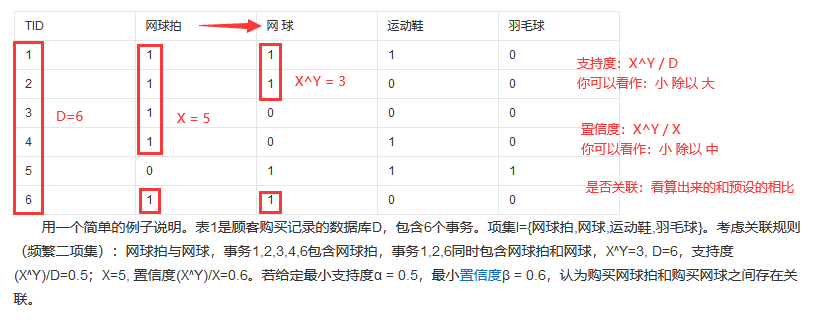
本论文相关内容
- 论文下载地址——Web Of Science
- 论文中文翻译——How Double-Fetch Situations turn into Double-Fetch Vulnerabilities A Study of Double Fetches in the Linux Kernel
文章目录
- 本论文相关内容
- 前言
- Double-Fetch情况如何演变为Double-Fetch漏洞:Linux内核中的双重获取研究
- 作者信息
- 论文来源
- 主办方信息
- 摘要
- 1 引言
- 2 背景
- 2.1 内核/用户空间保护
- 2.2 驱动程序中的内存访问
- 2.3 双重提取
- 2.4 Coccinelle
- 3 Linux内核中的双重获取
- 3.1 基本模式匹配分析
- 3.2 双重提取分类
- 3.2.1 类型选择
- 3.2.2 大小检查
- 3.2.3 浅拷贝
- 3.3 精细的Double-Fetch错误检测
- 4 评估
- 4.1 统计与分析
- 4.2 三个开源内核的分析
- 5 讨论
- 5.1 检测到的错误和漏洞
- 5.2 对照
- 5.3 Double-Fetch错误预防
- 5.4 结果解释
- 5.5 局限性
- 6 相关工作
- 7 结论
- 致谢
- 总结
前言
此博客为How Double-Fetch Situations turn into Double-Fetch Vulnerabilities A Study of Double Fetches in the Linux Kernel论文的中文翻译,本篇论文详细讨论了Linux系统内核中的Double-Fetch漏洞,并提出了一种Double-Fetch漏洞检测方法,基于此方法设计出了三种工具,经过实验发现这三种工具的检测效果都很不错,这也证明了本实验所提出的方法的有效性。总之,这篇论文写的非常不错,读起来并不是很困难,而且比较接地气,十分推荐读一读这篇论文!
Double-Fetch情况如何演变为Double-Fetch漏洞:Linux内核中的双重获取研究
作者信息
论文来源
主办方信息
摘要
我们提出了第一种静态方法,该方法系统地检测Linux内核中潜在的double-fetch漏洞。使用基于模式的分析,我们在Linux内核中确定了90次双取。其中57个发生在驱动程序中,以前的动态方法在没有访问相应硬件的情况下无法检测到这些驱动程序。我们手动调查了90次发生的情况,并推断出发生双重提取的三种典型情况。我们详细讨论了每一个问题。我们进一步开发了一种基于Coccinelle匹配引擎的静态分析,用于检测可能导致内核漏洞的double-fetch情况。当应用于Linux、FreeBSD和Android内核时,我们的方法发现了六个以前未知的double-fetch错误,其中四个在驱动程序中,其中三个是可利用的double-fetch漏洞。所有已识别的错误和漏洞都已得到维护人员的确认和修补。我们的方法已经被Coccinelle团队采用,目前正在集成到Linux内核补丁审查中。基于我们的研究,我们还为预测double-fetch错误和漏洞提供了实用的解决方案。我们还提供了一种自动修补检测到的double-fetch错误的解决方案。
1 引言
多核硬件的广泛使用使得并发程序越来越普遍,尤其是在操作系统、实时系统和计算密集型系统中。然而,并发程序也因难以检测并发错误而臭名昭著。现实世界中的并发错误可以分为三种类型:原子性违反错误、顺序违反错误和死锁。
数据竞争是并发程序中的另一种常见情况。当两个线程正在访问一个共享内存位置,两次访问中至少有一次是写入,并且两次访问的相对顺序不由任何同步原语强制执行时,就会发生这种情况。数据竞争通常会导致并发错误,因为它们可能导致原子性冲突或顺序冲突。除了发生在两个线程之间,数据竞争也可能发生在内核和用户空间之间。Serna是第一个使用“double-fetch”一词来描述Windows内核漏洞的人,该漏洞是由于内核两次提取相同的用户空间数据的竞争条件造成的。当内核读取并使用两次驻留在用户空间中的相同值(期望两次都相同)时,就会出现double-fetch错误,而同时运行的用户线程可以在两次内核读取之间的时间窗口中修改该值。double-fetch错误在内核代码中引入数据不一致,导致可利用的漏洞,如缓冲区溢出。
Jurczyk和Coldwind是第一个系统地研究双取的人。他们的动态方法通过跟踪内存访问来检测双取,并在Windows内核中发现了一系列double-fetch漏洞。然而,他们的动态方法只能实现有限的覆盖范围。特别是,它不能应用于需要执行相应硬件的代码,因此在没有访问设备或对其进行模拟的情况下,无法分析设备驱动程序。因此,它们的分析不能覆盖整个内核。事实上,他们的方法并没有在Linux、FreeBSD或OpenBSD中发现任何double-fetch漏洞。此外,Jurczyk和Coldwind不仅关注如何查找,还关注如何利用double-fetch漏洞。关于如何利用双取的说明最近已经公开。因此,针对double-fetch漏洞对内核,特别是驱动程序进行审计已成为当务之急。
设备驱动程序是关键的内核级程序,通过在操作系统和连接到系统的设备之间提供接口来桥接硬件和软件。驱动程序是当前操作系统的很大一部分,例如,44%的Linux 4.5源文件属于驱动程序。驱动程序被发现是特别容易出错的内核组件。Chou等人根据经验表明,设备驱动程序中的错误率大约是内核任何其他部分的十倍。Swift等人还发现,Windows XP中85%的系统崩溃可归咎于驱动程序错误。此外,Ryzhyk等人发现驱动程序中19%的错误是并发错误,其中大多数是数据争用或死锁。
因为驱动程序是内核中的一个关键故障点,所以即使在相应的硬件不可用的情况下,也必须分析它们的安全漏洞。事实上,26%的Linux内核源文件属于x86以外的硬件体系结构,无法使用Jurczyk和Coldwind的基于x86的技术进行分析。因此,动态分析不是一种可行的、负担得起的方法。因此,我们开发了一种基于静态模式的方法来识别Linux内核中的双重获取,包括驱动程序的完整空间。我们确定了90次双取,然后对其进行了调查,并将其分类为发生双取的三种典型场景。我们发现大多数双取都不是double-fetch错误,因为尽管内核两次获取相同的数据,但它只使用两次获取中的一次的数据。因此,我们改进了基于静态模式的方法来检测实际的double-fetch错误和漏洞,并用它分析了Linux、Android和FreeBSD。
我们发现Linux 4.5中的大多数双取都发生在驱动程序中(57/90),大多数已识别的double-fetch错误(4/5)也是如此。这意味着,除非研究人员能够访问与他们分析的内核兼容的完整硬件,否则动态分析方法无法检测到大多数双取错误。这一点通过与Bochspwn(一种动态分析方法)的比较得到了证实,后者在Linux 3.5.0中找不到任何double-fetch错误,而我们的方法找到了三个。总之,我们在本文中做出了以下贡献:
(1) 首次对Linux内核中的双取进行系统研究。据我们所知,我们首次对完整Linux内核中的双取进行了研究,包括对双取发生的方式和原因的分析。我们使用模式匹配来自动识别Linux内核中的90种double-fetch情况,并通过手动查看内核源代码来研究这些候选情况。我们将已识别的双取分为三种典型场景(类型选择、大小检查、浅拷贝),在这三种场景中容易发生双取,并通过详细的双取案例分析来说明每种场景。大多数(57/90)已识别的双取发生在驱动程序中。
(2) 一种基于模式的double-fetch错误检测方法。我们开发了一种基于静态模式的方法来检测double-fetch错误。该方法已在Coccinelle程序匹配和转换引擎上实现,并适用于检查Linux、FreeBSD和Android内核。这是第一种能够在包括所有驱动程序和所有硬件架构在内的完整内核中检测double-fetch漏洞的方法。我们的方法已经被Coccinelle团队采用,目前正在通过Coccineller集成到Linux内核补丁审查中。
(3) 识别六个double-fetch错误。我们总共发现了六个真正的double-fetch错误。其中四个在Linux 4.5的驱动程序中,其中三个是可利用的漏洞。此外,所有四个与驱动程序相关的double-fetch错误都属于相同的大小检查场景。Linux维护人员已经确认了这些错误,并根据我们的报告在新版本中进行了修复。在Android 6.0.1内核中发现了一个double-fetch漏洞,该漏洞已在较新的Linux内核中修复。
(4) 防止double-fetch错误的策略。基于我们的研究,我们提出了五种解决方案来预测double-fetch错误,并在一个自动修补double-fetch错误的工具中实现了其中一种策略。
本文的其余部分组织如下:第2节介绍了Linux中内存访问的相关背景,特别是Linux驱动程序中的内存访问,以及double-fetch错误是如何发生的。第3节介绍了我们的双取检测方法,包括我们的分析过程,将已识别的双取分类为三种场景,以及我们从已识别的double-fetch错误中学到了什么。第4节介绍了对我们工作的评估,包括手动分析的统计数据,以及将我们的方法应用于Linux、FreeBSD和Android内核的结果。第5节讨论了检测到的错误、double-fetch错误预防的含义、对我们发现的解释以及我们方法的局限性。相关工作在第6节中进行了讨论,随后是结论。
2 背景
我们为读者提供了一个提醒,提醒他们Linux内核及其驱动程序和用户空间之间是如何交换数据的,以及在这个框架内如何出现竞争条件和double-fetch错误。
2.1 内核/用户空间保护
在现代计算机系统中,内存分为内核空间和用户空间。内核空间是内核代码执行和内部数据存储的地方,而用户空间是正常用户进程运行的地方。每个用户空间进程都驻留在自己的地址空间中,并且只能对该空间中的内存进行寻址。内核将这些虚拟地址空间映射到物理内存上,以保证独立空间之间的隔离。内核也有自己独立的地址空间。
操作系统提供了特殊的方案来在内核和用户空间之间交换数据。在Windows中,我们可以使用设备输入和输出控制(IOCTL)方法,或共享内存对象方法在内核和用户空间之间交换数据,这与共享内存区域非常相似。在Linux和FreeBSD中,提供了在内核空间和用户空间之间安全传输数据的函数,我们称之为传输函数。例如,Linux有四个常用的传输函数,即copy_from_user()、copy_to_user()、get_user()和put_user(),它们以安全的方式在用户空间之间复制单个值或任意数量的数据。传输函数不仅在内核和用户空间之间交换数据,而且还提供了一种防止无效内存访问的保护机制,例如非法地址或页面错误。因此,Linux中的任何双取都将涉及对传输函数的多次调用。
2.2 驱动程序中的内存访问
设备驱动程序是内核组件,负责使内核能够与连接到系统的硬件设备通信并使用这些设备。驱动程序具有典型的特性,例如支持同步和异步操作以及可以多次打开。驱动程序对安全性至关重要,因为它们中的故障可能会导致漏洞,从而授予整个系统的控制权。最后,驱动程序通常必须将可变类型或可变长度的消息从用户空间复制到硬件,正如我们稍后将看到的,这通常会导致double-fetch情况,从而导致漏洞。
在Linux中,所有设备都有一个文件表示,可以从用户空间访问该文件,以便与硬件的驱动程序交互。内核在/dev目录中为每个驱动程序创建一个文件,用户空间进程可以使用文件输入/输出系统调用与该文件进行交互。该驱动程序提供了所有与文件相关的操作的实现,包括read()和write()函数。在这样的功能中,驱动程序需要从用户空间获取数据(写入)或将数据复制到用户空间(读取)。驱动程序使用传输函数来实现这一点,而且,任何双重提取都将涉及对传输函数的多次调用。
2.3 双重提取
双取是在内核和用户空间之间的内存访问中发生的竞争条件的一种特殊情况。Serna在一份关于Windows double-fetch漏洞的报告中提出了第一个此类漏洞。从技术上讲,双取发生在内核函数(如系统调用)中,该函数由用户应用程序从用户模式调用。如图1所示,内核函数从用户空间中的同一内存位置获取两次值,第一次是检查和验证它,第二次是使用它(请注意,事件从左到右都在时间线上,但用户数据始终是同一对象)。同时,在两个内核获取之间的时间窗口内,同时运行的用户线程会修改该值。然后,当内核函数第二次获取要使用的值时,它会得到一个不同的值,这不仅会导致不同的计算结果,而且可能导致缓冲区溢出、空指针崩溃,甚至更严重的后果。

为了避免混淆,我们在本文中使用术语双取或double-fetch情况来表示内核多次获取同一用户数据的所有情况,所谓的双取可以进一步分为以下几种情况:
良性双取:良性双取是指由于额外的保护方案或因为双取值没有使用两次而不会造成伤害的情况(详细信息将在第5.3节中讨论)。
有害的双重提取:有害的双取或double-fetch错误是指在特定情况下,实际上可能导致内核失败的双重获取,例如,可能由用户进程触发的竞争条件。
Double-fetch漏洞:一旦竞争条件造成的后果可被利用,double-fetch错误也可能转化为double-fetch漏洞,例如通过缓冲区溢出,导致权限提升、信息泄露或内核崩溃。
在本文中,我们研究了有害的双重获取和良性的双重获取。尽管良性的双取目前不易受攻击,但当代码在未来更改或更新时(当重复使用双取数据时),其中一些可能会变成有害的双取。此外,当其中一个获取是冗余的时,一些良性的双重获取可能会导致性能下降(在第5节中讨论)。
Double-fetch漏洞不仅出现在Windows内核中,也出现在Linux内核中。图2显示了Linux 2.6.9中的一个double-fetch错误,报告为CVE-2005-2490。在compat.c文件中,当用户控制的内容通过sendmsg()复制到内核时,相同的用户数据会被访问两次,而第二次不会进行健全性检查。这可能会导致内核缓冲区溢出,因此可能导致权限提升。函数cmsghdr_from_user_compat_to_kern()分两步工作:它首先检查第一个循环中的参数(第151行),然后复制第二个循环中(第184行)的数据。然而,只有ucmlen的第一次提取(第152行)在使用前被检查(第156–161行),而在第二次提取后(第185行),在使用前没有检查,这可能会导致复制操作(第195行)中的溢出,可以利用该溢出通过修改消息来执行任意代码。

已经提出了许多在存储器访问级别进行数据竞争检测的方法。静态方法在不运行程序的情况下分析程序。然而,它们的主要缺点是,由于缺乏程序的完整执行上下文,它们会生成大量错误报告。动态方法执行程序以验证数据争用,检查争用是否会导致程序在执行中失败。动态方法通常控制活动线程调度程序来触发特定的间隔,以增加错误出现的概率。然而,运行时开销是一个严重的问题,驱动程序代码的测试需要特定硬件或专用模拟的支持。不幸的是,现有的数据竞争检测方法(无论是静态还是动态)都不能直接应用于double-fetch错误检测,原因如下:
(1) double-fetch错误是由内核和用户空间之间的竞争条件引起的,这与常见的数据竞争不同,因为竞争条件是由内核空间和用户空间分隔的。对于数据竞争,读取和写入操作存在于相同的地址空间中,并且以前的大多数方法通过识别访问相同存储器位置的所有读取和写入操作来检测数据竞争。然而,double-fetch错误的情况有所不同。内核只包含两个读操作,而写操作则驻留在用户线程中。此外,如果内核有可能两次提取并使用同一内存位置,则会出现double-fetch错误,因为恶意用户进程可能被专门设计为在第一次和第二次提取之间进行写入。
(2) 内核的参与使得double-fetch错误在访问数据的方式上不同于数据竞争。在Linux中,从用户空间到内核空间的数据提取依赖于传递给传递函数的特定参数(例如,copy_from_user()和get_user()),而不是直接解除用户指针关联,这意味着基于指针解引用的常规数据竞争检测方法不再适用。
(3) 此外,Linux中的double-fetch错误比Windows中常见的数据竞争或double-fetch错误更复杂。如图3所示,Linux中的double-fetch错误需要第一次提取来复制数据,通常随后是第一次检查或使用复制的数据,然后是第二次提取来再次复制相同的数据,第二次使用相同的数据。尽管可以通过匹配提取操作的模式来定位双取,但提取的数据的使用会有很大差异。例如,除了用于验证之外,第一个提取的值还可以复制到其他地方供以后使用,这意味着第一次使用(或检查)可能暂时不存在。此外,提取的值可以作为参数传递给其他函数以供进一步使用。因此,在本文中,我们将双重提取中的用途定义为条件检查(读取数据进行比较)、对其他变量的赋值、函数调用参数传递或使用提取的数据进行计算。我们需要考虑这些双重获取特性。

由于这些原因,识别double-fetch错误需要专门的分析,而以前的方法要么不适用,要么无效。
2.4 Coccinelle
Coccinelle是一个程序匹配和转换引擎,具有专用语言SmPL(语义补丁语言),用于在C代码中指定所需的匹配和转换。Coccinelle最初的目标是Linux驱动程序的并行进化,但现在被广泛用于查找和修复系统代码中的错误。
Coccinelle遍历控制流图的策略是基于时间逻辑CTL(计算树逻辑),并且在Coccinele上实现的模式匹配是路径敏感的,从而实现了更好的代码覆盖。Coccinelle经过高度优化,可以在穷尽所有执行路径时提高性能。此外,Coccinelle对换行、空格、注释等不敏感。此外,基于模式的分析直接应用于源代码,因此定义为宏的操作,如get_user()或__get_user(),在匹配过程中不会扩展,这有助于基于传递函数的识别来检测双取。因此,Coccinelle是我们进行基于模式匹配的双取研究的合适工具。
3 Linux内核中的双重获取
在本文中,我们对Linux内核中的双重获取的研究分为两个阶段。如图4所示,在第一阶段,我们使用Coccinelle引擎分析Linux内核,使用一个基本的double-fetch模式来识别一个函数何时多次调用一个传递函数。然后,我们手动调查模式匹配找到的候选文件,根据与错误相关的上下文信息,对发生双重提取的场景以及何时容易发生double-fetch错误或漏洞进行分类。在第二阶段,基于从手动分析中获得的知识,我们使用Coccinelle引擎开发了一个更精确的分析,以系统地检测整个内核中的double-fetch错误和漏洞,我们还使用它来额外分析FreeBSD和Android。

3.1 基本模式匹配分析
在某些情况下,很难避免双重提取,并且Linux内核中存在大量函数,可以两次提取相同的数据。根据定义,当同一用户数据在短时间内被提取两次时,内核中可能会发生双重提取。因此,我们可以得出一个基本模式,用于匹配所有潜在的double-fetch情况。该模式与内核函数使用传递函数从同一用户内存区域提取数据至少两次的情况相匹配。在Linux内核的情况下,要匹配的传递函数主要是get_user()和copy_from_user()的所有变体。该模式允许拷贝的目标和拷贝数据的大小不同,但拷贝的源(用户空间中的地址)必须相同。如图4所示,我们在Coccinelle引擎中实现了基本的模式匹配。
我们的方法检查Linux内核的所有源代码文件,并检查内核函数是否包含两个或多个从同一用户指针获取数据的传输函数调用。在39906个Linux源文件中,17532个文件属于驱动程序(44%),10398个文件属于非x86硬件架构(26%),这些文件无法用Jurczyk和Coldwind基于x86的技术进行分析。我们手动分析了匹配的内核函数,以推断关于双取特征的知识,即用户数据如何传输到内核并在内核中使用,这有助于我们对double-fetch情况进行分类,正如我们在第3.2节中所讨论的那样。手动分析还帮助我们完善了模式匹配方法,并更准确地检测到实际的double-fetch错误,如第3.3节所述。
在调查过程中,我们注意到,在很多情况下,传递函数从不同的地址或从相同的地址提取数据,但偏移量不同。例如,内核函数可以单独获取特定结构的元素,而不是将整个结构复制到内核。通过向该结构的起始地址添加不同的偏移量,内核将分别获取该结构的不同元素,从而导致多次获取。另一种常见的情况是向源指针添加固定的偏移量,以便单独处理长消息,或者只使用自增量(++)在循环中自动处理消息。所有这些情况都是由基本模式匹配引起的误报,我们的初始报告中有226例被确定为误报,在我们的细化阶段,这些误报已被自动删除,因为它们不被视为double-fetch情况,也不会导致double-fetch错误,因为每条消息只提取一次。
我们研究的第一阶段集中于理解容易发生双重获取的环境,而不是彻底发现潜在的double-fetch错误。尽管分析和表征并不是完全自动化的,但它只有90个候选需要手动调查,只花了几天时间就对它们进行了分析,这使得我们的方法所需的手动工作是可以接受的。
3.2 双重提取分类
当我们手动检查双取候选时,我们注意到有三种常见的情况容易发生双取,我们将其分类为类型选择、大小检查和浅拷贝。我们现在详细讨论这些问题。
大多数情况下,通过调用一个传递函数就可以直接将数据从用户空间复制到内核空间。然而,当数据具有可变类型或可变长度时,情况会变得复杂,这取决于数据本身。此类数据通常以标头开头,后跟数据的正文。在下文中,我们将这些数据视为消息,因为我们根据经验发现,驱动程序经常使用可变数据从用户空间向硬件传递消息。
图5说明了这个场景:从用户空间复制到内核(驱动程序)空间的消息通常由两部分组成,即头部和主体。标头包含有关消息的一些元信息,例如消息类型的指示符或消息正文的大小。由于消息有不同的类型,消息长度也可能不同,内核通常首先获取(复制)报头,以决定需要创建哪个缓冲区类型,或者需要为完整的消息分配多少空间。然后,第二次提取将完整的消息复制到指定类型或大小的已分配缓冲区中。第二次提取不仅复制正文,还复制包括已经提取的头的完整消息。因为消息的头被提取(复制)了两次,所以会出现两次提取的情况。当使用来自第二次提取的大小或类型信息时,由于用户可能已经在两次提取之间改变了大小或类型的信息,因此double-fetch情况变成double-fetch错误。例如,如果大小信息被用来控制缓冲区访问,那么double-fetch错误就会变成一个漏洞。

只需在第二次提取中复制消息主体,然后将标头与主体连接,就可以很容易地避免消息标头被复制两次的双重提取情况。然而,在第二步中复制完整的消息更方便,因此在Linux内核中经常发生这种double-fetch情况。此外,Linux内核的大部分都是旧的,也就是说,它们是在知道或理解double-fetch错误之前开发的。因此,我们将更详细地讨论内核中的这种double-fetch情况,并强调我们在手动分析过程中发现的三种情况。
3.2.1 类型选择
当消息头用于类型选择时,会发生双重获取的常见情况。换言之,首先提取消息的标头以识别消息类型,然后根据识别的类型提取和处理整个消息。我们已经观察到,在Linux内核中,一个驱动程序中的一个函数被设计为通过使用switch语句结构来处理多种类型的消息,这是非常常见的,在switch语句结构中,每个特定的消息类型都被提取,然后被处理。第一次提取的结果(消息类型)用于switch语句的条件,在switch的每种情况下,消息都会通过第二次提取复制到特定类型的本地缓冲区(然后进行处理)。
图6显示了由于文件cxgb3_main.c(网络驱动程序的一部分)中的类型选择而导致的double-fetch情况的示例。函数cxgb_extension_ioctl()首先在第2136行从指向用户空间useraddr的指针中取出消息类型(用于所连接硬件的命令)到cmd中。然后,它根据cmd决定消息的类型(例如,CHELSIP_SET_QSET_PARAMS,CHELSIP_SET_QSET_NUM或CHELSIO_SETMTUTAB),并将完整的消息复制到相应的结构中(类型为ch_QSET_PARAMS,ch_reg,ch_mtus,…)。消息的类型将作为整个消息的一部分进行第二次提取(分别为2149、2292、2355行)。只要不再使用消息的头部分,这种情况下的双重提取就不会导致double-fetch错误。然而,如果再次使用第二次提取的标头部分(类型/命令),则可能会出现问题,因为恶意用户可能在两次提取之间更改了标头。在cxgb_extension_ioctl()的情况下,一项手动调查显示,缓冲区t,edata,m,…中没有使用类型部分,并且此处的double-fetch情况不会导致double-fetch漏洞。

我们发现11次出现这种double-fetch类别,其中9次出现在驱动程序中。11次出现中没有一次使用第二次获取的头部,因此,它们不会导致double-fetch错误。
3.2.2 大小检查
当消息的实际长度可能发生变化时,会出现另一种常见情况。在这种情况下,消息头用于标识完整消息的大小。首先将消息头复制到内核以获得消息大小(第一次提取),检查其有效性,并分配必要大小的本地缓冲区,然后进行第二次提取,将整个消息(也包括头)复制到分配的缓冲区中。只要只使用第一次提取的大小,而不是从第二次提取的标头中检索,在这种情况下的双重提取就不会导致double-fetch漏洞或错误。然而,如果从第二次获取的标头中检索并使用大小,内核就会变得容易受到攻击,因为恶意用户可能已经更改了标头的大小元素。
在Linux 4.5的Adaptec RAID控制器驱动程序的commctrl.c文件中发现了一个这样的double-fetch错误(CVE-2016-6480)。图7显示了负责的函数ioctl_send_fib(),它在第81行和第116行两次通过copy_from_user()从指针arg指向的用户空间中获取数据。第一个获取的值用于计算缓冲区大小(第90行),检查大小的有效性(第93行),并分配计算大小的缓冲区(第101行),而第二个副本(第116行)获取具有计算大小的整个消息。请注意,指向存储消息的内核缓冲区的变量kfib在第101行中被重用。消息的报头很大,并且在第二次提取消息之后使用报头的各种元素(例如,第121和129行中的kfib->header.Command)。该函数还在第130行第二次使用标头的大小元素,导致double-fetch漏洞,因为恶意用户可能在两次提取之间更改了标头的大小字段。

我们观察到30次此类大小检查double-fetch情况的发生,其中22次发生在驱动程序中,其中4次(均发生在驱动器中)易受攻击。
3.2.3 浅拷贝
我们确定的double-fetch场景的最后一个特殊情况是我们所说的浅拷贝问题。当用户空间中的缓冲区(第一个缓冲区)被复制到内核空间,并且缓冲区包含指向用户空间中另一个缓冲区(第二个缓冲区时)的指针时,就会发生用户和内核空间之间的浅拷贝。传递函数只复制第一个缓冲区(浅拷贝),第二个缓冲区必须通过传递函数的第二次调用来复制(以执行深度拷贝)。有时需要将数据从用户空间复制到内核空间,对数据进行操作,然后将数据复制回用户空间。这样的数据通常包含在用户空间中的第二缓冲区中,并由包含附加数据的用户空间中第一缓冲区中的指针指向。传输函数执行浅拷贝,因此传输函数拷贝的缓冲区中指向的数据也必须显式拷贝,以便执行深度拷贝。这种深度复制将导致对传输函数的多次调用,这些调用不一定是双重获取,因为每个传输函数都是用不同的要复制的缓冲区调用的。我们观察到了其中31种情况,其中19种发生在驱动上。
使用只执行浅拷贝的传输函数执行深度拷贝的复杂性可能会导致程序员引入错误,我们在IBM S/390 SCLP控制台驱动程序的sclp_ctl.c文件中发现了一个这样的错误,该错误是由浅拷贝问题引起的(CVE-2016-6130)。图8中的函数sclp_ctl_ioctl_sccb将数据结构从user_area指向的用户空间浅层复制到ctl_sccb中(第61行)。要进行深度复制,它必须从ctl_sccb.sccb指向的用户空间复制另一个数据结构。然而,数据结构的大小是可变的,这导致了大小检查的情况。为了复制数据,它首先将数据结构的头部提取到由sccb指向的新创建的内核空间中(第68行),以获得以sccb->length为单位的数据长度,该数据长度在第72行中被检查是否有效。然后,基于sccb->length,它通过第74行中的第二次提取来复制整个内容。最后,在第81行,数据被复制回用户空间。虽然看起来第74行和第81行中的两个传递函数调用都使用相同的长度sccb->length,但第81行实际使用第74行中复制的值(第二次提取),而第74行使用第一次提取的值。

同样,这是一个double-fetch错误,因为用户可能已经改变了第68行和第74行中两次提取之间的值。然而,这个double-fetch错误并没有导致漏洞,因为内核既不会因给定给传递函数的无效大小而崩溃,也不会在内核复制回超过其先前接收到的大小的数据时发生信息泄漏,因为复制的缓冲区位于其自己的内存页中。触发错误的尝试将简单地以系统调用的终止结束,并在第82行中显示错误代码。Linux 4.6中已经消除了double-fetch错误。
3.3 精细的Double-Fetch错误检测
在本节中,我们介绍了我们研究的第二阶段,该阶段使用了一种改进的double-fetch错误检测方法,该方法再次基于Coccinelle匹配引擎。虽然我们研究的第一阶段是识别和分类发生双重提取的场景,但第二阶段利用从第一阶段获得的知识来设计改进的分析,旨在专门识别double-fetch错误和漏洞。
如图9所示,除了基本的double-fetch模式匹配规则(规则0)(当两个读取从同一源位置提取数据时会触发该规则)之外,我们还添加了以下五个附加规则,以提高精度并发现角点情况。Coccinelle引擎在分析源文件时逐一应用这些规则。double-fetch错误可能涉及不同的传输函数,因此,我们必须考虑从用户空间复制数据的四个传输函数(get_user()、__get_user()、__get_user()、__ copy_from.user())。我们在图9中使用trans_func()来表示Linux内核中任何可能的传递函数。
规则1:不更改指针。检测double-fetch错误的最关键规则是在两次获取之间保持用户指针不变。否则,每次都会提取不同的数据,而不是重复提取相同的数据,这可能会导致误报。从图9中的规则1可以看出,这种变化可能包括自增量(++)、添加偏移或分配另一个值的情况,以及相应的减法情况。
规则2:指针别名。指针别名在double-fetch情况下很常见。在某些情况下,用户指针被分配给另一个指针,因为原始指针可能会被更改(例如,在循环中逐段处理长消息),而使用两个指针更方便,一个用于检查数据,另一个用于使用数据。从图9中的规则2可以看出,这种赋值可能出现在函数的开头或两个fetch之间。缺少混叠情况可能会导致假阴性。
规则3:显式类型转换。当内核从用户空间获取数据时,显式指针类型转换被广泛使用。例如,在大小检查场景中,消息指针将被转换为标头指针,以在第一次获取中获取标头,然后在第二次获取中再次用作消息指针。从图9中的规则3可以看出,两个源指针中的任何一个都可能涉及类型转换。缺少类型转换的情况可能会导致假阴性。此外,显式指针类型转换通常与指针别名相结合,导致同一内存区域由两种类型的指针操作。
规则4:元素提取和指针提取的组合。在某些情况下,用户指针既用于获取整个数据结构,也用于通过将指针解引用到数据结构的元素来仅获取一部分。例如,在大小检查场景中,用户指针首先用于通过get_user(len,ptr->len)获取消息长度,然后通过get_user(len,ptr->len)在第二次获取中复制整个消息,这意味着两次获取使用的指针与传递函数参数不完全相同,但它们在语义上涵盖了相同的值。正如我们从图9中的规则4中看到的那样,这种情况可能使用用户指针或数据结构的地址作为传递函数的参数。这种情况通常在显式指针类型转换时出现,如果错过这种情况,可能会导致假阴性。

规则5:循环参与。由于Coccinelle对路径敏感,当代码中出现循环时,循环中的一个传递函数调用将被报告为两个调用,这可能会导致误报。此外,从图9中的规则5可以看出,当一个循环中有两次提取时,上一次迭代的第二次提取和下一次迭代中的第一次提取将作为双提取进行匹配。这种情况应该作为假阳性删除,因为在遍历迭代时应该更改用户指针,并且这两次获取的值不同。此外,使用数组在循环中复制不同值的情况也会导致误报。
4 评估
在本节中,我们介绍了对我们研究的评估,其中包括两个部分:手动分析的统计数据,以及将改进方法应用于三个开源内核(Linux、Android和FreeBSD)时的结果。我们获得了分析时可用的最新版本。
4.1 统计与分析
在Linux 4.5中,总共有52881个文件,其中39906个是源文件(文件扩展名为.c或.h),它们是我们的分析目标(其他文件被忽略)。17532个源文件属于驱动程序(44%)。在对源文件进行基本模式匹配并进行手动检查以消除误报后,我们获得了90个double-fetch候选文件以供进一步检查。我们将候选文件分为三种double-fetch场景:大小检查、类型选择和浅拷贝。它们是关于在用户空间数据被复制到内核空间时如何进行双重提取以及如何在内核中使用数据的最常见情况。在上一节中,我们已经用真实的double-fetch错误示例详细讨论了这些场景。如表1所示,在我们发现的90个候选文件中,30个与大小检查场景有关,11个与类型选择场景有关,31个与浅拷贝场景有关,分别占33%、12%和34%。18名候选文件不符合这三种情况中的一种。

此外,90份候选文件中有57份是Linux驱动程序的一部分,其中22份与大小检查有关,9份与类型选择有关,19份与浅拷贝有关。
最重要的是,我们发现了五个以前未知的双取错误,其中包括四个大小检查场景和一个浅拷贝场景,后者也属于大小检查场景。其中三个是可利用的漏洞。这五个错误已经被报告,它们都得到了开发人员的确认,同时也得到了修复。从统计结果中,我们可以观察到以下几点:
- 90份候选文件中有57份(63%)与驱动有关,30份中有22份(73%)进行大小检查,11份中有9份(82%)进行类型选择,31份中有19份(61%)进行浅拷贝。
- 我们在驱动程序中发现的五分之四(80%)的double-fetch错误属于大小检查类别。
总的来说,这导致了这样一个结论,即大多数双取不会导致double-fetch错误,并且在驱动程序中更有可能发生双取。然而,一旦由于大小检查而导致双取,开发人员就必须小心:驱动程序中22个大小检查场景中有4个是double-fetch错误。
4.2 三个开源内核的分析
在双取基本模式匹配和手动分析的基础上,我们改进了双取模式,并开发了一种新的基于Coccinelle引擎的double-fetch错误检测分析。为了充分评估我们的方法,我们分析了三个流行的开源内核,即Linux、Android和FreeBSD。结果如表2所示。

对于Linux内核,实验是在4.5版本上进行的,这是进行实验时的最新版本。分析耗时约10分钟,报告了53份候选文件。对53份候选文件的调查揭示了五个真正的double-fetch错误,这也是通过之前的手动分析发现的。在报告的文件中,23份与大小检查有关,6份与类型选择有关。
对于Android,尽管它也使用Linux作为内核,但我们分析了基于Linux 3.18的6.0.1版本。Android内核和原始Linux内核之间仍然存在差异:Android内核是主流的Linux内核,具有特定Android设备的附加驱动程序,以及其他附加功能,如增强的电源管理或更快的图形支持。我们的分析花了大约9分钟,报告了48份候选文件,其中包括原始Linux内核报告中未包含的7份文件。在报告的候选漏洞中,有三个是真正的double-fetch漏洞,其中两个与上面的Linux 4.5报告共享,还有一个仅针对Android报告。在结果中,18份候选文件与大小检查有关,6份候选文件与类型选择有关。
对于FreeBSD,我们需要将传递函数copy_from_user()和__copy_from-user()更改为FreeBSD中的相应函数,即copyin()和copyin_nofault()。我们从主分支获得了源代码。这项分析花了大约2分钟的时间,只报告了16个文件,但没有一个文件是易受攻击的double-fetch错误。在报告的候选文件中,8份与大小检查有关,3份与类型选择有关。值得注意的是,这16份文件中有5份是良性的双取,这可能是double-fetch错误,但被额外的检查方案阻止了。FreeBSD的开发人员似乎更清楚double-fetch错误,并试图积极防止它们。相比之下,对于Linux,53份报告中只有5个受到额外检查方案的保护。
在这个实验中,我们只计算了大小检查和类型选择的情况,因为改进的模式匹配方法丢弃了不会导致double-fetch错误的浅拷贝情况。我们的方法与从同一内存区域提取数据的双提取模式相匹配,该模式在浅拷贝的情况下忽略第一个缓冲区的提取,而只考虑对同一个第二缓冲区的多次提取。这种浅拷贝情况通常与其他场景相结合,如大小检查和类型选择。在表2中,Linux内核的大小检查案例还包括一个发生在浅拷贝场景中的案例。
5 讨论
在本节中,我们将讨论Linux 4.5中发现的double-fetch错误和漏洞,以及如何在出现double-fetch情况时防止double-fetch错误。我们还解释了我们的发现和我们方法的局限性。
5.1 检测到的错误和漏洞
根据我们的方法,我们总共发现了六个双取错误。其中五个是以前从未报告过的未知错误(CVE-2016-5728、-6130、6136、-6156、-6480),第六个(CVE-2015-1420)是最新Android系统(6.0.1版本)中存在的一个double-fetch错误,该系统基于包含该错误的旧Linux内核(3.18版本),自Linux 4.1以来,该错误已在主流Linux内核中修复。五个新错误中有三个是可利用的double-fetch漏洞(CVE-2016-5728、-6136、-6480)。五个中有四个在驱动程序中(CVE-2016-5728、-6130、-6156、-6480)。所有的错误都已经报告给了Linux内核维护人员,他们已经确认了这些错误。从Linux 4.8开始,所有这些报告的错误都已修复。我们在FreeBSD中没有发现任何新的双取错误。检测到的错误的详细信息如表3所示。

所提出的方法识别了大量的double-fetch情况,其中只有少量是double-fetch错误(甚至是漏洞)。然而,尽管我们称之为良性double-fetch情况的目前没有错误,但当代码更新时,如果不特别注意double-fetch情况,它们很容易变成double-fetch错误或漏洞。我们在调查double-fetch漏洞CVE-2016-5728的补丁历史时观察到了这种情况的发生。当开发人员将功能从MIC主机驱动程序转移到Virtio Over PCIe(VOP)驱动程序时,引入了第二个提取值的重用,从而引入了double-fetch错误。我们未来工作的一个主要部分将是防止这种良性的双重获取情况转变为有害的情况。
在手动检查Linux内核源代码文件的随机样本时,我们没有发现任何假阴性。
5.2 对照
只有少数系统性的研究是针对双重提取进行的。Bochspwn是唯一一种足够相似的方法,可以与之进行比较。使用Bochspwn对Linux 3.5.0进行的分析没有发现任何double-fetch错误,同时产生了高达200KB的double-fetch日志。在同一内核中,我们的方法确定了上述6个double-fetch错误中的3个(我们发现的其他3个错误位于Linux 3.5.0中不存在的文件中)。
Bochspwn很可能找不到这些错误,因为它们存在于驱动程序中。事实上,如果没有相应的硬件或硬件模拟,动态方法就无法支持驱动程序。Bochspwn报告内核的指令覆盖率仅为28%,而我们的方法静态分析完整的源代码。
至于效率,我们的方法只需要几分钟就可以对整个Linux内核的源代码进行路径敏感的探索。相比之下,Bochspwn引入了严重的运行时开销。例如,他们的模拟器需要15个小时才能启动Windows内核。
虽然只花了几天时间就调查了90次double-fetch情况,但Jurczyk和Coldwind没有报告他们调查模拟器生成的200KBdouble-fetch日志所需的时间。
5.3 Double-Fetch错误预防
尽管我们提供了检测double-fetch错误的分析,但开发人员仍然必须意识到它们是如何发生的,并先发制人地防止双取错误。在处理导致新的double-fetch情况的可变消息时,在驱动程序开发中预计会出现人为错误。
(1) 不要复制标头两次。 如果第二次提取只复制消息体,而不是第二次复制头的完整消息,则可以完全避免双重提取的情况。例如,Android 6.0.1(Linux 3.18)中的double-fetch漏洞在Linux 4.1中通过仅在第二次提取中复制主体来解决。
(2) 使用相同的值。 当使用两次提取操作中的“相同”数据时,由于(恶意)用户可以在两次提取之间更改数据,因此double-fetch情况会变成错误。如果开发人员只使用其中一个获取的数据,那么问题就可以避免。根据我们的调查,大多数double-fetch情况都是良性的,因为它们只使用第一个提取的值。
(3) 覆盖数据。 还有一些情况下,数据必须被提取并使用两次,例如,完整的消息被传递给不同的函数进行处理。解决这种情况并消除double-fetch错误的一种方法是用第一次提取的标头覆盖第二次提取的标头。即使恶意用户在两次获取之间更改了标头,更改也不会产生影响。这种方法在FreeBSD代码中被广泛采用,例如在sys/dev/aac/aac.c和sys/dev/aacraid/aacraid.c中。
(4) 比较数据。 解决double-fetch错误的另一种方法是在使用前将第一次fetch的数据与第二次fetch中的数据进行比较。如果数据不相同,则必须中止操作。
(5) 同步获取。 防止double-fetch错误的最后一种方法是使用同步方法来保证两个不可分割的操作(如锁或关键部分)的原子性。只要我们保证提取的值在两次提取之间不会发生变化,那么多次提取就不会出错。然而,由于同步是在关键部分引入的,这种方法将对内核造成性能损失。
由于比较数据方法不需要修改太多源代码,我们发现的大多数已识别的double-fetch错误都已由Linux开发人员以这种方式进行了修补(CVE-2016-5728、6130、-6156、-6480)。如果两次获取的重叠数据段不相同,那么内核现在将返回一个错误。有人可能会说,最好使用其他前三个建议中的任何一个来避免重复获取标头。然而,比较数据有两个优点:它不仅可以检测恶意用户的攻击,还可以防止数据在没有恶意的情况下被更改(例如,用户空间代码中的一些错误)。
我们在Coccinelle中实现了Compare Data方法,作为一个自动补丁,它注入代码,在发现double-fetch错误的地方比较第一次提取的数据和第二次提取的结果。它能够自动修补所有大小检查double-fetch错误,这占了大多数已识别的错误(5/6)。
5.4 结果解释
双取是内核开发的一个基本问题。流行的操作系统,如Windows、Linux、Android和FreeBSD,过去都有double-fetch错误和漏洞。Double-fetch问题由来已久,我们发现的一个错误(CVE-20166480)已经存在了十多年。
双重提取在内核中很普遍,有时也是不可避免的。我们根据检测到的事件对三种典型的双取场景进行了分类。63%的双重提取发生在驱动程序中,这意味着驱动程序是重灾区。五个新错误中有四个属于大小检查场景,这表明可变长度消息处理需要检查double-fetch错误。
在Linux内核中,double-fetch错误比Windows中更复杂,因为在double-fetch错误中,传输函数将取和使用分离开来,这使得很难将良性的和易受攻击的双取分离开来。以前的动态方法在Linux中没有发现任何double-fetch错误,而我们的静态方法发现了一些错误,证明了简单静态分析的能力。
我们的方法需要手动检查,但是,由于未来的分析可能仅限于更改的文件,因此不必对整个内核重复手动检查。此外,开发一种能够以更高精度自动识别double-fetch错误的静态分析,将比开发我们目前的方法、在不同内核上运行它以及一起调查结果的手动方法花费更多的时间。此外,在我们进行分析和分类之前,还不知道在哪些情况下,Linux内核知识中会出现double-fetch错误,这是设计更精确的静态double-fetch错误分析所必需的。使用改进的方法,只需要查看53个潜在的double-fetch错误,而不需要查看90个double-fetch情况。因此,我们方法中的手动分析部分是不可避免的,但非常有益。
至于预防,所有四个大小检查错误都是通过Compare Data方法修补的,这表明由于修补后的情况仍然会返回错误而中止客户端程序,因此无法完全避免双重获取。此外,即使是良性的double-fetch情况也不安全,因为它们很容易变成有害的情况。一个这样的错误(CVE-2016-5728)是通过代码更新从良性的double-fetch情况中引入的。然而,这些潜在问题中的大多数并没有得到修复,因为它们目前并不易受攻击。
即使双取是良性的,即不易受攻击,也可以将其视为性能问题,因为其中一个取(调用传输函数)是冗余的。
5.5 局限性
我们通过对源代码的基于模式的分析,重点分析了Linux中发生双重获取的情况。然而,分析的性质防止检测到在较低级别上发生的双重获取,例如,在预处理或编译的代码中。
在宏中甚至可能出现Double-fetch错误。在一种这样的情况中,宏获取指针两次,第一次是测试NULL,第二次是使用它。但是,由于两次获取之间可能发生指针更改,可能会导致空指针崩溃。
通过编译器优化也可以引入double-fetch错误。然后它会出现在编译后的二进制文件中,但不会出现在源代码中。Wilhelm最近在Xen Hypervisor中发现了这样一个编译器生成的double-fetch错误,这是因为指向共享内存区域的指针没有标记为易失性,允许编译器在二进制级别将单个内存访问转换为多个访问,因为它假设内存不会更改。
6 相关工作
到目前为止,对double-fetch分析的研究只集中在动态分析上,而我们提出了一种静态分析方法。除了已经讨论过的关于Bochspwn的工作之外,还有一些相关的研究如下。
Wilhelm使用了与Bochspwn类似的方法来分析准虚拟化设备后端组件的内存访问模式。他的分析发现了39个潜在的双重获取问题,并在安全关键的后端组件中发现了三个新的安全漏洞。其中一个发现的漏洞不存在于源代码中,而是通过编译器优化引入的(请参阅第5.5节中的讨论)。此外,源代码中发现的另一个漏洞通常是不可利用的,因为编译器优化代码的方式是将第二次获取替换为重用第一次获取的值。
Double-fetch竞争条件与Time Of Check to Time Of Use(TOCTOU)竞争条件非常相似,后者是由检查条件和使用检查结果之间发生的变化(条件不再成立)引起的。TOCTOU中的数据不一致通常是由对共享对象的不正确同步并发访问导致的竞争条件引起的。任何计算机系统中都有各种共享对象,如文件、套接字和内存位置,因此,TOCTOU可以存在于整个系统的不同层中。TOCTOU竞争条件经常出现在文件系统中,已经提出了许多方法来解决这些问题,但应用程序仍然没有通用的、安全的方法来以无竞争的方式访问文件系统。
Watson致力于利用来自系统调用插入的包装器并发漏洞。他专注于包装漏洞,这些漏洞将导致权限提升和审计绕过等安全问题。通过识别与访问控制、审计或其他跨信任边界同时访问的安全功能相关的资源,他发现了包装器中的漏洞,并通过示例演示了利用技术。除了检查时间到使用时间问题外,他还将审计时间和使用时间以及更换时间和使用使用时间问题进行了分类。然而,他关注的是系统调用插入安全扩展,而不是像我们那样关注内核。他也没有提供他是如何发现这些漏洞的细节。
Yang等人通过研究46种不同类型的攻击,对外部的并发攻击进行了分类,并介绍了它们的特征。他们指出,并发攻击的风险与漏洞窗口的持续时间成正比。此外,他们发现以前的TOCTOU检测和预防技术过于具体,无法检测或预防一般的并发攻击。
Coccinelle是我们在方法中使用的程序匹配和转换引擎,最初用于Linux驱动程序的并行优化,但现在被广泛用于查找和修复系统代码中的错误。与Coccinelle一起,Nicolas等人对2003年至2011年间发布的所有Linux版本进行了研究,这是在Chou等人工作十年后。Chou等人对Linux中发现的故障进行了首次彻底研究。Nicolas等人指出,十年前考虑的故障类型仍然相关,并且仍然存在于新的和现有的文件中。他们还发现,所考虑的故障类型在驱动程序目录中的比率正在下降,这支持了Chou等人。
7 结论
这项工作首次(据我们所知)对Linux内核中的双取进行了静态分析。这是第一种能够在包括所有驱动程序和所有硬件体系结构在内的完整内核中检测double-fetch漏洞的方法(使用动态方法是不可能的)。基于我们基于模式的静态分析,我们对三种典型的情况进行了分类,在这三种情况下容易发生双取。我们还提供了针对我们在研究中发现的典型double-fetch场景的推荐解决方案,以防止double-fetch错误和漏洞。一种解决方案用于自动修补double-fetch错误,它能够自动修补在大小检查场景中发现的所有错误。
在对Linux、FreeBSD和OpenBSD内核进行的已知动态分析没有发现double-fetch漏洞的情况下,我们的静态分析发现了六个真正的double-fetch漏洞,其中五个是以前未知的漏洞,三个是可利用的double-fetch漏洞。所有报告的错误都已得到维护人员的确认和修复。我们的方法已经被Coccinelle团队采用,目前正在集成到Linux内核补丁审查中。
致谢
作者衷心感谢所有的审稿人在这篇论文上投入的时间和专业知识。您富有洞察力的评论有助于我们改进这项工作。这项工作得到了国家重点研发计划(2016YFB0200401)、大学新世纪优秀人才计划、国家科学基金61402492、61402486、61379146、61472437和实验室预研基金(9140C810106150C81001)的部分支持。
总结
以上就是本篇论文翻译的全部内容了,读完这篇论文后,我对Double-Fetch漏洞的成因以及检测有了更深入的了解,有一种醍醐灌顶的感觉,同时我也在本地部署了本论文的测试环境,经过测试发现,基于本论文所提出的方法的三种Double-Fetch漏洞检测工具的效果都十分不错,后面如果有时间,我会分享本篇论文的阅读笔记!