概述
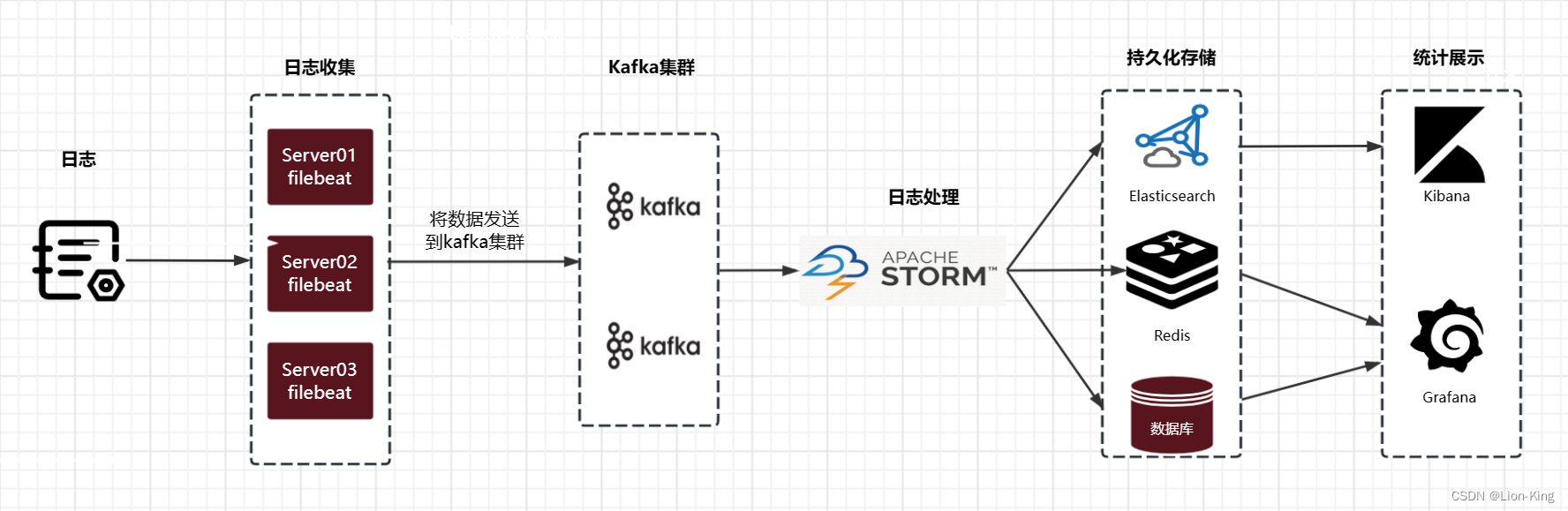
Kafka是一个基于Zookeeper的分布式消息中间件,支持消息分区,提供发布和订阅功能。使用Scala编写,主要特点是可水平扩展,高吞吐率以及高并发。
常见的使用场景:
- 企业级别活动数据和运营数据的消息传递,活动数据一般包括页面的访问,搜索。运营数据包括服务器上CPU,IO,用户活跃度等数据。
- 日志收集,收集的日志对接hadoop,Hbase,Elasticsearch等系统。
- 流式处理,支持spark streaming和storm。
基本架构以及概念
Kafka的主要工作原理是多个Producer发送Topic消息体到Kafka集群上,消息首先会存放在不同Broker对应的Leader分区上,Follower分区拉取Leader分区消息并写入日志,Consumer客户端同时也拉取Leader分区消息,完成消息消费。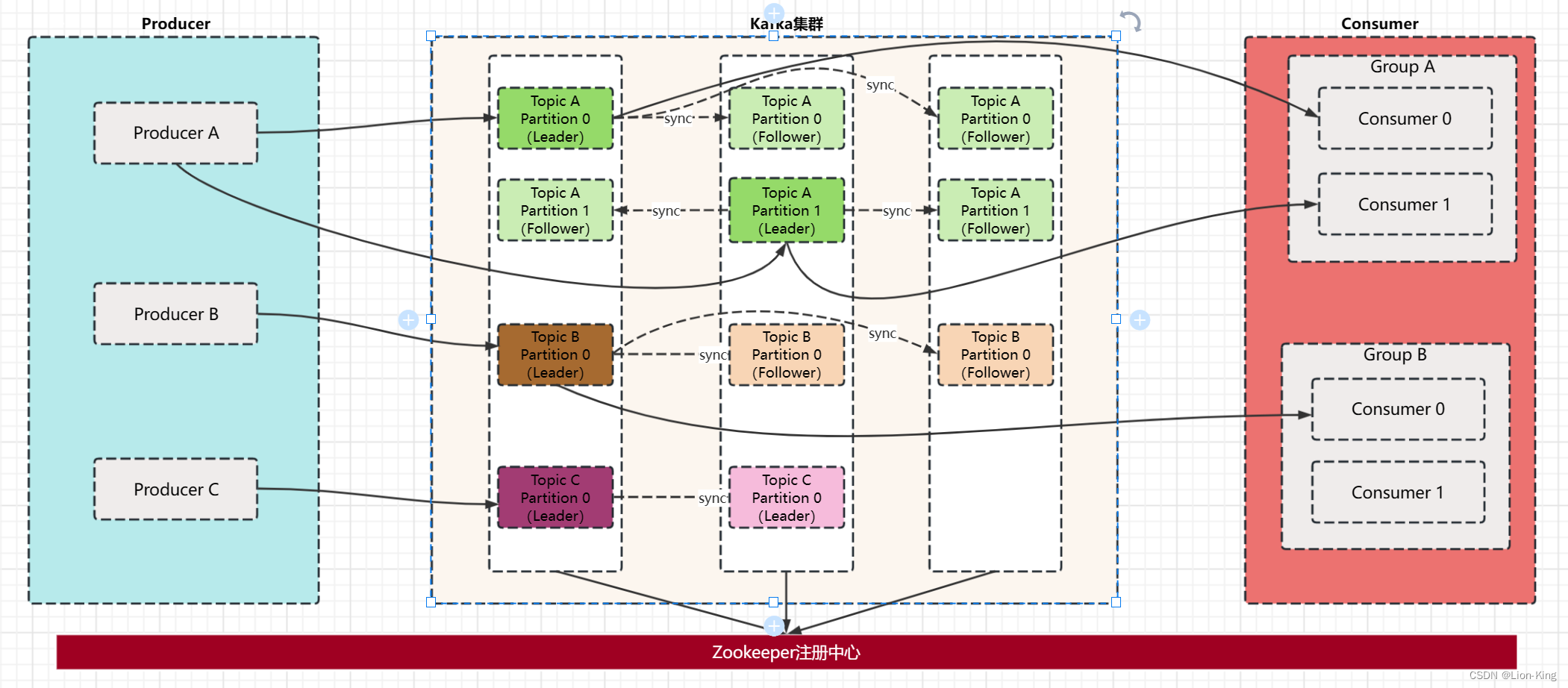
上图中,Kafka集群中有3台Broker,Kafka集群在启动的时候会将自身信息注册到Zookeeper集群中,保证信息的一致性。Producer有3个,分别发送Topic为A,B,C的消息体道Kafka集群中。Kafka集群中Topic A的Partition数为2,Replication数为3,Topic B的Partition数为1,Replication数为3,Topic C的Partition数为1,Replication数为2.每个Partition有主从之分,主Partition会接收Producer消息并共Consumer消费,从Partition只会从主Partition接收数据,不会和Producer以及Cosumer有直接联系。多个Consumer可以组成一个Group,同一group下不同的Consumer只能消费同一Topic下不同Partition的消息。例如Consumer Group A下的Consumer0和Consumer1只能分别消费Topic A中Partition0和Partition1的消息。
以下是Kafka部分概念解析
- Producer:消息生产者。
- Consumer:消息消费者。
- Consumer Group: 消费者群组,包含多个消费者,同组消费者消费同一个Topic下不同的分区的消息。
- Broker: Kafka实例,可以理解为不同的kafka服务器,每个都有一个唯一的编号。
- Message: 生产者传递给消费者的消息体。
- Topic: 消息主题,Broker上有不同的Topic, Message发送到不同的Topic供消费者消费。
- Partition: 相当于将消息进行了分发,一个Topic可以分为多个分区,消费者群组里面的消费者可以同时消费不同分区里面的消息,提高了吞吐量。
- Replication: 分区副本,默认最大为10个,不能大于Broker的数量,当分区的Leader挂掉之后,Follower继续工作,提供可靠性保证。
- Offset:消息持久化中消息的位置偏移信息。
- zookeeper: 保存Kafka集群的信息的Metadata,同样提供了可靠性保证
具体工作流程
- Producer发送数据到Broker
同一Topic下的消息在集群中有多个分区,Producer发送数据的时候总会发送给Leader分区,Leader分区再将数据同步给其他Follower分区,等待所有的Follower同步完成之后向Leader分区返回ack消息,Leader分区接收到所有的Follower分区ack之后向Producer发送ack,确认消息接收完成。

Leader分区的选择是首先所有Broker选取出一个Controller,由Controller指定分区的leader。
其中ACK应答机制是有参数可以设置的,值为0,1,all;来确定kafka是否有接收到数据,这3个参数的含义如下:
- 0:Producer发送完数据后直接返回,不会等待集群的ack消息
- 1:Producer只要leader分区应答ack即可,不用其他follower应答ack
- all: Producer要等待集群中所有分区都回复ack才会继续发送下一条数据,否则发送失败
ACK应答机制能够确保消息的可靠性。但是可靠性和消息交互速率是一对矛盾体。消息越可靠,相对传输速率就会降低。
同样,Producer发送消息到broker,到底发送到了那一个分区,通常遵循以下规则:
- Producer在发送时指定
- 如果没有指定但是设置了数据key, 就会对数据key进行hash,根据hash之后的值选定分区
- 如果上述两者都没有设定,则轮询选择分区
2. Broker保存数据
Kafka的数据是保存在磁盘的,之所以采用文件追加的方式进行存放,实际是采用了顺序IO的方式,避免随机IO造成大量的耗时。一个Topic有多个Partition,每个partition相当于一个有序的队列。每个parition以文件夹的形式存储在Broker上。
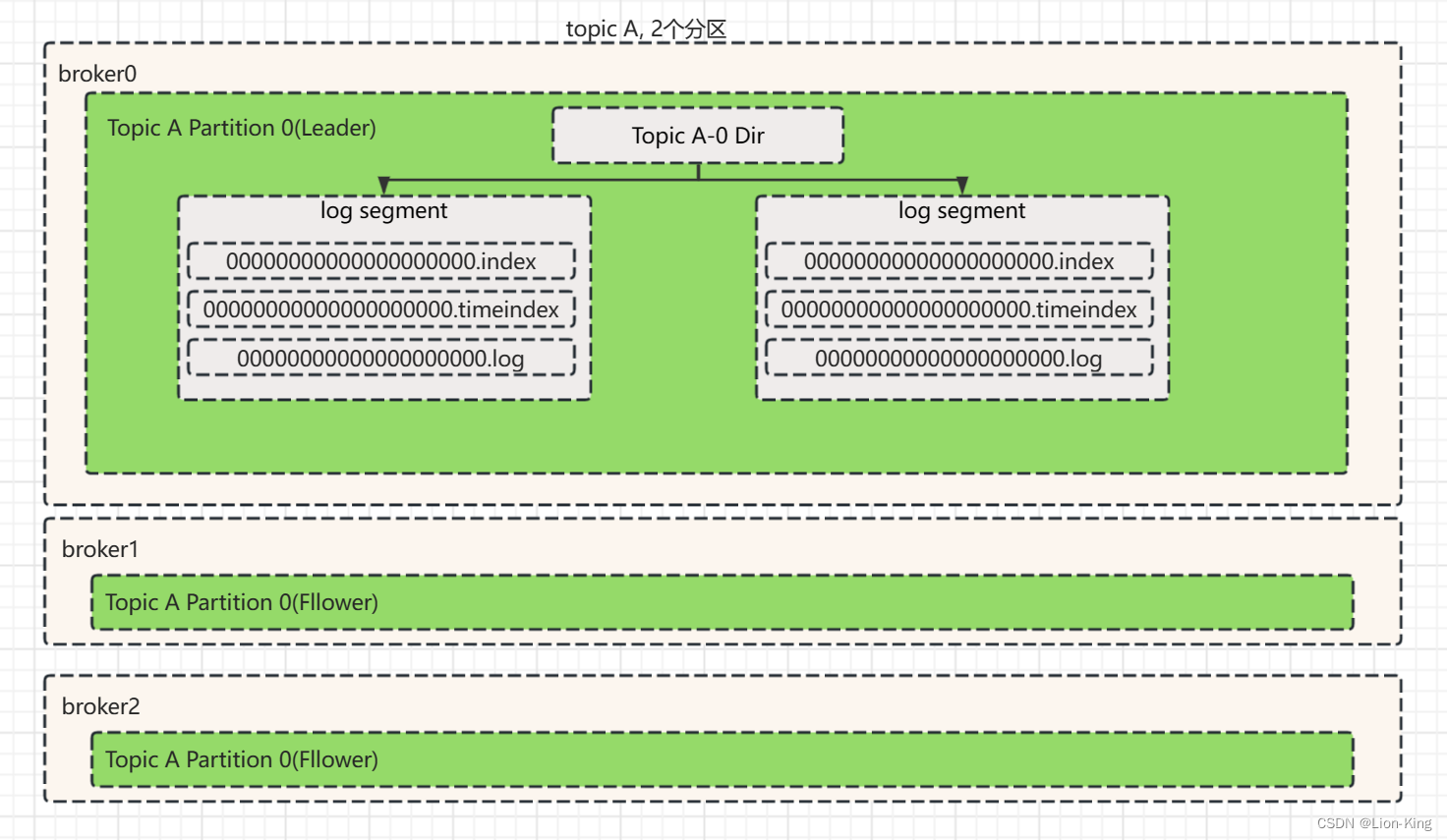
a) Partition存储结构
Partiion采用分段(segment)存储的方式,每段有3个文件:.log, .index, .timeindex。
| .log | 数据存储文件,存放位置position和消息对应关系 |
| .index | offset索引文件,存放offset和position对应关系,offset代表消息顺序,position代表消息在磁盘中的位置 |
| .timeindex | 时间索引文件, 存放时间戳和offset的对应关系 |
以下是Partition存放文件夹对应示意图。
b) Message存储结构
Message在.log文件中存放,具体字段和含义如下
| 字节 | 描述 |
| 8 | Position |
| 4 | 消息体大小 |
| 4 | CRC32校验值 |
| 1 | kafka版本号 |
| 1 | attributes |
| 4 | key的长度 |
| m | key的内容 |
| 4 | payload长度 |
| n | payload内容 |
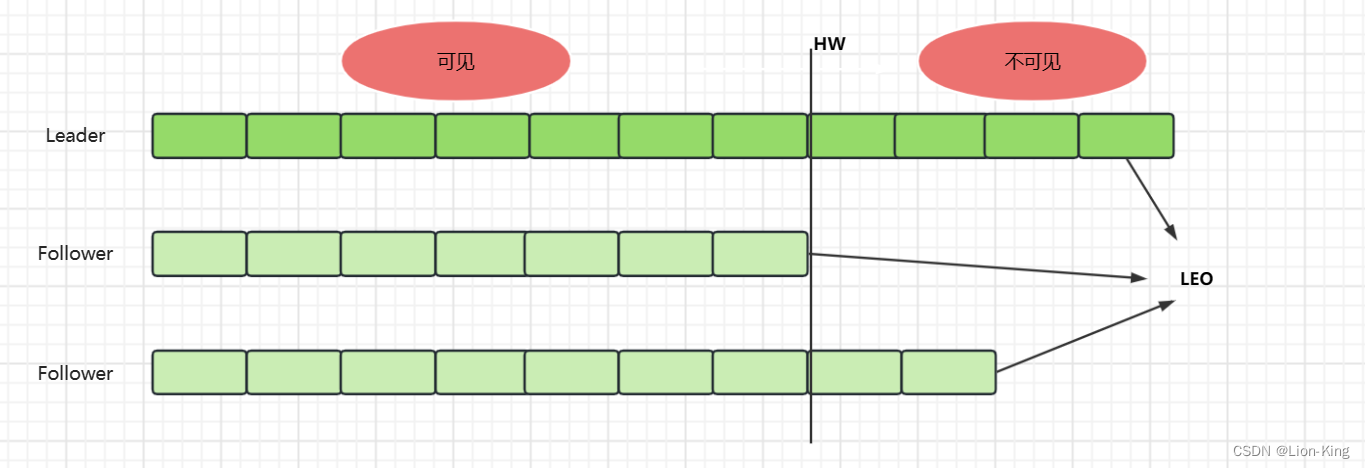
c) 两个概念LEO和HW
LEO(Log End Offset): 表示每个Partiotion log中最后一条message的offset位置。
HW(High Water Mark): 是统一Partiotion中各个Replicas数据同步一直的offset位置,该位置前的数据consumer可见,该位置之后不可见。
d)通过索引定位消息
以下是一个例子: 找出offset为7的消息内容
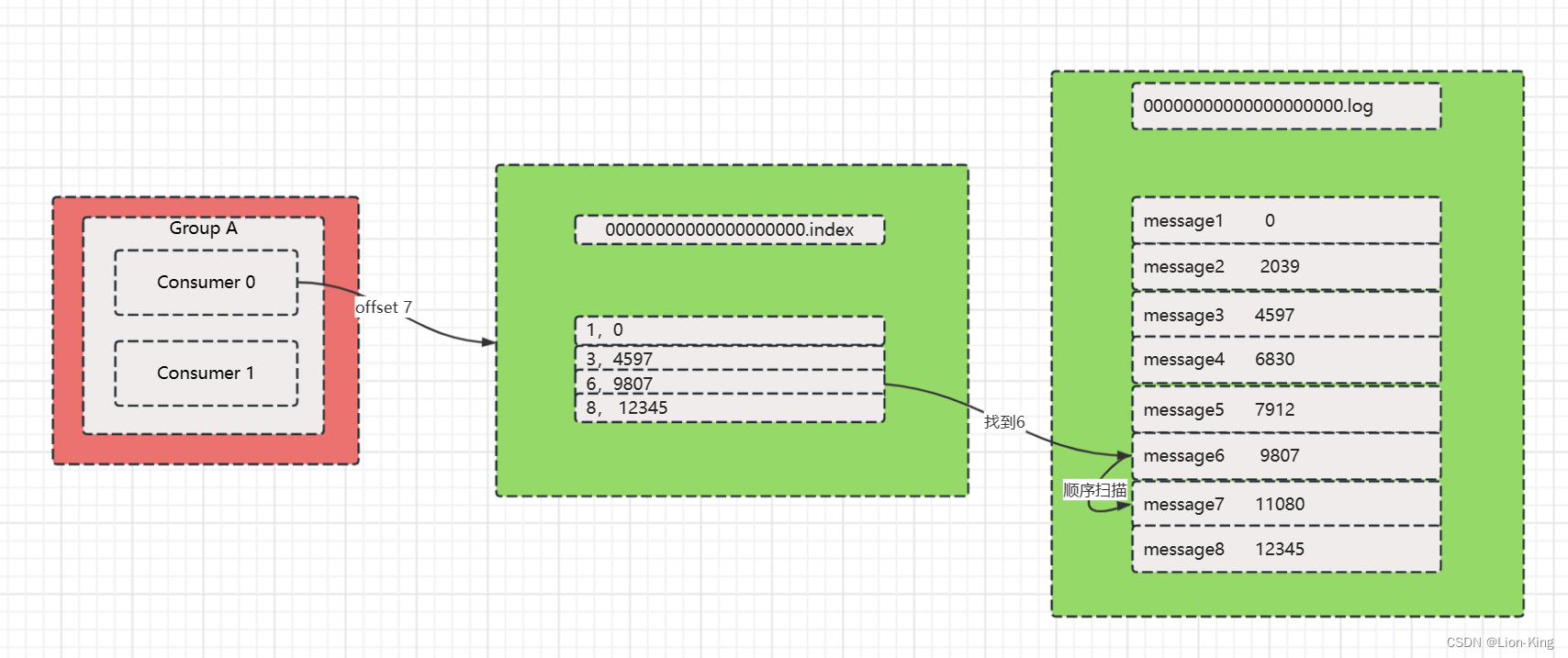
1)首先通过offset值7确定文件在哪个segment中,显然在00000000000000000.index,这一步是offset值和index文件名进行比对。
2)index文件索引采用的是稀疏索引进行存储,有可能恰好没有对应的offset值,所以这里是利用二分查找找到小于等于offset值的那条记录,这里找到offset=6,取出Message在log文件中的位置为9807。
3) 在log文件中从position为9807的位置顺序检索,首先找到的是offset为6的数据,然后加上消息体大小,定位出offset为7的数据位置,然后读取该message数据。
d) 数据清理策略
清理策略:时间和大小阈值(时间默认超过7天或者大小超过1G,清除日志)
#清理超过指定时间的消息,默认是168小时,7天,
#还有log.retention.ms, log.retention.minutes, log.retention.hours,优先级高到低
log.retention.hours=168
#超过指定大小后,删除旧的消息,下面是1G的字节数,-1就是没限制
log.retention.bytes=1073741824
3. Consumer消费数据:
消费者通常会有一个消费者群组,同一消费组中的消费者可以消费一个Topic不同分区的数据。不会有两个同组消费者消费同一topic下同一分区的消息。
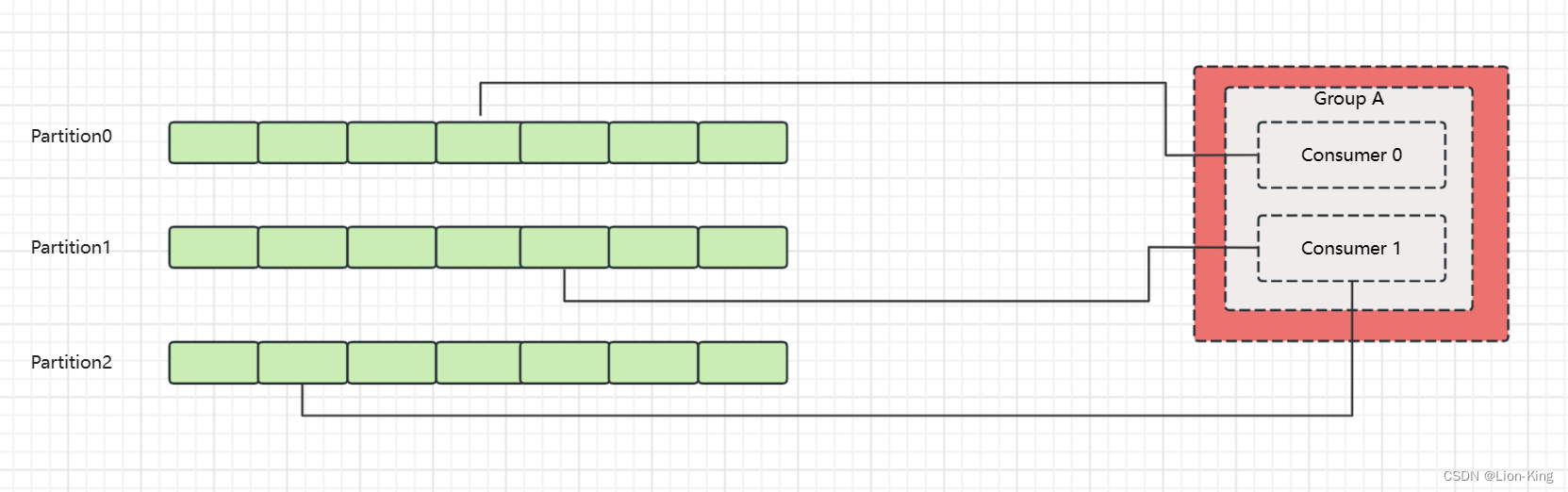
消费者记录消费消息的信息在早期版本会记录在zookeeper中,后边的版本统一记录在_consumer_offsets topic下。
集群搭建
本文采用docker-compose部署kafka集群以及UI页面,docker版本:18.06.3-ce docker-compose版本:1.24.1。下图中的10.232.112.13为宿主机的IP,注意需要替换
version: "3"
services:
zookeeper:
image: 'bitnami/zookeeper:3.6'
container_name: zookeeper
ports:
- '2181:2181'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
volumes:
- ./zookeeper:/bitnami/zookeeper
restart: always
kafka1:
image: 'bitnami/kafka:3.0'
container_name: kafka1
ports:
- '9092:9092'
environment:
- KAFKA_BROKER_ID=1
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://10.232.112.13:9092
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
# restart: always
depends_on:
- zookeeper
kafka2:
image: 'bitnami/kafka:3.0'
container_name: kafka2
ports:
- '9093:9093'
environment:
- KAFKA_BROKER_ID=2
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://10.232.112.13:9093
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
# restart: always
depends_on:
- zookeeper
kafka3:
image: 'bitnami/kafka:3.0'
container_name: kafka3
ports:
- '9094:9094'
environment:
- KAFKA_BROKER_ID=3
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://10.232.112.13:9094
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
# restart: always
depends_on:
- zookeeper
kafka-ui:
image: 'provectuslabs/kafka-ui'
container_name: kafka-ui
ports:
- "18080:8080"
environment:
- KAFKA_CLUSTERS_0_NAME=CLUUSTER001
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=10.232.112.13:9092
# restart: always
depends_on:
- zookeeper
- kafka1
- kafka2
- kafka3Demo代码
Producer代码
public class KProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException{
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","10.232.112.13:9192");
properties.setProperty("key.serializer", StringSerializer.class.getName());
properties.setProperty("value.serializer",StringSerializer.class.getName());
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
ProducerRecord<String, String> stringStringProducerRecord = new ProducerRecord<String, String>("Test",3,"testKey","hello");
Future<RecordMetadata> send = kafkaProducer.send(stringStringProducerRecord);
RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
}Consumer代码
public class KConsumer {
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","10.232.112.13:9192");
properties.setProperty("key.deserializer", StringDeserializer.class.getName());
properties.setProperty("value.deserializer",StringDeserializer.class.getName());
properties.setProperty("group.id","1111");
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Collections.singletonList("Test"));
while (true){
ConsumerRecords<String, String> poll = consumer.poll(500);
for (ConsumerRecord<String, String> stringStringConsumerRecord : poll) {
System.out.println("**********" + stringStringConsumerRecord.key() + stringStringConsumerRecord.value());
}
}
}
}Kafka的优缺点
优点:
1、高吞吐量:Kafka支持高吞吐量的传输,可以支持数千个客户端和每秒数百万条消息。
2、可扩展性:Kafka支持水平扩展,可以添加更多的节点来支持多客户端和更多的消息。
3、可靠性:Kafka支持消息的可靠传输,可以确保消息不会丢失。
4、低延迟:Kafka支持低延迟的消息传输,可以确保消息能够及时到达消费者。
缺点:
1、管理复杂性:Kafka的管理比较复杂,需要对Kafka集群进行维护和监控。
2、消息顺序:Kafka不能保证消息的顺序,因为消息可能会被分发到不同的分区中。
到这里,你了解Kafka了吗