目录
库的操作
显示数据库
创建数据库
创建数据库案例
删除数据库
删除数据库案例
字符集和校验规则
字符集
校验规则
小结
查看数据库支持的字符集
查看数据库支持的校验规则
校验规则对数据库的影响
不区分大小写
区分大小写
进行查询
结果排序
修改数据库
修改数据库案例
备份和恢复
备份
备份数据库案例
还原
注意事项
查看连接数
库的操作
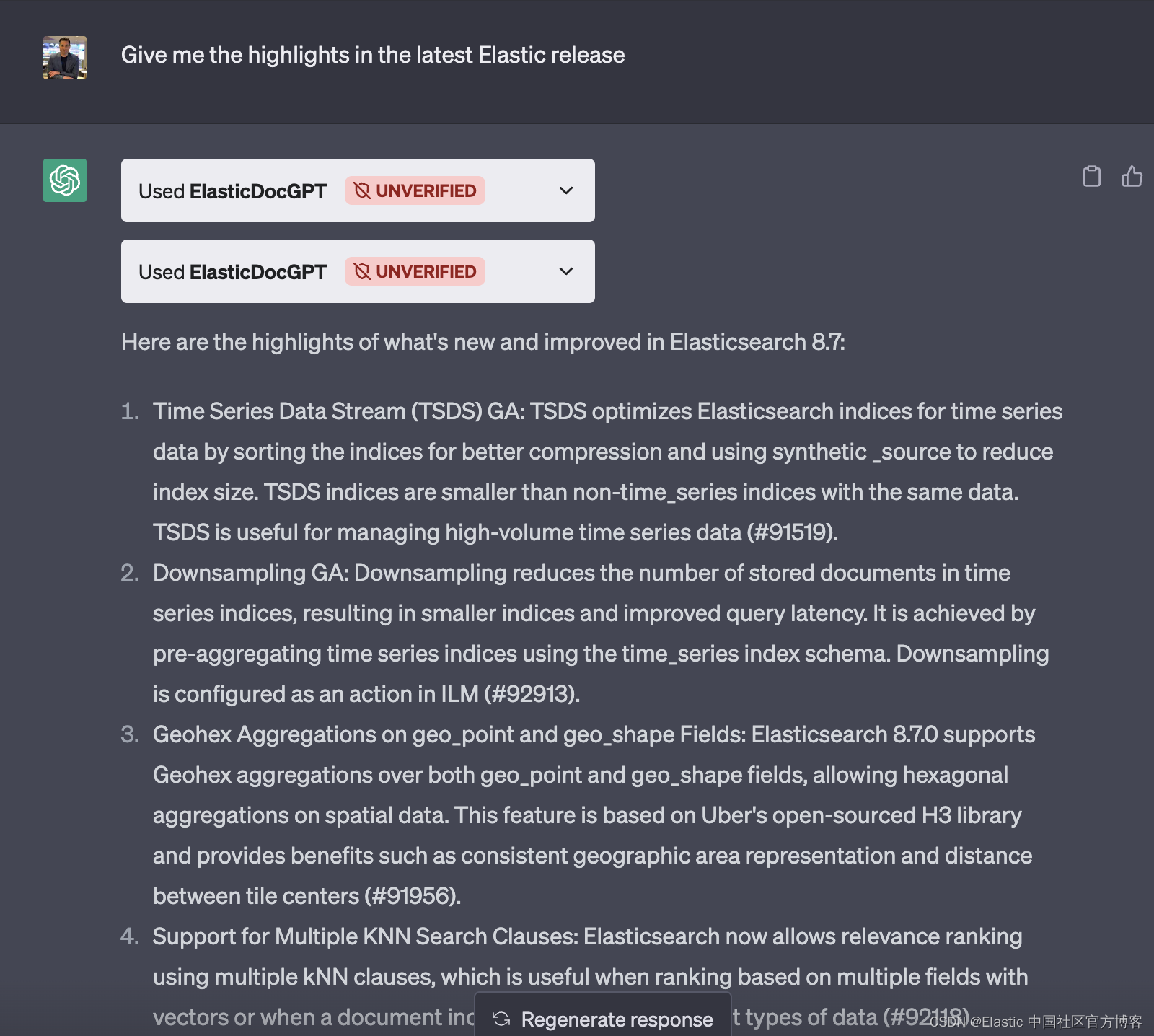
显示数据库
show database;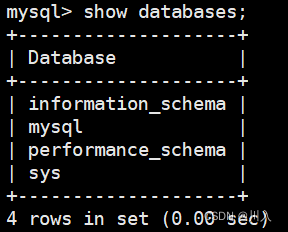
创建数据库
语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification] [create_specification] ...
----------------------------------------
更多的SQL选项语句:
[IF NOT EXISTS] - 如果不存在(创建数据库如果不存在才创建,存在就不创建了)
create_specification: - 创建时的选择项字段
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name- 大写的表示关键字
- [] 是可选项
- CHARACTER SET:指定数据库采用的字符集(数据库编码)
- COLLATE:指定数据库字符集的校验规则(数据库校验规则 / 校验码)
创建数据库案例
- 创建名为 cr 的数据库:
输入:
create database cr;输出:
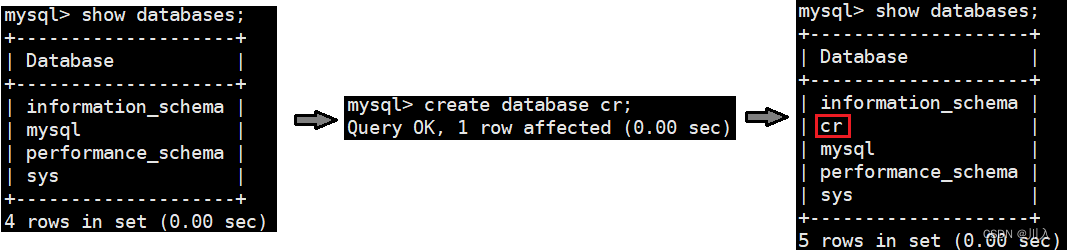
- 查看创建的数据库 cr 的详细信息:
输入:
show create database cr;
输出:

Create Database:
创建数据库时的SQL语句。可以发现其写的和我们之前写的是不一样的,因为MySQL是大小写不敏感的,可以写大写也可以写小写,其实严格意义上讲写大写是推荐的。
#:仅仅是SQL语句的语法关键字是支持大小写忽略的。
而一般关于数据库名或表名可以用反引号(键盘的Esc下一个键),也可不。一般是如下列情况采用:
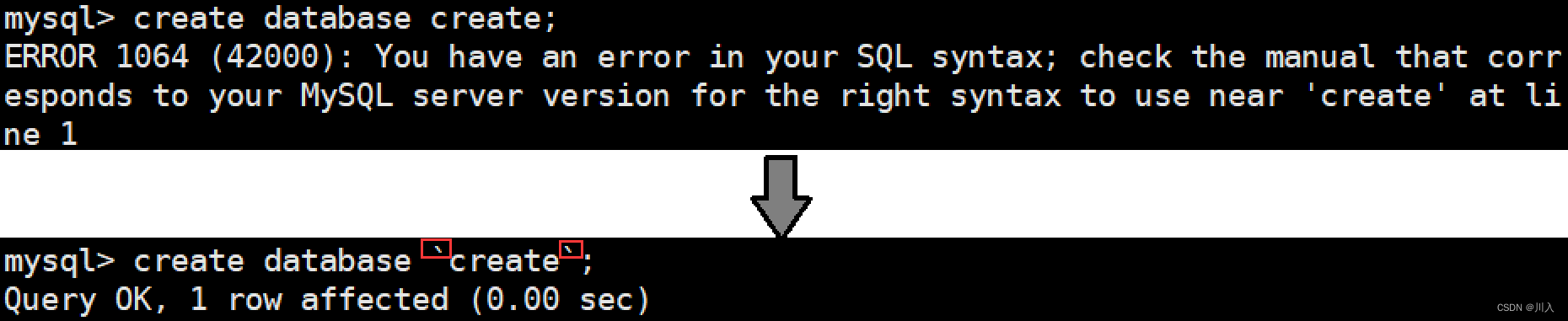
换而言之:加不加反引号,取决于我们对应的创建的数据库,以及未来的表,它的名称是否和我们的系统当中的某一些关键字冲突 - 正常来讲都得加上。
还有后面一大推:
/*!40100 DEFAULT CHARACTER SET utf8 */这个东西不是注释,它指的是如果当前我们用的MySQL的版本大于4.01版本,其就会默认执行:
DEFAULT CHARACTER SET utf8也就是说:版本小于4.01版本用前面的SQL语句,大于4.01版本前面的SQL语句拼上后面的SQL语句。
删除数据库
语法:
DROP DATABASE [IF EXISTS] db_ name;- 对应的数据库文件夹被删除,其是级联(递归)删除,里面的数据表全部被删。
#:不要随意删除数据库
删除数据库案例
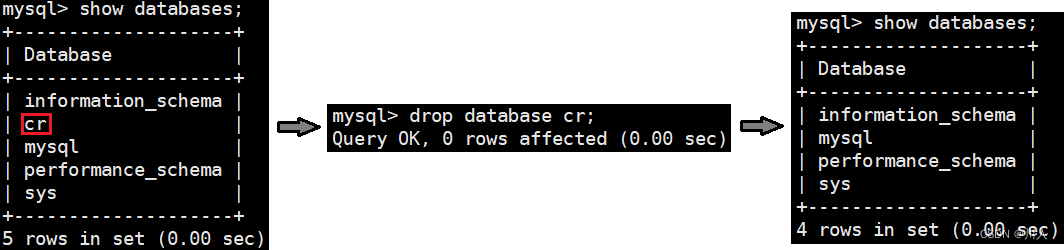
- 删除名为 cr 的数据库:(慎重)
输入:
drop database cr;输出:
字符集和校验规则
数据库是用来保存数据的,保存数据的时候,对于一个数据库来讲,必须得有统一的编码。因为编码意味着未来如何去存 / 取,以及最后的识别 / 对比。就如同整数类型和浮点数类型,对于一个二进制类型的解释是不同的。
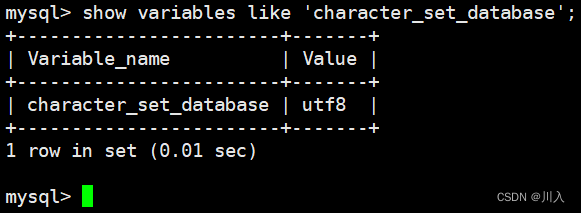
show variables like 'character_set_database'; - 查看系统字符集
show variables like 'collation_database'; - 查看系统校验规则MySQL的核心工作:
- 存数据 - 按照特定的编码来进行存储(数据库的字符集来保证)
- 取数据 - 比较(筛选的本质)(数据库的校验编码来保证)
字符集
MySQL在服务启动之后,MySQL内部会存在很多很多的variables,这些variables其实也是在数据库表里面存着的。MySQL在服务启动的时候,有一些常用的variables值可能load到MySQL进程的上下文当中。这个东西就有点像在Linux中所学到的环境变量,环境变量是:一旦我们在Linux中设置好了环境变量,那么我们的进程 / 子进程 / 用户,就能够继承使用我们的环境变量。同样的这个variables一般都是MySQL系统当中的全局的一些变量,这些变量一旦被设置好,默认在使用的时候,创建库 / 表 / 做比较的时候都会采用上面某些设置好的变量。
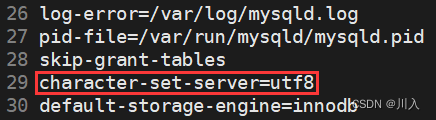
这是本人在/etc/my.cnf的配置文件内配置的。
服务端的字符编码,全部采用的是utf8。
使用%,类似于Linux的* -- 模糊匹配。
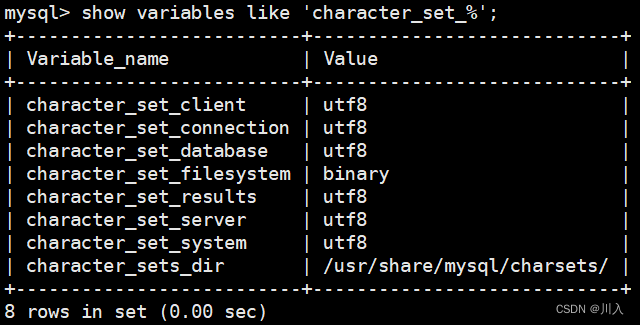
可以看到,只要使用到/etc/mycnf配置文件,客户端、连接通信、数据库、结果、服务端、系统都是utf8的,文件系统(将数据写道磁盘上、写道文件里)不考虑,采用的是二进制方案。最后一个是编码集所在的位置。
也就是为来存数据的时候,保证整个数据库里面存的所有的数据全部都是utf8的。字符集和校验规则(集)必须是匹配的,是MySQL自动匹配的。
校验规则
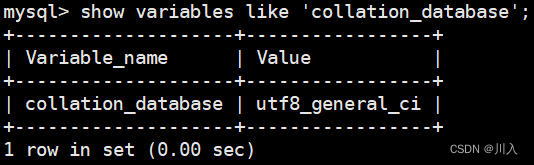
utf8_general_ci:utf8的通用校验集。
所以,我们将字符集配utf8之后,其实我们的MySQL默认给我们匹配的校验级就是这个样子,也就是说未来如果想进行存数据的时候,MySQL就按照utf8的方式存。如果想进行数据的比较,查一个字段,采用的比较规则(查找方式)就是utf8_general_ci。
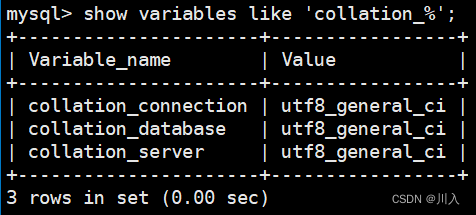
可以看到整个系统当中,无论是连接、数据库内部、服务器内部,清一色都是utf8_general_ci。因为MySQL的配置文件里,我进行了配置当前的规则。
小结
数据库存和取是有对应的校验规则的,存是有它的编码,取是有它的校验规则,存和取的校验规则必须保持一致。而且我们只需要指明字符集是什么,默认它的校验集MySQL就会自动的确认 -- 二者是有关系的。
所以整个数据库的所有编码都是可预测、可衡量、可确认的,未来再怎么存数据,一旦发现数据库乱码了,至少一定可以确认的是一定不是数据库的问题,一定是当时在存的时候没有指明编码格式,而存过去在数据库里的数据直接被解释为utf8进行了存储,导致最后变成乱码 -- 即:MySQL那里是utf8,交给其的数据也就必须是utf8的。
查看数据库支持的字符集
输入:
show charset;输出:
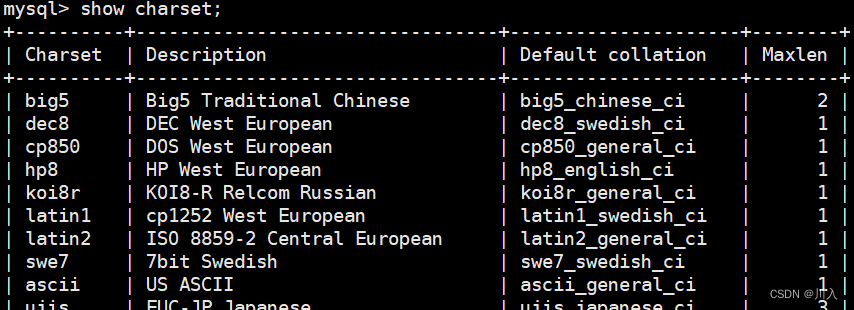
这个是MySQL数据库目前支持的所有编码,并不代表当前是全部都使用,用的哪些 - 就是上面的显示,配置的哪些,字符集主要是控制用什么语言,比如:utf8就可以使用中文。

查看数据库支持的校验规则
输入:
show collation;输出:
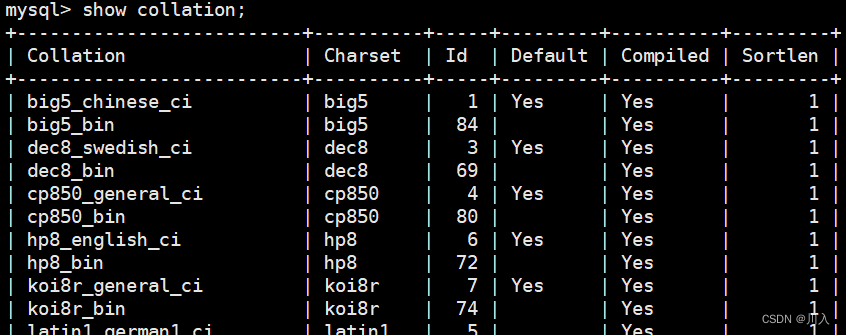
这个是MySQL数据库目前支持的所有校验规则(集)。

#问:编码集与校验集是给谁用的?
是给数据库以及给数据库所对应的表来用的,根上就是给表来用的。创建数据库时,我们可以直接在数据库里面指明这个数据库内部所采用的编码集和校验规则。也就是说,我们在创建数据库的时候,可以指明这个数据库所采用的编码集和校验规则。
之前输入:
create database cr;如果不指明数据库编码集和校验规则,该数据库默认会使用MySQL目前已经配置好的编码集和校验规则的方案 - 但是,想的就是使用默认设置的utf8,所以不指明是主流,并且并不能保证所有的MySQL是默认utf8的,所以配置文件写明主要的是为了确定性。
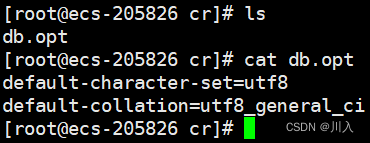
创建一个空的数据库,其唯一的一个db.opt文件里面,保存的就是默认的字符集和默认的校验规则。
指明的输入:
有两种等价的写法:
create database cr charater set gbk;
create database cr charset=gbk;先就只指明字符集。
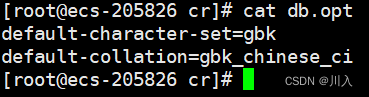
这次创建的一个空的数据库,其唯一的一个db.opt文件里面,保存的就是指明的字符集,然后还自动的找对应的校验规则。
create database cr charset=utf8 collate utf8_bin;
create database cr charset=utf8 collate=utf8_bin;指明字符集与校验规则。
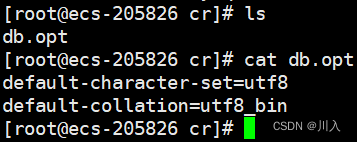
这就叫做创建一个对应的数据库的时候,指明编码集和校验规则,这样也可以创建数据库。
校验规则对数据库的影响
#问:设置数据库的编码和校验规则,本质会影响谁?
在MySQL当中,数据库就是一个目录,所有目录里面放的东西就是未来的表。实际上这些编码和校验规则,并不是影响数据库,其实是影响对应的数据库内部的表,和所对应的编码和校验规则。
创建表的时候可以指定编码和校验规则,或者其默认的看设置的数据库的编码和校验规则。所以:
- 数据库受:创建数据库的SQL语句的影响 + 系统本身的影响。
- 表受:创建表的SQL语句的影响 + 数据库的影响。
一环扣一环,并且前者SQL语句先。
-
不区分大小写
建数据库test1 :
create database test1 collate utf8_general_ci;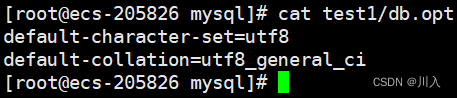
选择数据库test1 :
use test1;use可以理解为相当于cd进入到某个目录(数据库)的行为。
建表:(此文不讲,只为展示)
create table person(name varchar(20));插入数据:(此文不讲,只为展示)
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');查看表:(此文不讲,只为展示)
show tables;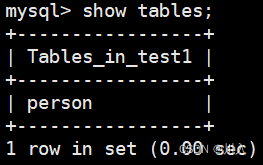
查看表的内容:(此文不讲,只为展示)
select * from person;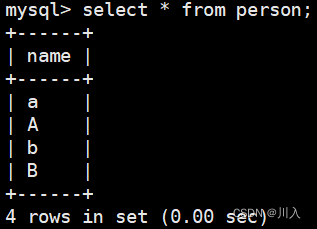
-
区分大小写
create database test2 collate utf8_bin;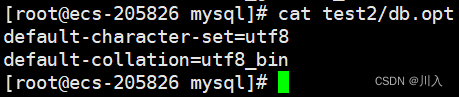
(跟上述操作一样,此处略省略)
建表:(此文不讲,只为展示)
create table person(name varchar(20));插入数据:(此文不讲,只为展示)
insert into person values('a');
insert into person values('A');
insert into person values('b');
insert into person values('B');-
进行查询
1、 不区分大小写的查询以及结果 (此文不讲,只为展示)
use test1;
select * from person where name='a';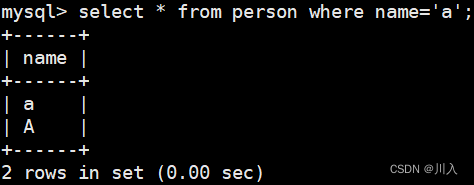
2、 区分大小写的查询以及结果 (此文不讲,只为展示)
use test2;
select * from person where name='a';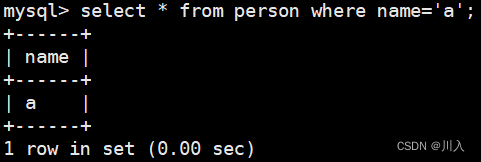
会发现上述二者的编码集是一样的utf8,但是二者的校验规则是不一样的,而:utf8_general_ci忽略大小写,utf8_bin严格的按照是否相等的比较查找方式。
补充:
查看当前自己在什么数据库下。
select database();
便可以知道现在,在test2数据库中的。可以理解为相当于pwd查看当前路径。

-
结果排序
1、不区分大小写排序以及结果(此文不讲,只为展示)
use test1;
select * from person order by name;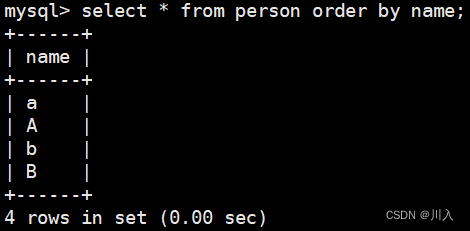
2、 区分大小写排序以及结果 (此文不讲,只为展示)
use test2;
select * from person order by name;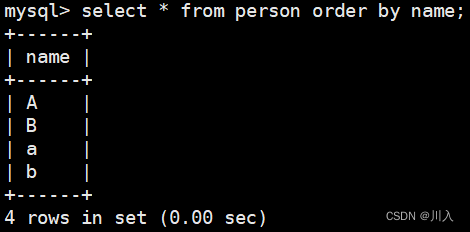
就是排序本质就是比较,而比较就需要使用校验规则。
修改数据库
ALTER DATABASE db_name [alter_spacification] [alter_spacification]...
-------------------------------------
alter_spacification: - 创建时的选择项字段
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name- 对数据库的修改主要指的是修改数据库的字符集和校验规则。
#:以前MySQL支持对数据库名的修改,但是现在不支持了。
很好玩的是,我们前面已经讲到的对数据库的理解,在Linux中简易的理解就是一个目录,所以其实利用Linux命令mv就可以修改名。但是千万不要这么干,MySQL不愿意提供就是最有利的证明。并且,会出现其他问题,如对此方式改名的数据库无法删除,所以千万不要这么干(如果你已经干了,那就使用rm删)!
拷贝也一样,我们可以将整个文件拷走,这么干运行上可以,但是行为是违规的、很不好的,都要人家MySQL进行管理了,还越过其进行操作是不合理的。
修改数据库案例
输入:
alter database test charset=gbk;
alter database test character set gbk;
alter database test charset=gbk collate=gbk_chinese_ci;输出:

备份和恢复
需要保证:
- MySQL服务是启动的。
- 权限操作是对应的(数据库是自己的)。
备份
我们不使用mysql客户端,而在安装MySQL的时候,其早就考虑到了我们需要做数据库备份,所以给了我们一个mysqldump的工具。

mysqldump也是一个客户端,通常是用来做数据库备份的。
mysqldump -P 3306 -u root -p (可以在这里显示的写密码) -B 数据库名 > 数据库备份存储的文件路径备份数据库案例
mysqldump -P3306 -uroot -p -B test1 > test1.sql;![]()
这个时候,可以打开看看test.sql文件里的内容。
[root@ecs-205826 mysql]# cat test1.sql
-- MySQL dump 10.13 Distrib 5.7.41, for Linux (x86_64)
--
-- Host: localhost Database: test1
-- ------------------------------------------------------
-- Server version 5.7.41
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Current Database: `test1`
--
CREATE DATABASE /*!32312 IF NOT EXISTS*/ `test1` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `test1`;
--
-- Table structure for table `person`
--
DROP TABLE IF EXISTS `person`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `person` (
`name` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `person`
--
LOCK TABLES `person` WRITE;
/*!40000 ALTER TABLE `person` DISABLE KEYS */;
INSERT INTO `person` VALUES ('a'),('A'),('b'),('B');
/*!40000 ALTER TABLE `person` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
-- Dump completed on 2023-05-14 18:36:23
主流数据库的备份方式:
- 对数据做备份
- 对操作语句做备份 - mysqldump
融汇贯通的理解:
我们前面所说的利用Linux命令做的备份,只是将数据内容做备份,但是实际上是数据库历史上被进行的操作,比如说:100次。
其将我们历史上所有的100条SQL语句全部记录下来,然后其备份就是将历史上的100条数据全部执行一遍,最后的数据库状态就和拷贝的数据库状态一样了。
所以数据库备份,mysqldump对应的是将历史的所有的SQL语句,全部保留下来做的备份,因为这样比较好,因为数据没有上下文,但是语句有上下文,可以看数据是如何而来,可读性好、效率性不低、好备份。更重要的是执行某些SQL语句的时候,SQL语句后面可以带时间。如果能带时间,后面可以备份某个时间区间内的数据,即执行这个区间内的SQL语句。
(知道就行,此处略微提及)
并且,可以看出他还对我们的SQL进行了优化,就比如将我们的多次insert变为一次,进行了合并 - 所以其是一个工业型的软件。
还原
source 备份的数据库路径;输入:
将之前的数据库删除,再以拷贝的test.sql复原。
source /root/mysql/test1.sql;输出:
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 1 row affected (0.00 sec)
Database changed
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.02 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected, 1 warning (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.00 sec)可以发现他就是将操作语句做备份,然后复原的时候就是执行SQL语句。
注意事项
#: 如果备份的不是整个数据库,而是其中的一张表。
不用带-P选项。
mysqldump -u root -p 数据库名 表名1 表名2 > 表存放路径#:同时备份多个数据库。
mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径查看连接数
show processlist;

在使用的时候,MySQL甄别有多少人正连接其,是谁连、在哪里连、连的是哪个数据库、当前的状态、访问了几次、……。