油管attention机制解释
油管的attention机制视频。
基础形态
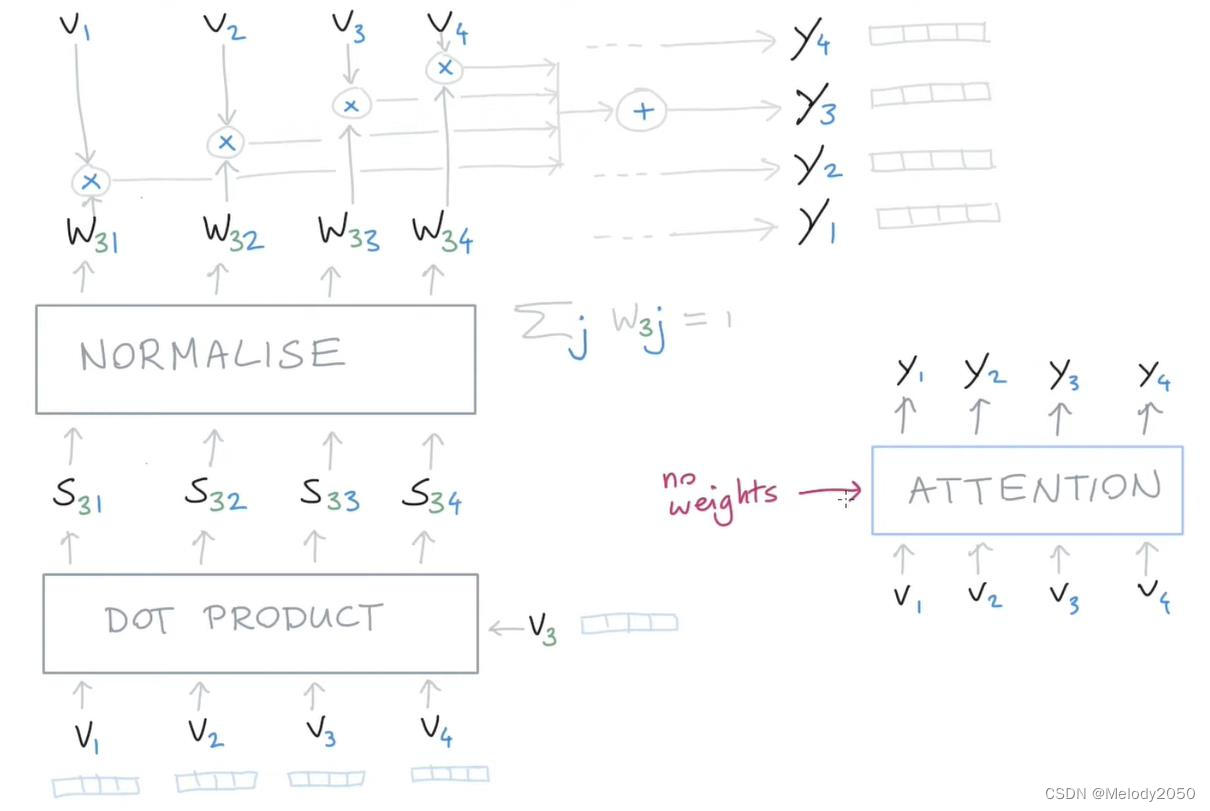
如下图所示,假设现在有4个向量, v 1 v_1 v1到 v 4 v_4 v4。我们以 v 3 v_3 v3为视角,看它是怎么得到 y 3 y_3 y3的。首先用 v 3 v_3 v3和全部4个向量做点乘,然后归一化,得到权重w。然后用这些权重与4个向量分别作加权和,得到 y 3 y_3 y3。四个向量都这样做,就得到了四个y向量了。
留意到这种做法有两个特点:
- 输入维度和输出维度相同。输入是4个v,输出是4个y
- 没有权重需要训练。在这个过程中是没有参数要训练的,整个过程的计算只需要输入向量v。
这对应的公式就是 S o f t m a x ( X X T ) X Softmax(XX^T)X Softmax(XXT)X
注意力机制
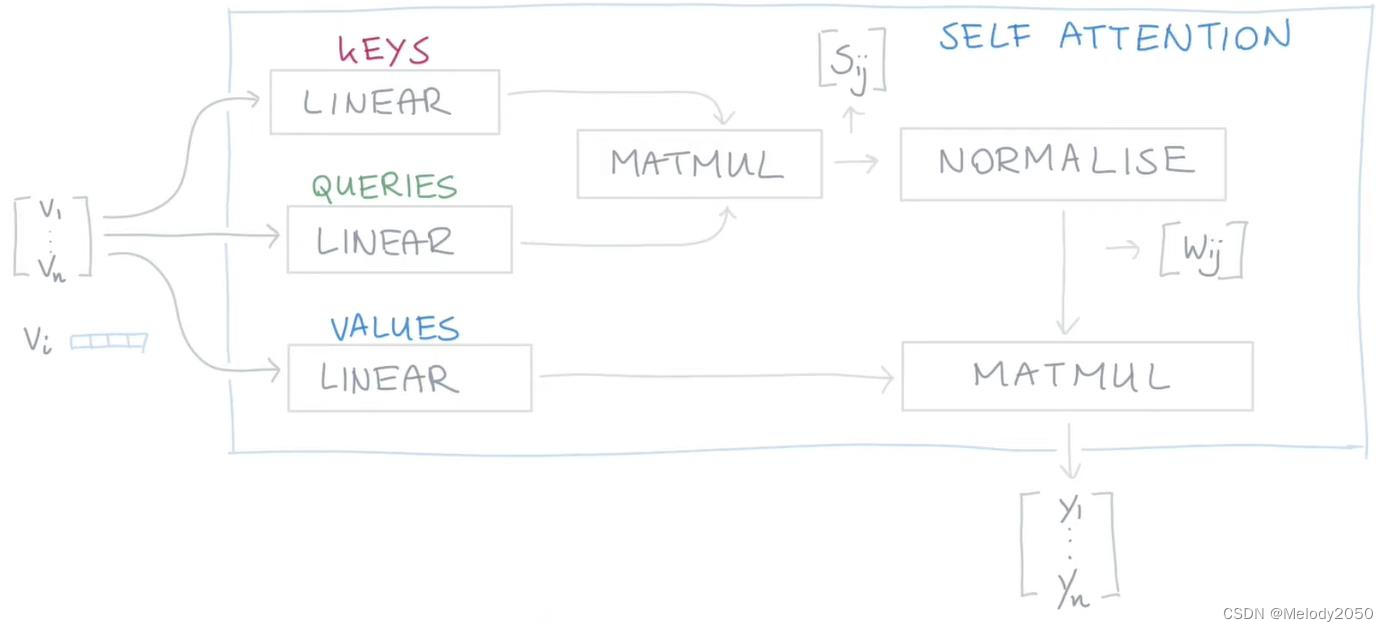
假如我们希望有可训练的参数呢?我们可以在三处v出现的地方,都用一个转置矩阵将v进行映射,这样我们就能让参数可训练了。

所以,这样的过程可以视为一个self-attention blobk,能嵌入到神经网络中被学习。
其它链接的理解
参考 Self-Attention:Learning QKV step by step,键值对形式的self-attention和基本的self-attention的公式如下。
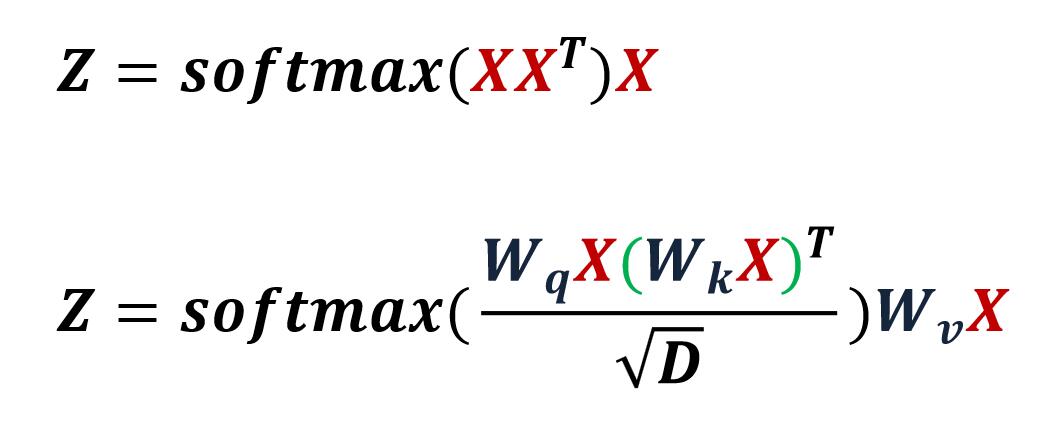
Transformer之十万个为什么?
为什么Q、K、V代表了注意力?
V是表示输入特征的向量,Q、K是计算Attention权重的特征向量。它们都是由输入特征得到的。Attention(Q,K,V)是根据关注程度对V乘以相应权重
你有一个问题Q,然后去搜索引擎里面搜,搜索引擎里面有好多文章,每个文章V有一个能代表其正文内容的标题K,然后搜索引擎用你的问题Q和那些文章V的标题K进行一个匹配,看看相关度(QK —>attention值),然后你想用这些检索到的不同相关度的文章V来表示你的问题,就用这些相关度将检索的文章V做一个加权和,那么你就得到了一个新的Q’,这个Q’融合了相关性强的文章V更多信息,而融合了相关性弱的文章V较少的信息。这就是注意力机制,注意力度不同,重点关注(权值大)与你想要的东西相关性强的部分,稍微关注(权值小)相关性弱的部分。