一、概述
title:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
论文地址:https://arxiv.org/abs/2110.07602
代码:GitHub - THUDM/P-tuning-v2: An optimized deep prompt tuning strategy comparable to fine-tuning across scales and tasks
1.1 Motivation
- 之前的prompt tuning方法对正常大小的模型(小模型例如BERT)效果比较差,另外对于有些任务(例如序列标注)效果也不太行。
- 本文提出一个方法适应于不同大小的模型,并且对各种NLU任务效果都不错,
1.2 Methods
- 之前的prompt tuning方法只在embedding层加了prompt参数,本文在其他层也添加可训练的prompt参数,提升其适用各种任务的容量(能力)
1.3 Conclusion
- 添加可训练的参数,提升其适应各式各样任务的能力
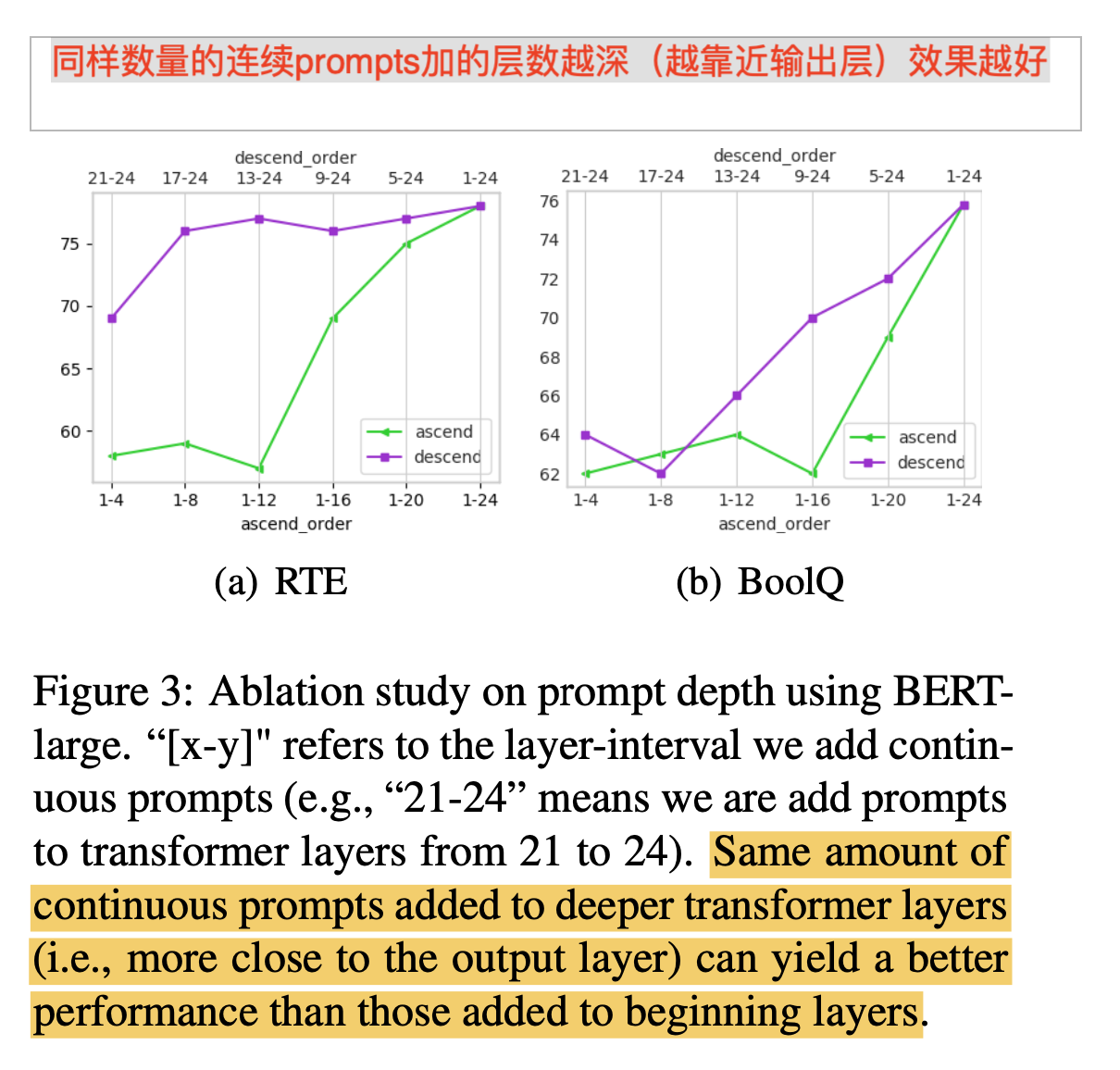
- 加的位置越深(越靠近输出层),效果越好
1.4 limitation
- 创新新可能不太够,但是提供了一个强的baseline,具有高的准确率和参数有效性。
二、详细内容
1 与v1版本效果对比,可以适用于各种大小的模型
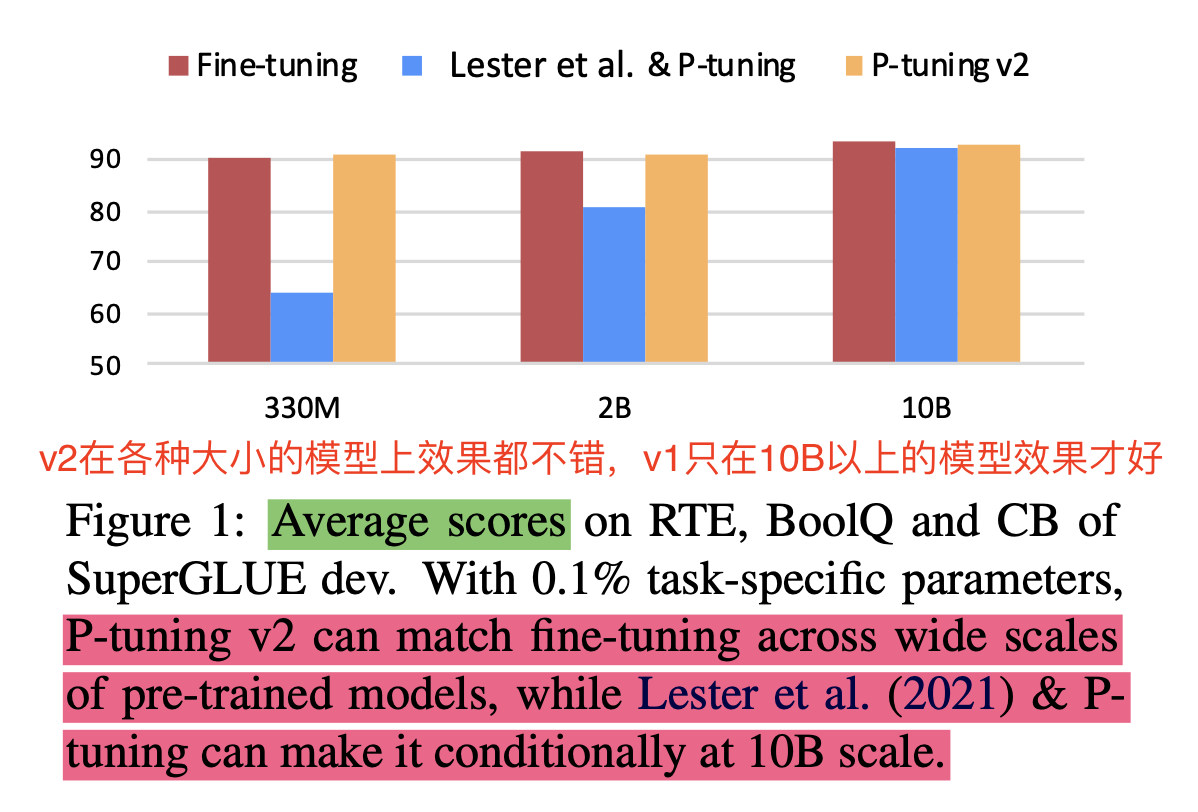
- v1模型在330M的模型上,效果比fine-tuning差的比较多,如今v2版本,基本和fine-tuning在各种尺寸上效果都差别不大了。
2 与v1版本模型结构对比
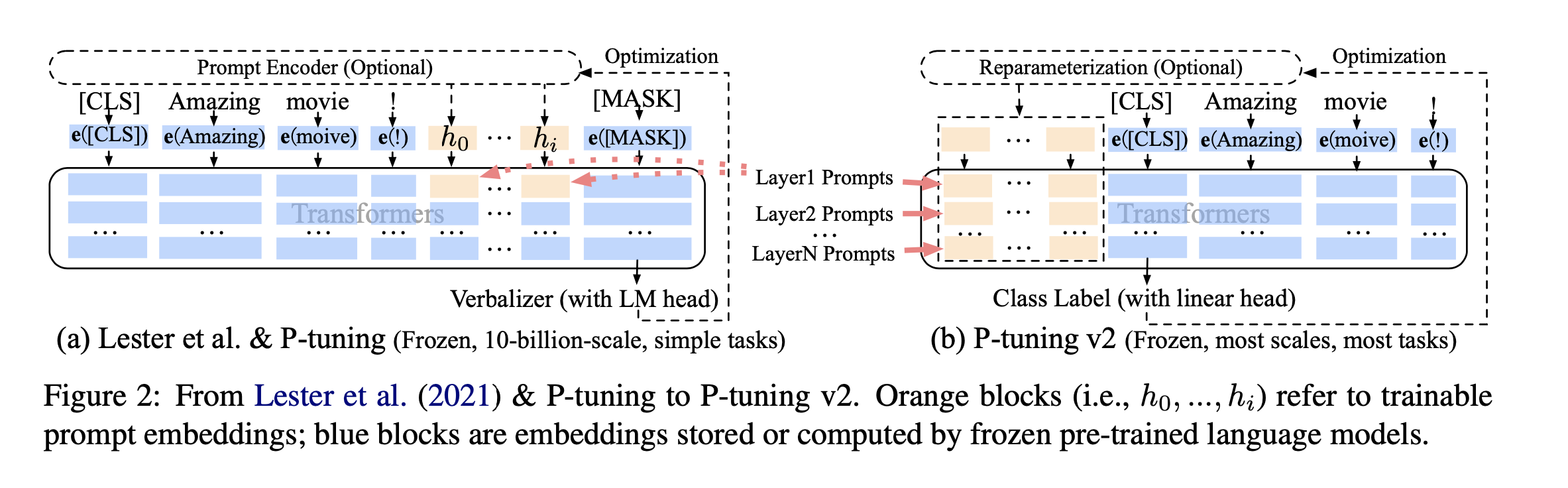
- v1:
-
- 因为序列长度的限制,可训练的参数还比较少
- 输入的embeding没有直接影响模型的输出
- v2
-
- 每一层都加上可训练的参数,可训练的参数变多了(0.01%->0.1%-0.3%),对各式各样的任务,有更大的容量(能力)去适应
- prompt加到更深的层次,可以直接影响输出
3 模型效果
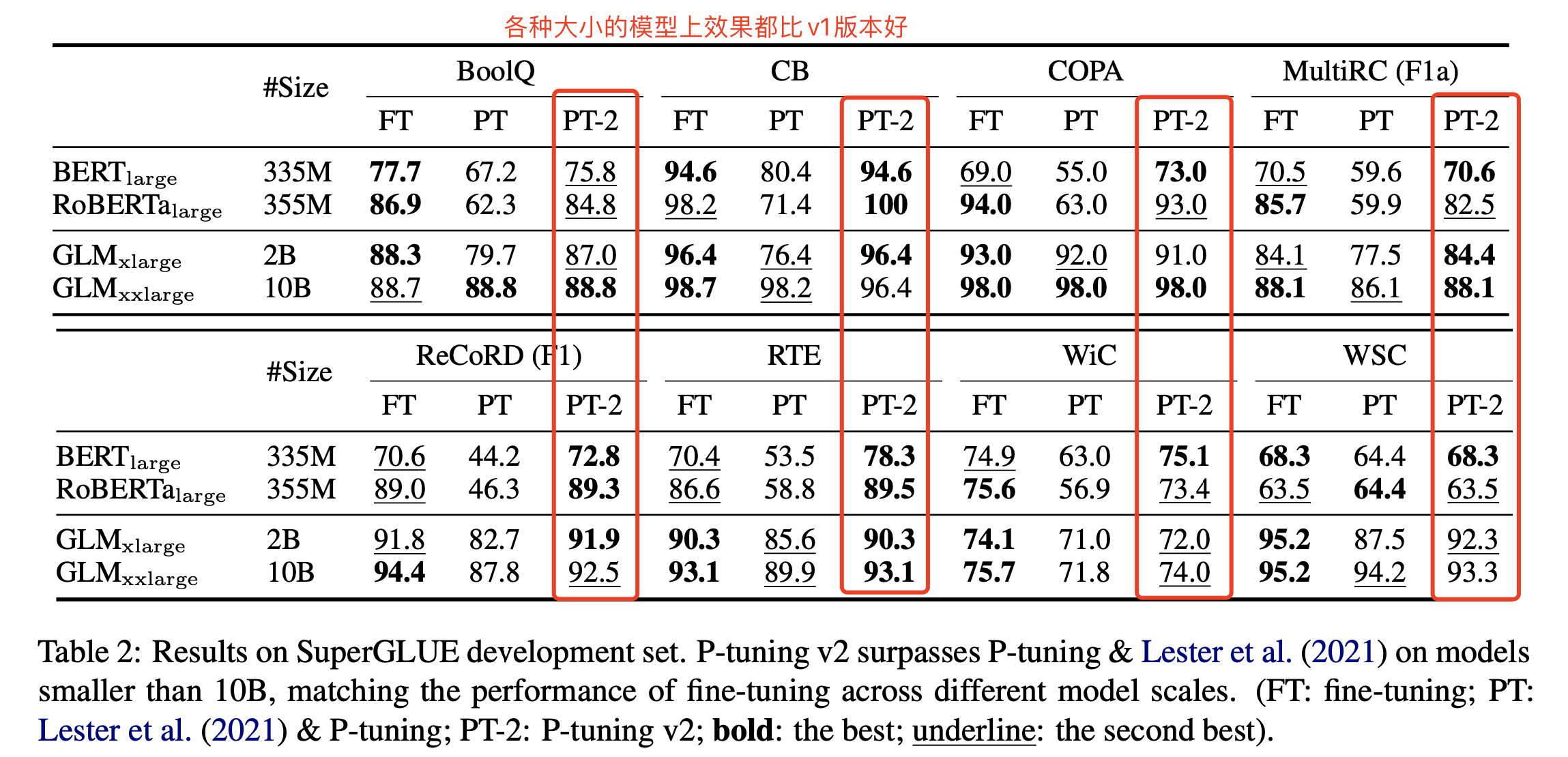
- 在NLU任务上,不同尺寸的模型,效果都比v1版本好
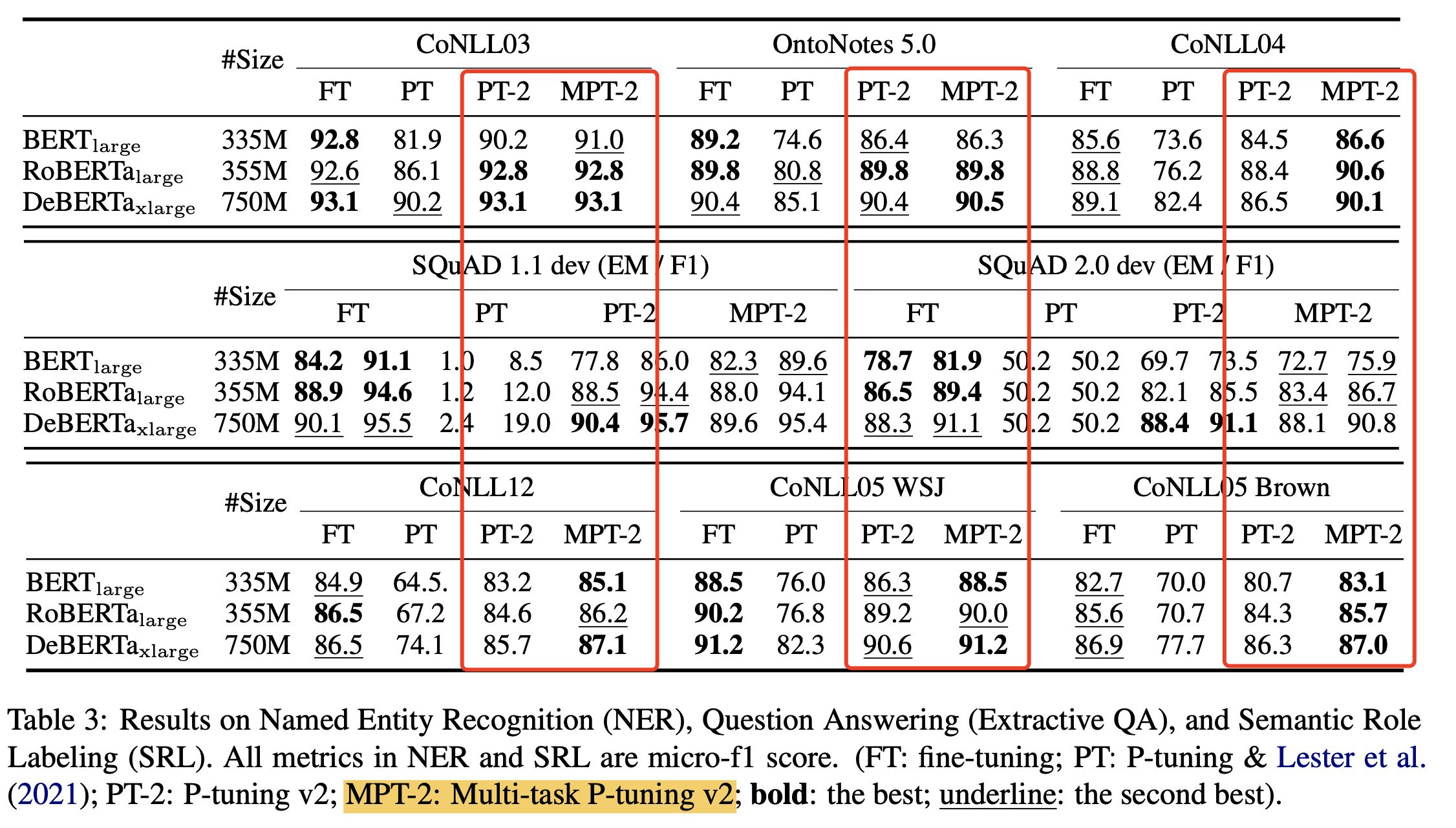
- 在序列标注任务,QA任务,语义角色Labeling上,效果也比v1版本好
- Multi-task:多任务训练初始化,可以获得持续的提升
4 同样数量的连续prompts加的层数越深(越靠近输出层)效果越好