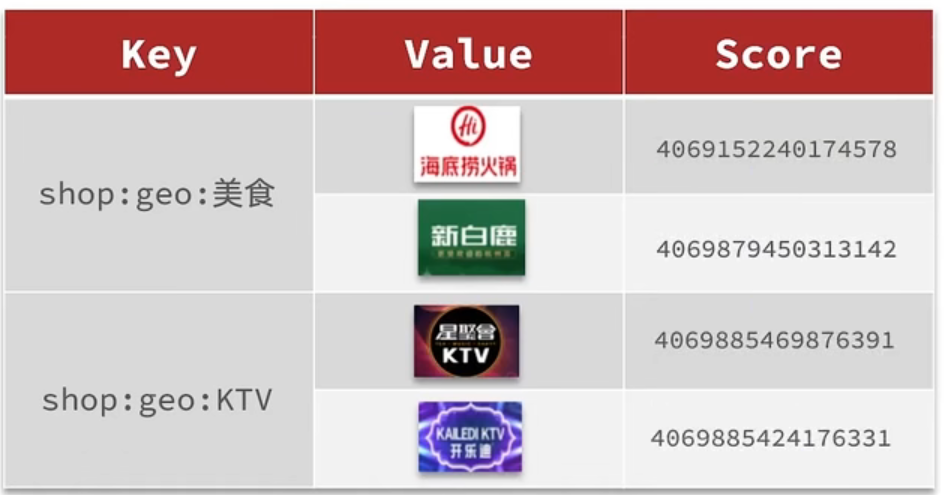
1 MobileNetV3介绍
MobileNetV3 是由 google 团队在 2019 年提出的轻量化网络模型,传统的卷积神经网络,内容需求大,运算量大,无法再移动设备以及嵌入式设备上运行,为了解决这一问题,MobileNet网络应运而生。MobileNetV3在移动端图像分类、目标检测、语义分割等任务上均取得了优秀的表现。MobileNetV3采用了很多新的技术,包括针对通道注意力的Squeeze-and-Excitation模块、NAS搜索方法等,这些方法都有利于进一步提升网络的性能。
MobileNetV3论文地址:https://openaccess.thecvf.com/content_ICCV_2019/papers/Howard_Searching_for_MobileNetV3_ICCV_2019_paper.pdf MobileNetV3的整体架构基本沿用了MobileNetV2的设计,采用了轻量级的深度可分离卷积和残差块等结构,依然是由多个模块组成,但是每个模块得到了优化和升级,包括瓶颈结构、SE模块和NL模块。MobileNetV3https://openaccess.thecvf.com/content_ICCV_2019/papers/Howard_Searching_for_MobileNetV3_ICCV_2019_paper.pdf在 ImageNet 分类任务中正确率上升了 3.2%,计算延时还降低了20%。
整体来说MobileNetV3有两大创新点:
1)互补搜索技术组合:由资源受限的NAS执行模块级搜索,NetAdapt执行局部搜索。
2)网络结构改进:将最后一步的平均池化层前移并移除最后一个卷积层,引入h-swish激活函数。
MobileNetV3 有两个版本,MobileNetV3-Small 与 MobileNetV3-Large 分别对应对计算和存储要求低和高的版本。
2 MobileNetV3的网络结构
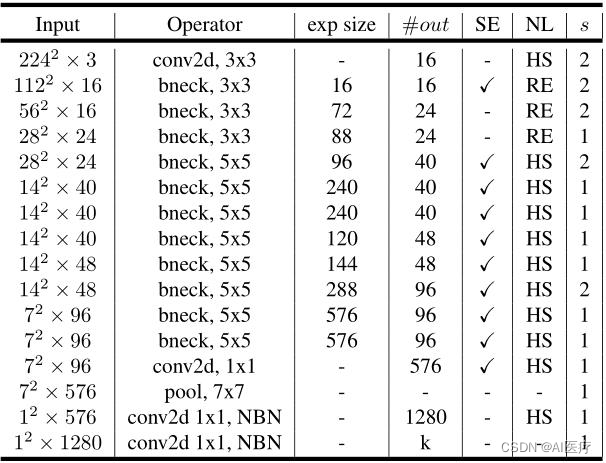
1)MobileNetV3-Large的网络结构:
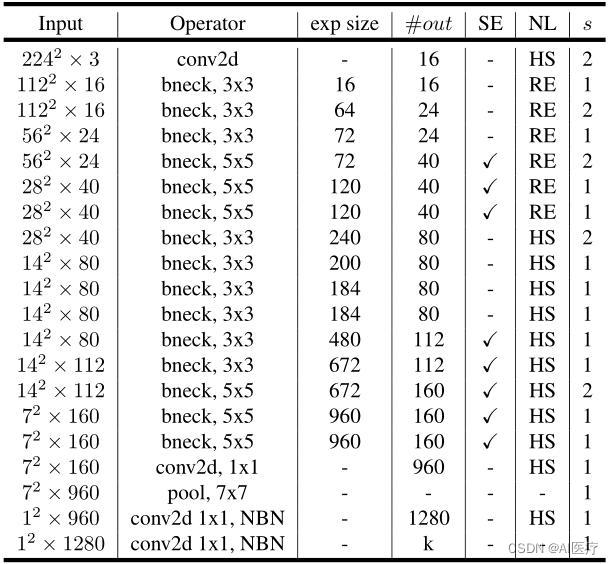
2)MobileNetV3-Small的网络结构:
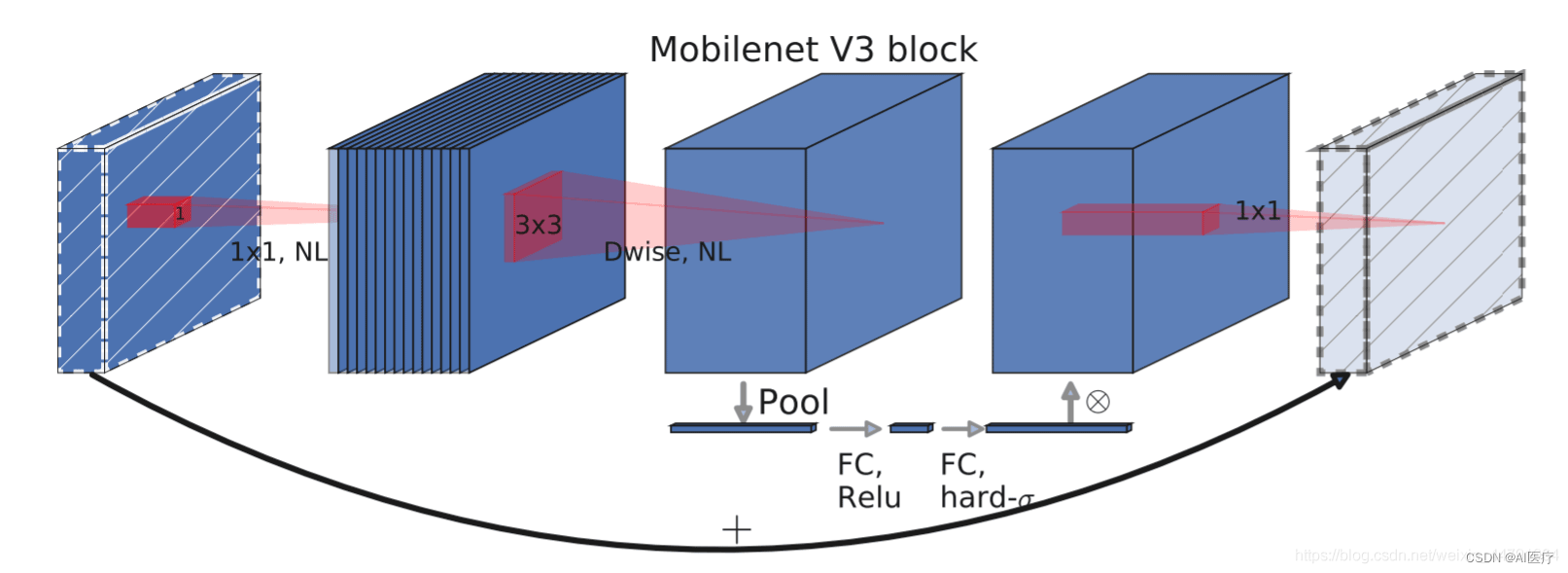
MobileNetV3特有的bneck结构:
3 MobileNetV3基于pytorch在CIFAR10数据集上的实现
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import transforms
from torchvision.transforms.transforms import ToTensor
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
import datetime
class hswish(nn.Module):
def __init__(self, inplace=True):
super(hswish, self).__init__()
self.inplace = inplace
def forward(self, x):
f = nn.functional.relu6(x + 3., inplace=self.inplace) / 6.
return x * f
class hsigmoid(nn.Module):
def __init__(self, inplace=True):
super(hsigmoid, self).__init__()
self.inplace = inplace
def forward(self, x):
f = nn.functional.relu6(x + 3., inplace=self.inplace) / 6.
return f
class SeModule(nn.Module):
def __init__(self, in_channels, se_ratio=0.25):
super(SeModule, self).__init__()
self.se_reduce = nn.Conv2d(in_channels, int(in_channels * se_ratio), kernel_size=1, stride=1, padding=0)
self.se_expand = nn.Conv2d(int(in_channels * se_ratio), in_channels, kernel_size=1, stride=1, padding=0)
def forward(self, x):
s = nn.functional.adaptive_avg_pool2d(x, 1)
s = self.se_expand(nn.functional.relu(self.se_reduce(s), inplace=True))
return x * s.sigmoid()
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.act = hswish()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class SqueezeExcitation(nn.Module):
def __init__(self, in_channel, out_channel, reduction=4):
super(SqueezeExcitation, self).__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(in_channel, out_channel // reduction, kernel_size=1, stride=1)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(out_channel // reduction, out_channel, kernel_size=1, stride=1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.pool(x)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
return out
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, use_se=True):
super(ResidualBlock, self).__init__()
self.conv1 = ConvBlock(in_channels, out_channels, kernel_size, stride, kernel_size // 2)
self.conv2 = ConvBlock(out_channels, out_channels, kernel_size, 1, kernel_size // 2)
self.use_se = use_se
if use_se:
self.se = SqueezeExcitation(out_channels, out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
if self.use_se:
out = out * self.se(out)
out += self.shortcut(x)
out = nn.functional.relu(out, inplace=True)
return out
class MobileNetV3Large(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3Large, self).__init__() #
self.conv1 = ConvBlock(3, 16, 3, 2, 1) # 1/2
self.bottlenecks = nn.Sequential(
ResidualBlock(16, 16, 3, 1, False),
ResidualBlock(16, 24, 3, 2, False), # 1/4
ResidualBlock(24, 24, 3, 1, False),
ResidualBlock(24, 40, 5, 2, True), # 1/8
ResidualBlock(40, 40, 5, 1, True),
ResidualBlock(40, 40, 5, 1, True),
ResidualBlock(40, 80, 3, 2, False), # 1/16
ResidualBlock(80, 80, 3, 1, False),
ResidualBlock(80, 80, 3, 1, False),
ResidualBlock(80, 112, 5, 1, True),
ResidualBlock(112, 112, 5, 1, True),
ResidualBlock(112, 160, 5, 2, True), # 1/32
ResidualBlock(160, 160, 5, 1, True),
ResidualBlock(160, 160, 5, 1, True)
)
self.conv2 = ConvBlock(160, 960, 1, 1, 0)
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(960, 1280),
nn.BatchNorm1d(1280),
nn.Hardswish(inplace=True),
nn.Linear(1280, num_classes),
)
def forward(self, x):
out = self.conv1(x)
out = self.bottlenecks(out)
out = self.conv2(out)
out = self.pool(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
class MobileNetV3Small(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3Small, self).__init__()
self.conv1 = ConvBlock(3, 16, 3, 2, 1) # 1/2
self.bottlenecks = nn.Sequential(
ResidualBlock(16, 16, 3, 2, False), # 1/4
ResidualBlock(16, 72, 3, 2, False), # 1/8
ResidualBlock(72, 72, 3, 1, False),
ResidualBlock(72, 72, 3, 1, True),
ResidualBlock(72, 96, 3, 2, True), # 1/16
ResidualBlock(96, 96, 3, 1, True),
ResidualBlock(96, 96, 3, 1, True),
ResidualBlock(96, 240, 5, 2, True), # 1/32
ResidualBlock(240, 240, 5, 1, True),
ResidualBlock(240, 240, 5, 1, True),
ResidualBlock(240, 480, 5, 1, True),
ResidualBlock(480, 480, 5, 1, True),
ResidualBlock(480, 480, 5, 1, True),
)
self.conv2 = ConvBlock(480, 576, 1, 1, 0, groups=2)
self.conv3 = nn.Conv2d(576, 1024, kernel_size=1, stride=1, padding=0, bias=False)
self.bn = nn.BatchNorm2d(1024)
self.act = hswish()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(1024, num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.bottlenecks(out)
out = self.conv2(out)
out = self.conv3(out)
out = self.bn(out)
out = self.act(out)
out = self.pool(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
transform = transforms.Compose([ToTensor(),
transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
),
transforms.Resize((224, 224))
])
train_data = datasets.CIFAR10(
root="data",
train=True,
download=True,
transform=transform,
)
test_data = datasets.CIFAR10(
root="data",
train=False,
download=True,
transform=transform,
)
def get_format_time():
return datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
if __name__ == '__main__':
batch_size = 64
train_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=True, drop_last=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MobileNetV3Large(num_classes=10).to(device)
print(model)
cross = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), 0.001)
train_loss = 0
train_accuracy = 0
epochs = 10
accuracy_rate = []
for epoch in range(epochs):
print(f'{get_format_time()}, train epoch: {epoch}/{epochs}')
train_correct = 0
for step, (images, labels) in enumerate(train_loader, 0):
images, labels = images.to(device), labels.to(device)
outputs = model.forward(images)
train_loss = cross(outputs, labels)
train_loss.backward()
optimizer.zero_grad()
optimizer.step()
predicted = torch.argmax(outputs, 1)
correct = torch.sum(predicted == labels)
train_correct += correct
train_accuracy = train_correct / len(train_data)
print(f"{get_format_time()}, loss:{train_loss.item()}, accuracy:{train_accuracy}")
test_total = 0
test_correct = 0
test_loss = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images).to(device)
loss = cross(outputs, labels)
_, predicted = torch.max(outputs, 1)
test_total += labels.size(0)
test_correct += torch.sum(predicted == labels.data)
test_loss += loss.item()
accuracy = 100 * test_correct / test_total
accuracy_rate.append(accuracy)
print("{}, Train Loss is:{:.4f}, Train Accuracy is:{:.4f}%, Test Loss is::{:.4f} Test Accuracy is:{:.4f}%".format(
get_format_time(),
train_loss / len(train_data),
100 * train_correct / len(train_data),
test_loss / len(test_data),
100 * test_correct / len(test_data)
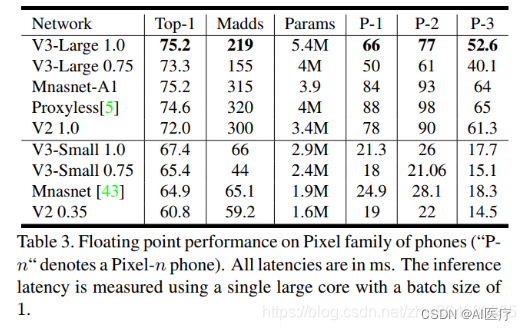
))4 不同大小的MobileNet模型结果比较





![[数字图像处理]第四章 频率域滤波](https://img-blog.csdnimg.cn/b4a8edd4b3e84cef9de4984c21a5abb8.png)