系列文章目录
文章目录
- 系列文章目录
- 前言
- 第7章 Structured Streaming
- 7.1 概述
- 7.1.1 基本概念
- 7.1.2 两种处理模型
- 7.1.3 Structured Streaming 和 Spark SQL、Spark Streaming 关系
- 7.2 编写Structured Streaming程序的基本步骤
- 7.3 输入源
- 7.3.1 File源
- 7.3.2 Kafka源
- 7.3.3 Socket源
- 7.3.4 Rate源
- 7.3.1 File源
- 7.3.2 Kafka源
- 7.3.3 Socket源
- 7.3.4 Rate源
- 7.4 输出操作
- 7.5 容错处理(自学)
- 7.6 迟到数据处理(自学)
- 7.7 查询的管理和监控(自学)
- 总结
前言
第7章 Structured Streaming
7.1 概述
7.1.1 基本概念
- Structured Streaming的关键思想是将实时数据流视为一张正在不断添加数据的表
- 可以把流计算等同于在一个静态表上的批处理查询,Spark会在不断添加数据的无界输入表上运行计算,并进行增量查询
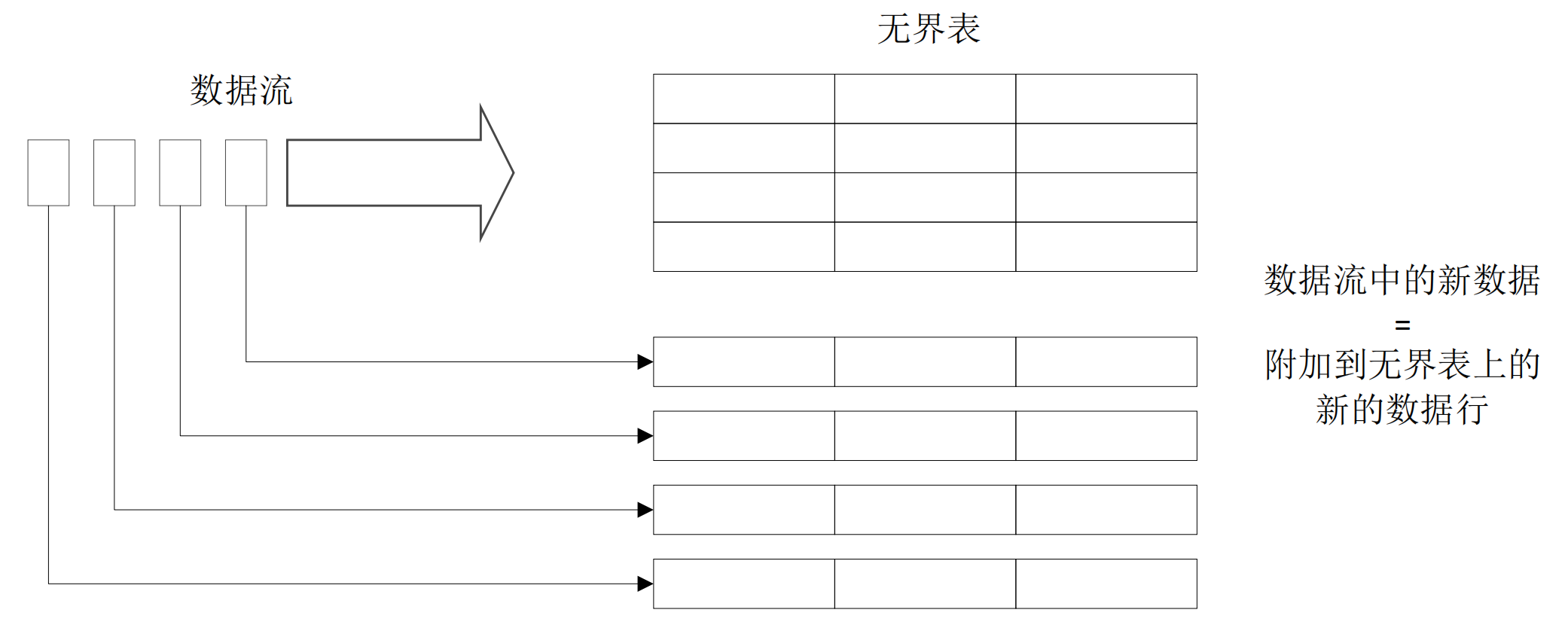
- 在无界表上对输入的查询将生成结果表,系统每隔一定的周期会触发对无界表的计算并更新结果表
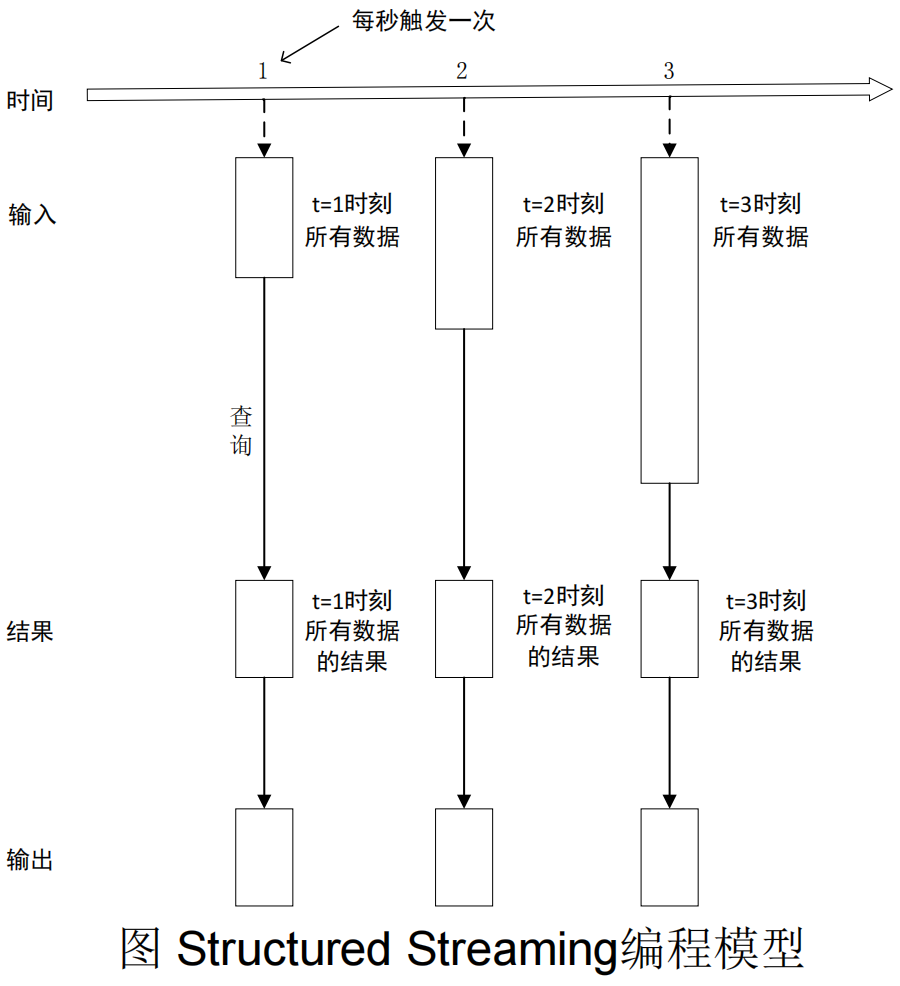
7.1.2 两种处理模型
(1)微批处理
- Structured Streaming默认使用微批处理执行模型,这意味着Spark流计算引擎会定期检查流数据源,并对自上一批次结束后到达的新数据执行批量查询
- 数据到达和得到处理并输出结果之间的延时超过100毫秒
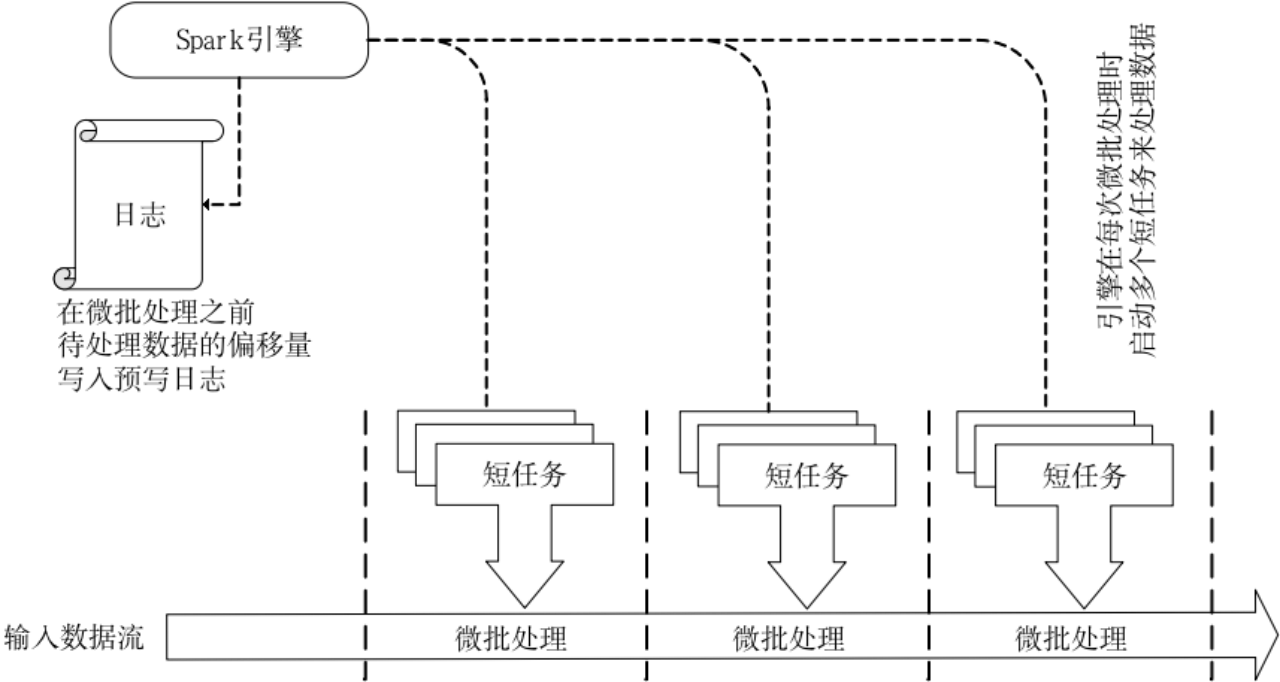
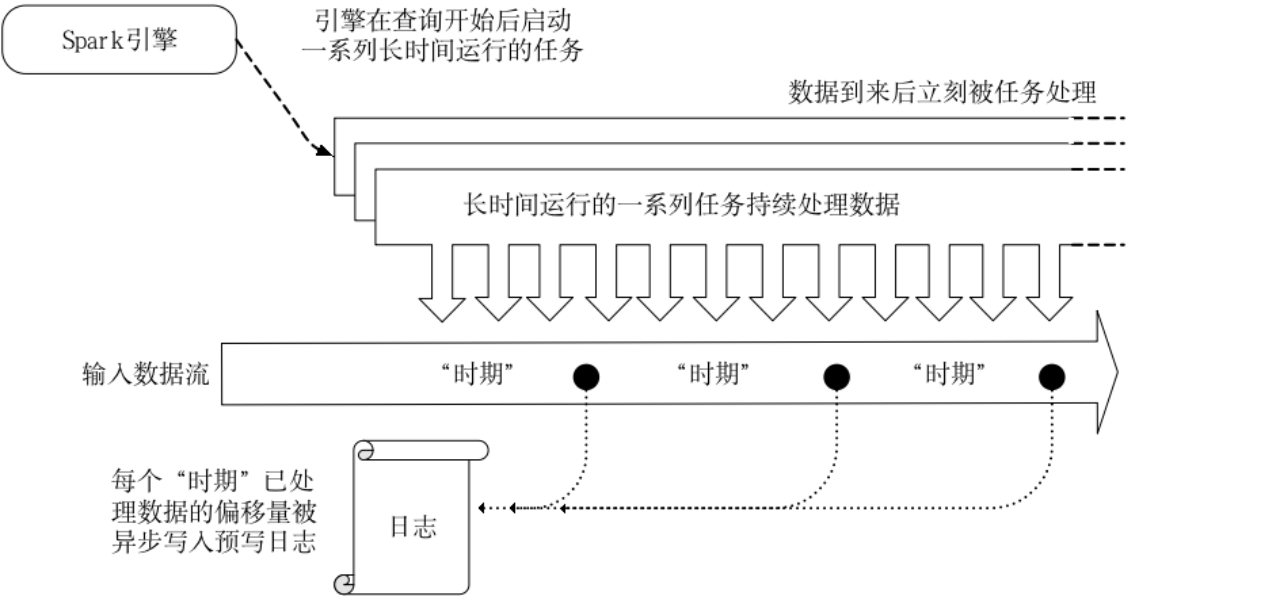
(2)持续处理
- Spark从2.3.0版本开始引入了持续处理的试验性功能,可以实现流计算的毫秒级延迟
- 在持续处理模式下,Spark不再根据触发器来周期性启动任务,而是启动一系列的连续读取、处理和写入结果的长时间运行的任务
7.1.3 Structured Streaming 和 Spark SQL、Spark Streaming 关系
- Structured Streaming处理的数据跟Spark Streaming一样,也是源源不断的数据流,区别在于,Spark Streaming采用的数据抽象是DStream(本质上就是一系列RDD),而Structured Streaming采用的数据抽象是DataFrame。
- Structured Streaming可以使用Spark SQL的DataFrame/Dataset来处理数据流。虽然Spark SQL也是采用DataFrame作为数据抽象,但是,Spark SQL只能处理静态的数据,而Structured Streaming可以处理结构化的数据流。这样,Structured Streaming就将Spark SQL和Spark Streaming二者的特性结合了起来。
- Structured Streaming可以对DataFrame/Dataset应用前面章节提到的各种操作,包括select、where、groupBy、map、filter、flatMap等。
- Spark Streaming只能实现秒级的实时响应,而Structured Streaming由于采用了全新的设计方式,采用微批处理模型时可以实现100毫秒级别的实时响应,采用持续处理模型时可以支持毫秒级的实时响应。
7.2 编写Structured Streaming程序的基本步骤
- 编写Structured Streaming程序的基本步骤包括:
- 导入pyspark模块
- 创建SparkSession对象
- 创建输入数据源
- 定义流计算过程
- 启动流计算并输出结果
- 实例任务:
- 一个包含很多行英文语句的数据流源源不断到达,
- Structured Streaming程序对每行英文语句进行拆分,并统计每个单词出现的频率
1.步骤1:导入pyspark模块
- 导入PySpark模块,代码如下:
from pyspark.sql import SparkSession
from pyspark.sql.functions import split
from pyspark.sql.functions import explode
由于程序中需要用到拆分字符串和展开数组内的所有单词的功能,所以引用了来自pyspark.sql.functions里面的split和explode函数。
2.步骤2:创建SparkSession对象
- 创建一个SparkSession对象,代码如下:
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN')
3.步骤3:创建输入数据源
- 创建一个输入数据源,从“监听在本机(localhost)的9999端口上的服务”那里接收文本数据,具体语句如下:
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
4.步骤4:定义流计算过程
- 有了输入数据源以后,接着需要定义相关的查询语句,具体如下:
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
wordCounts = words.groupBy("word").count()
5.步骤5:启动流计算并输出结果
- 定义完查询语句后,下面就可以开始真正执行流计算,具体语句如下:
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.trigger(processingTime="8 seconds") \
.start()
query.awaitTermination()


7.3 输入源
- File源(或称为“文件源”)以文件流的形式读取某个目录中的文件,支持的文件格式为csv、json、orc、parquet、text等。
- 需要注意的是,文件放置到给定目录的操作应当是原子性的,即不能长时间在给定目录内打开文件写入内容,而是应当采取大部分操作系统都支持的、通过写入到临时文件后移动文件到给定目录的方式来完成。
7.3.1 File源
- File源(或称为“文件源”)以文件流的形式读取某个目录中的文件,支持的文件格式为csv、json、orc、parquet、text等。
- 需要注意的是,文件放置到给定目录的操作应当是原子性的,即不能长时间在给定目录内打开文件写入内容,而是应当采取大部分操作系统都支持的、通过写入到临时文件后移动文件到给定目录的方式来完成。
- 一个实例:
- 这里以一个JSON格式文件的处理来演示File源的使用方法,主要包括以下两个步骤:
- 创建程序生成JSON格式的File源测试数据
- 创建程序对数据进行统计
- 这里以一个JSON格式文件的处理来演示File源的使用方法,主要包括以下两个步骤:
(1)创建程序生成JSON格式的File源测试数据
- 为了演示JSON格式文件的处理,这里随机生成一些JSON格式的文件来进行测试。
- 代码文件spark_ss_filesource_generate.py内容如下:




- 这段程序首先建立测试环境,清空测试数据所在的目录,接着使用for循环一千次来生成一千个文件,
- 文件名为“e-mall-数字.json”,
- 文件内容是不超过100行的随机JSON行,行的格式是类似如下:
- {“eventTime”: 1546939167, “action”: “logout”, “district”: “fujian”}\n
(2)创建程序对数据进行统计
- spark_ss_filesource.py”,其代码内容如下:




(3)测试运行程序