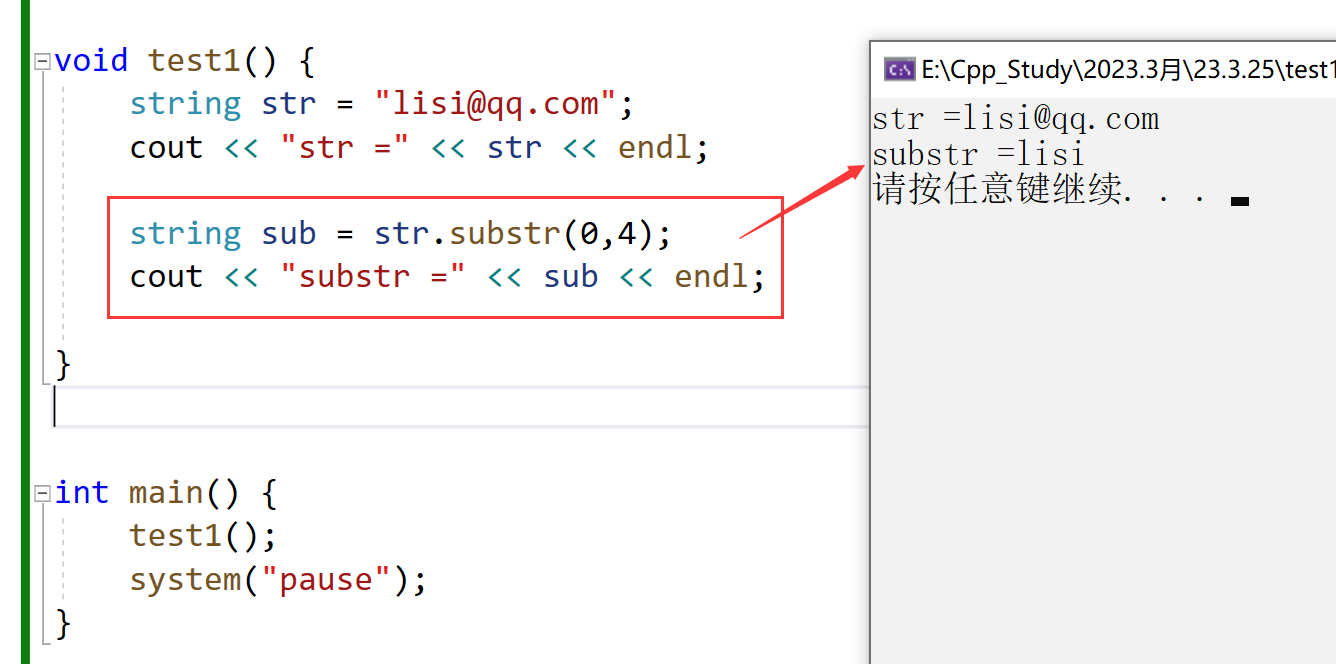
分布式锁的实现?
答:
应用比较广泛:后台业务的防重提交
以前的传统应用用户流量比较小,为了节省成本,很多应用的成本都是单节点部署,为了解决单节点访问资源一致性的问题,对于java来说,一般使用的是synchronized和Renntrantlock锁来进行实现的,但是随着微服务架构的兴起,为了支持高并发的流量,和高可用的结构,应用逐渐就从单节点到多节点,到集群,这个时候jvm的锁就没有办法满足我们的需求了,于是就出现了分布式锁的概念,那么分布式锁究竟是什么,分布式锁是分布式系统或者集群环境下,多进程可见,并且互斥的锁,如果要实现优秀的分布式锁,需要具备的特性,首先这个锁对多个集群节点是可见的,其次,这个锁对各个节点是互斥的,这个锁还必须是高可用的,不能在我业务执行的过程中,这个锁突然失效了,最后这个锁必须是高性能的,一个优秀的分布式锁加锁一般都是几毫秒。在互联网高并发的情况下会出现各种各样的问题,失效锁重入,所以分布式锁高可用就要支持这些异常的场景。
1.常见的分布式锁的方案:
1.基于数据库的实现(3种) C端高并发不适合,后台管理系统,可以根据场景选择这个方案
1.防重表(新系统可以使用,因为他是不侵入我们的业务,实现简单)
通过操作表的数据来实现,获取锁的时候插入一条记录,释放锁的时候删除一条记录。
设计字段:id(自增) 唯一的key 创建时间 更新时间等等
怎么获取锁和释放的锁的呢?
执行业务方法的时候,我们可以向这个表插入一条记录,这个记录里面的唯一key可以设置为业务的主键,或者业务的编号。如果多个请求进入这个方法,那么只有一个方法能够插入成功。因为我们的数据库有一个唯一的key做保证的。加完锁的话就执行我们的业务逻辑,执行完业务逻辑的话,我们就要释放锁,通过根据防重表里面的唯一键去删除对应的记录。删除了之后,这个请求他持有的分布式锁就被释放掉了,后面的请求过来的话,就可以拿到这个锁。
优点:就是方案很简单,只需要以来数据库,不需要依赖任何的中间件
缺点:当我们执行方法插入防重表记录的时候,把它加锁了,这个时候由于其他原因被重启了,锁的记录没有被释放,就会产生了死锁,所以,我们的解决方法就是在防重中加入一个过期时间的字段。再起一个定时任务,定时去扫描当前过期时间和我们的当前时间做对比,如果说过期了的话我们就把这条记录给删掉,这样我们就实现了死锁的问题。
再就是阻塞的问题。 锁的可重入问题(这个可以通过在表中加一个字段线程的id,加锁的次数字段,获取了锁的进程每次进来就把次数字段+1,每次释放-1,直到线程次数为0,这个线程持有的锁就会释放)
2.悲观锁(性能差,最简单)
利用了业务表的行锁,sql中用for update把他给锁掉,但是mysql的innodb在进行加锁的时候,必须要加一个唯一的索引主键,如果不加这个的话,那查询的时候用for update可能会把你的整个表都给锁了,所以在用的时候要非常的慎重
执行的过程:以spring为例。
a.开启spring的事务的自动事务提交,比如在方法或者类上加一个transaction,
b.开始执行锁掉的记录,select …for update来实现
c.执行业务逻辑。
d.spring自动提交事务,最后就把锁给释放掉了
优点:1.天然的实现了阻塞
缺点:2.性能很差
3.乐观锁
一般我们认为数据的更新是不会发生冲突的,只有数据库在更新提交的时候,我们才会进行数据的检测,如果在检测的时候出现了数据不一致的情况,就会返回失败的信息,实现乐观锁的话就要可以加版本号、时间戳
优点:不用锁表,也不用锁记录,他会检测这个数据的版本是不是一致 ,相对来说他的性能会比悲观锁要强很多,但是高并发发时候,对数据库的冲击也比较大,因为版本号要经常的去更新和维护
2.基于redis的实现
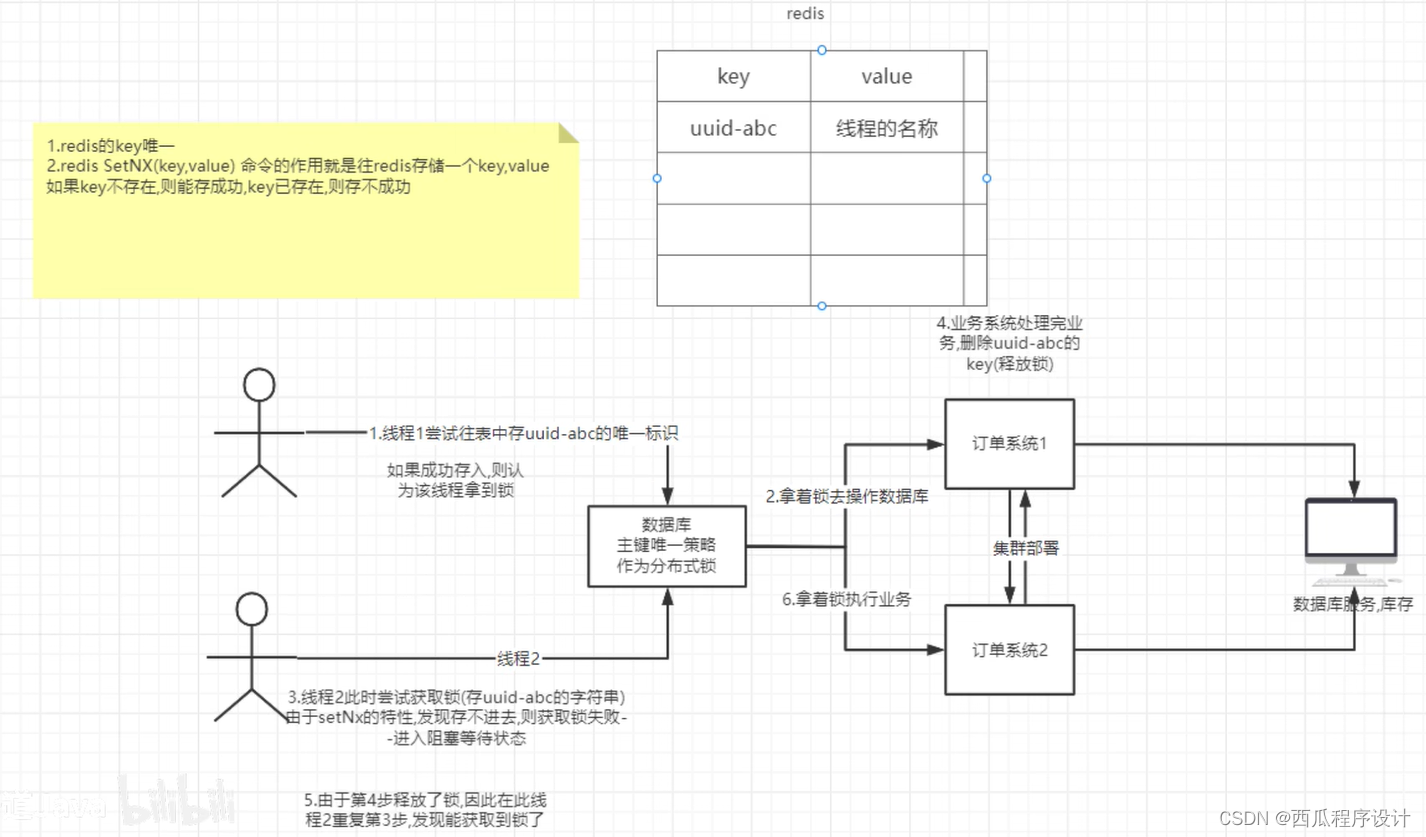
3.基于zookper的实现
- 核心思想:当客户端要获取锁,则创建节点,使用完锁,就删除该节点!
1.客户端获取到锁,在lock节点下创建临时顺序节点。(避免了宕机问题)
2.然后获取到lock下面的所有子节点,客户端获取到所有子节点之后,如果发现自己创建的子节点序号最小,那么就认为该客户端获取到了锁。使用完锁后,就将该节点删除。
3.如果发现自己创建的节点,并非lock所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,同时对其注册事件监听器,监听删除事件。
4.如果发现比自己小的那个节点被删除,则客户端的Watcher会收到相应通知,此时再次判断自己创建的节点是否是lock子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。
参考博客:https://blog.csdn.net/MoastAll/article/details/125320077