作者:Enrico Zimuel

这些天每个人都在谈论 ChatGPT。 这种大型语言模型 (LLM) 的一项很酷的功能是能够生成代码。 我们用它来生成 Elasticsearch DSL 查询。 目标是在 Elasticsearch® 中搜索 “给我股票指数中 2017 年的前 10 个文档(Give me the first 10 documents of 2017 from the stocks index.)” 这样的句子。 这个实验表明这是可能的,但有一些局限性。 在这篇文章中,我们描述了这个实验和我们为这个用例发布的开源库。
ChatGPT 可以生成 Elasticsearch DSL 吗?
我们从一些侧重于 ChatGPT 生成 Elasticsearch DSL 查询的能力的测试开始实验。 对于此范围,你需要向 ChatGPT 提供一些关于你要搜索的数据结构的上下文。
在 Elasticsearch 中,数据存储在索引中,类似于关系数据库中的 “table”。 它有一个定义多个字段及其类型的映射。 这意味着我们需要提供我们要查询的索引的映射信息。 通过这样做,ChatGPT 拥有必要的上下文来将查询转换为 Elasticsearch DSL。
Elasticsearch 提供了一个获取映射 API 来检索索引的映射。 在我们的实验中,我们使用了此处提供的股票指数数据集。 该数据集包含 500 家财富公司五年的股价,时间跨度为 2013 年 2 月至 2018 年 2 月。
在这里,我们报告了包含数据集的 CSV 文件的前五行:
date,open,high,low,close,volume,name
2013-02-08,15.07,15.12,14.63,14.75,8407500,AAL
2013-02-11,14.89,15.01,14.26,14.46,8882000,AAL
2013-02-12,14.45,14.51,14.1,14.27,8126000,AAL
2013-02-13,14.3,14.94,14.25,14.66,10259500,AAL每行包含股票的日期、当天的开盘价、最高价和最低价、收盘价、股票交易量,最后是股票名称 —— 例如,美国航空集团公司 (AAL) ).
与股票指数相关的映射如下:
{
"stocks": {
"mappings": {
"properties": {
"close": {"type":"float"},
"date" : {"type":"date"},
"high" : {"type":"float"},
"low" : {"type":"float"},
"name" : {
"type": "text",
"fields": {
"keyword":{"type":"keyword", "ignore_above":256}
}
},
"open" : {"type":"float"},
"volume": {"type":"long"}
}
}
}
}我们可以使用 GET /stocks/_mapping API 从 Elasticsearch 检索映射。
[相关文章:ChatGPT 和 Elasticsearch:OpenAI 遇见私有数据]
让我们建立一个提示来找出答案
为了将用人类语言表达的查询翻译成 Elasticsearch DSL,我们需要找到正确的提示给 ChatGPT。 这是该过程中最困难的部分:使用正确的问题格式(换句话说,正确的提示)对 ChatGPT 进行实际编程。
经过一些迭代后,我们得到了以下似乎运行良好的提示:
Given the mapping delimited by triple backticks ```{mapping}``` translate the text delimited by triple quotes in a valid Elasticsearch DSL query """{query}""". Give me only the json code part of the answer. Compress the json output removing spaces.
提示中的值 {mapping} 和 {query} 是两个占位符,需要替换为 mapping json 字符串(例如上例中 GET /stocks/_mapping 返回)和人类语言表达的 query(例如 : 返回 2017 年的前 10 个文件)。
当然,ChatGPT 是有限的,在某些情况下它无法回答问题。 我们发现,大多数情况下,发生这种情况是因为提示中使用的句子过于笼统或模棱两可。 为了解决这种情况,我们需要使用更多细节来增强提示。 这个过程称为迭代,它需要多个步骤来定义要使用的正确句子。
如果你想尝试 ChatGPT 如何翻译 Elasticsearch DSL 查询(甚至 SQL)中的搜索语句,你可以使用 dsltranslate.com。在文章 “Elasticsearch:人类语言到 Elasticsearch 查询 DSL” 有详细介绍。
把它们放在一起
使用 OpenAI 提供的 ChatGPT API 和用于映射和搜索的 Elasticsearch API,我们将它们放在一个 PHP 的实验库中。
该库使用以下 API 公开 search() 函数:
search(string $index, string $prompt, bool $cache = true)其中 $index 是要使用的索引名称,$prompt 是用人类语言表达的查询,$bool 是使用缓存的可选参数(默认启用)。
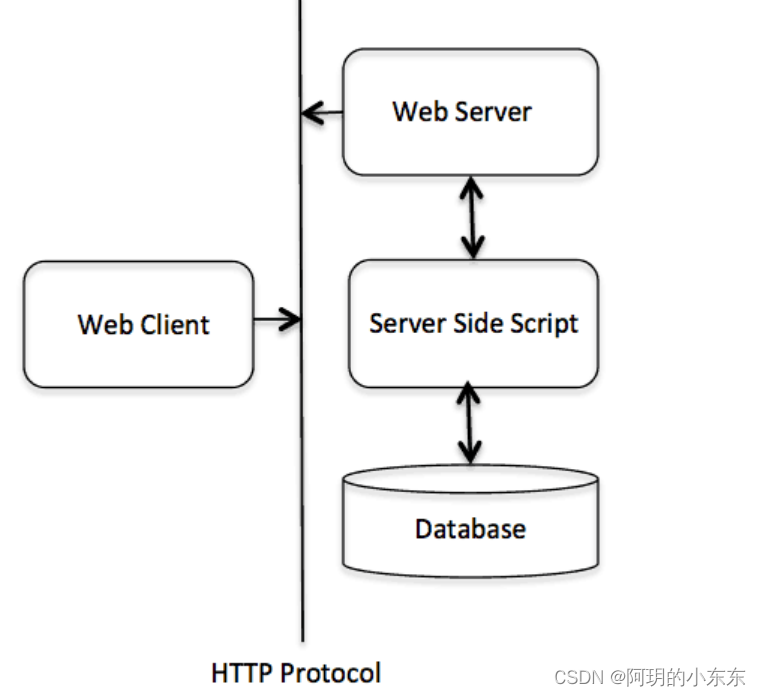
该函数的流程如下图所示:
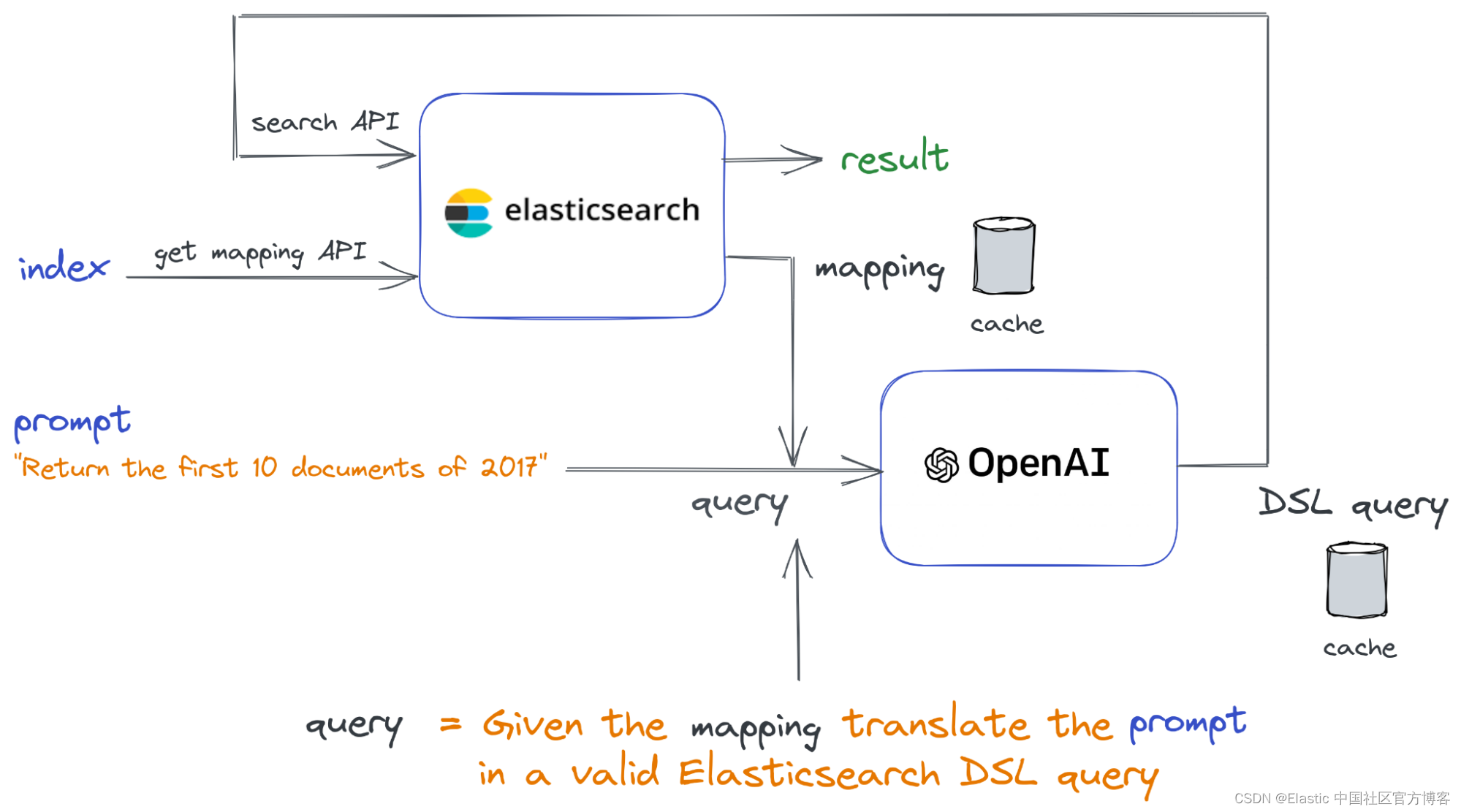
输入是 index 和 prompt(提示,在左侧)。 索引用于从 Elasticsearch 检索映射(使用获取映射 API)。 结果是 JSON 中的映射,用于构建查询字符串以使用以下 API 代码发送到 ChatGPT。 我们使用了能够在代码中翻译的 OpenAI 的 gpt-3.5-turbo 模型。
ChatGPT 的结果包含我们用来查询 Elasticsearch 的 Elasticsearch DSL 查询。 然后将结果返回给用户。 为了查询 Elasticsearch,我们使用了官方的 elastic/elasticsearch-php 客户端。
为了优化响应时间并降低使用 ChatGPT API 的成本,我们使用了一个基于文件的简单缓存系统。 我们使用缓存来:
- 存储 Elasticsearch 返回的映射 JSON:我们将此 JSON 存储在以索引命名的文件中。 这使我们无需额外调用 Elasticsearch 即可检索映射信息。
- 存储 ChatGPT 生成的 Elasticsearch DSL:为了缓存生成的 Elasticsearch DSL,我们使用所用提示的哈希 (MD5) 命名缓存文件。 这种方法使我们能够为同一查询重用之前生成的 Elasticsearch DSL,无需再次调用 ChatGPT API。
我们还添加了使用 getLastQuery() 函数以编程方式检索 Elasticsearch DSL 的可能性。
使用财务数据运行实验
我们使用 Elastic Cloud 来存储此处报告的股票价值。 特别是,我们使用了一个简单的批量脚本来读取 CSV 格式的股票文件,并使用 bulk API 将其发送到 Elasticsearch。
有关如何设置 Elastic cloud 和获取 API 密钥的更多详细信息,请阅读文档。
一旦我们存储了股票索引,我们就使用了一个简单的 PHP 脚本来测试一些用英语表达的查询。 我们使用的脚本是 examples/test.php。
要执行这个 examples/test.php 脚本,我们需要设置三个环境变量:
- OPENAI_API_KEY:OpenAI 的 API 密钥
- ELASTIC_CLOUD_ENDPOINT:Elasticsearch 实例的 url
- ELASTIC_CLOUD_API_KEY:Elastic Cloud 的 API 密钥
使用股票映射,我们测试了以下记录所有 Elasticsearch DSL 响应的查询:
Query: Return the first 10 documents of 2017
Result:
{
"query":{
"range":{
"date":{
"gte":"2017-01-01",
"lte":"2017-12-31"
}
}
},
"size":10
}Query: Return the first 30 names of all the different stock names
Result:
{
"size":0,
"aggs":{
"unique_names":{
"terms":{
"field":"name.keyword",
"size":30
}
}
}
}Query: Return the max value of the field "high" for each stock in 2015
Result:
{
"aggs":{
"stocks":{
"terms":{"field":"name.keyword","size":100},
"aggs":{
"max_high":{"max":{"field":"high"}}
}
}
},
"query":{
"bool":{
"must":[{
"range":{
"date":{
"gte":"2015-01-01",
"lt":"2016-01-01"
}
}
}]
}
}
}Query: Return the average value of the field "high" for each stock in 2015
Result:
{
"size":0,
"aggs":{
"stocks":{
"terms":{
"field":"name.keyword",
"size":10000
},
"aggs":{
"2015":{
"filter":{
"range":{
"date":{
"gte":"2015-01-01",
"lt":"2016-01-01"
}
}
},
"aggs":{
"avg_high":{
"avg":{
"field":"high"
}
}
}
}
}
}
}
}Query: Return the max value of the field "high" for all the documents with name MON in 2014
Result:
{
"query":{
"bool":{
"must":[
{
"match":{
"name.keyword":"MON"
}
},
{
"range":{
"date":{
"gte":"2014-01-01",
"lt":"2015-01-01"
}
}
}
]
}
},
"size":0,
"aggs":{
"max_high":{
"max":{
"field":"high"
}
}
}
}Query: Return the documents that have the difference between close and open fields > 20
Response:
{
"query":{
"bool":{
"must":[
{
"script":{
"script":{
"lang":"painless",
"source":"doc['close'].value - doc['open'].value > 20"
}
}
}
]
}
}
}如您所见,结果非常好。 最后一个关于封闭和开放领域之间的区别令人印象深刻!
所有请求都已翻译成有效的 Elasticsearch DSL 查询,该查询根据以自然语言表达的问题是正确的。
使用你所说的语言!
ChatGPT 的一个非常好的功能是能够用不同的语言指定问题。
这意味着你可以使用该库并以不同的自然语言指定查询,例如意大利语、西班牙语、法语、德语等。
这是一个例子:
# English
$result = $chatGPT->search('stocks', 'Return the first 10 documents of 2017');
# Italian
$result = $chatGPT->search('stocks', 'Restituisci i primi 10 documenti del 2017');
# Spanish
$result = $chatGPT->search('stocks', 'Devuelve los 10 primeros documentos de 2017');
# French
$result = $chatGPT->search('stocks', 'Retourner les 10 premiers documents de 2017');
# German
$result = $chatGPT->search('stocks', 'Senden Sie die ersten 10 Dokumente des Jahres 2017 zurück');之前的所有搜索都有相同的结果,产生以下 Elasticsearch 查询(或多或少):
{"size":10,"query":{"range":{"date":{"gte":"2017-01-01","lt":"2018-01-01"}}}}重要提示:ChatGPT 是针对英语进行了优化的 LLM,这意味着使用英语输入的查询可以获得最佳结果。
LLM 的局限性
不幸的是,ChatGPT 和 LLM 通常无法从语义的角度验证答案的正确性。 他们给出的答案从统计的角度来看是正确的。 这意味着,我们无法测试 ChatGPT 生成的 Elasticsearch DSL 查询是否是自然语言查询的正确翻译。
当然,目前这是一个很大的限制。 在其他一些用例中,例如数学运算,我们可以使用外部插件解决正确性问题,例如 ChatGPT 的 Wolfram 插件。 在这种情况下,ChatGPT 的结果使用 Wolfram 引擎,该引擎使用数学符号模型检查响应的正确性。
除了正确性限制(这意味着我们应该始终检查 ChatGPT 的答案)之外,在 Elasticsearch DSL 查询中翻译人类句子的能力也存在限制。
例如,如果我们提出以下问题,则使用之前的股票数据集:
Query: Return the first 10 documents of 2017 and 2015
Result:
{
"from":0,
"size":10,
"query":{
"bool":{
"must":[
{
"range":{
"date":{
"gte":"2015-01-01",
"lte":"2015-12-31",
"format":"yyyy"
}
}
},
{
"range":{
"date":{
"gte":"2017-01-01",
"lte":"2017-12-31",
"format":"yyyy"
}
}
}
]
}
}
}ChatGPT 生成的 DSL 查询无效,产生此 Elasticsearch 错误:
Failed to parse date field [2015-01-01] with format [yyyy].如果我们使用更具体的信息改写句子,消除日期格式的明显歧义,我们可以检索正确的答案,如下所示:
Query: Return the first 10 documents with year 2017 and 2015 in "date" field
Result:
{
"size":10,
"query":{
"bool":{
"should":[
{
"term":{
"date":"2017"
}
},
{
"term":{
"date":"2015"
}
}
]
}
}
}基本上,句子必须使用 Elasticsearch DSL 应该如何的描述而不是真实的人类句子来表达。
总结起来
在这篇文章中,我们展示了一个 ChatGPT 的实验性用例,用于将自然语言搜索句子翻译成 Elasticsearch DSL 查询。 我们用 PHP 开发了一个简单的库,用于使用 OpenAI API 在底层翻译查询,还提供了一个缓存系统。
实验的结果是有希望的,即使答案的正确性受到限制。 也就是说,我们肯定会进一步研究使用 ChatGPT 以及其他越来越流行的 LLM 模型以自然语言查询 Elasticsearch 的可能性。
详细了解 Elasticsearch 和 AI 的可能性。
在这篇博文中,我们可能使用了由其各自所有者拥有和运营的第三方生成人工智能工具。 Elastic 对第三方工具没有任何控制权,我们对其内容、操作或使用不承担任何责任,也不对您使用此类工具可能造成的任何损失或损害承担任何责任。 使用带有个人、敏感或机密信息的 AI 工具时请谨慎行事。 您提交的任何数据都可能用于人工智能训练或其他目的。 无法保证您提供的信息将得到安全保护或保密。 在使用之前,您应该熟悉任何生成人工智能工具的隐私惯例和使用条款。
Elastic、Elasticsearch 和相关标记是 Elasticsearch N.V. 在美国和其他国家/地区的商标、徽标或注册商标。 所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。