协议:CC BY-NC-SA 4.0
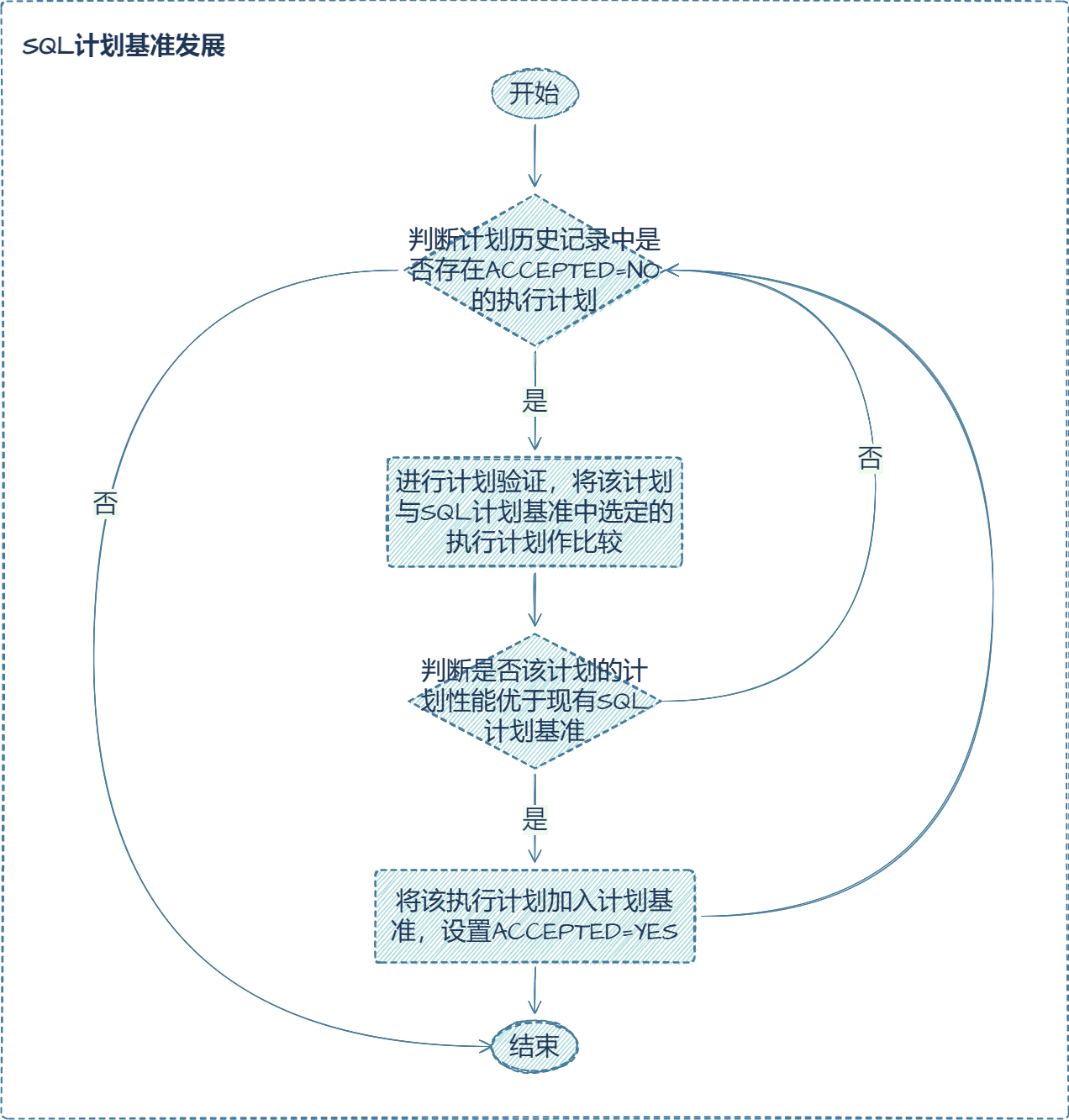
译者:飞龙
本文来自【OpenDocCN 饱和式翻译计划】,采用译后编辑(MTPE)流程来尽可能提升效率。
真相一旦入眼,你就再也无法视而不见。——《黑客帝国》
五、字符串
本章涵盖
- 理解GO中符文的基本概念
- 通过字符串迭代和修剪防止常见错误
- 避免因字符串连接或无用转换而导致的低效代码
- 用子字符串避免内存泄漏
在 Go 中,字符串是一种不可变的数据结构,包含以下内容:
-
指向不可变字节序列的指针
-
该序列中的总字节数
我们将在本章中看到 Go 有一个非常独特的处理字符串的方法。Go 引入了一个概念叫做符文;这个概念对于理解是必不可少的,可能会让新手感到困惑。一旦我们知道了字符串是如何被管理的,我们就可以避免在字符串上迭代时的常见错误。我们还将看看 Go 开发者在使用或生成字符串时所犯的常见错误。此外,我们会看到有时我们可以直接使用[]byte工作,避免额外的分配。最后,我们将讨论如何避免一个常见的错误,这个错误会造成子字符串的泄漏。本章的主要目的是通过介绍常见的字符串错误来帮助你理解字符串在 Go 中是如何工作的。
5.1 #36:不理解符文的概念
如果不讨论GO中的符文概念,我们就不能开始这一章。正如您将在接下来的部分中看到的,这个概念是彻底理解如何处理字符串和避免常见错误的关键。但是在深入研究 Go runes 之前,我们需要确保我们在一些基本的编程概念上是一致的。
我们应该理解字符集和编码之间的区别:
-
字符集,顾名思义,就是一组字符。例如,Unicode 字符集包含 2^21 字符。
-
编码是字符列表的二进制翻译。例如,UTF-8 是一种能够以可变字节数(从 1 到 4 个字节)对所有 Unicode 字符进行编码的编码标准。
我们提到字符是为了简化字符集的定义。但是在Unicode中,我们使用码位的概念来指代由单个值表示的项。例如,在汉字符由U+6C49代码点标识。使用UTF-8,汉使用三个字节编码:0xE6、0xB1和0x89。为什么这很重要?因为在 GO 中,一个符文就是一个Unicode码位。
同时,我们提到 UTF-8 将字符编码成 1 到 4 个字节,因此,最多 32 位。这就是为什么在GO中,符文是int32的别名:
type rune = int32
关于 UTF-8,另一件要强调的事情是:有些人认为GO字符串总是 UTF-8,但这不是真的。让我们考虑下面的例子:
s := "hello"
我们将一个字符串字面值(一个字符串常量)赋给s。在GO中,源代码是用 UTF 8 编码的。因此,所有的字符串都使用 UTF-8 编码成一个字节序列。然而,字符串是任意字节的序列;它不一定基于 UTF-8。因此,当我们操作一个不是从字符串初始化的变量时(例如,从文件系统中读取),我们不能假定它使用 UTF-8 编码。
注意 golang.org/x ,一个为标准库提供扩展的库,包含使用 UTF-16 和 UTF-32 的包。
让我们回到hello的例子。我们有一个由五个字符组成的字符串:h、e、l、l和i。
这些简单的字符每个都用一个字节进行编码。这就是为什么得到s的长度会返回5:
s := "hello"
fmt.Println(len(s)) // 5
但是一个字符并不总是被编码成一个字节。回到汉字符,我们提到了UTF-8,这个字符被编码成三个字节。我们可以用下面的例子来验证这一点:
s := "汉"
fmt.Println(len(s)) // 3
这个例子打印的不是1,而是3。事实上,对字符串应用的len内置函数不会返回字符数;它返回字节数。
相反,我们可以从字节列表中创建一个字符串。我们提到过汉字符使用三个字节编码,即0xE6、0xB1和0x89:
s := string([]byte{0xE6, 0xB1, 0x89})
fmt.Printf("%s\n", s)
这里,我们构建一个由这三个字节组成的字符串。当我们打印字符串时,代码打印的不是三个字符,而是一个字符:汉。
总而言之:
-
字符集是一组字符,而编码描述了如何将字符集转换成二进制。
-
在 Go 中,一个字符串引用一个不可变的任意字节切片。
-
Go 源代码使用 UTF-8 编码。因此,所有字符串都是 UTF 8 字符串。但是因为一个字符串可以包含任意字节,如果它是从其他地方(不是源代码)获得的,就不能保证它是基于 UTF-8 编码的。
-
一个符文对应一个 Unicode 码点的概念,意思是用单个值表示的物品。
-
使用 UTF-8,一个 Unicode 码位可以编码成 1 到 4 个字节。
-
在 Go 中对一个字符串使用
len返回字节数,而不是符文数。
记住这些概念是必要的,因为在GO中,符文无处不在。让我们来看看这一知识的具体应用,它涉及一个与字符串迭代相关的常见错误。
5.2 #37:不准确的字符串迭代
对字符串进行迭代是开发者的常用操作。也许我们希望对字符串中的每个符文执行一次操作,或者实现一个自定义函数来搜索特定的子字符串。在这两种情况下,我们都必须迭代一个字符串的不同符文。但是很容易混淆迭代是如何工作的。
我们来看一个具体的例子。这里,我们要打印字符串中不同的符文及其对应的位置:
s := "hêllo" // ❶
for i := range s {
fmt.Printf("position %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
❶ 字符串字面值包含一个特殊的符文:ê。
我们使用range操作符对进行迭代,然后我们希望使用字符串中的索引打印每个符文。以下是输出结果:
position 0: h
position 1: Ã
position 3: l
position 4: l
position 5: o
len=6
这段代码没有做我们想要的事情。让我们强调三点:
-
第二个符文是输出中的
Ã而不是ê。 -
我们从位置 1 跳到位置 3:位置 2 是什么?
-
len返回 6 的计数,而s只包含 5 个符文。
让我们从最后一个观察开始。我们已经提到过len返回一个字符串中的字节数,而不是符文数。因为我们给s分配了一个字符串字面值,s是一个 UTF-8 字符串。同时,特殊字符ê不是用一个字节编码的;它需要 2 个字节。因此,调用len(s)会返回6。
计算一串符文的数量
如果我们想得到一个字符串中符文的个数,而不是字节数呢?我们如何做到这一点取决于编码。
在前面的例子中,因为我们给s分配了一个字符串,所以我们可以使用unicode/utf8包中的:
fmt.Println(utf8.RuneCountInString(s)) // 5
让我们回到迭代中来理解剩余的惊喜:
for i := range s {
fmt.Printf("position %d: %c\n", i, s[i])
}
我们必须认识到,在这个例子中,我们没有迭代每个符文;相反,我们迭代一个符文的每个起始索引,如图 5.1 所示。

图 5.1 打印s[i]打印索引i处每个字节的 UTF-8 表示。
打印s[i]不打印第i个符文;它打印索引i处字节的 UTF-8 表示。因此,我们印了hÃllo而不是hêllo。那么,如果我们想打印所有不同的符文,我们如何修复代码呢?有两个主要选项。
我们必须使用range操作符的值元素:
s := "hêllo"
for i, r := range s {
fmt.Printf("position %d: %c\n", i, r)
}
我们使用了r变量,而不是使用s[i]来打印符文。在上使用range循环,字符串返回两个变量,符文的起始索引和符文本身:
position 0: h
position 1: ê
position 3: l
position 4: l
position 5: o
另一种方法是将字符串转换成一片符文,并对其进行迭代:
s := "hêllo"
runes := []rune(s)
for i, r := range runes {
fmt.Printf("position %d: %c\n", i, r)
}
position 0: h
position 1: ê
position 2: l
position 3: l
position 4: o
在这里,我们使用[]rune(s)将s转换成一片符文。然后我们迭代这个切片,使用range操作符的值元素打印所有的符文。唯一的区别与位置有关:代码直接打印符文的索引,而不是打印符文字节序列的起始索引。
请注意,与前一个解决方案相比,这个解决方案引入了运行时开销。事实上,将一个字符串转换成一片符文需要分配一个额外的片并将字节转换成符文:一个O(n)的时间复杂度,n 是字符串中的字节数。因此,如果我们想迭代所有的符文,我们应该使用第一种解决方案。
但是,如果我们想用第一个选项访问一个字符串的第i个符文,我们没有访问符文索引的权限;相反,我们知道一个符文在字节序列中的起始索引。因此,在大多数情况下,我们应该倾向于第二种选择:
s := "hêllo"
r := []rune(s)[4]
fmt.Printf("%c\n", r) // o
这段代码打印第四个符文,首先将字符串转换成一个符文片。
访问特定符文的可能优化
如果一个字符串由单字节的符文组成,那么一个优化是可能的:例如,如果字符串包含字母A到Z和a到z。我们可以通过使用s[i]直接访问字节来访问第i个符文,而不用将整个字符串转换成一片符文:
s := "hello"
fmt.Printf("%c\n", rune(s[4])) // o
总之,如果我们想要迭代一个字符串的符文,我们可以直接在字符串上使用range循环。但是我们必须记住,索引并不对应于符文索引,而是对应于符文字节序列的起始索引。因为一个符文可以由多个字节组成,所以如果我们要访问符文本身,应该使用range的值变量,而不是字符串中的索引。同时,如果我们对得到一个字符串的第i个符文感兴趣,我们应该在大多数情况下将该字符串转换成一片符文。
在下一节中,我们来看看在和strings包中使用trim函数时常见的混淆来源。
5.3 #38:误用trim函数
GO开发者在使用strings包时的一个常见错误是将的TrimRight和TrimSuffix混在一起。这两个函数的目的相似,很容易混淆。让我们来看看。
在下面的例子中,我们使用TrimRight。这段代码的输出应该是什么?
fmt.Println(strings.TrimRight("123oxo", "xo"))
答案是123。这是你所期望的吗?如果没有,你可能期待的是TrimSuffix的结果。让我们回顾一下这两个函数。
移除给定集合中包含的所有尾随符文。在我们的例子中,我们作为一个集合xo传递,它包含两个符文:x和o。图 5.2 显示了逻辑。

图 5.2 TrimRight向后迭代,直到找到一个不属于集合的符文。
在每个符文上向后迭代。如果某个符文是所提供符文的一部分,该函数会将其移除。如果没有,函数停止迭代并返回剩余的字符串。这就是我们的例子返回123的原因。
另一方面,TrimSuffix返回一个没有提供尾随后缀的字符串:
fmt.Println(strings.TrimSuffix("123oxo", "xo"))
因为123oxo以xo结尾,所以这段代码打印123o。此外,删除尾部后缀不是一个重复的操作,所以TrimSuffix("123xoxo", "xo")返回123xo。
对于带有TrimLeft和TrimPrefix的字符串的左侧,原理是相同的:
fmt.Println(strings.TrimLeft("oxo123", "ox")) // 123
fmt.Println(strings.TrimPrefix("oxo123", "ox")) /// o123
strings.TrimLeft移除一组符文中的所有前导符文,并因此打印123。TrimPrefix删除提供的前导前缀,打印o123。
与这个主题相关的最后一个注意事项:Trim在一个字符串上同时应用TrimLeft和TrimRight。因此,它删除了集合中包含的所有前导和尾随符文:
fmt.Println(strings.Trim("oxo123oxo", "ox")) // 123
总之,我们必须确保理解TrimRight / TrimLeft和TrimSuffix / TrimPrefix之间的区别:
-
TrimRight/TrimLeft移除一组中的尾随/前导符文。 -
TrimSuffix/TrimPrefix删除给定的后缀/前缀。
在下一节中,我们将深入研究字符串连接。
5.4 #39:优化不足的字符串连接
当谈到连接字符串时,Go 中有两种主要的方法,其中一种在某些情况下效率很低。让我们检查这个主题,以了解我们应该支持哪个选项以及何时支持。
让我们编写一个concat函数,使用+=操作符连接一个片的所有字符串元素:
func concat(values []string) string {
s := ""
for _, value := range values {
s += value
}
return s
}
在每次迭代中,+=操作符将s和value字符串连接起来。乍一看,这个函数可能不会出错。但是在这个实现中,我们忘记了字符串的一个核心特征:它的不变性。所以每次迭代不更新s;它会在内存中重新分配一个新字符串,这会显著影响该函数的性能。
幸运的是,有一个解决这个问题的方法,使用strings包和Builder结构:
func concat(values []string) string {
sb := strings.Builder{} // ❶
for _, value := range values {
_, _ = sb.WriteString(value) // ❷
}
return sb.String() // ❸
}
❶ 创建了strings.Builder
❷ 追加了一个字符串
❸ 返回结果字符串
首先,我们使用的零值创建了一个strings.Builder结构。在每一次迭代中,我们通过调用WriteString方法来构造结果字符串,这个方法让将value的内容附加到它的内部缓冲区中,从而最小化内存复制。
注意WriteString返回一个错误作为第二个输出,但是我们故意忽略它。事实上,这个方法永远不会返回非零错误。那么这个方法返回一个错误作为其签名的一部分的目的是什么呢?strings.Builder实现的io.StringWriter接口,其中包含一个单独的方法:WriteString(s string) (n int, err error)。因此,为了符合这个接口,WriteString必须返回一个错误。
注意,我们将讨论错误#53“不处理错误”中惯用的忽略错误
使用strings.Builder,我们还可以追加
-
字节切片使用
Write -
单字节使用
WriteByte -
单个符文使用
WriteRune
在内部,strings.Builder保存一个字节切片。对WriteString的每次调用都会导致对该片上的append的调用。有两个影响。首先,这个结构不应该同时使用,因为对append的调用会导致竞争条件。第二个影响是我们在错误#21“低效的片初始化”中看到的:如果片的未来长度是已知的,我们应该预分配它。为此,strings.Builder公开了一个方法Grow(n int)来保证另外的n字节的空间。
让我们通过用总字节数调用Grow来编写另一个版本的concat方法:
func concat(values []string) string {
total := 0
for i := 0; i < len(values); i++ { // ❶
total += len(values[i])
}
sb := strings.Builder{}
sb.Grow(total) // ❷
for _, value := range values {
_, _ = sb.WriteString(value)
}
return sb.String()
}
❶ 遍历每个字符串来计算总字节数
❷ 使用这个总数调用sb.Grow
在迭代之前,我们计算最终字符串包含的总字节数,并将结果赋给total。注意,我们对符文的数量不感兴趣,而是对字节的数量感兴趣,所以我们使用了len函数。然后我们调用Grow来保证在遍历字符串之前有total字节的空间。
让我们运行一个基准来比较三个版本(v1 使用+=;v2 使用strings.Builder{}无预分配;和 v3 使用带有预分配的strings.Builder{})。输入片段包含 1,000 个字符串,每个字符串包含 1,000 个字节:
BenchmarkConcatV1-4 16 72291485 ns/op
BenchmarkConcatV2-4 1188 878962 ns/op
BenchmarkConcatV3-4 5922 190340 ns/op
正如我们所见,最新版本是迄今为止效率最高的:比 v1 快 99%,比 v2 快 78%。我们可能会问自己,在输入片上迭代两次如何能使代码更快?答案在于错误#21,“低效的片初始化”:如果一个片没有被分配给给定的长度或容量,该片将在每次变满时继续增长,导致额外的分配和拷贝。因此,在这种情况下,迭代两次是最有效的选择。
strings.Builder是连接字符串列表的推荐解决方案。通常,这种解决方案应该在循环中使用。事实上,如果我们只需要连接几个字符串(比如一个名字和一个姓氏),不推荐使用strings.Builder,因为这样做会使代码的可读性比使用+=操作符或fmt.Sprintf差一些。
一般来说,我们可以记住,从性能角度来看,从我们必须连接超过五个字符串的那一刻起,strings.Builder解决方案就比快。尽管这个确切的数字取决于许多因素,如连接字符串的大小和机器,但这可以作为帮助我们决定何时选择一个解决方案的经验法则。同样,我们不应该忘记,如果未来字符串的字节数是预先知道的,我们应该使用Grow方法来预分配内部字节切片。
接下来,我们将讨论bytes包和为什么它可以防止无用的字符串转换。
5.5 #40:无用的字符串转换
当选择使用字符串还是使用[]byte时,为了方便起见,大多数程序员倾向于使用字符串。但是大多数 I/O 实际上都是用[]byte完成的。比如io.Reader、io.Writer、io.ReadAll用的是[]byte,不是字符串。因此,处理字符串意味着额外的转换,尽管bytes包包含许多与strings包相同的操作。
让我们看一个我们不该做什么的例子。我们将实现一个getBytes函数,它将一个io.Reader作为输入,从中读取,并调用一个sanitize函数。清理将通过修剪所有前导和尾随空格来完成。这里是getBytes的骨架:
func getBytes(reader io.Reader) ([]byte, error) {
b, err := io.ReadAll(reader) // ❶
if err != nil {
return nil, err
}
// Call sanitize
}
❶ b是一个[]byte。
我们调用ReadAll并将字节切片分配给b。怎样才能实现sanitize函数?一种选择可能是使用strings包创建一个sanitize(string) string函数:
func sanitize(s string) string {
return strings.TrimSpace(s)
}
现在,回到getBytes:当我们操作一个[]byte时,在调用sanitize之前,我们必须首先将它转换成一个字符串。然后我们必须将结果转换回一个[]byte,因为getBytes返回一个字节切片:
return []byte(sanitize(string(b))), nil
这个实现有什么问题?我们要付出额外的代价,先把一个[]byte转换成一个字符串,再把一个字符串转换成一个[]byte。就内存而言,每一次转换都需要额外的分配。事实上,即使一个字符串由一个[]byte支持,将一个[]byte转换成一个字符串也需要一个字节切片的副本。这意味着一个新的内存分配和所有字节的副本。
字符串不变性
我们可以使用下面的代码来测试从[]byte创建一个字符串导致一个副本的事实:
b := []byte{'a', 'b', 'c'}
s := string(b)
b[1] = 'x'
fmt.Println(s)
运行这段代码会打印出abc,而不是axc。的确,在GO中,一个字符串是不可变的。
那么,应该如何实现sanitize函数呢?我们应该操作一个字节切片,而不是接受和返回一个字符串:
func sanitize(b []byte) []byte {
return bytes.TrimSpace(b)
}
bytes包还有一个函数来修剪所有的前导和尾随空白。然后,调用sanitize函数不需要任何额外的转换:
return sanitize(b), nil
正如我们提到的,大多数 I/O 是通过[]byte完成的,而不是字符串。当我们想知道我们应该使用字符串还是[]byte时,让我们回忆一下使用[]byte并不一定不方便。实际上,包中所有导出的函数在包中也有替代:Split、Count、Contains、Index等等。因此,无论我们是否正在进行 I/O,我们都应该首先检查我们是否可以使用字节而不是字符串来实现整个工作流,并避免额外转换的代价。
本章的最后一节讨论了子串操作有时会导致内存泄漏的情况。
5.6 #41:子字符串和内存泄漏
在错误 26“切片和内存泄漏”中,我们看到了切片或数组如何导致内存泄漏。这个原则也适用于字符串和子字符串操作。首先,我们将看到如何在 Go 中处理子字符串以防止内存泄漏。
要提取字符串的子集,我们可以使用以下语法:
s1 := "Hello, World!"
s2 := s1[:5] // Hello
s2被构造为s1的子串。这个例子从前五个字节创建一个字符串,而不是前五个符文。因此,我们不应该在用多字节编码的符文中使用这种语法。相反,我们应该首先将输入字符串转换成[]rune类型:
s1 := "Hêllo, World!"
s2 := string([]rune(s1)[:5]) // Hêllo
既然我们已经对子串操作有了新的认识,让我们来看一个具体的问题来说明可能的内存泄漏。
我们将接收字符串形式的日志消息。每个日志将首先用一个通用的唯一标识符(UUID;36 个字符)后跟消息本身。我们希望将这些 UUID 存储在内存中:例如,保存最新的n个 UUID 的缓存。我们还应该注意到,这些日志消息可能非常大(高达数KB)。下面是我们的实现:
func (s store) handleLog(log string) error {
if len(log) < 36 {
return errors.New("log is not correctly formatted")
}
uuid := log[:36]
s.store(uuid)
// Do something
}
为了提取 UUID,我们使用带有log[:36]的子串操作,因为我们知道 UUID 编码为 36 字节。然后我们将这个uuid变量传递给store方法,后者会将它存储在内存中。这个解决方案有问题吗?是的,它是。
在进行子串操作时,Go 规范并没有指定结果字符串和子串操作中涉及的字符串是否应该共享相同的数据。然而,标准的 Go 编译器确实让它们共享相同的后备数组,这可能是内存和性能方面的最佳解决方案,因为它防止了新的分配和复制。
我们提到过,日志消息可能会非常多。log[:36]将创建一个引用相同后备数组的新字符串。因此,我们存储在内存中的每个uuid字符串将不仅包含 36 个字节,还包含初始log字符串中的字节数:潜在地,数KB。
我们如何解决这个问题?通过制作子字符串的深度副本,使uuid的内部字节切片引用一个只有 36 个字节的新后备数组:
func (s store) handleLog(log string) error {
if len(log) < 36 {
return errors.New("log is not correctly formatted")
}
uuid := string([]byte(log[:36])) // ❶
s.store(uuid)
// Do something
}
❶ 执行一个[]byte,然后是一个字符串转换
复制是通过首先将子串转换成[]byte,然后再转换成字符串来执行的。通过这样做,我们防止了内存泄漏的发生。uuid字符串由一个仅包含 36 个字节的数组支持。
注意,一些 ide 或 linters 可能警告说string([]byte(s))转换是不必要的。例如,Go JetBrains IDE GoLand 会对冗余的类型转换发出警告。从我们把一个字符串转换成一个字符串的意义上来说这是真的,但是这个操作有实际的效果。如前所述,它防止新字符串被与uuid相同的数组支持。我们需要意识到 ide 或 linters 发出的警告有时可能是不准确的。
注意因为字符串主要是一个指针,所以调用函数来传递字符串不会导致字节的深度复制。复制的字符串仍将引用相同的支持数组。
从 Go 1.18 开始,标准库还包括一个带有strings.Clone的解决方案,它返回一个字符串的新副本:
uuid := strings.Clone(log[:36])
调用strings.Clone会将log[:36]的副本放入新的分配中,从而防止内存泄漏。
在 Go 中使用子串操作时,我们需要记住两件事。第一,提供的区间是基于字节数,而不是符文数。其次,子字符串操作可能导致内存泄漏,因为结果子字符串将与初始字符串共享相同的支持数组。防止这种情况发生的解决方案是手动执行字符串复制或使用 Go 1.18 中的strings.Clone。
总结
-
理解符文对应于 Unicode 码位的概念,并且它可以由多个字节组成,这应该是 Go 开发者的核心知识的一部分,以便准确地处理字符串。
-
用
range操作符在字符串上迭代,在符文上迭代的索引对应于符文字节序列的起始索引。要访问特定的符文索引(如第三个符文),将字符串转换为[]rune。 -
strings.TrimRight/strings.TrimLeft删除给定集合中包含的所有尾随/前导符文,而strings.TrimSuffix/strings.TrimPrefix返回一个没有提供后缀/前缀的字符串。 -
应该使用
strings.Builder来连接字符串列表,以防止在每次迭代中分配新的字符串。 -
记住
bytes包提供与strings包相同的操作有助于避免额外的字节/字符串转换。 -
使用副本而不是子字符串可以防止内存泄漏,因为子字符串操作返回的字符串将由相同的字节数组支持。
六、函数和方法
本章涵盖
- 何时使用值型或指针型接收器
- 何时使用命名结果参数及其潜在的副作用
- 返回
nil接收器时避免常见错误 - 为什么使用接受文件名的函数不是最佳实践
- 处理
defer参数
一个函数将一系列语句包装成一个单元,可以在其他地方调用。它可以接受一些输入并产生一些输出。另一方面,方法是附加到给定类型的函数。附加类型称为接收器接收器,可以是指针或值。本章一开始我们讨论如何选择一种接收机类型,因为这通常是一个争论的来源。然后我们讨论命名参数,何时使用它们,以及为什么它们有时会导致错误。我们还讨论了设计函数或返回特定值(如nil接收器)时的常见错误。
6.1 #42:不知道使用哪种类型的接收器
为一个方法选择一个接收器类型并不总是那么简单。什么时候我们应该使用值接收器?我们什么时候应该使用指针接收器?在这一节中,我们来看看做出正确决定的条件。
在第 12 章,我们将彻底讨论值和指针。因此,这一节将只涉及性能方面的皮毛。此外,在许多情况下,使用值或指针接收器不应该由性能决定,而是由我们将讨论的其他条件决定。但首先,让我们回忆一下接收器是如何工作的。
在 Go 中,我们可以给一个方法附加一个值或者一个指针接收器。使用值接收器,Go 复制该值并将其传递给方法。对对象的任何更改都保持在方法的本地。原始对象保持不变。
作为一个示例,下面的示例改变了一个值接收器:
type customer struct {
balance float64
}
func (c customer) add(v float64) { // ❶
c.balance += v
}
func main() {
c := customer{balance: 100.}
c.add(50.)
fmt.Printf("balance: %.2f\n", c.balance) // ❷
}
❶ 值接收器
❷ 客户余额保持不变。
因为我们使用了一个值接收器,所以在add方法中增加余额不会改变原始customer结构的balance字段:
100.00
另一方面,使用指针接收器,Go 将对象的地址传递给方法。本质上,它仍然是一个副本,但我们只复制了一个指针,而不是对象本身(通过引用传递在 Go 中是不存在的)。对接收器的任何修改都是在原始对象上完成的。下面是同样的例子,但是现在接收器是一个指针:
type customer struct {
balance float64
}
func (c *customer) add(operation float64) { // ❶
c.balance += operation
}
func main() {
c := customer{balance: 100.0}
c.add(50.0)
fmt.Printf("balance: %.2f\n", c.balance) // ❷
}
❶ 指针接收器
❷ 客户余额被更新。
因为我们使用指针接收器,增加余额会改变原始customer结构的balance字段:
150.00
在值接收器和指针接收器之间做出选择并不总是那么简单。让我们讨论一些条件来帮助我们选择。
接收器必须是一个指针
- 如果方法需要改变接收器。如果接收器是一个片并且一个方法需要附加元素,这个规则也是有效的:
type slice []int
func (s *slice) add(element int) {
*s = append(*s, element)
}
- 如果方法接收器包含一个不能复制的字段:例如,
sync包的类型部分(我们将在错误#74“复制同步类型”中讨论这一点)。
接收器应该是一个指针
- 如果接收器是一个大物体。使用指针可以使调用更有效,因为这样做可以防止进行大范围的复制。当你不确定多大才算大的时候,标杆管理可以是解决方案;很难给出一个具体的尺寸,因为它取决于很多因素。
接收器必须是一个值
-
如果我们必须强制一个接收器的不变性。
-
如果接收器是映射、函数或通道。否则,会发生编译错误。
接收器应该是一个值
-
如果接收器是一个不必改变的切片。
-
如果接收器是一个小数组或者结构,自然是一个没有可变字段的值类型,比如
time.Time。 -
如果接收器是基本型如
int、float64或string。
一个案例需要更多的讨论。假设我们设计了一个不同的customer结构。它的可变字段不直接是结构的一部分,而是在另一个结构中:
type customer struct {
data *data // ❶
}
type data struct {
balance float64
}
func (c customer) add(operation float64) { // ❷
c.data.balance += operation
}
func main() {
c := customer{data: &data{
balance: 100,
}}
c.add(50.)
fmt.Printf("balance: %.2f\n", c.data.balance)
}
❶ 余额不直接是客户结构的一部分,而是在指针字段引用的结构中。
❷ 使用值接受器
即使接收器是一个值,调用add最终也会改变实际余额:
150.00
在这种情况下,我们不需要接收器是一个指针来改变balance。然而,为了清楚起见,我们可能倾向于使用指针接收器来强调customer作为一个整体对象是可变的。
混合接收器类型
我们是否可以混合接收器类型,比如一个包含多个方法的结构,其中一些有指针接收器,另一些有值接收器?共识倾向于禁止它。不过标准库中也有一些反例,比如time.Time。
设计者希望强制要求一个time.Time结构是不可变的。因此,大多数方法,如After、IsZero和UTC,都有一个值接收器。但是为了符合现有的接口,如encoding.TextUnmarshaler,time.Time必须实现UnmarshalBinary([]byte) error方法,该方法在给定一个字节切片的情况下改变接收器。因此,这个方法有一个指针接收器。
因此,通常应避免混合接收器类型,但在 100%的情况下并不禁止。
我们现在应该很好地理解是使用值接收器还是指针接收器。当然,不可能面面俱到,因为总会有边缘情况,但本节的目标是提供涵盖大多数情况的指导。默认情况下,我们可以选择使用值接收器,除非有很好的理由不这样做。如果有疑问,我们应该使用指针接收器。
在下一节中,我们将讨论命名结果参数:它们是什么以及何时使用它们。
6.2 #43:从不使用命名结果参数
命名结果参数是 Go 中不常用的选项。这一节将讨论何时使用命名结果参数来使我们的 API 更加方便。但首先,让我们回忆一下它们是如何工作的。
当我们在函数或方法中返回参数时,我们可以给这些参数附加名称,并将其作为常规变量使用。当结果参数被命名时,它在函数/方法开始时被初始化为零值。有了命名的结果参数,我们还可以调用一个裸return语句(不带参数)。在这种情况下,结果参数的当前值被用作返回值。
下面是一个使用命名结果参数b的例子:
func f(a int) (b int) { // ❶
b = a
return // ❷
}
❶ 将int结果参数命名为b
❷ 返回b的当前值
在这个例子中,我们给结果参数附加了一个名称:b。当我们不带参数调用return时,它返回b的当前值。
何时建议我们使用命名结果参数?首先,让我们考虑下面的接口,它包含一个从给定地址获取坐标的方法:
type locator interface {
getCoordinates(address string) (float32, float32, error)
}
因为这个接口是未导出的,所以文档不是强制性的。光是看这段代码,你能猜出这两个float32结果是什么吗?也许它们是一个纬度和一个经度,但顺序是什么呢?根据惯例,纬度并不总是第一要素。因此,我们必须检查实现才能了解结果。
在这种情况下,我们可能应该使用命名的结果参数,以使代码更容易阅读:
type locator interface {
getCoordinates(address string) (lat, lng float32, err error)
}
有了这个新版本,我们可以通过查看接口来理解方法签名的含义:首先是纬度,其次是经度。
现在,让我们探讨一下在方法实现中何时使用命名结果参数的问题。我们还应该使用命名结果参数作为实现本身的一部分吗?
func (l loc) getCoordinates(address string) (
lat, lng float32, err error) {
// ...
}
在这种特定的情况下,拥有一个表达性的方法签名也可以帮助代码读者。因此,我们可能也想使用命名的结果参数。
注如果我们需要返回同一类型的多个结果,我们也可以考虑用有意义的字段名创建一个特别的结构。然而,这并不总是可能的:例如,当满足我们不能更新的现有接口时。
接下来,让我们考虑另一个函数签名,它允许我们在数据库中存储一个Customer类型:
func StoreCustomer(customer Customer) (err error) {
// ...
}
在这里,命名error参数err是没有帮助的,对读者没有帮助。在这种情况下,我们应该倾向于不使用命名结果参数。
因此,何时使用命名结果参数取决于上下文。在大多数情况下,如果不清楚使用它们是否会使我们的代码更易读,我们就不应该使用命名的结果参数。
还要注意,在某些上下文中,已经初始化的结果参数可能非常方便,即使它们不一定有助于可读性。下面这个例子提出的中的《高效 Go 编程》 (go.dev/doc/effective_go)是受io.ReadFull函数的启发:
func ReadFull(r io.Reader, buf []byte) (n int, err error) {
for len(buf) > 0 && err == nil {
var nr int
nr, err = r.Read(buf)
n += nr
buf = buf[nr:]
}
return
}
在这个例子中,命名结果参数并没有真正增加可读性。然而,因为n和err都被初始化为它们的零值,所以实现更短。另一方面,这个函数乍一看可能会让读者有点困惑。同样,这是一个找到正确平衡的问题。
关于裸返回(无参数返回)的一个注意事项:它们在短函数中被认为是可接受的;否则,它们会损害可读性,因为读者必须记住整个函数的输出。我们还应该在函数范围内保持一致,要么只使用裸返回,要么只使用带参数的返回。
那么关于命名结果参数的规则是什么呢?在大多数情况下,在接口定义的上下文中使用命名结果参数可以增加可读性,而不会导致任何副作用。但是在方法实现的上下文中没有严格的规则。在某些情况下,命名的结果参数也可以增加可读性:例如,如果两个参数具有相同的类型。在其他情况下,它们也可以方便地使用。因此,当有明显的好处时,我们应该谨慎地使用命名结果参数。
注意在错误#54“不处理延迟错误”中,我们将讨论在defer调用的上下文中使用命名结果参数的另一个用例。
此外,如果我们不够小心,使用命名结果参数可能会导致副作用和意想不到的后果,正如我们在下一节中看到的。
6.3 #44:命名结果参数的意外副作用
我们提到了为什么命名的结果参数在某些情况下是有用的。但是当这些结果参数被初始化为它们的零值时,如果我们不够小心,使用它们有时会导致微妙的错误。本节举例说明了这样一种情况。
让我们增强前面的示例,它是一个从给定地址返回纬度和经度的方法。因为我们返回两个float32,所以我们决定使用命名的结果参数来明确纬度和经度。这个函数将首先验证给定的地址,然后获取坐标。在此期间,它将对输入上下文执行检查,以确保它没有被取消,并且它的截止日期还没有过去。
请注意,我们将在错误#60“误解 Go 上下文”中深入探究 Go 中的上下文概念如果你不熟悉上下文,简而言之,上下文可以携带取消信号或截止日期。我们可以通过调用的Err方法并测试返回的错误是否不为零来检查这些错误。
下面是getCoordinates方法的新实现。你能找出这段代码的错误吗?
func (l loc) getCoordinates(ctx context.Context, address string) (
lat, lng float32, err error) {
isValid := l.validateAddress(address) // ❶
if !isValid {
return 0, 0, errors.New("invalid address")
}
if ctx.Err() != nil { // ❷
return 0, 0, err
}
// Get and return coordinates
}
❶ 验证了该地址
❷ 检查上下文是否被取消或截止日期是否已过
乍一看,这个错误可能并不明显。这里,if ctx.Err() != nil范围内返回的错误是err。但是我们没有给变量err赋值。它仍然被赋值给和error类型:nil的零值。因此,这段代码将总是返回一个nil错误。
此外,这段代码可以编译,因为err由于命名的结果参数而被初始化为零值。如果不附加名称,我们会得到以下编译错误:
Unresolved reference 'err'
一种可能的解决方法是将ctx.Err()分配给err,如下所示:
if err := ctx.Err(); err != nil {
return 0, 0, err
}
我们一直返回err,但是我们首先把它赋给ctx.Err()的结果。注意,本例中的err隐藏了结果变量。
使用裸返回语句
另一种选择是使用裸return语句:
if err = ctx.Err(); err != nil {
return
}
然而,这样做将打破规则,即我们不应该混合裸返回和带参数的返回。在这种情况下,我们可能应该坚持第一种选择。请记住,使用命名结果参数并不一定意味着使用裸返回。有时我们可以使用命名的结果参数来使签名更清晰。
我们通过强调命名结果参数在某些情况下可以提高代码的可读性(比如多次返回相同的类型),而在其他情况下非常方便,来结束这个讨论。但是我们必须记住,每个参数都被初始化为零值。正如我们在本节中看到的,这可能会导致微妙的错误,在阅读代码时并不总是容易发现。因此,在使用命名结果参数时,让我们保持谨慎,以避免潜在的副作用。
在下一节中,我们将讨论 Go 开发者在函数返回接口时会犯的一个常见错误。
6.4 #45:返回nil接收器
在本节中,我们将讨论返回接口的影响,以及为什么在某些情况下这样做会导致错误。这个错误可能是GO中最普遍的错误之一,因为它可能被认为是违反直觉的,至少在我们犯这个错误之前是这样。
让我们考虑下面的例子。我们将处理一个Customer结构并实现一个Validate方法来执行健全性检查。我们不想返回第一个错误,而是想返回一个错误列表。为此,我们将创建一个自定义错误类型来传达多个错误:
type MultiError struct {
errs []string
}
func (m *MultiError) Add(err error) { // ❶
m.errs = append(m.errs, err.Error())
}
func (m *MultiError) Error() string { // ❷
return strings.Join(m.errs, ";")
}
❶ 补充错误
❷ 实现了Error接口
MultiError满足error接口,因为实现了Error() string。同时,它公开了一个Add方法来附加一个错误。使用这个结构,我们可以以下面的方式实现一个Customer.Validate方法来检查客户的年龄和姓名。如果健全性检查正常,我们希望返回一个零错误:
func (c Customer) Validate() error {
var m *MultiError // ❶
if c.Age < 0 {
m = &MultiError{}
m.Add(errors.New("age is negative")) // ❷
}
if c.Name == "" {
if m == nil {
m = &MultiError{}
}
m.Add(errors.New("name is nil")) // ❸
}
return m
}
❶ 实例化一个空的*MultiError
❷ 如果年龄为负,会附加一个错误
❸ 如果名称为空,会追加一个错误
在该实现中,m被初始化为*MultiError的零值:因此为nil。当健全性检查失败时,如果需要,我们分配一个新的MultiError,然后附加一个错误。最后,我们返回m,它可以是一个空指针,也可以是一个指向MultiError结构的指针,这取决于检查。
现在,让我们通过使用有效的Customer运行一个案例来测试这个实现:
customer := Customer{Age: 33, Name: "John"}
if err := customer.Validate(); err != nil {
log.Fatalf("customer is invalid: %v", err)
}
以下是输出:
2021/05/08 13:47:28 customer is invalid: <nil>
这个结果可能相当令人惊讶。Customer有效,但err != nil条件为真,并记录打印的错误<nil>。那么,问题是什么?
在GO中,我们要知道一个指针接收器可以是nil。让我们通过创建一个虚拟类型并调用一个具有nil指针接收器的方法来进行实验:
type Foo struct{}
func (foo *Foo) Bar() string {
return "bar"
}
func main() {
var foo *Foo
fmt.Println(foo.Bar()) // ❶
}
❶ Foo是nil。
foo初始化为指针的零值:nil。但是这段代码可以编译,如果我们运行它,它会打印出bar。零指针是一个有效的接收器。
但是为什么会这样呢?在 Go 中,方法只是函数的语法糖,函数的第一个参数是接收器。因此,我们看到的Bar方法类似于这个函数:
func Bar(foo *Foo) string {
return "bar"
}
我们知道向函数传递一个空指针是有效的。因此,使用nil指针作为接收器也是有效的。
让我们回到最初的例子:
func (c Customer) Validate() error {
var m *MultiError
if c.Age < 0 {
// ...
}
if c.Name == "" {
// ...
}
return m
}
m被初始化为指针的零值:nil。然后,如果所有的检查都有效,那么提供给return语句的参数不是直接提供给nil,而是一个空指针。因为nil指针是一个有效的接收器,所以将结果转换成接口不会产生nil值。换句话说,Validate的调用者总是会得到一个非零的错误。
为了明确这一点,让我们记住在 Go 中,接口是一个调度包装器。这里,被包装对象是nil(MultiError指针),而包装器不是(error接口);参见图 6.1。

图 6.1error包装器不是nil。
因此,不管提供了什么样的Customer,这个函数的调用者总是会收到一个非零的错误。理解这种行为是必要的,因为这是一个普遍的错误。
那么,我们应该做些什么来修正这个例子呢?最简单的解决方案是仅当它不是nil时才返回m:
func (c Customer) Validate() error {
var m *MultiError
if c.Age < 0 {
// ...
}
if c.Name == "" {
// ...
}
if m != nil {
return m // ❶
}
return nil // ❷
}
❶ 只有当至少有一个错误时,才返回m
❷ 否则返回nil
在方法的最后,我们检查m是否不是nil。如果这是真的,我们返回m;否则,我们显式返回nil。因此,在有效的Customer的情况下,我们返回一个nil接口,而不是一个转换成非零接口的nil接收器。
我们在这一节已经看到,在 Go 中,允许有一个nil接收器,并且从nil指针转换的接口不是nil接口。因此,当我们必须返回一个接口时,我们不应该返回一个空指针,而应该直接返回一个空值。一般来说,拥有一个空指针并不是一个理想的状态,这意味着可能有 bug。
我们在本节中看到了一个错误示例,因为这是导致该错误的最常见情况。但是这个问题不仅仅与错误有关:任何使用指针接收器实现的接口都会发生这个问题。
下一节讨论使用文件名作为函数输入时的一个常见设计错误。
6.5 #46:使用文件名作为函数输入
当创建一个需要读取文件的新函数时,传递文件名被认为不是一个最佳实践,而且可能会产生负面影响,比如使单元测试更难编写。让我们深入研究这个问题,了解如何克服它。
假设我们想实现一个函数来计算文件中空行的数量。实现该函数的一种方法是接受一个文件名,并使用bufio.NewScanner扫描和检查每一行:
func countEmptyLinesInFile(filename string) (int, error) {
file, err := os.Open(filename) // ❶
if err != nil {
return 0, err
}
// Handle file closure
scanner := bufio.NewScanner(file) // ❷
for scanner.Scan() { // ❸
// ...
}
}
❶ 打开filename
❷ 从*os.File创建了一个扫描器,将输入按行拆分
❸ 迭代每一行
我们从文件名中打开一个文件。然后我们使用bufio.NewScanner扫描每一行(默认情况下,它会将输入拆分为每行)。
这个函数会做我们期望它做的事情。事实上,只要提供的文件名有效,我们就会从中读取并返回空行的数量。那么问题出在哪里?
假设我们想要实现单元测试来覆盖以下情况:
-
一个常见案例
-
一个空文件
-
只包含空行的文件
每个单元测试都需要在我们的 Go 项目中创建一个文件。函数越复杂,我们想要添加的案例就越多,我们要创建的文件也就越多。在某些情况下,我们可能需要创建几十个文件,这很快就会变得难以管理。
此外,该函数不可重用。例如,如果我们必须实现相同的逻辑,但是计算一个 HTTP 请求的空行数量,我们就必须复制主要的逻辑:
func countEmptyLinesInHTTPRequest(request http.Request) (int, error) {
scanner := bufio.NewScanner(request.Body)
// Copy the same logic
}
克服这些限制的一个方法可能是让函数接受一个*bufio.Scanner(由bufio.NewScanner返回的输出)。从我们创建scanner变量的那一刻起,这两个函数就有相同的逻辑,所以这种方法是可行的。但在GO中,惯用的方式是从读者的抽象出发。
让我们编写一个新版本的countEmptyLines函数,它接收一个io.Reader抽象:
func countEmptyLines(reader io.Reader) (int, error) { // ❶
scanner := bufio.NewScanner(reader) // ❷
for scanner.Scan() {
// ...
}
}
❶ 接受了一个io.Reader作为输入
❷ 从io.Reader创建了bufio.NewScanner。而不是*os.File
因为bufio.NewScanner接受一个io.Reader,所以我们可以直接传递reader变量。
这种方法的好处是什么?首先,这个函数抽象了数据源。是文件吗?一个 HTTP 请求?一个插座输入?对于函数来说不重要。因为*os.File和http.Request的Body字段实现了io.Reader,所以不管输入类型如何,我们都可以重用同一个函数。
另一个好处与测试有关。我们提到过为每个测试用例创建一个文件会很快变得很麻烦。既然countEmptyLines接受了一个io.Reader,我们可以通过从字符串创建一个io.Reader来实现单元测试:
func TestCountEmptyLines(t *testing.T) {
emptyLines, err := countEmptyLines(strings.NewReader( // ❶
`foo
bar
baz
`))
// Test logic
}
❶ 向strings.NewReader传递字符串
在这个测试中,我们直接从字符串中使用strings.NewReader创建一个io.Reader。因此,我们不必为每个测试用例创建一个文件。每个测试用例都是独立的,提高了测试的可读性和可维护性,因为我们不必打开另一个文件来查看内容。
在大多数情况下,接受一个文件名作为函数输入来读取文件应该被认为是一种代码味道(除了在特定的函数中,比如os.Open)。正如我们所看到的,这使得单元测试更加复杂,因为我们可能需要创建多个文件。它还降低了函数的可重用性(尽管并不是所有的函数都应该被重用)。使用io.Reader接口抽象数据源。不管输入是一个文件、一个字符串、一个 HTTP 请求还是一个 gRPC 请求,这个实现都可以被重用和容易地测试。
在本章的最后一节,让我们讨论一个与defer相关的常见错误:函数/方法参数和方法接收器是如何计算的。
6.6 #47:忽略如何求值延迟参数和接收器
我们在上一节提到过defer语句会延迟调用的执行,直到周围的函数返回。Go 开发人员的一个常见错误是不理解参数是如何计算的。我们将用两个小节来研究这个问题:一个与函数和方法参数有关,另一个与方法接收器有关。
6.6.1 参数求值
为了说明如何用defer对参数求值,我们来看一个具体的例子。一个函数需要调用两个函数foo和bar。同时,它必须处理关于执行的状态:
-
StatusSuccess如果foo和bar都没有返回错误 -
StatusErrorFoo如果foo返回错误 -
StatusErrorBar如果bar返回错误
我们将在多个操作中使用这个状态:例如,通知另一个 goroutine 和增加计数器。为了避免在每个return语句的之前重复这些调用,我们将使用defer。这是我们的第一个实现:
const (
StatusSuccess = "success"
StatusErrorFoo = "error_foo"
StatusErrorBar = "error_bar"
)
func f() error {
var status string
defer notify(status) // ❶
defer incrementCounter(status) // ❷
if err := foo(); err != nil {
status = StatusErrorFoo // ❸
return err
}
if err := bar(); err != nil {
status = StatusErrorBar // ❹
return err
}
status = StatusSuccess // ❺
return nil
}
❶ 延迟调用notify
❷ 延迟调用incrementCounter
❸ 将状态设置为StatusErrorFoo
❹ 将状态设置为StatusErrorBar
❺ 将状态设置为成功
首先我们声明一个status变量。然后我们使用defer将调用延迟到notify和incrementCounter。在这个函数中,根据执行路径,我们相应地更新status。
然而,如果我们尝试一下这个函数,我们会发现不管执行路径如何,notify和incrementCounter总是以相同的状态被调用:一个空字符串。这怎么可能?
我们需要理解一个defer函数中参数求值的关键之处:参数被立即求值,而不是在周围的函数返回之后。在我们的例子中,我们调用notify(status)和incrementCounter(status)作为defer函数。因此,一旦在我们使用defer的阶段f返回status的当前值,Go 将延迟这些调用的执行,从而传递一个空字符串。想继续用defer怎么解决这个问题?有两种主要的解决方案。
第一种解决方案是将一个字符串指针传递给defer函数的:
func f() error {
var status string
defer notify(&status) // ❶
defer incrementCounter(&status) // ❷
// The rest of the function is unchanged
if err := foo(); err != nil {
status = StatusErrorFoo
return err
}
if err := bar(); err != nil {
status = StatusErrorBar
return err
}
status = StatusSuccess
return nil
}
❶ 传递一个字符串指针给notify
❷ 将一个字符串指针传递给incrementCounter
我们根据情况不断更新status,但是现在notify和incrementCounter接收一个字符串指针。这种方法为什么有效?
使用defer立即计算参数:这里是status的地址。是的,status本身在整个函数中被修改,但是它的地址保持不变,不管赋值如何。因此,如果notify或incrementCounter使用字符串指针引用的值,它将按预期工作。但是这种解决方案需要改变两个函数的签名,这并不总是可能的。
还有另一个解决方案:调用一个闭包作为一个defer语句。提醒一下,闭包是一个匿名的函数值,它从自身外部引用变量。传递给defer函数的参数会被立即计算。但是我们必须知道由一个defer闭包引用的变量在闭包执行期间被求值(因此,当周围的函数返回时)。
这里有一个例子来说明defer闭包是如何工作的。一个闭包引用两个变量,一个作为函数参数,另一个作为其正文之外的变量:
func main() {
i := 0
j := 0
defer func(i int) { // ❶
fmt.Println(i, j) // ❷
}(i) // ❸
i++
j++
}
❶ 延迟调用接受整数作为输入的闭包
❷ i是函数输入,j是外部变量。
❸ 将i传给了闭包(立即求值)
这里,闭包使用了i和j变量。i是作为函数参数传递的,所以它会被立即计算。相反,j引用了闭包体外部的变量,所以在执行闭包时会对它进行求值。如果我们运行这个例子,它将打印出0 1。
因此,我们可以使用闭包来实现函数的新版本:
func f() error {
var status string
defer func() { // ❶
notify(status) // ❷
incrementCounter(status) // ❸
}()
// The rest of the function is unchanged
}
❶ 将闭包作为延迟函数调用
❷ 在闭包和引用状态内调用notify
❸ 在闭包和引用状态内调用incrementCounter
这里,我们将对notify和incrementCounter的调用包装在一个闭包中。这个闭包从变量体的外部引用了status变量。因此,一旦闭包被执行,status就被求值,而不是当我们调用defer时。这个解决方案也有效,并且不需要notify和incrementCounter改变它们的签名。
现在,在带有指针或值接收器的方法上使用defer怎么样?我们来看看这些问题。
6.6.2 指针和值接收器
在错误#42“不知道使用哪种类型的接收器”中,我们说接收器可以是值,也可以是指针。当我们在一个方法上使用defer时,与参数求值相关的相同逻辑也适用:接收器也被立即求值。让我们来了解这两种接收器类型的影响。
首先,这里有一个例子,它使用defer调用一个值接收器上的方法,但是后来改变了这个接收器:
func main() {
s := Struct{id: "foo"}
defer s.print() // ❶
s.id = "bar" // ❷
}
type Struct struct {
id string
}
func (s Struct) print() {
fmt.Println(s.id) // ❸
}
❶ 立即被求值。
❷ 更新s.id(不可见)
❸ "foo"
我们将调用延迟到print方法。与参数一样,调用defer会立即对接收器进行求值。因此,defer用一个包含等于foo的id字段的结构来延迟方法的执行。因此,这个例子打印了foo。
相反,如果指针是接收器,那么在调用defer之后接收器的潜在变化是可见的:
func main() {
s := &Struct{id: "foo"}
defer s.print() // ❶
s.id = "bar" // ❷
}
type Struct struct {
id string
}
func (s *Struct) print() {
fmt.Println(s.id) // ❸
}
❶ s是一个指针,所以它会被立即求值,但在执行defer方法时可能会引用另一个变量。
❷ 更新s.id(可见)
❸ "bar"
s接收器也会被立即求值。但是,调用方法会导致复制指针接收器。因此,对指针引用的结构所做的更改是可见的。这个例子打印了bar。
总之,当我们在函数或方法上调用defer时,调用的参数会立即被计算。如果我们后来想改变提供给defer的参数,我们可以使用指针或闭包。对于一个方法,接收器也立即被求值;因此,行为取决于接收器是值还是指针。
总结
-
应该根据诸如类型、是否必须改变、是否包含不能复制的字段以及对象有多大之类的因素来决定是使用值还是指针接收器。如有疑问,使用指针接收器。
-
使用命名结果参数是提高函数/方法可读性的有效方法,尤其是在多个结果参数具有相同类型的情况下。在某些情况下,这种方法也很方便,因为命名结果参数被初始化为零值。但是要小心潜在的副作用。
-
当返回一个接口时,小心不要返回一个空指针,而是一个显式的空值。否则,可能会导致意想不到的后果,因为调用方将收到一个非零值。
-
设计接收
io.Reader类型而不是文件名的函数提高了函数的可重用性,并使测试更容易。 -
传递一个指向
defer函数的指针和将一个调用封装在闭包里是两种可能的解决方案,可以克服参数和接收器的即时求值。
七、错误管理
本章涵盖
- 理解何时该恐慌
- 知道何时包装错误
- 从 Go 1.13 开始有效比较错误类型和错误值
- 习惯性地处理错误
- 了解如何忽略错误
- 处理
defer调用中的错误
错误管理是构建健壮且可观察的应用的一个基本方面,它应该和代码库的其他部分一样重要。在 Go 中,错误管理不像大多数编程语言那样依赖于传统的try/catch机制。相反,错误作为正常返回值返回。
本章将涵盖与错误相关的最常见的错误。
7.1 #48:恐慌
对于 Go 新手来说,对错误处理有些困惑是很常见的。在 Go 中,错误通常由返回和error类型作为最后一个参数的函数或方法来管理。但是一些开发人员可能会发现这种方法令人惊讶,并试图使用panic和recover在 Java 或 Python 等语言中重现异常处理。所以,让我们重温一下恐慌的概念,讨论一下什么时候恐慌是合适的,什么时候不恐慌。
在 Go 中,panic是一个停止普通流程的内置函数:
func main() {
fmt.Println("a")
panic("foo")
fmt.Println("b")
}
该代码打印a,然后在打印b之前停止:
a
panic: foo
goroutine 1 [running]:
main.main()
main.go:7 +0xb3
一旦恐慌被触发,它将继续在调用栈中向上运行,直到当前的 goroutine 返回或者panic被recover捕获:
func main() {
defer func() { // ❶
if r := recover(); r != nil {
fmt.Println("recover", r)
}
}()
f() // ❷
}
func f() {
fmt.Println("a")
panic("foo")
fmt.Println("b")
}
❶ 延迟闭包内调用recover
❷ 调用f,f恐慌。这种恐慌被前面的recover所抓住。
在f函数中,一旦panic被调用,就停止当前函数的执行,并向上调用栈:main。在main中,因为恐慌是由recover引起的,所以并不停止 goroutine:
a
recover foo
注意,调用recover()来捕获 goroutine 恐慌只在一个defer函数内部有用;否则,该函数将返回nil并且没有其他作用。这是因为defer函数也是在周围函数恐慌时执行的。
现在,让我们来解决这个问题:什么时候恐慌是合适的?在 Go 中,panic用来表示真正的异常情况,比如程序员出错。例如,如果我们查看net/http包,我们会注意到在WriteHeader方法中,有一个对checkWriteHeaderCode函数的调用,用于检查状态代码是否有效:
func checkWriteHeaderCode(code int) {
if code < 100 || code > 999 {
panic(fmt.Sprintf("invalid WriteHeader code %v", code))
}
}
如果状态码无效,此函数会出现混乱,这纯粹是程序员错误。
另一个基于程序员错误的例子可以在注册数据库驱动时的database/sql包中找到:
func Register(name string, driver driver.Driver) {
driversMu.Lock()
defer driversMu.Unlock()
if driver == nil {
panic("sql: Register driver is nil") // ❶
}
if _, dup := drivers[name]; dup {
panic("sql: Register called twice for driver " + name) // ❷
}
drivers[name] = driver
}
如果司机是零,❶就恐慌
如果司机已经注册,❷会感到恐慌
如果驱动程序是nil ( driver.Driver是一个接口)或者已经被注册,这个函数就会恐慌。这两种情况都会被认为是程序员的错误。此外,在大多数情况下(例如,使用最流行的 MySQL 驱动程序go-sql-driver/mysql【github.com/go-sql-driver/mysql】),Register通过调用一个init函数,这限制了错误处理。出于所有这些原因,设计者在出现错误的情况下使函数变得混乱。
另一个令人恐慌的用例是当我们的应用需要一个依赖项,但是无法初始化它。例如,假设我们公开一个服务来创建新的客户帐户。在某个阶段,该服务需要验证所提供的电子邮件地址。为了实现这一点,我们决定使用正则表达式。
在 Go 中,regexp包公开了两个函数来从字符串创建正则表达式:Compile和MustCompile。前者返回一个*regexp.Regexp和一个错误,而后者只返回一个*regexp.Regexp但在出错时会恐慌。在这种情况下,正则表达式是一个强制依赖项。事实上,如果我们不能编译它,我们将永远无法验证任何电子邮件输入。因此,我们可能倾向于使用MustCompile并在出错时惊慌失措。
GO中的恐慌应该少用。我们已经看到了两个突出的例子,一个是程序员出错的信号,另一个是我们的应用不能创建一个强制依赖。因此,存在导致我们停止应用的异常情况。在大多数其他情况下,错误管理应该通过一个函数来完成,该函数返回一个合适的类型作为最后一个返回参数。
现在让我们开始讨论错误。在下一节中,我们将看到何时包装一个错误。
7.2 #49:忽略何时包装错误
从 Go 1.13 开始,%w指令让我们可以方便地包装错误。但是一些开发人员可能不知道什么时候包装错误(或者不包装)。因此,让我们提醒自己什么是错误包装,以及何时使用它。
错误包装是将一个错误包装或打包到一个包装容器中,这样也可以得到错误源(见图 7.1)。通常,错误包装的两个主要用例如下:
-
向错误添加附加上下文
-
将错误标记为特定错误
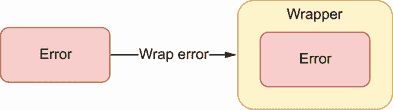
图 7.1 将错误包装在包装器中。
关于添加上下文,让我们考虑下面的例子。我们收到一个来自特定用户的访问数据库资源的请求,但是在查询过程中我们得到一个“权限被拒绝”的错误。出于调试目的,如果最终记录了错误,我们希望添加额外的上下文。在这种情况下,我们可以包装错误以表明用户是谁以及正在访问什么资源,如图 7.2 所示。
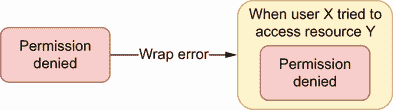
图 7.2 向“权限被拒绝”错误添加附加上下文
现在假设我们不添加上下文,而是要标记错误。例如,我们希望实现一个 HTTP 处理器,它检查在调用函数时收到的所有错误是否都属于Forbidden类型,这样我们就可以返回一个 403 状态代码。在这种情况下,我们可以将这个错误包装在Forbidden中(见图 7.3)。
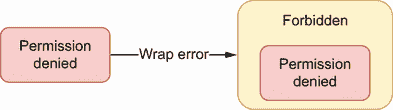
图 7.3 标记错误Forbidden
在这两种情况下,源错误仍然存在。因此,调用者也可以通过解开错误并检查错误源来处理错误。还要注意,有时我们希望将两种方法结合起来:添加上下文和标记错误。
现在我们已经阐明了包装错误的主要用例,让我们看看在 Go 中返回我们收到的错误的不同方法。我们将考虑下面这段代码,并探索if err != nil块中的不同选项:
func Foo() error {
err := bar()
if err != nil {
// ? // ❶
}
// ...
}
❶ 我们如何返回错误?
第一种选择是直接返回这个错误。如果我们不想标记错误,并且没有想要添加的有用上下文,这种方法很好:
if err != nil {
return err
}
图 7.4 显示我们返回了与bar相同的错误。

图 7.4 我们可以直接返回错误。
在 Go 1.13 之前,要包装一个错误,唯一不使用外部库的选项是创建一个自定义错误类型:
type BarError struct {
Err error
}
func (b BarError) Error() string {
return "bar failed:" + b.Err.Error()
}
然后,我们没有直接返回err,而是将错误包装成一个BarError(见图 7.5):
if err != nil {
return BarError{Err: err}
}

图 7.5 将错误包裹在BarError内部
这个选项的好处是它的灵活性。因为BarError是一个定制结构,如果需要,我们可以添加任何额外的上下文。然而,如果我们想要重复这个操作,被迫创建一个特定的错误类型会很快变得很麻烦。
为了克服这种情况,Go 1.13 引入了%w指令:
if err != nil {
return fmt.Errorf("bar failed: %w", err)
}
这段代码包装了源错误以添加额外的上下文,而不必创建另一种错误类型,如图 7.6 所示。
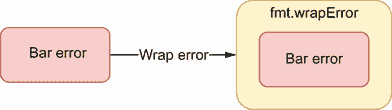
图 7.6 将一个错误包装成一个标准错误。
因为源错误仍然可用,所以客户端可以解开父错误,然后检查源错误是否是特定的类型或值(我们将在下面的部分中讨论这些问题)。
我们将讨论的最后一个选项是使用%v指令:
if err != nil {
return fmt.Errorf("bar failed: %v", err)
}
区别在于错误本身没有被包装。我们将其转换为另一个错误来添加上下文,源错误不再可用,如图 7.7 所示。

图 7.7 转换错误
关于问题来源的信息仍然可用。然而,调用者不能解开这个错误并检查来源是否是bar error。所以,从某种意义上来说,这个选项比%w更具限制性。既然%w指令已经发布,我们应该阻止吗?不一定。
包装错误使调用者可以使用源错误。因此,这意味着引入潜在耦合。例如,假设我们使用包装,Foo的调用者检查源错误是否为bar error。现在,如果我们改变我们的实现,并使用另一个函数将返回另一种类型的错误呢?它将破坏调用者进行的错误检查。
为了确保我们的客户不依赖于我们认为是实现细节的东西,返回的错误应该被转换,而不是包装。在这种情况下,使用%v而不是%w可能是正确的选择。
让我们回顾一下我们处理过的所有不同选项。
| 选项 | 额外上下文 | 标记错误 | 源错误可用 |
|---|---|---|---|
| 直接返回错误 | 不 | 不 | 是 |
| 自定义错误类型 | 可能(例如,如果错误类型包含字符串字段) | 是 | 可能(如果源错误是通过方法导出或访问的) |
fmt.Errorf和%w | 是 | 不 | 是 |
fmt.Errorf和%v | 是 | 不 | 不 |
总而言之,当处理一个错误时,我们可以决定包装它。包装是向错误添加额外的上下文和/或将错误标记为特定类型。如果我们需要标记一个错误,我们应该创建一个自定义的错误类型。然而,如果我们只是想添加额外的上下文,我们应该使用带有%w指令的fmt.Errorf,因为它不需要创建新的错误类型。然而,错误包装会产生潜在的耦合,因为它使调用者可以获得源错误。如果我们想防止它,我们不应该使用错误包装,而应该使用错误转换,例如,将fmt.Errorf与%v指令一起使用。
本节展示了如何用%w指令包装错误。但是一旦我们开始使用它,检查一个错误类型会有什么影响?
7.3 #50:检查错误类型不准确
上一节介绍了一种使用%w指令包装错误的可能方法。然而,当我们使用这种方法时,改变我们检查特定错误类型的方式也是必要的;否则,我们可能会不准确地处理错误。
我们来讨论一个具体的例子。我们将编写一个 HTTP 处理器,从一个 ID 返回交易金额。我们的处理器将解析请求以获取 ID,并从数据库(DB)中检索金额。我们的实现可能在两种情况下失败:
-
如果 ID 无效(字符串长度不是五个字符)
-
如果查询数据库失败
在前一种情况下,我们希望返回StatusBadRequest (400),而在后一种情况下,我们希望返回ServiceUnavailable (503)。为此,我们将创建一个transientError类型来标记错误是暂时的。父处理器将检查错误类型。如果错误是一个transientError,将返回一个 503 状态码;否则,它将返回 400 状态代码。
让我们首先关注错误类型定义和处理器将调用的函数:
type transientError struct {
err error
}
func (t transientError) Error() string { // ❶
return fmt.Sprintf("transient error: %v", t.err)
}
func getTransactionAmount(transactionID string) (float32, error) {
if len(transactionID) != 5 {
return 0, fmt.Errorf("id is invalid: %s",
transactionID) // ❷
}
amount, err := getTransactionAmountFromDB(transactionID)
if err != nil {
return 0, transientError{err: err} // ❸
}
return amount, nil
}
❶ 创建一个自定义的transientError
❷ 如果事务 ID 无效,将返回一个简单的错误
❸ 如果我们无法查询数据库,会返回一个transientError
如果标识符无效,使用fmt.Errorf返回一个错误。但是,如果从数据库获取交易金额失败,getTransactionAmount将错误封装到transientError类型中。
现在,让我们编写 HTTP 处理器来检查错误类型,以返回适当的 HTTP 状态代码:
func handler(w http.ResponseWriter, r *http.Request) {
transactionID := r.URL.Query().Get("transaction") // ❶
amount, err := getTransactionAmount(transactionID) // ❷
if err != nil {
switch err := err.(type) { // ❸
case transientError:
http.Error(w, err.Error(), http.StatusServiceUnavailable)
default:
http.Error(w, err.Error(), http.StatusBadRequest)
}
return
}
// Write response
}
❶ 提取交易 ID
❷ 调用包含所有逻辑的getTransactionAmount
❸ 检查错误类型,如果错误是暂时的,则返回 503;否则,一个 400
在错误类型上使用一个switch,我们返回适当的 HTTP 状态代码:在错误请求的情况下返回 400,在暂时错误的情况下返回 503。
这段代码完全有效。然而,让我们假设我们想要对getTransactionAmount进行一个小的重构。transientError将由getTransactionAmountFromDB而不是getTransactionAmount返回。getTransactionAmount现在使用%w指令包装该错误:
func getTransactionAmount(transactionID string) (float32, error) {
// Check transaction ID validity
amount, err := getTransactionAmountFromDB(transactionID)
if err != nil {
return 0, fmt.Errorf("failed to get transaction %s: %w",
transactionID, err) // ❶
}
return amount, nil
}
func getTransactionAmountFromDB(transactionID string) (float32, error) {
// ...
if err != nil {
return 0, transientError{err: err} // ❷
}
// ...
}
❶ 包装错误,而不是直接返回transientError
❷ 这个函数现在返回transientError。
如果我们运行这段代码,不管错误情况如何,它总是返回 400,所以永远不会遇到case Transient错误。我们如何解释这种行为?
重构之前,getTransactionAmount返回了transientError(见图 7.8)。重构后,transientError现在由getTransactionAmountFromDB返回(图 7.9)。

图 7.8 因为如果 DB 失败的话getTransactionAmount会返回一个transientError,所以情况是真的。
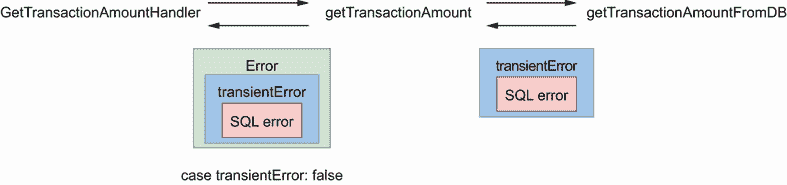
图 7.9 现在getTransactionAmount返回一个包装错误。于是,case transientError是假的。
getTransactionAmount返回的不是一个直接的transientError:它是一个错误包装transientError。因此case transientError现在为假。
正是为了这个目的,Go 1.13 提供了一个封装错误的指令,以及一种检查被封装的错误是否属于带有errors.As的某种类型的方法。这个函数递归地展开一个错误,如果链中的错误与预期的类型匹配,则返回true。
让我们使用errors.As重写调用者的实现:
func handler(w http.ResponseWriter, r *http.Request) {
// Get transaction ID
amount, err := getTransactionAmount(transactionID)
if err != nil {
if errors.As(err, &transientError{}) { // ❶
http.Error(w, err.Error(),
http.StatusServiceUnavailable) // ❷
} else {
http.Error(w, err.Error(),
http.StatusBadRequest) // ❸
}
return
}
// Write response
}
❶ 通过提供指向transientError的指针调用errors.As
❷ 如果错误是暂时的,返回 503
❸ 否则返回一个 400
在这个新版本中,我们去掉了switch案例类型,现在使用errors.As。这个函数要求第二个参数(目标错误)是一个指针。否则,该函数将会编译,但在运行时会恐慌。无论运行时错误是直接类型transientError还是错误包装transientError,errors.As都返回true;因此,处理器将返回 503 状态代码。
综上所述,如果我们依赖 Go 1.13 错误包装,我们必须使用errors.As来检查错误是否属于特定类型。这样,不管错误是由我们调用的函数直接返回,还是包装在错误中,errors.As将能够递归地打开我们的主错误,并查看其中一个错误是否是特定的类型。
我们刚刚看到了如何比较错误类型;现在是时候比较一个错误值了。
7.4 #51:检查错误值不准确
本节与上一节相似,但有标记错误(错误值)。首先,我们将定义一个哨兵错误传达了什么。然后,我们将会看到如何比较一个错误和一个值。
标记错误是定义为全局变量的错误:
import "errors"
var ErrFoo = errors.New("foo")
一般来说,约定是从Err开始,后面跟着错误类型:这里是ErrFoo。标记错误传达一个预期的错误。但是我们所说的预期错误是什么意思呢?让我们在 SQL 库的上下文中讨论它。
我们想设计一个Query方法,允许我们执行对数据库的查询。此方法返回一部分行。当没有找到行时,我们应该如何处理这种情况?我们有两个选择:
-
返回一个标记值:例如,一个
nil切片(想想strings.Index,如果一个子串不存在,它返回标记值-1)。 -
返回客户端可以检查的特定错误。
让我们采用第二种方法:如果没有找到行,我们的方法可以返回一个特定的错误。我们可以将这归类为一个预期的错误,因为传递一个不返回任何行的请求是被允许的。相反,像网络问题和连接轮询错误这样的情况是意外的错误。这并不意味着我们不想处理意外的错误;这意味着语义上,这些错误传达了不同的意思。
如果我们看一下标准库,我们可以找到许多标记错误的例子:
-
sql.ErrNoRows——当查询没有返回任何行时返回(这正是我们的情况) -
io.EOF——当没有更多输入可用时,由io.Reader返回
这是哨兵错误背后的一般原则。它们传达了客户希望检查的预期错误。因此,作为一般准则,
-
预期错误应设计为错误值(哨兵错误):
var ErrFoo = errors.New("foo")。 -
意外错误应设计为错误类型:
typeBarErrorstruct { ... },用BarError实现error接口。
让我们回到常见的错误。我们如何将错误与特定值进行比较?通过使用==操作符:
err := query()
if err != nil {
if err == sql.ErrNoRows { // ❶
// ...
} else {
// ...
}
}
❶ 根据sql.ErrNoRows变量检查错误。
这里,我们调用一个query函数,得到一个错误。使用==操作符检查错误是否为sql.ErrNoRows。
然而,正如我们在上一节中讨论的,也可以包装一个标记错误。如果使用fmt.Errorf和%w指令包装sql.ErrNoRows,err == sql.ErrNoRows将始终为假。
还是那句话,Go 1.13 提供了答案。我们已经看到了如何使用errors.As来检查一个类型的错误。有了错误值,我们可以用它的对应物: errors.Is。让我们重写前面的例子:
err := query()
if err != nil {
if errors.Is(err, sql.ErrNoRows) {
// ...
} else {
// ...
}
}
使用errors.Is而不是==操作符允许进行比较,即使使用%w包装了错误。
总之,如果我们在应用中使用带有%w指令和fmt.Errorf的错误包装,那么应该使用errors.Is而不是==来检查特定值的错误。因此,即使标记错误被包装,errors.Is也可以递归地展开它,并将链中的每个错误与提供的值进行比较。
现在是时候讨论错误处理最重要的一个方面了:不要两次处理一个错误。
7.5 #52:处理一个错误两次
多次处理一个错误是开发人员经常犯的错误,而不是 Go 中特有的错误。让我们来理解为什么这是一个问题,以及如何有效地处理错误。
为了说明问题,让我们编写一个GetRoute函数来获得从一对源到一对目标坐标的路线。让我们假设这个函数将调用一个未导出的getRoute函数,该函数包含计算最佳路线的业务逻辑。在调用getRoute之前,我们必须使用validateCoordinates验证源和目标坐标。我们还希望记录可能的错误。下面是一个可能的实现:
func GetRoute(srcLat, srcLng, dstLat, dstLng float32) (Route, error) {
err := validateCoordinates(srcLat, srcLng)
if err != nil {
log.Println("failed to validate source coordinates") // ❶
return Route{}, err
}
err = validateCoordinates(dstLat, dstLng)
if err != nil {
log.Println("failed to validate target coordinates") // ❶
return Route{}, err
}
return getRoute(srcLat, srcLng, dstLat, dstLng)
}
func validateCoordinates(lat, lng float32) error {
if lat > 90.0 || lat < -90.0 {
log.Printf("invalid latitude: %f", lat) // ❶
return fmt.Errorf("invalid latitude: %f", lat)
}
if lng > 180.0 || lng < -180.0 {
log.Printf("invalid longitude: %f", lng) // ❶
return fmt.Errorf("invalid longitude: %f", lng)
}
return nil
}
❶ 记录并返回错误
这个代码有什么问题?首先,在validateCoordinates中,在日志记录和返回的错误中重复invalid latitude或invalid longitude错误消息是很麻烦的。此外,例如,如果我们使用无效的纬度运行代码,它将记录以下行:
2021/06/01 20:35:12 invalid latitude: 200.000000
2021/06/01 20:35:12 failed to validate source coordinates
一个错误有两个日志行是一个问题。为什么?因为这使得调试更加困难。例如,如果同时多次调用此函数,日志中的两条消息可能不会一个接一个,从而使调试过程更加复杂。
根据经验,一个错误应该只处理一次。记录错误就是处理错误,返回错误也是如此。因此,我们应该记录或返回一个错误,而不是两者都记录。
让我们重写实现,只处理一次错误:
func GetRoute(srcLat, srcLng, dstLat, dstLng float32) (Route, error) {
err := validateCoordinates(srcLat, srcLng)
if err != nil {
return Route{}, err // ❶
}
err = validateCoordinates(dstLat, dstLng)
if err != nil {
return Route{}, err // ❶
}
return getRoute(srcLat, srcLng, dstLat, dstLng)
}
func validateCoordinates(lat, lng float32) error {
if lat > 90.0 || lat < -90.0 {
return fmt.Errorf("invalid latitude: %f", lat) // ❶
}
if lng > 180.0 || lng < -180.0 {
return fmt.Errorf("invalid longitude: %f", lng) // ❶
}
return nil
}
❶ 只返回一个错误
在这个版本中,通过直接返回,每个错误只被处理一次。然后,假设GetRoute的调用者正在处理可能的日志错误,在纬度无效的情况下,代码将输出以下消息:
2021/06/01 20:35:12 invalid latitude: 200.000000
这个新的 Go 版本代码是否完美?不完全是。例如,在纬度无效的情况下,第一个实现导致两个日志。尽管如此,我们知道哪个对validateCoordinates的调用失败了:要么是源坐标,要么是目标坐标。在这里,我们丢失了这些信息,所以我们需要向错误添加额外的上下文。
让我们使用 Go 1.13 错误包装重写我们代码的最新版本(我们省略了validateCoordinates,因为它保持不变):
func GetRoute(srcLat, srcLng, dstLat, dstLng float32) (Route, error) {
err := validateCoordinates(srcLat, srcLng)
if err != nil {
return Route{},
fmt.Errorf("failed to validate source coordinates: %w",
err) // ❶
}
err = validateCoordinates(dstLat, dstLng)
if err != nil {
return Route{},
fmt.Errorf("failed to validate target coordinates: %w",
err) // ❶
}
return getRoute(srcLat, srcLng, dstLat, dstLng)
}
❶ 返回一个包装错误
由validateCoordinates返回的每个错误现在都被包装起来,为错误提供额外的上下文:它是与源坐标相关还是与目标坐标相关。因此,如果我们运行这个新版本,在源纬度无效的情况下,调用者会记录以下内容:
2021/06/01 20:35:12 failed to validate source coordinates:
invalid latitude: 200.000000
在这个版本中,我们涵盖了所有不同的情况:一个日志,没有丢失任何有价值的信息。此外,每个错误只处理一次,这简化了我们的代码,例如,避免重复的错误消息。
处理一个错误应该只做一次。正如我们所见,记录错误就是处理错误。因此,我们应该记录或返回一个错误。通过这样做,我们简化了代码,并更好地了解了错误情况。使用错误包装是最方便的方法,因为它允许我们传播源错误并向错误添加上下文。
在下一节中,我们将看到在 Go 中忽略错误的适当方法。
7.6 #53:不处理错误
在某些情况下,我们可能想忽略函数返回的错误。在GO中应该只有一种方法可以做到这一点;我们来了解一下原因。
我们将考虑下面的例子,其中我们调用一个返回单个error参数的notify函数。我们对这个错误不感兴趣,所以我们故意忽略任何错误处理:
func f() {
// ...
notify() // ❶
}
func notify() error {
// ...
}
省略了❶错误处理。
因为我们想忽略这个错误,所以在这个例子中,我们只调用了notify,而没有将其输出赋给一个经典的err变量。从功能的角度来看,这段代码没有任何问题:它按照预期编译和运行。
然而,从可维护性的角度来看,代码可能会导致一些问题。让我们考虑一个新读者看它。这个读者注意到notify返回了一个错误,但是这个错误不是由父函数处理的。他们如何猜测处理错误是否是有意的呢?他们怎么知道是之前的开发者忘记处理了还是故意的?
由于这些原因,当我们想要忽略 Go 中的错误时,只有一种方法来编写它:
_ = notify()
我们不是将错误分配给变量,而是将其分配给空白标识符。就编译和运行时间而言,与第一段代码相比,这种方法没有任何改变。但是这个新版本明确表示我们对错误不感兴趣。
这样的代码也可以附带一条注释,但不要像下面这样提到忽略错误的注释:
// Ignore the error
_ = notify()
这个注释只是重复了代码所做的事情,应该避免。但是,写一个注释来说明错误被忽略的原因可能是个好主意,如下所示:
// At-most once delivery.
// Hence, it's accepted to miss some of them in case of errors.
_ = notify()
忽略 Go 中的错误应该是个例外。在许多情况下,我们仍然倾向于记录它们,即使是在低日志级别。但是如果我们确定一个错误能够并且应该被忽略,我们必须通过将它分配给空白标识符来明确地做到这一点。这样,未来的读者会理解我们故意忽略了这个错误。
本章的最后一节讨论了如何处理由defer函数返回的错误。
7.7 #54:不处理延迟错误
不处理defer语句中的错误是 Go 开发者经常犯的错误。我们来了解一下问题是什么,以及可能的解决方案。
在下面的例子中,我们将实现一个函数来查询数据库,以获得给定客户 ID 的余额。我们将使用database/sql和Query方法。
注意,我们不会在这里深入探究这个包是如何工作的;我们在错误#78“常见的 SQL 错误”中这样做
下面是一个可能的实现(我们关注查询本身,而不是结果的解析):
const query = "..."
func getBalance(db *sql.DB, clientID string) (
float32, error) {
rows, err := db.Query(query, clientID)
if err != nil {
return 0, err
}
defer rows.Close() // ❶
// Use rows
}
❶ 延迟调用rows.Close
rows是一种*sql.Rows类型。它实现了的Closer接口:
type Closer interface {
Close() error
}
这个接口包含一个返回错误的方法(我们也将在错误#79“不关闭瞬态资源”中看到这个主题)。我们在上一节中提到,错误应该总是被处理。但是在这种情况下,由defer调用返回的错误被忽略:
defer rows.Close()
如前一节所述,如果我们不想处理错误,我们应该使用空白标识符显式忽略它:
defer func() { _ = rows.Close() }()
这个版本更详细,但是从可维护性的角度来看更好,因为我们明确地标记了我们正在忽略这个错误。
但是在这种情况下,我们不应该盲目地忽略来自defer调用的所有错误,而是应该问自己这是否是最好的方法。在这种情况下,当调用Close()无法从池中释放 DB 连接时,会返回一个错误。因此,忽略这个错误可能不是我们想要做的。更好的选择是记录一条消息:
defer func() {
err := rows.Close()
if err != nil {
log.Printf("failed to close rows: %v", err)
}
}()
现在,如果关闭rows失败,代码会记录一条消息,这样我们就知道了。
如果我们不处理错误,而是将它传播给getBalance的调用者,这样他们就可以决定如何处理它,那该怎么办?
defer func() {
err := rows.Close()
if err != nil {
return err
}
}()
这个实现不能编译。的确,return语句是与匿名func()函数相关联的,而不是getBalance。
如果我们想将由getBalance返回的错误与在调用defer中捕获的错误联系起来,我们必须使用命名的结果参数。让我们写第一个版本:
func getBalance(db *sql.DB, clientID string) (
balance float32, err error) {
rows, err := db.Query(query, clientID)
if err != nil {
return 0, err
}
defer func() {
err = rows.Close() // ❶
}()
if rows.Next() {
err := rows.Scan(&balance)
if err != nil {
return 0, err
}
return balance, nil
}
// ...
}
❶ 将错误赋值给输出命名参数
一旦正确创建了rows变量,我们就在匿名函数中延迟对rows.Close()的调用。该函数将错误分配给err变量,该变量使用命名结果参数进行初始化。
这段代码看起来可能没问题,但是有一个问题。如果rows.Scan返回一个错误,无论如何都要执行rows.Close;但是因为这个调用覆盖了getBalance返回的错误,如果rows.Close成功返回,我们可能会返回一个空错误,而不是返回一个错误。换句话说,如果对db.Query的调用成功(函数的第一行),那么getBalance返回的错误将永远是rows.Close返回的错误,这不是我们想要的。
我们需要实现的逻辑并不简单:
-
如果
rows.Scan成功,- 如果
rows.Close成功,不返回错误。 - 如果
rows.Close失败,返回此错误。
- 如果
如果rows.Scan失败,逻辑会更复杂一点,因为我们可能需要处理两个错误:
-
如果
rows.Scan失败,- 如果
rows.Close成功,返回rows.Scan的错误。 - 如果
rows.Close失败。。。然后呢?
- 如果
如果rows.Scan和rows.Close都失败了,我们该怎么办?有几种选择。例如,我们可以返回一个传达两个错误的自定义错误。我们将实现的另一个选项是返回rows.Scan错误,但记录rows.Close错误。下面是匿名函数的最终实现:
defer func() {
closeErr := rows.Close() // ❶
if err != nil { // ❷
if closeErr != nil {
log.Printf("failed to close rows: %v", err)
}
return
}
err = closeErr // ❸
}()
❶ 将错误rows.Close赋值给另一个变量
❷ 如果错误已经不为nil,我们优先考虑它。
❸ 否则,我们还会走得更近。
rows.Close错误被分配给另一个变量:closeErr。在将其分配给err之前,我们检查err与nil是否不同。如果是这种情况,那么getBalance已经返回了一个错误,所以我们决定记录err并返回现有的错误。
如前所述,错误应该总是被处理。对于由defer调用返回的错误,我们最起码应该做的是显式忽略它们。如果这还不够,我们可以通过记录错误或将错误传播给调用者来直接处理错误,如本节所示。
总结
-
使用
panic是处理GO中错误的一个选项。但是,只有在不可恢复的情况下才应该谨慎使用它:例如,向程序员发出错误信号,或者当您未能加载强制依赖项时。 -
包装错误允许您标记错误和/或提供额外的上下文。但是,错误包装会产生潜在的耦合,因为它使调用者可以获得源错误。如果您想防止这种情况,请不要使用错误包装。
-
如果将 Go 1.13 错误包装与
%w指令和fmt.Errorf一起使用,必须分别使用errors.As或errors.Is将错误与类型或值进行比较。否则,如果要检查的返回错误被包装,检查将失败。 -
为了传达一个预期的错误,使用错误标记(错误值)。意外错误应该是特定的错误类型。
-
在大多数情况下,一个错误应该只处理一次。记录错误就是处理错误。因此,您必须在记录或返回错误之间做出选择。在许多情况下,错误包装是解决方案,因为它允许您为错误提供额外的上下文并返回错误源。
-
忽略错误,无论是在函数调用期间还是在
defer函数中,都应该使用空白标识符明确完成。否则,未来的读者可能会搞不清这是有意为之还是失手。 -
在很多情况下,你不应该忽略由
defer函数返回的错误。根据上下文,可以直接处理它,也可以将它传播给调用者。如果您想忽略它,请使用空白标识符。
八、并发基础
本章涵盖
- 了解并发和并行
- 为什么并发并不总是更快
- CPU 受限和 I/O 受限工作负载的影响
- 使用通道与互斥
- 理解数据竞争和竞争条件之间的差异
- 使用 Go 上下文
近几十年来,CPU 厂商不再只关注时钟速度。相反,现代 CPU 设计有多个内核和超线程(同一个物理内核上有多个逻辑内核)。因此,为了利用这些架构,并发性对于软件开发人员来说变得至关重要。尽管 Go 提供了简单的原语,但这并不意味着编写并发代码变得容易了。本章讨论与并发性相关的基本概念;第 9 章将关注实践。
8.1 #55:混淆并发性和并行性
即使经过多年的并发编程,开发者也不一定清楚并发和并行的区别。在深入研究特定于 Go 的主题之前,首先必须理解这些概念,这样我们就有了一个共同的词汇表。本节用一个真实的例子来说明:一家咖啡店。
在这家咖啡店,一名服务员负责接受订单,并使用一台咖啡机准备订单。顾客点餐,然后等待他们的咖啡(见图 8.1)。

图 8.1 一个简单的咖啡店
如果服务员很难服务所有的顾客,而咖啡店想加快整个过程,一个想法可能是有第二个服务员和第二个咖啡机。队列中的顾客会等待服务员过来(图 8.2)。
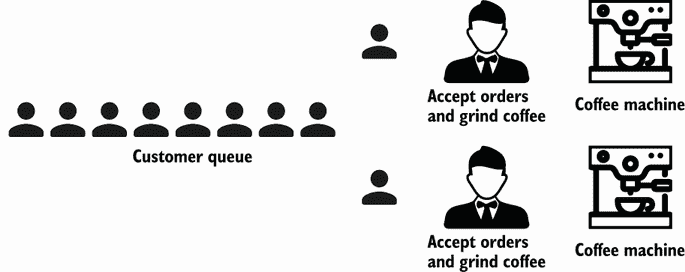
图 8.2 复制咖啡店里的一切
在这个新过程中,系统的每个部分都是独立的。咖啡店应该以两倍的速度为消费者服务。这是一个咖啡店的并行实现。
如果我们想扩大规模,我们可以一遍又一遍地复制服务员和咖啡机。然而,这不是唯一可能的咖啡店设计。另一种方法可能是将服务员的工作进行分工,让一个人负责接受订单,另一个人负责研磨咖啡豆,然后在一台机器中冲泡。此外,我们可以为等待订单的顾客引入另一个队列(想想星巴克),而不是阻塞顾客队列直到顾客得到服务(图 8.3)。
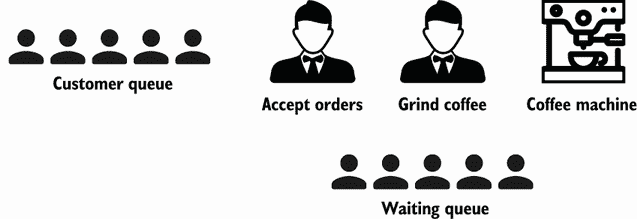
图 8.3 拆分服务员的角色
有了这个新的设计,我们不再把事情平行化。但是整体结构受到了影响:我们将一个给定的角色分成两个角色,并引入了另一个队列。与并行性不同,并行性是指一次多次做同一件事,并发性是关于结构的。
假设一个线程代表服务员接受订单,另一个线程代表咖啡机,我们引入了另一个线程来研磨咖啡豆。每个线程都是独立的,但必须与其他线程协调。在这里,接受订单的服务员线程必须传达要研磨哪些咖啡豆。同时,咖啡研磨线程必须与咖啡机线程连通。
如果我们想通过每小时服务更多的客户来提高吞吐量,该怎么办?因为磨咖啡豆比接受订单花费的时间更长,一个可能的改变是雇佣另一个磨咖啡的服务员(图 8.4)。

图 8.4 雇佣另一个服务员研磨咖啡豆
这里,结构保持不变。依然是三步走的设计:接受、研磨、冲泡咖啡。因此,在并发性方面没有变化。但是我们又回到了添加并行性,这里是针对一个特定的步骤:订单准备。
现在,让我们假设减慢整个过程的部分是咖啡机。使用单个咖啡机会引起咖啡研磨线程的争用,因为它们都在等待咖啡机线程可用。什么是解决方案?添加更多咖啡机线程(图 8.5)。
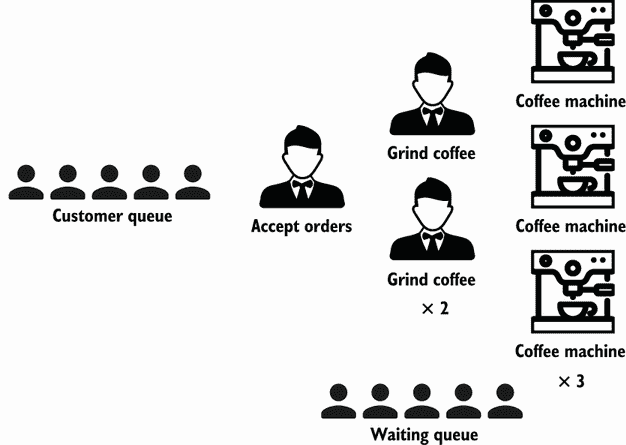
图 8.5 添加更多咖啡机
我们引入了更多的机器,而不是单一的咖啡机,从而提高了并行度。同样,结构没有改变。它仍然是一个三步设计。但是吞吐量应该会增加,因为咖啡研磨线程的争用程度应该会降低。
通过这种设计,我们可以注意到的重要之处:并发支持并行。事实上,并发性提供了一种结构来解决可能被并行化的部分的问题。
并发是指同时处理大量的事情。并行就是同时做很多事情。
——罗布·派克
总之,并发和并行是不同的。并发是关于结构的,我们可以通过引入独立并发线程可以处理的不同步骤,将顺序实现更改为并发实现。同时,并行是关于执行的,我们可以通过添加更多的并行线程在步骤级别使用它。理解这两个概念是成为一个熟练的 Go 开发者的基础。
下一节讨论一个普遍的错误:认为并发永远是正确的。
8.2 #56:认为并发总是更快
许多开发人员的一个误解是相信并发解决方案总是比顺序解决方案更快。这真是大错特错。解决方案的整体性能取决于许多因素,例如我们的结构的效率(并发性),哪些部分可以并行处理,以及计算单元之间的争用程度。本节提醒我们一些 Go 中并发的基础知识;然后我们将看到一个具体的例子,其中并发解决方案并不一定更快。
8.2.1 调度
线程是操作系统能够执行的最小处理单元。如果一个进程想要同时执行多个动作,它就会旋转多个线程。这些线程可以是
-
并发——两个或两个以上的线程可以在重叠的时间段内启动、运行、完成,就像上一节的服务员线程和咖啡机线程。
-
并行——同一任务可以一次执行多次,就像多个等待线程。
操作系统负责优化调度线程的进程,以便
-
所有线程都可以消耗 CPU 周期,而不会饥饿太长时间。
-
工作负载尽可能均匀地分布在不同的 CPU 内核中。
注意线程这个词在 CPU 级别上也可以有不同的含义。每个物理核心可以由多个逻辑核心组成(超线程的概念),一个逻辑核心也称为线程。在本节中,当我们使用字线程时,我们指的是处理单元,而不是逻辑核心。
一个 CPU 内核执行不同的线程。当它从一个线程切换到另一个线程时,它执行一个叫做上下文切换的操作。消耗 CPU 周期的活动线程处于执行状态,并转移到可运行状态,这意味着它已准备好执行,等待可用内核。上下文切换被认为是一种开销很大的操作,因为操作系统需要在切换之前保存线程的当前执行状态(如当前寄存器值)。
作为 Go 开发者,我们不能直接创建线程,但是可以创建 goroutines,可以认为是应用级线程。然而,操作系统线程是由操作系统根据上下文切换到 CPU 内核的,而 goroutine 是由 Go 运行时根据上下文切换到操作系统线程的。此外,与 OS 线程相比,goroutine 的内存占用更小:Go 1.4 中的 Goroutine 为 2 KB。一个操作系统线程依赖于操作系统,但是,例如,在 Linux/x86-32 上,默认大小是 2 MB(参见 mng.bz/DgMw )。尺寸越小,上下文切换越快。
注意上下文切换一个 goroutine 比一个线程快大约 80%到 90%,这取决于架构。
现在让我们讨论 Go scheduler 是如何工作的,以概述 goroutines 是如何处理的。在内部,Go 调度器使用以下术语(参见 mng.bz/N611 ):
-
G——goroutines
-
M——OS 线程(代表机器)
-
P——CPU 内核(代表处理器)
操作系统调度器将每个操作系统线程(M)分配给一个 CPU 内核§。然后,每个 goroutine (G)在一个 M 上运行。GOMAXPROCS变量定义了负责同时执行用户级代码的 M 的限制。但是,如果一个线程在系统调用(例如 I/O)中被阻塞,调度器可以加速更多的 M。
goroutine 的生命周期比 OS 线程更简单。它可以执行以下操作之一:
-
执行——goroutine 在 M 上调度并执行其指令。
-
可执行——goroutine 正在等待进入执行状态。
-
等待——goroutine 被停止,等待某些事情的完成,如系统调用或同步操作(如获取互斥)。
关于 Go 调度的实现还有最后一个需要理解的阶段:当一个 goroutine 被创建但还不能被执行时;例如,所有其他 M 都已经在执行 G 了,在这种情况下,Go 运行时会做什么呢?答案是排队。Go 运行时处理两种队列:每个 P 一个本地队列和所有 P 共享的全局队列。
图 8.6 显示了在一台四核机器上给定的调度情况,其中GOMAXPROCS等于4。这些部分是逻辑核心(Ps)、goroutines (Gs)、OS 线程(Ms)、本地队列和全局队列。
首先,我们可以看到五个 Ms,而GOMAXPROCS被设置为4。但是正如我们提到的,如果需要,Go 运行时可以创建比GOMAXPROCS值更多的 OS 线程。

图 8.6 在四核机器上执行的 Go 应用的当前状态示例。不处于执行状态的 Goroutines 要么是可运行的(等待执行),要么是等待的(等待阻塞操作)。
P0、P1 和 P3 目前正忙于执行 Go 运行时线程。但是 P2 现在很闲,因为 M3 离开了 P2,而且也没有戈鲁廷被处决。这不是一个好的情况,因为有六个可运行的 goroutines 正在等待执行,一些在全局队列中,一些在其他本地队列中。Go 运行时将如何处理这种情况?下面是用伪代码实现的调度(参见 mng.bz/lxY8 ):
runtime.schedule() {
// Only 1/61 of the time, check the global runnable queue for a G.
// If not found, check the local queue.
// If not found,
// Try to steal from other Ps.
// If not, check the global runnable queue.
// If not found, poll network.
}
每执行 61 次, Go 调度器将检查全局队列中的 goroutines 是否可用。如果没有,它将检查其本地队列。同时,如果全局和本地队列都是空的,Go 调度器可以从其他本地队列中提取 goroutines。调度中的这个原理叫做偷工,它允许一个未被充分利用的处理器主动寻找另一个处理器的 goroutines 并偷一些。
最后要提到的一件重要的事情是:在 Go 1.14 之前,调度器是合作的,这意味着只有在特定的阻塞情况下(例如,通道发送或接收、I/O、等待获取互斥锁),goroutine 才可以从线程的上下文中切换出来。从 Go 1.14 开始,Go 调度器现在是抢占式的:当一个 goroutine 运行了一段特定的时间(10 ms)时,它将被标记为可抢占的,并且可以在上下文中关闭,由另一个 goroutine 替换。这允许长时间运行的作业被强制共享 CPU 时间。
现在我们已经理解了 Go 中调度的基本原理,让我们看一个具体的例子:以并行方式实现归并排序。
8.2.2 并行归并排序
首先,我们简单回顾一下归并排序算法是如何工作的。然后我们将实现一个并行版本。请注意,我们的目标不是实现最有效的版本,而是支持一个具体的示例,展示为什么并发并不总是更快。
归并排序算法的工作原理是将一个列表重复分成两个子列表,直到每个子列表包含一个元素,然后合并这些子列表,这样结果就是一个排序后的列表(见图 8.7)。每个分割操作将列表分割成两个子列表,而合并操作将两个子列表合并成一个排序列表。

图 8.7 应用归并排序算法重复地将每个列表分成两个子列表。然后,该算法使用合并操作,从而对结果列表进行排序。
下面是该算法的顺序实现。我们没有包括所有的代码,因为这不是本节的重点:
func sequentialMergesort(s []int) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
sequentialMergesort(s[:middle]) // ❶
sequentialMergesort(s[middle:]) // ❷
merge(s, middle) // ❸
}
func merge(s []int, middle int) {
// ...
}
❶ 前半部分
❷ 后半部分
❸ 合并了两半
这个算法有一个结构,使它对并发开放。事实上,由于每个sequentialMergesort操作都处理一组不需要完全复制的独立数据(这里是使用切片的底层数组的独立视图),我们可以通过在不同的 goroutine 中加速每个sequentialMergesort操作,在 CPU 内核之间分配这个工作负载。让我们编写第一个并行实现:
func parallelMergesortV1(s []int) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
var wg sync.WaitGroup
wg.Add(2)
go func() { // ❶
defer wg.Done()
parallelMergesortV1(s[:middle])
}()
go func() { // ❷
defer wg.Done()
parallelMergesortV1(s[middle:])
}()
wg.Wait()
merge(s, middle) // ❸
}
❶ 使用 goroutine 加快前半部分
❷ 使用 goroutine 加快后半部分
❸ 合并了两半
在这个版本中,工作负载的每一半都在一个单独的 goroutine 中处理。父 goroutine 通过使用sync.WaitGroup来等待两个部分。因此,我们在合并操作之前调用Wait方法。
注意,如果你还不熟悉sync.WaitGroup,我们将在错误#71“误用 sync.WaitGroup”中更详细地了解它。简而言之,它允许我们等待n操作完成:通常是 goroutines,就像前面的例子一样。
我们现在有了归并排序算法的并行版本。因此,如果我们运行一个基准来比较这个版本和顺序版本,并行版本应该更快,对吗?让我们在具有 10,000 个元素的四核计算机上运行它:
Benchmark_sequentialMergesort-4 2278993555 ns/op
Benchmark_parallelMergesortV1-4 17525998709 ns/op
令人惊讶的是,并行版本几乎慢了一个数量级。我们如何解释这个结果?在四个内核之间分配工作负载的并行版本怎么可能比运行在单台机器上的顺序版本慢?我们来分析一下问题。
如果我们有一个 1024 个元素的切片,父 goroutine 将旋转两个 goroutine,每个负责处理由 512 个元素组成的另一半。这些 goroutine 中的每一个都将增加两个新的 goroutine,负责处理 256 个元素,然后是 128 个,依此类推,直到我们增加一个 goroutine 来计算一个元素。
如果我们想要并行化的工作负载太小,这意味着我们将计算得太快,那么跨内核分布作业的好处就会被破坏:与直接合并当前 goroutine 中的少量项目相比,创建 goroutine 并让调度器执行它所花费的时间太长了。尽管 goroutines 是轻量级的,启动速度比线程快,但我们仍然会遇到工作负载太小的情况。
注我们将讨论如何识别错误#98“没有使用 Go 诊断工具”中的执行并行性差的情况
那么我们能从这个结果中得出什么结论呢?这是否意味着归并排序算法不能并行化?等等,别这么快。
让我们尝试另一种方法。因为在一个新的 goroutine 中合并少量的元素效率不高,所以让我们定义一个阈值。该阈值将表示为了以并行方式处理,一半应该包含多少元素。如果一半中的元素数小于这个值,我们将按顺序处理。这是一个新版本:
const max = 2048 // ❶
func parallelMergesortV2(s []int) {
if len(s) <= 1 {
return
}
if len(s) <= max {
sequentialMergesort(s) // ❷
} else { // ❸
middle := len(s) / 2
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
parallelMergesortV2(s[:middle])
}()
go func() {
defer wg.Done()
parallelMergesortV2(s[middle:])
}()
wg.Wait()
merge(s, middle)
}
}
❶ 定义了阈值
❷ 调用我们最初的串行版本
❸ 如果大于阈值,则保持并行版本
如果s切片中的元素数量小于max,我们称之为顺序版本。否则,我们继续调用我们的并行实现。这种方法会影响结果吗?是的,确实如此:
Benchmark_sequentialMergesort-4 2278993555 ns/op
Benchmark_parallelMergesortV1-4 17525998709 ns/op
Benchmark_parallelMergesortV2-4 1313010260 ns/op
我们的 v2 并行实现比顺序实现快 40%以上,这要归功于定义一个阈值来指示并行何时应该比顺序更高效的想法。
请注意,为什么我将阈值设置为 2,048?因为这是我的机器上这个特定工作负载的最佳值。一般来说,这种神奇的值应该用基准仔细定义(在类似于生产的执行环境中运行)。有趣的是,在没有实现 goroutines 概念的编程语言中运行相同的算法会对值产生影响。例如,在 Java 中使用线程运行相同的示例意味着最佳值接近 8,192。这有助于说明 goroutines 比线程更高效。
在本章中,我们已经看到了 Go 中调度的基本概念:线程和 goroutine 之间的区别,以及 Go 运行时如何调度 goroutine。同时,使用并行归并排序的例子,我们说明了并发并不总是更快。正如我们所看到的,让 goroutines 运行来处理最少的工作负载(只合并一小部分元素)会破坏我们从并行性中获得的好处。
那么,我们该何去何从呢?我们必须记住,并发并不总是更快,也不应该被认为是解决所有问题的默认方式。首先,它使事情变得更加复杂。此外,现代 CPU 在执行顺序代码和可预测代码方面已经变得非常高效。例如,超标量处理器可以在单个内核上高效地并行执行指令。
这是否意味着我们不应该使用并发性?当然不是。然而,记住这些结论是很重要的。例如,如果我们不确定并行版本会更快,正确的方法可能是从简单的顺序版本开始,然后使用概要分析(错误#98,“没有使用 Go 诊断工具”)和基准测试(错误#89,“编写不准确的基准测试”)进行构建。这可能是确保并发性值得的唯一方法。
下一节讨论一个常见的问题:什么时候应该使用通道或互斥体?
8.3 #57:对何时使用通道或互斥感到困惑
给定一个并发问题,我们是否可以使用通道或互斥来实现一个解决方案可能并不总是很清楚。因为 Go 提倡通过通信共享内存,所以一个错误可能是总是强制使用通道,而不管用例是什么。然而,我们应该把这两种选择看作是互补的。这一节阐明了我们应该在什么时候选择一个选项。我们的目标不是讨论每一个可能的用例(这可能需要一整章的时间),而是给出可以帮助我们做出决定的一般准则。
首先,简单提醒一下 Go 中的通道:通道是一种沟通机制。在内部,通道是一个我们可以用来发送和接收值的管道,它允许我们连接并发的 goroutines。通道可以是以下任意一种:
-
未缓冲——发送方 goroutine 阻塞,直到接收方 goroutine 准备就绪。
-
缓冲——发送方仅在缓冲区已满时阻塞。
让我们回到我们最初的问题。我们什么时候应该使用通道或互斥?我们将使用图 8.8 中的例子作为主干。我们的示例中有三种不同的 goroutines,它们具有特定的关系:
-
G1 和 G2 是平行的两条路线。它们可能是两个执行相同函数的 goroutine,该函数从一个通道接收消息,或者可能是两个 goroutine 同时执行相同的 HTTP 处理器。
-
另一方面,G1 和 G3 是并发的 goroutines,G2 和 G3 也是。所有的 goroutines 都是整个并发结构的一部分,但是 G1 和 G2 执行第一步,而 G3 执行下一步。
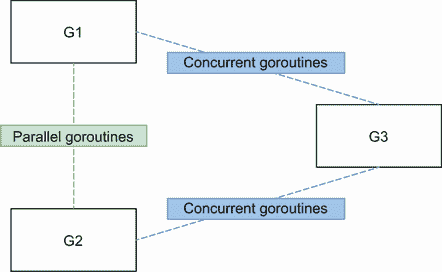
图 8.8 和 G2 是并行的,而 G2 和 G3 是并发的。
一般来说,并行 goroutines 必须同步:例如,当它们需要访问或改变一个共享资源(比如一个片)时。同步是通过互斥体实现的,而不是通过任何通道类型(不是缓冲通道)实现的。因此,一般来说,并行 goroutines 之间的同步应该通过互斥来实现。
相反,一般来说,并发的 goroutines 必须协调和编排。例如,如果 G3 需要汇总来自 G1 和 G2 的结果,则 G1 和 G2 需要向 G3 发出信号,告知有新的中间结果可用。这种协调属于沟通的范畴,因此属于通道的范畴。
关于并发 goroutines,也有这样的情况,我们希望将资源的所有权从一个步骤(G1 和 G2)转移到另一个步骤(G3);例如,如果 G1 和 G2 正在丰富一个共享资源,在某个时刻,我们认为这项工作已经完成。这里,我们应该使用通道来表示特定的资源已经准备好,并处理所有权转移。
互斥体和通道有不同的语义。每当我们想要共享一个状态或访问一个共享资源时,互斥锁确保对这个资源的独占访问。相反,通道是一种机制,用于发送有数据或无数据的信号(chan struct{}或无数据)。协调或所有权转移应通过通道实现。了解 goroutine 是并行的还是并发的很重要,因为一般来说,我们需要为并行的 goroutine 使用互斥体,为并发的 goroutine 使用通道。
现在让我们讨论一个关于并发性的普遍问题:竞争问题。
8.4 #58:不理解竞争问题
竞争问题可能是程序员面临的最困难和最阴险的错误之一。作为 Go 开发人员,我们必须理解关键的方面,比如数据竞争和竞争条件,它们可能的影响,以及如何避免它们。我们将讨论这些主题,首先讨论数据竞争和竞争条件,然后研究 go 内存模型及其重要性。
8.4.1 数据竞争与竞争条件
我们先来关注一下数据竞争。当两个或多个 goroutines 同时访问同一个内存位置,并且至少有一个正在写入时,就会发生数据竞争。以下是两个 goroutines 递增一个共享变量的示例:
i := 0
go func() {
i++ // ❶
}()
go func() {
i++
}()
❶ 递增i
如果我们使用 Go 竞争检测器(-race选项)运行这段代码,它会警告我们发生了数据竞争:
==================
WARNING: DATA RACE
Write at 0x00c00008e000 by goroutine 7:
main.main.func2()
Previous write at 0x00c00008e000 by goroutine 6:
main.main.func1()
==================
i的最终值也是无法预测的。有时候可以是1,有时候是2。
这段代码有什么问题?i++语句可以分解成三个操作:
-
读取
i。 -
递增数值。
-
写回
i。
如果第一个 goroutine 在第二个之前执行并完成,会发生以下情况。
| Goroutine 1 | Goroutine 2 | 操作 | i |
|---|---|---|---|
| 0 | |||
| 读取 | <- | 0 | |
| 递增 | 0 | ||
| 响应 | -> | 1 | |
| 读取 | <- | 1 | |
| 递增 | 1 | ||
| 响应 | -> | 2 |
第一个 goroutine 读取、递增并将值1写回i。然后第二个 goroutine 执行相同的一组动作,但是从1开始。因此,写入i的最终结果是2。
然而,在前面的例子中,不能保证第一个 goroutine 会在第二个之前开始或完成。我们还可以面对交叉执行的情况,其中两个 goroutines 同时运行并竞争访问i。这是另一种可能的情况。
| Goroutine 1 | Goroutine 2 | 操作 | i |
|---|---|---|---|
| 0 | |||
| 读取 | <- | 0 | |
| 读取 | <- | 0 | |
| 递增 | 0 | ||
| 递增 | 0 | ||
| 响应 | -> | 1 | |
| 响应 | -> | 1 |
首先,两个 goroutines 从i读取并获得值0。然后,两者都将其递增,并写回它们的本地结果:1,这不是预期的结果。
这是数据竞争可能带来的影响。如果两个 goroutines 同时访问同一个内存位置,并且至少对该内存位置进行一次写入,结果可能是危险的。更糟糕的是,在某些情况下,内存位置最终可能会保存一个包含无意义的位组合的值。
请注意,在错误#83“未启用-race标志”中,我们将看到 Go 如何帮助我们检测数据竞争。
我们如何防止数据竞争的发生?让我们看看一些不同的技术。这里的范围不是展示所有可能的选项(例如,我们将省略atomic.Value),而是展示主要的选项。
第一种选择是使增量操作原子化,这意味着它在单个操作中完成。这防止了纠缠的运行操作。
| Goroutine 1 | Goroutine 2 | 操作 | i |
|---|---|---|---|
| 0 | |||
| 读取并递增 | <-> | 1 | |
| 读取并递增 | <-> | 2 |
即使第二个 goroutine 在第一个之前运行,结果仍然是2。
原子操作可以在 Go 中使用T2 包来完成。这里有一个我们如何自动增加一个int64的例子:
var i int64
go func() {
atomic.AddInt64(&i, 1) // ❶
}()
go func() {
atomic.AddInt64(&i, 1) // ❷
}()
❶ 原子地递增i
❷ 相同
两个 goroutines 都自动更新i。原子操作不能被中断,从而防止同时进行两次访问。不管 goroutines 的执行顺序如何,i最终将等于2。
注意sync/atomic包为int32、int64、uint32和uint64提供了原语,但不为int提供原语。这就是为什么在这个例子中i是一个int64。
另一个选择是用一个类似互斥的特殊数据结构来同步两个 goroutines。Mutex代表互斥(Mutation Exclusion);互斥体确保最多一个 goroutine 访问一个所谓的临界区。在 Go 中,sync包提供了一个Mutex类型:
i := 0
mutex := sync.Mutex{}
go func() {
mutex.Lock() // ❶
i++ // ❷
mutex.Unlock() // ❸
}()
go func() {
mutex.Lock()
i++
mutex.Unlock()
}()
❶ 进入临界区
❷ 递增i
❸ 退出临界区
在本例中,递增i是临界区。不管 goroutines 的顺序如何,这个例子也为i : 2产生一个确定值。
哪种方法效果最好?界限很简单。正如我们提到的,sync/atomic包只对特定类型的有效。如果我们想要别的东西(例如,切片、映射和结构),我们不能依赖sync/atomic。
另一个可能的选择是避免共享同一个内存位置,而是支持跨 goroutines 的通信。例如,我们可以创建一个通道,每个 goroutine 使用该通道来产生增量值:
i := 0
ch := make(chan int)
go func() {
ch <- 1 // ❶
}()
go func() {
ch <- 1
}()
i += <-ch // ❷
i += <-ch
❶ 通知 goroutine 增加 1
❷ 从通道接收到的信息中增加i
每个 goroutine 通过通道发送一个通知,告诉我们应该将i增加1。父 goroutine 收集通知并增加i。因为这是唯一写入i的 goroutine,这个解决方案也没有数据竞争。
让我们总结一下到目前为止我们所看到的。当多个 goroutines 同时访问同一个内存位置(例如,同一个变量)并且其中至少有一个正在写入时,就会发生数据争用。我们还看到了如何通过三种同步方法来防止这个问题:
-
使用原子操作
-
用互斥体保护临界区
-
使用通信和通道来确保一个变量只由一个例程更新
通过这三种方法,i的值最终将被设置为2,而不考虑两个 goroutines 的执行顺序。但是根据我们想要执行的操作,无数据竞争的应用一定意味着确定性的结果吗?让我们用另一个例子来探讨这个问题。
不是让两个 goroutines 递增一个共享变量,而是每个都做一个赋值。我们将遵循使用互斥体来防止数据竞争的方法:
i := 0
mutex := sync.Mutex{}
go func() {
mutex.Lock()
defer mutex.Unlock()
i = 1 // ❶
}()
go func() {
mutex.Lock()
defer mutex.Unlock()
i = 2 // ❷
}()
❶ 第一次把 1 赋值给i
❷ 第二次把 2 赋值给i
第一个 goroutine 分配1到i,而第二个分配2。
这个例子中有数据竞争吗?不,没有。两个 goroutines 访问同一个变量,但不是同时,因为互斥体保护它。但是这个例子是确定性的吗?不,不是的。
根据执行顺序,i最终将等于1或2。这个例子不会导致数据竞争。但是它有一个竞争条件。当行为依赖于无法控制的事件顺序或时间时,就会出现竞争情况。在这里,事件的时间是 goroutines 的执行顺序。
确保 goroutines 之间特定的执行顺序是一个协调和编排的问题。如果我们想确保我们首先从状态 0 到状态 1,然后从状态 1 到状态 2,我们应该找到一种方法来保证 goroutines 按顺序执行。通道可以是解决这个问题的一种方式。协调和编排还可以确保一个特定的部分只被一个 goroutine 访问,这也意味着删除前面例子中的互斥体。
总之,当我们在并发应用中工作时,必须理解数据竞争不同于竞争条件。当多个 goroutines 同时访问同一个内存位置,并且其中至少有一个正在写入时,就会发生数据竞争。数据竞争意味着意外的行为。然而,无数据竞争的应用并不一定意味着确定的结果。一个应用可以没有数据竞争,但仍然具有依赖于不受控事件的行为(例如 goroutine 执行、消息发布到通道的速度,或者对数据库的调用持续多长时间);这是一个竞争条件。理解这两个概念对于熟练设计并发应用至关重要。
现在让我们检查 Go 内存模型,并理解它为什么重要。
8.4.2 Go 内存模型
上一节讨论了同步 goroutines 的三种主要技术:原子操作、互斥和通道。然而,作为 Go 开发者,我们应该了解一些核心原则。例如,缓冲和无缓冲通道提供不同的保证。为了避免由于缺乏对语言核心规范的理解而导致的意外竞争,我们必须看看 Go 内存模型。
Go 内存模型(golang.org/ref/mem)是一种规范,它定义了在写入不同 goroutine 中的相同变量后,从一个 goroutine 中的变量读取数据的条件。换句话说,它提供了开发人员应该记住的保证,以避免数据竞争和强制确定性输出。
在单个 goroutine 中,不存在不同步的访问。事实上,我们的程序所表达的顺序保证了先发生顺序。
然而,在多个 goroutines 中,我们应该记住其中的一些保证。我们将使用符号A < B来表示事件A发生在事件B之前。让我们检查一下这些保证(有些是从Go 内存模型复制过来的):
-
创建一个 goroutine 发生在 goroutine 执行开始之前。因此,读取一个变量,然后启动一个新的 goroutine 写入该变量,不会导致数据竞争:
i := 0 go func() { i++ }() -
相反,一个 goroutine 的退出并不能保证发生在任何事件之前。因此,以下示例存在数据竞争:
i := 0 go func() { i++ }() fmt.Println(i)同样,如果我们想防止数据竞争的发生,我们应该同步这些 goroutines。
-
通道上的发送发生在该通道的相应接收完成之前。在下一个示例中,父 goroutine 在发送前递增变量,而另一个 goroutine 在通道读取后读取变量:
i := 0 ch := make(chan struct{}) go func() { <-ch fmt.Println(i) }() i++ ch <- struct{}{}顺序如下:
variable increment < channel send < channel receive < variable read通过传递性,我们可以确保对
i的访问是同步的,因此没有数据竞争。 -
关闭通道发生在接收到该关闭之前。下一个例子与上一个类似,只是我们没有发送消息,而是关闭了通道:
i := 0 ch := make(chan struct{}) go func() { <-ch fmt.Println(i) }() i++ close(ch)因此,这个例子也没有数据竞争。
-
关于通道的最后一个保证乍一看可能是违反直觉的:来自无缓冲通道的接收发生在该通道上的发送完成之前。
首先,我们来看一个用缓冲通道代替无缓冲通道的例子。我们有两个 goroutines,父节点发送消息并读取一个变量,而子节点更新这个变量并从通道接收:
i := 0 ch := make(chan struct{}, 1) go func() { i = 1 <-ch }() ch <- struct{}{} fmt.Println(i)这个例子导致了一场数据竞争。我们可以在图 8.9 中看到,对
i的读取和写入可能同时发生;因此,i并不同步。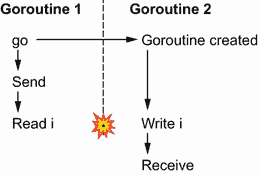
图 8.9 如果通道被缓冲,就会导致数据竞争。
现在,让我们将通道改为无缓冲通道,以说明内存模型保证:
i := 0 ch := make(chan struct{}) // ❶ go func() { i = 1 <-ch }() ch <- struct{}{} fmt.Println(i)❶使通道无缓冲
改变通道类型使本例无数据竞争(见图 8.10)。在这里,我们可以看到主要的区别:写操作肯定发生在读操作之前。注意,箭头不代表因果关系(当然,接收是由发送引起的);它们代表 Go 内存模型的排序保证。因为来自无缓冲通道的接收发生在发送之前,所以对
i的写入总是发生在读取之前。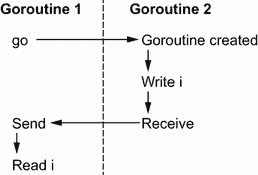
图 8.10 如果通道是无缓冲的,它不会导致数据竞争。
在本节中,我们已经讨论了 Go 内存模型的主要保证。在编写并发代码时,理解这些保证应该是我们核心知识的一部分,并且可以防止我们做出可能导致数据竞争和/或竞争条件的错误假设。
下一节讨论了理解工作负载类型的重要性。
8.5 #59:不了解工作负载类型的并发影响
本节介绍了并行实现中工作负载类型的影响。根据工作负载是受 CPU 限制还是受 I/O 限制,我们可能需要以不同的方式处理这个问题。让我们首先定义这些概念,然后讨论影响。
在编程中,工作负荷的执行时间受以下因素的限制:
-
CPU 的速度——例如,运行归并排序算法。这个工作负载被称为 CPU 限制。
-
I/O 的速度——例如,进行 REST 调用或数据库查询。工作负载称为 I/O 限制。
-
可用内存量——工作负载称为内存限制。
注意,鉴于近几十年来内存变得非常便宜,最后一种是现在最罕见的。因此,本节重点介绍前两种工作负载类型:CPU 和 I/O 负载。
为什么在并发应用环境中对工作负载进行分类很重要?让我们通过一个并发模式来理解这一点:工作器池。
下面的例子实现了一个read函数,它接受一个io.Reader并从中重复读取 1024 个字节。我们将这 1024 字节传递给一个执行某些任务的task函数(稍后我们将看到是什么类型的任务)。这个task函数返回一个整数,我们要返回所有结果的和。下面是一个顺序实现:
func read(r io.Reader) (int, error) {
count := 0
for {
b := make([]byte, 1024)
_, err := r.Read(b) // ❶
if err != nil {
if err == io.EOF { // ❷
break
}
return 0, err
}
count += task(b) // ❸
}
return count, nil
}
❶ 读取 1024 字节
❷ 当我们到达终点时,停止循环
❸ 根据任务函数的结果增加计数
该函数创建一个count变量,从读取io.Reader输入,调用task,并递增count。现在,如果我们想以并行的方式运行所有的和task函数,该怎么办呢?
一种选择是使用所谓的 工作器统筹模式。这样做涉及到创建固定大小的工作器(goroutines ),这些工作器从一个公共通道轮询任务(见图 8.11)。
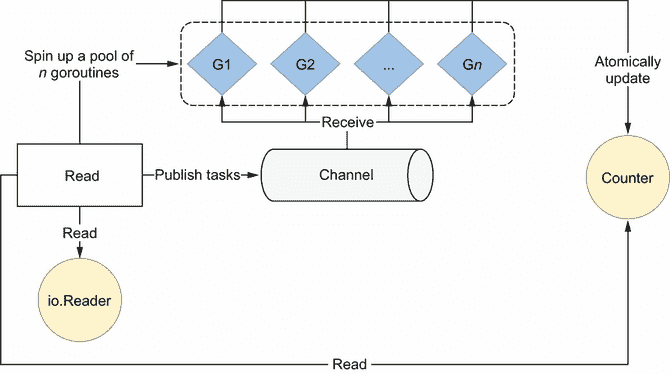
图 8.11 来自固定池的每个 goroutine 从共享通道接收。
首先,我们构建一个固定的 goroutines 池(稍后我们将讨论有多少)。然后我们创建一个共享通道,在每次读取到io.Reader之后,我们将任务发布到这个通道。池中的每个 goroutine 从这个通道接收数据,执行它的工作,然后自动更新一个共享计数器。
这里有一种在 Go 中写这个的可能方法,池大小为 10 个 goroutines。每个 goroutine 自动更新一个共享计数器:
func read(r io.Reader) (int, error) {
var count int64
wg := sync.WaitGroup{}
var n = 10
ch := make(chan []byte, n) // ❶
wg.Add(n) // ❷
for i := 0; i < n; i++ { // ❸
go func() {
defer wg.Done() // ❹
for b := range ch { // ❺
v := task(b)
atomic.AddInt64(&count, int64(v))
}
}()
}
for {
b := make([]byte, 1024)
// Read from r to b
ch <- b // ❻
}
close(ch)
wg.Wait() // ❼
return int(count), nil
}
❶ 创建一个容量等于池容量的通道
❷ 将n添加到等待组中
❸ 创建了n个 goroutine 池
❹ 一旦 goroutine 从通道收到消息,就调用Done方法
❺ 每个 goroutine 从共享通道接收。
❻ 每次读取后,都会向通道发布一个新任务
❼ 在返回之前等待等待组完成
在这个例子中,我们使用n来定义池的大小。我们创建一个容量与池相同的通道和一个增量为n的等待组。这样,我们在发布消息时减少了父 goroutine 中的潜在争用。我们迭代n次来创建一个从共享通道接收的新的 goroutine。收到的每条消息都通过执行task和自动递增共享计数器来处理。从通道中读取数据后,每个 goroutine 都会递减等待组。
在父 goroutine 中,我们一直从io.Reader开始读取,并将每个任务发布到通道。最后但同样重要的是,我们关闭通道,等待等待组完成(意味着所有的子 goroutines 都完成了它们的任务)再返回。
拥有固定数量的 goroutines 限制了我们讨论过的缺点;它缩小了资源的影响,并防止外部系统被淹没。现在的关键问题是:池大小的值应该是多少?答案取决于工作负载类型。
如果工作负载是 I/O 受限的,那么答案主要取决于外部系统。如果我们想要最大化吞吐量,系统可以处理多少个并发访问?
如果工作负载受 CPU 限制,最佳实践是依赖GOMAXPROCS。GOMAXPROCS是变量,设置分配给正在运行的 goroutines 的 OS 线程数。默认情况下,该值设置为逻辑 CPU 的数量。
使用runtime.GOMAXPROCS
我们可以使用runtime.GOMAXPROCS(int)函数来更新GOMAXPROCS的值。用0作为参数调用它不会改变值;它只返回当前值:
n := runtime.GOMAXPROCS(0)
那么,将池的大小映射到GOMAXPROCS的基本原理是什么?我们举一个具体的例子,说我们将在四核机器上运行我们的应用;因此,Go 将实例化四个 OS 线程,其中 goroutines 将被执行。起初,事情可能并不理想:我们可能面临一个场景,有四个 CPU 核心和四个 goroutine,但是只有一个 goroutine 被执行,如图 8.12 所示。
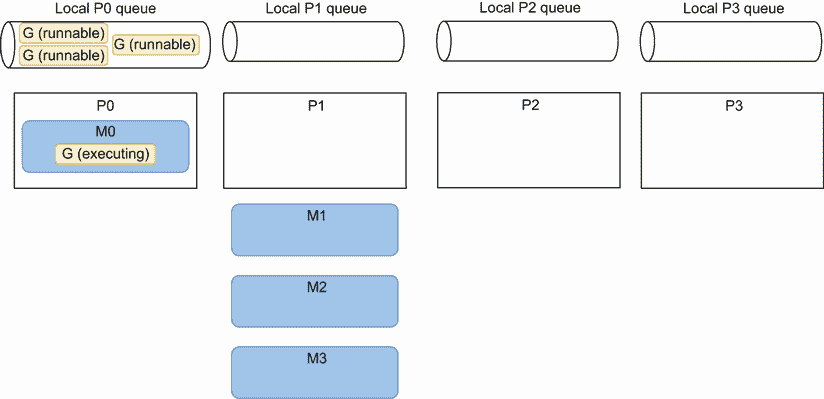
图 8.12 最多运行一个 goroutine。
M0 目前正在运行工作器池的 goroutine。因此,这些 goroutines 开始从通道接收消息并执行它们的作业。但是池中的其他三个 goroutines 还没有分配给 M;因此,它们处于可运行状态。M1、M2 和 M3 没有任何 goroutines 要运行,所以它们仍然没有核心。因此只有一个 goroutine 在运行。
最终,考虑到我们已经描述过的窃取工作的概念,P1 可能会从本地 P0 队列中窃取 goroutines。在图 8.13 中,P1 从 P0 那里偷了三个 goroutines。在这种情况下,Go 调度器也可能最终将所有的 goroutines 分配给不同的 OS 线程,但是不能保证这应该在什么时候发生。然而,由于 Go 调度器的主要目标之一是优化资源(这里是 goroutines 的分布),考虑到工作负载的性质,我们应该以这样的场景结束。

图 8.13 最多运行两个 goroutines。
这个场景仍然不是最佳的,因为最多运行两个 goroutines。假设机器只运行我们的应用(而不是操作系统进程),那么 P2 和 P3 是自由的。最终,操作系统应该移动 M2 和 M3,如图 8.14 所示。

图 8.14 现在最多运行四个 goroutines。
在这里,操作系统调度器决定将 M2 移到 P2,将 M3 移到 P3。同样,无法保证这种情况何时会发生。但是假设一台机器只执行我们的四线程应用,这应该是最终的画面。
情况发生了变化;它已经变得最优。四个 goroutines 运行在不同的线程中,线程运行在不同的内核上。这种方法减少了 goroutine 和线程级别的上下文切换量。
这个全局图不是我们(Go 开发者)能设计和要求的。然而,正如我们所看到的,我们可以在 CPU 受限的工作负载的情况下以有利的条件启用它:拥有一个基于GOMAXPROCS的工作池。
注意,如果给定特定的条件,我们希望将 goroutines 的数量绑定到 CPU 内核的数量,为什么不依赖于返回逻辑 CPU 内核数量的runtime.NumCPU()?我们提到过,GOMAXPROCS是可以改变的,可以小于 CPU 核心的数量。在 CPU 受限的工作负载的情况下,如果内核的数量是四个,但我们只有三个线程,我们应该增加三个 goroutines,而不是四个。否则,一个线程将在两个 goroutines 之间共享其执行时间,从而增加上下文切换的次数。
在实现 worker-pooling 模式时,我们已经看到池中 goroutines 的最佳数量取决于工作负载类型。如果工作线程执行的工作负载是 I/O 受限的,那么这个值主要取决于外部系统。相反,如果工作负载是 CPU 受限的,那么 goroutines 的最佳数量接近可用线程的数量。设计并发应用时,了解工作负载类型(I/O 或 CPU)至关重要。
最后但同样重要的是,让我们记住,在大多数情况下,我们应该通过基准来验证我们的假设。并发并不简单,很容易做出草率的假设,结果证明是无效的。
在本章的最后一节,我们将讨论一个要精通 Go 必须了解的重要话题:上下文。
8.6 #60:误解 Go 上下文
开发人员有时会误解context.Context类型,尽管它是该语言的关键概念之一,也是 Go 中并发代码的基础。让我们看看这个概念,并确保我们理解为什么以及如何有效地使用它。
根据官方文档(pkg.go.dev/context):
上下文携带截止日期、取消信号和其他跨 API 边界的值。
让我们检查一下这个定义,并理解与 Go 上下文相关的所有概念。
8.6.1 截止日期
截止日期是指由以下某一项确定的特定时间点:
-
从现在起一个
time.Duration(例如,在 250 毫秒内) -
A
time.Time(例如世界协调时2023-02-07 00:00:00)
截止日期的语义表明,如果符合截止日期,正在进行的活动应该停止。例如,一个活动是一个 I/O 请求或一个等待从通道接收消息的 goroutine。
让我们考虑一个每四秒钟从雷达接收一次飞行位置的应用。一旦我们收到一个职位,我们希望与只对最新职位感兴趣的其他应用共享它。我们拥有一个包含单一方法的publisher接口:
type publisher interface {
Publish(ctx context.Context, position flight.Position) error
}
此方法接受上下文和位置。我们假设具体实现调用一个函数向代理发布消息(比如使用 Sarama 发布 Kafka 消息)。这个函数是上下文感知的,这意味着一旦上下文被取消,它就可以取消请求。
假设我们没有收到一个现有的上下文,我们应该为上下文参数的Publish方法提供什么?我们已经提到,申请人只对最新的职位感兴趣。因此,我们构建的上下文应该传达这样的信息:4 秒钟后,如果我们无法发布航班位置,我们应该停止对Publish的调用:
type publishHandler struct {
pub publisher
}
func (h publishHandler) publishPosition(position flight.Position) error {
ctx, cancel := context.WithTimeout(context.Background(), 4*time.Second) // ❶
defer cancel() // ❷
return h.pub.Publish(ctx, position) // ❸
}
❶ 创建的上下文将在 4 秒钟后超时
❷ 延迟调用cancel
❸ 传递了创建的上下文
这段代码使用函数context.WithTimeout创建一个上下文。该函数接受超时和上下文。在这里,由于publishPosition没有接收现有的上下文,我们用context.Background从一个空的上下文中创建一个。同时,context.WithTimeout返回两个变量:创建的上下文和一个取消func()函数,该函数将在调用后取消上下文。将创建的上下文传递给Publish方法应该会使它在最多 4 秒内返回。
称cancel函数为函数的基本原理是什么?在内部,context.WithTimeout创建一个 goroutine,该 goroutine 将在内存中保留 4 秒钟或直到cancel被调用。因此,调用cancel作为一个defer函数意味着当我们退出父函数时,上下文将被取消,创建的 goroutine 将被停止。这是一种保护措施,这样当我们返回时,不会在内存中留下保留的对象。
现在让我们转到 Go 上下文的第二个方面:取消信号。
8.6.2 取消信号
Go 上下文的另一个用例是携带取消信号。假设我们想要创建一个在另一个 goroutine 中调用CreateFileWatcher(ctx context.Context, filename string)的应用。这个函数创建了一个特定的文件监视器,它不断读取文件并捕捉更新。当提供的上下文过期或被取消时,该函数处理它以关闭文件描述符。
最后,当main返回时,我们希望通过关闭这个文件描述符来优雅地处理事情。因此,我们需要传播一个信号。
一种可能的方法是使用context.WithCancel,它返回一个上下文(返回的第一个变量),一旦调用了cancel函数(返回的第二个变量),它将取消:
func main() {
ctx, cancel := context.WithCancel(context.Background()) // ❶
defer cancel() // ❷
go func() {
CreateFileWatcher(ctx, "foo.txt") // ❸
}()
// ...
}
❶ 创建了一个可取消的环境
❷ 延迟调用cancel
❸ 使用创建的上下文调用该函数
当main返回时,它调用cancel函数来取消传递给CreateFileWatcher的上下文,以便文件描述符被优雅地关闭。
接下来,让我们讨论 Go 上下文的最后一个方面:值。
8.6.3 上下文值
Go 上下文的最后一个用例是携带一个键值列表。在了解其背后的原理之前,我们先来看看如何使用它。
传达值的上下文可以这样创建:
ctx := context.WithValue(parentCtx, "key", "value")
与context.WithTimeout、context.WithDeadline、context.WithCancel一样,context.WithValue是从父上下文(这里是parentCtx)中创建的。在这种情况下,我们创建一个新的ctx上下文,它包含与parentCtx相同的特征,但也传递一个键和值。
我们可以使用Value方法访问该值:
ctx := context.WithValue(context.Background(), "key", "value")
fmt.Println(ctx.Value("key"))
value
提供的键和值是any类型。事实上,对于值,我们希望传递any类型。但是为什么键也应该是一个空接口,而不是一个字符串呢?这可能会导致冲突:来自不同包的两个函数可能使用相同的字符串值作为键。因此,后者将覆盖前者的值。因此,处理上下文键的最佳实践是创建一个未导出的自定义类型:
package provider
type key string
const myCustomKey key = "key"
func f(ctx context.Context) {
ctx = context.WithValue(ctx, myCustomKey, "foo")
// ...
}
myCustomKey常量未导出。因此,使用相同上下文的另一个包不会覆盖已经设置的值。即使另一个包也基于一个key类型创建了相同的myCustomKey,它也将是一个不同的键。
那么,让上下文携带一个键值列表有什么意义呢?因为 Go 上下文是通用的和主流的,所以有无限的用例。
例如,如果我们使用跟踪,我们可能希望不同的子函数共享相同的关联 ID。一些开发人员可能认为这个 ID 太具侵入性,不适合作为函数签名的一部分。在这方面,我们也可以决定将其作为所提供的上下文的一部分。
另一个例子是如果我们想要实现一个 HTTP 中间件。如果你不熟悉这个概念,中间件是在服务请求之前执行的中间功能。例如,在图 8.15 中,我们已经配置了两个中间件,它们必须在执行处理器本身之前执行。如果我们想要中间件通信,它们必须通过*http.Request中处理的上下文。
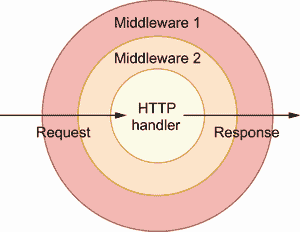
图 8.15 在到达处理器之前,一个请求通过配置好的中间件。
让我们编写一个标记源主机是否有效的中间件示例:
type key string
const isValidHostKey key = "isValidHost" // ❶
func checkValid(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
validHost := r.Host == "acme" // ❷
ctx := context.WithValue(r.Context(), isValidHostKey, validHost) // ❸
next.ServeHTTP(w, r.WithContext(ctx)) // ❹
})
}
❶ 创建上下文键
❷ 检查主机是否有效
❸ 创建一个新的上下文,其中包含一个值来表示源主机是否有效
❹ 在新环境下的调用next.ServeHTTP
首先,我们定义一个名为isValidHostKey的特定上下文键。然后checkValid中间件检查源主机是否有效。这个信息在新的上下文中传递,使用next.ServeHTTP传递到下一个 HTTP 步骤(下一个步骤可以是另一个 HTTP 中间件或最终的 HTTP 处理器)。
这个例子展示了如何在具体的 Go 应用中使用带有值的上下文。在前面的章节中,我们已经看到了如何创建一个上下文来承载截止日期、取消信号和/或值。我们可以使用这个上下文,并将其传递给上下文感知库,这意味着库公开了接受上下文的函数。但是现在,假设我们必须创建一个库,并且我们希望外部客户端提供一个可以被取消的上下文。
8.6.4 捕捉上下文取消
context.Context类型导出返回一个只收通知通道的Done方法:<-chan struct{}。当与上下文相关联的工作应该被取消时,该通道被关闭。举个例子,
-
调用
cancel函数时,与context.WithCancel创建的上下文相关的Done通道关闭。 -
当截止日期到期时,与用
context.WithDeadline创建的上下文相关的Done通道关闭。
需要注意的一点是,内部通道应该在上下文被取消或达到截止日期时关闭,而不是在它收到特定值时关闭,因为通道的关闭是所有消费者 goroutines 将收到的唯一通道操作。这样,一旦上下文被取消或截止日期到了,所有的消费者都会得到通知。
此外,context.Context导出一个Err方法,如果Done通道尚未关闭,则返回nil。否则,它返回一个非零错误,解释为什么Done通道被关闭:例如,
-
一个
context.Canceled错误,如果通道被取消 -
如果上下文的截止日期已过,则出现
context.DeadlineExceeded错误
让我们看一个具体的例子,在这个例子中,我们希望不断地从一个通道接收消息。同时,我们的实现应该是上下文感知的,如果所提供的上下文完成了,就返回:
func handler(ctx context.Context, ch chan Message) error {
for {
select {
case msg := <-ch: // ❶
// Do something with msg
case <-ctx.Done(): // ❷
return ctx.Err()
}
}
}
❶ 不断接收来自通道的消息
❷ 如果上下文完成,返回与之相关的错误
我们创建一个for循环,并在两种情况下使用select:从ch接收消息或接收一个信号,表明上下文已经完成,我们必须停止我们的作业。在处理通道时,这是一个如何让函数感知上下文的例子。
实现接收上下文的函数
在接收传达可能的取消或超时的上下文的函数中,接收或发送消息到通道的操作不应该以阻塞方式完成。例如,在下面的函数中,我们向一个通道发送消息,并从另一个通道接收消息:
func f(ctx context.Context) error {
// ...
ch1 <- struct{}{} // ❶
v := <-ch2 // ❷
// ...
}
❶ 接收
❷ 发送
这个函数的问题是,如果上下文被取消或超时,我们可能不得不等待消息被发送或接收,而没有好处。相反,我们应该使用select来等待通道动作完成或者等待上下文取消:
func f(ctx context.Context) error {
// ...
select { // ❶
case <-ctx.Done():
return ctx.Err()
case ch1 <- struct{}{}:
}
select { // ❷
case <-ctx.Done():
return ctx.Err()
case v := <-ch2:
// ...
}
}
❶ 向ch1发送消息或者等待上下文被取消
❷ 从ch2接收消息或者等待上下文被取消
在这个新版本中,如果ctx被取消或超时,我们会立即返回,而不会阻塞通道发送或接收。
总之,要成为一名精通GO的开发人员,我们必须了解什么是上下文以及如何使用它。在GO中,context.Context在标准库和外部库中随处可见。正如我们提到的,上下文允许我们携带截止日期、取消信号和/或键值列表。一般来说,用户等待的函数应该获取上下文,因为这样做允许上游调用者决定何时应该中止调用该函数。
当不确定使用哪个上下文时,我们应该使用context.TODO(),而不是用context.Background传递一个空上下文。context.TODO()返回一个空的上下文,但是从语义上来说,它表示要使用的上下文要么不清楚,要么还不可用(例如,还没有被父节点传播)。
最后,让我们注意标准库中的可用上下文对于多个 goroutines 的并发使用都是安全的。
总结
-
理解并发和并行之间的根本区别是 Go 开发人员知识的基石。并发是关于结构的,而并行是关于执行的。
-
要成为一名熟练的开发人员,你必须承认并发并不总是更快。涉及最小工作量并行化的解决方案不一定比顺序实现更快。对顺序解决方案和并发解决方案进行基准测试应该是验证假设的方法。
-
了解 goroutine 交互也有助于在通道和互斥之间做出决定。一般来说,并行 goroutines 需要同步,因此也需要互斥。相反,并发 goroutines 通常需要协调和编排,因此也需要通道。
-
精通并发也意味着理解数据竞争和竞争条件是不同的概念。当多个 goroutines 同时访问同一个内存位置,并且其中至少有一个正在写入时,就会发生数据争用。同时,无数据竞争并不一定意味着确定性执行。当一个行为依赖于无法控制的事件顺序或时间时,这就是一个竞争条件。
-
了解 Go 内存模型以及排序和同步方面的底层保证对于防止可能的数据争用和/或争用情况至关重要。
-
在创建一定数量的 goroutines 时,要考虑工作负载类型。创建 CPU 绑定的 goroutines 意味着将这个数字绑定到接近于
GOMAXPROCS变量的位置(默认情况下基于主机上 CPU 核心的数量)。创建 I/O 绑定的 goroutines 取决于其他因素,例如外部系统。 -
Go 上下文也是 Go 中并发的基石之一。上下文允许你携带截止日期、取消信号和/或键值列表。