select one neighbor in each scan.
* @param paraCurrent
* @return
*/
public int[] computeNearests(int paraCurrent) {
int[] resultNearests = new int[numNeighbors];
boolean[] tempSelected = new boolean[trainingSet.length];
double tempMinimalDistance;
int tempMinimalIndex = 0;
//compute all distance to avoid redundant computation
double[] tempDistances = new double[trainingSet.length];
for (int i = 0; i < trainingSet.length; i ++) {
tempDistances[i] = distance(paraCurrent, trainingSet[i]);
}
// Select the nearest paraK indices.
for (int i = 0; i < numNeighbors; i++) {
tempMinimalDistance = Double.MAX_VALUE;
for (int j = 0; j < trainingSet.length; j++) {
if (tempSelected[j]) {
continue;
}
if (tempDistances[j] < tempMinimalDistance) {
tempMinimalDistance = tempDistances[j];
tempMinimalIndex = j;
}
}
resultNearests[i] = trainingSet[tempMinimalIndex];
tempSelected[tempMinimalIndex] = true;
}
System.out.println("The nearest of " + paraCurrent + " are: " + Arrays.toString(resultNearests));
return resultNearests;
}
/**
* Voting using the instances
* @param paraNeighbors The indices of the neighbors.
* @return The predicted label.
*/
public int simpleVoting(int[] paraNeighbors) {
int[] tempVotes = new int[dataset.numClasses()];
for (int i = 0; i < paraNeighbors.length; i++) {
tempVotes[(int) dataset.instance(paraNeighbors[i]).classValue()]++;
}
int tempMaximalVotingIndex = 0;
int tempMaximalVoting = 0;
for (int i = 0; i < dataset.numClasses(); i++) {
if (tempVotes[i] > tempMaximalVoting) {
tempMaximalVoting = tempVotes[i];
tempMaximalVotingIndex = i;
}
}
return tempMaximalVotingIndex;
}
public static void main(String[] args) {
KnnClassification tempClassifier = new KnnClassification("D:/fulisha/iris.arff");
tempClassifier.splitTrainingTesting(0.8);
tempClassifier.predict();
System.out.println("The accuracy of the classifier is: " + tempClassifier.getAccuracy());
}
}
运行结果:
The nearest of 56 are: [51, 91, 127, 86, 70, 138, 63]
The nearest of 11 are: [29, 7, 26, 30, 24, 6, 49]
The nearest of 21 are: [19, 17, 4, 48, 0, 40, 43]
The nearest of 119 are: [72, 68, 146, 113, 123, 101, 142]
The nearest of 12 are: [1, 9, 37, 34, 45, 30, 25]
The nearest of 85 are: [70, 51, 91, 61, 138, 63, 127]
The nearest of 83 are: [101, 142, 149, 123, 127, 72, 138]
The nearest of 103 are: [116, 137, 111, 147, 134, 108, 149]
The nearest of 93 are: [60, 98, 81, 80, 79, 59, 69]
The nearest of 66 are: [84, 55, 96, 61, 95, 88, 94]
The nearest of 104 are: [140, 124, 143, 120, 144, 116, 100]
The nearest of 32 are: [33, 19, 48, 10, 16, 5, 4]
The nearest of 132 are: [111, 140, 116, 147, 115, 137, 145]
The nearest of 90 are: [94, 55, 96, 89, 99, 95, 92]
The nearest of 54 are: [58, 75, 76, 86, 74, 65, 51]
The nearest of 47 are: [42, 6, 29, 45, 30, 9, 37]
The nearest of 136 are: [148, 115, 100, 144, 140, 124, 143]
The nearest of 38 are: [8, 42, 13, 45, 6, 29, 30]
The nearest of 3 are: [29, 30, 45, 42, 8, 9, 37]
The nearest of 129 are: [125, 130, 102, 107, 139, 108, 124]
The nearest of 128 are: [111, 116, 137, 147, 140, 115, 108]
The nearest of 2 are: [6, 45, 42, 29, 1, 35, 9]
The nearest of 133 are: [72, 123, 127, 63, 111, 77, 146]
The nearest of 46 are: [19, 48, 4, 10, 44, 0, 17]
The nearest of 57 are: [98, 60, 81, 80, 59, 79, 69]
The nearest of 126 are: [123, 127, 138, 146, 63, 72, 149]
The nearest of 67 are: [92, 82, 99, 69, 94, 95, 96]
The nearest of 112 are: [139, 140, 120, 145, 124, 116, 147]
The nearest of 78 are: [91, 63, 61, 97, 55, 73, 138]
The nearest of 27 are: [28, 39, 0, 17, 48, 7, 4]
The accuracy of the classifier is: 0.9666666666666667
Day53 knn补充
1.加权思路
距离加权,距离越短说明他们的话语权最大,采用了最简单的方式,采用倒数形式,距离为d,则它的权重为1/d,可以对距离再进行平方,在进行倒数都可以。我这里改进方法是两种
- 结合我们k个邻居的数组是按距离从小到大来进行排序的,那么我这里可以不用去花一个数组去存储距离,而是用他的索引值i去平替他的距离
- 我们即用一个对象去存储测试点到这k个邻居的距离,当然也可以不存储,那你就得再去算一次,但我觉得牺牲一点空间存储也是可以的。用实际距离去计算权重。(代码中新增了一个 Map<Integer, double[]> distanceMap = new HashMap<>();来全局记录测试点到k个邻居的距离)
2.加权代码
我全局新增三种投票模式 新增一个set方法全局定义一个选择投票的方式
/**
* simple voting
*/
public static final int VOTE_SIMPLE = 0;
/**
* add index to simple voting(用索引做距离的平替)
*/
public static final int VOTE_DISTANCE_1 = 1;
/**
* add distance to simple voting(actual distance)
*/
public static final int VOTE_DISTANCE_2 = 2;
/**
* The vote measure
*/
public int voteDistance = VOTE_SIMPLE;
public void setVoteDistance(Integer vote) {
this.voteDistance = vote;
}
新增weightedVoting方法替代simpleVoting方法,根据所传参数来选择投票方式。
public int weightedVoting(int[] paraNeighbors, Integer weightModel, double[] tempDistances) {
int[] tempVotes = new int[dataset.numClasses()];
for (int i = 0; i < paraNeighbors.length; i++) {
//voting 花类型的索引index
int index = (int)dataset.instance(paraNeighbors[i]).classValue();
if (weightModel.equals(VOTE_SIMPLE)) {
tempVotes[index]++;
} else if (weightModel.equals(VOTE_DISTANCE_1)) {
// 因为本身paraNeighbors存储的顺序是按从小到大的顺序存储的,我用i做平替
tempVotes[index] += 1/(i+1);
} else if (weightModel.equals(VOTE_DISTANCE_2)) {
// 用具体的距离方式
tempVotes[index] += 1/tempDistances[i];
}
}
int tempMaximalVotingIndex = 0;
int tempMaximalVoting = 0;
for (int i = 0; i < dataset.numClasses(); i++) {
if (tempVotes[i] > tempMaximalVoting) {
tempMaximalVoting = tempVotes[i];
tempMaximalVotingIndex = i;
}
}
return tempMaximalVotingIndex;
}
3.leave-one-out 测试思路
- 将数据集中的每一个样本都被单独作为测试集,而剩下的样本就作为训练集。就像我们的代码中,我们一共有150个数据集,我们依次将样本作为测试集,而剩下的149个样本就作为训练集,在每一次的迭代中,每次选择一个不同的样本作为测试集,直到所有样本都被用作测试集为止。(不同的投票方式结果不一样)
4.leave-one-out代码
- 主要代码如下:(数据集我是打乱了顺序,其实不打乱顺序也无所谓,不会影响结果)
/**
* leave-one-out test
*/
public void leaveOneOutTesting() {
int tempSize = dataset.numInstances();
//int[] predicts = new int[tempSize];
int[] tempIndices = getRandomIndices(tempSize);
int tempCorrect = 0;
for (int i = 0; i < tempSize; i++) {
// 分训练集和测试集 (测试集一个.其余为训练集)
splitByIndex(tempIndices, i);
int[] neighbors = computeNearests(tempIndices[i]);
int resultPrediction = weightedVoting(neighbors, voteDistance, distanceMap.get(tempIndices[i]));
if(resultPrediction == dataset.instance(tempIndices[i]).classValue()){
tempCorrect++;
} else{
System.out.println(tempIndices[i] + "The resultPrediction " + resultPrediction + " and actual result " + dataset.instance(tempIndices[i]).classValue());
}
}
System.out.println("The total size " + tempSize + ", after leave-one-test, the correct predict size :" + tempCorrect);
}
/**
* split for leave-one-out test
* @param tempIndices the given dataSet
* @param index the index
*/
public void splitByIndex(int[] tempIndices, int index) {
int tempSize = dataset.numInstances();
int tempTrainingSize = tempSize - 1;
testingSet = new int[1];
trainingSet = new int[tempTrainingSize];
testingSet[0] = tempIndices[index];
int j = 0;
for (int i = 0; i < tempSize; i++) {
if (i == index) {
continue;
}
trainingSet[j++] = tempIndices[i];
}
}
运行结果
The nearest of 14 are: [33, 16, 15, 18, 10, 36, 48]
The nearest of 70 are: [138, 127, 149, 85, 56, 126, 91]
70 The resultPrediction 2 and actual result 1.0
The nearest of 3 are: [47, 29, 30, 2, 45, 12, 38]
The nearest of 95 are: [96, 88, 99, 94, 61, 55, 67]
The nearest of 19 are: [21, 46, 48, 4, 17, 0, 27]
The nearest of 90 are: [94, 55, 96, 89, 99, 67, 95]
The nearest of 6 are: [47, 2, 11, 42, 29, 3, 30]
The nearest of 56 are: [51, 85, 91, 127, 86, 70, 138]
The nearest of 4 are: [0, 17, 40, 7, 39, 27, 19]
The nearest of 12 are: [1, 34, 37, 9, 45, 30, 2]
The nearest of 48 are: [10, 27, 19, 46, 21, 0, 17]
The nearest of 75 are: [65, 58, 74, 54, 51, 86, 97]
The nearest of 39 are: [7, 0, 28, 27, 49, 17, 26]
The nearest of 49 are: [7, 39, 35, 0, 28, 17, 40]
The nearest of 142 are: [101, 113, 121, 149, 83, 127, 138]
The nearest of 43 are: [26, 23, 21, 17, 40, 7, 39]
The nearest of 124 are: [120, 143, 112, 140, 104, 144, 139]
The nearest of 17 are: [0, 40, 4, 39, 28, 27, 7]
The nearest of 68 are: [87, 72, 119, 54, 73, 146, 123]
The nearest of 34 are: [37, 9, 1, 30, 12, 25, 49]
The nearest of 118 are: [122, 105, 135, 107, 130, 117, 102]
The nearest of 37 are: [34, 9, 1, 30, 12, 25, 49]
The nearest of 21 are: [19, 46, 17, 4, 48, 0, 27]
The nearest of 8 are: [38, 3, 42, 13, 47, 12, 45]
The nearest of 24 are: [11, 29, 26, 30, 7, 23, 39]
The nearest of 108 are: [128, 103, 132, 116, 111, 112, 104]
The nearest of 122 are: [105, 118, 107, 130, 135, 125, 117]
The nearest of 104 are: [132, 128, 140, 124, 143, 112, 120]
The nearest of 115 are: [148, 110, 145, 147, 136, 140, 132]
The nearest of 35 are: [49, 1, 2, 40, 28, 34, 37]
The nearest of 92 are: [82, 67, 99, 69, 94, 89, 71]
The nearest of 119 are: [72, 83, 68, 146, 113, 123, 133]
119 The resultPrediction 1 and actual result 2.0
The nearest of 61 are: [96, 78, 95, 99, 88, 97, 71]
The nearest of 102 are: [125, 120, 143, 130, 112, 129, 124]
The nearest of 45 are: [1, 12, 30, 2, 3, 34, 37]
The nearest of 127 are: [138, 126, 149, 70, 123, 83, 133]
The nearest of 106 are: [84, 59, 90, 89, 94, 66, 53]
106 The resultPrediction 1 and actual result 2.0
The nearest of 22 are: [6, 2, 40, 42, 47, 4, 35]
The nearest of 93 are: [57, 60, 98, 81, 80, 79, 59]
The nearest of 18 are: [5, 10, 48, 20, 16, 31, 36]
The nearest of 130 are: [107, 102, 125, 129, 135, 105, 122]
The nearest of 98 are: [57, 93, 60, 79, 81, 80, 64]
The nearest of 36 are: [10, 31, 28, 48, 27, 0, 20]
The nearest of 0 are: [17, 4, 39, 28, 27, 40, 7]
The nearest of 32 are: [33, 46, 19, 48, 10, 5, 16]
The nearest of 33 are: [32, 15, 16, 14, 5, 10, 48]
The nearest of 2 are: [47, 3, 6, 12, 45, 42, 29]
The nearest of 57 are: [93, 98, 60, 81, 80, 59, 79]
The nearest of 125 are: [129, 102, 107, 130, 143, 120, 124]
The nearest of 13 are: [38, 42, 8, 47, 2, 3, 12]
The nearest of 101 are: [142, 113, 121, 149, 83, 127, 138]
The nearest of 11 are: [29, 7, 26, 24, 30, 6, 49]
The nearest of 73 are: [63, 91, 78, 97, 55, 72, 54]
The nearest of 28 are: [27, 39, 0, 17, 49, 7, 40]
The nearest of 137 are: [116, 103, 147, 128, 111, 110, 112]
The nearest of 55 are: [66, 90, 96, 94, 78, 95, 99]
The nearest of 25 are: [34, 37, 9, 1, 30, 12, 45]
The nearest of 47 are: [3, 2, 42, 6, 29, 38, 12]
The nearest of 91 are: [63, 78, 73, 97, 51, 56, 74]
The nearest of 53 are: [89, 80, 69, 81, 92, 94, 90]
The nearest of 112 are: [139, 140, 120, 145, 124, 116, 104]
The nearest of 44 are: [46, 5, 21, 19, 43, 48, 26]
The nearest of 99 are: [96, 94, 88, 95, 92, 82, 67]
The nearest of 29 are: [30, 3, 11, 47, 34, 37, 9]
The nearest of 132 are: [128, 104, 103, 111, 112, 140, 116]
The nearest of 141 are: [145, 139, 112, 110, 147, 115, 140]
The nearest of 136 are: [148, 115, 100, 144, 140, 124, 104]
The nearest of 138 are: [127, 70, 126, 149, 123, 78, 63]
The nearest of 107 are: [130, 125, 105, 102, 129, 122, 135]
The nearest of 109 are: [143, 120, 144, 102, 135, 124, 125]
The nearest of 88 are: [95, 96, 99, 94, 61, 82, 66]
The nearest of 114 are: [121, 142, 101, 113, 149, 127, 138]
The nearest of 46 are: [19, 21, 48, 4, 27, 10, 32]
The nearest of 149 are: [127, 138, 142, 101, 70, 83, 121]
The nearest of 50 are: [52, 86, 65, 76, 58, 75, 77]
The nearest of 135 are: [130, 105, 102, 107, 122, 125, 109]
The nearest of 147 are: [110, 111, 116, 145, 115, 137, 77]
The nearest of 100 are: [136, 144, 104, 143, 140, 124, 148]
The nearest of 40 are: [17, 0, 4, 7, 49, 39, 28]
The nearest of 133 are: [83, 72, 123, 126, 127, 63, 111]
133 The resultPrediction 1 and actual result 2.0
The nearest of 80 are: [81, 69, 53, 89, 92, 79, 82]
The nearest of 54 are: [58, 75, 76, 86, 74, 65, 51]
The nearest of 82 are: [92, 99, 67, 69, 71, 94, 89]
The nearest of 5 are: [18, 10, 48, 44, 19, 46, 16]
The nearest of 74 are: [97, 75, 58, 54, 65, 51, 71]
The nearest of 85 are: [56, 70, 51, 91, 78, 61, 138]
The nearest of 86 are: [52, 65, 58, 50, 75, 76, 77]
The nearest of 38 are: [8, 42, 13, 3, 47, 2, 45]
The nearest of 87 are: [68, 72, 62, 54, 97, 74, 73]
The nearest of 97 are: [74, 71, 91, 78, 61, 63, 75]
The nearest of 128 are: [132, 104, 103, 111, 116, 137, 112]
The nearest of 139 are: [112, 145, 141, 120, 140, 124, 147]
The nearest of 31 are: [20, 28, 27, 36, 17, 10, 39]
The nearest of 64 are: [82, 79, 88, 99, 69, 59, 92]
The nearest of 134 are: [103, 83, 133, 111, 116, 137, 119]
The nearest of 60 are: [93, 57, 81, 80, 98, 53, 69]
The nearest of 66 are: [84, 55, 96, 78, 61, 95, 88]
The nearest of 77 are: [52, 86, 147, 110, 76, 133, 123]
The nearest of 41 are: [8, 38, 45, 13, 12, 1, 3]
The nearest of 126 are: [123, 127, 138, 146, 83, 133, 63]
The nearest of 89 are: [53, 69, 80, 94, 92, 99, 59]
The nearest of 103 are: [116, 137, 128, 111, 132, 147, 104]
The nearest of 63 are: [91, 73, 78, 97, 138, 126, 54]
The nearest of 10 are: [48, 27, 36, 19, 46, 5, 16]
The nearest of 111 are: [147, 128, 146, 103, 116, 123, 132]
The nearest of 105 are: [122, 107, 135, 118, 130, 125, 117]
The nearest of 146 are: [123, 111, 126, 72, 83, 133, 142]
The nearest of 71 are: [97, 82, 92, 61, 99, 74, 67]
The nearest of 79 are: [81, 80, 69, 64, 82, 92, 67]
The nearest of 69 are: [80, 89, 81, 92, 82, 53, 67]
The nearest of 110 are: [147, 115, 77, 145, 137, 116, 141]
The nearest of 78 are: [91, 63, 61, 97, 55, 73, 66]
The nearest of 9 are: [34, 37, 1, 30, 12, 25, 49]
The nearest of 59 are: [89, 94, 53, 80, 69, 88, 64]
The nearest of 145 are: [141, 147, 139, 112, 115, 140, 110]
The nearest of 148 are: [136, 115, 110, 147, 140, 137, 124]
The nearest of 116 are: [137, 103, 147, 111, 128, 112, 132]
The nearest of 16 are: [10, 48, 33, 19, 5, 21, 36]
The nearest of 58 are: [75, 54, 65, 76, 86, 74, 51]
The nearest of 96 are: [95, 99, 88, 94, 61, 55, 92]
The nearest of 23 are: [26, 43, 39, 7, 31, 17, 27]
The nearest of 121 are: [142, 101, 113, 149, 114, 138, 70]
The nearest of 72 are: [133, 123, 146, 83, 119, 126, 54]
72 The resultPrediction 2 and actual result 1.0
The nearest of 123 are: [126, 146, 127, 72, 133, 83, 111]
The nearest of 30 are: [29, 34, 37, 9, 3, 25, 45]
The nearest of 42 are: [38, 47, 3, 2, 6, 8, 13]
The nearest of 113 are: [142, 101, 121, 114, 83, 149, 146]
The nearest of 20 are: [31, 27, 28, 10, 39, 48, 36]
The nearest of 26 are: [23, 43, 7, 39, 17, 11, 49]
The nearest of 84 are: [66, 55, 96, 88, 94, 95, 90]
The nearest of 62 are: [92, 69, 67, 80, 82, 53, 87]
The nearest of 131 are: [117, 105, 135, 109, 125, 122, 107]
The nearest of 143 are: [120, 124, 144, 140, 104, 102, 112]
The nearest of 51 are: [56, 75, 65, 86, 91, 74, 58]
The nearest of 94 are: [99, 96, 90, 89, 88, 92, 55]
The nearest of 117 are: [131, 105, 109, 135, 122, 125, 107]
The nearest of 83 are: [133, 142, 101, 149, 123, 127, 72]
83 The resultPrediction 2 and actual result 1.0
The nearest of 120 are: [143, 140, 124, 144, 112, 139, 102]
The nearest of 67 are: [92, 82, 99, 69, 94, 95, 96]
The nearest of 81 are: [80, 69, 79, 53, 89, 92, 82]
The nearest of 15 are: [33, 14, 5, 16, 18, 32, 10]
The nearest of 65 are: [75, 58, 86, 51, 74, 54, 50]
The nearest of 27 are: [28, 39, 0, 17, 48, 7, 4]
The nearest of 1 are: [45, 12, 34, 37, 9, 25, 30]
The nearest of 129 are: [125, 130, 102, 107, 112, 139, 108]
The nearest of 144 are: [140, 120, 143, 124, 136, 104, 100]
The nearest of 140 are: [144, 120, 112, 143, 104, 124, 139]
The nearest of 76 are: [58, 86, 52, 54, 77, 50, 75]
The nearest of 7 are: [39, 49, 0, 17, 26, 4, 11]
The nearest of 52 are: [50, 86, 77, 76, 58, 65, 54]
The total size 150, after leave-one-test, the correct predict size :144
这三天的全部代码:
package machinelearing.knn;
import weka.core.Instance;
import weka.core.Instances;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
/**
* @author: fulisha
* @date: 2023/5/15 9:43
* @description:
*/
public class KnnClassification {
/**
* Manhattan distance.
*/
public static final int MANHATTAN = 0;
/**
* Euclidean distance(欧几里得距离)
*/
public static final int EUCLIDEAN = 1;
/**
* The distance measure
*/
public int distanceMeasure = EUCLIDEAN;
/**
* simple voting
*/
public static final int VOTE_SIMPLE = 0;
/**
* add index to simple voting(用索引做距离的平替)
*/
public static final int VOTE_DISTANCE_1 = 1;
/**
* add distance to simple voting(actual distance)
*/
public static final int VOTE_DISTANCE_2 = 2;
/**
* The vote measure
*/
public int voteDistance = VOTE_DISTANCE_2;
/**
* a random instance
*/
public static final Random random = new Random();
/**
* The number of neighbors
*/
int numNeighbors = 7;
/**
* The whole dataset
*/
Instances dataset;
/**
* The training set. Represented by the indices of the data
*/
int[] trainingSet;
/**
* The testing set. Represented by the indices of the data.
*/
int[] testingSet;
/**
* the predictions
*/
int[] predictions;
Map<Integer, double[]> distanceMap = new HashMap<>();
public void setDistanceMeasure(int distanceMeasure) {
this.distanceMeasure = distanceMeasure;
}
public void setNumNeighbors(int numNeighbors) {
this.numNeighbors = numNeighbors;
}
public void setVoteDistance(Integer vote) {
this.voteDistance = vote;
}
/**
* the first constructor
* @param paraFilename The arff filename.
*/
public KnnClassification(String paraFilename) {
try {
FileReader fileReader = new FileReader(paraFilename);
dataset = new Instances(fileReader);
// the last attribute is the decision class
dataset.setClassIndex(dataset.numAttributes() - 1);
fileReader.close();
} catch (Exception e) {
System.out.println("Error occurred while trying to read \'" + paraFilename + "\' in KnnClassification constructor.\r\n" + e);
System.exit(0);
}
}
/**
* get a random indices for data randomization
* @param paraLength the length of the sequence
* @return An array of indices. eg.{4, 3, 1, 5, 0, 2} with length 6
*/
public static int[] getRandomIndices(int paraLength) {
int[] resultIndices = new int[paraLength];
//step1. Initialize
for (int i = 0; i < paraLength; i++) {
resultIndices[i] = i;
}
//step2 Randomly swap
int tempFirst, tempSecond, tempValue;
for (int i = 0; i < paraLength; i++) {
//Generate two random indices
tempFirst = random.nextInt(paraLength);
tempSecond = random.nextInt(paraLength);
//swap
tempValue = resultIndices[tempFirst];
resultIndices[tempFirst] = resultIndices[tempSecond];
resultIndices[tempSecond] = tempValue;
}
return resultIndices;
}
public void splitTrainingTesting(double paraTrainingFraction) {
int tempSize = dataset.numInstances();
int[] tempIndices = getRandomIndices(tempSize);
int tempTrainingSize = (int) (tempSize * paraTrainingFraction);
trainingSet = new int[tempTrainingSize];
testingSet = new int[tempSize - tempTrainingSize];
for (int i = 0; i < tempTrainingSize; i++) {
trainingSet[i] = tempIndices[i];
}
for (int i = 0; i < tempSize - tempTrainingSize; i++) {
testingSet[i] = tempIndices[tempTrainingSize + i];
}
}
public void TrainingTesting() {
int tempSize = dataset.numInstances();
int[] tempIndices = getRandomIndices(tempSize);
int testingSize = 1;
trainingSet = new int[tempSize - testingSize];
testingSet = new int[testingSize];
for (int i = 0; i < tempSize - testingSize; i++) {
trainingSet[i] = tempIndices[i];
}
}
/**
* Predict for the whole testing set. The results are stored in predictions
*/
public void predict() {
predictions = new int[testingSet.length];
for (int i = 0; i < predictions.length; i++) {
predictions[i] = predict(testingSet[i]);
}
}
/**
* Predict for given instance
* @param paraIndex
* @return
*/
public int predict(int paraIndex) {
int[] tempNeighbors = computeNearests(paraIndex);
//int resultPrediction = simpleVoting(tempNeighbors);
int resultPrediction = weightedVoting(tempNeighbors, voteDistance, distanceMap.get(paraIndex));
return resultPrediction;
}
/**
* The distance between two instance
* @param paraI The index of the first instance
* @param paraJ The index of the second instance
* @return The distance
*/
public double distance(int paraI, int paraJ) {
double resultDistance = 0;
double tempDifference;
switch (distanceMeasure) {
case MANHATTAN:
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - dataset.instance(paraJ).value(i);
if (tempDifference < 0) {
resultDistance -= tempDifference;
}else {
resultDistance += tempDifference;
}
}
break;
case EUCLIDEAN:
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - dataset.instance(paraJ).value(i);
resultDistance += tempDifference*tempDifference;
}
break;
default:
System.out.println("Unsupported distance measure: " + distanceMeasure);
}
return resultDistance;
}
/**
* Get the accuracy of the classifier
* @return
*/
public double getAccuracy() {
// A double divides an int gets another double
double tempCorrect = 0;
for (int i = 0; i < predictions.length; i++) {
if (predictions[i] == dataset.instance(testingSet[i]).classValue()) {
tempCorrect++;
}
}
return tempCorrect / testingSet.length;
}
/**
* compute the nearnest k neighbors.select one neighbor in each scan.
* @param paraCurrent
* @return
*/
public int[] computeNearests(int paraCurrent) {
int[] resultNearests = new int[numNeighbors];
double[] resultDistance = new double[numNeighbors];
boolean[] tempSelected = new boolean[trainingSet.length];
double tempMinimalDistance;
int tempMinimalIndex = 0;
//compute all distance to avoid redundant computation
double[] tempDistances = new double[trainingSet.length];
for (int i = 0; i < trainingSet.length; i ++) {
tempDistances[i] = distance(paraCurrent, trainingSet[i]);
}
// Select the nearest paraK indices.
for (int i = 0; i < numNeighbors; i++) {
tempMinimalDistance = Double.MAX_VALUE;
for (int j = 0; j < trainingSet.length; j++) {
if (tempSelected[j]) {
continue;
}
if (tempDistances[j] < tempMinimalDistance) {
tempMinimalDistance = tempDistances[j];
tempMinimalIndex = j;
}
}
resultNearests[i] = trainingSet[tempMinimalIndex];
resultDistance[i] = tempDistances[tempMinimalIndex];
tempSelected[tempMinimalIndex] = true;
}
distanceMap.put(paraCurrent, resultDistance);
System.out.println("The nearest of " + paraCurrent + " are: " + Arrays.toString(resultNearests));
return resultNearests;
}
/**
* Voting using the instances
* @param paraNeighbors The indices of the neighbors.
* @return The predicted label.
*/
public int simpleVoting(int[] paraNeighbors) {
int[] tempVotes = new int[dataset.numClasses()]; //对k个邻居,看k个邻居种,那种类型的花最多则返回这个类型的花的索引。
for (int i = 0; i < paraNeighbors.length; i++) {
tempVotes[(int) dataset.instance(paraNeighbors[i]).classValue()]++;
}
int tempMaximalVotingIndex = 0;
int tempMaximalVoting = 0;
for (int i = 0; i < dataset.numClasses(); i++) {
if (tempVotes[i] > tempMaximalVoting) {
tempMaximalVoting = tempVotes[i];
tempMaximalVotingIndex = i;
}
}
return tempMaximalVotingIndex;
}
public int weightedVoting(int[] paraNeighbors, Integer weightModel, double[] tempDistances) {
int[] tempVotes = new int[dataset.numClasses()];
for (int i = 0; i < paraNeighbors.length; i++) {
//voting 花类型的索引index
int index = (int)dataset.instance(paraNeighbors[i]).classValue();
if (weightModel.equals(VOTE_SIMPLE)) {
tempVotes[index]++;
} else if (weightModel.equals(VOTE_DISTANCE_1)) {
// 因为本身paraNeighbors存储的顺序是按从小到大的顺序存储的,我用i做平替
tempVotes[index] += 1/(i+1);
} else if (weightModel.equals(VOTE_DISTANCE_2)) {
// 用具体的距离方式
tempVotes[index] += 1/tempDistances[i];
}
}
int tempMaximalVotingIndex = 0;
int tempMaximalVoting = 0;
for (int i = 0; i < dataset.numClasses(); i++) {
if (tempVotes[i] > tempMaximalVoting) {
tempMaximalVoting = tempVotes[i];
tempMaximalVotingIndex = i;
}
}
return tempMaximalVotingIndex;
}
/**
* leave-one-out test
*/
public void leaveOneOutTesting() {
System.out.println("leave one out test ..........................");
int tempSize = dataset.numInstances();
//int[] predicts = new int[tempSize];
int[] tempIndices = getRandomIndices(tempSize);
int tempCorrect = 0;
for (int i = 0; i < tempSize; i++) {
// 分训练集和测试集 (测试集一个.其余为训练集)
splitByIndex(tempIndices, i);
int[] neighbors = computeNearests(tempIndices[i]);
int resultPrediction = weightedVoting(neighbors, voteDistance, distanceMap.get(tempIndices[i]));
if(resultPrediction == dataset.instance(tempIndices[i]).classValue()){
tempCorrect++;
} else{
System.out.println(tempIndices[i] + " The resultPrediction " + resultPrediction + " and actual result " + dataset.instance(tempIndices[i]).classValue());
}
}
System.out.println("The total size " + tempSize + ", after leave-one-test, the correct predict size :" + tempCorrect);
}
/**
* split for leave-one-out test
* @param tempIndices the given dataSet
* @param index the index
*/
public void splitByIndex(int[] tempIndices, int index) {
int tempSize = dataset.numInstances();
int tempTrainingSize = tempSize - 1;
testingSet = new int[1];
trainingSet = new int[tempTrainingSize];
testingSet[0] = tempIndices[index];
int j = 0;
for (int i = 0; i < tempSize; i++) {
if (i == index) {
continue;
}
trainingSet[j++] = tempIndices[i];
}
}
public static void main(String[] args) {
KnnClassification tempClassifier = new KnnClassification("C:/Users/王忠云/Desktop/iris.arff");
tempClassifier.leaveOneOutTesting();
tempClassifier.splitTrainingTesting(0.8);
tempClassifier.predict();
System.out.println("The accuracy of the classifier is: " + tempClassifier.getAccuracy());
}
}