🧸🧸🧸各位大佬大家好,我是猪皮兄弟🧸🧸🧸

文章目录
- 一、项目介绍
- 项目技术栈和开发环境
- 二、项目的宏观结构
- 三、compile_server模块
- ①日志模块开发,Util工具类,供所以模块使用
- ②编译功能开发(compiler模块)
- 拼接路径工具类
- 检测编译是否成功
- 编译出错
- compiler编译模块核心逻辑实现
- ③运行功能开发(runner模块)
- 资源限制(CPU占用,内存)
- runner模块核心逻辑以及实现
- ④ 编译运行模块开发(compile_run模块)
- 引入jsoncpp
- compile_run模块 明确步骤
- 差错处理
- 独特文件名的形成
- 读写文件接口
- 清理所有临时文件
- compile_run模块的核心逻辑与实现
- 设计测试用例对compile_run模块进行测试
- 引入cpp-httplib第三方网络库
- gcc升级
- compile_run打包成网络服务
- ⑤使用Postman对打包成为网络后的c_r模块进行综合测试
- 四、oj_server模块
- ①oj_server模块结构设计,MVC架构模式
- ②oj_server的功能路由
- ③ version1: 建立文件版的题库
- 文件结构
- 给用户预设的代码header
- tail.cpp测试用例部分
- ③version2 MySQL版本
- 创建用户并赋权
- 使用MySQL_WorkBench创建表结构
- 在MySQL_WorkBench当中进行录题
- 编写MySQL版本的model模块
- ④model模块
- 使用boost准标准库当中的split进行字符串分割
- 按行读取配置文件形成Question对象
- ⑤controller模块
- controller模块整体结构
- 引入ctemplate模板渲染库测试基本功能
- ⑥judge模块(负载均衡)
- 编写负载均衡器
- 离线和上线
- ⑦使用Postman进行oj_server的综合测试
- ⑧view模块整体代码结构(前端的东西,不是重点)
- index
- all_questions
- one_question
- 五、最终效果
- 六、项目结项与扩展
- 七、顶层makefile发布项目
- 项目源码
一、项目介绍
项目相关背景
在线oj系统是一种在线评测系统,用于评测程序员提交的代码。它可以模拟各种编程语言的运行环境,对程序进行编译、运行和测试,并根据测试结果给出评分和反馈。可以帮助程序员提高编程能力和解决问题的能力,同时也可以帮助教师和企业筛选优秀的人才。在线oj系统的背景可以追溯到20世纪80年代,当时已经有一些类似的系统出现,但是随着互联网的发展和计算机技术的进步,在线oj系统得到了广泛的应用和发展。目前,国内外已经有很多知名的在线oj系统,例如LeetCode、Codeforces、TopCoder等。
我们对于leetcode,newcode这些一定不陌生
我们选择在线oj系统项目的原因是因为它可以帮助我们提高编程能力和解决问题的能力,同时也可以帮助我们更好地适应工作和学习中的编程需求。在线oj系统具有丰富的题库和实时反馈功能,可以帮助我们更好地进行编程练习和测试。 此外,负载均衡在线oj系统还可以进行项目的扩展,具有方便的使用和活跃的社区互动等优势,可以提高我们的学习效果和团队协作能力。
项目技术栈和开发环境
技术栈:
- C++ STL 标准库
- Boost准标准库,主要应用split字符串切割
- cpp-httplib 第三方开源网络库
- ctemplate 第三方开源前端网页渲染库
- jsoncpp 第三方开源序列化、反序列化库
- 负载均衡设计
- 多线程、多进程
- MySQL C connect
- Ace前端在线编辑器(了解)
- html/css/js/jquery/ajax(了解)
开发环境:
- Centos 7云服务器
- vscode
- MySQL workbench
二、项目的宏观结构
我们的项目核心是三个模块
①comm公共模块(httplib网络服务,log日志信息,util工具类集合等)
②compile_server编译运行模块(以网络的形式访问compile_server请求编译运行服务)
③oj_server基于MVC架构模式的服务器,主要负责负载均衡、用户交互以及数据访问
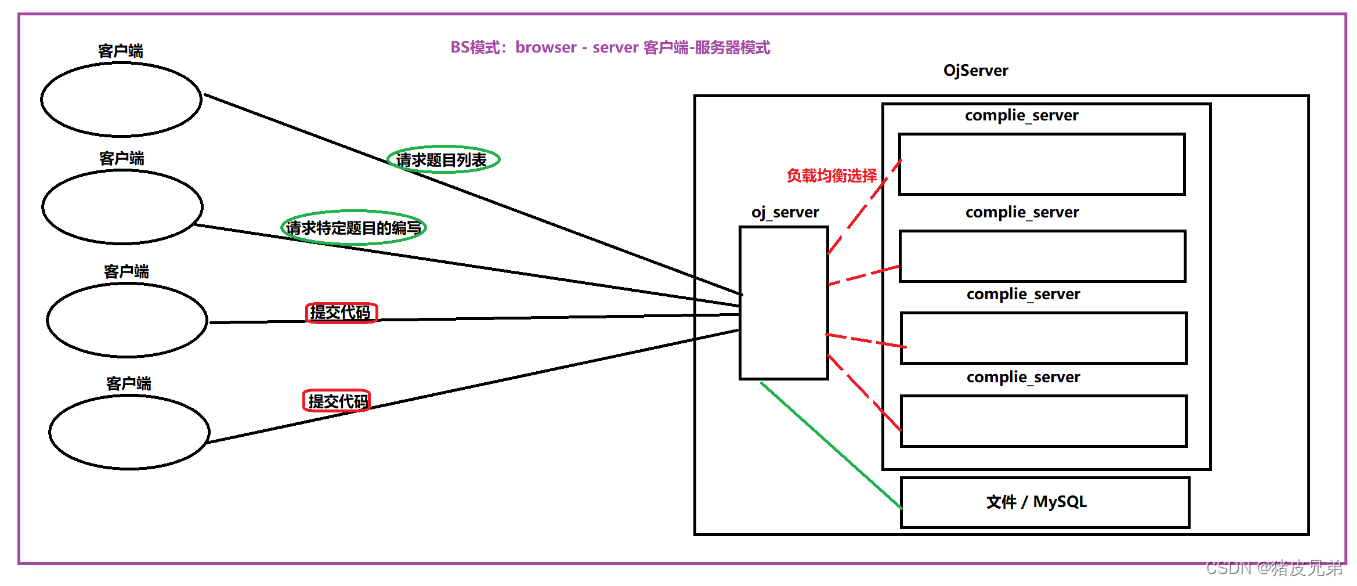
运行过程梳理
客服端(网页)向oj_server服务器发起请求,oj_server通过cpp-httplib打包的server进行功能路由,如获取题目列表,获取单道题目,以及代码的提交。然后oj_server负载均衡式的选择compile_server进行编译运行。结果返回给用户。
三、compile_server模块
compile_server模块主要的工作是进行编译运行。通过cpp-httplib打包成服务器,然后进行功能路由
①日志模块开发,Util工具类,供所以模块使用
日志,我们想提供
- 日志等级
- 打印日志的文件名称
- 报错行
- 添加日志的时间
- 日志信息
- 开放性输出
开放性输出就是说我们可以在后面输出自己想输出的东西,比如LOG(DEBUG)<<"我想输出的东西"<<std::endl;
#pragma once
#include <iostream>
#include <string>
#include "util.hpp"
namespace ns_log
{
using namespace ns_util;
enum
{
// 日志等级 0-4
INFO, // 常规的,只是一些提示信息
DEBUG, // 调试日志
WARNING, // 告警,不影响后续使用
// 一般碰到ERROR或者FATAL这样的错误,就需要有人来运维了
ERROR, // 错误,用户的请求不能继续了
FATAL // 整个系统就用不了了
};
// LOG() << "message" 我们想进行日志打印的方式,是一个开放式的日志功能
inline std::ostream &Log(const std::string &level, const std::string &file_name, int line) // 打印日志的函数
{
// 添加日志等级
std::string message = "[";
message += level;
message += "]";
// 添加报错文件名称
message += "[";
message += file_name;
message += "]";
// 添加报错行
message += "[";
message += std::to_string(line); // 整数转字符串
message += "]";
// 日志一般都有它的时间,就是这个日志是上面时候打的
// 添加日志时间戳
message += "[";
message += TimeUtil::GetTimeStamp(); // 整数转字符串
message += "]";
// cout 本质 内部是包含缓冲区的
std::cout << message; // 不要std::endl进行刷新,因为换行就会刷新缓冲区
return std::cout; // 返回一个流式缓冲区,上面的信息写到一个缓冲区当种
}
// LOG(INFO)<<"message"<<"\n"; # \n进行缓冲区的刷新
#define LOG(level) Log(#level, __FILE__, __LINE__)
// LOG中的level是枚举 0-4 log中的#level就可以把宏参以字符串的方式传参 比如INFO,对应的enum是0,而#level就是INFO
}
解释说明:
- 其中 __FILE__和__LINE__是C语言中的两个宏,获得文件名称和获得行数。
#define LOG(level) log(#level,__FILE__,__LINE__);这个宏当中,#level的作用是,直接转化成字符串的形式,比如DEBUG对应的枚举是1,那么我们只传DEBUG的话,在预编译阶段就会替换成1,但是我们传入#level的话,他就会认为是字符串"DEBUG";
②编译功能开发(compiler模块)
编译模块的整体结构如下。
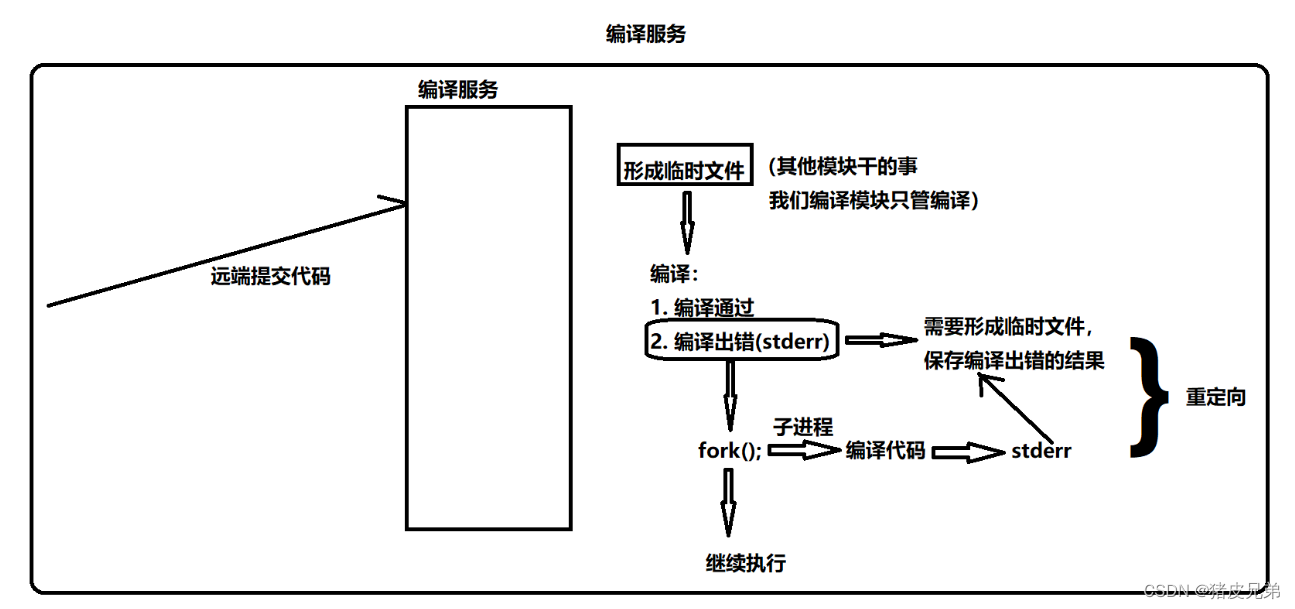
首先,我们想要提供编译服务,那么急需要去调用编译器。在Linux当中,我们知道对进程操作可以有进程创建、进程终止、进程等待、进程程序替换,那么我们就需要去进程程序替换成g++来对用户提交的代码进行编译
进程程序替换
通过 man 2 exec 我们可以看到操作系统给我们提供的用于程序替换的接口exec系列函数
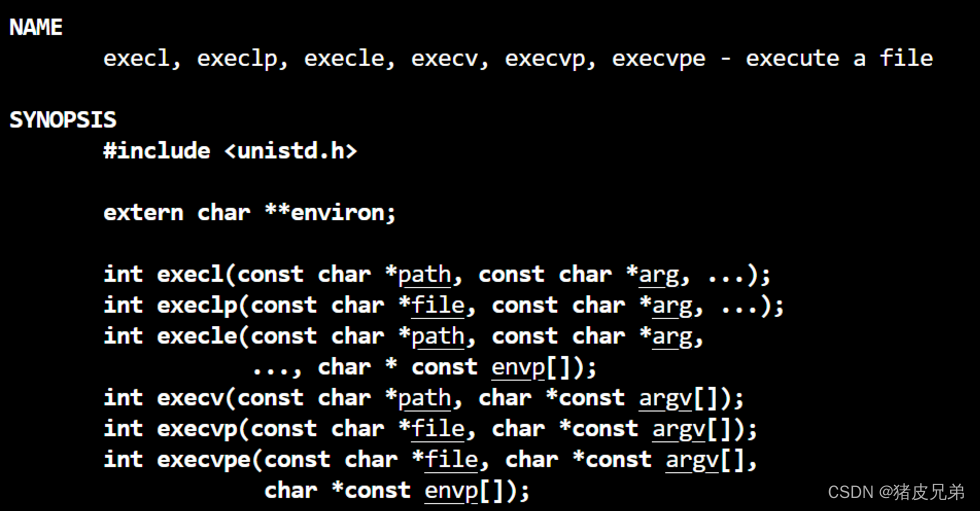
接口说明:猪皮兄弟:进程控制.csdn
- 带l的我们可以认为是需要传入一串参数,比如说
g++ -o test test.cc,需要以NULL/nullptr结尾 - 带v的我们可以认为是需要数组去进行传递,也就是把我们上面的一串参数,先放入数组再进行调用
- 带p的可以认为是环境变量,也就是说系统已经认识了该程序,无序我们传入相对/绝对地址,而不带p是需要我们传入的。
我们今天选择的是execlp,最符合我们的调用,execlp的调用方式:execlp("g++","g++","-o","test","test.cc",nullptr); ; (第一个g++代表的是在环境变量当中去找)
拼接路径工具类
在客户提交代码之后,要形成一些文件,比如源文件,编译之后形成可执行文件,编译错误的话要形成编译错误文件。
所以,这时候需要一些方法来对这些文件进行构建,我们把这些构建后缀的方法放到comm模块的Util类当中
//comm模块
class PathUtil // 路径工具类
{
public:
// 添加后缀
static std::string AddSuffix(const std::string &file_name, const std::string &suffix)
{
std::string path_name = temp_path;
path_name += file_name;
path_name += suffix;
return path_name;
}
// 编译时需要有的临时文件
// 构建源文件路径+后缀的完整文件名
// 1234 -> ./temp/1234.cpp
static std::string Src(const std::string &file_name)
{
return AddSuffix(file_name, ".cpp");
}
// 构建可执行程序的完整路径+后缀名
// 1234 -> ./temp/1234.exe
static std::string Exe(const std::string &file_name)
{
return AddSuffix(file_name, ".exe");
}
// 构建该程序对应的标准错误的完整路径+后缀名
// 1234 -> ./temp/1234.stderr
static std::string CompilerError(const std::string &file_name)
{
return AddSuffix(file_name, ".compile_error");
}
};
检测编译是否成功
我们编译是否成功只有一个标准,就是是否形成可执行文件
- 第一种方式:r读方式打开文件,如果失败了,说明不存在,这种方式太简单粗暴
- 第二种方式:使用系统调用接口stat检测文件属性。
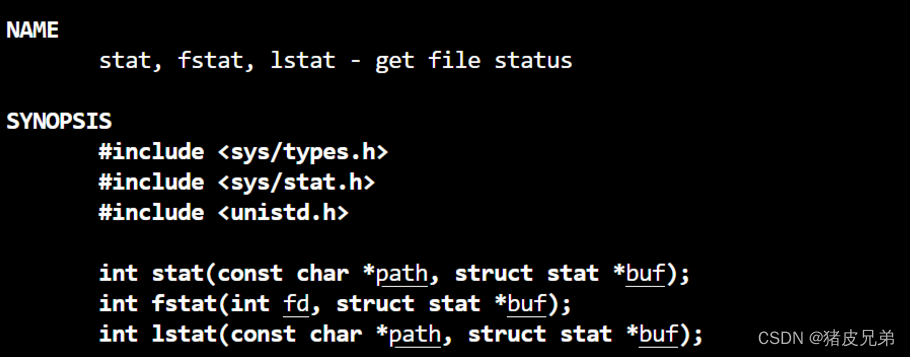
stat的第二个参数是一个输出型参数,是一个系统提供的结构体类型,结构如下
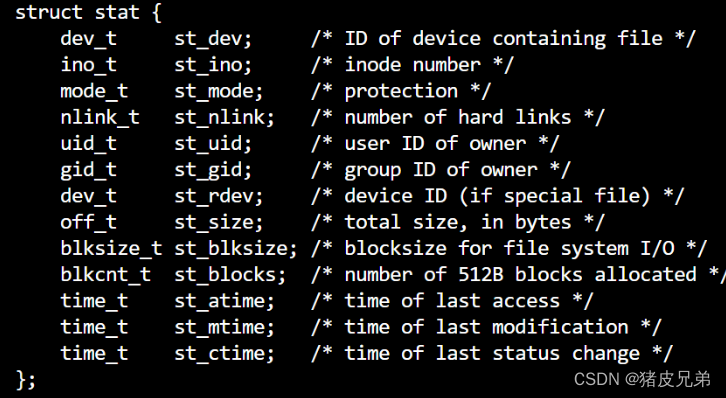
判断文件是否存在逻辑
class FileUtil
{
public:
static bool IsFileExists(const std::string &file_path)
{
// stat成功,0被返回,失败-1返回
struct stat st;
if (stat(file_path.c_str(), &st) == 0)
{
// 获取属性成功,说明文件依旧存在
return true;
}
return false;
}
};
编译出错
编译出错,g++会向标准错误流里面打印错误信息,所以我们就要形成一个文件,也就是编译错误文件xxx.compiler_error,让标准错误文件描述符进行重定向到该文件,如果编译出错,就可以在这个文件当中看见错误原因。
形成路径
class PathUtil // 路径工具类
{
public:
// 添加后缀
static std::string AddSuffix(const std::string &file_name, const std::string &suffix)
{
std::string path_name = temp_path;
path_name += file_name;
path_name += suffix;
return path_name;
}
// 构建该程序对应的标准错误的完整路径+后缀名
// 1234 -> ./temp/1234.stderr
static std::string CompilerError(const std::string &file_name)
{
return AddSuffix(file_name, ".compile_error");
}
};
compiler编译模块核心逻辑实现
我们需要对标准错误文件描述符重定向,这里采用的是系统调用dup2的方式
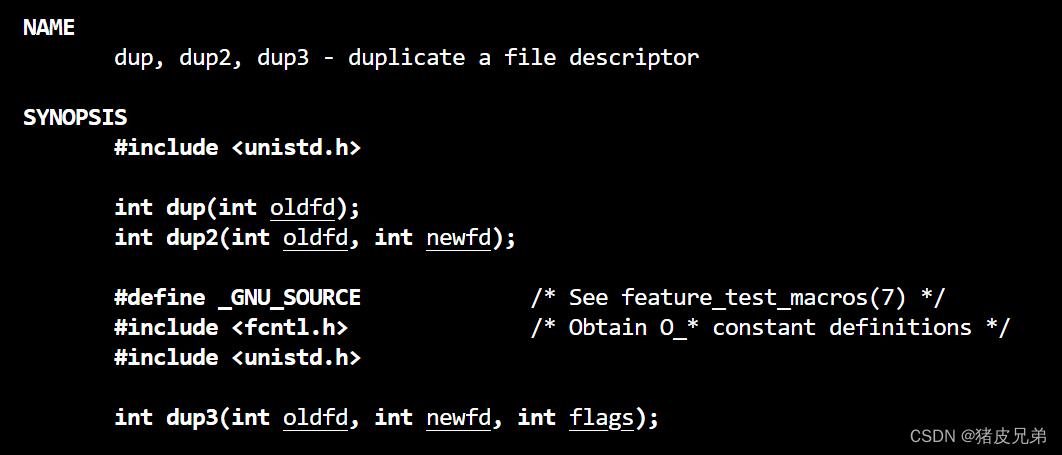
编译模块核心逻辑
namespace ns_compiler
{
// 引入路径拼接功能
using namespace ns_util;
class Compiler
{
public:
Compiler()
{
}
~Compiler()
{
}
// 返回值 编译成功:true 否则:false
// 输入参数:编译的文件名
// file_name:1234 后续我们自己拼接路径,后缀等
// 1234 -> ./temp/1234.cpp
// 1234 -> ./temp/1234.exe
// 1234 -> ./temp/1234.compile_error
static bool Compile(const std::string &file_name) // 编译
{
pid_t pid = fork();
if (pid < 0)
{
LOG(ERROR) << "内部错误,创建子进程失败" <<std::endl;
return false;
}
else if (pid == 0)
{
umask(0);
int _stderr = open(PathUtil::CompilerError(file_name).c_str(),O_CREAT | O_WRONLY,0644);
//打开标准错误临时文件,出错就向其中写入错误信息
if(_stderr<0)
{
LOG(WARNING) << "没有成功形成stderr临时文件" << std::endl;
exit(1);
}
//重定向标准错误到我们形成的标准错误临时文件,dup2(oldfd,newfd);
dup2(_stderr,2);//我要把old的文件描述符放到new的文件描述符位置
//g++打印错误信息到stderr当中,就会重定向到我们的标准错误临时文件
// 子进程调用编译器,完成对代码的编译工作
// 进程程序替换exec系列函数
// g++ -o target src -std=c++11
//因为我们选用的带p的进程程序替换函数,所以g++可以在环境变量中找到
execlp("g++","g++", "-o", PathUtil::Exe(file_name).c_str(),
PathUtil::Src(file_name).c_str(), "-std=c++11","-D","COMPILER_ONLINE",nullptr);
//未替换成功,直接终止
LOG(ERROR)<<"启动编译器g++失败,可能是参数错误"<<std::endl;
exit(2);
}
else
{
waitpid(pid,nullptr,0);//进程等待,等pid进程,退出结果,等待方式(这里S是阻塞等待)
//编译是否成功,标准就是可执行文件是否存在
if(FileUtil::IsFileExists(PathUtil::Exe(file_name)))
{
LOG(INFO)<<PathUtil::Src(file_name)<<"编译成功"<<std::endl;
return true;
}
}
LOG(ERROR)<<"编译失败,没有形成可执行程序"<<std::endl;
return false;
}
private:
};
}
③运行功能开发(runner模块)
编译完成之后,如果成功,则会生成可执行程序,我们现在是想办法把程序run起来。
程序运行
1.代码跑完,结果正确
2.代码跑完,结果不正确
3.代码没跑完,异常了
进程等待中的status就可以直到 前8位是退出吗 低8位是核心转储 后面7位是进程信号
信号为0,则退出码有效,不为0,则退出码无效。核心转储需要自己开启,并且核心转储是存储核心错误信息
但是运行模块,Run,我们是不需要考虑结果正确与否
结果正确与否是由测试用例决定的。但是跑错了是要报错的。
错误又分为编译错误和运行错误,运行错误才是在runner模块里该出现的
进程起来之后,默认会打开三个文件描述符,分别是0,1,2号文件描述符,分别对应stdin,stdout,stderr。我们为了方便我们运行的自测输入(我们这里暂时不支持),运行结果,运行错误结果等的查看与返回给用户。我们需要把这三个文件描述符进行重定向
//file_name为传入的文件名参数。文件分文件名和文件后缀
std::string _stdin = PathUtil::Stdin(file_name);
std::string _stdout = PathUtil::Stdout(file_name);
std::string _stderr = PathUtil::Stderr(file_name);
umask(0); // 置权限掩码为0
//打开文件
int _stdin_fd = open(_stdin.c_str(), O_CREAT | O_RDONLY, 0644);
int _stdout_fd = open(_stdout.c_str(), O_CREAT | O_WRONLY, 0644);
int _stderr_fd = open(_stderr.c_str(), O_CREAT | O_WRONLY, 0644);
//文件重定向(打开了才能重定向,打开了才有对应的fd)
dup2(_stdin_fd, 0);
dup2(_stdout_fd, 1);
dup2(_stderr_fd, 2);
资源限制(CPU占用,内存)
我们在leetcode做题的时候通常会发现出现 CPU占用时间超限,内存超限等,其实就是给执行这个运行服务的进程进行了资源的限制
对进程做资源限制(这里只针对CPU占用时间和内存占用)
对进程做资源限制,我们需要调用 setrlimit 的系统调用来完成
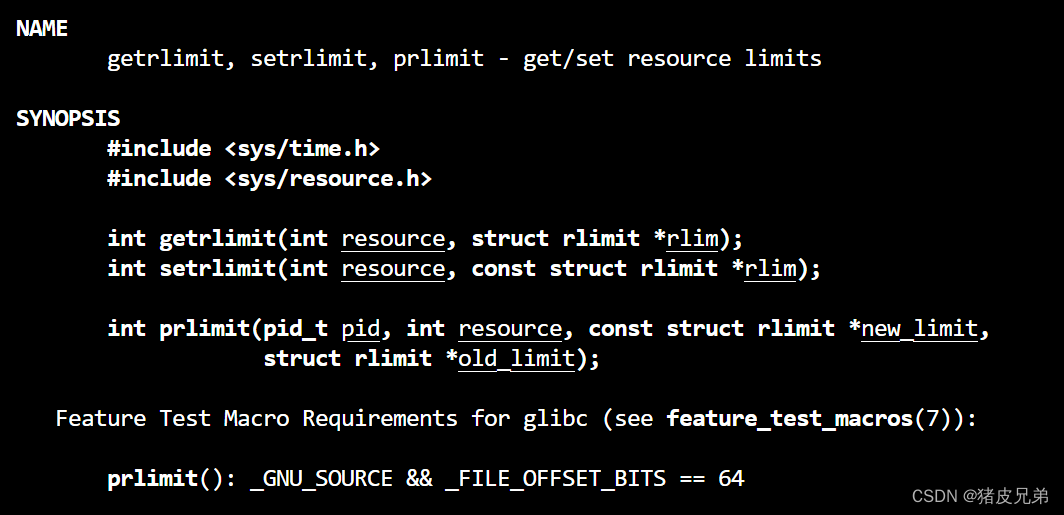
其中,RLIMIT_AS最大给这个进程的虚拟地址(用字节来衡量)

RLIMIT_CPU就代表CPU占用时间的限制

而我们看到还有一个对应的struct rlimit结构体,第一个是软件限制,第二个是硬件限制,硬件一般设成无穷的,不加约束 (无限,INFINITY)

其实就是设置对应的struct rlimit结构体,然后调用setrlimit进行设置就可以了,具体操作如下:
#include <sys/time.h>
#include <sys/resource.h>
class Runner
{
public:
Runner()
{
}
~Runner()
{
}
public:
//提供设置进程占用资源大小的接口
static void SetProcLimit(int _cpu_limit,int _mem_limit)
{
//设置CPU时长
struct rlimit cpu_rlimit;
cpu_rlimit.rlim_cur = _cpu_limit;
cpu_rlimit.rlim_max = RLIM_INFINITY;//无限
setrlimit(RLIMIT_CPU,&cpu_rlimit);
//设置内存大小
struct rlimit mem_rlimit;
mem_rlimit.rlim_cur = _mem_limit * 1024;//传过来是以KB为单位,我们这里是以B为单位
mem_rlimit.rlim_max = RLIM_INFINITY;//无限
setrlimit(RLIMIT_AS,&mem_rlimit);
}
};
另外,如果超过了资源限制,则会被信号中断,比如超出CPU占用时间限制,则会被SIGXCPU(CPU time limit exceeded)信号打断,内存使用超限,就会被SIGABRT打断(abort signal)。分别对应24号信号和6号信号
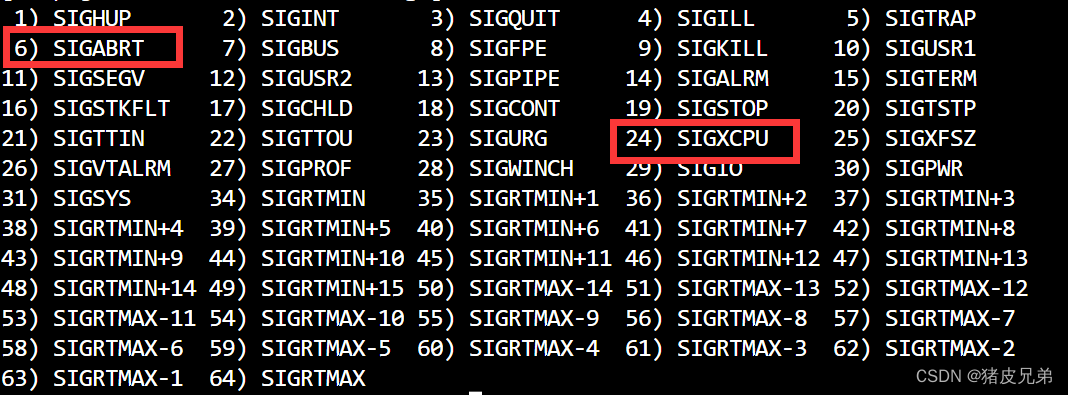
如果我们想测试是否是这两个信号,则我们可以对1-31号进行signal,自定义捕捉(0号信号,32,33号信号是不存在的,34号及以后是实时信号,我们不管。),然后捕捉到了就进打印出来看看。
runner模块核心逻辑以及实现
//runner模块
#pragma once
#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/wait.h>
#include <sys/time.h>
#include <sys/resource.h>
#include "../comm/log.hpp"
#include "../comm/util.hpp"
namespace ns_runner
{
using namespace ns_log;
using namespace ns_util;
class Runner
{
public:
Runner()
{
}
~Runner()
{
}
public:
//提供设置进程占用资源大小的接口
static void SetProcLimit(int _cpu_limit,int _mem_limit)
{
//设置CPU时长
struct rlimit cpu_rlimit;
cpu_rlimit.rlim_cur = _cpu_limit;
cpu_rlimit.rlim_max = RLIM_INFINITY;//无限
setrlimit(RLIMIT_CPU,&cpu_rlimit);
//设置内存大小
struct rlimit mem_rlimit;
mem_rlimit.rlim_cur = _mem_limit * 1024;//传过来是以KB为单位,我们这里是以B为单位
mem_rlimit.rlim_max = RLIM_INFINITY;//无限
setrlimit(RLIMIT_AS,&mem_rlimit);
}
// 运行和我们之前一样,指明文件名即可,不需要带路径,我们可以自动补全,全在temp目录下
/**
* 返回值如果是>0,证明程序异常了,退出时收到了信号,返回值就是对应的信号编号
* 返回值==0,标明是正常运行完成,结果是什么我们不关心,结果保存到了对应的临时标准输出文件当中
* 返回值<0,表名是内部错误
* cpu_limit: 程序运行的时候,可以使用的最大CPU资源上限
* mem_limit: 程序运行的时候,可以使用的最大内存大小(KB)
*/
static int Run(const std::string &file_name,int cpu_limit ,int mem_limit)
// bool也是可以的,不过为了让它适应各种场景,把它设为int
{
/**
* 程序运行
* 1.代码跑完,结果正确
* 2.代码跑完,结果不正确
* 3.代码没跑完,异常了
*
* //进程等待中的status就可以直到 前8位是退出吗 低8位是核心转储 后面7位是进程信号
* //信号为0,则退出码有效,不为0,则退出码无效。核心转储需要自己开启,并且核心转储是存储核心错误信息
*
* 但是运行模块,Run,我们是不需要考虑结果正确与否
* 结果正确与否是由测试用例决定的。但是跑错了是要报错的。
*
* 知道是哪个可执行程序
* 一个程序在默认启动的时候
* 标准输入(我们今天不考虑用户自测,由oj平台帮我们去做)
* 标准输出(程序运行完成,输出结果是什么)
* 标准错误(运行的时候的错误信息)
*
* 错误又分为编译错误和运行错误,运行错误才是在runner模块里该出现的
*/
std::string _execute = PathUtil::Exe(file_name); // 可执行程序路径
/**
* 标准输入用于输入的参数等等
* 标准输出用于存放运行结果
* 标准错误用于执行异常的时候报错
*/
std::string _stdin = PathUtil::Stdin(file_name);
std::string _stdout = PathUtil::Stdout(file_name);
std::string _stderr = PathUtil::Stderr(file_name);
umask(0); // 置权限掩码为0
int _stdin_fd = open(_stdin.c_str(), O_CREAT | O_RDONLY, 0644);
int _stdout_fd = open(_stdout.c_str(), O_CREAT | O_WRONLY, 0644);
int _stderr_fd = open(_stderr.c_str(), O_CREAT | O_WRONLY, 0644);
if (_stdin_fd < 0 || _stdout_fd < 0 || _stderr_fd < 0)
{
// 打开文件错误属于内部错误,严格来讲不应该暴露给用户
LOG(ERROR) << "运行时打开标准文件失败" << std::endl;
return -1; // 代表打开文件失败
}
pid_t pid = fork();
if (pid < 0)
{
LOG(ERROR) << "运行时创建子进程失败" << std::endl; // 服务器压力太大
close(_stdin_fd);
close(_stdout_fd);
close(_stderr_fd);
return -2; // 代表创建子进程失败
}
else if (pid == 0)
{ //现在对应的是子进程,我们要对子进程的资源做限制
//我们今天重点关心的是运行时长和资源占用 RLIMIT_AS RLIMIT_CPU
SetProcLimit(cpu_limit,mem_limit);
// 进行重定向,子进程随便执行,执行结果一定会输出到打开的文件当中
dup2(_stdin_fd, 0);
dup2(_stdout_fd, 1);
dup2(_stderr_fd, 2);
// 我们现在有的是路径,而不是像g++那样的环境变量当中有的,所以我们选择使用execl
execl(_execute.c_str() /*路径*/, _execute.c_str(), nullptr /*如何执行的可变参数,以nullptr结尾*/);
exit(1);
}
else
{
close(_stdin_fd);
close(_stdout_fd);
close(_stderr_fd);
int status = 0;
waitpid(pid, &status, 0);
LOG(INFO) << "运行完毕, info(退出信号):" << (status & 0x7F) << std::endl;
return status & 0x7F; // 有异常返回值一定是>0的值,没有异常返回值就是0
}
}
};
}
④ 编译运行模块开发(compile_run模块)
现在就应该编写compile_run模块去进行组合。compile_run模块就需要去适配用户请求,定制通信协议字段,然后逐次完善功能,正确的调用compile和runner
引入jsoncpp
未来在使用compile_server服务的时候,是以网络的形式请求的,我们要求,客户端需要给我们发一个json string供我们解析。等待我们运行完成之后,结果也会以json string的方式发送给client或者oj_server服务器
jsoncpp是一个开源的第三方库,用于序列化和反序列化,序列化和反序列化的原因在于,我们要==屏蔽机器大小端和结构体内存对齐==等问题。
jsoncpp的安装
$ sudo yum install -y jsoncpp-devel
[sudo] password for zhupi:******
Loaded plugins: aliases, auto-update-debuginfo, fastestmirror, protectbase
Repository epel is listed more than once in the configuration
Loading mirror speeds from cached hostfile
* base: mirrors.aliyun.com
* epel-debuginfo: mirrors.tuna.tsinghua.edu.cn
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
0 packages excluded due to repository protections
Package jsoncpp-devel-0.10.5-2.el7.x86_64 already installed and latest version
jsoncpp的简单使用
jsoncpp最简单的用法就是创建一个Value类型的万能对象,然后以KV的方式进行序列化,然后给对方,对端接收到之后进行read反序列化
#include <json/jsoncpp/json.h>
#include <string>
int main()
{
Json::Value root;
root["code"] = "mycode";//KV的形式,读的时候就可以通过key读出value
root["user"] = "zhupi";
root["age"] = "19";
//序列化
Json::StyleWriter writer;//不止一种序列化的类,区别就在于形成的json string不同
std::string str = writer.write(root);//str就是序列化之后的结果
std::cout<<str<<std::endl;
}
//假设对端接收到了一个json string
void jsonTest(const std::string & in_json)
{
Json::Value in_value;
Json::Reader reader;//反序列化对象
reader.parse(in_json,in_value);//把in_json反序列化到in_value当中
std::string code = in_value["code"].asString(); // 当成字符串
std::string user = in_value["user"].asString();
std::string age = in_value["age"].asString();
//就得到了对端发给我的结果
}
需要注意的是,因为我们使用了jsoncpp,他是一个第三方库,在编译的时候我们需要给g++一些选项,g++ -o test test.cc -std=c++11 -ljsoncpp
compile_run模块 明确步骤
明确步骤:
- 1.把被人通过网络传给我们的json string 反序列化,取出里面规定好的内容(这是我们定制的协议,我们 规定里面需要有code代码,input自测输入(目前不支持),cpu_limit占用时间限制,mem_limit占用空间限制)
- 2.生成独特的文件名,不能和其他的起冲突,这个文件名就用来后面生成本次提供编译运行服务的临时文件。
- 3.生成一份源文件程序,把code代码放进去
- 4.正确调用compiler和runner模块的接口进行处理(编译运行)
- 5.结果发回给对端
差错处理
我们可以把其他的错误的错误码用负数表示,与信号做区分
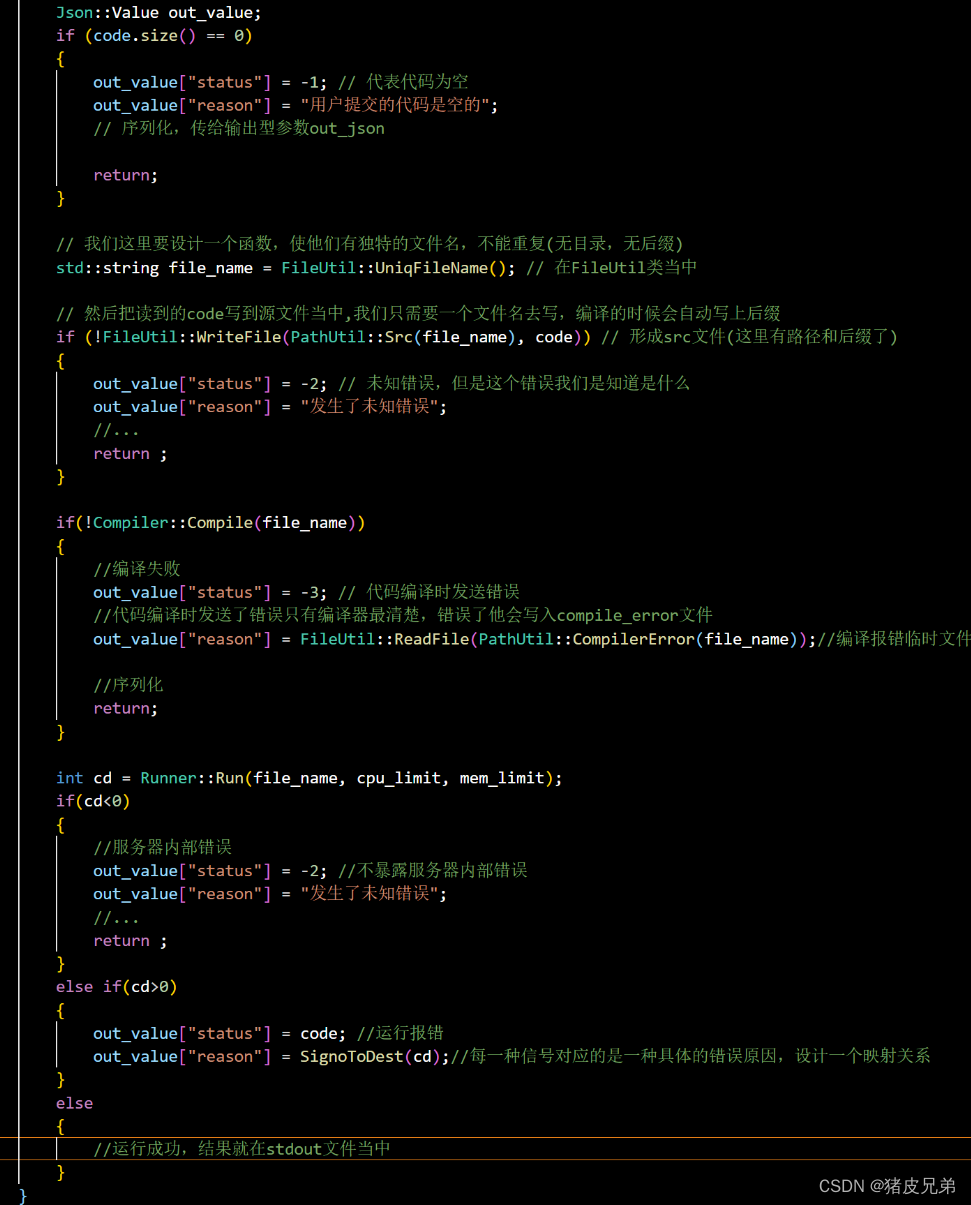
但是每一次我们都要去构建 status,reasons,序列化,甚至还有选填字段,那么这样写下来,显而易见的就知道很臃肿。我们就看能不能想办法把这块代码统一做下处理。
int status_code = 0;
Json::Value out_value;
int run_result = 0;
std::string file_name; // 需要内部形成的唯一文件名
// goto语句中是不能定义变量的,所以我们把定义全部放在前面
if (code.size() == 0)
{
status_code = -1; // 代码为空
goto END;
}
// 我们这里要设计一个函数,使他们有独特的文件名,不能重复(无目录,无后缀)
file_name = FileUtil::UniqFileName(); // 在FileUtil类当中
// 然后把读到的code写到源文件当中,我们只需要一个文件名去写,编译的时候会自动写上后缀
if (!FileUtil::WriteFile(PathUtil::Src(file_name), code)) // 形成src文件(这里有路径和后缀了)
{
status_code = -2; // 未知错误
goto END;
}
if (!Compiler::Compile(file_name))
{
status_code = -3; // 代码编译时发生了错误
goto END;
}
run_result = Runner::Run(file_name, cpu_limit, mem_limit);
if (run_result < 0)
{
// 服务器内部错误
status_code = -2; // 服务器内部错误,给用户显示成未知错误
}
else if (run_result > 0)
{
// 程序运行错误,被信号终止
status_code = run_result;
}
else
{
// 运行成功,结果就在stdout文件当中
status_code = 0;
}
END: // END标签,用来goto
out_value["status"] = status_code;
out_value["reason"] = CodeToDesc(status_code, file_name);
if (status_code == 0) // 说明整个过程全部成功
{
// 全部正确,开始填充
std::string _stdout;
// 我们这次必须带上\n,要不然打印出来就是一行内容,这就是我们设计的好处
FileUtil::ReadFile(PathUtil::Stdout(file_name), &_stdout, true);
out_value["stdout"] = _stdout;
std::string _stderr;
FileUtil::ReadFile(PathUtil::Stderr(file_name), &_stderr, true);
out_value["stderr"] = _stderr;
}
我们使用的是goto语句去处理,对于到了END标签,我们把对于status_code转化为reason的任务全交给CodeToDesc(int code)这个函数去做 ,进行错误描述的转化。
如果全部成功,编译运行成功,那么status_code就会是0.
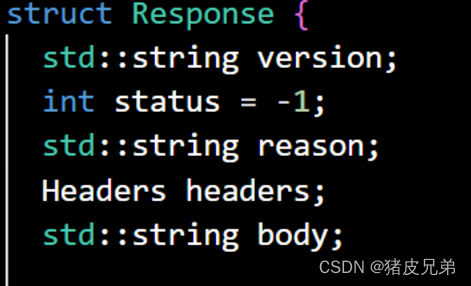
处理status和reason外,我们还要添加选填的stdout和stderr字段进out_value
最后进行序列化,让输出型参数out_json带出
CodeToDesc(int code)
static std::string CodeToDesc(int code, const std::string &file_name)
{
// 待完善
std::string desc;
switch (code)
{
case 0:
desc = "编译运行成功";
break;
case -1:
desc = "提交的代码是空";
break;
case -2:
desc = "未知错误";
break;
case -3:
// desc = "代码编译的时候发生了错误";
FileUtil::ReadFile(PathUtil::CompilerError(file_name), &desc, true);
break;
case SIGABRT: // 6
desc = "内存超限";
break;
case SIGXCPU: // 24
desc = "CPU占用超时";
break;
case SIGFPE: // 8 floating-point execption
desc = "浮点数溢出错误";
break;
default:
desc = "未知:" + std::to_string(code);
break;
}
return desc;
}
独特文件名的形成
我们采用毫秒级时间戳和原子性的唯一值来保证形成的文件名的唯一性。
或者我们用mutex互斥锁去进行计数也是一样的。
获得时间戳
我们可以使用gettimeofday来获得时间戳
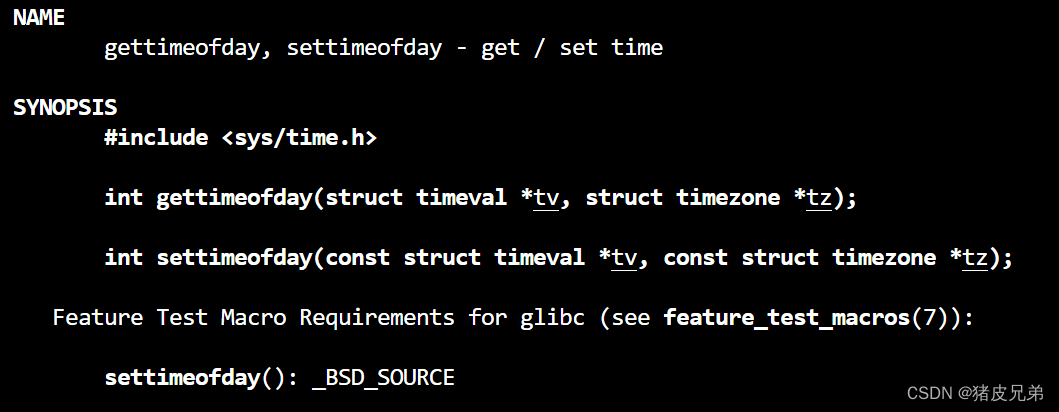
它需要的是一个struct timeval的结构体

第二个成员就是我们需要的成员,毫秒级时间戳
class TimeUtil
{
public:
static std::string GetTimeStamp()
{
struct timeval _time;
gettimeofday(&_time, nullptr);
return std::to_string(_time.tv_sec);
}
static std::string GetTimeMs()
// 获取毫秒级别的时间戳,而在我们的timeval结构体当中,第二个成员就是表示的微秒
// s -> ms *1000 us -> ms /1000
// 因为s级别的时间戳跨度太长了
{
struct timeval _time;
gettimeofday(&_time, nullptr); // 第二个参数我们不管
return std::to_string(_time.tv_sec * 1000 + _time.tv_usec / 1000);
}
};
原子性的递增数
C++中是有原子类的
我们就可以使用std::automic_uint id(0);来产生一个原子数
唯一文件名
class FileUtil
{
public:
static std::string UniqFileName()
{
std::string ms = TimeUtil::GetTimeMs(); // 获得毫秒级的时间戳
// 架不住有时候客户请求同时到来,所以我们还需要一个原子性的递增唯一数来确保文件的唯一性
// 1.mutex加锁 2.C++当中的原子数,高并发内存池计时的时候用过
// 定义一个原子性递增的计数器,初始化为0
// 定义成静态,避免每次进这个函数都会重新定义,在函数当中定义static就是每次都不会被重新定义
static std::atomic_uint id(0);
id++;//原子操作
std::string uniq_id = std::to_string(id);
return ms + "." + uniq_id;//中间可以加上一个点来进行区分
}
};
读写文件接口
class FileUtil
{
static bool WriteFile(const std::string &target, const std::string &content)
{
std::ofstream out(target);//写谁,模式(我们不用管,ofstream默认就是输出的)
if(!out.is_open())
{
return false;
}
out.write(content.c_str(), content.size());
out.close();
return true;
}
static bool ReadFile(const std::string &target,std::string*content,bool keep = false) // 需要传一个路径给我,然后接收文件内容
{
(*content).clear();
std::ifstream in(target);
if(!in.is_open())
{
return false;
}
std::string line;
//getline是不保存行分隔符的,比如abcd\n,读上来只有abcd
//但是有些时候我们是需要保留行分隔符\n的,比如特定的一些格式,使用getline之后就变了。
//getline重载了强制类型转换,所以while可以直接判断
while(std::getline(in,line))//从哪个流当中读,读到哪儿
{
(*content) += line;
(*content) += ((keep) ? "\n" : "");//我们自动添加,如果需要保留(keep是true的话)
}
in.close();
return true;
}
};
getline()的注意事项
- 1.getline()不会保留换行符,比如1234\n,它只会读上来1234,所以如果在后面我们想换行的话需要自己添加(在读文件的参数中,第三个参数设为true,自己写getline逻辑的话就要自己判断填不填加)
- 2.getline进行了返回类型的重载,导致while()可以对getline的返回值做正确与否的判断
清理所有临时文件
我们会在执行过程中产生多少个临时文件的数目是不确定。但是有哪些类型我们是知道的,上面都说过
一共有六个
- .cpp
- .exe
- .compile_error
- .stdin
- .stdout
- .stderr
我们只需要判断文件存不存在FileUtil::IsFileExists()来判断,再进行删除就可以了unlink()函数
static void RemoveTempFile(const std::string &file_name)
{
std::string _src = PathUtil::Src(file_name);
if (FileUtil::IsFileExists(_src))
unlink(_src.c_str());
std::string _exe = PathUtil::Exe(file_name);
if (FileUtil::IsFileExists(_exe))
unlink(_exe.c_str());
std::string _compiler_error = PathUtil::CompilerError(file_name);
if (FileUtil::IsFileExists(_compiler_error))
unlink(_compiler_error.c_str());
std::string _stdin = PathUtil::Stdin(file_name);
if (FileUtil::IsFileExists(_stdin))
unlink(_stdin.c_str());
std::string _stdout = PathUtil::Stdout(file_name);
if (FileUtil::IsFileExists(_stdout))
unlink(_stdout.c_str());
std::string _stderr = PathUtil::Stderr(file_name);
if (FileUtil::IsFileExists(_stderr))
unlink(_stderr.c_str());
}
compile_run模块的核心逻辑与实现
#pragma once
#include "compiler.hpp"
#include "runner.hpp"
#include <jsoncpp/json/json.h>
#include "../comm/log.hpp"
#include "../comm/util.hpp"
#include <signal.h>
#include <unistd.h>
namespace ns_compile_and_run
{
using namespace ns_util;
using namespace ns_log;
using namespace ns_compiler;
using namespace ns_runner;
class CompileAndRun
{
public:
static std::string CodeToDesc(int code, const std::string &file_name)
{
// 待完善
std::string desc;
switch (code)
{
case 0:
desc = "编译运行成功";
break;
case -1:
desc = "提交的代码是空";
break;
case -2:
desc = "未知错误";
break;
case -3:
// desc = "代码编译的时候发生了错误";
FileUtil::ReadFile(PathUtil::CompilerError(file_name), &desc, true);
break;
case SIGABRT: // 6
desc = "内存超限";
break;
case SIGXCPU: // 24
desc = "CPU占用超时";
break;
case SIGFPE: // 8 floating-point execption
desc = "浮点数溢出错误";
break;
default:
desc = "未知:" + std::to_string(code);
break;
}
return desc;
}
static void RemoveTempFile(const std::string &file_name)
{
std::string _src = PathUtil::Src(file_name);
if (FileUtil::IsFileExists(_src))
unlink(_src.c_str());
std::string _exe = PathUtil::Exe(file_name);
if (FileUtil::IsFileExists(_exe))
unlink(_exe.c_str());
std::string _compiler_error = PathUtil::CompilerError(file_name);
if (FileUtil::IsFileExists(_compiler_error))
unlink(_compiler_error.c_str());
std::string _stdin = PathUtil::Stdin(file_name);
if (FileUtil::IsFileExists(_stdin))
unlink(_stdin.c_str());
std::string _stdout = PathUtil::Stdout(file_name);
if (FileUtil::IsFileExists(_stdout))
unlink(_stdout.c_str());
std::string _stderr = PathUtil::Stderr(file_name);
if (FileUtil::IsFileExists(_stderr))
unlink(_stderr.c_str());
}
/**
* 输入参数:
* code:用户提交的代码
* input:用户给自己提交的代码对应的输入,不做处理,只是把接口留出来,供我们扩展
* cpu_limit:时间要求
* mem_limit:空间要求
* 输出参数:
* 必填:
* status:状态码
* reason:请求结果
* 选填:
* stdout:程序运行结果
* stderr:程序运行错误结果
*
* in_json: {"code": "#include...","input": "...","cpu_limit": 1,"mem_limit": 10240};
* out_json: {"status": 0,"reason": "","stdout": "","stderr": ""}
*/
static void Start(const std::string &in_json, std::string *out_json)
{
// 首先反序列化
Json::Value in_value;
Json::Reader reader;
// parse叫做解析,解析哪个字符串到哪个Value的对象
reader.parse(in_json, in_value); // 最后再处理差错问题
std::string code = in_value["code"].asString(); // 当成字符串
std::string input = in_value["input"].asString();
int cpu_limit = in_value["cpu_limit"].asInt();
int mem_limit = in_value["mem_limit"].asInt();
// input我们暂时是不管的,是用户提交的测试用例
int status_code = 0;
Json::Value out_value;
int run_result = 0;
std::string file_name; // 需要内部形成的唯一文件名
// goto语句中是不能定义变量的,所以我们把定义全部放在前面
if (code.size() == 0)
{
status_code = -1; // 代码为空
goto END;
}
// 我们这里要设计一个函数,使他们有独特的文件名,不能重复(无目录,无后缀)
file_name = FileUtil::UniqFileName(); // 在FileUtil类当中
// 然后把读到的code写到源文件当中,我们只需要一个文件名去写,编译的时候会自动写上后缀
if (!FileUtil::WriteFile(PathUtil::Src(file_name), code)) // 形成src文件(这里有路径和后缀了)
{
status_code = -2; // 未知错误
goto END;
}
if (!Compiler::Compile(file_name))
{
status_code = -3; // 代码编译时发生了错误
goto END;
}
run_result = Runner::Run(file_name, cpu_limit, mem_limit);
if (run_result < 0)
{
// 服务器内部错误
status_code = -2; // 服务器内部错误,给用户显示成未知错误
}
else if (run_result > 0)
{
// 程序运行错误,被信号终止
status_code = run_result;
}
else
{
// 运行成功,结果就在stdout文件当中
status_code = 0;
}
END: // END标签,用来goto
out_value["status"] = status_code;
out_value["reason"] = CodeToDesc(status_code, file_name);
if (status_code == 0) // 说明整个过程全部成功
{
// 全部正确,开始填充
std::string _stdout;
// 我们这次必须带上\n,要不然打印出来就是一行内容,这就是我们设计的好处
FileUtil::ReadFile(PathUtil::Stdout(file_name), &_stdout, true);
out_value["stdout"] = _stdout;
std::string _stderr;
FileUtil::ReadFile(PathUtil::Stderr(file_name), &_stderr, true);
out_value["stderr"] = _stderr;
}
// 序列化
Json::StyledWriter writer;
*out_json = writer.write(out_value);
// 清理掉所有文件,因为是临时的
RemoveTempFile(file_name);
}
};
}
设计测试用例对compile_run模块进行测试
测试这种复杂程序的时候,一定要单元化的测试,不要等最后代码全写完了才来测试,像这样的话代码根本跑不通。
compile_run需要对端传入一个json串,我们这里本地的构建一个,但是实际上是oj_server服务器负载均衡选择后通过http传过来的。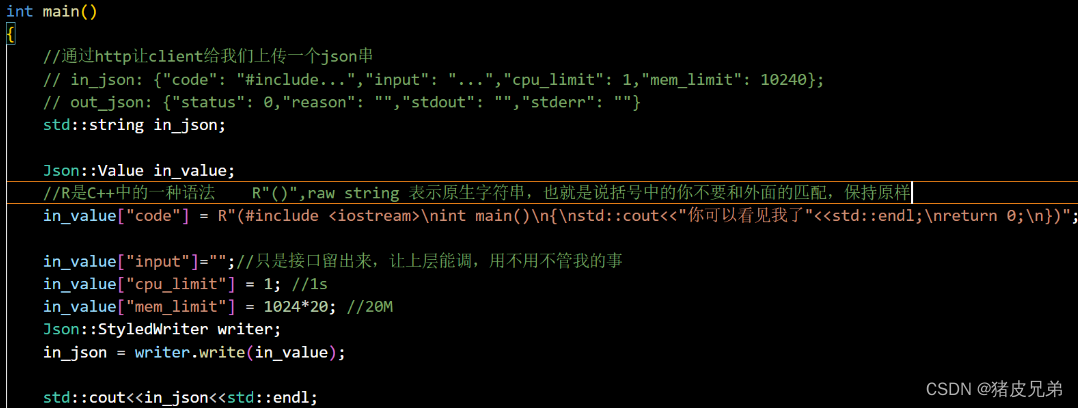
- 这里用到了一个R"()"的语法,这是C++的语法,意思是Row String 原生字符串的意思,他就是说括号里面的东西保持原貌,不要和其他东西进行匹配(主要就是因为里面的双引号和字符串的双引号会匹配,冲突一些东西)
但是呢,R"()"当中其实会屏蔽\n,也就是把\n也给转义成\\n,所以我们在写row string的时候,我们需要如下的方式去写

运行结果
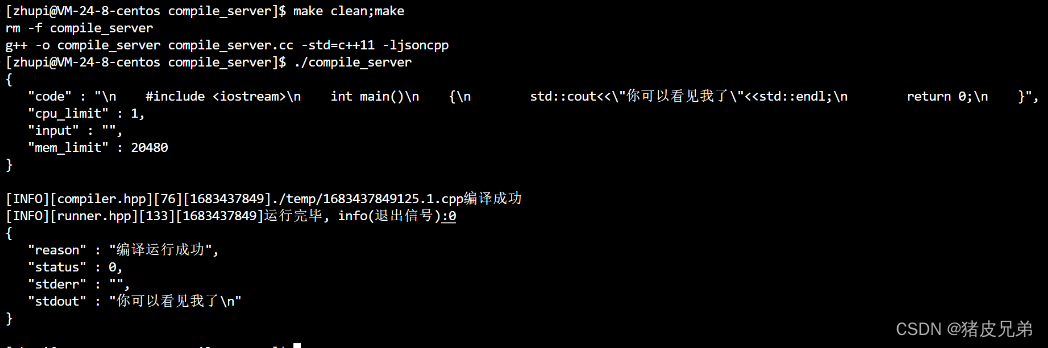
形成的临时文件
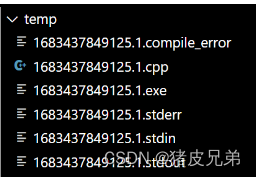
资源限制测试
CPU占用超时
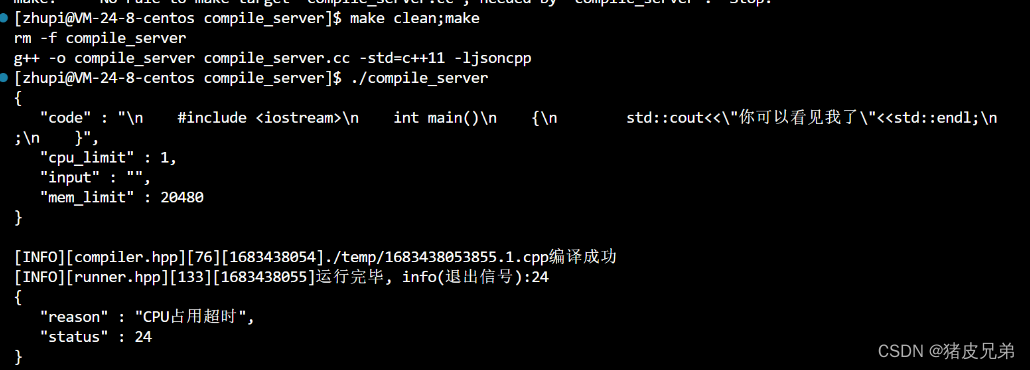
内存超限
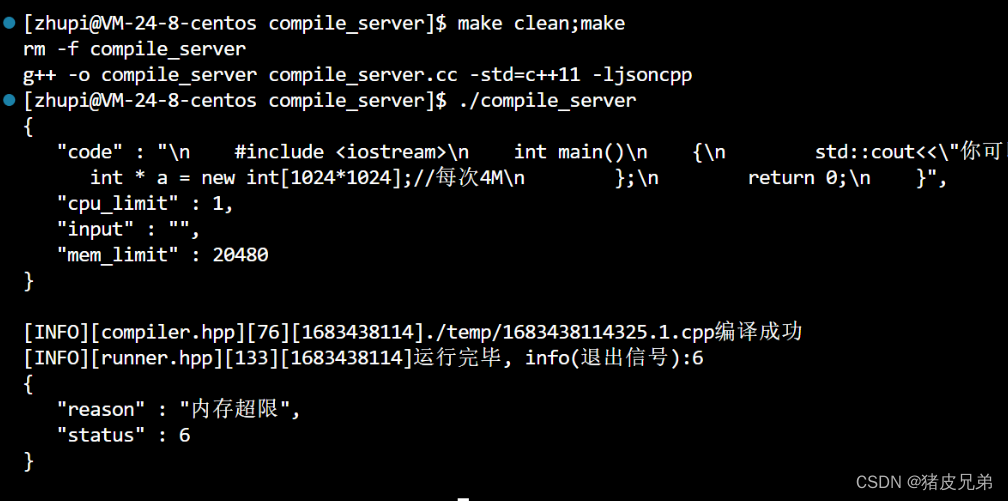
浮点数溢出错误
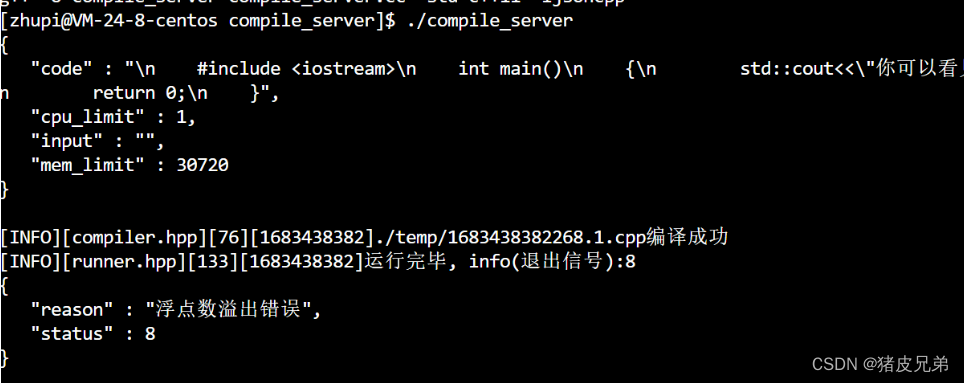
编译出错
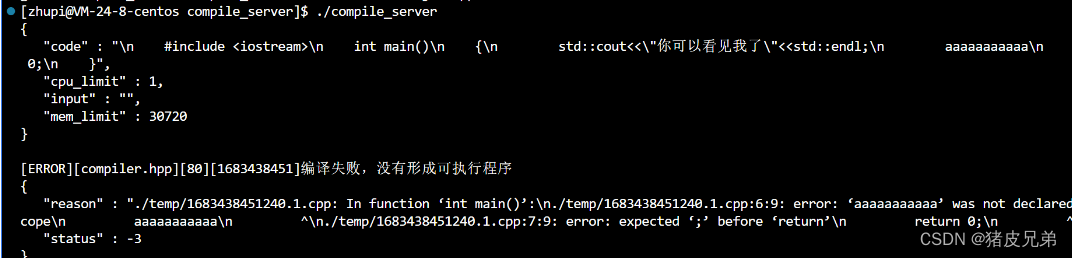
引入cpp-httplib第三方网络库
我们自己写网络套接字来进行通信也是可以的,不过太麻烦了,我们直接使用开源第三方库cpp-httplib
进行cpp-httplib的安装后,cpp-httplib是header only的,也就是说把它里面的.h拷贝到项目中,就可以直接完成。如果你想的话,你也可以拷贝到系统目录下,比如/usr/include/,但是不推荐
需要注意的是
- cpp-httplib的使用需要使用高版本的gcc/g++
- cpp-httplib是阻塞式的多线程http网络库,因为里面使用了原生线程库,所以在编译的时候,需要带上选项-lpthread
gcc升级
首先,我们通过gcc -v来查看当前gcc的版本,cpp-httplib的使用要求gcc的版本在7.x.x以上,这里有两种方法进行gcc的升级
①在vscode上,我们可以通过以下命令中的其中一个对gcc进行升级,这样的升级方式只在本次登录有效,vscode被关掉或者断开连接下一次需要重新升级,不然使用了cpp-httplib编译的时候就会报错。
# 安装工具集 scl
sudo yum install centos-release-scl scl-utils-build
scl enable devtoolset-7 bash
scl enable devtoolset-8 bash
scl enable devtoolset-9 bash
②在云服务器上,我们就可以通过上面的方法,进行单次的升级,还有下面的方法,进行永久升级(修改配置文件~/.bash_profile)。
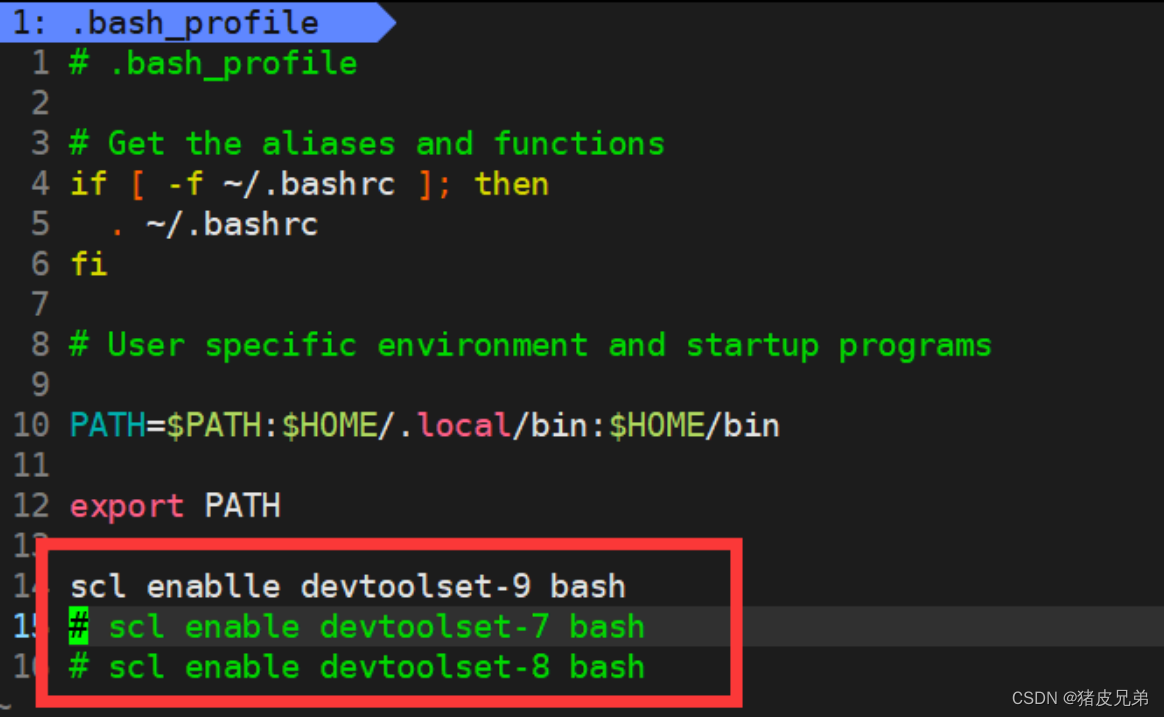
compile_run打包成网络服务
刚刚已经测试过,我们已经能在本地进行编译运行的服务了。接下来,我们使用cpp-httplib将我们的compile_run模块打包成网络服务。
我们这里是想把它构成服务器,那么在cpp-httplib中的做法就是
- 1.构建服务器对象
- 2.进行功能路由(通过访问资源和回调函数的方式)
- 3.启动服务器,等待链接(tcp的方式)
#include <../comm/httplib.h>
...
int main()
{
//1.构建服务器对象
Server svr;
//2.功能路由(资源相对路径,lambda表达式);
svr.Get("/hello",[](const Request& req,Response&resp){
});
//3.启动服务器
svr.listen("0.0.0.0",8080);//指定IP地址和PORT端口号
return 0;
}
解释:
- Get的意思是对放用Get方法来请求资源。Get和Post的区别就是提交参数的位置不同而已,Get回显到url通过url进行提参,Post通过请求正文提交参数。
- Get成员函数的参数当中,第一个就是需要的资源是哪个,如果对端申请的是这个资源(也就是说将来url是
http://101.43.231.47:8080/hello通过Get方法请求,这样的形式就会被捕捉到),然后调用第二个参数,是回调函数(这里使用lambda表达式)。 - Request和Response就是httplib给我们提供的类型,可以填特定的成员进行通信,httplib会自动帮我们发送和接收
- "0.0.0.0"就代表的是任意地址,对应INADDR_ANY,就是说只要是发给这个端口,任何IP都可以被接收到,因为有可能服务器不止一个网卡,所以服务器一般都是这样设置
比如用户提交上来的代码,就在Request的body当中,method就是请求的方法,path就是请求的路径(也就是请求我的什么资源),然后header就是请求报头等等。
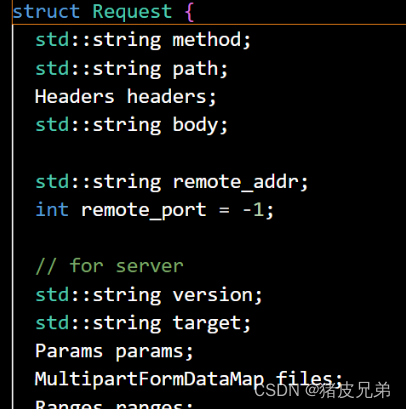
这些都是部分截图,Request和Response类远不止如此
svr.Get("hello",[](const Request&req,Response&resp){
resp.set_content("hello httplib,你好httplib","text/plain;charset utf-8");
//第二个参数就是这个内容的content-type,我们这是纯文本,字符编码utf8
});
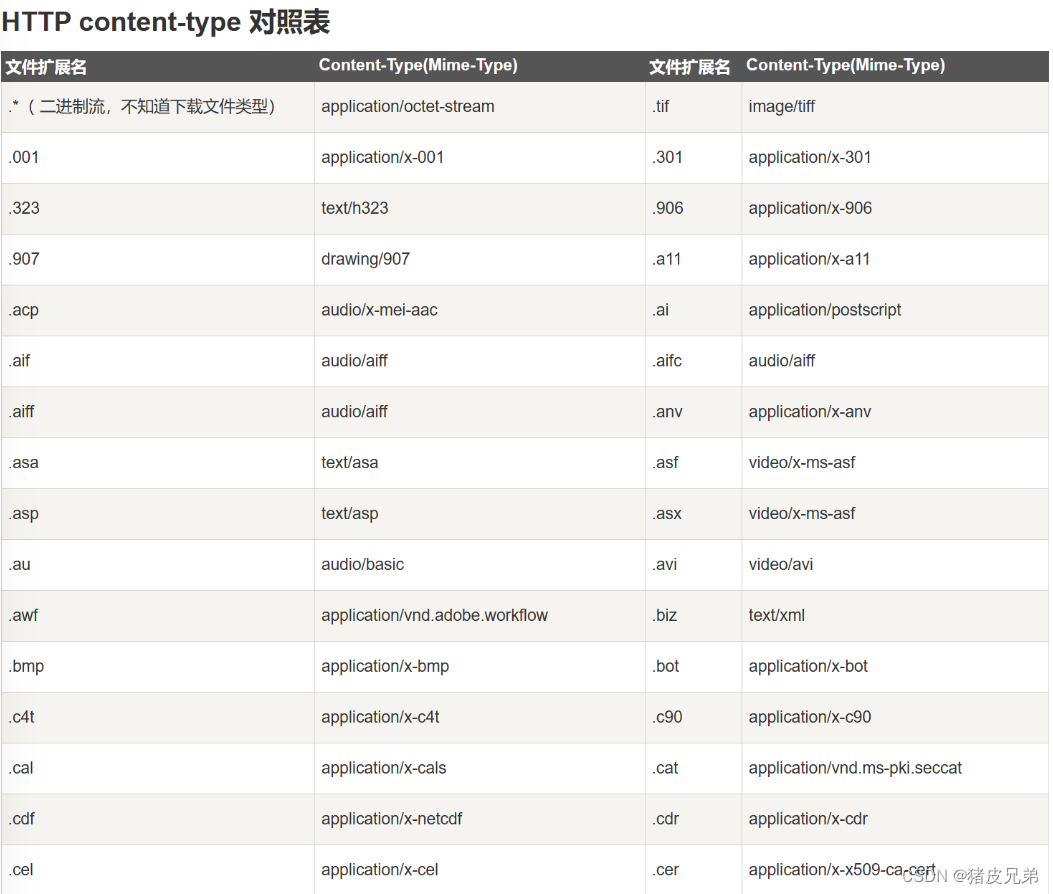
上面的content-type就是内容的形式,比如纯文本text/plain,比如html 的类型text/html,json串的content-type就是application/json
这样的转化表在网上是可以搜到的
有些时候你在进行编译的时候,编译器会给你报一个fatal的错误,就是vscode占用资源过多了,OS直接终止掉了,把vscode重启一下就行。
后续呢,用户请求到来时,在lambda表达式中,调用compile_run的接口去进行编译运行,拿到一个out_json的字符串,装的就时是编译运行的结果。然后直接resp.set_content(out_json,content-type)就可以了,然后httplib自动帮我们响应给用户
利用httplib将compile_run服务打包成网络服务,我们需要的服务是compile_run
//compile_server.cc
#include "compile_run.hpp"
#include "../comm/httplib.h"
using namespace ns_compile_and_run;
using namespace httplib;
void Usage(std::string proc)
{
std::cerr << "Usage: "
<< "\n\t" << proc << "port" << std::endl;
}
//./compile_server port
int main(int argc, char *argv[])
{
if (argc != 2)
{
Usage(argv[0]);
return 1;
}
Server svr; // 定义服务器对象
// compile_and_run打包成网络服务
svr.Post("/compile_and_run", [](const Request &req, Response &resp)
{
//用户请求的服务,正文是我们想要的json string
std::string in_json = req.body;//代码
std::string out_json;//返回的结果
if(!in_json.empty())
{
CompileAndRun::Start(in_json,&out_json);
//编译运行,然后结果就在out_json当中
resp.set_content(out_json,"application/json;charset=utf-8");//什么内容,内容是什么格式
} }); // 客户端将来采用Post的方式
// 这个listen就等于是启动网络服务了
std::cout<<argv[1]<<std::endl;
svr.listen("0.0.0.0", atoi(argv[1])); // 哪个ip,哪个端口提供服务,选项默认
return 0;
}
⑤使用Postman对打包成为网络后的c_r模块进行综合测试
Postman是一个可以用来发送网络请求的工具
我们的服务器打包成为了Post方法的一个功能路由,所以我们拿Postman构建一个方法为Post的申请给compile_server服务器
设置Postman的这些东西
然后构建我们的请求
发送之后我们可以看到结果
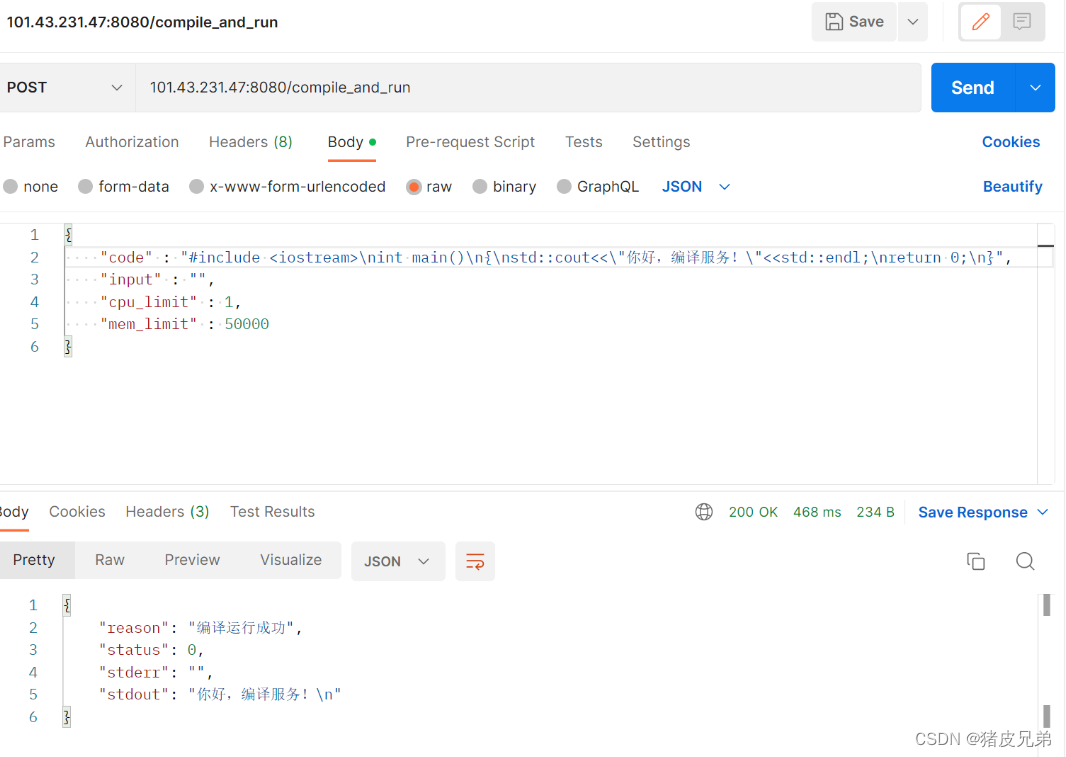
测试CPU占用超时
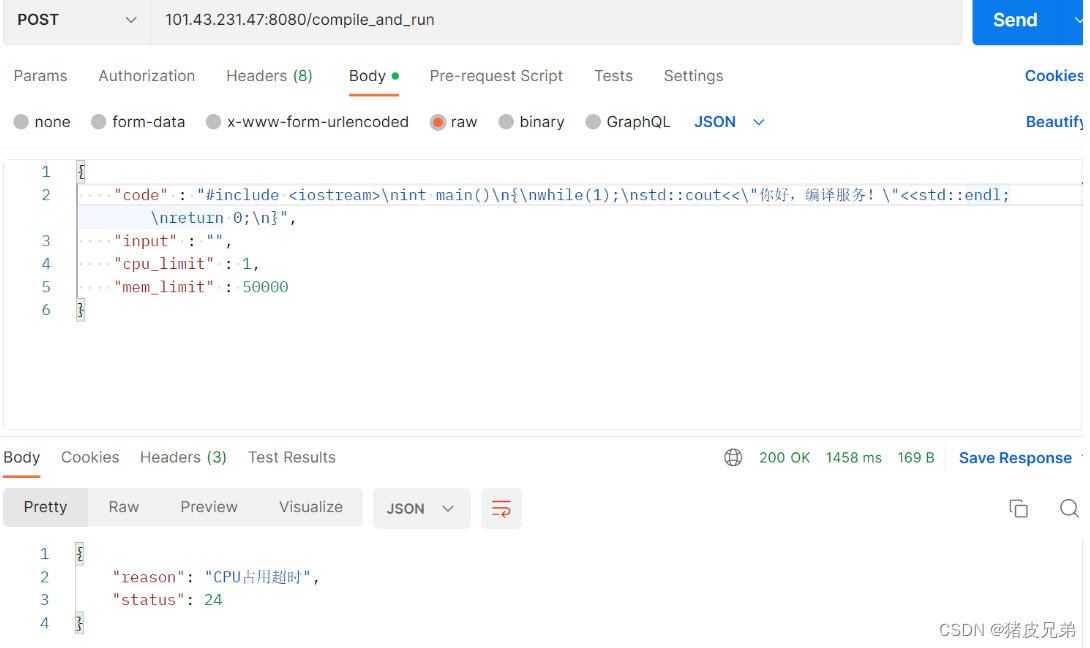
测试空间申请超限
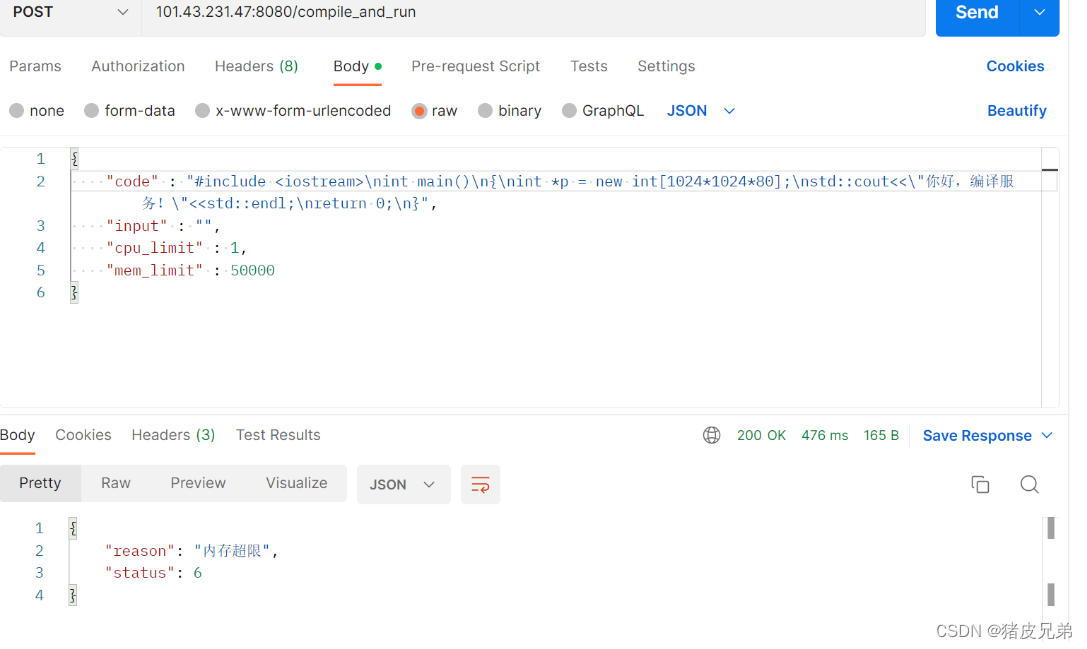
都非常成功。至此呢就有了可以对外提供编译运行服务的服务器了(只要你用Post方法申请/compile_and_run)我们现在完成的就是最右边的compile_server,一个一个的小框框
然后呢,我们的compile_server作为一个多平台,多主机部署。甚至在一台主机上部署多个服务这样的情况,我们默认端口8080就不行了。我们需要引入命令行参数,将端口暴露
int main(int argc,char*argv[])
{
....
}
然后我们后续就可以 ./compile_server 8081 ./compile_server 8082就可以了。可以在不同的主机上进行部署,也可以在同一台主机部署多个。
四、oj_server模块
①oj_server模块结构设计,MVC架构模式
我们以及有了能够给我们提供网络服务的编译运行服务器了,现在需要实现oj_server
oj_server说白了就是一个网站。oj_server的功能如下
- 1.获取首页
- 2.获取题目列表
- 3.获取单道题目,并提供编辑功能
- 4.提交判题功能(背后依靠的就是提供编译运行服务的服务器)
我们想采用的是基于MVC的一种架构模式
MVC
- M model 与数据交互的模块
- V view 视图,指用户界面,就是用来与用户进行交互的,模块
- C controller 控制器,核心的业务逻辑都在这里实现,合理调配model和view模块。
oj_server承担的就是负载均衡式的去调用后端的一个个编译服务,然后展现给用户,所以oj_server更靠近用户。
②oj_server的功能路由
我们设计的oj_server一共能提供给用户的是3个功能路由
- 1.题目列表的功能路由
- 2.单道题目的功能路由
- 3.提交代码进行判题的功能路由
而至于首页,就直接写了,不用去功能路由
#include "oj_controller.hpp"
#include <iostream>
#include <signal.h>
#include "../comm/httplib.h"
using namespace httplib;
using namespace ns_controller;
static Controller *ctrl_ptr = nullptr;
void Recovery(int signo)
{
ctrl_ptr->RecoveryMachine();
}
int main(int argc, char *argv[2])
{
signal(SIGQUIT,Recovery);
// 用户请求的服务路由功能
Server svr;
Controller ctrl; // 当用户请求时就直接调用controller当中的方法,交互数据model也被controller包含在内
ctrl_ptr = &ctrl;
// 获取所有的题目列表
svr.Get("/all_questions", [&ctrl](const Request &req, Response &resp) { // lambda表达式想用父作用域的变量,引用捕捉一下
// 我想返回的是一张包含所有题目的html网页
std::string html;
ctrl.AllQuestions(&html);
resp.set_content(html, "text/html;charset=utf-8"); // 测试,给个响应就行
// 要从后端的model获取(和数据交互的模块去获取)
}); // 获取什么资源,然后回调
// 用户要根据题目编号获取题目内容,编辑代码
// /questions/100 -> 正则匹配
//\d+是正则表达式 \d代表匹配数字,+代表匹配一个或多个,那么这就可以把题号全部读出来
// R"()",raw string 保持字符串内容的原貌,不用做相关的转义
svr.Get(R"(/questions/(\d+))", [&ctrl](const Request &req, Response &resp) { // C++当中的raw string原生字符串
std::string number = req.matches[1];
std::string html;
ctrl.Question(number, &html);//获得一道题的html
// req中有一个成员是matches,他是把资源请求分段放在了里面,我们拿的数字的位置就是matches[1]
resp.set_content(html,"text/html;charset=utf-8");
});
// 用户提交代码,判题(依靠compile_server功能)(1.每道题的测试用例 2.compile_and_run)
svr.Post(R"(/judge/(\d+))", [&ctrl](const Request &req, Response &resp) { //\d+正则表达式
std::string number = req.matches[1];//matches分割请求资源
//植入controller判题
std::string result_json;
ctrl.Judge(number,req.body,&result_json);//传过来的是提交的代码,然后获得了out_json,执行结果,返回给用户,通过response
resp.set_content(result_json,"application/json;charset=utf-8");//给用户响应
//resp.set_content("指定题目的判题" + number, "text/plain;charset=utf-8");
});
// 设置Web根目录
svr.set_base_dir("./wwwroot");
// 启动服务器
svr.listen("0.0.0.0", 8080); // 就固定成8080来提供服务
// 在这里就固定了,虽然也可以像compile_server那样可以暴露出去,今天我们就写死
return 0;
}
解释
-
1.set_base_dir其实是提供给首页的,我们的url如果是
http://101.43.231.47/的话就代表想要的资源是/,这个其实就代表的是访问的我们的web根目录(我们命名为wwwroot),而一般,这样的访问代表首页,我们会在web根目录下放置一个index.html供用户访问
-
2.R"()"上面以及说过了,就是row string,保持()中字符串原貌。
-
3.然后(\d+)代表的是正则表达式,+代表有多少就匹配多少,\d是匹配数字
-
4.上面使用到了Request当中的mathes对象,其实matches对象就是将我们的资源申请做了切分,比如说
\question\100,question就放到了matches[0],100就放到了matches[1]当中。
我们提供了三个功能路由就分别对应三种资源申请
-
http://101.43.231.47/all_questions
-
http://101.43.231.47/questions/题号
-
http://101.43.231.47/judge/题号
③ version1: 建立文件版的题库
首先,我们的题目需要的东西有
- 1.题号 number
- 2.标题 title
- 3.难度 star
- 4.描述 desc
- 5.时间要求 cpu_limit
- 6.空间要求 mem_limit
文件结构
在oj_server目录下,我们需要一个questions目录对题目的所有东西进行存储。
而我们需要一个questions.list配置文件来读取所有题目(我们打算将题目构建成一个Question对象)
然后更具体的东西,比如题目的描述,预设给用户的代码,测试用例单独放在一个目录里
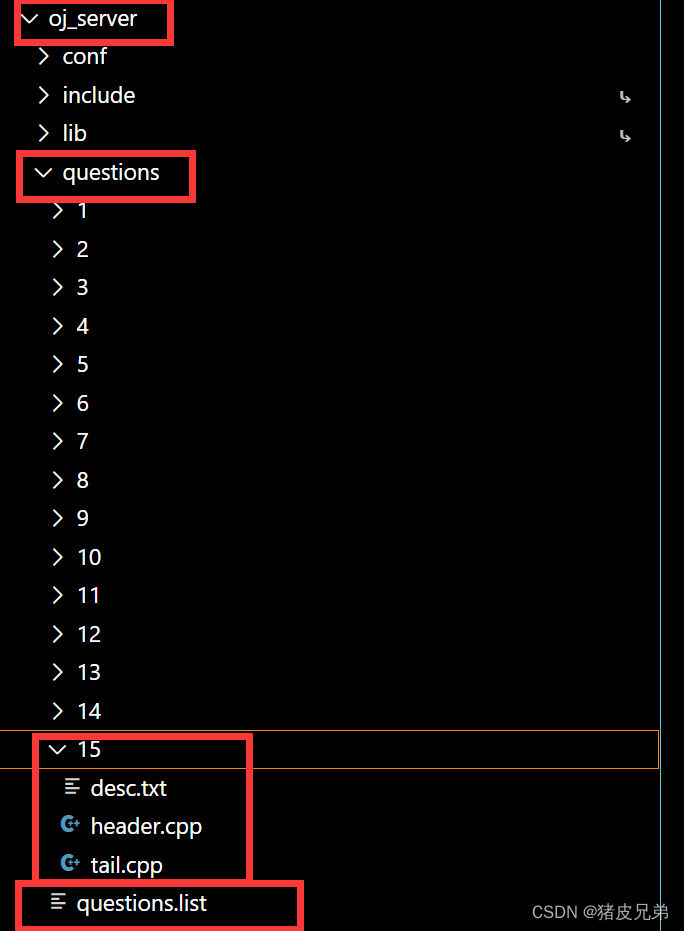
在questions.list配置文件中的存储方式
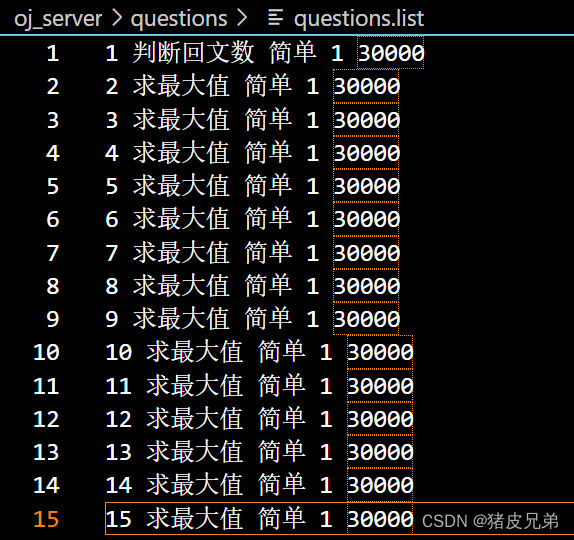
我们并不需要存储题目描述,我们可以通过对应的题号,找到题目对应细节目录下的题目描述,如上面的文件结构,我们就可以找到对应题目的desc.txt
给用户预设的代码header
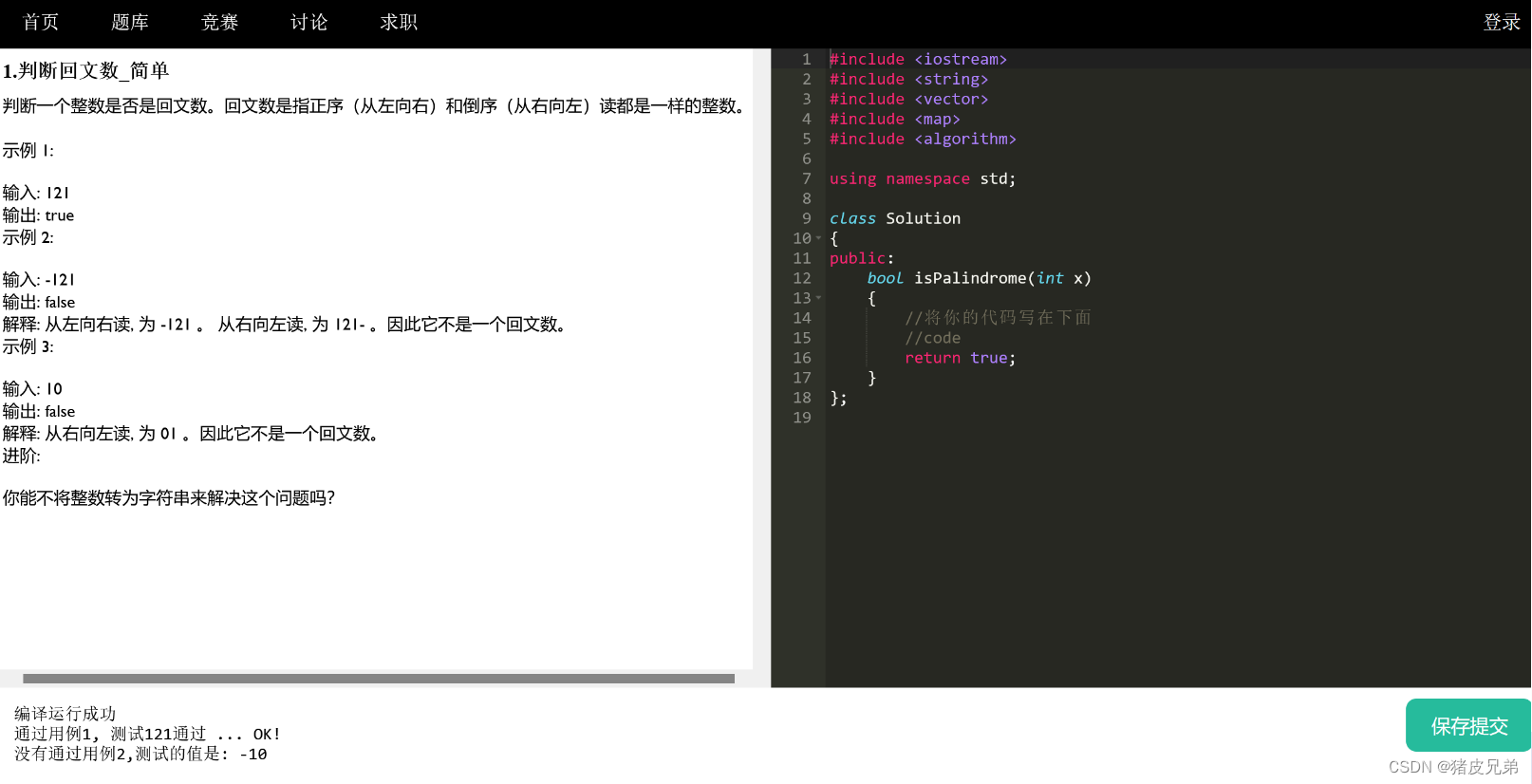
我们想要的效果是这样的,在代码编辑窗口我们是给用户预设了一部分代码的。
这些代码就放在了header.cpp当中。
未来,用户提交代码之后,我们不是直接将这部分代码直接交给compile_server进行编译运行。因为代码不全,compile_server只提供编译运行服务。只提交这部分代码的话是一定报错的。
tail.cpp测试用例部分
所以我们需要给header.cpp中的代码进行合并,进行合并的代码就放在tail.cpp当中
所谓测试用例,其实就是把你在代码编辑框中的代码提交上来,然后和另外一个代码进行合并。这个代码里差的就是对你写的那部分函数。所以两个合在一起,才形成了完整的一个程序。
tail.cpp的样子如下
#ifndef COMPILER_ONLINE
#include "header.cpp"
#endif
void Test1()
{
vector<int> v = {1, 2, 3, 4, 5, 6};
int max = Solution().Max(v); // 匿名对象,来完成方法的调用
if (max == 6)
{
std::cout << "Test 1 ... OK!" << std::endl;
}
else
{
// 这些可以不显示,但是我需要方便我调试
std::cout << "Test 1 ... Failed" << std::endl;
}
}
void Test2()
{
vector<int> v = {-1, -2, -3, -4, -5, -6};
int max = Solution().Max(v);
if (max == -1)
{
std::cout << "Test2 ... OK!" << std::endl;
}
else
{
std::cout << "Test2 ... Failed!" << std::endl;
}
}
int main()
{
Test1(); // 测试用例1
Test2(); // 测试用例2
return 0;
}
解释
- 条件编译的原因是:这部分代码因为缺少用户提交的那部分函数,所以我们在编译oj_server的时候,是会报错的,因为少了函数,跑不了可以理解。所以我们需要加一个条件编译,让这个.cc文件知道我们有该函数,不要报错。
- 这个条件编译到时候我们再通过给其他方式去掉,我们可以在调用g++的时候加选项,比如我们上面的宏是
COMPILER_ONLINE,那么到时候,我们直接gcc ... -D COMPILER_ONLIEN就可以去掉了。-D选项就是在命令行进行宏定义的方式
③version2 MySQL版本
首先,我们要创建一个用户,并给他赋权,以便我们进行连接和其他库的隐藏。
创建用户并赋权
创建可以远程登录的用户
Create user oj_client@'%' identified by '密码';
//%就是在任意地点登录,MySQL默认是只允许localhost登录的。
//这就给它设置了可以远程登录的能力
建立数据库 oj
create database oj;
赋权,赋权就是让该用户只能看见一些想让他看见的东西,比如我只让他看见oj这个数据库
grant all on oj.* to oj_client@'%';
这里会出现一些错误,都整理好了,请点击☞解决MySQL赋权…
使用MySQL_WorkBench创建表结构
在MySQL当中,我们就不需要像文件那样分很多个模块存储了,都直接存一起
MySQL的表结构
CREATE TABLE IF NOT EXISTS `oj_questions` (
`number` INT PRIMARY KEY AUTO_INCREMENT COMMENT '题目的编号',
`title` VARCHAR(128) NOT NULL COMMENT '题目的标题',
`star` VARCHAR(8) NOT NULL COMMENT '题目的难度',
`desc` TEXT NOT NULL COMMENT '题目的描述',
`header` TEXT NOT NULL COMMENT '对应题目的预设代码',
`tail` TEXT NOT NULL COMMENT '对应题目的测试用例代码',
`cpu_limit` INT DEFAULT 1 COMMENT '对应题目的超时时间',
`mem_limit` INT DEFAULT 50000 COMMENT '对应题目的最大开辟的内存空间'
) ENGINE=INNODB , CHARSET=UTF8;
注意desc,header和tail可能一个varchar不够,所以用tex大文本来进行存储
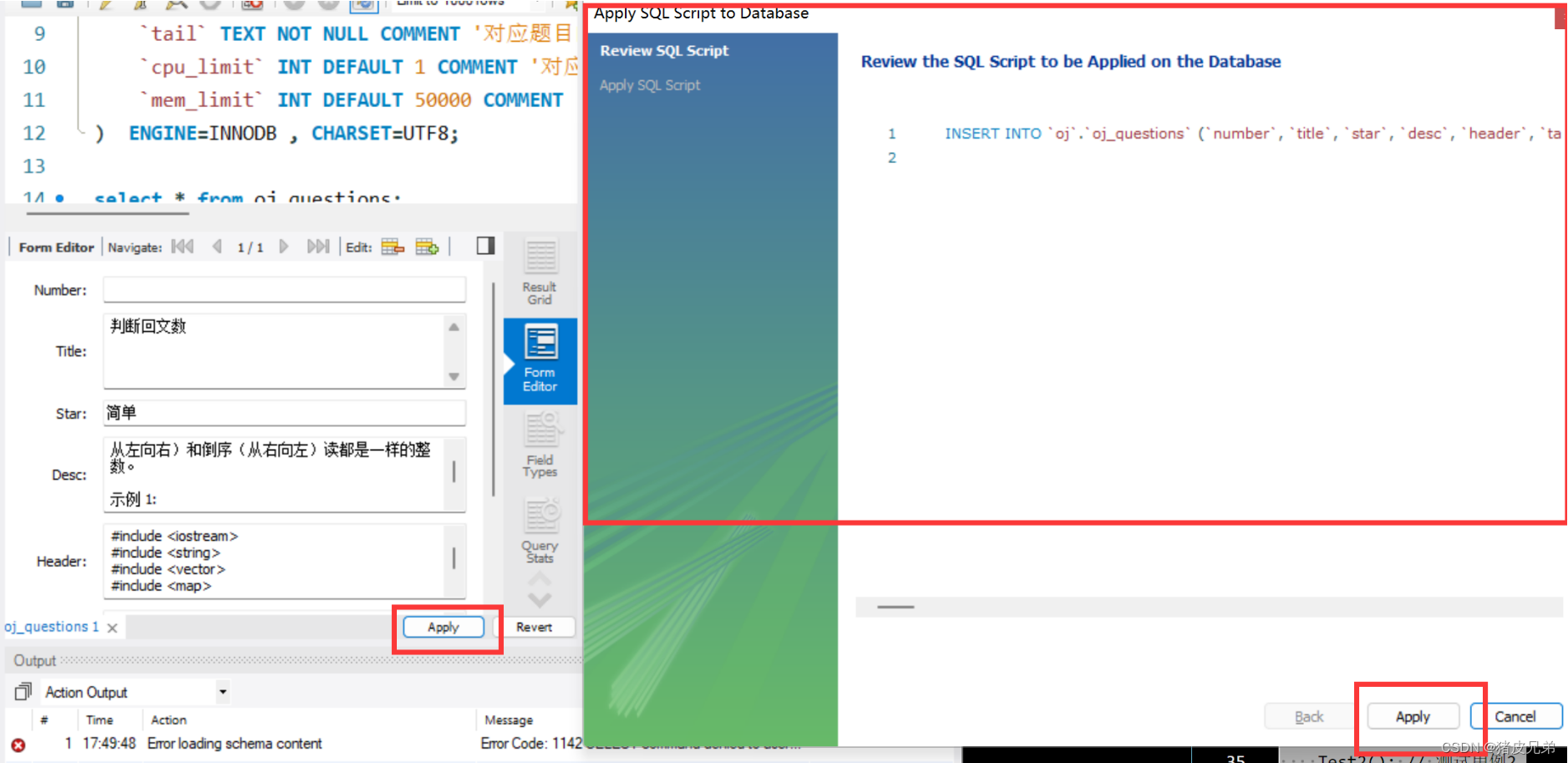
在MySQL_WorkBench当中进行录题
编写MySQL版本的model模块
首先我们梳理一下,在文件版当中,我们model模块是要完成以下几个部分
- 1.我们进行文件题库的读取,生成unordered_map< string,Question>的容器
- 2.提供获得所有题目的接口
- 3.提供获得单道题目的接口
那么我们现在MySQL版本的model模块就是
- 1.创建Question对象,因为要给别人返回这个对象
- 2.连接数据库进行读取,读取好了之后构建Question给别人返回就完了
而MySQL当中也需要搜题目列表和单道题目。
- 如果是需要题目列表,那么MySQL会通过你传过来的sql语句进行搜索,因为搜索出来的是多行,所以搜索出来的会放进一个特定的地方,结构是
MYSQL_RES,然后我们以二维数组的方式去读取就可以了。 - 如果是单道,同样的也是放入MYSQL_RES,只不过我们的Question只构建一次
读取MySQ流程
-
1.我们需要定义一个MySQL句柄
MYSQL * my = mysql_init(nullptr); -
2.然后进行MySQL的链接,
mysql_real_connect(my,ip,port,db.....)需要传入的参数如下。

-
3.修改字符编码
mysql_set_character_set(my,'utf8') -
4.然后已经找到了数据库,连接其实是连接的数据库,然后通过传入的sql去进行查询
mysql_query(my,sal); -
5.查询好的东西都放在一个特定的结构里面,叫做
MYSQL_RES,我们通过mysql_num_rows和mysql_num_fields去进行该结构中数据的行和列的数目。 -
6.循环进行读取数据,构建Question对象
-
7.
MYSQL_ROW row = mysql_fetch_row(res)就是拿到了一行,res是MYSQL_RES的对象,res是通过MYSQL_RES *res = mysql_store_result(my)拿到的 -
8.通过数组的方式读取 比如
code = row[1] -
9.释放MYSQL_RES结构,关掉MYSQL句柄
free(res); mysql_close(my);
namespace ns_model
{
using namespace std;
using namespace ns_log;
using namespace ns_util;
struct Question
{
std::string number; // 题目编号,唯一
std::string title; // 题目标题
std::string star; // 题目难度:简单 中等 困难
std::string desc; // 题目的描述
std::string header; // 题目预设给用户在线编辑器的代码
std::string tail; // 题目的测试用例,需要和header拼接,形成完整代码再compile_server
int cpu_limit; // CPU占用时间限制(s)
int mem_limit; // 空间限制(KB)
};
const std::string oj_questions = "oj_questions"; // 表名
const std::string host = "127.0.0.1";
const std::string user = "oj_client";
const std::string passwd = "123456";
const std::string db = "oj";
const unsigned int port = 3306;//MySQL默认端口
class Model
{
public:
Model()
{
}
bool QueryMySQL(const std::string &sql, vector<Question> *out)
{
//这里面访问数据库,构建Question结构体,或者数组,返回给调用者。
//主要就是访问数据库,调用官方给的第三方库
MYSQL *my = mysql_init(nullptr);//创建MySQL句柄
//连接数据库
if(nullptr == mysql_real_connect(my,host.c_str(),user.c_str(),passwd.c_str(),db.c_str(),port,
nullptr,0))//句柄,主机,用户,密码,数据库,端口,是否使用域间套接字,选项
{
LOG(FATAL)<<"连接数据库失败!"<<std::endl;
return false;
}
mysql_set_character_set(my,"utf8");//一定要设置编码格式,要不然会出先乱码问题(默认的应该是拉丁1)
LOG(INFO)<<"连接数据库成功!"<<std::endl;
//访问数据库,执行sql语句
if( 0 != mysql_query(my,sql.c_str()))//mysql进行查询
{
LOG(WARNING)<<sql <<" execute error!"<<std::endl;//sql执行失败
return false;
}//调用完之后我们这里就有了,只不过它帮我们存储好的,我们调用特定的方法去取这些数据
//提取结果,结果给我们放到特定的结构当中了
MYSQL_RES *res = mysql_store_result(my);//store叫做存储,这就把保存结果的特定结构拿到了
//分析访问结果
//获得行数和列数,我们还没开始用就觉得多半是数据存储字符串的形式
int rows = mysql_num_rows(res);//特定结果的行数
int cols = mysql_num_fields(res);//列数,fields是领域的意思
//提取数据
for(int i=0;i<rows;i++)
{
MYSQL_ROW row = mysql_fetch_row(res);//拿出一行
struct Question q;//然后构成一个或多个Question,返回
q.number = row[0];//拿到这一行的第j列
q.title = row[1];
q.star = row[2];
q.desc = row[3];
q.header = row[4];
q.tail = row[5];
q.cpu_limit = stoi(row[6]);
q.mem_limit = stoi(row[7]);
out->push_back(q);//多少行mysql表就会有多少个
}
//释放结果空间
free(res);
//关掉mysql连接
mysql_close(my);
return true;
}
bool GetAllQuestions(vector<Question> *out)
{
std::string sql = "select * from ";
sql += oj_questions;
return QueryMySQL(sql, out); // 所有题目全部拿到返回给controller进行其他操作
}
bool GetOneQuestion(const std::string &number, Question *q)
{
bool res = false;
std::string sql = "select * from ";
sql += oj_questions;
sql += " where number=";
sql += number;
vector<Question> result; // 只是转化一下,满足调用接口的参数要求
if (QueryMySQL(sql, &result))
{
if (result.size() == 1)
{
*q = result[0];
res = true;
}
}
return res;
}
~Model()
{
}
};
④model模块
model模块主要是用来和数据交互的,对外提供访问数据的接口
我们在model模块当中,因为我们的数据就是题目,所以一上来我们就要把题目读出来。
我们会有一个Question类,用它来描述该题目的信息
struct Question
{
std::string number; // 题目编号,唯一
std::string title; // 题目标题
std::string star; // 题目难度:简单 中等 困难
int cpu_limit; // CPU占用时间限制(s)
int mem_limit; // 空间限制(KB)
std::string desc; // 题目的描述
std::string header; // 题目预设给用户在线编辑器的代码
std::string tail; // 题目的测试用例,需要和header拼接,形成完整代码再compile_server
};
选择用unordered_map<string,Question>的结构体来存储生成的Question,建立题目(字符串)与Question的映射。
使用boost准标准库当中的split进行字符串分割
class StringUtil
{
public:
/**
* str:输入性参数,要切分的字符串
* target:输出型参数,保存并返回切分完毕的结果
* sep:separator分隔符
*/
static void SplitString(const std::string &str,std::vector<std::string>* target,std::string sep)
{
//使用C++准标准库boost 当中的split进行字符串分割
boost::split((*target),str,boost::is_any_of(sep),boost::algorithm::token_compress_on);
//is_any_of代表sep分隔符字符串当中的任意一个字符都能用来分割
//token_compress_on代表我是否需要进行压缩
//调用这个接口就自动的帮我们完成了字符串切分
}
};
按行读取配置文件形成Question对象
- 1.用C++的文件流的方式创建ifstream对象,打开文件流
- 2.使用getline进行按行读取,getline的注意事项上面以及说过,不再重复
- 3.使用字符串工具类中封装好的函数进行字符串切割放入tokens数组
- 4.利用该数组进行Question结构体的创建
bool LoadQuestionList(const std::string &questino_list)
{
// 加载配置文件 questions/questions.list + 题目编号对应目录下的文件
// 比如200道题,其实就是加载了200个Key值和200个Question对象
// 我们按行读取配置文件,可以用FileUtil当中的
ifstream in(question_list);
if (!in.is_open())
{
LOG(FATAL) << "加载题库失败,请检查是否存在题库文件" << std::endl; // 题目列表这个配置文件都加载不进来,那所有的都跑不动,所以是致命的
return false;
}
// 读取,getline,注意①不会保留换行符,②重载了强制类型转换,使得while可以判断成功与否
std::string line;
while (getline(in, line))
{
// 我们要按顺序进行切分,编号,标题,难度,时间限制,空间限制
std::vector<std::string> tokens;
StringUtil::SplitString(line, &tokens, " "); // 按空格分割到target当中
// 是按顺序切分的,按照我们questions.list配置文件的要求,它必须是被分成几份
// 如:1 判断回文数 简单 1 30000
if (tokens.size() != 5)
{
LOG(WARNING) << "加载部分题目失败,请检查文件格式" << std::endl; // 因为只是这道题出问题,不是很影响,所以WARNING
continue; // 这一行配置我们就不能要
}
// 构建Question对象
Question q;
q.number = tokens[0];
q.title = tokens[1];
q.star = tokens[2];
q.cpu_limit = stoi(tokens[3]);
q.mem_limit = stoi(tokens[4]); // 或者转成c_str()使用atoi
std::string path = question_path;
path += q.number; // q.number是字符串的方式呈现的
path += "/"; // 题号目录路径
FileUtil::ReadFile(path + "desc.txt", &(q.desc), true); // 读取描述文件
FileUtil::ReadFile(path + "header.cpp", &(q.header), true); // 读取header.cpp
FileUtil::ReadFile(path + "tail.cpp", &(q.tail), true); // 读取tail.cpp
// 我们是要保持原貌的,不然特别丑,所以true
// 然后插入questions 题号:Question
// questions.insert(make_pair(q.number,q));
questions.insert({q.number, q}); // 使用列表初始化
}
LOG(INFO) << "加载题录...成功!" << std::endl;
in.close();
return true;
}
⑤controller模块
controller模块整体结构
Controller模块是MVC架构模式当中的C,主要负责核心逻辑的编写。
比如model模块和view模块的调用将来都是在controller模块
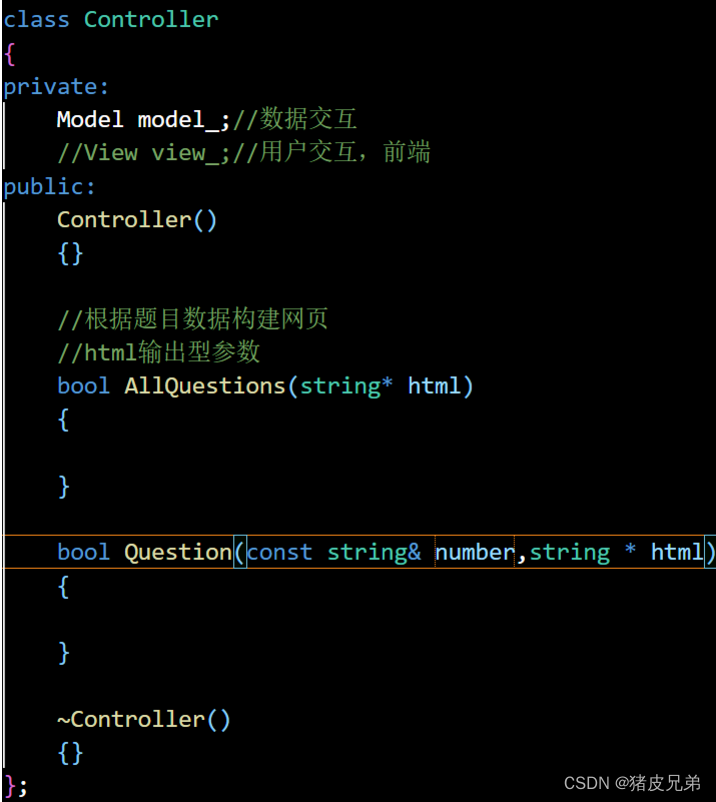
我们以及有了功能路由,但是如果向访问到页面,就需要用到view模块(前端页面)和model模块(数据获取)。所以功能路由一定是通过创建controller对象去进行调用。(controller的类当中就会合理的调用model模块还要view模块,就会有一个渲染好的html显示给用户)
引入ctemplate模板渲染库测试基本功能
首先百度搜索ctemplate的教程进行ctemplate库的安装
ctemplate的渲染方法:
- 1.需要体现准备好html模板
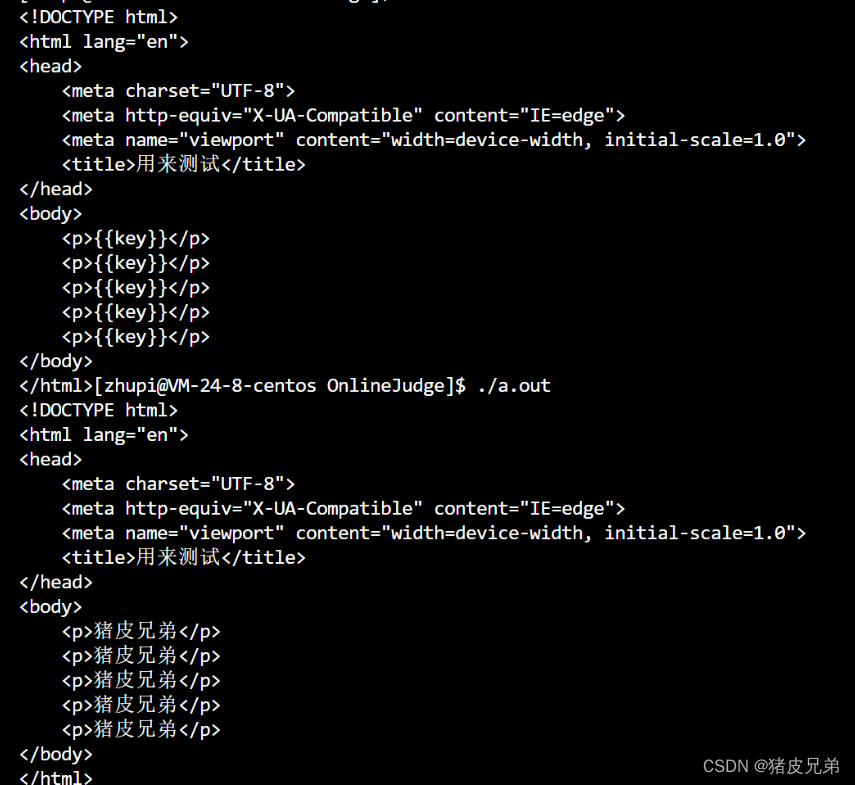
- 2.使用
ctemplate::TemplateDirection这个类型构建一个模板对应的数据字典,这个字典是Key-Value的形式。Key就是html模板当中的Key,Value就是待填入的值 - 3.然后进行html模板的获取
ctemplate::Template * tpl = cctemplate::Template::GetTemplate(html模板路径,是否保持原貌);保持原貌的话就传入参数ctemplate::DO_NOT_STRIP - 4.调用Template对象的成员方法Expand进行渲染
// 测试ctemplate 小demo
int main()
{
std::string in_html = "./test.html";
// 我们要处理的网页,也就是说我们测试的demo就直接放在test.cc的同级目录下
std::string value = "猪皮兄弟";
// 形成模板字典
ctemplate::TemplateDictionary root("test"); // 这就相当于这个字典对象的名字叫做test
root.SetValue("key", value); // SetValue,给模板字典设置值进去
// 获取被渲染网页对象
ctemplate::Template *tpl = ctemplate::Template::GetTemplate(in_html, ctemplate::DO_NOT_STRIP);
//DO_NOT_STRIP是保持网页htmp原貌,strip是剥夺的意思
// 添加模板字典到网页中进行合并
std::string out_html;
tpl->Expand(&out_html, &root);
// 完成了渲染
std::cout << out_html << std::endl;
return 0;
}
⑥judge模块(负载均衡)
用户在编辑器中编写的代码提交给oj_server之后,oj_server是需要做负载均衡的,也就是选择负载最少的主机进行访问
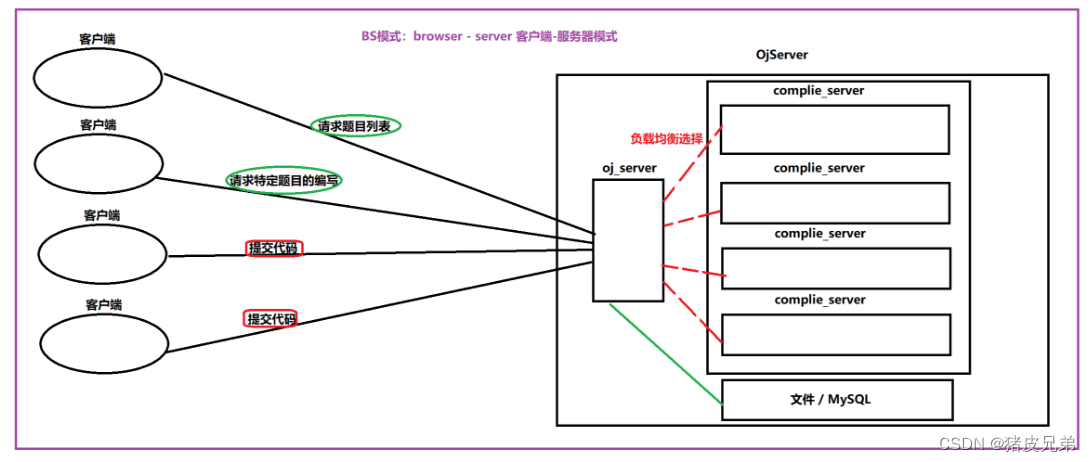
那么我们就在controller增加一个判题的功能。当客户端把代码提交上来之后,judge模块就要进行主机的选择,然后序列化成compile_server需要的json串发过去。(不要忘记需要拼接测试用例)
现在看来,用户提交的json串,有三部分构成
- 1.首先需要题目的id,让我们可以进行测试用例的拼接
- 2.code,这个就是用户编辑的那部分代码
- 3.input,其实是可以有自测输入的,不过我们今天不支持,反正也不难
收到json串的code之后,judge模块就会根据读取配置文件建立好的unordered_map来找到对应的题目细节,然后拿到题目对应的测试用例,进行拼接
下一步我们就是把拼接好的代码需要发给compile_server服务器进行编译运行了
那么有哪些主机可以供我们选择呢?我们又怎么去选择负载最低的呢?
所以我们就需要给一个配置文件,里面配置的就是主机的信息,比如IP,端口,然后我们还需要再oj_server当中维护对应主机的负载情况,以便我们进行选择。
Machine类
// 提供compile_server服务的主机
class Machine
{
public:
std::string ip; // 编译服务的IP
int port; // 编译服务的端口
uint64_t load; // 编译服务的负载情况
std::mutex *mtx; // mutex是禁止拷贝,Machine管理到容器当中是一定会发生拷贝的,所以我们用指针来管理mutex
public:
Machine()
: ip(""), port(0), load(0), mtx(nullptr)
{
}
~Machine()
{
}
public:
void IncLoad() // increase,提升主机负载
{
if (mtx)
mtx->lock();
++load;
if (mtx)
mtx->unlock();
}
void DecLoad() // decrease,减少主机负载
{
if (mtx)
mtx->lock();
--load;
if (mtx)
mtx->unlock();
}
// 获取主机负载,没有太大的意义,只是为了统一接口
uint64_t Load()
{
uint64_t _load = 0;
if (mtx)
mtx->lock();
_load = load;
if (mtx)
mtx->unlock();
return _load;
} // 获取负载的时候避免这个machine被下线,加锁
};
因为一旦连接我,拼接完之后就要对主机进行选择,所以这里是要加锁包的,为了负载均衡,我们维护的有load,我们要选择load最小的去进行服务。
加锁也可以用系统当中的pthread_mutex_xxx等(pthread库中的内容)
也可以用C++当中的mutex库,需要注意的是,C++当中所有的锁都是防拷贝的。
因为创建出来的Machine对象,要管理到某个容器当中,所以一定会发生拷贝,所以我们直接定义mutex对象是会报错的,我们这里需要用指针的方式去用锁
负载均衡函数
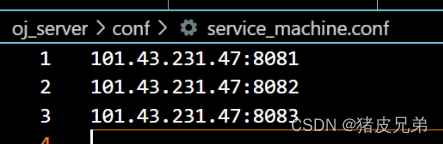
const std::string service_machine = "./conf/service_machine.conf";
// 负载均衡模块
class LoadBalance
{
private:
// 此时,我就想从配置文件当中把所有的主机读上来,IP,端口
// 把可以提供compile_server的Machine对象放入容器。
// 每一台主机都有自己的下标,我们用它充当当前主机的id
std::vector<Machine> machines; // 可以提供compile_server的所有的主机
std::vector<int> online; // 所有在线的主机
std::vector<int> offline; // 所有离线主机的id
std::mutex mtx; // 这个只有一个就不用用指针了
public:
LoadBalance()
{
assert(LoadConf(service_machine));
LOG(INFO) << "加载" << service_machine << "配置文件成功" << std::endl;
}
~LoadBalance()
{
}
bool LoadConf(const std::string &machine_conf) // 传入配置文件路径
{
// 读取部署主机配置文件
ifstream in(machine_conf); // 打开文件流
if (!in.is_open())
{
LOG(FATAL) << " 加载: " << machine_conf << "失败" << std::endl;
return false;
}
// 开始读取并构建Machine对象放入vector形成machines
std::string line;
while (std::getline(in, line)) // getline 1.不会保留换行符,2.重载了强制类型转换,所以可用while进行判断
{
// 101.43.231.47:8081
Machine m;
// int i = line.find(":");
// machine.ip = line.substr(0, i - 0);
// machine.port = stoi(line.substr(i));
std::vector<std::string> tokens;
StringUtil::SplitString(line, &tokens, ":"); // 以冒号分割进v
if (tokens.size() != 2)
{
LOG(WARNING) << "切分" << line << "失败" << std::endl;
continue; // 失败,切下一个
}
m.ip = tokens[0];
m.port = stoi(tokens[1]); // 转为int
m.load = 0;
m.mtx = new std::mutex(); // 一定要是指针,C++的所有mutex防拷贝,push到容器当中是需要拷贝的,必须用指针来使用锁
line.clear();
// 一开始全部都是Online,在后面使用的时候再去下线,我们push的是下标,所以使用machines.size()来进行push
online.push_back(machines.size());
machines.push_back(m);
}
in.close();
return true;
}
/**
* id:输出型参数,选择到了哪个主机
* m:输出型参数,选择的主机的对象,(只是我想直接访问,不想再去通过下标访问machines)
*/
bool ItelligentChoice(int *id, Machine **m) // 智能选择,负载均衡,我们想拿的是二级指针
{ // 我现在要访问compile_server了,给我智能选择
// 通过machines来进行选择,通过它的负载load,而选择machines的时候因为要操作load,所以加锁保护临界资源
mtx.lock(); // 加锁保护
// 选择服务器,负载均衡。
// 负载均衡的算法:1.随机数法,2.轮询+随机(选择最小的load,绝对负载均衡),我们选择这种方案
int online_num = online.size();
if (online_num == 0)
{
// 所有主机离线
mtx.unlock(); // 最好搞成RAII,C++中就有LockGuard能够RAII
LOG(FATAL) << "所有的后端编译运行主机已经离线,请运维的老铁尽快查看" << std::endl;
return false;
}
// 通过遍历的方式,找到负载最小的机器
*id = online[0];
*m = &machines[online[0]];
uint64_t min_load = machines[online[0]].Load(); // online和offline存在是machines的下标
for (int i = 1; i < online_num; i++)
{
uint64_t curr_load = machines[online[i]].Load();
if (min_load > curr_load)
{
min_load = curr_load;
*id = online[i]; // 选择的主机是对应的machines的哪台,online中是下标的映射
*m = &machines[online[i]]; // 我要拿的是这台主机的地址
}
}
mtx.unlock();
return true;
}
};
编写负载均衡器
过程明确:
- 1.获得该题目对应的Question结构体
- 2.解析客户端发来的json串,进行代码拼接和构建新的compile_server需要的json串
- 3.负载均衡,主机智能选择
- 4.选择到负载最小的主机,使用cpp-httplib生成客户端进行数据发送。
- 5.会自动的帮我们发送请求,并接收结果,然后我们就拿到了结果,对结果进行分析,发送给用户
cpp-httplib 构建Client端的方法:
- 1.Client cli(IP,Port);
- 2.cli.Post/Get.(请求的资源,发送什么数据,content-type)
- 3.自动接收结果,第二步的方法的返回值是一个result结构体,里面就有Response结构的成员,返回的东西都填到body里面了的,包括执行结果等等
//ctroller的Judge成员函数
void Judge(const std::string &number, const std::string &in_json, std::string *out_json) // 给我json串,我judge之后返回结果json串
{
//LOG(DEBUG) << in_json << "\nnumber:" << number << std::endl;
// 0.根据题目编号,直接拿到对应的题目细节,很简单,因为我们有和数据交互的model模块
struct Question q;
model_.GetOneQuestion(number, &q);
// 1.对in_json反序列化 ,因为in_json当中的code只有header,不全
// 而且我们还需要里面的题目的id,input数据
Json::Value in_value;
Json::Reader reader;
reader.parse(in_json, in_value); // 将in_json解析到in_value当中
std::string code = in_value["code"].asString(); // 拿到用户提交的代码
// 2.重新拼接用户代码和测试用例代码
Json::Value compile_value;
compile_value["input"] = in_value["input"].asString();
compile_value["code"] = code +"\n" + q.tail; // 需要把编译宏给去掉
compile_value["cpu_limit"] = q.cpu_limit;
compile_value["mem_limit"] = q.mem_limit; // 以上四个字段就是compile_server需要的
Json::FastWriter writer;
std::string compile_string = writer.write(compile_value);
// 3.负载均衡,选择负载最低的主机(前面的数据准备工作已经做好) 这里要做各种差错处理
// 规则:一直选择,直到主机可用,否则,就是全部下线(挂掉),不需要让客户知道
while (true) // 必须选择主机并编译运行成功返回的Response中状态码是200表示成功才行
{
int id = 0;
Machine *m = nullptr;
if (!load_balance_.ItelligentChoice(&id, &m))
{
break; // 所有主机都挂掉了
}
// 4.发起http请求,请求compile_server服务
Client cli(m->ip, m->port); // 构建客户端
m->IncLoad(); // 请求主机,增加负载
LOG(INFO) << "选择主机成功,主机id: " << id << " 详情: " << m->ip << ":" << m->port
<< " 当前主机的负载是: " << m->Load() << std::endl;
if (auto res = cli.Post("/compile_and_run", compile_string, "application/json;charset=utf-8"))
// 请求的服务,请求的参数,请求的content-type
{
// res指的是result,里面有response,和err 请求是否成功是判断res里面有没有response,err就是一堆的枚举常量
// 发起了之后,服务端处理完成之后会返回给我Response
// 5.返回用户json串,json串的发送和接收由cli和svr自动完成
if (res->status == 200) // 这样请求才算完全成功
{
*out_json = res->body; // 拿到编译的结果
m->DecLoad(); // 请求完毕,减少负载
LOG(INFO) << "请求编译和运行服务成功..." << std::endl;
break;
}
// 访问到了,但是结果是不对的,那么就会while(true)回来重新再选择主机
m->DecLoad();
}
else
{
// 请求失败
LOG(ERROR) << "当前选择的主机id: " << id << " 详情: " << m->ip << ":" << m->port << "可能已经离线" << std::endl;
// 请求完毕,减少负载。这里没有必要,因为一旦我们将主机离线,负载会清零
load_balance_.OfflineMachine(id); // 根据id来进行主机的离线
load_balance_.ShowMachines(); // 仅仅是为了调试
}
}
}
离线和上线
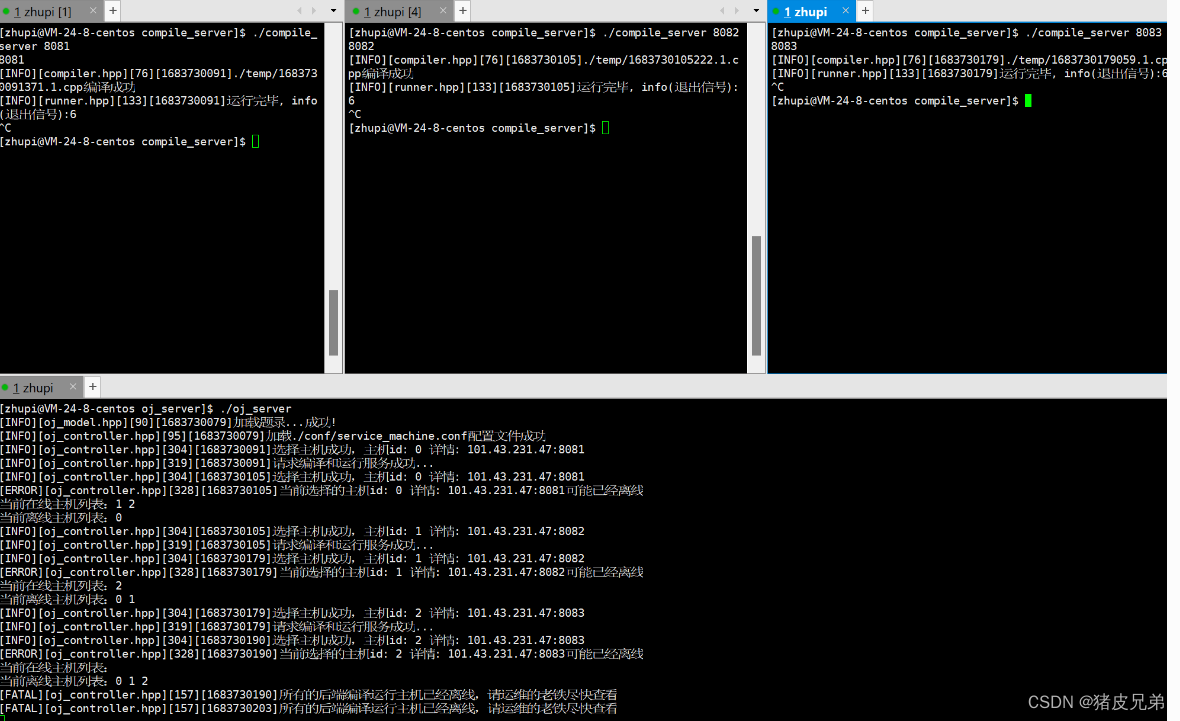
如果一台主机请求失败,我们就应该让该主机离线
如果是上线,就是说如果运维把主机弄好了重新启动了,我们就进行上线,可以让他重新被选择。我们这里粗暴一点,如果所有主机都离线了,统一上线。
而上线和离线呢,我们其实均衡调度LoadBalance模块有online和offliine两个数组进行machines机器下标的存储。上线就是把下标加到online数组,能够被选择嘛,离线就是从online数组移到offline数组。
void OfflineMachine(int which) // 请求不成功,将这台主机offline
{
// 离线的时候可能有人正在ItelligentChoice,所以加锁
mtx.lock();
for (auto iter = online.begin(); iter != online.end(); iter++)
{
if (*iter == which)
{ // 找到该目标主机在Online保存的下标,移到Offline当中
machines[which].load=0;//负载清零
online.erase(iter);
// offline.push_back(*iter);//迭代器失效
offline.push_back(which);
break; // 有break的存在,我们这里就不用迭代器失效的问题,只会erase一次,不然的话就要去更新迭代器
}
}
mtx.unlock();
}
void OnlineMachine()//上线所有的
{
// 当所有主机都离线的时候,我们统一上线,offline的移到online
// 所以我们要有一些检测机制来检测全部离线
mtx.lock();
online = offline;//vector的深拷贝
//online.insert(online.end(),offline.begin(),offline.end());
offline.clear();
//offline.erase(offline.begin(),offline.end());
mtx.unlock();
LOG(INFO)<<"所有的主机又上线啦"<<std::endl;
}
⑦使用Postman进行oj_server的综合测试
首先,我们启动三个 compile_server服务
分别是./compile_server 8081 ./compile_server 8082 ./compile_server 8083
这就可以支持oj_server对我们进行负载均衡调度的选择
我们这里测试的主要是oj_server的判题Judge功能,我们对于oj_server,需要访问的资源是/judge/number ,比如 http://101.43.231.47/judge/1;判断1号题目是否正确
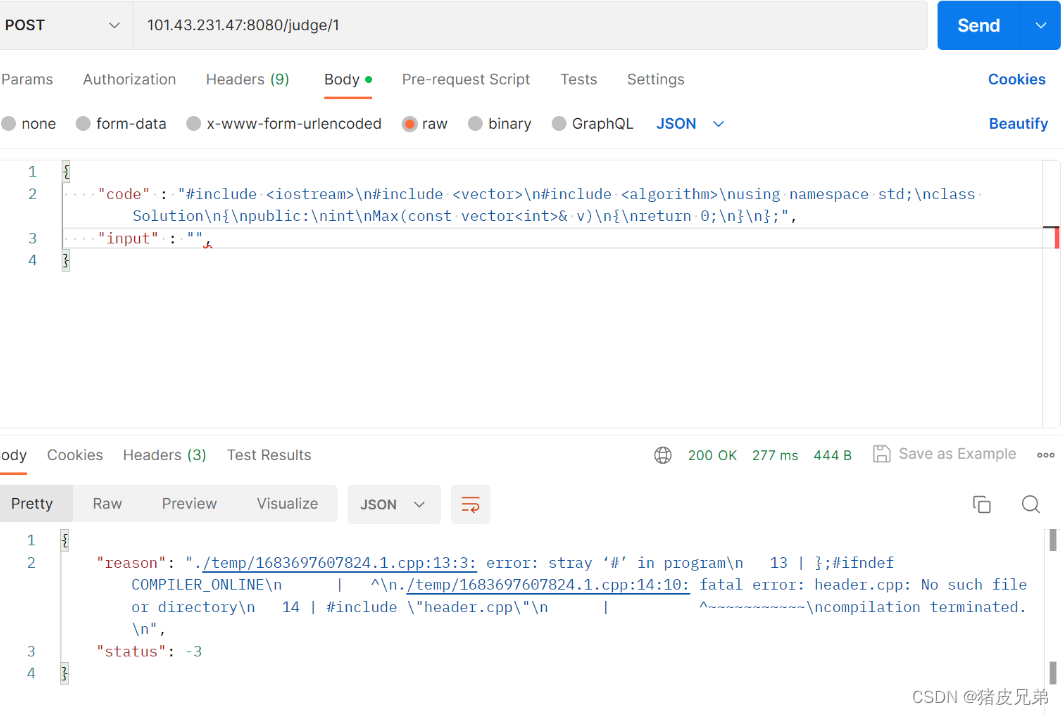
我们看到这里的状态码是-3,从我们之前对于状态码的描述来看,负数就是编译错误。
然后找到错误是因为测试用例当中有一段空定义我们忘记去掉。
那么我们就改一下g++的选项就可以了。
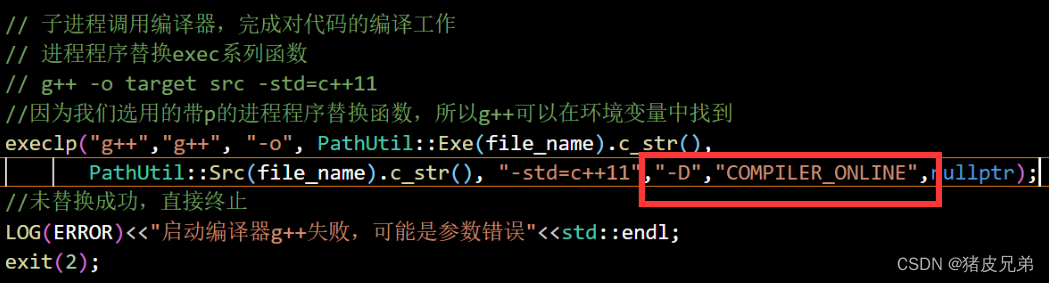
然后重新编译运行
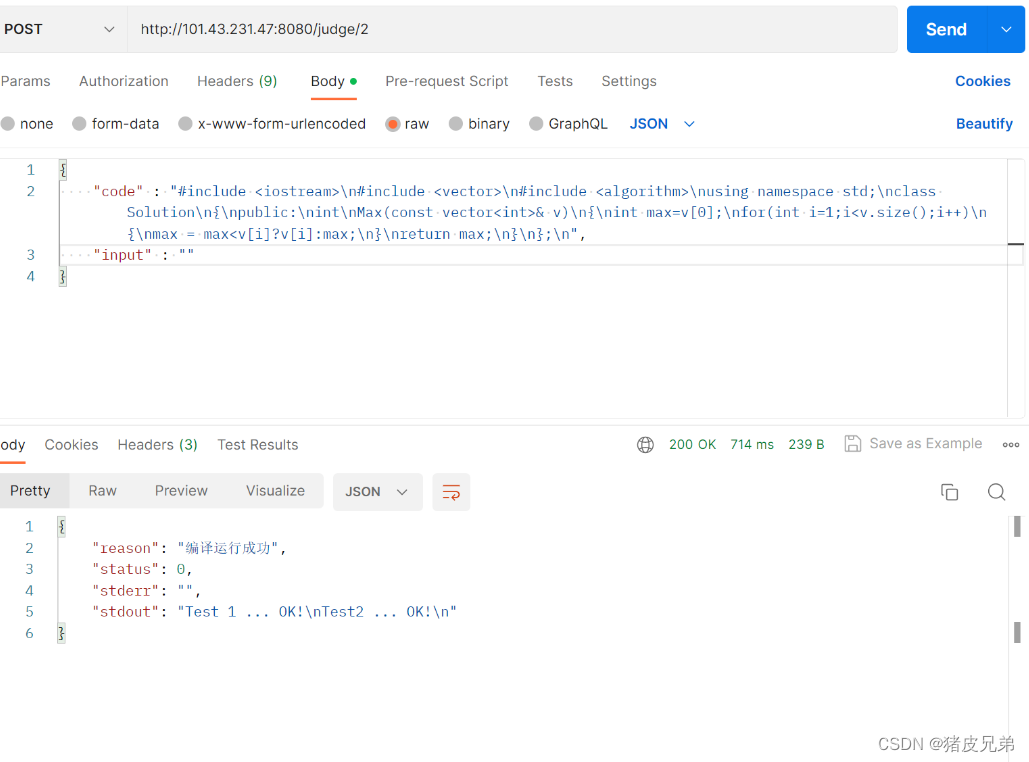
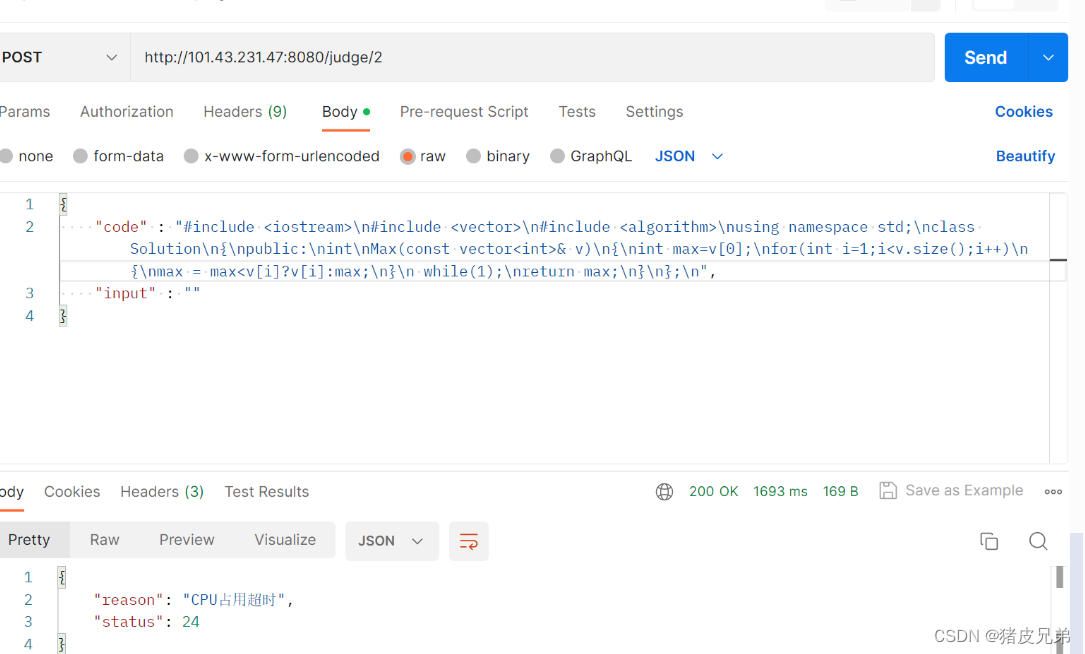
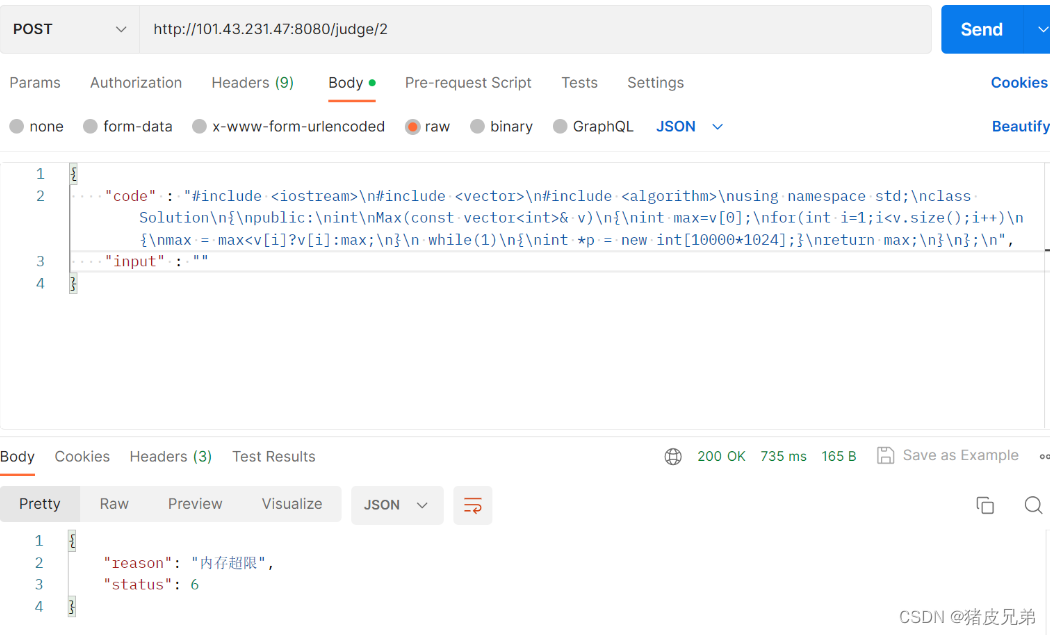
负载均衡的话,因为Postman只能一次一次发,我们没办法测试 ,我们得等到后面能通过网页提交代码的时候才测试得了。
我们挂掉主机
⑧view模块整体代码结构(前端的东西,不是重点)
由上可知,View类应该需要的是两个接口,AllExpandHtml和Expand
从名字就可以看出来,AllExpandHtml用于获得题目列表的html形成,Expand就用于单道题目的html形成
因为这个前端的东西,对于我们来说不是很重要,我也只进行了一些了解,后面就直接粘代码了。前端的东西涉及html/css/js/jquery/ajax等等,我们在用户编辑代码的部分,引入了Ace在线编辑器,可以在后端调用Ace的方法,直接拿到用户编辑的内容
下面的html代码就是html模板,我们根据上面的方法对模板里面的内容用ctemplate库进行渲染即可
对于前后端交互就是,前端给了一个按钮,点击按钮后,设的有onclick的属性,然后响应事件,会触发后面给定的函数(js),该函数就完成调用Ace在线编辑器提供的方法拿到用户提交代码,构成json串,发给oj_server进行处理。然后后面过程走完了,我返回给你结果你进行显示
index
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>ZPXD个人oj系统</title>
<!-- 这张网页的整体样式 -->
<style>
/* 选中所有标签,消除内外边距 */
* {
/* 消除网页的默认外边距 */
margin:0px;
/* 消除网页的默认内边距,这俩100%保证我们的样式设置不受默认影响 */
padding:0px;
}
/* html和body标签都是按照100%进行 */
html,
body{
width: 100%;
height: 100%;
}
.container .navbar{
width: 100%;
height: 50px;
background-color: black;
/* 给父级标签设置overflow */
overflow:hidden;
}
.container .navbar a{
/* 设置成行内块元素 */
display: inline-block;
/* 设置a标签的宽度 */
width: 80px;
/* 设置字体颜色 */
color: white;
/* 设置大小 */
font-size: large;
/* 设置文字的高度和导航栏一样的高度 */
line-height: 50px;
/* 去掉下划线 */
text-decoration: none;
/* 设置文字居中 */
text-align: center;
}
/* 设置鼠标事件 */
.container .navbar a:hover{
background-color: green;
}
.container .navbar .login{
float: right;
}
.container .content{
/* 设置标签的宽度,px是像素点的意思 */
width: 800px;
/* 背景色 */
/* background-color:#ccc; */
/* content整体居中,上下0px像素点,左右auto居中 */
margin: 0px auto;
/* 设置content在container当中也居中 */
text-align: center;
/* 设置上外边距 */
margin-top: 200px;
}
.container .content .font_{
/* 设置标签为块级元素,独占一行,可以设置高度宽度等属性 */
display: block;
/* 设置每个文字的上外边距 */
margin-top: 20px;
/* 去掉下划线 */
text-decoration: none;
/* 设置字体大小 */
/* font-size:larger; */
}
.container2 .footer{
margin-top: 400px;
width: 100%;
height: 50px;
background-color: black;
text-align: center;
color: white;
}
</style>
</head>
<body>
<div class="container">
<!-- 导航栏 ,功能不实现,但是给个导航栏-->
<div class="navbar">
<a href="#">首页</a>
<!-- a标签是超链接 -->
<a href="/all_questions">题库</a>
<a href="#">竞赛</a>
<a href="#">讨论</a>
<a href="#">求职</a>
<a class="login" href="#">登录</a>
</div>
<!-- 网页的内容 -->
<div class="content">
<h1 class="font_">欢迎来到我的OnlineJudge平台</h1>
<p class="font_">这是我个人独立发开的一个oj平台</p>
<a class="font_" href="/all_questions">点击我开始编程了!!</a>
</div>
</div>
<div class="container2">
<div class="footer">
<h4>@猪皮兄弟</h4>
</div>
</div>
</body>
</html>
all_questions
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<!-- 这是网页标题,在最上面的框框中 -->
<title>在线OJ-题目列表</title>
<style>
/* 选中所有标签,消除内外边距 */
* {
/* 消除网页的默认外边距 */
margin:0px;
/* 消除网页的默认内边距,这俩100%保证我们的样式设置不受默认影响 */
padding:0px;
}
/* html和body标签都是按照100%进行 */
html,
body{
width: 100%;
height: 100%;
}
.container .navbar{
width: 100%;
height: 50px;
background-color: black;
/* 给父级标签设置overflow */
overflow:hidden;
}
.container .navbar a{
/* 设置成行内块元素 */
display: inline-block;
/* 设置a标签的宽度 */
width: 80px;
/* 设置字体颜色 */
color: white;
/* 设置大小 */
font-size: large;
/* 设置文字的高度和导航栏一样的高度 */
line-height: 50px;
/* 去掉下划线 */
text-decoration: none;
/* 设置文字居中 */
text-align: center;
}
/* 设置鼠标事件 */
.container .navbar a:hover{
background-color: green;
}
.container .navbar .login{
float: right;
}
.container .questions_list {
padding-top: 50px;
width: 800px;
height: 100%;
margin: 0px auto;
/* background-color: #ccc; */
text-align: center;
}
.container .questions_list table{
width: 100%;
font-size: large;
font-family: 'Lucida Sans', 'Lucida Sans Regular', 'Lucida Grande', 'Lucida Sans Unicode', Geneva, Verdana, sans-serif;
margin-top: 50px;
background-color: rgb(243,248,246);
}
.container .questions_list h1{
color: green;
}
/* .是用来查类的,标签比如table不用加. */
.container .questions_list table .item{
width: 100px;
height: 40px;
font-size: large;
font-family: 'Times New Roman', Times, serif;
}
.container .questions_list table .item a{
text-decoration: none;
color: black;
}
.container .questions_list table .item a:hover{
color:blue;
font-size: larger;
}
.container .footer{
width: 100%;
height: 50px;
text-align: center;
line-height: 50px;
color:#ccc;
margin-top: 15px;
}
.container2 .footer{
margin-top: 50px;
width: 100%;
height: 50px;
background-color: black;
text-align: center;
color: white;
}
</style>
</head>
<body>
<div class="container">
<!-- 导航栏 ,功能不实现,但是给个导航栏-->
<div class="navbar">
<a href="/">首页</a>
<!-- a标签是超链接 -->
<a href="/all_questions">题库</a>
<a href="#">竞赛</a>
<a href="#">讨论</a>
<a href="#">求职</a>
<a class="login" href="#">登录</a>
</div>
<div class="questions_list">
<h1>OnlineJudge题目列表</h1>
<table>
<!-- <tr></tr>代表一行 TableRow
<th></th>代表表头 TableHead
<td></td>代表数据框,就是一行中的一个表格 TableData -->
<tr>
<th class ="item">编号</th>
<th class ="item">标题</th>
<th class ="item">难度</th>
</tr>
{{#questions_list}}
<tr>
<td class ="item">{{number}}</td>
<td class ="item"><a href="/questions/{{number}}">{{title}}</a></td>
<!-- 虽然访问的是/question/{{number}}这个资源 -->
<!-- 但是会由我们的功能路由去进行路由,最终是渲染的我们的one_question.html -->
<td class ="item">{{star}}</td>
</tr>
{{/questions_list}}
</table>
</div>
</div>
<div class="container2">
<div class="footer">
<h4>@猪皮兄弟</h4>
</div>
</div>
</body>
</html>
one_question
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>{{number}}.{{title}}</title>
<!-- 1.判断回文数 -->
<!-- 引入ACE CDN,CDN是用来帮我们进行网络加速的,类似于云服务 -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/ace/1.2.6/ace.js" type="text/javascript"
charset="utf-8"></script>
<!-- 引入另一个CDN,语言识别 -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/ace/1.2.6/ext-language_tools.js" type="text/javascript"
charset="utf-8"></script>
<!-- 引入jquery CDN -->
<script src="http://code.jquery.com/jquery-2.1.1.min.js"></script>
<style>
* {
margin: 0;
padding: 0;
}
html,
body {
width: 100%;
height: 100%;
}
.container .navbar {
width: 100%;
height: 50px;
background-color: black;
/* 给父级标签设置overflow */
overflow: hidden;
}
.container .navbar a {
/* 设置成行内块元素 */
display: inline-block;
/* 设置a标签的宽度 */
width: 80px;
/* 设置字体颜色 */
color: white;
/* 设置大小 */
font-size: large;
/* 设置文字的高度和导航栏一样的高度 */
line-height: 50px;
/* 去掉下划线 */
text-decoration: none;
/* 设置文字居中 */
text-align: center;
}
/* 设置鼠标事件 */
.container .navbar a:hover {
background-color: green;
}
.container .navbar .login {
float: right;
}
.container .part1 {
/* 宽度铺满 */
width: 100%;
/* 高度600像素 */
height: 600px;
}
.container .part1 .left_desc {
width: 50%;
height: 600px;
float: left;
/* 添加滚动条 */
overflow: scroll;
}
.container .part1 .left_desc h3 {
padding-top: 10px;
padding-left: 10px;
}
.container .part1 .left_desc pre {
padding-top: 10px;
padding-left: 10px;
font-size: medium;
font-family: 'Gill Sans', 'Gill Sans MT', Calibri, 'Trebuchet MS', sans-serif;
}
.container .part1 .right_code {
width: 50%;
height: 600px;
float: right;
}
.container .part1 .right_code .ace_editor {
height: 600px;
}
.container .part2 {
width: 100%;
overflow: hidden;
}
.container .part2 .result {
width: 300px;
float: left;
}
.container .part2 .btn_submit {
width: 120px;
height: 50px;
font-size: large;
float: right;
background-color: #26bb9c;
color: #fff;
/* 给按钮带上圆角 */
border-radius: 1ch;
border: #26bb9c solid 0px;
margin-top: 10px;
margin-right: 10px;
}
.container .part2 button:hover {
color: green;
}
.container .part2 .result {
margin-top: 15px;
margin-left: 15px;
}
.container .part2 .result pre{
font-size: large;
}
</style>
</head>
<body>
<div class="container">
<!-- 导航栏 ,功能不实现,但是给个导航栏-->
<div class="navbar">
<a href="/">首页</a>
<!-- a标签是超链接 -->
<a href="/all_questions">题库</a>
<a href="#">竞赛</a>
<a href="#">讨论</a>
<a href="#">求职</a>
<a class="login" href="#">登录</a>
</div>
<!-- 左右的结构 -->
<div class="part1">
<div class="left_desc">
<h3><span id="number">{{number}}</span>.{{title}}_{{star}}</h3>
<!-- 三级标题 -->
<pre>{{desc}}</pre>
<!-- p是段落,放题目描述 -->
</div>
<div class="right_code">
<pre id="code" class="ace_editor"><textarea class="ace_text-input">{{pre_code}}</textarea></pre>
</div>
</div>
<!-- 交互模块!!!! -->
<!-- 提交并且得到结果并显示 -->
<div class="part2">
<!-- 结果查看,后面使用jquery进行标签的插入 -->
<div class="result"></div>
<!-- 提交按钮 -->
<button class="btn_submit" onclick="submit()">保存提交</button>
</div>
</div>
<!-- <textarea name="code" id="" cols="120" rows="30">{{pre_code}}</textarea> -->
<!-- 这是文本编辑框,要放我们预设的代码 pre_code -->
<script>
//初始化对象
editor = ace.edit("code");
//设置风格和语言(更多风格和语言,请到github上相应目录查看)
// 主题大全:http://www.manongjc.com/detail/25-cfpdrwkkivkikmk.html
editor.setTheme("ace/theme/monokai");
editor.session.setMode("ace/mode/c_cpp");
// 字体大小
editor.setFontSize(16);
// 设置默认制表符的大小:
editor.getSession().setTabSize(4);
// 设置只读(true时只读,用于展示代码)
editor.setReadOnly(false);
// 启用提示菜单
ace.require("ace/ext/language_tools");
editor.setOptions({
enableBasicAutocompletion: true,
enableSnippets: true,
enableLiveAutocompletion: true
});
function submit() {
//alert("嘿嘿");
//console.log("哈哈!");
//1.收集当前页面的有关数据,1.题号,2.代码
var code = editor.getSession().getValue();
//console.log(code);
var number = $(".container .part1 .left_desc h3 #number").text();//#是id选择器
//console.log(number);
var judge_url = "/judge/" + number;
//console.log(judge_url);//请求哪个资源,我们后台进行路由GET,POST
//2.构建需要的json串,并向后台发起请求基于http的json请求(json串)
$.ajax({
method: "Post",//请求方法
url: judge_url,//想请求什么资源
dataType: 'json',//告知服务端我需要说明格式
contentType: 'application/json;charset=utf-8',//我给你的是什么格式
data: JSON.stringify({
"code": code,
"input": ""
}),
success: function (data) {//成功的时候执行回调,匿名函数
//成功得到结果,写到data当中
//console.log(data);
show_result(data);
}
});
//3.得到结果,我们解析结果并显示到result中
function show_result(data) {
//里面肯定是json串,那么里面的字段我们怎么拿出来呢
//status reason 等等
//console.log(data.status);
//console.log(data.reason);//√
//拿到结果标签
var result_div = $(".container .part2 .result");
result_div.empty();//清空上一次的运行结果
//拿到结果的状态码和原因
var _status = data.status;
var _reason = data.reason;
var reason_lable = $("<p>", {
text: _reason
});
reason_lable.appendTo(result_div);
if (status == 0) {
//请求成功,但是结果是否正确看测试用例的结果
var _stdout = data.stdout;
var _stderr = data.stderr;
var stdout_lable = $("<pre>", {
text: _stdout
});
var stderr_lable = $("<pre>", {
text: _stderr
});
stdout_lable.appendTo(result_div);
stderr_lable.appendTo(result_div);
}
else {
//编译运行出错,我们只显示reason,do nothing
}
}
}
</script>
</body>
</html>
五、最终效果
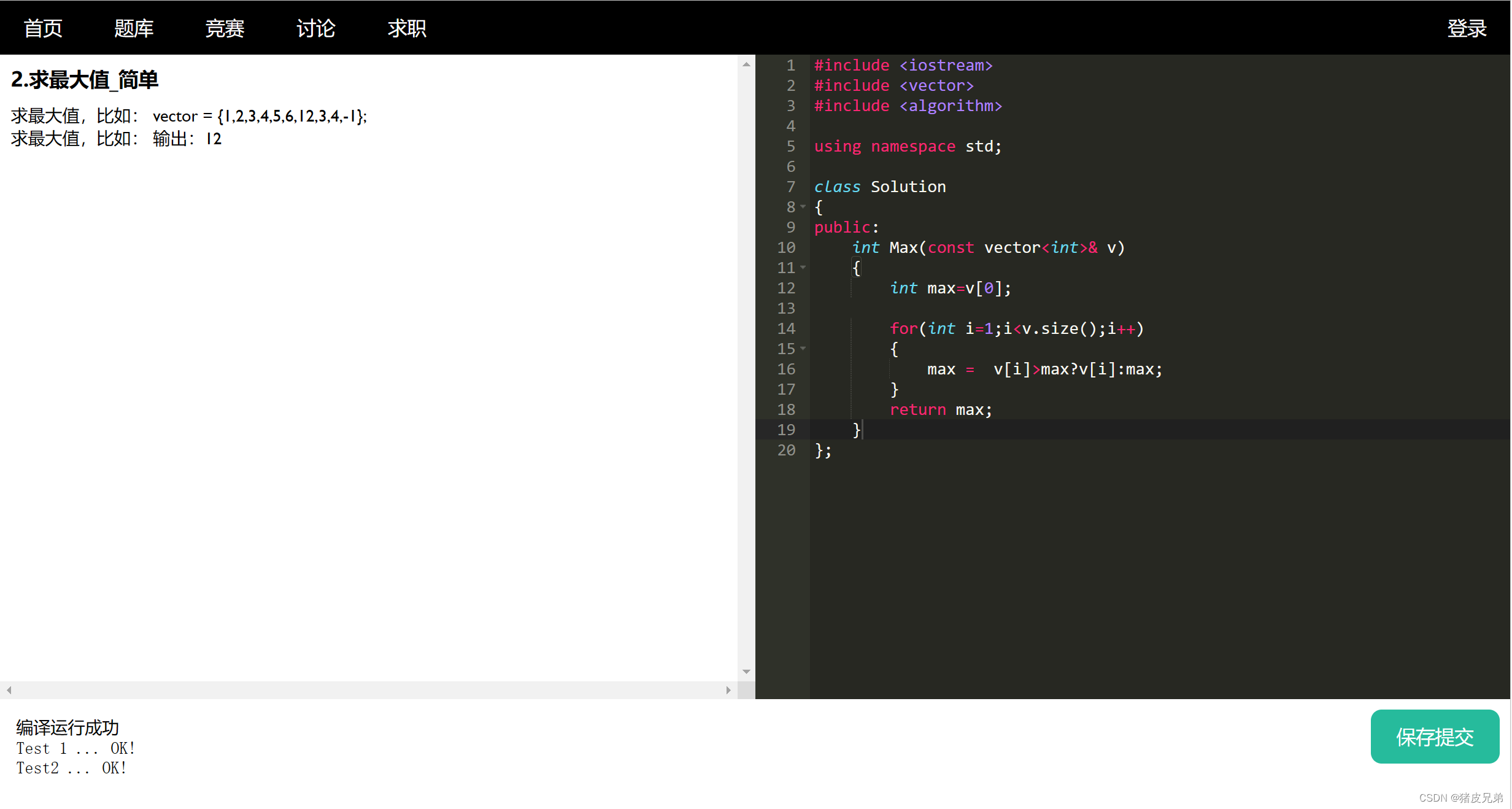
六、项目结项与扩展
项目亮点:
- STL标准库的使用
- Boost准标准库split字符串切割
- cpp-httplib的使用
- ctemplate进行网页渲染
- jsoncpp进行序列化和反序列化
- 负载均衡的设计
- 多线程多进程
- 锁的使用
- ACE插件,在线编辑器
- 前端html/js/css/jquery/ajax的使用等
项目扩展思路:
- 1.基于注册和登录的录题功能
- 2.业务扩展,比如我们保留出来的论坛,竞赛,求职等,接入到我们的在线oj当中
- 3.即便是便器服务在其他机器上,也其实不太安全。可以将编译服务部署自docker上。一旦挂掉,不会 影响操作系统
- 4.目前compiler编译运行服务使用的是http方式请求,因为简单,我们也可以把它设计成远程过程调用RPC,可以用它来替换我们的httplib的内容
- 5.其他
七、顶层makefile发布项目
我们的项目写好了之后,给别人用不是把代码给别人的,而是只需要把可执行文件和运行该程序需要的配置文件给用户就可以了。
对于顶层makefile,我们想完成3个任务
- 1.一键编译
- 2.一键发布
- 3.一件清除
.PHONY:all
all:
@cd compile_server;\
make;\
cd -;\
cd oj_server;\
make;\
cd -;\
.PHONY:output
output:
@mkdir -p output/compile_server;\
mkdir -p output/oj_server;\
cp -rf compile_server/compile_server output/compile_server;\
cp -rf compile_server/temp output/compile_server/;\
cp -rf oj_server/conf output/oj_server/;\
cp -rf oj_server/include output/oj_server/;\
cp -rf oj_server/lib output/oj_server/;\
cp -rf oj_server/questions output/oj_server/;\
cp -rf oj_server/template_html output/oj_server/;\
cp -rf oj_server/wwwroot output/oj_server/;\
cp -rf oj_server/oj_server output/oj_server/;\
.PHNOY:clean
clean:
@cd compile_server;\
make clean;\
cd -;\
cd oj_server;\
make clean;\
cd -;\
rm -rf output;\
\除了有转移的意思,还有续航的意思,代表这一坨东西都是一起的。然后@就是说在执行的时候不要显示这部分内容,默默执行就可以了,output中就是我们发布后给别人的文件,别人就可以直接使用
项目源码
Gitee:https://gitee.com/zhu-pi/zhupi-linux/tree/master/OnlineJudge


![[MYAQL / Mariadb] 数据库学习-数据导入导出](https://img-blog.csdnimg.cn/019f88f7a15746edb81eb54b4ca011a0.png)