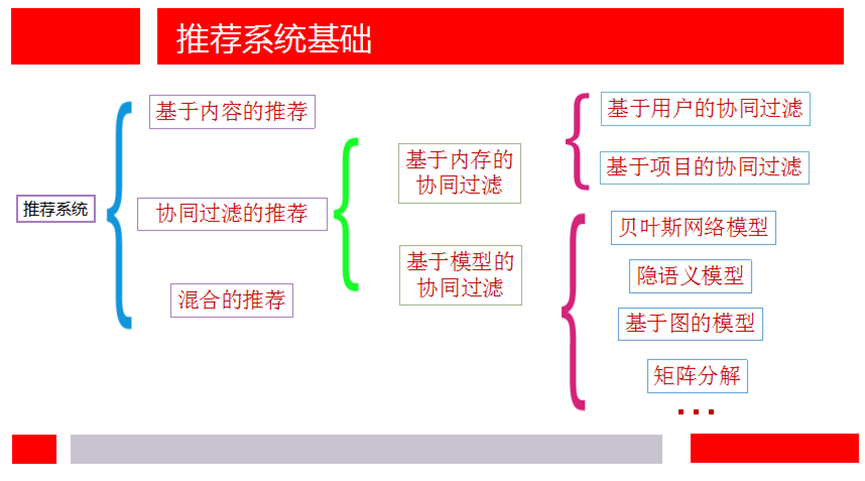
机器学习应用
机器学习的应用,主要分为两类:预测、分类
预测,一般是指:根据数据,预测数值
分类,一般是指:根据数据,进行分类
预测与分类的关系【个人理解】
分类,本质上也是一种预测。
预测,可预测实值,也可预测类别。
预测实值可通过线性回归模型,预测出线性的实际数值。
但当预测某个数据的类别(例如男女、老少等非连续的离散值)时,则变为了人们常说的分类问题。
因此,如果非要对预测、分类进行一个严格区分:
『 预测问题是对线性连续值的预测,分类问题是对非线性值的预测 』
机器学习基础流程
- 建立模型:根据应用类型,构造函数模型
- 学习模型:将数据应用于模型计算,并不断地根据计算结果,完善模型
- 使用模型:将学习后的模型(即训练好的模型),进行实际应用
机器学习的流程,就像是做菜-菠萝炒鸡。
👉建立模型,就像是根据目标,凭经验设计一个做菜的固定步骤。
- 开火
- 烧油
- 放菜
- 放盐
- 关火
虽然知道需要什么材料,但这个过程需要多少油,多少盐,多少火力,煮多久——无从知晓!
所以,建立模型时,只知道需要锅碗瓢盆油盐酱醋这些参数,但却不知道参数是多少!!!
👉学习模型,就像是一个鲁莽的菜鸟厨师。
它菜就菜在,不知道这些材料,都需要放多少量(即它也不知道放多少油盐酱醋才好吃)
它莽就莽在,不管三七二十一,先按这个步骤随便放初始量的材料,直接开炒!
每次炒的结果,都由一个试吃小白鼠去尝,如果小白鼠摇摇头不满意,鲁莽的菜鸟厨师就稍微调整一下材料用量
俗话说的好,不怕莽夫莽,就怕莽夫坚持不懈地莽下去。——我人有多俗,这话就有多俗,因为这话就是我这个俗人说的。。。
炒的次数多了,这个材料量自然就会慢慢调整好,小白鼠总有一天会拍灯,为你转身!
于是,鲁莽的菜鸟厨师,经过坚持不懈的尝试与改进,终于含泪掌握了菠萝炒鸡的配方。
其实有点儿“暴力破解法”的思想,就是,我也不知道你什么答案,但我一个个试,总能试出最佳答案!
👉使用模型,就像是鲁莽的菜鸟厨师,拿着配方出去开饭店了!
【比喻还是有些不够恰当的,但精髓到位就行】
1. 建立模型
建立模型,就是根据应用类型,构造函数模型。
应用类型分为:预测、分类。
1.1 预测的函数模型
预测:一般采用线性回归模型。
求解线性回归模型参数,即是学习模型的过程
常见的线性回归函数:一元线性回归【y = wx + b】、多元线性回归【Y= W T X W^{T}X WTX】
1.1.1 一元线性回归
一元线性回归【y = wx + b】,只有一个自变量 x,和一个因变量 y,有两个未知参数w和b
其中,w是变量x的权重,b是偏差。
一元线性回归,适用于预测只有单个因素影响某个指标的数据,并且该因素与该数据指标,是线性关系才会预测的更准。
例如,假设工资是唯一影响幸福指数的因素,那么可以建立一元线性回归的预测模型。
即:y = wx+b,x表示工资,y表示幸福指数
| 工资x | 幸福指数y |
|---|---|
| 10k | 10% |
| 19k | 13% |
| 15k | 40% |
| 119k | 80% |
| 500k | 120% |
| … | … |
1.1.2 多元线性回归
多元线性回归【y =
W
T
X
W^{T}X
WTX】,有多个变量x1,x2,x3…xn,构成了自变量X,每一个自变量x,都有对应的权重w1,w2,w3…wn
即y =
W
T
X
W^{T}X
WTX=w1x1+w2x2+w3x3+…+wnxn + w0*x0【这里的w0,x0,其实就相当于x0=1,w0=b,表示偏差b】
只有一个因变量y,因此多元线性回归,适用于由多个因素x影响某个数据指标y的情况,如果因素和指标是线性关系才会预测更准。
例如,假设颜值和工作,是影响幸福指数的两个因素,那么可以建立多元线性回归的预测模型。
即:y =
W
T
X
W^{T}X
WTX,X为,x0=1,x1,x2; y表示工资。
| 颜值x1 | 工资x2 | 幸福指数y |
|---|---|---|
| 30 | 10k | 10% |
| 10 | 19k | 13% |
| 80 | 15k | 40% |
| 40 | 119k | 80% |
| 90 | 500k | 120% |
| … | … | … |
1.2 分类的函数模型
分类:一般是线性回归函数+非线性函数,构成的逻辑回归函数。
通常是引入非线性函数(激活函数),对线性回归结果进行非线性加工计算。
常见的激活函数有逻辑回归
具体的激活函数σ有多种,常见的有sigmoid函数(也叫逻辑回归函数)、Relu函数、softmax函数等。

(sigmoid与softmax实际相通,解释不同)
线性回归预测的结果值,经过逻辑回归,可实现分类效果。
总结来看:
如果要求实现预测,需建立线性回归模型。
如果要求实现分类,需建立逻辑回归模型。
2. 学习模型:求解最优模型
选择损失函数
模型效果如何,是通过判断当前模型计算结果与实际结果拟合程度,拟合效果可通过损失函数来计算。
损失函数:用于判断模型效果。
损失函数有多种,常见的有三种:最小二乘法、极大似然估计法、交叉熵法。
即对应:平方损失函数(最小二乘法)、交叉熵损失函数(极大似然估计法、交叉熵法)
认识常用损失函数:
① 最小二乘法(模型计算结果与实际结果差值的平方和)
Loss = (模型计算结果-实际结果)的平方和
平方损失函数值越小,模型越优
② 极大似然估计法——(即交叉熵法,解释角度不同,但公式相同)
似然值:每个模型下发生的概率,叫做似然值。当似然值越大,表示该概率模型与实际结果概率的分布更接近。
极大似然估计法,就是在挑出似然值越大的那个概率模型。
Loss =
似然值(交叉熵)越大,模型越优。
总结来看:
最小二乘法(平方损失函数值越小,模型越优)
极大似然估计法(似然值越大,模型越优)
计算损失函数的值,并更新模型参数
模型与实际模型的拟合程度通过损失函数计算可得,而损失函数的计算通常有以下两种方法:
求出解析解,得到精确模型——数学计算求极值
求出近似解,逼近较优模型——梯度下降法、牛顿法…
① 求出解析解,更新模型参数
解析法求线性回归(可换为逻辑回归)的平方损失函数极小值
但使用解析法求出线性回归的平方损失函数极小值的前提是,是满秩矩阵
(数据集内容不同,结果可能满秩,也可能不满秩,因此最小二乘法在数据量过大数据内容不确定情况,有可能无法使用最小二乘法,可采用L2正则化进行优化【此知识点难度较大,待更新】,或是数量级差距过大,最小二乘法得出的结果偏差过大)
解析法求交叉熵损失函数的极大值(求解似然最大值)
对交叉熵损失函数求导,使导数为0,计算极值(具体不作详解)
计算平方损失函数、或是交叉熵损失函数的极值后,得到模型参数,即可更新为最终模型。
解析法难以应对大批量的数据集计算,因此实际常用求近似解,逼近较优模型的方式。
② 求出近似解,更新模型参数
求出近似解-梯度下降法:
使用梯度下降法,求解损失函数的值,多次迭代计算出损失函数的值。
停止迭代的方式有两种:
①设置损失函数的阈值,当损失函数小于某阈值,即停止迭代
②设置迭代的次数,当迭代次数超过时,即停止迭代(迭代会收敛,迭代次数越多,则越逼近极值)
多次迭代过程中,不断更新模型参数,使模型在迭代过程中逐渐变优。
牛顿法:
(正在学习中,涉及较多,待更新)
多层神经网络的浅显认识
上述是对单层神经网络的模型进行迭代,更新模型参数。
但当涉及多层神经网络时,中间含有较多隐含层,要如何更新各层模型的参数呢?
若是要训练多层神经网络,可考虑误差反向传播法:
计算当前模型的预测值与实际值的误差,根据误差值反向计算各层的参数加粗样式