感谢点赞和关注 ,每天进步一点点!加油!
目录
一、字符串
1.1 字符串的定义与输入
1.2 字符串的拼接与格式化输出
1.3 字符串的下标
1.4 字符串的切片和倒序
1.5 字符串的常见操作
二、列表-List
2.1 列表的常见操作
2.2 列表合并和拼接
2.3 列表嵌套
三、元组-Tuple
四、字典-Dictionary
一、字符串
1.1 字符串的定义与输入
在python中,用引号引起来的都是字符串。还有input函数输入的, str()函数转换的等。
string1 = "hello"
string2 = 'hello'
string3 = """hello
python"""
string4 = '''hello
world'''
string5 = input("input anything: ")
string6 = str(18)
print(isinstance(string3, str)) # isinstance函数可以用来判断数据是否为某一个数据类型,返回值为True或False执行结果:

1.2 字符串的拼接与格式化输出
示例:
name = "张三丰"
age = 95
# print("name,你五年后age+5岁了")
print(name+",你五年后 " + str(age + 5) + " 岁了")
print("%s,你五年后 %d 岁了" % (name, age + 5))执行结果:

1.3 字符串的下标
字符串,列表,元组都属于==序列==(sequence),所以都会有下标。
什么是下标(index)?
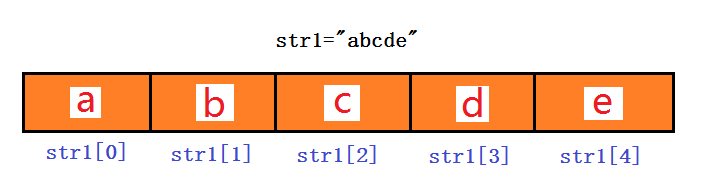
示例: 将字符串遍历打印
str1 = "kang"
# index 从 0 开始
for index, i in enumerate(str1):
print("第 %d 个字符是 %s. " % (index, i))
print("++++++++++++++++++++")
# index 从 1
for index, i in enumerate(str1):
print("第 %d 个字符是 %s. " % (index+1, i))
print("++++++++++++++++++++")
index = 0
for i in str1:
print("第 %d 个字符是 %s. " % (index+1, i))
index += 1执行结果:

1.4 字符串的切片和倒序
示例:
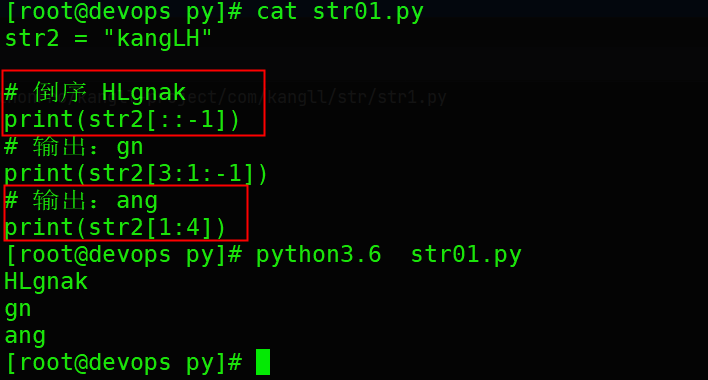
str2 = "kangLH"
# 倒序 HLgnak
print(str2[::-1])
# 输出:gn
print(str2[3:1:-1])
# 输出:ang
print(str2[1:4])执行结果:
1.5 字符串的常见操作
示例:
str1 = "hadoop kafka hive range hbase azkaban"
# 拆分
a = str1.split(" ")
num = 0
for i in a:
print(num, i, end="\t") # 拆分的字符串打印
for index in i:
print(index, end=", ") # 拆分字符串的字符打印
num += 1
print()
print(len(str1)) # 调用len()函数来算长度 (常用)
print(str1.__len__()) # 使用字符串的__len__()方法来算字符串的长度
print(str1.capitalize()) # 整个字符串的首字母大写
print(str1.title()) # 每个单词的首字母大写
print(str1.upper()) # 全大写
print(str1.lower()) # 全小写
print("HAHAhehe".swapcase()) # 字符串里大小写互换
print(str1.center(50,"*")) # 一共50个字符,字符串放中间,不够的两边补*
print(str1.ljust(50,"*")) # 一共50个字符,字符串放左边,不够的右边补*
print(str1.rjust(50,"*")) # 一共50个字符,字符串放右边,不够的左边补*
print(" haha\n".strip()) # 删除字符串左边和右边的空格或换行 (常用,处理文件的换行符很有用)
print(" haha\n".lstrip()) # 删除字符串左边的空格或换行
print(" haha\n".rstrip()) # 删除字符串右边的空格或换行
print(str1.endswith("you")) # 判断字符串是否以you结尾 类似于正则里的$ (常用)
print(str1.startswith("hello")) # 判断字符串是否以hello开始 类似于正则里的^ (常用)
print(str1.count("e")) # 统计字符串里e出现了多少次 (常用)
print(str1.find("hive")) # 找出nice在字符串的第1个下标,找不到会返回-1
print(str1.rfind("e")) # 找出最后一个e字符在字符串的下标,找不到会返回-1
print(str1.index("hive")) # 与find类似,区别是找不到会有异常(报错) (常用)
print(str1.rindex("e")) # 与rfind类似,区别是找不到会有异常(报错)
print(str1.isalnum()) # 判断是否为数字字母混合(可以有大写字母,小写字母,数字任意混合)
print(str1.isalpha()) # 判断是否全为字母(分为纯大写,纯小写,大小写混合三种情况)
print(str1.isdigit()) # 判断是否为纯数字
print(str1.islower()) # 测试结果为:只要不包含大写字母就返回True
print(str1.isupper()) # 测试结果为:只要不包含小写字母就返回True
print(str1.isspace()) # 判断是否为全空格
print(str1.upper().isupper()) # 先把str1字符串全转为大写,再判断是否为全大写字母,结果为True当然了字符串的方法很多,我们可以使用PyCharm 联想直接 寻找。

二、列表-List
序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。Python有6个序列的内置类型,但最常见的是列表和元组。
序列都可以进行的操作包括索引,切片,加,乘,检查成员。
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型。
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5 ]
list3 = ["a", "b", "c", "d"]2.1 列表的常见操作
列表的增删改查操作,列表是可变数据类型,可以进行增,删,改操作。
示例:
str_list = ["kafka", "hadoop", "hadoop", "hive", "range", "flink", "hbase"]
print(str_list)
print("列表长度: ", len(str_list))
# 修改 原来的元素
str_list.append("azkaban")
print("追加: " + str(str_list))
# 移除
str_list.remove("hive")
print("移除: " + str(str_list))
# c插入
str_list.insert(0,"yarn")
print("插入: " + str( str_list))
# 统计次数
cnt = str_list.count("hadoop")
print("hadoop出现的次数: ", cnt)
# 统计次数
a = str_list.index("hadoop")
print("hadoop第一次出现的索引位: ", a)执行结果:

2.2 列表合并和拼接
我们可以将两个列表拼接为一个。
示例:
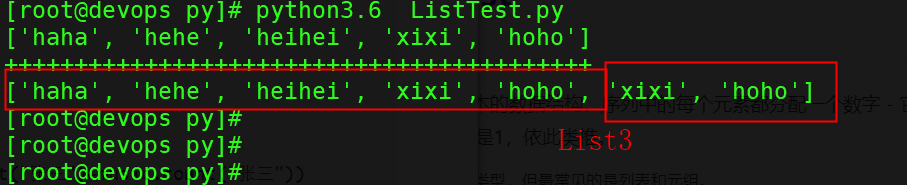
list1 = ["haha", "hehe", "heihei"]
list2 = ["xixi", "hoho"]
list1.extend(list2) # list1 += list2也可以,类似字符串拼接
print(list1)
print("++++++++++++++++++++++++++++++++++++++++++")
list3 = list1 + list2 # 上面list1 再拼接 list2
print(list3)执行结果:
2.3 列表嵌套
示例:
# 列表里可以嵌套列表,也可以嵌套其它数据类型
emp = [["张三丰", 18000], ["张无忌", 16000], ["南乔峰", 20000], ["慕容复", 15000]]
# 循环打印出人名与其对应的工资
for i in emp:
print("%s 的工资是%d." % (i[0], i[1])) 执行结果:

三、元组-Tuple
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。元组是只读的,不代表元组里任何数据不可变。如果元组里有列表,那么列表里是可变的。
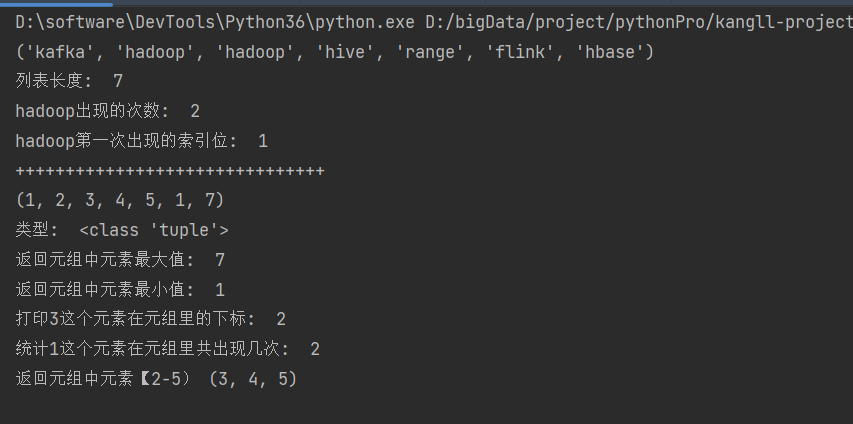
str_tup = ("kafka", "hadoop", "hadoop", "hive", "range", "flink", "hbase")
print(str_tup)
print("列表长度: ", len(str_tup))
# 统计次数
cnt = str_tup.count("hadoop")
print("hadoop出现的次数: ", cnt)
# 统计次数
a = str_tup.index("hadoop")
print("hadoop第一次出现的索引位: ", a)
print("+++++++++++++++++++++++++++++++")
tuple1 = (1, 2, 3, 4, 5, 1, 7)
print(tuple1)
print("类型: ", type(tuple1))
print("返回元组中元素最大值: ", max(tuple1))
print("返回元组中元素最小值: ", min(tuple1))
print("打印3这个元素在元组里的下标: ", tuple1.index(3))
print("统计1这个元素在元组里共出现几次: ", tuple1.count(1))
print("返回元组中元素【2-5)", tuple1[2:5])执行结果:
四、字典-Dictionary
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key:value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }注意:dict 作为 Python 的关键字和内置函数,变量名不建议命名为 dict。
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
示例:
dict1 = {
'stu01': "张三丰",
'stu02': "张无忌",
'stu03': "夫子",
'stu04': "昊天",
}
print(type(dict1))
print(len(dict1))
print(dict1)
for i in dict1.items():
print(i)
for i in dict1.items():
print(i[0], i[1])
if i[1] == "张无忌":
dict1[i[0]] = "郭靖"
print("张无忌改为郭靖: ", dict1)
print("查询stu03: ", dict1.get("stu03"))
dict1["stu05"] = "谢逊"
print("新增 stu05: ", dict1)
# 删
dict1.pop("stu01")
print("删除 stu01: ", dict1)执行结果:

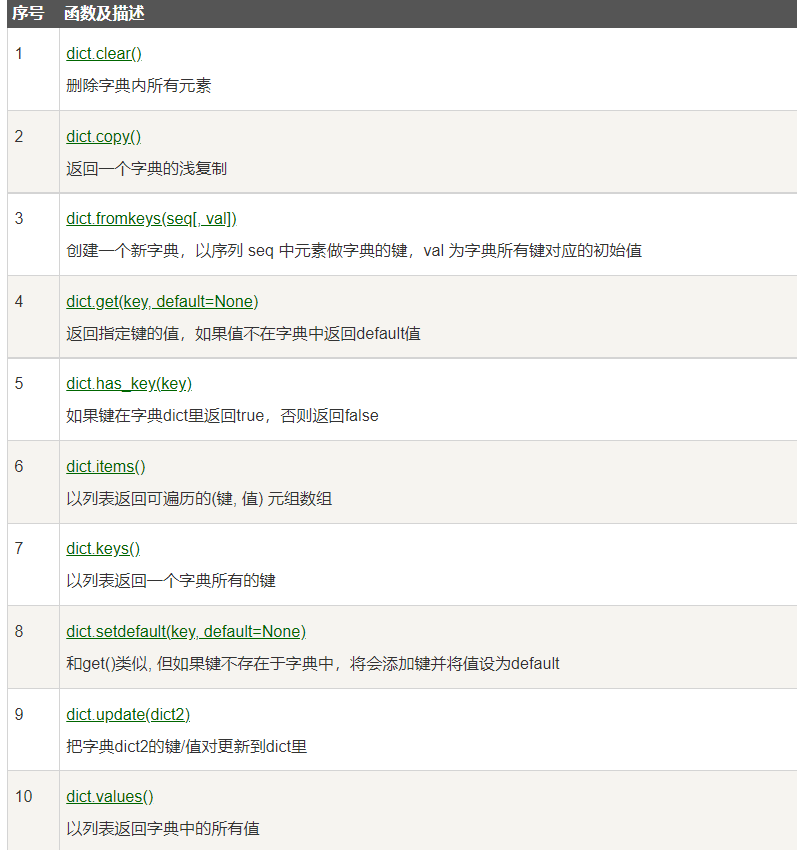
Python字典包含了以下内置方法: