目录
数据库基础
代码建库
数据完整性
代码建表
数据库基础
- 系统数据库:master、model、tempdb、madb
- 数据库文件的组成:【数据文件可以放在不同的文件组里】
- 主数据文件:*.mdf 主数据文件只能有一个
- 次要数据文件:*.ndf
- 日志文件:*.ldf 日志文件不属于任何文件组
-
数据库分离和附加:右击——>任务——>分离【分离后数据库是与服务器分离,SQL界面的数据库就会消失,此时就可以剪切文件到U盘】 下次要用:又剪切到原文件夹,然后右击数据库——>附加——>选主数据文件所在文件夹。单机确定就会显示出来。
-
数据库的脱机与联机
右击此数据库——>任务——>脱机。脱机后数据库还显示在SQL界面。
【脱机后可完成数据库文件的剪切和复制】
下次要用:重新剪切到原文件夹——>右击该脱机数据库——>任务——>联机。即可
【不建议收缩数据库】
代码建库
create database XK--数据库名称
on primary--主文件组
(
name=XK_data,--主数据文件
filename='D:\project\XK_data.mdf',--主数据文件路径
size=10mb,--文件初始大小
maxsize=500mb,--文件增长最大容量限制
filegrowth=10mb--文件的增量
),
(
name=XK_data1,--辅数据文件
filename='D:\project\XK_data1.ndf',--辅数据文件路径
size=5mb,
maxsize=100mb,
filegrowth=1mb
),
filegroup client--新建的文件组
(
name=XK_data2,
filename='C:\project\XK_data2.ndf',
size=4mb,
maxsize=10mb,
filegrowth=1mb
)
log on--日志文件
(
name=XK_log,
filename='D:\project\XK_log.ldf',
size=5mb,
maxsize=unlimited,
filegrowth=1mb
),
(
name=XK_log1,
filename='D:\project\XK_log1.ldf',
size=5mb,
maxsize=unlimited,
filegrowth=10%
)
go
exec sp_detach_db 'XK'--分离XK数据库
exec sp_attach_db 'XK' , 'D:\project\XK_data.mdf'--附加XK数据库
exec sp_dboption 'XK' , 'read only' , 'false'--设置数据库只读为关闭
exec sp_dboption 'XK' , 'single user' , 'false'--设置数据库单用户访问(限制访问)为关闭
exec sp_dboption 'XK' , 'autoshrink' , 'false'--设置自动收缩为关闭
exec sp_dboption 'XK' , 'autoclose' , 'false'--设置自动关闭为关闭
exec sp_dboption 'XK' , 'auto create statistics' , 'true'--自动创建统计信息为开启
exec sp_dboption 'XK' , 'auto update statistics' , 'true'--自更新统计信息为开启
exec sp_renamedb 'XK' , 'XK1'--数据库重命名
alter database XK1 --修改数据库
modify name=XK --修改数据库名称 modify是修改
drop database XK --删除XK数据库
--------------------------------------------------------------------------------
alter database XK
add file
(
name=XK_data3,
filename='C:\project\XK_data3.ndf',
size=5mb,
maxsize=unlimited,
filegrowth=1mb
) to filegroup client
----添加数据文件到client文件组
----------------------------------------------------------------------------------
alter database XK
add log file
(
name=XK_log2,
filename='c:\project\XK_log2.ldf',
size=10mb,
maxsize=20mb,
filegrowth=1mb
)
--添加日志文件
-------------------------------------------------------------------------------
alter database XK
remove file XK_log2
--删除文件 后+文件名
---------------------------------------------------
alter database XK
modify file
(
name=XK_data1,
size=6
)
------------修改辅数据文件初始大小
alter database XK
add filegroup mygroup
-----------添加文件组
alter database XK
remove filegroup mygroup
--------------删除文件组
alter database XK
modify filegroup client default
----------------修改client文件组为默认
alter database XK
modify filegroup client readonly
------------修改client文件组为只读
alter database XK
modify filegroup client readwrite
--------------修改client文件组为可写
alter database XK
modify filegroup [primary] default
--------------修改主文件组为默认时,要把主文件组文件名用中括号括起来
数据完整性
-
一致性+准确性=数据完整性
-
完整性包括:域完整性、实体完整性、引用完整性、自定义完整性
-
实体完整性 约束方法:唯一约束、主键约束、标识列 保证数据不重复、唯一
-
域完整性 约束方法:限制数据类型、检查约束、外键约束、默认值、非空约束
-
引用完整性 外键用的值必须是主键里出现过的值 约束方法:外键约束
建表先主后从 删除信息先从后主
-
自定义完整性 触发器:检查信用值 约束方法:规则、存储过程、触发器
-
约束的目的:确保表中数据的完整性
常用的约束类型:
主键约束 要求主键列数据唯一,并且不允许为空
唯一约束 要求该列唯一,允许为空,但只能出现一个空值
检查约束 某列取值范围限制、格式限制、如有关年龄的约束
默认约束 某列的默认值,如班级男生较多,默认性别为男
外键约束 用于两表间建立关系时指定引用主表的那一刻
非空约束
-
选择主键的原则:
量少性:尽量选择单个键作为主键
稳定性:尽量选择数值更新少的作为主键
-
删除信息时需要注意的地方:
- 当主表中没有对应的纪录时,不能将记录添加到子表——成绩表中不能出现在学员信息表中不存在的学号
- 不能更改主表中的值导致子表中的记录孤立——把学员信息表中的学号改变了,学员成绩表中的学号也应当随之改变。
- 子表存在与主表对应的记录,不能从主表中删除该行——不能把有成绩的学员删除了。
- 删除主表前,先删子表——先删除学员成绩表,后删除学员信息表。
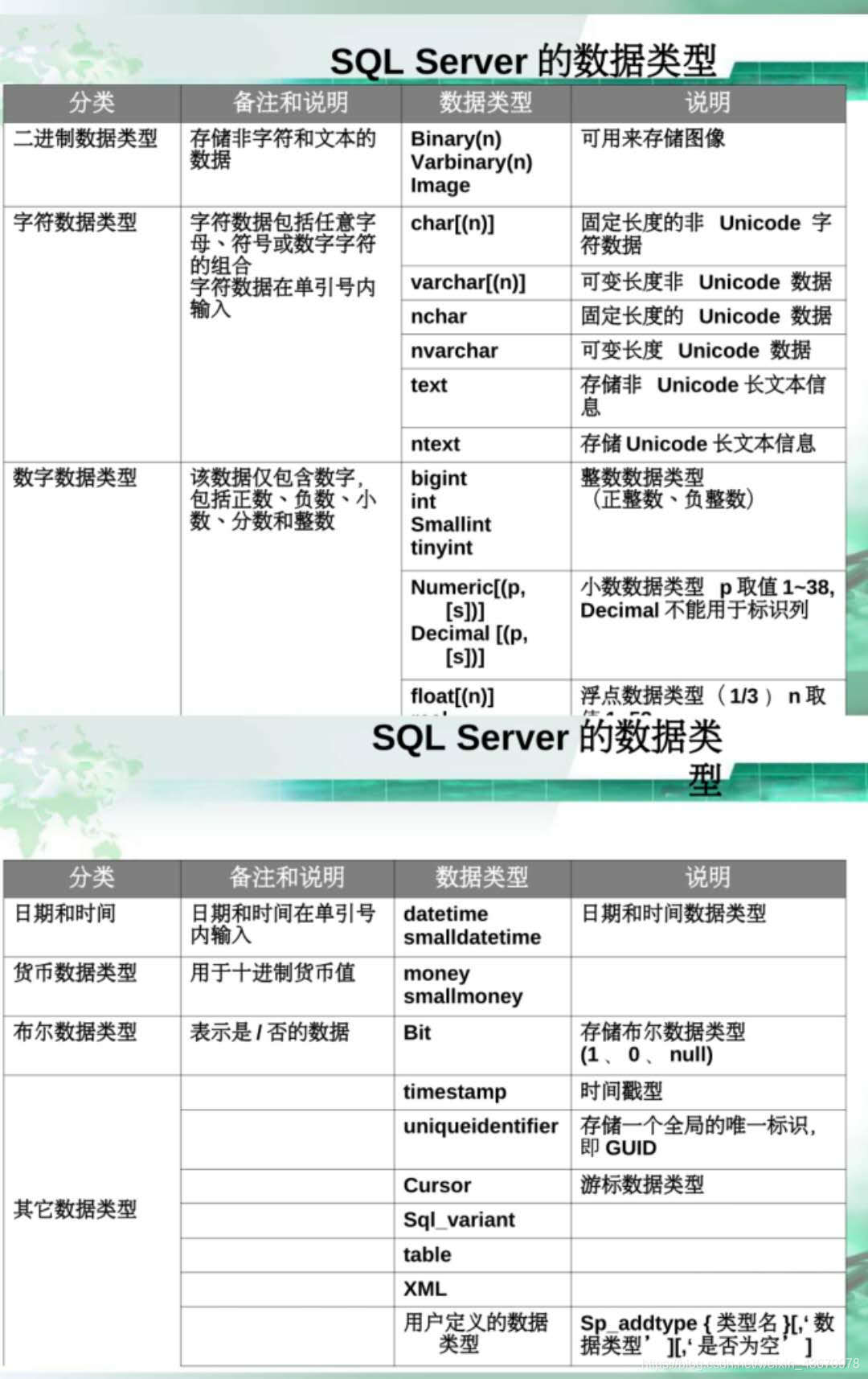
代码建表
-
代码建表,修改属性
use XK --打开数据库 create table Employees --创建数据表 ( 编号 char(6) not null constraint pk_编号 primary key, --not null 不为空 primary key 主键 姓名 char(8) not null , 性别 bit not null constraint df_性别 default 1 constraint ck_性别 check(性别=0 or 性别=1), --default 1 默认约束为1 check检查约束 部门 varchar(16) null, 电话 varchar(20) null, 地址 varchar(50) null ) go --也可以把约束写在最后面,比如上面三个约束还可以这样写: use XK create table Employees--创建数据表 ( 编号 char(6) not null , --not null 不为空 primary key 主键 姓名 char(8) not null , 性别 bit not null , --default 1 默认约束为1 check检查约束 部门 varchar(16) null, 电话 varchar(20) null, 地址 varchar(50) null, constraint pk_编号 primary key(编号), constraint ck_性别 check(性别=0 or 性别=1) )--如果是两个键联合做主键只能用这种表名约束 默认约束不能通过这个方式建立 go alter table Empolyees--修改表的默认约束 add constraint df_性别 default 1 for 性别 go create table Goods ( 商品编号 int not null identity(1,1), --identity(1,1)标识列(1,1) 进货员工编号 char(6) not null, constraint pk_商品号 primary key(商品编号), constraint fk_进货员工编号 foreign key(进货员工编号) references Empolyees(编号) -- 外键 引用 其他表(列名) ) go drop table Employees--删除数据表 drop table Goods --修改数据表代码 alter table Employees drop column 进货时间--删除列 alter table Employees add 部门 int not null--添加列 alter table Employees alter column 部门 varchar(16)--修改列的数据属性 alter table Employees add constraint df_进货时间 default getdate() for 进货时间--添加约束 -- getdate() 是一个系统函数,系统时间 alter table Employees drop constraint df_进货时间--删除约束 exec sp_help Employees--查看数据表结构 exec sp_rename Employees, Employees --重命名数据表 select * from Employees--数据表数据信息查询 -
两列联合做主键:复合键
--当一个字段无法确定唯一性的时候,抄需要其他字段来一起形成唯一性。就是说用来组成唯百一性的字段如果有多个就是联合主键 --如 --学生成绩(学号,课程号度,成绩) --那学号和课程号就可以做为联合主键. --因为学号和课程号决定了成绩.也就是说.你要知知道成绩..你就要知道学号道,知道学号,但还不能知-道某一科的成绩.还要知道课程号. --所以函数依赖关系是{学号,课程号}->{成绩} alter table tb add constraint PK_ID primary key(学号,课程号) go-
单行信息插入
--单行记录添加 insert into 表名(列名,列名,列名,····) values(列值,列值,列值,······) -- insert into Employees(编号,姓名,性别,部门,电话,地址) values('1001','赵飞燕',0,'采购部','12343212343','北京市南京路') --字符和日期型数据都必须加引号,各个数据之间逗号分隔 不省略列名的话,数据要与列名一一对应 insert into Employees values('1002','赵飞燕',default,'销售部','97653212343','运城市南京路') --省略列名时,数据录入要严格按列顺序输入 有几列就给几个值 insert into Goods values ('1001','sdlfjasg') --当数据表有标识列时,标识列数据不需要输入,系统自动给 delete from Goods where 商品编号=6--删除插入表的数据信息 delete from Goods--清空Goods数据表的全部数据信息 --删除已经插入的标识列信息时,例如删除商品编号为6的数据,再次插入信息此时商品编号为7 --此时只能把表做删除,然后用代码重新建表注意事项:
- 每个数据的数据类型、精度和小数位数必须与相应的列匹配
- 不能为标识列指定值,因为它的数字是自动增长的
- 如果在设计表的时候就指定了某列不允许为空,则必须插入数据
- 插入的数据项,要求符合检查约束的要求
- 具有缺省值的列,可以使用default(默认/缺省)关键字类代替插入的数值,且不用加单引号
-
多行数据的插入
-- --多行记录添加 -- insert into 表名(列名,列名,列名,······) --select 列值.列值,列值,···· union --select 列值.列值,列值,···· union --select 列值.列值,列值,···· union --select 列值.列值,列值,···· union --select 列值.列值,列值,···· --go --列名可以省略,但是要按照数据表中列的顺序添加列值 insert into Employees(编号,姓名,性别,部门,电话,地址) select '1001' , '赵飞燕' , 0 , '采购部' , '01032198454' , '北京市南京东路55号' union -
数据表的复制,数据的修改与删除
--一一一 --数据表的复制 ——利用 现有表 中的 所需列 重新建一个表 --select 列名,列名··· into 新表名 from 原表名 select 姓名 , 电话 into 通讯录 from Employees --复制数据表中所有列,含有数据 select * into Employees1 from Employees --没有条件复制全部数据 select * from Employees1 --复制数据表中所有列,不包含数据,但包含约束和数据 一个空表 select * into Employees2 from Employees where 1=2 --1!=2,所以只复制结构,不复制数据 满足条件则复制数据 select * from Employees2 --数据添加 --insert into 目标表名 select 各列名(*代表所有列名) from 原表名 insert into Employees2 select * from Employees where 性别=1 --性别为1的插入到employees2中,要求两个表中的结构相同 --二二二二二二二二二二 --数据的修改 --update 表名 set 列名=表达式 where 条件表达式 select * from Employees update Employees set 部门='采购部' where 部门='销售部' --把”销售部“改为“采购部” select * from Goods update Goods set 零售价=零售价+200 where 零售价<2000 --零售价小于2000的+200 update Goods set 零售价=零售价+200, 进货价=进货价+100 where 零售价<2000 --零售价小于2000的+200进货价+100 --三三三三三三三三 --数据的删除 --delete from 表明 where 条件表达式 --truncate table 表名 delete from employees2 --不带条件全部删除 清空时有记录,在日志文件中记录了清空数据 delete from employees1 where 性别=0 --符合条件的删除 truncate table employees1 -- 与delete from employees1 效果相同 清空没有记录,数据不能恢复 --在插入有标识列的信息时,因失误而需要删除信息重新插入时的方法 --1、 用delete from employees2 删除,重新插入信息标识号不连续,只能删除数据表重新插入 --2、 用truncate table employees2 删除,重新插入信息标识号连续
-