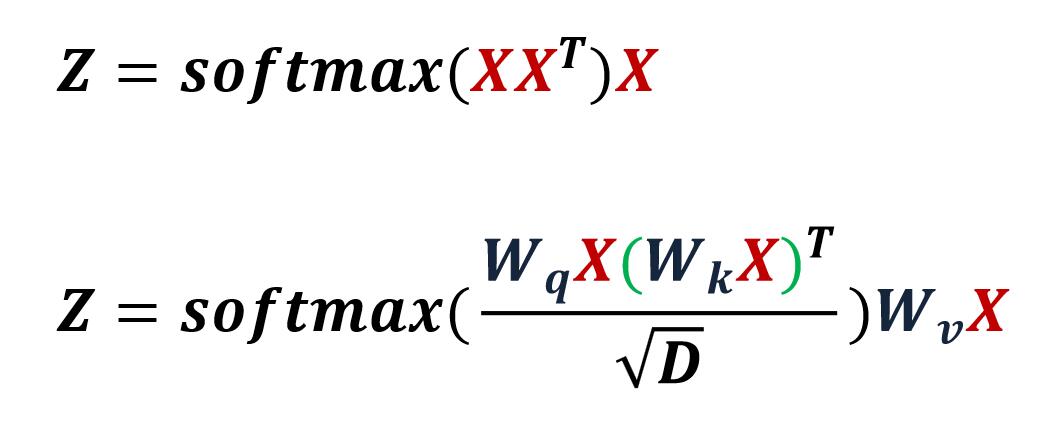看一下模型图:
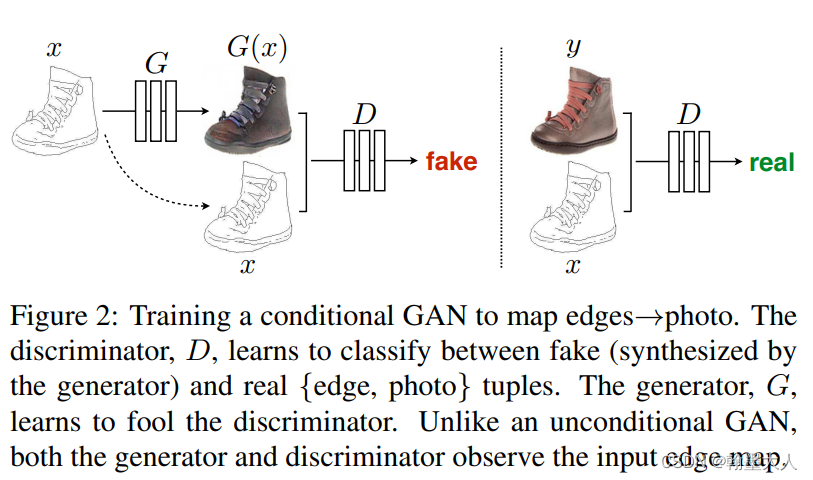
首先定义生成器G,和CGAN不同的是,pix2pix并没有输入噪声,而是采用dropout来增加随即性。然后生成器输入x,输出y都是一些图片。最后按照原文,G是一个U-Net shape的,除了上采样和下采样,最重要的是跳连接。
import torch
import torch.nn as nn
class Block(nn.Module):
def __init__(self, in_channels, out_channels, down=True, act="relu", use_dropout=False):
super(Block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 4, 2, 1, bias=False, padding_mode="reflect")
if down
else nn.ConvTranspose2d(in_channels, out_channels, 4, 2, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU() if act == "relu" else nn.LeakyReLU(0.2),
)
self.use_dropout = use_dropout
self.dropout = nn.Dropout(0.5)
self.down = down
def forward(self, x):
x = self.conv(x)
return self.dropout(x) if self.use_dropout else x
class Generator(nn.Module):
def __init__(self, in_channels=3, features=64):
super().__init__()
self.initial_down = nn.Sequential(
nn.Conv2d(in_channels, features, 4, 2, 1, padding_mode="reflect"),
nn.LeakyReLU(0.2),
)
self.down1 = Block(features, features * 2, down=True, act="leaky", use_dropout=False)
self.down2 = Block(
features * 2, features * 4, down=True, act="leaky", use_dropout=False
)
self.down3 = Block(
features * 4, features * 8, down=True, act="leaky", use_dropout=False
)
self.down4 = Block(
features * 8, features * 8, down=True, act="leaky", use_dropout=False
)
self.down5 = Block(
features * 8, features * 8, down=True, act="leaky", use_dropout=False
)
self.down6 = Block(
features * 8, features * 8, down=True, act="leaky", use_dropout=False
)
self.bottleneck = nn.Sequential(
nn.Conv2d(features * 8, features * 8, 4, 2, 1), nn.ReLU()
)
self.up1 = Block(features * 8, features * 8, down=False, act="relu", use_dropout=True)
self.up2 = Block(
features * 8 * 2, features * 8, down=False, act="relu", use_dropout=True
)
self.up3 = Block(
features * 8 * 2, features * 8, down=False, act="relu", use_dropout=True
)
self.up4 = Block(
features * 8 * 2, features * 8, down=False, act="relu", use_dropout=False
)
self.up5 = Block(
features * 8 * 2, features * 4, down=False, act="relu", use_dropout=False
)
self.up6 = Block(
features * 4 * 2, features * 2, down=False, act="relu", use_dropout=False
)
self.up7 = Block(features * 2 * 2, features, down=False, act="relu", use_dropout=False)
self.final_up = nn.Sequential(
nn.ConvTranspose2d(features * 2, in_channels, kernel_size=4, stride=2, padding=1),
nn.Tanh(),
)
def forward(self, x):#(1,3,256,256)
d1 = self.initial_down(x)#(1,64,128,128)
d2 = self.down1(d1)#(1,128,64,64)
d3 = self.down2(d2)#(1,256,32,32)
d4 = self.down3(d3)#(1,512,16,16)
d5 = self.down4(d4)#(1,512,8,8)
d6 = self.down5(d5)#(1,512,4,4)
d7 = self.down6(d6)#(1,512,2,2)
bottleneck = self.bottleneck(d7)#(1,512,1,1)
up1 = self.up1(bottleneck)#(1,512,2,2)
up2 = self.up2(torch.cat([up1, d7], 1))#(1,512,4,4)
up3 = self.up3(torch.cat([up2, d6], 1))#(1,512,8,8)
up4 = self.up4(torch.cat([up3, d5], 1))#(1,512,16,16)
up5 = self.up5(torch.cat([up4, d4], 1))#(1,256,32,32)
up6 = self.up6(torch.cat([up5, d3], 1))#(1,128,64,64)
up7 = self.up7(torch.cat([up6, d2], 1))#(1,64,128,128)
return self.final_up(torch.cat([up7, d1], 1))#(1,3,256,256)
def test():
x = torch.randn((1, 3, 256, 256))
model = Generator(in_channels=3, features=64)
preds = model(x)
print(preds.shape)
if __name__ == "__main__":
test()
这里随机生成一个和真实数据集大小的tensor进行验证。
首先使用第一个卷积:和常见的卷积不同的是卷积核大小为4,padd为reflect,后面没加BN,加的是LeakyReLU。
原始大小为(1,3,256,256)经过第一个卷积后变为((1,64,128,128))

接着经过6个down,就是encoder的连续下采样。
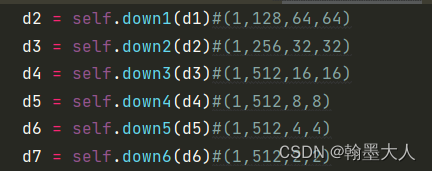
看一个,其他的也都一样。
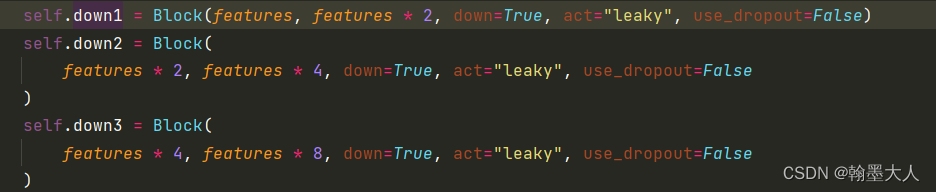
在Block内部:指定down,leakyrelu和dropout。如果指定了down那么使用步长为2的卷积进行下采样,如果未指定就使用转置卷积,后面紧接BN和leakyrelu。最后在encoder中不使用dropout。
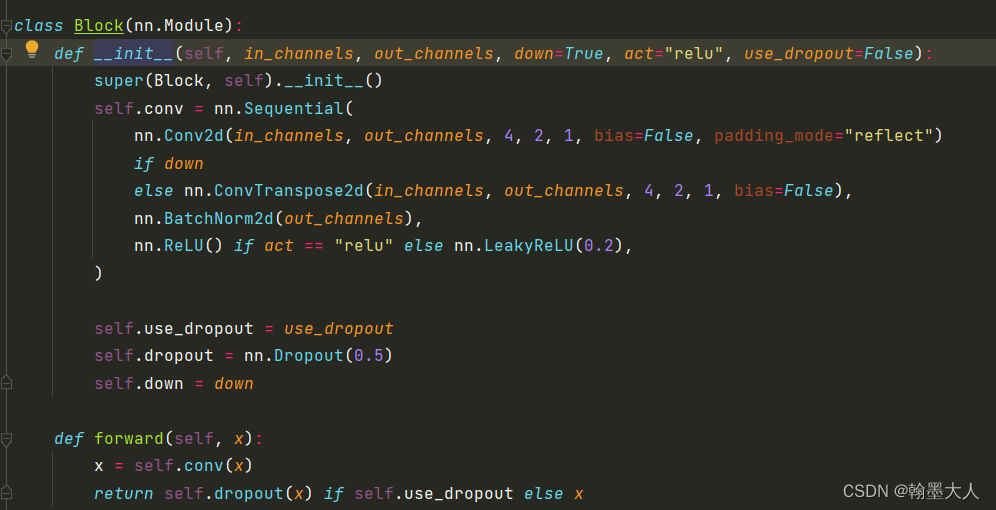
在encoder和decoder中间是bottleneck。是一个卷积加relu。


需要注意的是encoder的图片通道变换:不同于ResNet。

在decoder中首先进行上采样,才能和encoder对应层concat,否则大小不一无法concat。
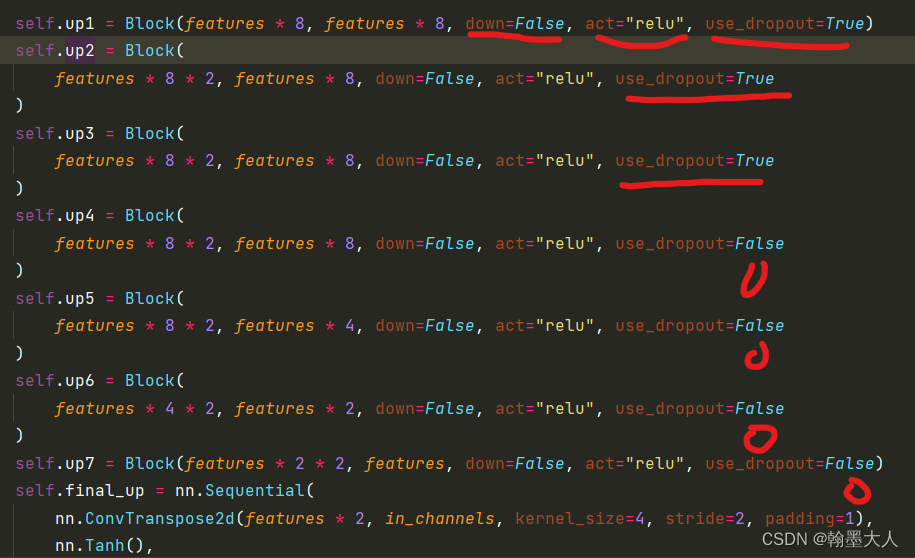
通过设置参数down为False,那么就采用的转置卷积,设置的激活函数为relu,且decoder前三层使用dropout。这些是和encoder不一样的地方。
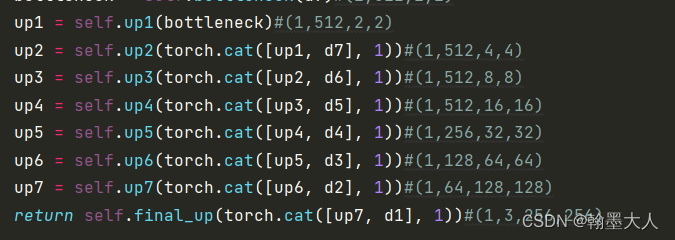
最终进过一个转置卷积和tanh得到最终的输出和原图像大小一样。
上述代码实现的是:
接着是辨别器:由原始论文知道采用的是patchGAN。在代码中也是通过卷积实现的。
import torch
import torch.nn as nn
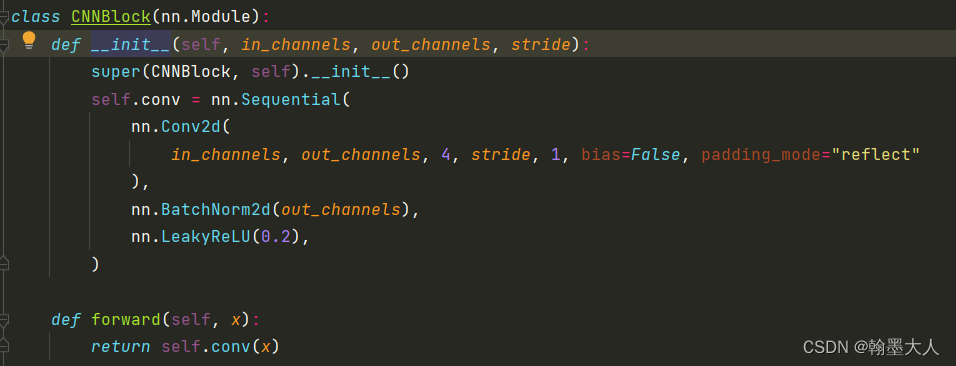
class CNNBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(CNNBlock, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(
in_channels, out_channels, 4, stride, 1, bias=False, padding_mode="reflect"
),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.2),
)
def forward(self, x):
return self.conv(x)
class Discriminator(nn.Module):
def __init__(self, in_channels=3, features=[64, 128, 256, 512]):
super().__init__()
self.initial = nn.Sequential(
nn.Conv2d(
in_channels * 2,
features[0],
kernel_size=4,
stride=2,
padding=1,
padding_mode="reflect",
),
nn.LeakyReLU(0.2),
)
layers = []
in_channels = features[0]#64
for feature in features[1:]:
layers.append(
CNNBlock(in_channels, feature, stride=1 if feature == features[-1] else 2),
)
in_channels = feature
layers.append(
nn.Conv2d(
in_channels, 1, kernel_size=4, stride=1, padding=1, padding_mode="reflect"
),
)
self.model = nn.Sequential(*layers)
def forward(self, x, y):
x = torch.cat([x, y], dim=1)#(1,6,256,256)
x = self.initial(x)#(1,64,128,128)
x = self.model(x)
return x
def test():
x = torch.randn((1, 3, 256, 256))
y = torch.randn((1, 3, 256, 256))
model = Discriminator(in_channels=3)
preds = model(x, y)#(1,1,30,30)
print(model)
print(preds.shape)
if __name__ == "__main__":
test()
辨别器D的输入有两个,因为本质还是CGAN,所以一个输入为生成的图片,另一个输入为condition,也就是x。
分为三步,首先将condition和生成的图片concat在一起,接着经过一个卷积来增大通道数,最后进过辨别器。

1:concat
2:拼接后的通道扩充到64,步长为2.
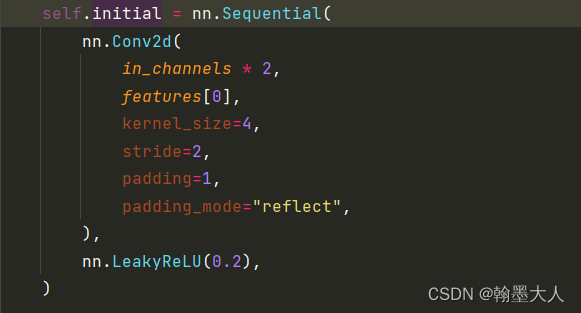
3:遍历feature,layers里面有四个卷积,采用的是CONV+BN+LeakyReLU形式,最后输出的通道为1.输出大小为30x30.

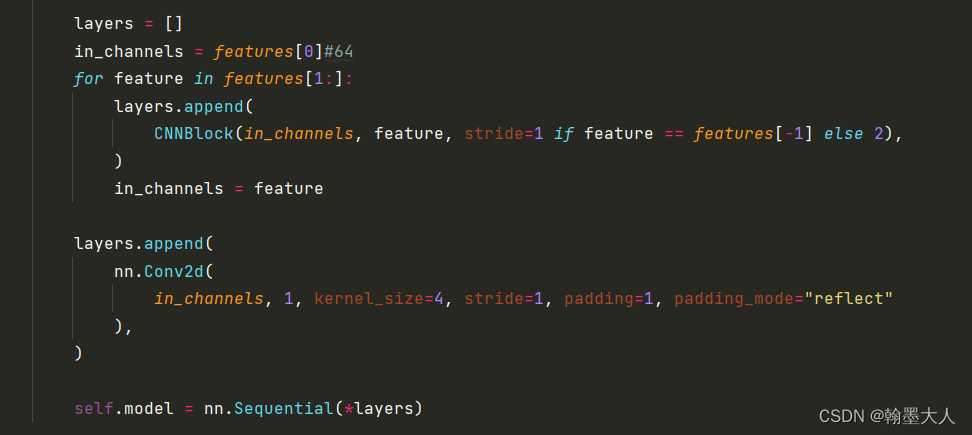
 辨别器model:
辨别器model:
Sequential(
(0): CNNBlock(
(conv): Sequential(
(0): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False, padding_mode=reflect)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
)
(1): CNNBlock(
(conv): Sequential(
(0): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False, padding_mode=reflect)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
)
(2): CNNBlock(
(conv): Sequential(
(0): Conv2d(256, 512, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1), bias=False, padding_mode=reflect)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
)
(3): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1), padding_mode=reflect)
)
接着看train:
import torch
from utils import save_checkpoint, load_checkpoint, save_some_examples
import torch.nn as nn
import torch.optim as optim
import config
from dataset import MapDataset
from generator_model import Generator
from discriminator_model import Discriminator
from torch.utils.data import DataLoader
from tqdm import tqdm
from torchvision.utils import save_image
torch.backends.cudnn.benchmark = True
def train_fn(
disc, gen, loader, opt_disc, opt_gen, l1_loss, bce, g_scaler, d_scaler,
):
loop = tqdm(loader, leave=True)
for idx, (x, y) in enumerate(loop):
x = x.to(config.DEVICE)
y = y.to(config.DEVICE)
# Train Discriminator
with torch.cuda.amp.autocast():
y_fake = gen(x)
D_real = disc(x, y)
D_real_loss = bce(D_real, torch.ones_like(D_real))
D_fake = disc(x, y_fake.detach())
D_fake_loss = bce(D_fake, torch.zeros_like(D_fake))
D_loss = (D_real_loss + D_fake_loss) / 2
disc.zero_grad()
d_scaler.scale(D_loss).backward()
d_scaler.step(opt_disc)
d_scaler.update()
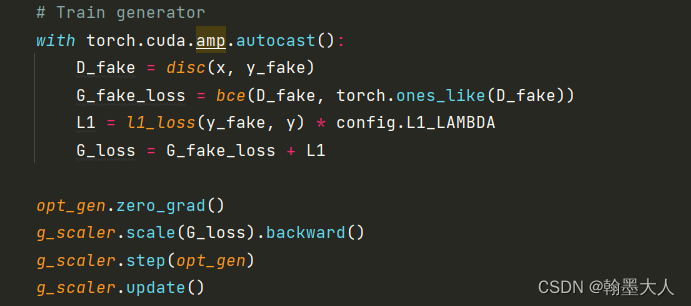
# Train generator
with torch.cuda.amp.autocast():
D_fake = disc(x, y_fake)
G_fake_loss = bce(D_fake, torch.ones_like(D_fake))
L1 = l1_loss(y_fake, y) * config.L1_LAMBDA
G_loss = G_fake_loss + L1
opt_gen.zero_grad()
g_scaler.scale(G_loss).backward()
g_scaler.step(opt_gen)
g_scaler.update()
if idx % 10 == 0:
loop.set_postfix(
D_real=torch.sigmoid(D_real).mean().item(),
D_fake=torch.sigmoid(D_fake).mean().item(),
)
def main():
disc = Discriminator(in_channels=3).to(config.DEVICE)
gen = Generator(in_channels=3, features=64).to(config.DEVICE)
opt_disc = optim.Adam(disc.parameters(), lr=config.LEARNING_RATE, betas=(0.5, 0.999),)
opt_gen = optim.Adam(gen.parameters(), lr=config.LEARNING_RATE, betas=(0.5, 0.999))
BCE = nn.BCEWithLogitsLoss()
L1_LOSS = nn.L1Loss()
if config.LOAD_MODEL:
load_checkpoint(
config.CHECKPOINT_GEN, gen, opt_gen, config.LEARNING_RATE,
)
load_checkpoint(
config.CHECKPOINT_DISC, disc, opt_disc, config.LEARNING_RATE,
)
train_dataset = MapDataset(root_dir=config.TRAIN_DIR)
train_loader = DataLoader(
train_dataset,
batch_size=config.BATCH_SIZE,
shuffle=True,
num_workers=config.NUM_WORKERS,
)
g_scaler = torch.cuda.amp.GradScaler()
d_scaler = torch.cuda.amp.GradScaler()
val_dataset = MapDataset(root_dir=config.VAL_DIR)
val_loader = DataLoader(val_dataset, batch_size=1, shuffle=False)
for epoch in range(config.NUM_EPOCHS):
train_fn(
disc, gen, train_loader, opt_disc, opt_gen, L1_LOSS, BCE, g_scaler, d_scaler,
)
if config.SAVE_MODEL and epoch % 5 == 0:
save_checkpoint(gen, opt_gen, filename=config.CHECKPOINT_GEN)
save_checkpoint(disc, opt_disc, filename=config.CHECKPOINT_DISC)
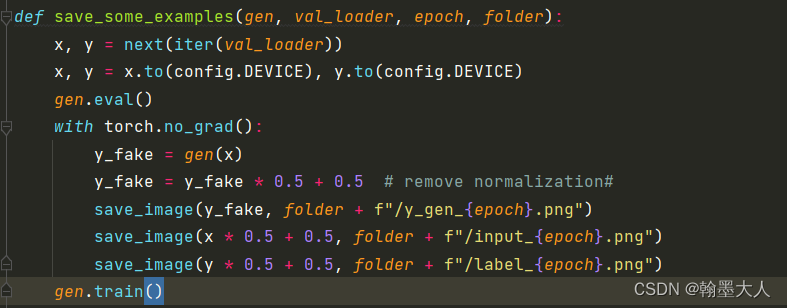
save_some_examples(gen, val_loader, epoch, folder="/home/Projects/ZQB/a/PyTorch-GAN-master/implementations/pix2pix-pytorch/results")
if __name__ == "__main__":
main()
1:实例化辨别器,生成器,设置优化器和损失函数。

2:传入预训练的权重:
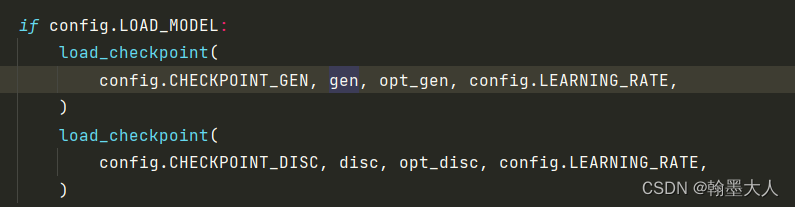
定义数据集:我们采用的给素描上色的数据集。

数据集结构:我们根据设定好的数据集位置,加载train文件下的图片。
我们到dataset中,主要看getitem中,如何加载处理数据的。
import numpy as np
import config
import os
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torchvision.utils import save_image
class MapDataset(Dataset):
def __init__(self, root_dir):
self.root_dir = root_dir
self.list_files = os.listdir(self.root_dir)
def __len__(self):
return len(self.list_files)
def __getitem__(self, index):
img_file = self.list_files[index]
img_path = os.path.join(self.root_dir, img_file)
image = np.array(Image.open(img_path))
t = np.unique(image)
print(t)
input_image = image[:, :600, :]#(512,600,3)
target_image = image[:, 600:, :]#(512,424,3)
augmentations = config.both_transform(image=input_image, image0=target_image)
input_image = augmentations["image"]#(256,256,3)
target_image = augmentations["image0"]#(256,256,3)
input_image = config.transform_only_input(image=input_image)["image"]#(3,256,256)
target_image = config.transform_only_mask(image=target_image)["image"]#(3,256,256)
return input_image, target_image
if __name__ == "__main__":
dataset = MapDataset("data/train/")
loader = DataLoader(dataset, batch_size=5)
for x, y in loader:
print(x.shape)
save_image(x, "x.png")
save_image(y, "y.png")
import sys
sys.exit()
首先根据索引,我们找到对应的图片并读入:

接着对图片进行划分:因为原始图片的input和target是连在一起的。


将图片拆分:
input:

target:

然后将两个图片裁切到256x256.再将两个图片进行变换:
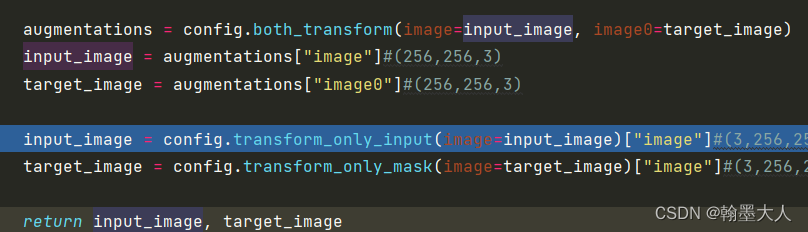
也就是执行mydataset时候输出的是input和配对的target。
回到train中:通过trainloader对图片进行加载用于训练。
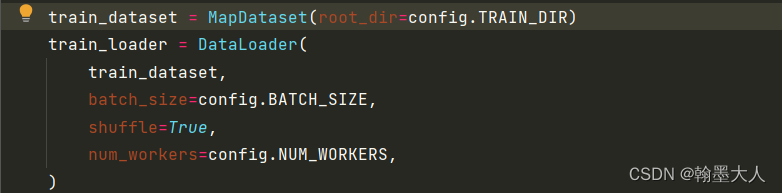
同理对val文件夹的图片进行加载,用于val。

然后就是正式训练:
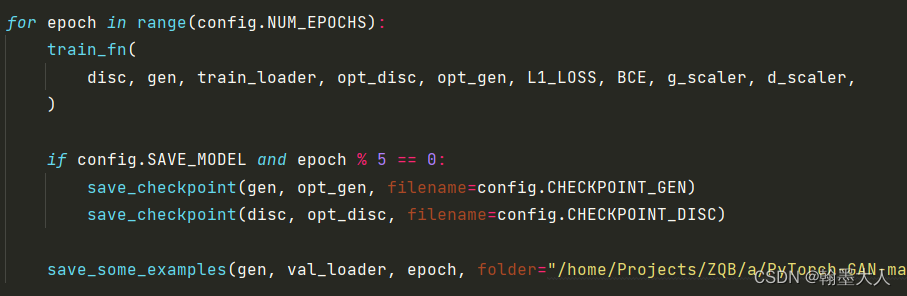
将模型,数据,优化器,损失函数都传到train中:

在train_fn函数中,首先添加一个进度条,接着将input和target都输入到cuda中。
训练判别器:
将真实的x,y输入到判别器中输出的真我们希望为1,将x输入到生成器生成的假y和真实的x(作为condition)输入到判别器中,我们希望输出0。
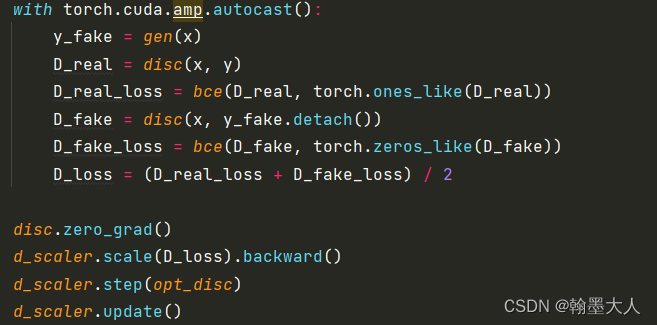
训练生成器:真实的x和虚假的y输入到D中,我们希望D判别不出来,即输出为1.还有一个L1损失,即真实的标签和虚假的生成之间的损失。然后两个损失加起来作为生成器损失。
接着我们保存D和G的权重。
然后保存图片: