目录
一、什么是索引?索引的作用
二、索引的简单使用
三、索引背后的数据结构
1、B 树
2、B + 树
一、什么是索引?索引的作用
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
官方的概念往往难以理解,简单来说索引就像我们书本的目录,能够加快我们查询速度。
在加快我们查询速度的同时,索引同时也要消耗存储空间(就好比目录也要费纸一样~)
索引的使用场景?
- 数据量较大,且经常对这些列进行条件查询
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率
反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
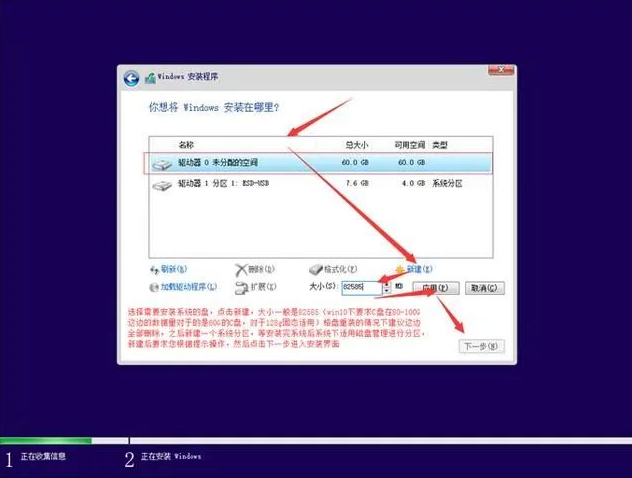
二、索引的简单使用
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
- 查看索引
show index from 表名;- 创建索引 (对于非主键,非唯一约束,非外键的字段可以创建普通索引)
create index 索引名 on 表名(字段名);- 删除索引
drop index 索引名 on 表名;
三、索引背后的数据结构
首先我们可以思考一下为什么索引背后的数据结构是 B+ 树而不是顺序表、链表、哈希表、二叉搜索树等数据结构?
- 顺序表和链表
顺序表和链表查找的时间复杂度都是O(N)的,这里我想消除一个误区就是好多人认为顺序表的查找是O(1)的,但其实按下标获取元素并不叫”查找“,查找是指按值找到对应的元素,因此显然这两种数据结构的复杂度都是线性的,不符合我们的预期。
- 哈希表
提到哈希表我们不得不说它是一个非常伟大的数据结构,因为它查找的时间复杂度是O(1)的,但我们依旧不能选择它,因为哈希表是根据哈希映射构建的,简单来说哈希表是没有顺序的,因此我们无法处理 > || == || < 的情况,试想,如果我们查找无法使用 比较 ,那无疑是致命的
- 二叉搜索树
二叉搜索树无疑是一个很适合作为索引的数据结构,在建树完美的情况下它的时间复杂度是O(N),并且适合范围查找,我们只需要找到两个端点中序遍历即可,但它美中不足的就是每个结点只有两个分叉,在数据量非常恐怖的时候树的高度仍然很高
1、B 树
ps:图片来源:wwzzzzzzzzzz博主
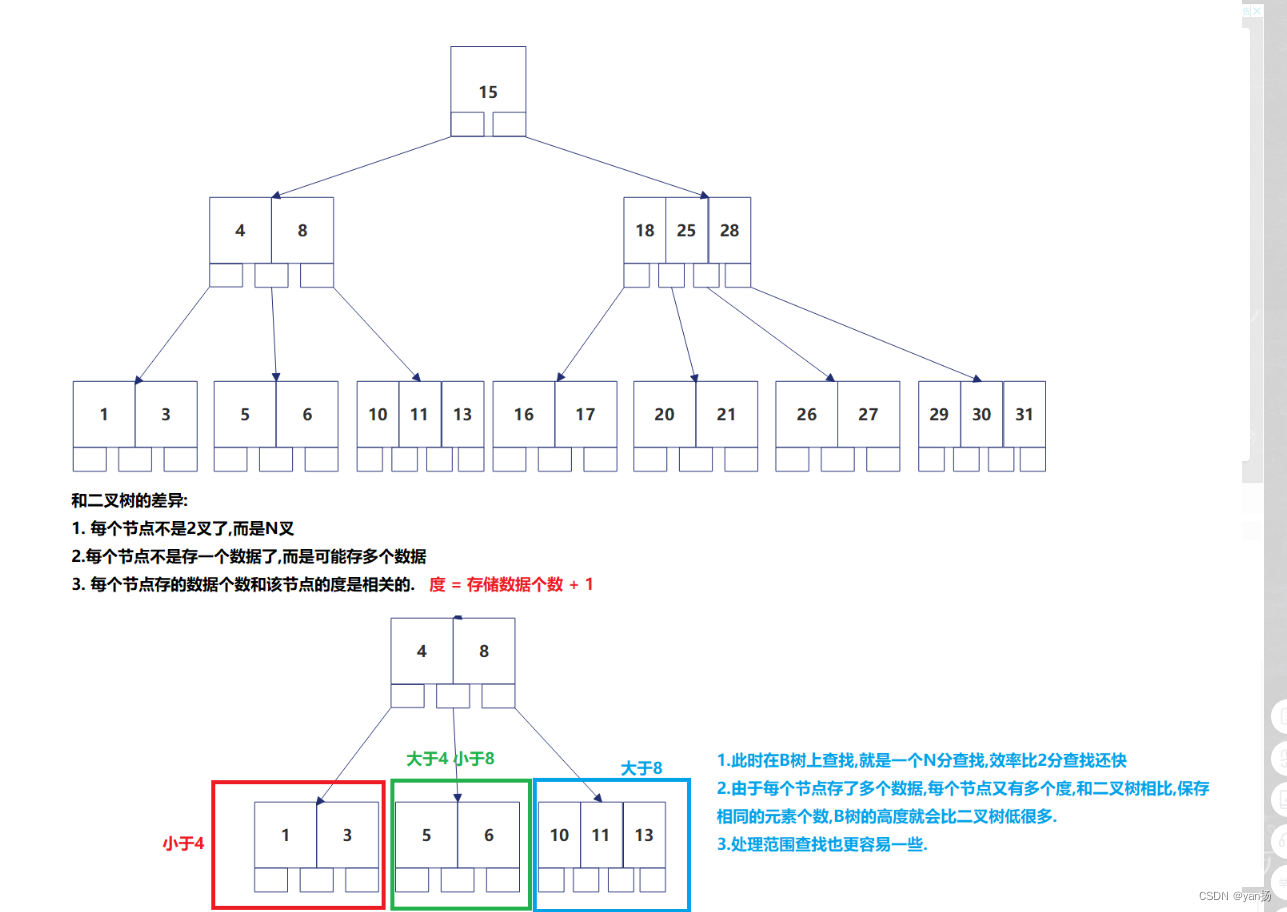
相信很多同学发现了,在确定区间时,B 树仍然需要经过多次比较,那么相比之前我们提到过的二叉搜索树,B 树的优点是什么?
B - Tree 的优点:
- N 叉树的树高非常低,查询很快
- 叶子结点和非叶子结点都可以存储数据,并且都可以存多个数据
- 一个结点多次比较,虽然比较次数更多,但硬盘IO次数降低
- 硬盘的访问速度是很慢的,因此减少硬盘IO次数,远比减少比较次数要更划得来
2、B + 树
B + 树是在 B 树的基础上改进而来,可以这么说:B + 树就是一种为索引而生的数据结构!
什么是 B + 树
【B+ 树 是 数据库中最常见的数据结构】
注意!数据库有很多种,每个数据库底层又支持多种存储引擎
这些存储引擎实现了数据库具体按照什么结构来存储的程序。
那么就意味着 每个存储引擎 存储数据的结构 可能都不一样,背后的索引数据结构可能也不同。
所以,这里面可能会有很多种多叉树来去表示这里的数据结构。
只是 B+ 树 是 最常用的一种数据结构。
那么,B+ 树 又是什么样子的?
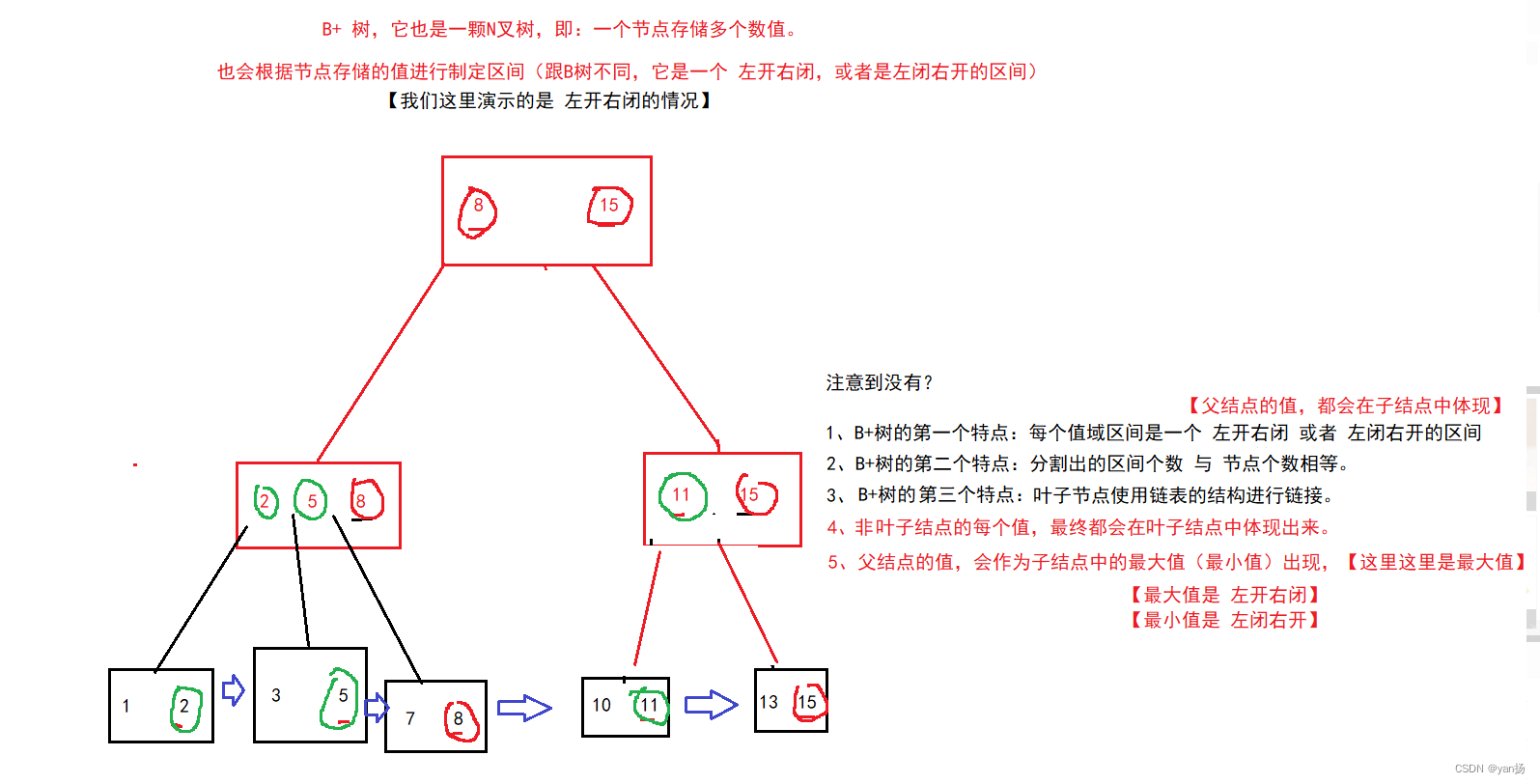
B+ Tree 的优点:
- 一个结点可以存很多值,在进行查找的时候整体IO次数较少,速度快
- 所有的查询都会落到叶子结点上,每次查询的IO次数都差不多,查询速度稳定
- 叶子结点最终是一个链表,非常适合范围查找
- 非叶子结点只存储key,相同内存下B+树可以存储更多索引