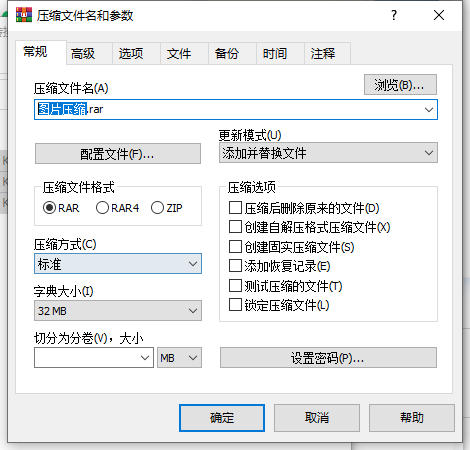
循环神经网络(RNN)是在其网络连接中包含循环的任何网络。也就是说,任何一个单元的值直接或间接依赖于作为输入的早期输出的网络。虽然这种网络很强大,但很难进行推理和训练。然而,在一般的循环网络中,有一些被证明在应用于口语和书面语时非常有效的约束架构。
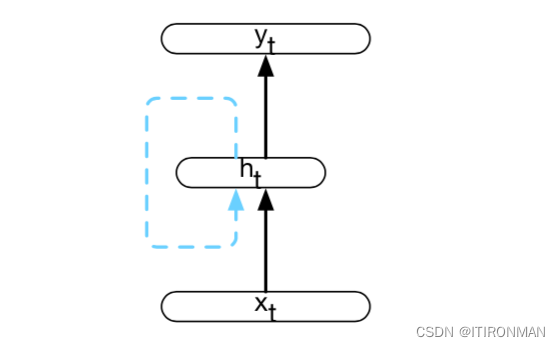
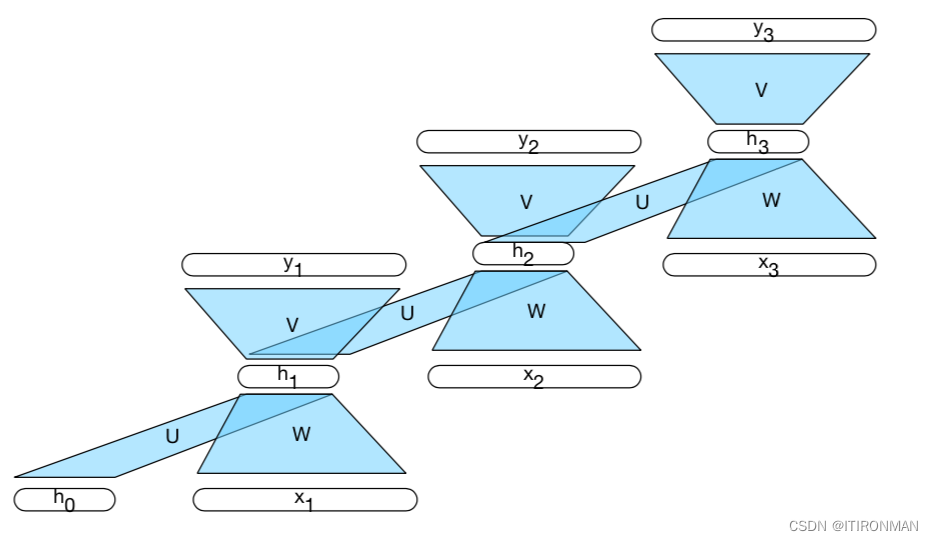
来自前一个时间步骤的隐藏层提供了一种形式的记忆或上下文,它对早期处理进行编码,并通知在稍后的时间点做出的决策。关键的是,这种体系结构并没有对这种先前的上下文施加固定的长度限制;前一个隐藏层中包含的上下文包括可追溯到序列开头的信息。添加这个时间维度可能会使rnn看起来比非循环架构更奇特。但实际上,它们并没有那么不同。给定一个输入向量和前一个时间步长的隐藏层的值,我们仍然执行标准的前馈计算。最重要的变化在于新的权重集U,它将隐藏层从前一个时间步长连接到当前隐藏层。这些权重决定了网络在计算当前输入的输出时应该如何利用过去的上下文。与网络中的其他权重一样,这些连接是通过反向传播来训练的。RNN中的前向推理(将输入序列映射到输出序列)几乎与我们已经看到的前馈网络相同。



1、训练
与前馈网络一样,我们将使用训练集、损失函数和反向传播来获得在这些循环网络中调整权重所需的梯度。
循环神经网络已被证明是语言建模、序列标记任务(如词性标记)以及序列分类任务(如情感分析和主题分类)的有效方法。它们构成了序列到序列的摘要、机器翻译和问答方法的基础。
2、循环神经网络语言模型
我们已经看到了两种创建概率语言模型的方法:N-gram模型和带滑动窗口的前馈网络。给定一个固定的上下文,两者都试图预测序列中的下一个单词。更正式地说,它们计算给定前面单词的序列中下一个单词的条件概率P(wn|wn−1)。
在这两种方法中,模型的质量在很大程度上取决于上下文的大小以及模型如何有效地利用它。因此,n-gram和滑动窗口神经网络都受到马尔可夫假设的约束,该假设体现在下面的等式中:

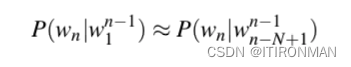
循环神经语言模型每次处理一个单词的序列,试图通过使用当前单词和前一个隐藏状态作为输入来预测序列中的下一个单词。因此,避免了N-gram模型和滑动窗口方法中固有的有限上下文约束,因为隐藏状态包含了所有前面单词的信息,一直追溯到序列的开头。循环语言模型中的前向推理在每一步中,网络检索当前单词的单词嵌入作为输入,并将其与前一步的隐藏层结合以计算新的隐藏层。然后使用这个隐藏层来生成一个输出层,该输出层通过softmax层来生成整个词汇表的概率分布。

为了训练这样的模型,我们使用具有代表性的文本语料库作为训练材料。任务是在给定前一个单词的序列中预测下一个单词,使用交叉熵作为损失函数。回想一下,单个示例的交叉熵损失是分配给正确类的负对数概率,这是对最终输出层应用softmax的结果。
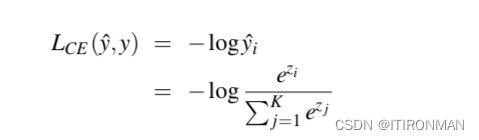
在这里,正确的类i是数据中实际出现的下一个单词,yi是分配给该单词的概率,softmax是在整个词汇表上,其大小为k。网络中的权重被调整为通过梯度下降最小化训练集上的交叉熵损失。
大致的流程如下:
•首先,从使用句子开头标记<s>作为第一个输入而产生的oftmaxdistribution的输出中采样第一个单词。
•将第一个单词的单词嵌入作为网络的输入下一个时间步骤,然后以同样的方式采样下一个单词。
•继续生成,直到句子结尾标记</s>被采样或达到固定长度限制。
3、序列标柱

在词性标注的RNN方法中,输入是词嵌入,输出是由标记集上的softmax层生成的标记概率。在这个图中,每个时间步的输入都是预训练的词嵌入,以响应输入令牌。RNN块是一个抽象,表示一个展开的简单循环网络,由每个时间步长的输入层、隐藏层和输出层组成,以及组成网络的共享U、V和W权重矩阵。网络在每个时间步长的输出表示由softmax层生成的POS标记集上的分布。
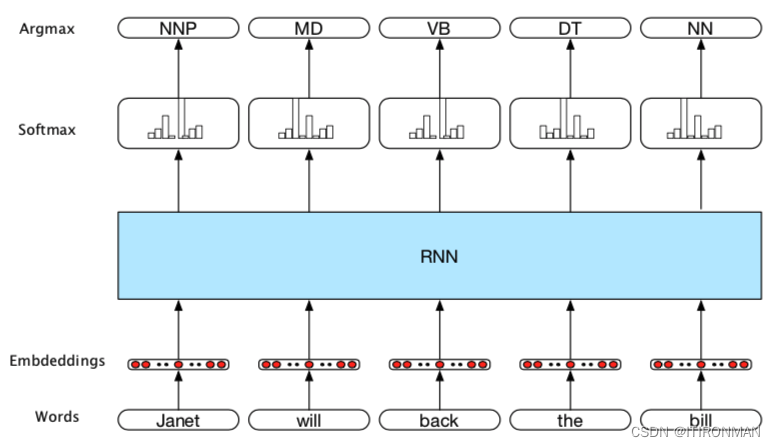
然后输入序列,并在每一步从softmax中选择最可能的标签。由于我们使用softmax层在每个时间步生成输出标记集的概率分布,因此我们将在训练期间再次使用交叉熵损失。序列标记的一个密切相关且非常有用的应用是查找和分类与某些任务域中感兴趣的概念相对应的文本范围。这种任务的一个例子是命名实体识别,即在文本中找到与人、地点或组织的名称相对应的所有跨度。为了在跨度识别问题中使用序列标记,我们将使用一种称为IOB编码的技术。
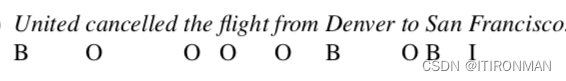
在我们对多个类别的实体感兴趣的应用程序中(例如,查找和区分人、地点或组织的名称),我们可以专门化B和I标签来表示每个更具体的类别,从而将标签集从3个标签扩展到2 * N + 1,其中N是我们感兴趣的类别的数量。 然后解码算法是维特比,今天讲的太多,后面专门讲这个算法细节。