文章目录
- 背景
- 压测准备
- 初步压测结论
- 排查过程记录
- 排除中间件及网络因素
- 借助Arthas及Skywalking
- 暴露prometheus指标
- 修改数据库最大连接池数
- 场景一
- 场景二
- 场景三
- 场景四
- 场景五
- 场景六
- 场景七
- 场景八
- 结论
- Consumer消费能力优化
- 增加消费者
- 增加Topic Queue数量
- Queue总数:96
- Queue总数:192
- Queue总数:900
- 调整消费程序http最大连接池数
- Consumer参数微调
- 总结
- 优化总结
- 经验总结
背景
事件中心服务新增定时消息功能:
- 基于 RocketMQ 5.0 的 TimerMessage 特性,作为触发定时消息的机制;
- 事件中心API(pubsub)提供新的定时消息接口,作为定时消息的提交入口;
- 定时消息元数据保存至 TiDB,RocketMQ 内只保存定时消息对应的主键ID;
- 定时消息执行服务消费 RocketMQ 指定 Topic ,调用事件中心回调接口,发送消息至Kafka;
- 为消息保证顺序性,RocketMQ Consumer 使用顺序消费。
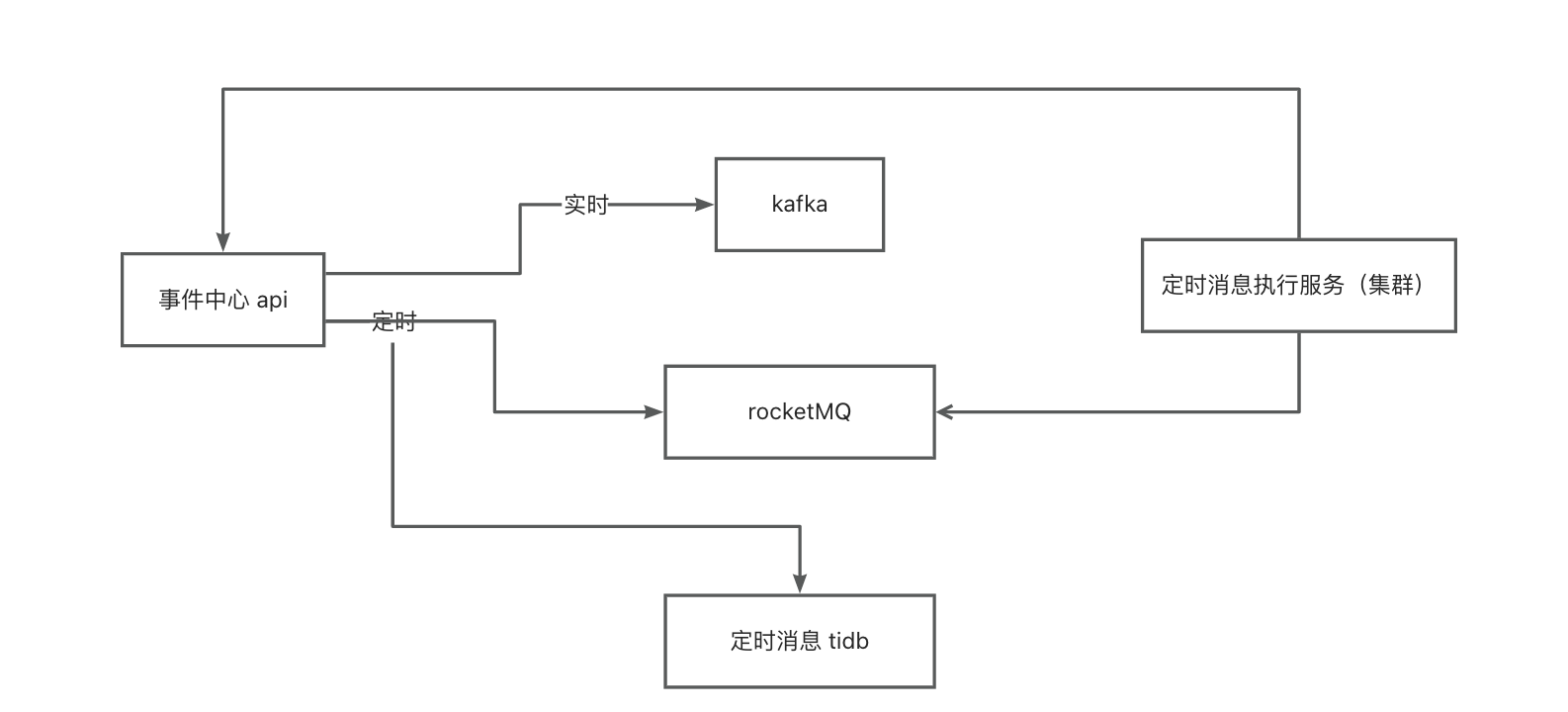
定时消息的链路为:定时消息接口(pubsub) --> TiDB、RocketMQ --> 定时消息执行服务(Consumer) --> 定时消息回调接口 --> Kafka
本次压测及调优,只针对定时消息接口、定时消息执行服务(Consumer)、定时消息回调接口。
压测准备
压测意图:
-
测试提交定时消息接口在不同 QPS 时的 RT 情况
-
观测pubsub服务在负载情况下的资源使用情况
-
测试consumer的消费能力、得出消息积压与Consumer数量的比例
-
测试定时消息回调接口的QPS峰值
场景描述:
-
pubsub单实例,最终调整配置和生产环境一致
- limit:8c-8g
- -Xms4G -Xmx4G
-
模拟固定QPS对提交定时消息接口进行压测:
- QPS 1000
- QPS 3000
- QPS 5000
-
堆积一定数量的定时消息:
- 观察Consumer消费速度
- 观察定时消息回调接口RT情况
- 观察pubsub服务资源使用情况
观测指标:
pubsub服务器:
-
机器CPU使用情况
- top -Hp {jvm_pid}
-
查看线程级别 user, system 情况
- 火焰图
-
主机 load
-
GC 情况
- 若没有 gc 日志,用 jstat 临时输出一下
-
内存增长情况
-
线程情况
-
接口耗时(通过压测平台监控查看)
- 99.99% RT
- 平均 RT
定时消息执行服务:
-
consumer TPS
-
consumer 服务监控
- jvm监控
- httpclient监控
- QPS
- RT
-
consumer 主机监控
- cpu
- load
- memory
-
pubsub服务器:
- 机器CPU使用情况
- 内存增长情况
-
消息延迟情况
- 对比数据库期望发送时间和实际发送时间
初步压测结论
-
pubsub服务2c-6g,单实例;Consumer服务2c-6g,单实例
-
定时消息提交接口并发数1000,思考时间为1000ms,模拟QPS为1000的场景,平均RT在好几秒,吞吐量只有200左右
-
单个消费者TPS只有60左右
-
pubsub服务及Consumer服务资源使用率均保持在很低水平
-
pubsub服务young GC频繁
离预期相距甚远,预期是可以承受上万条消息积压仍能保持毫秒级别的误差,所以优化目标为:
- 提升pubsub定时消息接口单实例QPS至3000+,99.99% RT 在200ms内;
- 提升Consumer消费TPS至10000+
排查过程记录
排除中间件及网络因素
在pubsub服务实例上ping TiDB、RocketMQ服务地址,延迟均为5ms内,先排除网络原因。
使用相同的压测脚本,尝试压了测试环境的pubsub服务,测试环境的压测结果很正常,QPS达到预期设置的1000,平均RT在10ms内,测试环境使用的是MySQL,生产环境使用的是新申请的阿里云服务器搭建的TiDB,怀疑是TiDB服务端配置或者其他原因导致影响性能。
将生产环境上pubsub使用的TiDB换为同网络环境的MySQL,压测情况并无变化,排除。
RocketMQ服务在相同网段进行过压测,压测结果正常,排除。
由于测试环境和生产环境压测结果大相径庭,很长一段时间的排查方向都指向了生产环境k8s的网络、组件间的延迟等,于是又把pubsub部署至生产环境的一台物理机上,结果任然保持不变。
客观测试了一下测试环境和生产环境的网络差异:
并发数 1,思考时间 1000ms
测试环境:

生产环境:

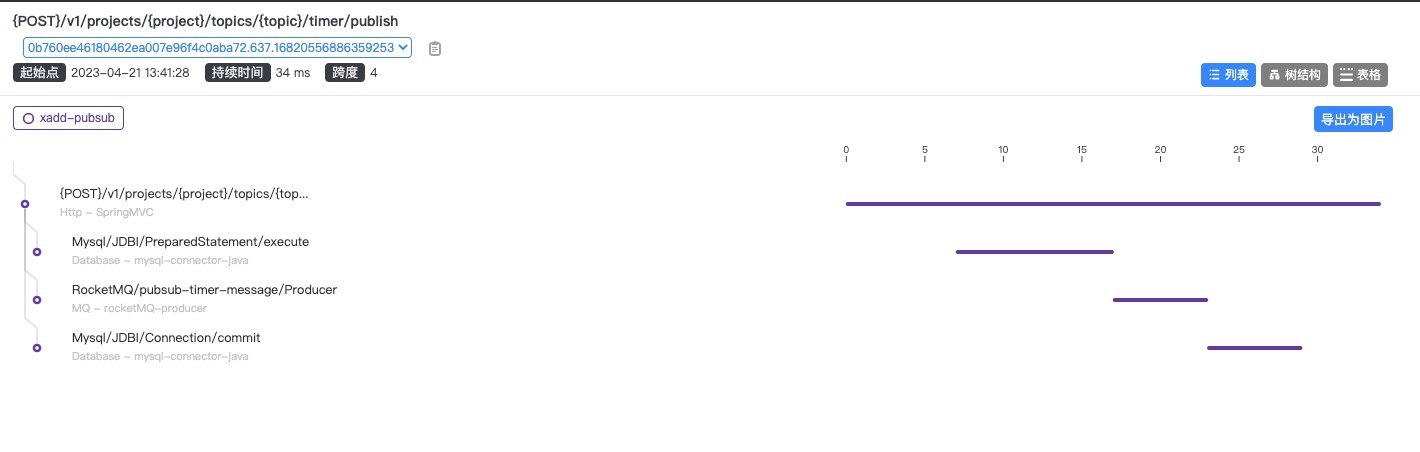
分析
每次接口提交,大致产生的跨进程交互如下:
| 内容 | 测试环境耗时 | 生产环境耗时 | |
|---|---|---|---|
| 施压机到pubsub主机 | 0.18 | 0.6 | |
| pubsub主机到tidb,开启事务 | 0.06 | 4.9 | |
| pubsub主机到tidb,运行 sql | 0.06 | 4.9 | |
| pubsub主机到rocketMQ,生产消息 | 0.3 | 4 | |
| pubsub主机到tidb,提交事务 | 0.06 | 4.9 | |
| 总计 | 0.66 | 19.3 | |
| 本场景压测RT平均值 | 7.98 | 40.93 |
结论:
由于测试环境的物理距离问题,天然有至少5倍左右的性能差异,所以测试环境的压测结果超出预期的理想,得益于各组件的网络低延迟,但是生产环境的网络延迟属于正常范围,还需进一步排查。
借助Arthas及Skywalking
使用 Arthas 的 trace 命令,对接口的主要逻辑方法进行耗时追踪:
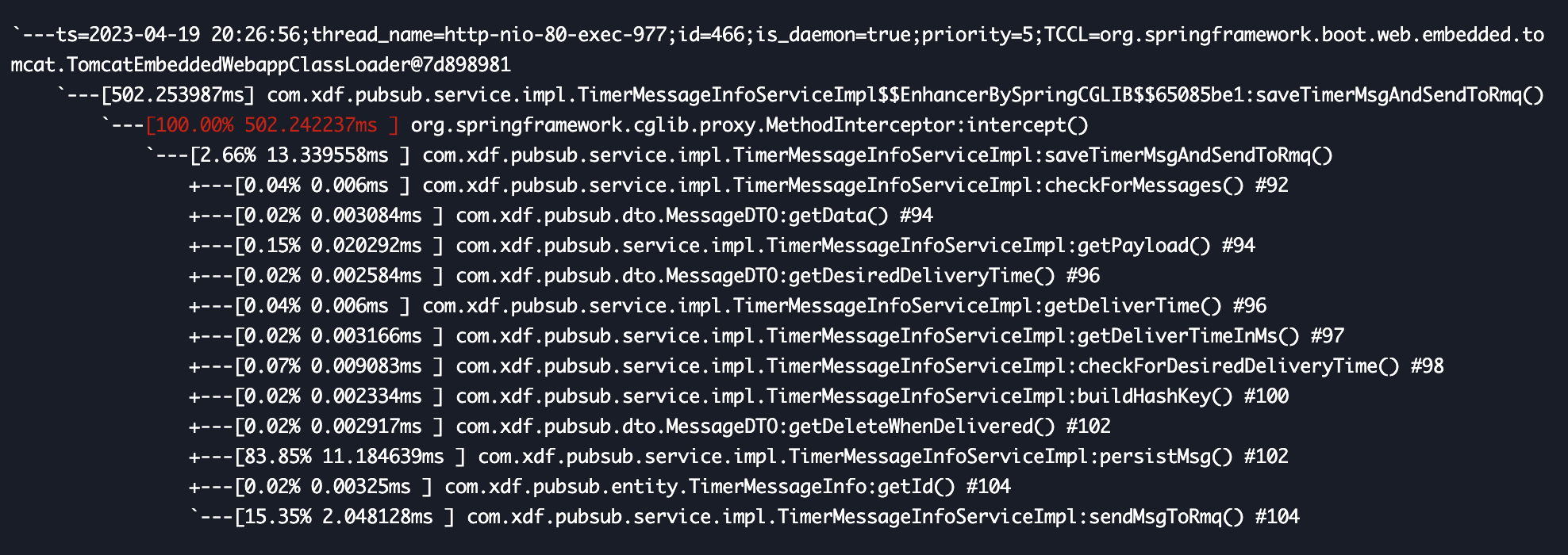
发现真正执行逻辑的代码只耗时13ms左右,但是执行方法之前,有一个500多ms的耗时。
使用skywalking观察耗时很长的请求,结果如下:
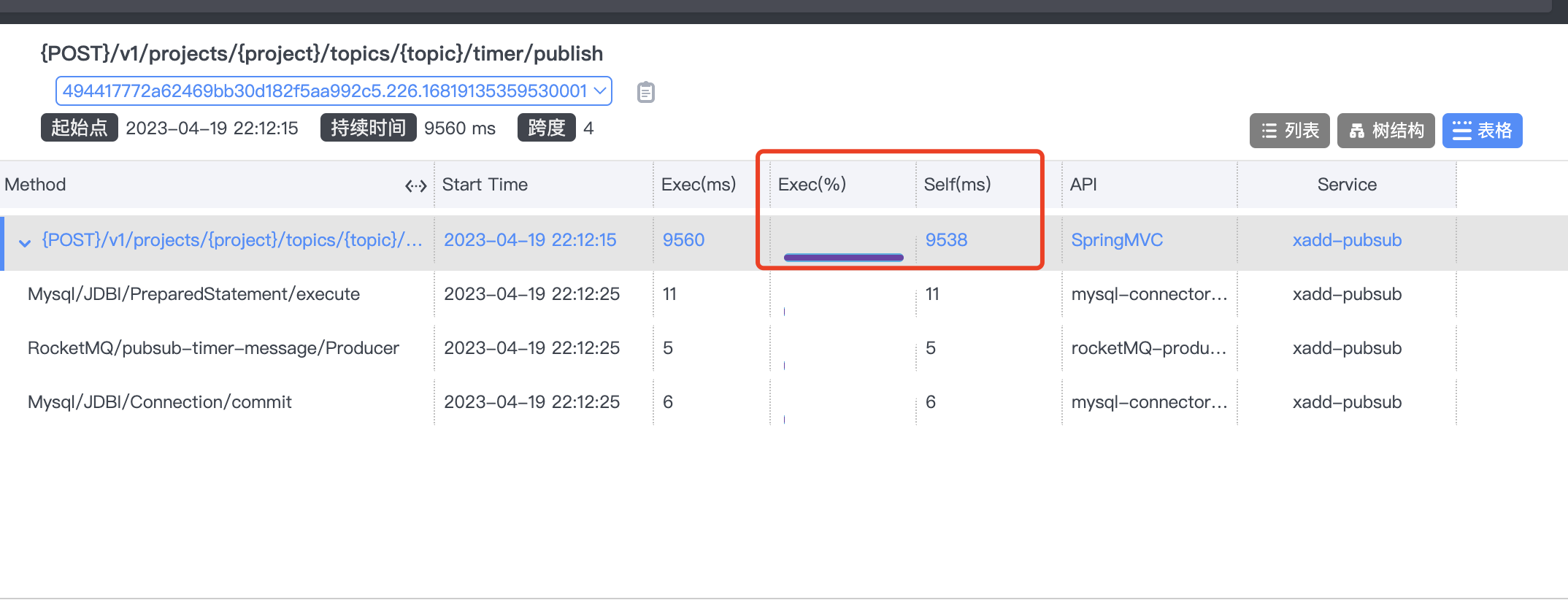
结论相同,在执行SQL前,有一个很长的等待时间,初步定位到问题,怀疑是数据库连接池的问题。
暴露prometheus指标
pom文件中添加:
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
<scope>runtime</scope>
</dependency>
添加配置:
# 对外暴露所有监控指标
management:
endpoints:
web:
exposure:
include: "*"
endpoint:
prometheus:
enabled: true # 激活普罗米修斯
health:
show-details: always # 健康值总是展示细节
metrics:
export:
prometheus:
enabled: true # 指标允许被导出
启动服务后,访问:/actuator/prometheus
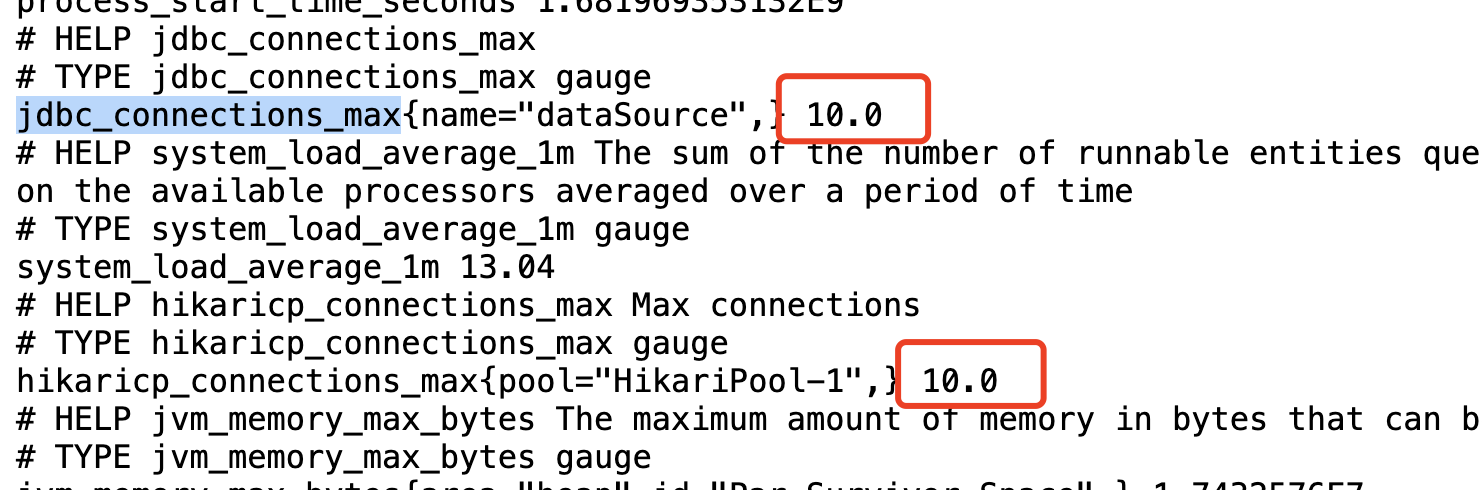

可以看到默认连接池最大数量是10,大量并发情况下,获取连接池时,耗费了大量的时间。
修改数据库最大连接池数
场景一至场景四:并发数 500,思考时间 400 ms
场景一
pubbsub 调整内容:
- tomcat 线程数改为 64
- connection 连接池数量改为 10

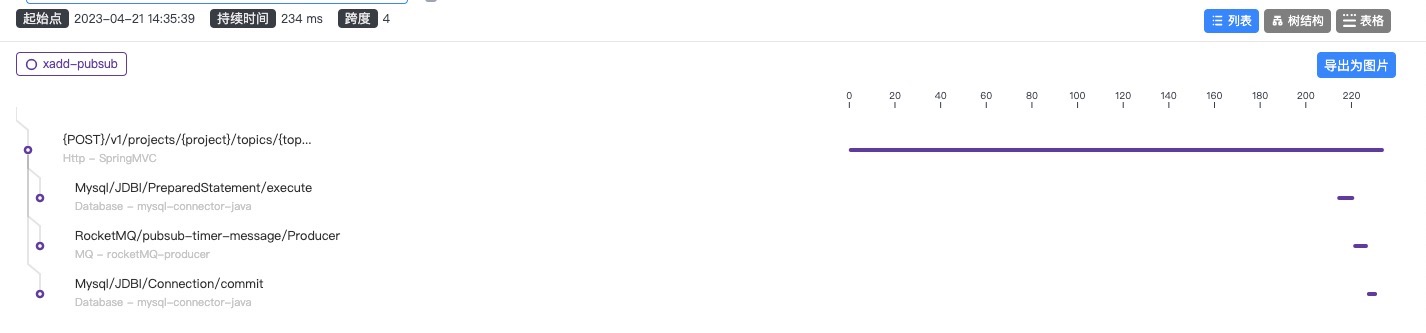
分析
- cpu 使用率不高,execute 前执行时间较长,怀疑是获取 jdbc connection 时间较长,更改 hikari 连接池数量为 32
- 压测平台与 sk 查看不同,是因为存在请求积压,即等待了一段时间后,才开始被执行
场景二
pubsub 调整内容:
- tomcat 线程数改为 64
- connection 连接池数量改为 32
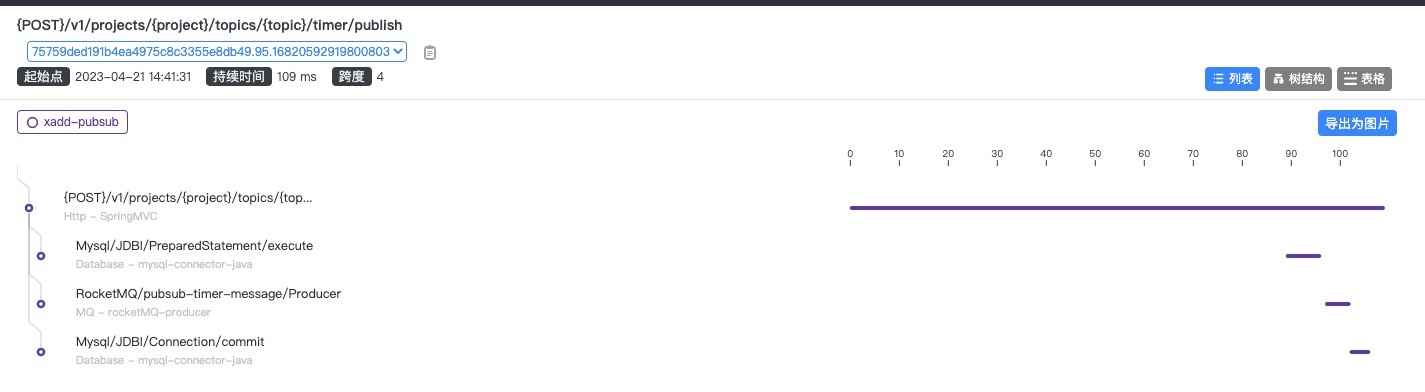
第一次压测:

第二次压测:
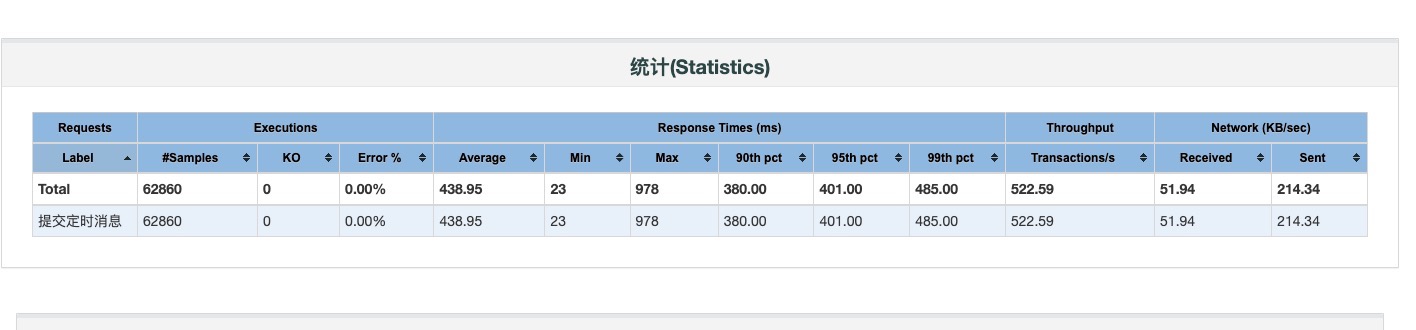

分析:
- 从 skywalking 看执行时间已经明显缩短,应该是增大了 connection 连接数导致
- 第二次执行压测时,性能已明显上升,应该是第一次压测时连接池还没有达到指定数量,都要重新建立连接,导致耗时较长
- cpu 使用率升高,说明线程使用 cpu 的时间多了起来,是正确的优化方向
场景三
pubsub 调整内容:
- tomcat 线程数改为 64
- connection 连接池数量改为 64
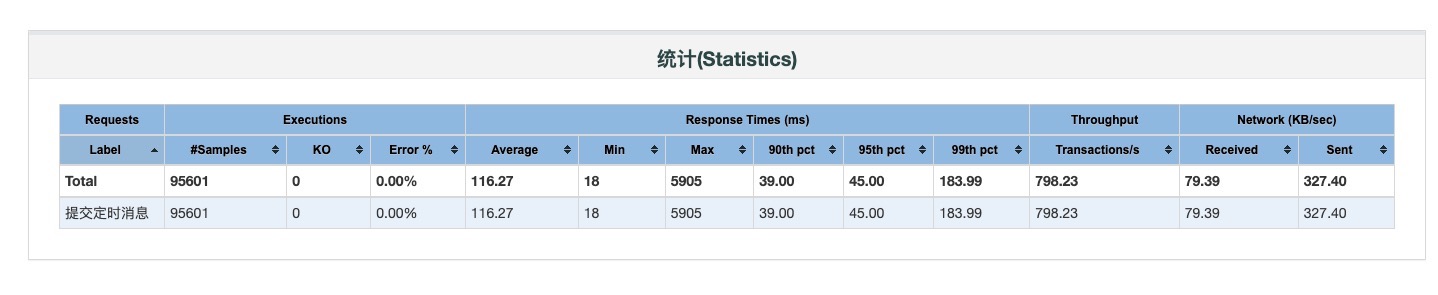
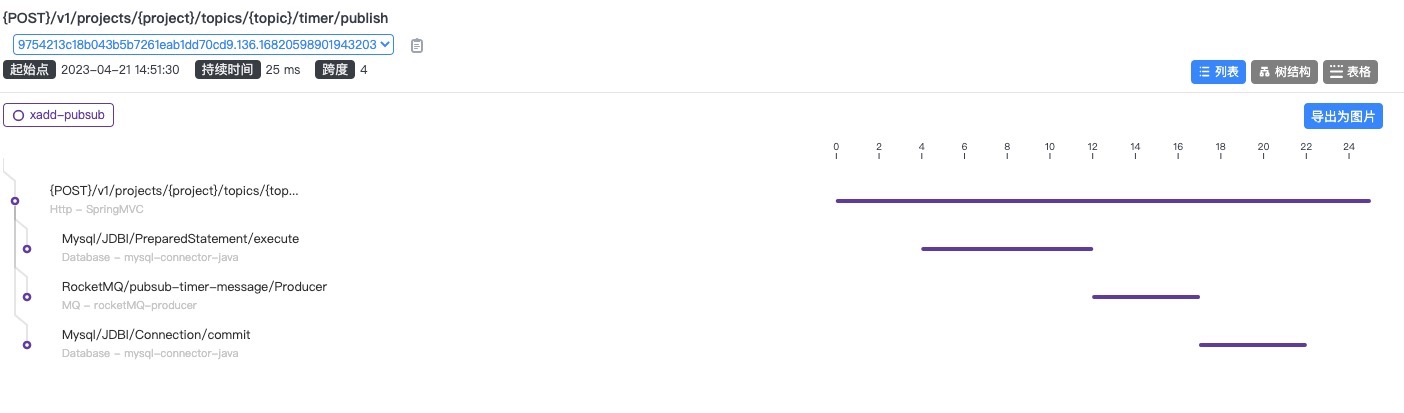

分析:
- 用在等待连接方面的耗时几乎已经没有
- cpu 还有一定空闲资源,进一步增大线程数和对应的连接数
场景四
pubsub 调整内容:
- tomcat 线程数改为 128
- connection 连接池数量改为 128

分析:
- cpu 已到达瓶颈,调整线程数量收益应该不太明显了
- 这时调整 gc 相关参数应该会有些收益
场景五
尝试提升压力,观察 RT 情况:并发数 500,思考时间 400 ms

分析:
- CPU 使用率下降,可能是 c2 代码优化已经完成
- TPS 上涨,RT 没有明显变化,继续加压
场景六
并发数 500,思考时间 300 ms

分析
- cpu 没有到达瓶颈,继续加压
场景七
并发数 500,思考时间 200 ms

场景八
pubsub 调整内容:
- tomcat 线程数改为 200
- connection 连接池数量改为 200
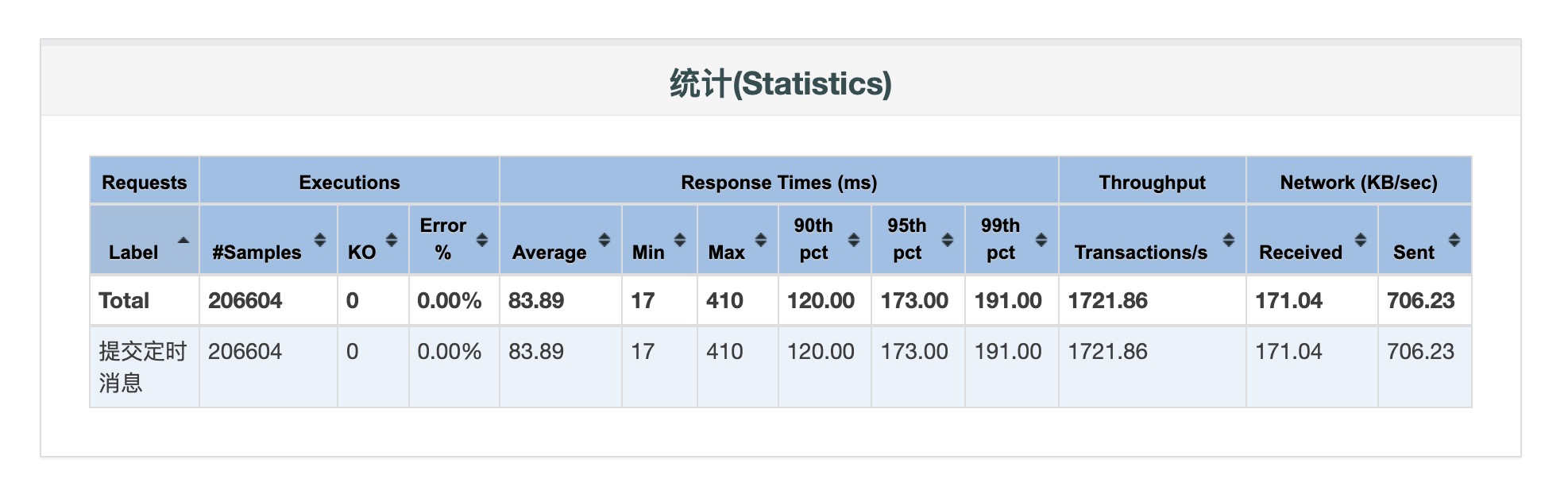
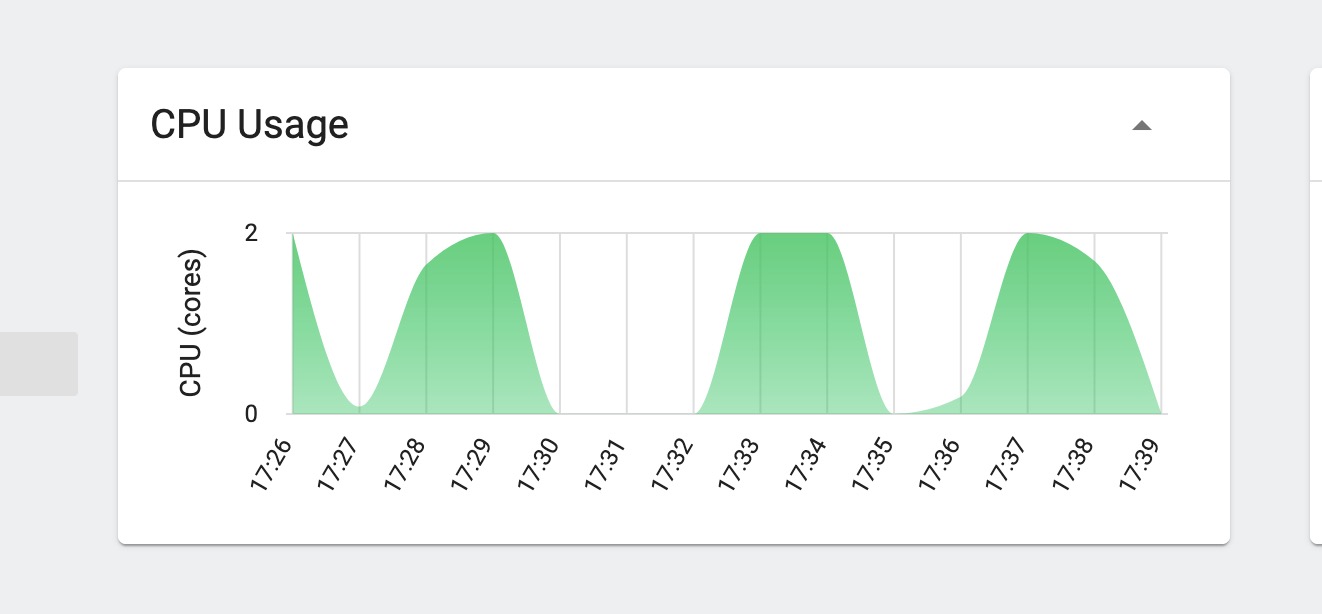
分析:
CPU已打满,继续增加线程数无提升,线程数已接近理想状态值。
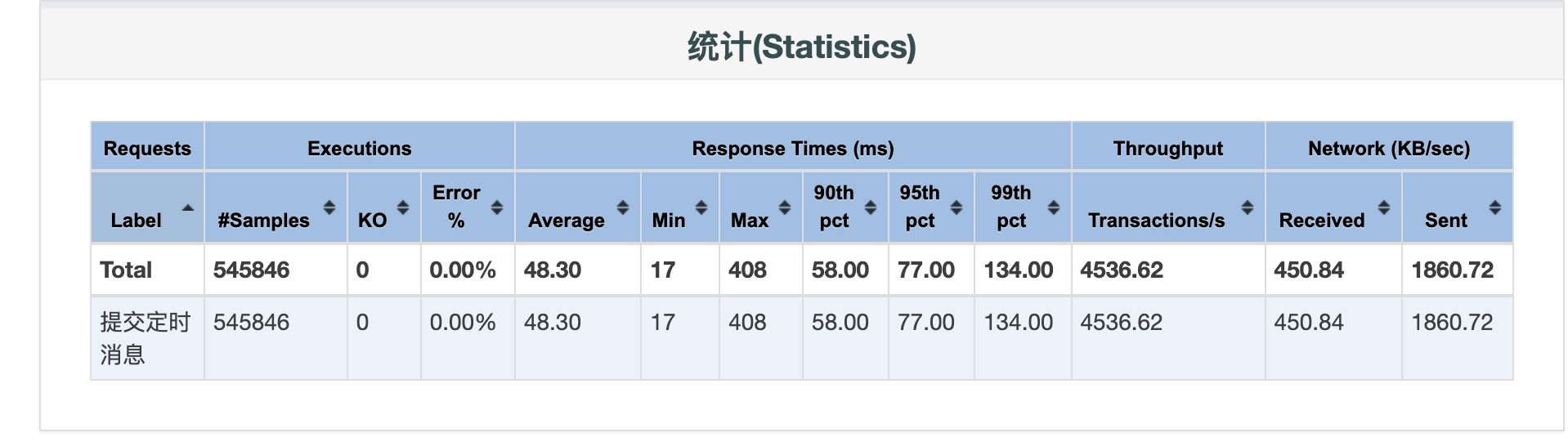
结论
CPU核数、Tomcat线程数、数据库连接池数比例约为:
1:100:100
将pubsub服务CPU核数修改为:8c,Tomcat线程数、数据库连接池数修改为:800
Consumer消费能力优化
初始状态:
- Consumer服务:2c-6g,启动一个消费者
- RocketMQ Topic读写队列总数均为48
- pubsub服务:8c-6g,单实例
- 消费者TPS:60左右
增加消费者
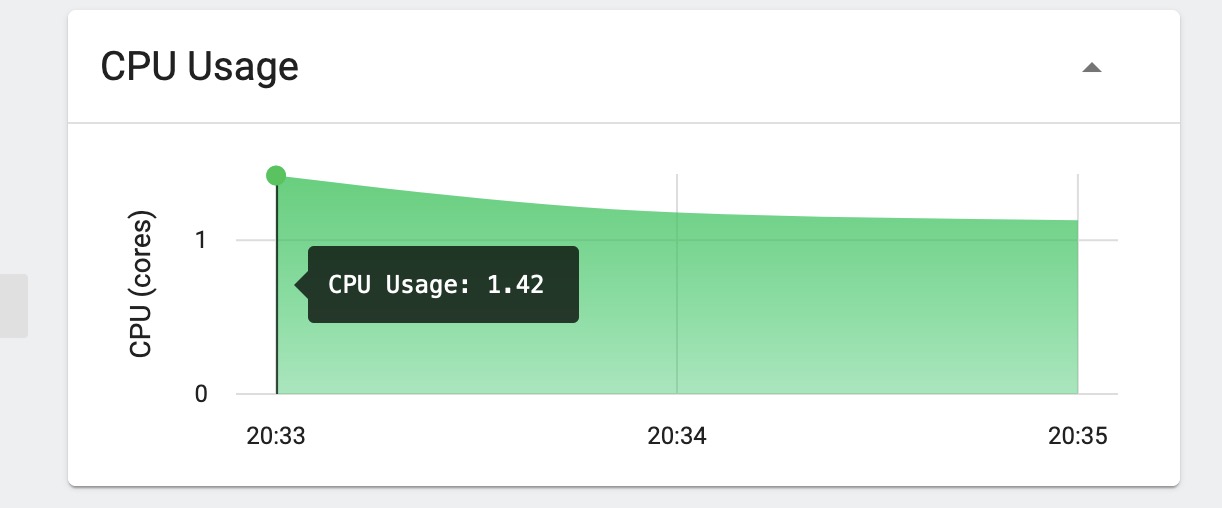
将消费者增加至20个:
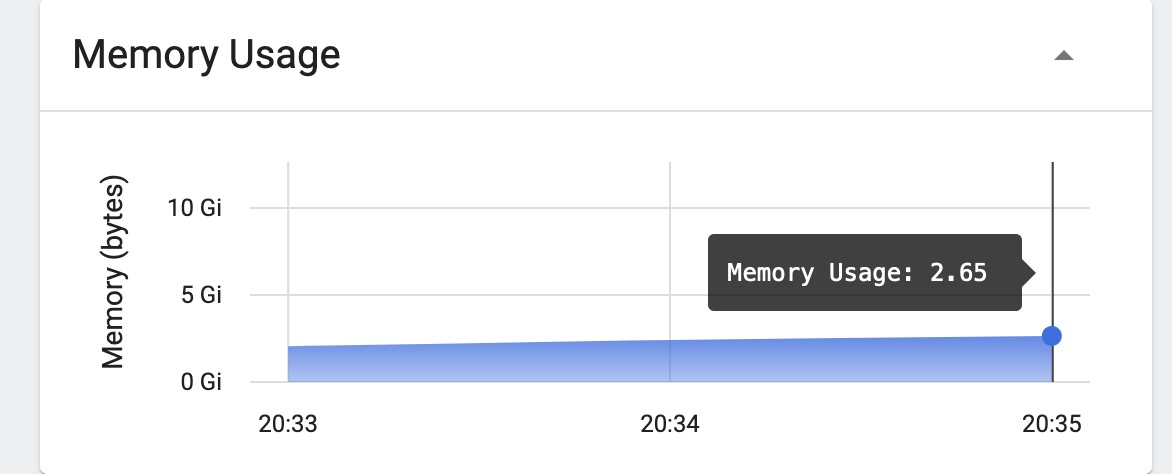
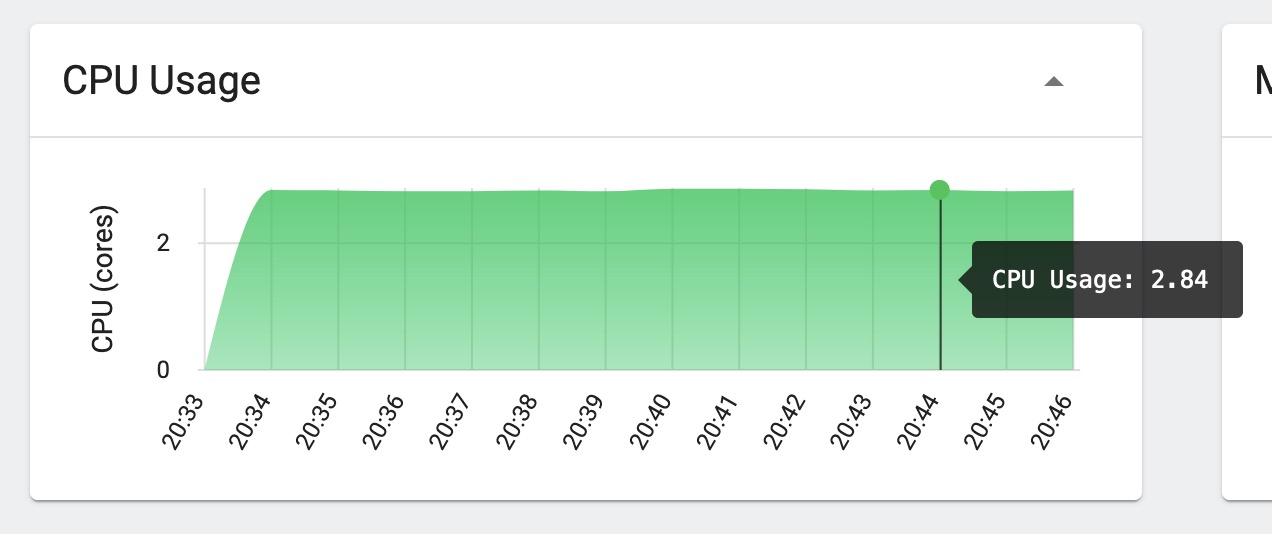
消费服务资源使用情况:
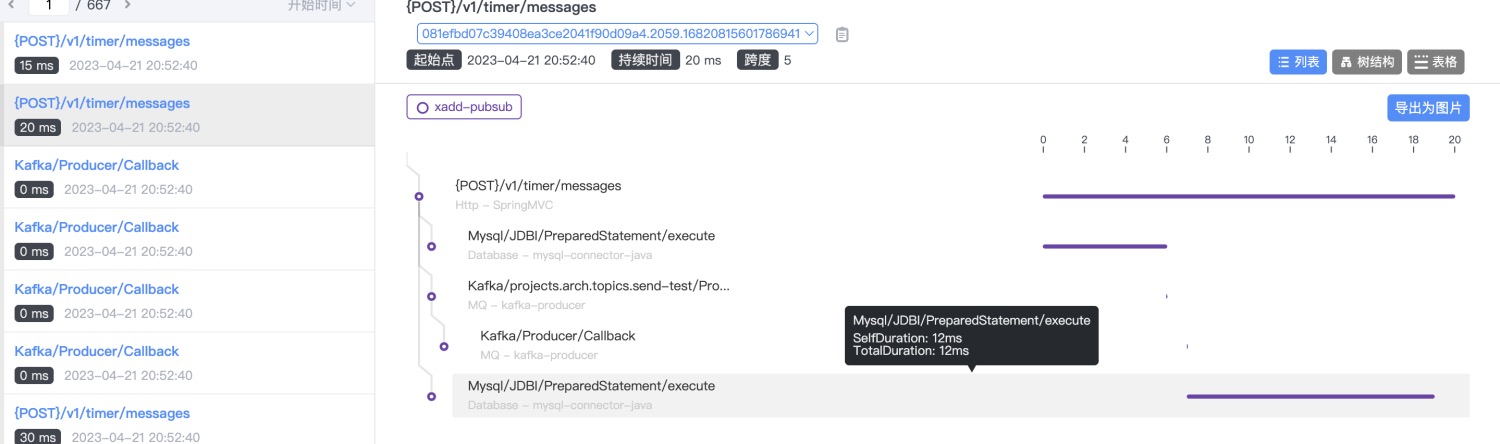
定时消息回调接口:
消费者TPS:
可以看到增加消费者后,消费能力明显提升,但是个服务资源使用率都未达到上限。
继续增加Consumer数量,TPS并没有提升。
增加Topic Queue数量
Queue总数:96
(这里测试消费能力,可以只修改读队列数)
| 消费服务实例数 | 单个服务消费者数量 | 消费者总数 | 消费TPS |
|---|---|---|---|
| 1 | 20 | 3000左右 | |
| 1 | 40 | 40 | 3000左右 |
| 2 | 20 | 40 | 5000左右 |
| 2 | 40 | 80 | 5000左右 |
以上压测过程中,pubsub服务和消费者服务的资源使用率都只维持在中等水平,单个消费者实例上消费者数量达到40时,出现个别报错:

第一次出现这个异常,刚开始没仔细看异常信息,以为是pubsub回调接口处理不过来了,没有在意,造成了一个排查疏漏,走了一些弯路。
Queue总数:192
| 消费服务实例数 | 单个服务消费者数量 | 消费者总数 | 消费TPS |
|---|---|---|---|
| 1 | 20 | 20 | 3000左右 |
| 1 | 40 | 40 | 3000左右 |
| 2 | 20 | 40 | 5000左右 |
| 4 | 20 | 80 | 8500左右 |
| 5 | 20 | 100 | 9500左右 |
| 6 | 20 | 120 | 9500左右 |
Queue总数:900
| 消费服务实例数 | 单个服务消费者数量 | 消费者总数 | 消费TPS |
|---|---|---|---|
| 4 | 30 | 120 | 9000左右 |
| 5 | 30 | 150 | 12000左右 |
由于每一轮压测成本过高,已经达到预期,没有继续进行后续压测。
消费者在30*4时,再次出现大量异常:ConnectionPoolTimeoutException
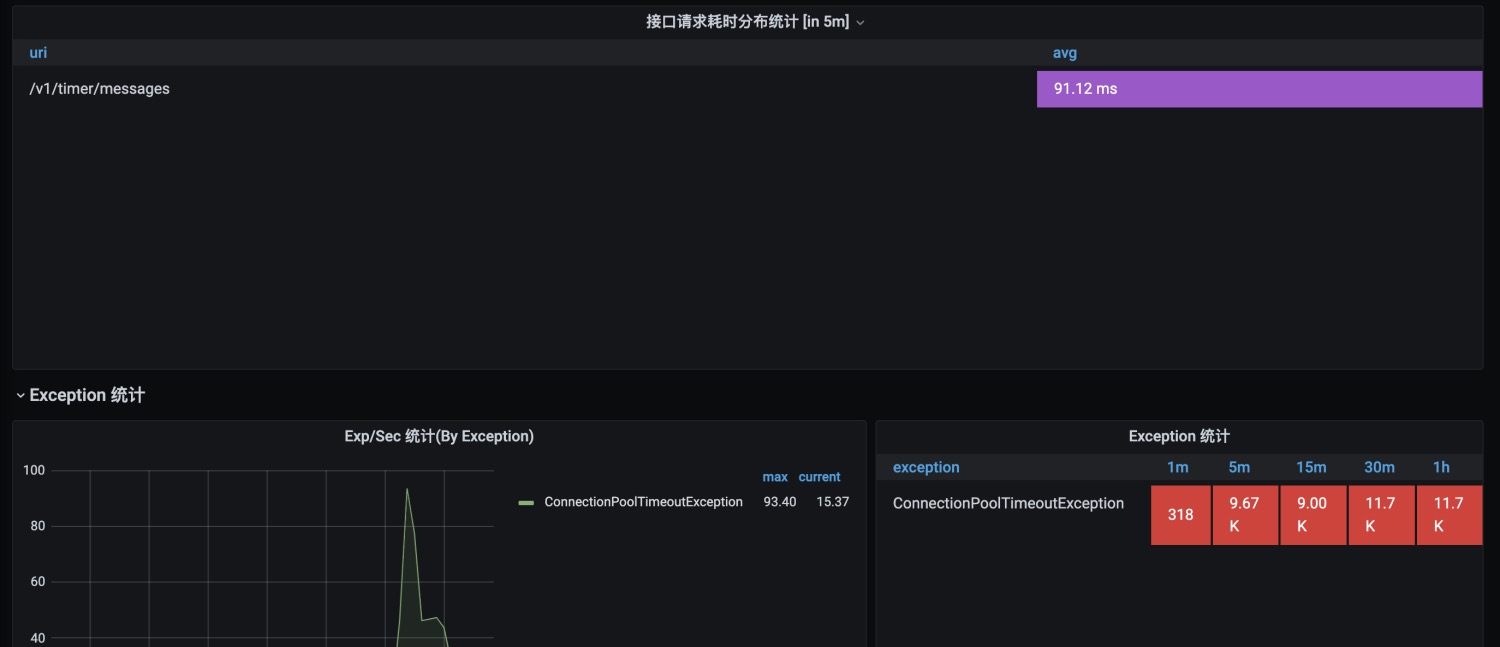
初步结论:
-
增加消费者数量和 Topic队列数,可以有效提升消费者TPS
-
目前单个消费服务配置20~30个消费者达到消费峰值,但是消费服务和pubsub服务的资源使用还远远没到瓶颈。
-
消费服务内有http客户端,怀疑是瓶颈在http连接池上,而之前出现的异常:ConnectionPoolTimeoutException,正式由于http客户端使用了连接池,从连接池内获取http连接超时导致的。
调整消费程序http最大连接池数
消费程序中的http客户端使用的是apache提供的CloseableHttpClient,有两个线程池核心参数:
- maxTotal:连接池最大连接数
- defaultMaxPerRoute:每路由最大连接数
maxTotal默认是200,defaultMaxPerRoute默认是50,而消费程序中只会调用一个接口,所以实际只有50个连接是可用的,将defaultMaxPerRoute修改为200。

消费者TPS有提升,不再有报错信息,消费者服务CPU消耗有提升。
Consumer参数微调
对Consumer进行了几个参数的调试,包括:consumeThreadMax、consumeThreadMin、consumeMessageBatchMaxSize、pullBatchSize,其中consumeThreadMax、consumeThreadMin两个参数修改后对消费能力有较明显提升,其余两个对于顺序消费场景无明显提升。
consumeThreadMax、consumeThreadMin默认为20,修改为40:

CPU消耗有提升,加大consumeThreadMin后,消费者TPS可以瞬间达到消费峰值
继续加大consumeThreadMin后,消费TPS出现下滑。
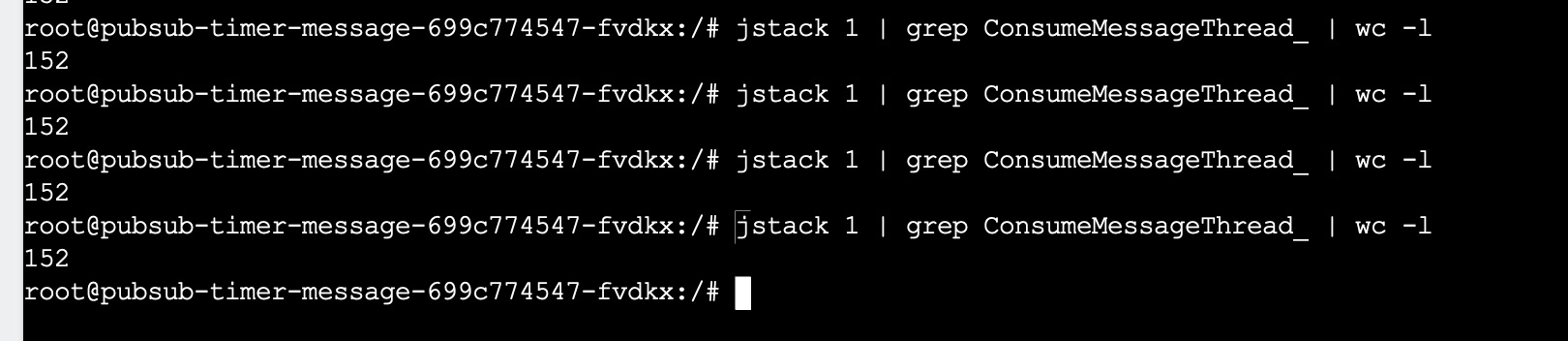
Tips:Consumer客户端会根据消费线程的压力,动态增加消费线程:

总结
优化总结
- pubsub服务资源为8c-6g,核数和Tomcat线程数比例为1:100、Tomcat线程数和数据库连接池数比例为1:1;
- 基于以上配置,pubsub单实例定时消息接口QPS理想值为4500左右、回调接口QPS高于此;
- 目前Consumer最佳配置为单实例30个消费者,每个消费者配置consumeThreadMin=40,按理说可以通过增加资源,来增加单实例上的消费者数量,减少实例数,但是通过测试发现不可行,由于时间原因没有继续探索。
- 增加Topic 读队列数和消费者数量可以提升消费能力,本次测试过程中,消费者和队列数比例达到1:2时,获得最大消费TPS;
- pubsub程序初始时没设置xmn,导致young GC比较频繁,后续根据观察各区域内存的变化情况,将xmn设置为总堆大小的3/4。
经验总结
- 压测时间需要尽量长一点,需要等编译优化完成后,程序的性能才能达到一个稳定值,尤其是对刚启动的项目;
- 优化过程中要注意小细节,对任何出现的异常都需要精确定位后再继续,避免大方向错误;
- 借助Trace工具、prometheus指标暴露插件能更快定位问题;
- 若性能达到瓶颈时,资源使用率没有提升,需要考虑各环节中使用到的线程池、连接池的限制;
- 注意版本不同时,一些配置的变化,如:Tomcat线程数配置,spring 2.3版本之前:server.tomcat.max-threads,spring 2.3版本之后:server.tomcat.threads.max
- 做优化前,需要有一个整体的规划,对整体的性能瓶颈点有一个预先的认知,包括服务本身、使用到的各中间件配置、客户端配置等,逐个进行排除