ElasticSearch
- 1.概述
- 2.入门
- 1.官方地址
- 2.RESTful
- 3.倒排索引
- 4.http请求操作
- 1.索引操作
- 2.document操作
- 1.基本操作
- 2.多条件查询
- 3.区间查询
- 4.完全匹配
- 5.高亮显示
- 6.聚合查询
- 7.映射关系
- 5.JAVA API
- 1.index操作
- 2.doc操作
- 1.基础操作
- 2.批量操作
- 3.复杂查询
1.概述
结构化数据、非结构化数据、半结构化数据
lasticsearch 是什么
The Elastic Stack, 包括 Elasticsearch、 Kibana、 Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
Elaticsearch,简称为 ES, ES 是一个开源的高扩展的分布式全文搜索引擎, 是整个 ElasticStack 技术栈的核心。
它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
全文搜索引擎
Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。
一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对 SQL 的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
基于以上原因可以分析得出,在一些生产环境中,使用常规的搜索方式,性能是非常差的:
搜索的数据对象是大量的非结构化的文本数据。
文件记录量达到数十万或数百万个甚至更多。
支持大量基于交互式文本的查询。
需求非常灵活的全文搜索查询。
对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。为了解决结构化数据搜索和非结构化数据搜索性能问题,我们就需要专业,健壮,强大的全文搜索引擎 。
这里说到的全文搜索引擎指的是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
Elasticsearch 应用案例
GitHub: 2013 年初,抛弃了 Solr,采取 Elasticsearch 来做 PB 级的搜索。 “GitHub 使用Elasticsearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码”。
维基百科:启动以 Elasticsearch 为基础的核心搜索架构
百度:目前广泛使用 Elasticsearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括云分析、网盟、预测、文库、直达号、钱包、 风控等),单集群最大 100 台机器, 200 个 ES 节点,每天导入 30TB+数据。
新浪:使用 Elasticsearch 分析处理 32 亿条实时日志。
阿里:使用 Elasticsearch 构建日志采集和分析体系。
Stack Overflow:解决 Bug 问题的网站,全英文,编程人员交流的网站。
2.入门
1.官方地址
官网地址
官方文档
下载页面
docker安装
2.RESTful
RESTful:
RESTful详解
3.倒排索引
正排索引(传统)
| id | content |
|---|---|
| 1001 | my name is zhang san |
| 1002 | my name is li si |
倒排索引
| keyword | id |
|---|---|
| name | 1001, 1002 |
| zhang | 1001 |
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。 为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比。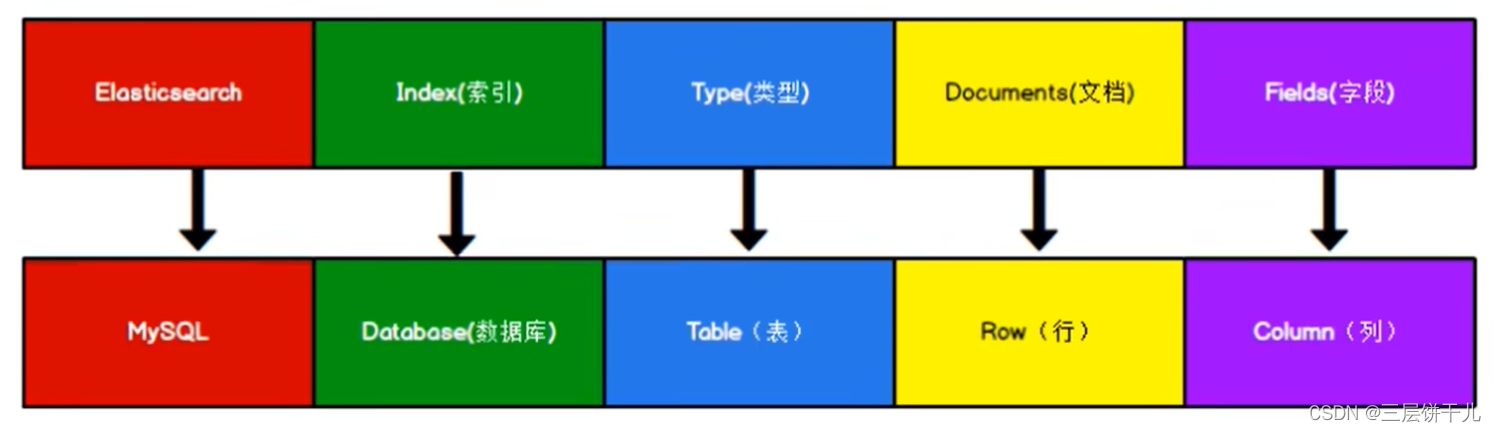
ES 里的 Index 可以看做一个库,而 Types 相当于表, Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一个 index 下已经只能包含一个type, Elasticsearch 7.X 中, Type 的概念已经被删除了。
4.http请求操作
1.索引操作
###### 索引
#查看所有索引
GET _cat/indices?v
#创建索引
PUT index_sample
#查看索引
GET index_sample
#删除索引
DELETE index_sample
2.document操作
1.基本操作
#添加数据 不指定id时,自动生成的id,每次返回不一样,操作不是幂等性操作,不能使用PUT
POST index_sample/_doc
{
"id":1001,
"name":"小明"
}
###### doc操作
#指定id时 执行多次返回的id都是相同的,所以时幂等性操作,可以使用PUT
POST index_sample/_doc/10001
{
"id":1001,
"name":"小明"
}
#或者
POST index_sample/_create/1002
{
"id":1002,
"name":"小明"
}
#查询 主键查询
GET index_sample/_doc/10001
#查询 所有
GET index_sample/_search
#全量更新
PUT index_sample/_doc/10001
{
"id" : 1001,
"name" : "小明2"
}
#局部更新 非幂等性
POST index_sample/_update/10001
{
"doc": {
"name":"小刚"
}
}
#删除
DELETE index_sample/_doc/1002
2.多条件查询
#### 匹配多个条件
## 条件且
GET index_sample/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "小明"
}
},
{
"match": {
"desc": "2"
}
}
]
}
}
}
## 条件或者
GET index_sample/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "小明"
}
},
{
"match": {
"desc": "我是小明"
}
}
]
}
}
}
3.区间查询
GET index_sample/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
]
}
}
}
4.完全匹配
GET index_sample/_search
{
"query": {
"match_phrase": {
"desc": "你有点2"
}
}
}
5.高亮显示
GET index_sample/_search
{
"query": {
"match_phrase": {
"desc": "小明"
}
},
"highlight": {
"fields": {
"desc": {}
}
}
}
6.聚合查询
一言以蔽之,聚合查询就是对查到的数据进行统计分析(分组、最大小值、平均值等)
参考
### 聚合查询
#按年龄分组 不展示具体数据
GET bank/_search
{
"aggs": {
"group_agg": {
"terms": {
"field": "age",
"size": 5
}
}
},
"size": 0
}
#年龄平均值 不展示具体数据
GET bank/_search
{
"aggs": {
"avg_agg": {
"avg": {
"field": "age"
}
}
},
"size": 0
}
#其他详见API
7.映射关系
### 映射
PUT index_sample_mapping
# 创建映射
PUT index_sample_mapping/_mapping
{
"properties": {
"name": {
"type": "text",
"index": true
},
"gender": {
"type": "keyword",
"index": true
},
"tel": {
"type": "text",
"index": false
}
}
}
# 查询映射
GET index_sample_mapping/_mapping
# 测试数据
PUT index_sample_mapping/_create/1001
{
"name": "小明",
"gender": "男生",
"tel": "1111111"
}
PUT index_sample_mapping/_create/1002
{
"name": "小红",
"gender": "女生",
"tel": "2222222"
}
# 支持分词
GET index_sample_mapping/_search
{
"query": {
"match": {
"name": "小"
}
}
}
# 关键字字段,不支持分词,必须全文匹配
GET index_sample_mapping/_search
{
"query": {
"match": {
"gender": "男生"
}
}
}
# 不支持索引,查询失败
GET index_sample_mapping/_search
{
"query": {
"match": {
"tel": "111"
}
}
}
5.JAVA API
1.index操作
public class IndexSample {
public static void main(String[] args) throws IOException {
RestHighLevelClient client =
new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.2.111", 9200, "http"))
);
//创建索引
CreateIndexRequest userIndexRequest = new CreateIndexRequest("user");
IndicesClient indices = client.indices();
CreateIndexResponse createIndexResponse = indices.create(userIndexRequest, RequestOptions.DEFAULT);
System.out.println(createIndexResponse.isAcknowledged());
//查看索引
GetIndexRequest getIndexRequest = new GetIndexRequest("user");
GetIndexResponse getIndexResponse = indices.get(getIndexRequest, RequestOptions.DEFAULT);
System.out.println(getIndexResponse.getAliases());
System.out.println(getIndexResponse.getMappings());
System.out.println(getIndexResponse.getSettings());
//删除索引
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("user");
AcknowledgedResponse acknowledgedResponse = indices.delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(acknowledgedResponse.isAcknowledged());
//关闭客户端
client.close();
}
2.doc操作
1.基础操作
public interface ElasticSearchTask {
/**
* 使用接口做部分操作
*
* @param client es客户端
*/
void doSth(RestHighLevelClient client) throws IOException;
}
public class ElasticSearchClientUtils {
public static void connect(ElasticSearchTask task) {
RestHighLevelClient client =
new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.2.111", 9200, "http"))
);
try {
task.doSth(client);
client.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
public class DocSample {
public static void main(String[] args) {
User user = new User();
user.setName("小明");
user.setAge(11);
user.setSex("男");
ElasticSearchClientUtils.connect(e -> {
//新增doc
IndexRequest indexRequest = new IndexRequest();
indexRequest.index("user").id("1001");
ObjectMapper objectMapper = new ObjectMapper();
String json = objectMapper.writeValueAsString(user);
indexRequest.source(json, XContentType.JSON);
IndexResponse indexResponse = e.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(indexResponse.getResult());
//查询
GetRequest getRequest = new GetRequest();
getRequest.index("user").id("1001");
GetResponse getResponse = e.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());
//修改
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index("user").id("1001");
updateRequest.doc(XContentType.JSON, "sex", "女");
UpdateResponse updateResponse = e.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse.getResult());
System.out.println(e.get(getRequest, RequestOptions.DEFAULT).getSourceAsString());
//删除
DeleteRequest deleteRequest = new DeleteRequest();
deleteRequest.index("user").id("1001");
DeleteResponse deleteResponse = e.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(deleteResponse.toString());
});
}
}
2.批量操作
略
3.复杂查询
略
分页、条件、组合、范围、模糊、高亮