1 问题提出
最近在阅读某个论文的源代码时, 发现作者在读取图像数据时没有使用PIL.Image或opencv库,而是使用了tf.image.decode_jpeg,代码节选如下:
# tf1中的函数, 用于读取文件
# tf2中该函数更改为了tf.io.read_file
image_contents = tf.read_file(img_path)
# tf.image.decode_jpeg别名tf.io.decode_jpeg, 用于将JPEG编码的图像解码为uint8张量
# channels参数设置返回的张量的通道数量
image = tf.image.decode_jpeg(image_contents, channels=3)在这里加载的原始数据是灰度数据,即通道数为1。
然而作者为了使用预训练的VGG16模型,在加载数据时将通道数channels参数设置为了3。
因为预训练的VGG16模型在ImageNet数据集上进行的预训练,而ImageNet的单张图片数据是形状为[3, 224, 224]的矩阵,这意味着预训练的VGG16模型的结构要求输入数据的通道数为3。
所以在使用预训练的VGG16模型时,如果处理的数据是灰度数据,需要额外处理将通道数变换为3。
我了解到的做法有4种:
(1)使用一个卷积核为1的卷积(Conv 1X1)将灰度图像的通道数增大为3
(2)处理预训练的VGG16的第一个卷积的参数,将三通道的权重参数求和
例如第一个卷积是
Conv2d(3, 64, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1))
那么权重矩阵就是64个[3, 4, 4]的矩阵,即形状为[64, 3, ,4, 4]的矩阵
将第2个维度的参数求和,则权重矩阵变换为形状为[64, 1, ,4, 4]的矩阵
(3)将灰度图在第一个维度复制三遍,则图像数据从[1, h, w]变换为[3, h, w]
(4)使用伪彩色处理算法将灰度图转换为彩色图像,从而将图像数据从[1, h, w]变换为[3, h, w]
一般是通过查表法或者其他映射函数将灰度值映射到指定的R,G,B值
伪彩色相关参考资料:
https://www.cnblogs.com/CiciXuanblog/p/15986085.html![]() https://www.cnblogs.com/CiciXuanblog/p/15986085.html
https://www.cnblogs.com/CiciXuanblog/p/15986085.html
【OpenCV 例程300篇】203. 伪彩色图像处理_opencv neser_youcans_的博客-CSDN博客NASA 公布了蟹状星云 (Crab Nebula )的观测图像。茫茫太空,距离我们几亿光年的宇宙真是这样绚丽迷人吗?NASA 专家撰文指出,蟹状星云彩色照片实际上人工合成的图像,这是不是暗示照片中的彩色是伪造的?伪彩色图像在形式和视觉表现为彩色图像,但其所呈现的颜色并非图像的真实色彩重现,仅仅是各颜色分量的像素值合成的结果。..................https://blog.csdn.net/youcans/article/details/125298385
图像分析——伪彩色图像、heatmap图像 | 码农家园一、Opencv 伪彩色图像最重要的是cv2.applyColorMap(heatmap, cv2.COLORMAP_JET),将np.unit8格式的矩阵转化为colormap,第二个参数有很多种配色方案,上面这...
进而我就产生了一个疑问:
如果channels参数设置为3,那么在函数tf.image.decode_jpeg的处理过程中具体是以上四种做法的3还是4呢?
我复现该论文使用的pytorch框架,搞清楚tf.image.decode_jpeg的工作原理对我来说很重要,而官方文档里面没有提到此事,因此我开始尝试解析。
tf.image.decode_jpeg函数的文档链接如下:
TensorFlow函数教程:tf.io.decode_jpeg_w3cschooltf.io.decode_jpeg函数 别名: tf.image.decode_jpeg tf.io.decode_jpegtf.io.decode_jpeg( contents, channels=_来自TensorFlow官方文档,w3cschool编程狮。
 https://tensorflow.google.cn/versions/r2.2/api_docs/python/tf/io/decode_jpeg
https://tensorflow.google.cn/versions/r2.2/api_docs/python/tf/io/decode_jpeg
2 理论分析
如果tf.image.decode_jpeg使用的第3种方法, 那么三个通道的像素值是一样的。
如果使用的第4种方法,那么三个通道的像素值大概率是不一样的。
因此只需要将tf.image.decode_jpeg处理后的数据的像素值输出看看就知道了
3 实验代码以及结果
测试代码如下:
test.jpg是一张灰度图像
# 观察tf.image.decode_jpeg的工作原理
# 图像路径
current_img_path = './test.jpg'
# 读取图像文件
raw_img_data = tf.io.read_file(current_img_path)
# 获取像素值矩阵
# dct_method='INTEGER_ACCURATE'是为了保证读取出来的像素值与Image.open保持一致
# 不加的话, tf的API可能会为了加速读取而造成值的不准确, 进而限制模型训练中的上限性能
# 参考资料:
# https://www.coder.work/article/6243772
image1 = tf.image.decode_jpeg(raw_img_data, channels=3, dct_method='INTEGER_ACCURATE').numpy() # 使用tf.image.decode_jpeg函数,通道参数设置为3
# 使用tf.image.decode_jpeg函数,通道参数根据原始数据自行确定
image2 = tf.image.decode_jpeg(raw_img_data, dct_method='INTEGER_ACCURATE').numpy()
# 使用Image.open读取图像,指定为灰度图
image3 = np.array(Image.open(current_img_path).convert("L"))
# 在数据末尾增加一个维度
image3 = np.expand_dims(image3, axis=2)
# 查看矩阵形状
print(image1.shape) # (288, 352, 3)
print(image2.shape) # (288, 352, 1)
print(image3.shape) # (288, 352, 1)在运行时使用debug模式,在最后一行打上断点
再使用pycharm的SciView观察三个矩阵的数据(也可以使用print函数+矩阵切片的方式观察数据)
发现tf.image.decode_jpeg使用的第3种方法, 三个通道的像素值是一样的
截图如下:
image1矩阵数据如下
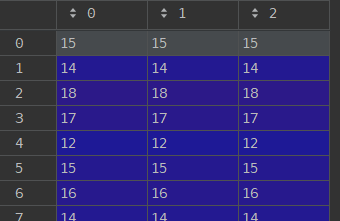
image2矩阵数据如下

image3矩阵数据如下