Ribbon负载均衡

Ribbon
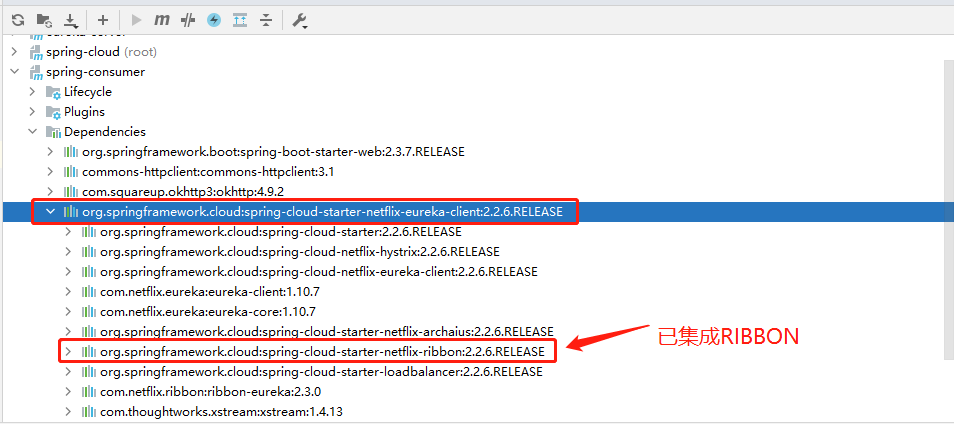
Eureka帮我们集成了负载均衡组件:Ribbon,简单修改代码即可使用。
什么是Ribbon:客户端负载均衡组件

开启负载均衡
1、Eureka中已经集成了Ribbon,所以我们无需引入新的依赖,直接修改代码。
2、spring-consumer的引导类,在RestTemplate的配置方法上添加@LoadBalanced注解
@Bean
@LoadBalanced //不添加这个注解,不能直接用服务名访问
public RestTemplate getRestTemplate(RestTemplateBuilder builder){
return builder.build();
}
3、修改调用方式,不再手动获取ip和端口,而是直接通过服务名称调用:
@RestController
public class UserController {
@Autowired
private RestTemplate restTemplate;
@RequestMapping(value = "/consumerLoadBalanced/{id}")
public String consumerLoadBalanced(@PathVariable String id){
String url = "http://spring-provider/provider/" + id;
String consumer = restTemplate.getForObject(url, String.class);
return "LoadBalanced restTemplate consumer " + consumer;
}
}
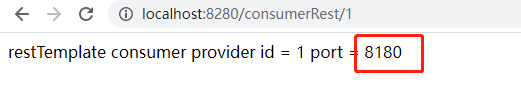
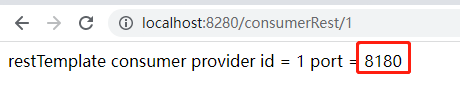
4、运行结果:
第一次调用结果
第二调用结果
Ribbon 的超时和超时重试
Ribbon 是有超时设置,以及超时之后的重试功能的。但是,在 RestTemplate 和 Ribbon 结合的方案中,Ribbon 的超时设置和重试设置的配置方式一直在变动,因此有很多『配置无效』的现象,十分诡异。
考虑到我们在后续的项目中不会使用 RestTemplate 和 Ribbon 整合,而是使用 OpenFeign ,因此,这里就不展开解释了。
Ribbon 的饥饿加载
默认情况下,服务消费方调用服务提供方接口的时候,第一次请求会慢一些,甚至会超时,而之后的调用就没有问题了。
这是因为 Ribbon 进行客户端负载均衡的 Client 并不是在服务启动的时候就初始化好的,而是在调用的时候才会去创建相应的 Client,所以第一次调用的耗时不仅仅包含发送HTTP请求的时间,还包含了创建 RibbonClient 的时间,这样一来如果创建时间速度较慢,同时设置的超时时间又比较短的话,很容易就会出现上面所描述的现象。
你可以通过启用 Ribbon 的饥饿加载(即立即加载)模式,并指定在项目启动时就要加载的服务:
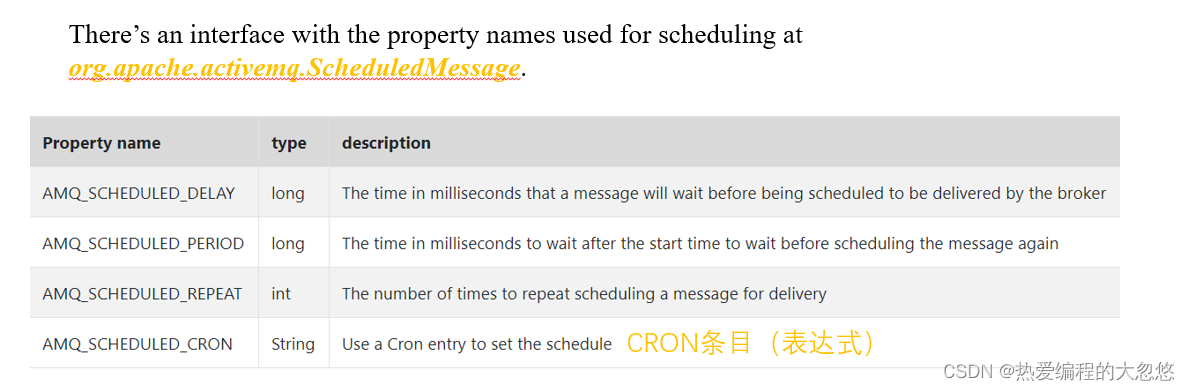
ribbon:
eager-load:
enabled: true # 开启饥饿加载
clients: spring-provider, xxx # (服务名)需要饥饿加载的服务
负载均衡策略
1.轮询策略
轮询策略:RoundRobinRule,按照一定的顺序依次调用服务实例。比如一共有 3 个服务,第一次调用服务 1,第二次调用服务 2,第三次调用服务 3,依次类推。此策略的配置设置如下:
spring-provider: # nacos中的服务id
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #设置负载均衡
格式是:{服务名称}.ribbon.NFLoadBalancerRuleClassName,值就是IRule的实现类。
2.权重策略
权重策略:WeightedResponseTimeRule,根据每个服务提供者的响应时间分配一个权重,响应时间越长,权重越小,被选中的可能性也就越低。它的实现原理是,刚开始使用轮询策略并开启一个计时器,每一段时间收集一次所有服务提供者的平均响应时间,然后再给每个服务提供者附上一个权重,权重越高被选中的概率也越大。此策略的配置设置如下:
spring-provider: # nacos中的服务id
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.WeightedResponseTimeRule
3.随机策略
随机策略:RandomRule,从服务提供者的列表中随机选择一个服务实例。此策略的配置设置如下:
spring-provider: # nacos中的服务id
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
4.最小连接数策略
最小连接数策略:BestAvailableRule,也叫最小并发数策略,它是遍历服务提供者列表,选取连接数最小的⼀个服务实例。如果有相同的最小连接数,那么会调用轮询策略进行选取。此策略的配置设置如下:
spring-provider: # nacos中的服务id
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.BestAvailableRule #设置负载均衡
5.重试策略
重试策略:RetryRule,按照轮询策略来获取服务,如果获取的服务实例为 null 或已经失效,则在指定的时间之内不断地进行重试来获取服务,如果超过指定时间依然没获取到服务实例则返回 null。此策略的配置设置如下:
ribbon:
ConnectTimeout: 2000 # 请求连接的超时时间
ReadTimeout: 5000 # 请求处理的超时时间
spring-provider: # nacos 中的服务 id
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #设置负载均衡
6.可用性敏感策略
可用敏感性策略:AvailabilityFilteringRule,先过滤掉非健康的服务实例,然后再选择连接数较小的服务实例。此策略的配置设置如下:
spring-provider: # nacos中的服务id
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.AvailabilityFilteringRule
7.区域敏感策略
区域敏感策略:ZoneAvoidanceRule,根据服务所在区域(zone)的性能和服务的可用性来选择服务实例,在没有区域的环境下,该策略和轮询策略类似。此策略的配置设置如下:
spring-provider: # nacos中的服务id
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.ZoneAvoidanceRule
Ribbon与Nginx的区别
Nginx是基于服务端的负载均衡,客户端所有请求统一交给 nginx,由 nginx 进行实现负载均衡请求转发,Nginx保持服务清单的同时,也负责负载均衡算法
Ribbon是从 eureka 注册中心服务器端上获取服务注册信息列表,缓存到本地,然后在本地实现轮询负载均衡策略,Ribbon不负责出来服务清单,

应用场景的区别:
1、Nginx适合于服务器端实现负载均衡比如 Tomcat ,Ribbon适合与在微服务中RPC远程调用实现本地服务负载均衡,比如 Dubbo、SpringCloud 中都是采用本地负载均衡。
spring cloud的Netflix中提供了两个组件实现软负载均衡调用:ribbon和feign。
2、Ribbon
是一个基于 HTTP 和 TCP 客户端的负载均衡器,可以在客户端配置 ribbonServerList(服务端列表),然后轮询请求以实现均衡负载。
3、springcloud的ribbon和nginx有什么区别?哪个性能好?
nginx性能好,但ribbon可以剔除不健康节点,nginx剔除节点比较复杂。ribbon还可以配合熔断器一起工作;
ribbon是客户端负载均衡,nginx是服务端负载均衡。客户端负载均衡,所有客户端节点都维护自己要访问的服务端清单。服务端负载均衡的软件模块会维护一个可用的服务清单;
ribbon 是一个客户端负载均衡器,可以简单的理解成类似于 nginx的负载均衡模块的功能。
Hystrix容错组件
Hystrix简介
Hystrix,英文意思是豪猪,全身是刺,看起来就不好惹,是一种保护机制。它是容错组件,Hystrix也是Netflix公司的一款组件。

那么Hystix的作用是什么呢?具体要保护什么呢?
Hystix是Netflix开源的一个延迟和容错库,用于隔离访问远程服务、第三方库,防止出现级联失败。
雪崩问题
微服务中,服务间调用关系错综复杂,一个请求,可能需要调用多个微服务接口才能实现,会形成非常复杂的调用链路:

如图,一次业务请求,需要调用A、P、H、I四个服务,这四个服务又可能调用其它服务。
如果此时,某个服务出现异常:
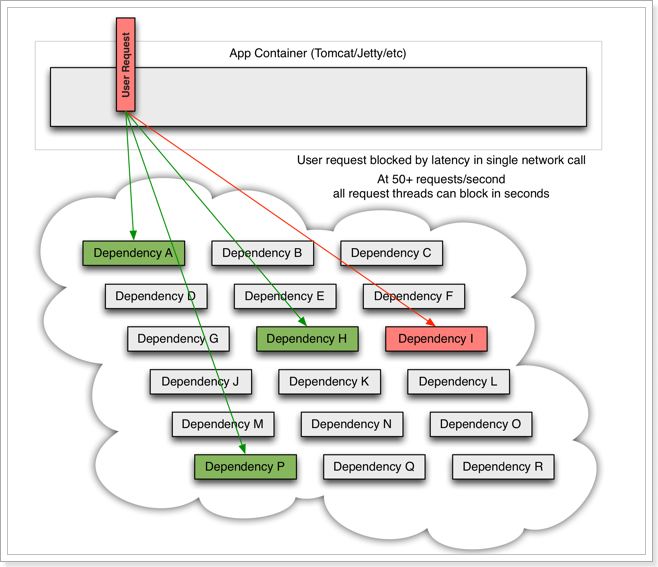
例如微服务 I 发生异常,请求阻塞,用户不会得到响应,则tomcat的这个线程不会释放,于是越来越多的用户请求到来,越来越多的线程会阻塞:
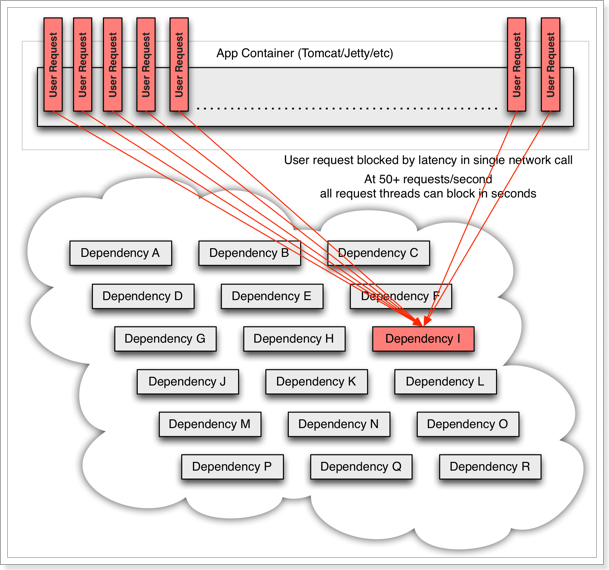
服务器支持的线程和并发数有限,请求一直阻塞,会导致服务器资源耗尽,从而导致所有其它服务都不可用,形成雪崩效应。
这就好比,一个汽车生产线,生产不同的汽车,需要使用不同的零件,如果某个零件因为种种原因无法使用,那么就会造成整台车无法装配,陷入等待零件的状态,直到零件到位,才能继续组装。 此时如果有很多个车型都需要这个零件,那么整个工厂都将陷入等待的状态,导致所有生产都陷入瘫痪。一个零件的波及范围不断扩大。
Hystix解决雪崩问题的手段有两个:
- 线程隔离(线程池隔离、信号量隔离)
- 服务熔断
服务降级
引入依赖
首先在spring-consumer的pom.xml中引入Hystrix依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
在服务调用方入口启动类上面加上 @EnableHystrix或 @EnableCircuitBreaker 注解,表示激活熔断器的默认配置,@EnableHystrix注解是 @EnableCircuitBreaker 的语义化,它们的关系类似于 @Service和 @Component 。
开启Hystrix熔断
@SpringBootApplication
@EnableDiscoveryClient
@EnableCircuitBreaker
public class SpringConsumerApplication {
@Bean
@LoadBalanced
public RestTemplate getRestTemplate(RestTemplateBuilder builder){
return builder.build();
}
public static void main(String[] args) {
SpringApplication.run(SpringConsumerApplication.class, args);
}
}
可以看到,我们类上的注解越来越多,在微服务中,经常会引入上面的三个注解,于是Spring就提供了一个组合注解:@SpringCloudApplication
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M7q8GbIJ-1684410183871)(D:\BaiduNetdiskDownload\阶段四\SpringCloud\assets\1535341390087.png)]
因此,我们可以使用这个组合注解来代替之前的3个注解。
@SpringCloudApplication
public class SpringConsumerApplication {
@Bean
@LoadBalanced
public RestTemplate getRestTemplate(RestTemplateBuilder builder){
return builder.build();
}
public static void main(String[] args) {
SpringApplication.run(SpringConsumerApplication.class, args);
}
}
编写降级逻辑
我们改造spring-consumer,当目标服务的调用出现故障,我们希望快速失败,给用户一个友好提示。因此需要提前编写好失败时的降级处理逻辑,要使用HystixCommond来完成:
@RestController
public class ConsumerController {
@Autowired
private RestTemplate restTemplate;
@RequestMapping(value = "/consumerLoadBalanced/{id}")
@HystrixCommand(fallbackMethod = "consumerLoadBalancedFallbackMethod")
public String consumerLoadBalanced(@PathVariable String id){
String url = "http://spring-provider/provider/" + id;
String consumer = restTemplate.getForObject(url, String.class);
return "LoadBalanced restTemplate consumer " + consumer;
}
public String consumerLoadBalancedFallbackMethod(String id){
return "系统繁忙,请稍后再试!";
}
}
要注意,降级逻辑方法必须跟正常逻辑方法保证:相同的参数列表和返回值声明。失败逻辑中返回User对象没有太大意义,一般会返回友好提示。所以我们把queryById的方法改造为返回String,反正也是Json数据。这样失败逻辑中返回一个错误说明,会比较方便。
说明:
- @HystrixCommand(fallbackMethod = “queryByIdFallBack”):用来声明一个降级逻辑的方法,当然这个注解里面还有其它的属性,默认情况下,读取hystrix的配置,对满足降级条件的进行统一降级,当然我们可以单独配置某个降级的业务方法,如
@HystrixCommand(
fallbackMethod = "fallBackMethod",
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "1000"),
@HystrixProperty(name = "...", value = "..."),
@HystrixProperty(name = "...", value = "...")
}
)
默认FallBack
我们刚才把fallback写在了某个业务方法上,如果有很多这样的业务方法访问不了服务器都需要降级时,那岂不是要写很多,所以我们可以把Fallback配置加在类上,实现默认fallback:
@RestController
@DefaultProperties(defaultFallback = "fallBackMethod") // 指定一个类的全局降级方法
public class ConsumerController {
@Autowired
private RestTemplate restTemplate;
@GetMapping
@HystrixCommand // 标记该方法需要降级
public String consumerLoadBalanced(@PathVariable String id){
String url = "http://spring-provider/provider/" + id;
String consumer = restTemplate.getForObject(url, String.class);
return "LoadBalanced restTemplate consumer " + consumer;
}
/**
* 降级方法
* 返回值要和被降级的方法的返回值一致
* 降级方法不需要参数
* @return
*/
public String fallbackMethod(){
return "全局默认,系统繁忙,请稍后再试!";
}
}
说明:
- @DefaultProperties(defaultFallback = “defaultFallBack”):在类上指明统一的失败降级方法
- @HystrixCommand:在方法上直接使用该注解,使用默认的降级方法。
- defaultFallback:默认降级方法,不用任何参数,以匹配更多方法,但是返回值一定一致
Hystrix超时配置
Hystrix 的全局配置也称为默认配置,它们在配置文件中通过 hystrix.command.default.* 来进行配置(再次强调,Hystrix 是用于服务的调用方,所以这里的配置自然也是配置在服务的调用方这边)
在之前的案例中,请求在超过1秒后都会返回错误信息,这是因为Hystix的默认超时时长为1秒,我们可以通过配置修改这个值:
我们可以通过hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds来设置Hystrix超时时间。该配置没有提示。
hystrix:
command:
default: #也可以把default 改成某个服务名,针对某个服务。
execution:
isolation:
thread: #其实是对每一次http请求,就开启一个线程,hystrix内部有一个线程池。
timeoutInMilliseconds: 6000 # 设置hystrix的超时时间为6000ms
strategy: THREAD ##默认是采用线程池隔离技术 可以省略
注意:配合测试,要改造服务提供者,打开浏览器 F12 看看时间
无论我们的使用的是 RestTemplate 还是 OpenFeign,它们都会是使用到 Ribbon 的负载均衡(和超时重试)能力。而 Ribbon 也会监管请求超时问题。所以,理论上,Hystrix 的超时时长的判断标准应该大于 Ribbon 的超时重试的总耗时,否则,会出现 Ribbon 还在『努力』,但是 Hystrix 决定『放弃』的情况。当然,这样也不是不行,只是有些不科学。
要注意:也就是说,hystrix触发熔断与ribbon的重试在机制上没关系,ribbon该重试还是会重试,如果有重试,还会使得被调用系统做无用且重复的业务
除了合理的参数值设置之外,你还可以直接关闭掉 Hystrix 的超时判断,完全由 Ribbon 来评判、上报(给 Hystrix)超时与否。
改造服务提供者
改造服务提供者的UserController接口,随机休眠一段时间
@RequestMapping(value = "/provider/{id}")
public String provider(@PathVariable String id){
try {
Thread.sleep(8000);
} catch (InterruptedException e) {
return "exception:" + e.getMessage();
}
return "provider id = " + id + "port = " + port;
}
当6s 不能正常请求服务提供者,其实先触发熔断,然后再降级
服务熔断
熔断原理
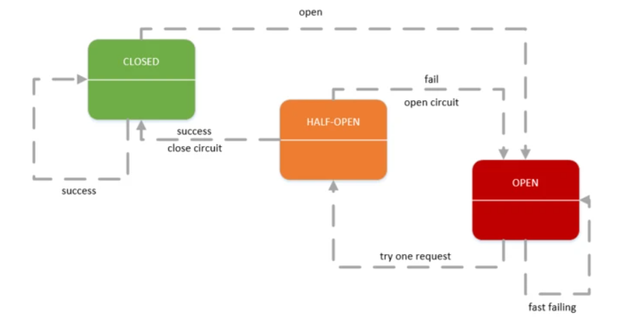
熔断器,也叫断路器,其英文单词为:Circuit Breaker

熔断器3个状态:
- Closed:关闭状态,所有请求都正常访问。
- Open:打开状态,所有请求都会被降级。Hystrix会对请求情况计数,当一定时间内失败请求百分比达到阈值,则触发熔断,断路器会完全打开。默认失败比例的阈值是50%,请求次数最少不低于20次。默认是 五秒之内请求20次 如果有10次失败(50%),则请求不能正常访问。
- Half Open:半开状态,open状态不是永久的,打开后会进入休眠时间(默认是5S)。随后断路器会自动进入半开状态。此时会释放部分请求通过,若这些请求都是健康的,则会完全关闭断路器,否则继续保持打开,再次进行休眠计时
动手实践
为了能够精确控制请求的成功或失败,我们在provider业务中加入一段逻辑:
@RequestMapping(value = "/provider/{id}")
public String provider(@PathVariable String id){
if(id.equals("1")){
throw new RuntimeException("异常");
}
return "provider id = " + id + "port = " + port;
}
消费方的业务代码
@RequestMapping(value = "/consumerLoadBalanced/{id}")
@HystrixCommand
public String consumerLoadBalanced(@PathVariable String id){
String url = "http://spring-provider/provider/" + id;
String consumer = restTemplate.getForObject(url, String.class);
return "LoadBalanced restTemplate consumer " + consumer;
}
public String fallbackMethod(){
return "全局默认,系统繁忙,请稍后再试!";
}
我们准备两个请求窗口:
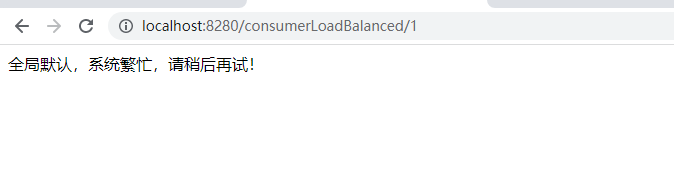
- 一个请求:http://localhost:8280/consumerLoadBalanced/1,注定失败
- 一个请求:http://localhost:8280/consumerLoadBalanced/2,肯定成功
当我们疯狂访问id为1的请求时(超过20次),就会触发熔断。断路器会断开,一切请求都会被降级处理。
此时你访问id为2的请求,会发现返回的也是失败,过一段时间又恢复正常。
熔断策略配置
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 6000
circuitBreaker:
requestVolumeThreshold: 20
sleepWindowInMilliseconds: 10000
errorThresholdPercentage: 50
#forceOpen: true #是否强制开启熔断(跳闸),默认false,如果为true,则所有请求都将被拒绝,直接执行fallback降级方法
解读:
- requestVolumeThreshold:触发熔断的最小请求次数,默认20,通过一个窗口10s内请求数大于20个就启动熔断器
- errorThresholdPercentage:触发熔断的失败请求最小占比,默认50%
- sleepWindowInMilliseconds:休眠时长,默认是5000毫秒
- forceOpen 是否强制跳闸
解决灾难性雪崩
线程池隔离
在前面讲过,当大多数人在使用Tomcat时,多个HTTP请求不同的接口时,tomcat服务器会创建一个线程池,来处理这些请求,它们会共享这个线程池,假设其中一个HTTP请求某个接口访问的数据库响应非常慢,这将造成服务响应时间延迟增加,大多数线程阻塞等待数据响应返回,导致整个Tomcat线程池都的线程都被用完,甚至拖垮整个Tomcat。因此,如果我们能把不同接口请求隔离到不同的线程池,则请求某个接口的线程池满了也不会对其他服务造成灾难性故障。这就需要线程隔离或者信号量隔离来实现了
默认情况下 Hystrix 是使用线程池作为隔离策略,请求的每个接口都准备了独立的线程池,请求相同接口的线程池相同(从线程池中取出的一个线程里执行该请求),请求不同的接口会创建不同的线程池,如:用户请求/provider接口,那么hystrix就为这个接口创建一个线程池,池里可以规定多少个线程和一个缓存队列(假如说:池里有10个线程,队列大小100,那么这个并发量最大就是110,如果第111个请求也请求该接口时,如果没有线程被回收,队列也放不下,那么直接会降级)
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 6000
strategy: THREAD ##默认值 采用线程池隔离技术
-------------------------------------------------------
hystrix:
threadpool:
default:
coreSize: 200
maxQueueSize: 1000
queueSizeRejectionThreshold: 800
#第1201个请求不会立马降级,具体的要看线程请求的超时时间 配置......thread.timeoutInMilliseconds: 6000
| 参数 | 说明 |
|---|---|
| coreSize | 并发执行的最大线程数,默认 10 |
| maxQueueSize | BlockingQueue 的最大队列数,默认值 -1 |
| queueSizeRejectionThreshold | 这个属性是控制队列最大阈值的,即使 maxQueueSize 没有达到,达到 queueSizeRejectionThreshold 该值后,请求也会被拒绝,默认值 5 |
需要说明的是必须配置maxQueueSize和queueSizeRejectionThreshold,不能只配一个
信号量隔离
底层使用原子计算器技术,针对每个服务(接口)都设置自己独立的阈值,比如设置每个服务接口最多同时只能访问50次,超出后则进行服务降级处理,当客户端需向依赖服务发起请求时, 计数器+1,请求返回成功后 计数器-1。
信号量隔离主要是通过控制并发请求量,防止请求线程大面积阻塞,从而达到限流和防止雪崩的目的
配置参数:
hystrix:
command:
default: #也可以把default 改成某个服务名,针对某个服务。
execution:
isolation:
thread:
timeoutInMilliseconds: 6000
strategy: SEMAPHORE #线程池隔离技术 还有一种就是信号量隔离 strategy: SEMAPHORE
semaphore:
maxConcurrentRequests: 100 #默认信号量最大值是100
使用场景
线程池隔离:请求并发量大,并且耗时长(请求耗时长一般是计算量大,读数据库),采用线程池隔离,这样的话,可以保证大量的容器线程可用,不会由于服务原因,一直处于阻塞状态或等待状态,快速失败返回。
信号量隔离:请求并发量大,并且耗时短(请求耗时短可能是计算量小,读缓存),采用信号量隔离,因为这类服务的返回通常会非常快,不会占用容器线程太长时间,而且也减少了线程切换的一些开销,提高了缓存服务的效率。
Open Feign
在前面的学习中,我们使用了Ribbon的负载均衡功能,简化了远程调用时的代码:
String user = this.restTemplate.getForObject("http://spring-provider/provider/" + id, String.class);
如果就学到这里,可能以后需要编写类似的大量重复代码,格式基本相同,无非参数不一样。有没有更优雅的方式,来对这些代码再次优化呢?这就是我们接下来要学的Feign的功能了。
简介
Netflix 提供了 Feign,并在 2016.7 月的最后一个版本 8.18.0 之后,将其捐赠给 spring cloud 社区,并更名为 OpenFeign 。OpenFeign 的第一个版本就是 9.0.0 ,OpenFeign 会完全代理 HTTP 的请求,在使用过程中我们只需要依赖注入 Bean,然后调用对应的方法传递参数即可。这对程序员而言屏蔽了 HTTP 的请求响应过程,让代码更趋近于『调用』的形式。
Feign是一个远程调用组件,集成了ribbon和hystrix。把Rest的请求进行隐藏,伪装成类似SpringMVC的Controller一样。不用再自己拼接url,拼接参数等等操作,一切都交给Feign去做。

入门
导入依赖
1、引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
2、启动类增加@EnableFeignClients
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients // 开启feign客户端,无需配置熔断器和负载均衡注解
public class SpringConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(SpringConsumerApplication.class, args);
}
}
启动类增加了新的注解: @EnableFeignClients,如果我们要使用 Feign(声明式 HTTP 客户端),必须要在启动类加入这个注解开启 Feign 。
这样,我们的 Feign 就已经集成完成了,那么如何通过 Feign 去调用之前我们写的 HTTP 接口呢?
首先创建一个接口 ApiService(名字任意),并且通过注解配置要调用的服务地址。
Feign的客户端
@FeignClient(value = "spring-provider") // 标注该类是一个feign接口
public interface ProviderOpenfeign {
@GetMapping("/sms/provider/{id}")
String provider(@PathVariable("id") String id);
}
- 这是一个接口,Feign会通过动态代理,帮我们生成实现类。这点跟mybatis的mapper很像;
@FeignClient,声明这是一个Feign客户端,类似@Mapper注解。同时通过value属性指定服务名称;- 接口中定义的方法,完全采用SpringMVC的注解,Feign会根据注解帮我们生成URL,并访问获取结果;
- 一个服务只能被一个类绑定,不能让多个类绑定同一个远程服务,否则,会在启动项目是出现『已绑定』异常。
说明:
1、方法的返回值、参数以及requestmapping路径要和提供方的一模一样和消费方无关,消费方只需要调用该方法得到结果;
2、如果服务方controller类有@RequestMapping 定义命名空间,provider,在这里我们建议在方法上面拼接,不能在ProviderOpenfeign接口上去定义@requestMapping("/provider/");
3、@PathVariable("id") 这个括号里面的id不能省略,同理@Requestparam("id")里面的id也不能省略。
改造原来的调用逻辑,调用ProviderOpenfeign接口:
@Controller
public class ConsumerController {
@Autowired
private ProviderOpenfeign providerOpenfeign;
@RequestMapping("/consumerOpenfeign/{id}")
public String consumerOpenfeign(@RequestParam("id") String id){
String consumer = providerOpenfeign.provider(id);
return "consumerOpenfeign " + consumer;
}
}
Hystrix支持
OPen Feign默认也有对Hystrix的集成:

默认是关闭的,我们需要通过下面的参数来开启:
feign:
hystrix:
enabled: true # 开启Feign的熔断功能,默认超时1s
只需要开启hystrix的熔断功能即可,默认时间是1s中,如果要修改熔断的时间,要做如下的配置:
feign:
hystrix:
enabled: true # 开启Feign的熔断功能
client:
config:
default:
connectTimeout: 4000 #设置feign超时连接时长
readTimeout: 4000 #设置feign请求的超时时长 4s之后 提供方没有响应 直接降级
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 6000
strategy: THREAD
timeout:
enabled: true
说明:
connectTimeout是feign连接某个服务的超时时间,
readTimeout是feign请求某个接口的超时时长,
timeoutInMilliseconds是hystrix熔断的时间,
Hystrix的超时时间是站在命令执行时间来看的和Feign设置的超时时间在设置上并没有关联关系。Hystrix不仅仅可以封装Http调用,还可以封装任意的代码执行片段。Hystrix是从命令对象的角度去定义,某个命令执行的超时时间,超过此此时间,命令将会直接熔断,假设hystrix 的默认超时时间设置了3000(3秒),而feign 设置的是4秒,那么Hystrix会在3秒到来时直接熔断返回,不会等到feign的4秒执行结束,如果hystrix的超时时间设置为6s,而feign 设置的是4秒,那么最终要以feign的时间4s为准,你可以理解为以时间短的为准,这两段都要配置,不能不配hystrix的配置,否则feign配置的readTimeout不生效。
Feign中的Fallback降级配置不像hystrix中那样了。
1)首先,我们要定义一个类ProviderOpenfeignFallback,实现刚才编写的ProviderOpenfeign,作为fallback的处理类
@Component
public class ProviderOpenfeignFallback implements ProviderOpenfeign {
@Override
public User provider(String id) {
return "服务器繁忙,请稍后再试!";
}
}
2)然后在ProviderOpenfeign中,指定刚才编写的实现类
@FeignClient(value = "spring-provider",fallback = ProviderOpenfeignFallback.class) // 标注该类是一个feign接口
public interface ProviderOpenfeign {
@GetMapping("/provider/{id}")
String provider(@PathVariable("id") String id);
}
3)修改消费方controller的consumerOpenfeign方法,注释掉**@HystrixCommand注解和@DefaultProperties(defaultFallback=“fallback”)**进行测试。
@RestController
//@DefaultProperties(defaultFallback = "fallbackMethod")
public class ConsumerController {
@Autowired
private ProviderOpenfeign providerOpenfeign;
@RequestMapping(value = "/consumerOpenfeign/{id}")
//@HystrixCommand
public String consumerOpenfeign(@PathVariable String id){
String consumer = providerOpenfeign.provider(id);
return "consumerOpenfeign consumer " + consumer;
}
}
4)重启测试:

超时和超时重试
OpenFeign 本身也具备重试能力,在早期的 Spring Cloud 中,OpenFeign 使用的是 feign.Retryer.Default#Default() ,重试 5 次。但 OpenFeign 集成了Ribbon依赖和自动配置(默认也是轮询),Ribbon 也有重试的能力,此时,就可能会导致行为的混乱。(总重试次数 = OpenFeign 重试次数 x Ribbon 的重试次数,这是一个笛卡尔积。)
后来 Spring Cloud 意识到了此问题,因此做了改进(issues 467),将 OpenFeign 的重试改为 feign.Retryer#NEVER_RETRY ,即默认关闭。 Ribbon的重试机制默认配置为0,也就是默认是去除重试机制的,如果两者都开启重试,先执行ribbon重试,抛出异常之后再执行feign的重试。
所以,OpenFeign『对外』表现出的超时和重试的行为,实际上是 Ribbon 的超时和超时重试行为。我们在项目中进行的配置,也都是配置 Ribbon 的超时和超时重试
在调用方配置如下
# 全局配置
ribbon:
# 请求连接的超时时间
connectTimeout: 1000
# 请求处理的超时时间
readTimeout: 1000 #1秒
# 最大重试次数
MaxAutoRetries: 5
# 切换实例的重试次数
MaxAutoRetriesNextServer: 1
#NFLoadBalancerRuleClassName: RandomRule
# 对所有请求开启重试,并非只有get 请求才充实。一般不会开启这个功能。该参数和上面的3三个参数没有关系
#okToRetryOnAllOperations: true
feign:
hystrix:
enabled: true #默认是1s降级
#client:
#config:
# default:
# connectTimeout: 4000 #要关掉feign超时连接时长
#readTimeout: 150000
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 100000 #这个时间要大于ribbon重试次数的总时长,否则还没重试完就降级了
被调用方设置线程睡眠
@RestController
public class ProviderController {
@Value("${server.port}")
private String port;
@RequestMapping(value = "/provider/{id}")
public String provider(@PathVariable String id){
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
return "exception:" + e.getMessage();
}
return "provider id = " + id + "port = " + port;
}
}
测试结果:由于openfeign重试默认是关闭的,我们不用管它。被调用方,如果只启动一个被调方实例,则一共12次,因为 MaxAutoRetriesNextServer: 1 切换下一个实例再重试,下一个实例还是自己,如果被调方启动两个实例,则各6次。另外重试和熔断都开启,超时时间是1s,一共是12次,也就是12s,12s之后就会降级,而hystrix配置的timeoutInMilliseconds的15s降级,在这里是以时间短的为主。如果不对timeoutInMilliseconds进行配置,那么hystrix默认是1s,也就是1s钟之后就会降级,但是不影响ribbon的重试。
你也可以指定对某个特定服务的超时和超时重试:
则其他的请求走上面的重试,spring-provider该服务的重试单独配置
# 针对 spring-provide 的设置,注意服务名是小写
spring-provide:
ribbon:
connectTimeout: 1000
readTimeout: 3000
MaxAutoRetries: 2
MaxAutoRetriesNextServer: 2
在被调方,修改如下代码测试
@RestController
public class ProviderController {
@Value("${server.port}")
private String port;
@RequestMapping(value = "/provider/{id}")
public String provider(@PathVariable String id){
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
return "exception:" + e.getMessage();
}
return "provider id = " + id + "port = " + port;
}
}
替换底层用HTTP实现
本质上是 OpenFeign 所使用的 RestTemplate 替换底层 HTTP 实现
- 替换成 HTTPClient
将 OpenFeign 的底层 HTTP 客户端替换成 HTTPClient 需要 2 步:
1、引入依赖:
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>
2、在配置文件中启用它:
feign:
httpclient:
enabled: true # 激活 httpclient 的使用
- 替换成 OkHttp
将 OpenFeign 的底层 HTTP 客户端替换成 OkHttp 需要 2 步:
1、引入依赖
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-okhttp</artifactId>
</dependency>
2、配置
feign:
httpclient:
enabled: false # 关闭 httpclient 的使用
okhttp:
enabled: true # 激活 okhttp 的使用
日志级别(了解)
前面讲过,通过logging.level.xx=debug来设置日志级别。然而这个对Fegin客户端而言不会产生效果。因为@FeignClient注解修改的客户端在被代理时,都会创建一个新的Fegin.Logger实例。我们需要额外指定这个日志的级别才可以。然后根据 logging.level. 参数配置格式来开启 Feign 客户端的 DEBUG 日志,其中 部分为 Feign 客户端定义接口的完整路径。默认值是NONE,而NONE不会记录Feign调用过程的任何日志的,也就是说这个日志不是启动feign客户端的日志,而是feign调用远程接口时产生的日志。
1)设置com.woniu包下的日志级别都为debug
logging:
level:
com:
woniu:
openfeign:
ProviderOpenfeign: debug #ProviderOpenfeign为某个feign接口
2)编写配置类,定义日志级别
内容:
@Configuration
public class FeignLogConfiguration {
@Bean
Logger.Level feignLoggerLevel(){
return Logger.Level.FULL;
}
}
这里指定的Level级别是FULL,Feign支持4种级别:

- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
3)在FeignClient中指定配置类:
@FeignClient(value = "spring-provider",fallback = ProviderOpenfeignFallback.class, configuration = FeignLogConfiguration.class)
public interface ProviderOpenfeign {
@GetMapping("/provider/{id}")
String provider(@PathVariable("id") String id);
}
4)重启项目,进行测试:在通过openfeign去调用某个接口时,会有详细的信息。如果把日志级别设置为NONE,则没有。
测试:http://localhost:8280/consumerOpenfeign







![[Java基础]—SpringBoot](https://img-blog.csdnimg.cn/7fe1904078864d418270bd9d08fd03a8.png#pic_center)