文章目录
- 1、动机
- 2、模型结构
- 3、代码实现细节:
- Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations
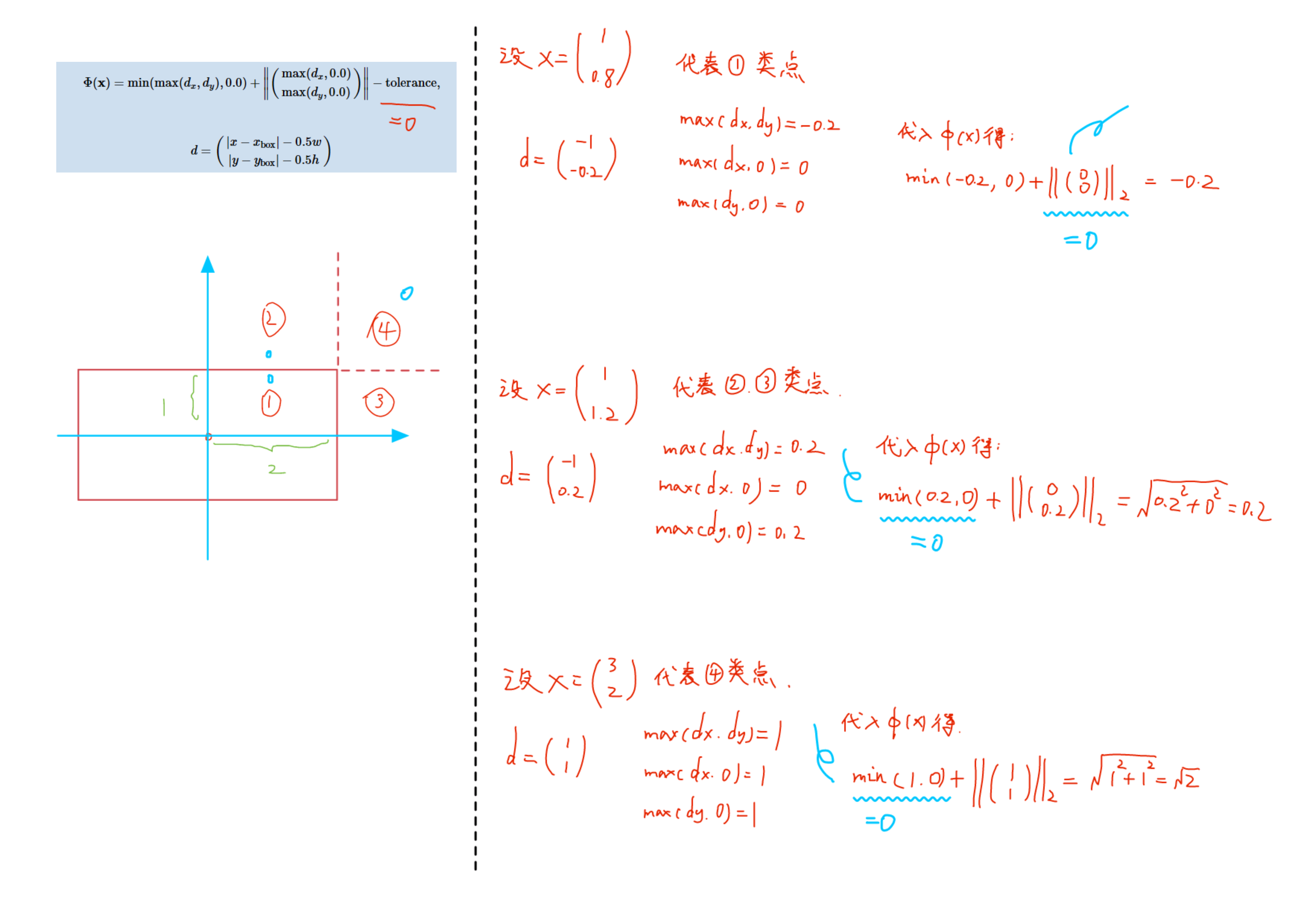
- 论文发表在 RecSys-2020, best paper。ple主要缓解了mtl里两大问题:负迁移和跷跷板现象,相比其他mtl model,提升较大(但性能的提升更像是堆叠层增加参数量带来的)。
1、动机
mtl里的两大问题:
- 跷跷板现象: 一个task性能的提升是通过损害另一个task性能作为代价换来的。
- 负迁移现象: 不同任务之间相关性不大,即存在冲突时,会导致模型无法有效进行参数的学习,不如对多个任务单独训练。
ple在多任务数据:视频有效观看(二分类任务)与观看时长(回归任务)上,测试了mtl model的效果,实验发现当前mtl模型的上述两大问题非常严重。
2、模型结构
模型结构如下,和MMOE非常相似,比MMOE更深层了。

Extraction Network:
- MMOE里不同task是共享相同的expert,然后不同task有不同的gate来整合expert的输出。而ple则分为了shared expert 和 task-specific expert。这样有利于通过share来保留一定的transfer learning的能力。
- 同样的,gate也分为了shared gate 和 task-specific gate。如其中任务A的task-specific gate的输入为expert A和expert shared。而shared gate 的输入为expert A,expert shared,expert B。
- 因为是multi-level Extraction Networks,所以一层出来后接着对应输入下一层Extraction Network。【注:single-level的ple,称为CGC(Customized Gate Control)】


- 最后task-specific expert的输出分别输入对应的塔。
3、代码实现细节:
- 每个task的expert数量以及shared expert是个超参数,需根据自己的任务做调整;
- Extraction Network里的gate的数量为 num_tasks+num_shared,最后一层gate的数量为 num_tasks;
- 如gate A负责给 expert A和expert shared生成注意力(att1, att2),那当前expert的gate的输出即为:expertA * att1 + expert shared * att2,即向量对应位置直接相加。
参考链接:https://blog.csdn.net/u012328159/article/details/123617326