文章目录
- BER任务介绍
- BiLSTM模型介绍
- ----------------------------------------------------------------------------------------------------
- 模型细节
- 如果没有CRF层会是什么样
- CRF 层
- CRF原理:
- 一、CRF基础
- 1、条件概率
- 2、图、无向图
- 3、概率图
- 4、马尔可夫性
- 5、概率无向图模型(又称马尔可夫随机场)
- 6、团、最大团
- 7、无向图的因子分解
- 8、Hammersley-Clifford 定理
- 8、条件随机场
- 9、线性链的条件随机场
- 10、线性链条件随机场公式
- 三大问题:
- 1、概率计算问题
- 2、学习问题
- 3、预测问题
- viterbi 算法
- CRF层的作用:CRF层可以学习到句子的约束条件
- 评估指标:
- BER任务实现:
- 参考:
BER任务介绍
命名实体识别(Named Entity Recognition, NER)
命名实体识别(Named Entity Recognition, NER)的工作,就是从一段文本中抽取到找到任何你想要的东西,可能是某个字,某个词,或者某个短语。通常是用序列标注(Sequence Tagging)的方式来做,老 NLP task 了
规定在数据集中有两类实体,人名和组织机构名称。
在数据集中总共有5类标签:
B-Person (人名的开始部分)
I- Person (人名的中间部分)
B-Organization (组织机构的开始部分)
I-Organization (组织机构的中间部分)
O (非实体信息)
BiLSTM模型介绍
BiLSTM,指的是双向LSTM;CRF指的是条件随机场。
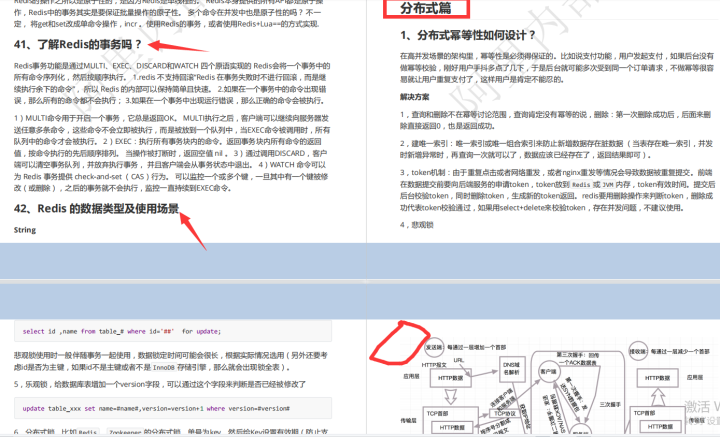
模型总览:
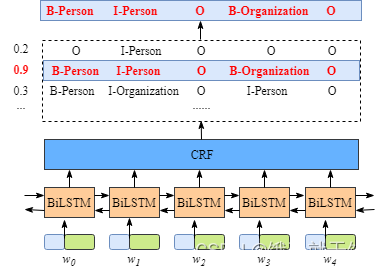
输入:模型输入是字符特征,
输出:每个字符对应的预测标签。
----------------------------------------------------------------------------------------------------
模型细节
首先,句中的每个单词是一条包含词嵌入和字嵌入的词向量,词嵌入通常是事先训练好的,字嵌入则是随机初始化的。所有的嵌入都会随着训练的迭代过程被调整。
其次,BiLSTM-CRF的输入是词嵌入向量,输出是每个单词对应的预测标签。
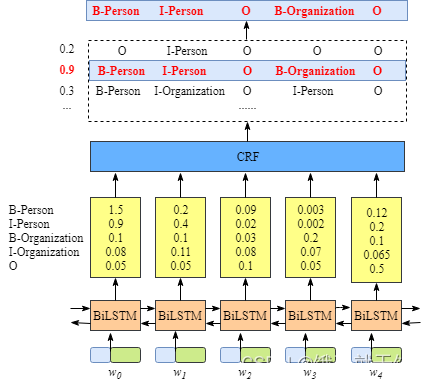
如下图所示,BiLSTM层的输出表示该单词对应各个类别的分数。
如W0,BiLSTM节点的输出是1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) and 0.05 (O)。这些分数将会是CRF层的输入。 所有的经BiLSTM层输出的分数将作为CRF层的输入,类别序列中分数最高的类别就是我们预测的最终结果。
如果没有CRF层会是什么样
即使没有CRF层,我们照样可以训练一个基于BiLSTM的命名实体识别模型,如下图所示。
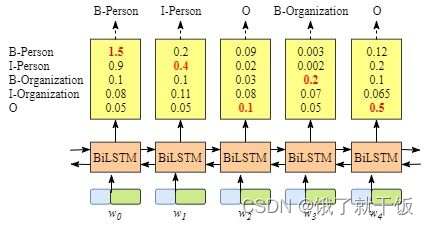
因为BiLSTM模型的结果是单词对应各类别的分数,我们可以选择分数最高的类别作为预测结果。如W0,“B-Person”的分数最高(1.5),那么我们可以选定“B-Person”作为预测结果。同样的,w1是“I-Person”, w2是“O”,w3是 “B-Organization” ,w4是 “O”。
尽管我们在该例子中得到了正确的结果,但实际情况并不总是这样,而是下面这样:
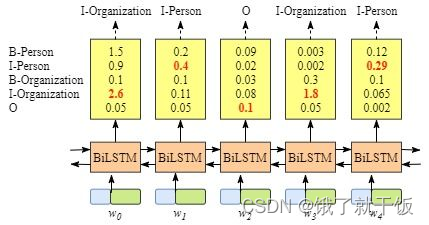
很明显BiLSTM识别出来的实体标签并没有实体的起始标识B和E,显然,这次的分类结果并不准确。
CRF 层
CRF原理:
一、CRF基础
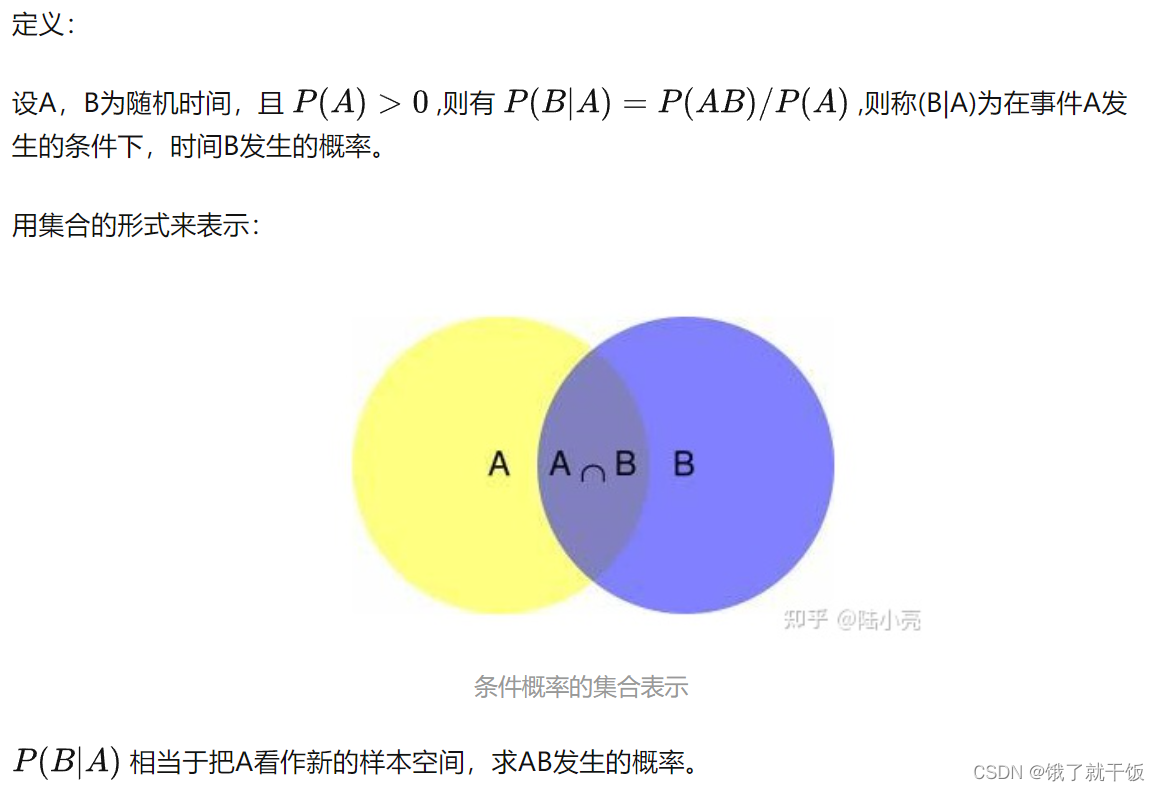
1、条件概率
一个随机事件发生的概率并非是一个绝对的概念,事实上,当另一个与其相关的随机事件发生时,该事件再发生的概率往往会随之改变。
2、图、无向图

3、概率图
概率图模型是指由图表示的概率分布。
详细说如下:设有联合概率分布P(Y),Y是一组随机变量。由无向图 G=(V,E)表示概率分布P(Y)。
即再图G中,结点v表示随机变量,e表示随机变量间的依赖关系。
4、马尔可夫性
马尔可夫性包含成对马尔可夫性、局部马尔可夫性、全局马尔可夫性
4.1 成对马尔可夫性:没有边直接相连接的两个点(变量)相互独立

4.2 局部马尔可夫性

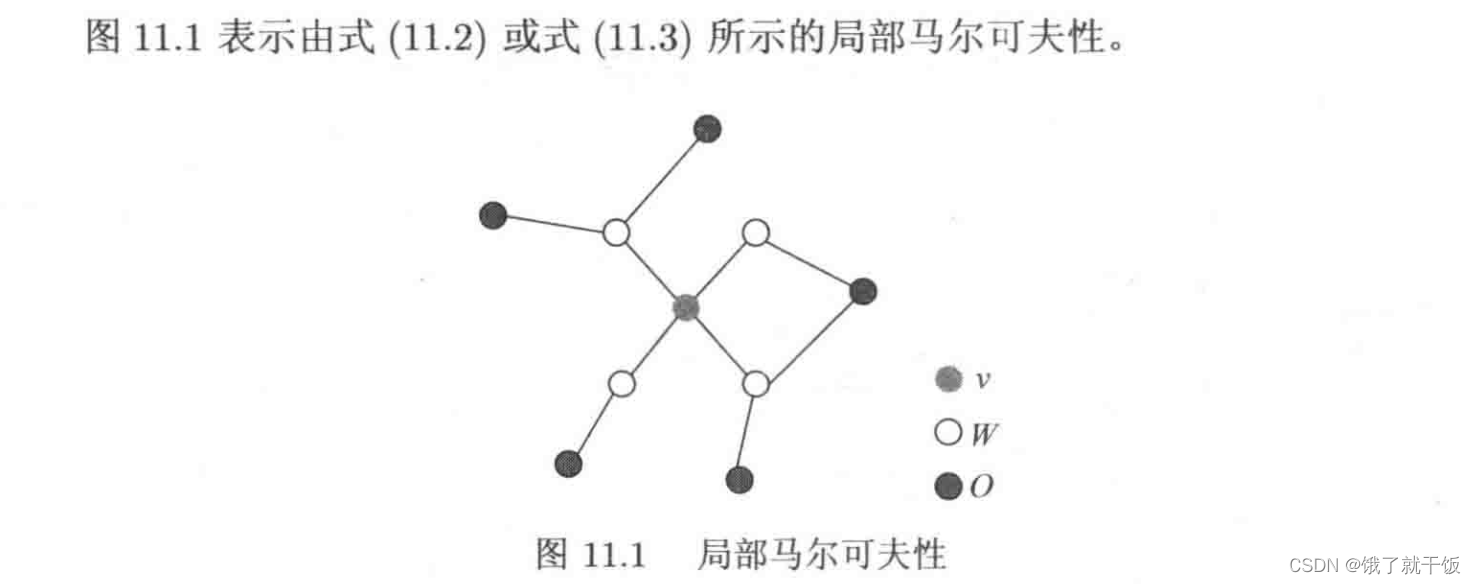
4.3 全局马尔可夫性:

5、概率无向图模型(又称马尔可夫随机场)
马尔可夫随机场,是一个可以由无向图表示的联合概率分布。

对于给定的概率无向图模型,我们希望将整体的联合概率写成若干子联合概率的乘积的形式,也就是将联合概率进行因子分解,这样便于模型的学习与计算。事实上,概率无向图模型的最大的特点就是易于因子分解。
在进行因子分解时需要引入团、最大团等概念。
6、团、最大团

7、无向图的因子分解
将概率无向图模型的联合概率分布表示为最大团的随机变量的函数的乘积形式的操作,称为概率无向图的因子分解。

8、Hammersley-Clifford 定理
无向图的因子分解总结如下:

8、条件随机场
我们前面讲到马尔可夫随机场,这个是指输出变量Y的形式,并没有指定输入变量X。条件随机场的条件,就是指给定输入变量X。所以很多同学会把概率无向图(马尔可夫随机场)与条件随机场搞混淆,在这里马尔可夫随机场是指随机变量Y,条件随机场是指给定随机变量X的条件下,随机变量Y的马尔可夫随机场。
9、线性链的条件随机场


10、线性链条件随机场公式
tk和sl都是特征函数,其中tk时转移特征函数,sl是状态特征函数。因为它们都是依赖于位置的,tk依赖于当前位置和前一位置,sl依赖于当前位置,所以两个函数又都是局部特征函数。

4、条件随机场例子
三大问题:
1、概率计算问题
2、学习问题
3、预测问题
viterbi 算法
参考:如何通俗地讲解 viterbi 算法?
CRF层中的损失函数包括两种类型的分数,而理解这两类分数的计算是理解CRF的关键。
1、发射分数(Emission score)
发射概率:指的是给定词性生成单词的概率
2、转移分数
转移概率:表示给定一个词性下面一个词性的概率(表示介词后面的词是名词的概率)
CRF层将BiLSTM的Emission_score作为输入,输出符合标注转移约束条件的、最大可能的预测标注序列。
CRF层的作用:CRF层可以学习到句子的约束条件
CRF层可以加入一些约束来保证最终预测结果是有效的。这些约束可以在训练数据时被CRF层自动学习得到。
可能的约束条件有:
1、句子的开头应该是“B-”或“O”,而不是“I-”。
2、“B-label1 I-label2 I-label3…”,在该模式中,类别1,2,3应该是同一种实体类别。比如,“B-Person I-Person” 是正确的,而“B-Person I-Organization”则是错误的。
3、“O I-label”是错误的,命名实体的开头应该是“B-”而不是“I-”。
有了这些有用的约束,错误的预测序列将会大大减少。
从实验的角度可以简单说说,就是 LSTM 只能通过输入判断输出,但是 CRF 可以通过学习转移矩阵,看前后的输出来判断当前的输出。这样就能学到一些规律(比如“O 后面不能直接接 I”“B-brand 后面不可能接 I-color”),这些规律在有时会起到至关重要的作用
评估指标:
大多数 NLP task 的评价指标有这三个:Precision / Recall / F1Score,Precision 就是找出来的有多少是正确的,Recall 是正确的有多少被找出来了,F1Score是二者的一个均衡分。这里有三点常识
方法固定的条件下,一般来说,提高了 Precision 就会降低 Recall,提高了 Recall 就会降低 Precision,结合指标定义很好理解
通常来说,F1Score 是最重要的指标,为了让 F1Score 最大化,通常需要调整权衡 Precision 与 Recall 的大小,让两者达到近似,此时 F1Score 是最大的
但是 F1Score 大,不代表模型就好。因为结合工程实际来说,不同场景不同需求下,对 P/R 会有不同的要求。有些场景就是要求准,不允许出错,所以对 Precision 要求比较高,而有些则相反,不希望有漏网之鱼,所以对 Recall 要求高
BER任务实现:
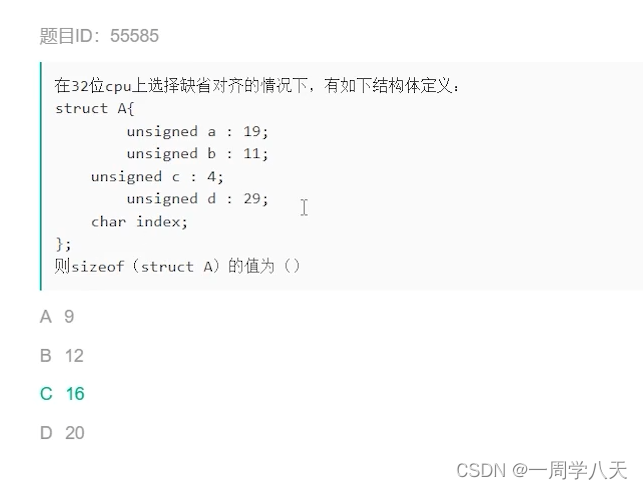
1、biLSTM_CRF模型在tensorflow中的实现
参考:
1、命名实体识别(NER):BiLSTM-CRF原理介绍+Pytorch_Tutorial代码解析
2、CRF条件随机场的原理、例子、公式推导和应用
3、《统计学习方法》- 条件随机场


![[附源码]计算机毕业设计springboot人体健康管理app](https://img-blog.csdnimg.cn/1b285403f73143969fdef1bc48e61fe5.png)