在2023年初,达坦科技发起成立硬件设计学习社区,邀请所有有志于从事数字芯片设计的同学加入我们的学习互助自学小组,以理解数字芯片设计的精髓,强化理论知识的同时提升实操技能,继而整体提升设计能力。现在,完成第一期学习的同学整理了MIT6.175和MIT6.375的关键内容以及Lab实践的学习笔记。
6.175和6.375的课程和Lab学习都有一定的难度,要求采用Bluespec语言实现RISC-V处理器,并支持多级流水、分支预测、缓存、异常处理、缓存一致性等功能。此外,Lab环节还涉及软硬件联合开发,要求基于所实现的RISC-V处理器运行真实的RISC-V程序,并给出性能评估。希望第一期学员(GitHub:kazutoiris )的学习笔记对想从事数字芯片设计的工程师有所帮助。
MIT 6.175
环境搭建
虚拟机场景
建议使用 Ubuntu 20.04 + bsc + connectal 进行环境初始化。
⚠️ Alma Linux/Rocky Linux/CentOS 对于 connectal 支持有限,可能会影响到后期仿真。
使用 bsvbuild.sh 可以很方便的进行仿真,而且还支持了一键波形导出等功能。
Docker 场景
建议使用 kazutoiris/connectal 镜像。在 Docker Hub 上的部分镜像使用的 bsc 是旧版,而且并没有安装 connectal。我的镜像由 Ubuntu 22.04 + bsc 2023.1 + connectal + bsvbuild.sh 四部分组成,足够满足 Lab 要求。
version: "3.9"
services:
connectal:
image: kazutoiris/connectal:latest
volumes:
- .:/root
network_mode: none四种 FIFO (Lab 4)
Lab4 的要求是设计各种 Depth-N FIFO。可并发 FIFO 允许流水线级与级之间相互连接而不引入额外的调度约束。一个可并发 FIFO 需要实现可并发的 enqueue 和 dequeue 方法。要实现较大深度的FIFO,需要使用循环缓冲。
握手常用的 FIFO 实例有三种,分别是:Depth-1 Pipeline FIFO、Depth-1 Bypass FIFO、Depth-2 Conflict-Free FIFO。这三种 FIFO 面积最小(可以省略 notEmpty、notFull 寄存器),且能够满足大多数流水线设计的需求。
1. Conflict FIFO
不可同时 deq 和 enq。
2. Conflict-Free FIFO
{notFull, enq, notEmpty, first, deq} < clear非空时可同时 deq 和 enq。
3. Pipeline FIFO
{notEmpty, first, deq} < {notFull, enq} < clear满可同时 deq 和 enq。级联会产生较长的 Ready 组合信号链,从后级一直指向前级。
4. Bypass FIFO
{notFull, enq} < {notEmpty, first, deq} < clear空可同时 deq 和 enq。级联会产生较长的 Valid、Payload 组合信号链,从前级一直指向后级。
Ready 和 Valid 握手
1. Valid 打一拍,Ready 不打拍

因为 Ready 快于 Valid,所以当 Ready 由有效变为无效时,需要缓存前一个周期的一拍数据。
(因为这一拍数据刚好就在实现延迟一拍的寄存器上,所以可以不用多加寄存器就可以直接实现)
因为第一拍数据送入之前为空,而之后都是处于满的状态,所以可以当成 Depth-1 Pipeline FIFO ,在满时可同时进行 deq 和 enq 操作。
case class Delay1() extends Component {
val io = new Bundle {
val m = slave Stream UInt(8 bits)
val s = master Stream UInt(8 bits)
}
io.m.ready := ~io.s.valid
io.s.payload := RegNextWhen(io.m.payload, io.m.fire) init 0
io.s.valid := RegNextWhen(Mux(io.s.fire, False, True), io.m.fire || io.s.fire) init False
}2. Ready 打一拍,Valid 不打拍

因为 Valid 快于 Ready,所以当 Ready 由有效变为无效时,线路上多发了一拍数据。这一拍数据就要新增一个 buffer 去进行缓存。
因为第一拍数据送入之前为满,而之后都是处于空的状态,所以可以当成 Depth-1 Bypass FIFO ,在空时可同时进行 deq 和 enq 操作。
(这里可以考虑一下传给 master 的 Ready 信号。如果 buffer 为空,那么必然是 Ready 的;如果 buffer 为满,那么必然不是 Ready 的。这样就可以省掉一个寄存器去为 slave 的 Ready 打一拍。)
case class Delay2() extends Component {
val io = new Bundle {
val m = slave Stream UInt(8 bits)
val s = master Stream UInt(8 bits)
}
private val buffer = Reg(UInt(8 bits)) init 0
private val bufferValid = RegInit(False)
io.m.ready := !bufferValid // buffer 为空
io.s.payload := Mux(!bufferValid, io.m.payload, buffer) // buffer 为空则直通
io.s.valid := io.m.valid || bufferValid // buffer 为空则直通
when(io.m.fire && !io.s.ready) { // buffer 为空且 m 有效且 s 不 ready
buffer := io.m.payload
bufferValid := True
}
when(io.s.fire) { // buffer 输出后失效
bufferValid := False
}
}3. Ready 和 Valid 各打一拍,要求所有输出都为寄存器输出。

Ready 从有效变为无效的时候,Ready 到达晚一拍,Valid 有一拍有效数据已经送出去了。等 Ready 到达 master,已经多送出了两拍有效数据。所以这两拍数据必须被缓存起来。
在数据传输刚开始的时候,第一拍数据是从 FIFO 中直出的。第二拍的时候,slave 的 Ready 送至 master。在之后的数据传输过程中,其中停滞的只有一个数据。
显而易见, 可以使用 Depth-2 Conflict-Free FIFO,在非满非空的时候可以同时 deq 和 enq。master 的 Ready 信号就是 notFull,slave 的 Valid 信号就是 notEmpty。可见,所有输出均为寄存器输出。
case class Delay3() extends Component {
val io = new Bundle {
val m = slave Stream UInt(8 bits) // 要求 Ready 为寄存器输出
val s = master Stream UInt(8 bits) // 要求 Valid、Payload 为寄存器输出
}
private val delay1 = Delay1()
private val delay2 = Delay2()
io.m <> delay2.io.m // Ready 为寄存器输出
delay2.io.s <> delay1.io.m
io.s <> delay1.io.s // Valid、Payload 为寄存器输出
}EHR 寄存器 (Lab4)
EHR 寄存器是一种特殊的寄存器,它可以进行并发操作。这意味着可以同时读取和写入 EHR 寄存器,而不需要任何同步或锁定,这使得 EHR 寄存器非常适合于流水线设计。
⚠️ EHR 往往会导致关键路径过长,而且难以跟踪具体路径,所以要尽可能避免在大型项目中使用。
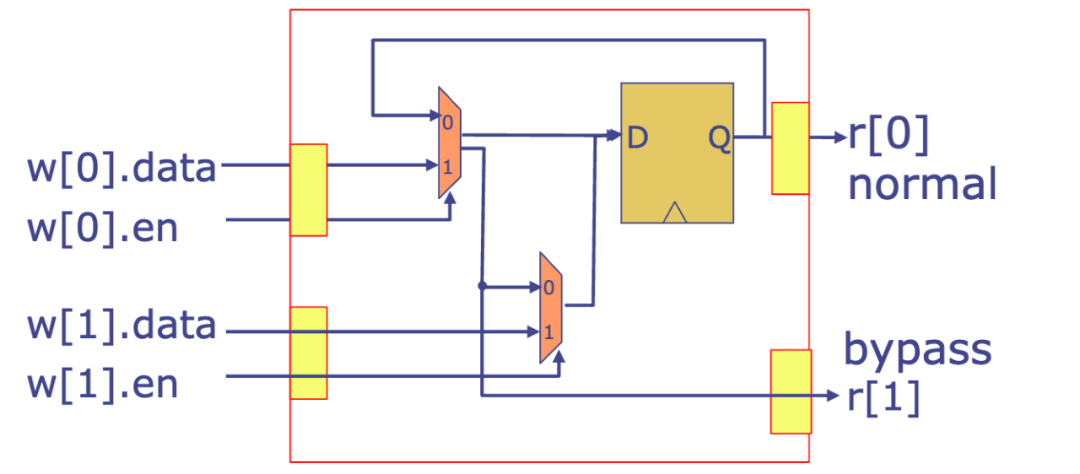
图上可以看出,r[0] 为寄存器输出,r[1] 为组合逻辑输出。

w[1] 具有最高优先级,当 w[1] 写入时,会忽略 w[0] 的写入。
RISC-V (Lab5)
elf2hex 可以通过 GitHub - riscvarchive/riscv-fesvr: RISC-V Frontend Server 编译得到。尽管仓库目前是弃用状态,但是编译出来的工具仍然可用。现行仓库 GitHub - riscv-software-src/riscv-isa-sim: Spike, a RISC-V ISA Simulator 也有这个工具,但是附带了很多不必要的工具。
trans_vmh.py 需要用 Python 3 运行,需要手动在 Makefile 里修改 python 为 python3。当然,你也可以直接修改文件头,直接作为可执行文件运行。
⚠️ CSR 寄存器在 gcc 中有改动,现行的命名、序号都与测试程序中不同。需要你在编译测试程序时进行修改。
1. 双周期(冯诺依曼架构)
取指 -> 执行在第一个周期中,处理器从内存中读取当前指令并对其进行解码。
在第二个周期中,处理器读取寄存器文件,执行指令,进行ALU操作、内存操作,并将结果写入寄存器文件。
2. 四周期(支持内存延迟)
取指 -> 解指 -> 执行 -> 写回- 在取指阶段,向内存发送 PC 地址请求,但是不要求立刻响应。
- 在解指阶段,读取内存请求响应。
- 在执行阶段,向内存发送数据读取或写入请求,但是不要求立刻响应。
- 在写回阶段,读取内存请求响应。
3. 两级流水线
取指 -> 执行与双周期不同的是,在执行的同时在进行取指。当处理器执行分支指令时,下一条指令的地址可能是未知的,这就是所谓的“控制流不确定性”。
这种不确定性会导致处理器在执行分支指令时停顿,直到下一条指令的地址被确定。这种停顿会降低处理器的性能。为了解决这个问题,可以使用PC+4预测器来预测下一条指令的地址。如果预测正确,处理器可以继续执行下一条指令。如果预测错误,则需要回退并重新执行分支指令后面的指令。这种回退会导致处理器停顿,从而降低性能。
4. 六级流水线 (Lab6)
取指 -> 解指 -> 读取寄存器 -> 执行 -> 内存 -> 写回- 取指:向 iMem 请求指令。
- 解指:从 iMem 接收响应并解码指令。
- 读取寄存器:从寄存器文件中读取。
- 执行:执行指令并在必要时重定向。
- 内存:向 dMem 发送请求
- 写回:从 dMem 接收响应,并写入寄存器。
一点调试小技巧
可以指定一个 cnt 计数器,在达到一定时钟周期后强制终止。在调试的时候,测试程序往往会进入死循环,导致日志文件相当庞大,而且进程也无法被终止。
Branch Prediction (Lab6)
1. BHT 记录分支指令最近一次或几次的执行情况(成功或不成功),预测是否采用 BTB 的目标地址跳转(即:跳不跳?taken or not taken)。

2. BTB 主要记录分支指令跳转目标地址(即:往哪里跳?branch target)


3. RAS 仅用于函数返回地址场景的预测。当程序执行到分支跳转指令时,RAS 需要判断指令是否属于“函数调用”类型的分支跳转指令。如果遇到 rd = x1 的 JAL/JALR 指令时,RAS 入栈返回地址;如果遇到 rd = x0 且 rs1 = x1 的 JALR 指令出栈 RAS,作为函数返回地址。
4. BONUS 是一种基于 BHT 和 BTB 的分支预测算法,它将两者的结果进行加权平均,以得到更为准确的预测结果。
分支预测的记录部分是放在执行环节,预测部分放在取指环节。
在分支预测中,建议使用 cononicalize 规则去单独处理 PC 指针的重定向。如果你在取指、解码、执行阶段直接进行重定向,往往会导致各种各样的时序环。
ℹ️ 分支预测错误需要洗刷流水线,可以通过设置一位 canary 并判断值是否一致。相较于直接 clear 全部前级,会更加方便。
❗ 只需要洗刷前级,禁止洗刷后级。
All the images in this section are cited from [jdelgado].
DDR3 Memory (Lab7)
DDR3 提供了大容量、高带宽、高延迟的内存。读取方式和之前读取 Mem 基本一致,不过响应位宽是 512 位。返回的指令可以存入 Cache,通过指定 index 来依次访问。也正是由于这个原因,DDR3 在访问时需要对地址做对齐。
⚠️ 务必修改 trans_vmh.py。导入的位宽是按 vmh 文件的位宽来算的,不是按在 RegFile 中指定的位宽来算的。
Cache Coherence (Project)
在项目中,需要实现多个核心之间的缓存一致性。

- MessageFIFO 优先出栈 resp 请求。MessageRoute 通过遍历所有核心,如果存在对应核心的回应,则会将回应送入对应核心的 MessageFIFO。
- c2m 是来自 L1 的 DCache(实际上是来自 MessageRoute)的 MessageFIFO 的接口,向上请求和向下响应可以从此接口读取。
- m2c 是 MessageFIFO 到 L1 的 DCache(实际上是到 MessageRoute)的接口,应将向下请求和向上响应发送到此接口。
ℹ️ 多核运行时会重复打印,可以指定只有 0 号核才可以打印。
阻塞式缓存
阻塞式缓存在接收到未命中的请求后,会等待内存响应后才能继续处理其他请求。这种方式会导致处理器停顿,从而降低性能。
整体流程:Ready → StrtMiss → SndFillReq → WaitFillResp → Resp → Ready
- Ready:处理器可以继续执行下一条指令。
- StrtMiss:处理器发起未命中请求。
- SndFillReq:处理器发送请求到内存。
- WaitFillResp:处理器等待内存响应。
- Resp:处理器接收到内存响应。
非阻塞式缓存
非阻塞式缓存能够在接收到未命中的请求后,继续处理其他请求,而不是等待内存响应。
非阻塞式缓存的实现方式是 MSHR [1]。MSHR 是一个队列,用于存储未命中的请求。
非阻塞式缓存的 miss 有三种可能:
- primary miss:某个块的第一次 miss。
- secondary miss:对某个已经在 fetch 的 block 又一次 miss。
- structural-stall miss:由于 MSHR 不够导致的 miss,会发生阻塞。
MSI 状态机转换模型
1. MSI

MSI 是一种缓存一致性协议的状态类型,它代表了缓存行的三种状态:Modified(已修改)、Shared(共享)和Invalid(无效)。其中,Modified 表示该缓存行已被修改且未被写回主存,Shared 表示该缓存行被多个缓存共享,而 Invalid 表示该缓存行无效,不包含有效数据。
2. MESI

MESI 协议将“Exclusive”状态添加到 MSI 状态机中,可以减少只在单个缓存中存在的缓存行的回写次数。
3. MOSI

MOSI 协议将“Owner”状态添加到 MSI,可以减少由从其他处理器读取而触发的写回操作。
4. MOESI

MOESI 中的 O 是 Owner 的意思,表示该缓存行已被修改且已被写回主存,E 是 Exclusive 的意思,表示该缓存行只被一个缓存独享。这两个状态可以被用到,也可以被忽略。
All the images in this section are cited from [kshitizdange].
Snooping 协议
所有的一致性控制器按照相同的顺序观察(嗅探)一致性请求,共同维护一致性。依靠当前块的所有请求,分布式一致性控制器能够正确地更新表示块状态的状态机。Snooping 协议向所有一致性控制器广播请求,包括发起请求的控制器。一致性请求通常在有序广播网络(如总线)上传输,这可以确保每个一致性控制器都以相同的顺序观察到所有请求,从而保证所有一致性控制器都可以正确地更新缓存块的状态。
Directory 协议
Directory 协议是一种用于解决多处理器中缓存一致性的硬件策略,适用于在分布式共享存储多处理器系统中实现。它使用目录表来维护缓存块的状态,以便在多个处理器之间共享数据时保持一致性。当一个处理器想要读取或写入一个缓存块时,它会向目录表发送请求,以确定该块是否已被其他处理器缓存。如果是,则确定哪些处理器缓存了该块。然后,该处理器可以与其他处理器通信以获取或更新该块的副本。
ℹ️ Snooping & Directory
Snooping 协议采用广播的形式。如果缓存控制器需要发起一个请求,是通过广播请求消息到所有其它的一致性控制器。
Directory 协议则是缓存控制器单播请求到那个块所在的控制器。每个控制器都维护一个目录,其中包含了每个块的状态,例如当前所有者和当前共享者的信息等。当一个请求到达根目录时,控制器递归会查找这个块的目录状态,并进行定向转发
Snooping 协议会广播所有请求,需要较少的硬件资源,但是在大型系统中可能会导致总线流量过大。
Directory 协议需要更多的硬件资源,但可以提供更好的可扩展性和更少的总线流量。
❗ 关于 Memory Consistency
Cache Coherence → 缓存一致性
Memory Consistency → 内存连贯性
为什么不同时使用 coherence 呢?为什么要区分一致和连贯呢?
原因:
缓存一致性是指多个处理器或核心共享同一缓存时,确保它们都可以访问相同的数据并且具有相同的值。当一个处理器或核心修改了缓存中的数据时,其他处理器或核心应该能够看到这个修改并且更新它们自己的缓存。例如,假设处理器有两个核心,它们都有自己的缓存,并且它们都在读取和写入同一块内存。如果一个核心写入了一个值,那么另一个核心应该能够看到这个值的变化并且更新自己的缓存,确保它也可以读取到最新的值。
内存连贯性是多线程共享同一内存并使用缓存层次结构的关键要素之一。例如,如果一个线程上写入了一个变量,那么在另一个线程读取该变量时,能够读取到该变量的最新值。
缓存一致性的主要对象是核心,而内存连贯性的主要对象是线程。所以,缓存一致性实现依靠硬件,而内存一致性依靠软件。在具有缓存的系统中,缓存一致性协议确保了缓存数据的 Cache coherence;而在不具有缓存的系统中,由于不存在缓存一致性问题,因此只需要考虑 Memory consistency。
Part of the content presented in this section has been cited from [AP].
MIT 6.375
Bluespec 中的一些特性
调度属性
- no_implicit_conditions 属性用于断言:一个规则中所有的方法不含隐式条件。
- fire_when_enabled 属性用于断言:当某个规则的显式和隐式条件为真时,该规则必须被触发。也就是说,fire_when_enabled 检查一个规则是否因为与其他规则有冲突,且紧急程度较低,而导致在本来该激活(显式和隐式条件都满足)时被抑制了激活。
- descending_urgency 在冲突发生时,指定多个规则的紧急程度,紧急的规则抑制不紧急的规则的激活。
- mutually_exclusive 在多个规则互斥(不会同时激活)的情况下,如果编译器分析不出来互斥关系,以为冲突会发生,用 mutually_exclusive 告诉编译器它们是互斥的。
- conflict_free 在多个规则可能同时激活,但它们中的引起冲突的语句并不会同时执行时,如果编译器分析不出来互斥关系,以为冲突会发生,用 conflict_free 告诉编译器冲突并不会发生。
- preempts 给两个规则强制加上冲突(即使他们之间不冲突),同时指定紧急程度。
❗尽管 Bluespec 中可以单独为 rule 指定不同的优先级,但是这往往会引起各种各样的时序冲突。所以一般都用于断言。
泛型约束
和 Java/Kotlin 中的泛型约束类似,规定了泛型的上界。

CORDIC 算法
CORDIC 算法的运算流程如下:
- 选择一个初始向量和目标角度。
- 将目标角度分解为多个旋转角度,每个旋转角度都是一个固定的值,可以通过查表得到。
- 对于每个旋转角度,计算出旋转后的向量,并将其作为下一次迭代的初始向量。
- 重复步骤 3 直到达到目标精度或迭代次数。
具体可以参考 第三章 CORDIC · FPGA并行编程。
一些常用的概念
Setup Time 、Hold Time 和 Clock-to-Q Time
概念
- Setup time 指的是数据在时钟沿(上升沿或下降沿)到来之前必须被稳定保持的最短时间。如果数据没有在 Setup time 内稳定下来,那么接收端可能无法正确识别数据,并产生错误结果。
- Hold time 指的是数据在时钟沿(上升沿或下降沿)到来之后需要保持的最短时间。如果数据没有在 Hold time 内得到保持,那么接收端可能无法正确地接收到数据,并产生错误结果。
- Clock-to-Q time 是指从时钟(Clock)信号的上升沿到输出数据(Q)稳定的时间。
时序分析
下面以“D型数据锁存器边沿触发器”为示例。
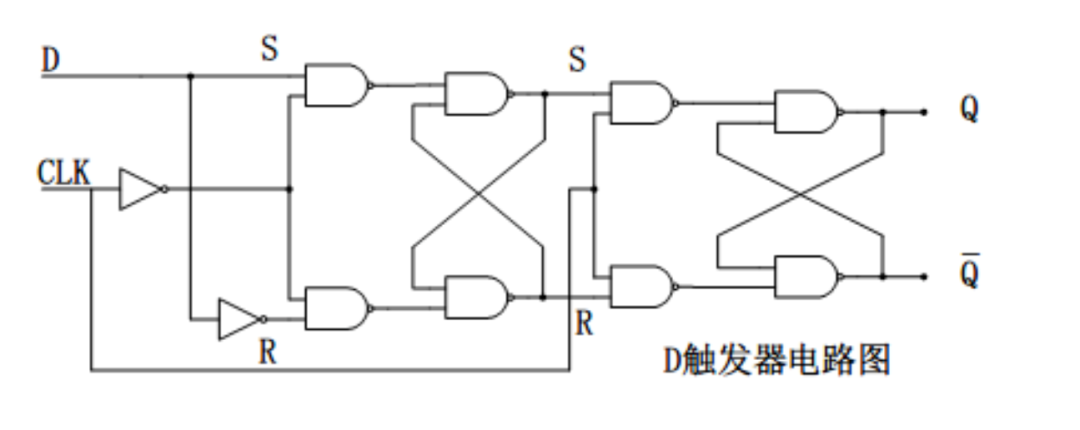
网上的一些“D触发器”图片并不是边沿触发的,而是电平触发的。写着触发器,实际上是锁存器。
1. Setup time
假设此时 CLK 从 0 跳变到 1。
Setup time 指的是数据在时钟沿(上升沿或下降沿)到来之前必须被稳定保持的最短时间。
如果不稳定会怎么样?如果 D 信号发生变化,会直接影响到 S 端的信号变化。由于前级处于直通模式,前级的变化会直接反映给后级。如果此时进行状态切换,则会导致前级记录错误数据。这段时间用于洗刷前级错误数据。
所以,此时的 Setup time 包含了前级的四个与非门和一个非门电路。即 D 信号通过路径上的所有门电路。
2. Hold time
假设此时 CLK 从 0 跳变到 1。
Hold time 指的是数据在时钟沿(上升沿或下降沿)到来之后需要保持的最短时间。
其保持原因和 Setup time 几乎一致。由于信号存在延迟,并没有立刻完成状态切换。所以,此时 CLK 的信号跳变所经过的所有门电路也应该一并考虑。
所以,此时的 Hold time 包含了前级的四个与非门和两个非门电路。即 D 信号、CLK 信号通过路径上的所有门电路。
3. Clock-to-Q time
Clock-to-Q time 是指从时钟(Clock)信号的上升沿到输出数据(Q)稳定的时间。在图中就是后级的门电路,包括了四个与非门。
4. 下降沿时序分析
上面的都是在分析上升沿,这是因为两个很明显的原因:
- 这张图中的 D 触发器是时钟上升沿触发的。
- 很明显,CLK 信号直通前级,但是经过一个反相器到达后级。所以前级状态切换的速度肯定比后级快,所以就没有必要去考虑 Setup time 和 Hold time。
ℹ️ 但是,如果是下降沿触发的 D 触发器呢?那么这个反相器会加在前级,前级的延时会比后级高。这种情况为什么在分析上升沿时候也可以不考虑 Setup time 和 Hold time 呢?
分析:
先明确一点,Setup time 和 Hold time 指的是整个电路中最开始的输入信号,对应着图上的 D 信号。
后级从直通进入保持状态。在 CLK 发生跳变前,前级处于保持状态,所以前级进入后级的信号在上升沿到下降沿的半个时钟周期内都不会发生变化,这早已满足后级 Setup time 要求,所以不需要考虑 Setup time。
当 CLK 发生跳变后,前级处于直通模式。此时,任何 D 信号的变化都会对前级产生影响。但是,D 信号发生的任何变化都需要经过前级的所有门电路。前级门电路的数量大于后级数量,所以前级带来的延迟也比后级大。即使变化传递至后级时,后级也早已进入稳定。所以不需要考虑 Hold time。
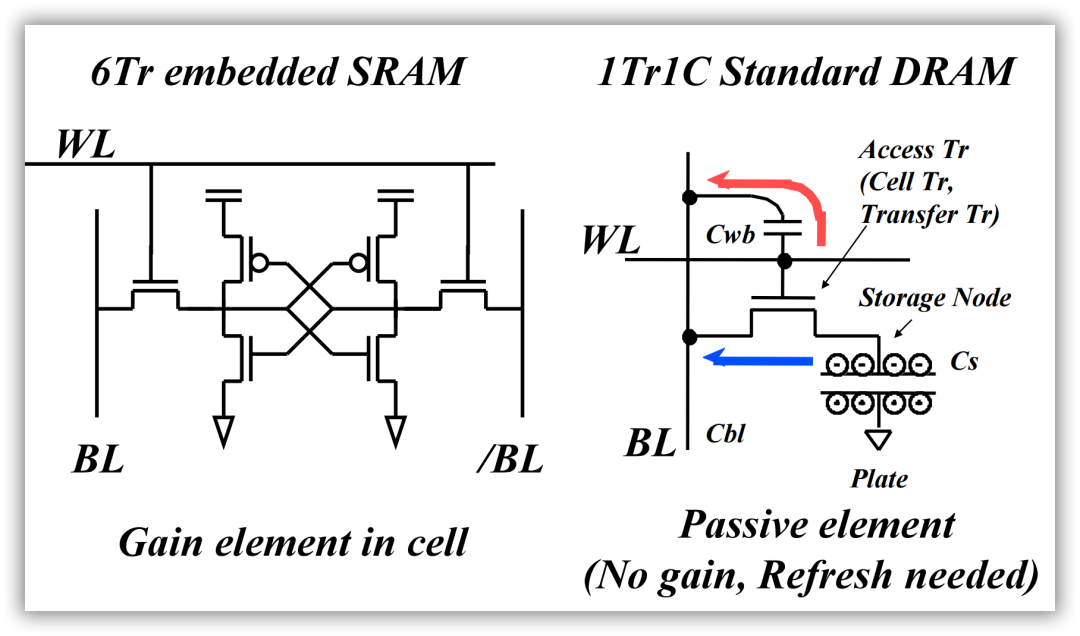
SRAM
单端口 SRAM(1R/W)

SRAM 是通过 BL 和 ~BL 控制读写,WL 控制具体的行。
1. SRAM 写 0
BL = 0, ~BL = 1, WL = 1。此时 Y = 0。
2. SRAM 写 1
BL = 1, ~BL = 0, WL = 1。此时 Y = 1。
3. SRAM 读
BL = 1, ~BL = 1, WL = 1。通过检查 BL 和 ~BL 的电压降低情况可以知道 Y 的值。
如果 BL 电压降低,那么 Y = 0;如果 ~BL 电压降低,那么 Y = 1。
伪双端口 SRAM (1R1W)

伪双端口具有独立的读写字线(RWL, WWL)和读写位线(RBL, WBL 和 WBLB)。
真双端口 SRAM (2R2W)

具有两套完整的读写字线和读写位线。
All the images in this section are cited from [宇芯电子].
DRAM
1. DRAM 写
- 双侧的 BL 预充电到 0.5V;
- 接通 WL 后,BL 设置成相应的电压;
- 数据写入。
2. DRAM 读
- 在 WL 不被激活的时候,两侧的 BL 的电压保持为 0.5V;
- 接通 WL 后,电容与右侧 BL 接通,部分电荷从电容流出或流入,使其电压小幅增加或减小(足够被检测到);
- 在放大器的作用下,电压较高的一侧越来越高,低的越来越低,最后输出可识别信号;
- 在电压的帮助下,电荷重新流入电容,使其充满电。
ℹ️ SRAM 要 6 个 transistor,而 DRAM 只需要 1 个 transistor。为什么 CPU 里面一般放的是 SRAM,不是 DRAM 呢?
原因:
在 CMOS 中,正反馈是指输出信号被放大并反馈到输入端,从而增强输入信号的幅度。这种放大器被称为正反馈放大器。在 CMOS 中,正反馈放大器是由 PMOS 和 NMOS 两个互补的 MOSFET 电晶体管组成的。
SRAM 用了正反馈的锁存器/寄存器,速度显然比类似于模拟电路(就是一个模拟的开关对电容充电)的 DRAM 要快很多。
References
- [jdelgado] José G. Delgado-Frias, https://eecs.wsu.edu/~jdelgado/CompArch/branch_predictionF12.pptx
- [kshitizdange] https://kshitizdange.github.io/418CacheSim/final-report
- [AP] Nagarajan, V., Sorin, D. J., Hill, M. D., & Wood, D. A. (2020). A Primer on Memory Consistency and Cache Coherence, Second Edition. Synthesis Lectures on Computer Architecture, 15(1), 1–294.
- [宇芯电子] https://www.cnblogs.com/wridy/p/13273377.html
1. MSHR是指“Miss Status Holding Register”,是一种用于缓存中的数据结构,用于保存未命中的缓存请求的状态信息。
达坦科技硬件设计学习社区持续开放,点击原文(GitHub - kazutoiris/MIT6.175)了解社区学习详情。若想询问加入细节,请添加小助手微信号:Apathy_no

达坦科技(DatenLord)专注下一代云计算——“天空计算”的基础设施技术,致力于拓宽云计算的边界。达坦科技打造的新一代开源跨云存储平台DatenLord,通过软硬件深度融合的方式打通云云壁垒,实现无限制跨云存储、跨云联通,建立海量异地、异构数据的统一存储访问机制,为云上应用提供高性能安全存储支持。以满足不同行业客户对海量数据跨云、跨数据中心高性能访问的需求。
公众号:达坦科技DatenLord
DatenLord官网:http://www.datenlord.io
知乎账号:
达坦科技DatenLord - 知乎
B站:
https://space.bilibili.com/2017027518
往期推荐
欢迎加入达坦科技硬件设计学习社区
达坦科技:创业是一场灵魂深处的摇滚
相约这个夏天|达坦科技邀您参加2023开源之夏