1. InnoDB 是干嘛的?
InnoDB 是一个将表中的数据存储到磁盘上的存储引擎。
2. InnoDB 是如何读写数据的?
InnoDB 处理数据的过程是发生在内存中的,需要把磁盘中的数据加载到内存中,如果是处理写入或修改请求的话,还需要把内存中的内容刷新到磁盘上。
读写磁盘的速度非常慢,和内存读写差了几个数量级,所以当我们想从表中获取某些记录时,InnoDB 存储引擎将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB 中页的大小默认为 16 KB。也就是在一般情况下,一次最少从磁盘中读取 16KB 的内容到内存中,或者一次最少把内存中的 16KB 内容刷新到磁盘中。
所以当你用 postman 测试一个 HTTP 分页查询接口(每页 10 条数据)时,发现第一次打印耗时 300 ~ 400ms,往后不停的查找下一页 10 条数据时都是 30 ~ 40ms,原因就是第一次请求接口时,读数据库的时候需要读磁盘,从磁盘加载 16KB 的数据到内存,往后 HTTP 请求每次查 10 条数据的时候都是从内存中获取,没有再读磁盘,除非在内存中的 16KB 的数据中找不到,才会再次读磁盘获取下一个 16KB 的数据到内存中。(我们不讨论 mysql 8.0 舍弃的查询缓存特性,我测试过 mysql 5.7 中关闭了查询缓存,也仍然是第一次慢,后续查询很快,查询时间相差大概 10 倍的样子)
温馨提示:分页查询和数据库的一页 16KB 中的 "页" 是两个概念。
总结:由于磁盘 I/O 速度相对内存来说较慢,因此第一次查询可能会比较耗时。一旦数据被加载到内存中,后续的查询就可以直接从内存中读取数据,这样的速度要比从磁盘读取数据快得多。这就解释了为什么第一次查询可能会比后续的查询慢。
查看磁盘和内存之间进行数据交换的页有多大

注意:innodb_page_size 变量在服务器运行过程中不可以更改,只能在第一次初始化 MySQL 数据目录时指定。所以页在运行时的大小不可更改。
3. varchar 疑问千千万 ——InnoDB 行格式
看到这里,你一定有着和我相同的疑问,比如 varchar (255) 后面这个最大长度应该怎么选择呢?为什么不能 varchar (65535) 而最大只能 varchar (16383) 呢?我来带你看!
我们平时是以记录为单位来向表中插入数据的,这些记录在磁盘上的存放方式也被称为行格式或者记录格式。行格式有 4 种,分别是 Dynamic、Compact、Redundant 和 Compressed
MySQL 5 + 默认行格式都是 Dynamic, 在 MySQL 5 和 MySQL 8 经过验证确实是的。
SHOW VARIABLES LIKE "innodb_default_row_format"
大家在业务中和平时使用中都几乎没有修改过或者注意过 InnoDB 行格式,那么我就只重点讲默认行格式 dynamic,让大家更深层次理解平时开发中的 varchar。
请记住这个表结构,后面会围绕这个来讲
CREATE TABLE test (
c1 VARCHAR(10),
c2 VARCHAR(10) NOT NULL,
c3 CHAR(10),
c4 VARCHAR(10)) CHARSET = utf8mb4;现在业务数据库字符集都是 utf8mb4,我就以这个来讲,把理解难度降到最低。
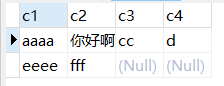
INSERT INTO test ( c1, c2, c3, c4 )
VALUES('aaaa', '你好啊', 'cc', 'd'),('eeee', 'fff', NULL, NULL);现在,表中的记录就是这样
3.1 dynamic——innodb 默认行格式
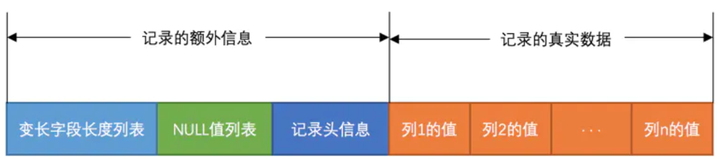
关于记录的额外信息这部分,是服务器为了描述这条记录而不得不额外添加的一些信息,这些额外信息分为 3 类,分别是变长字段长度列表、NULL 值列表和记录头信息。
在这里我只讲变长字段长度列表、NULL 值列表。因为记录头信息非常的绕和本篇没多大关系。
3.2 innodb 怎么知道 varchar 真正有多长?—— 变长字段长度列表
一些变长的数据类型,比如 VARCHAR (M)、各种 TEXT 类型,各种 BLOB 类型,变长数据类型的字段中存储多少字节的数据是不固定的,在存储真实数据的时候需要把这些数据占用的字节数也存起来。
就像设计 String 类型,不仅仅是存放真实数据的 char 数组,还有 length 变量去记录字符串长度。又比如 input 输入框最大限制 500 字,但是你还得有一个变量去统计真实在输入框内有多少字符。同理,varchar 也有记录真实数据长度的变量(假设为 L,后文沿用方便描述),L 表示 varchar 真实占用的字节数,innodb 最多分配 2 个字节去表示这个 L,就像 unsigned short 类型,2 个字节,寄存器最多只有 16 位来让你存这个长度,所以 L 记录范围是 2^16 - 1 = 65535。
这些变长字段 (比如 varchar) 占用的存储空间分为两部分:
- 真正的数据内容部分,放在对应的列
- 真实占用的字节数,放在变长字段列表部分
我们拿 test 表中的第一条记录来举个例子。因为 test 表的 c1、c2、c4 列都是 VARCHAR (10) 类型的,说明最大 10 个字符,所以这三个列的值的长度都需要保存在记录开头处,因为 test 表中的各个列都使用的是 utf8mb4 字符集,每个字符最大需要 4 个字节来进行编码(不使用 utf8 而是 utf8mb4 是因为可能存储 emoji 表情,如果只是文字,utf8 就足够),来看一下第一条记录各变长字段内容的长度:
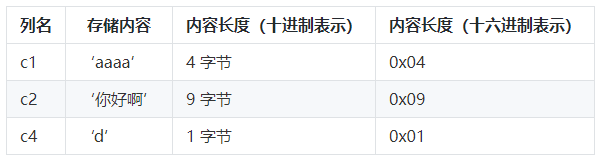
怎么确定这些字段有多少字节?
比如这里 c2 的 "你好啊",使用如下 sql 可以确定
SELECT LENGTH(c2) from test where c1='aaaa';

各变长字段数据占用的字节数按照列的顺序逆序存放!!
由于第一行记录中 c1、c2、c4 列中的字符串都比较短,也就是说 varchar 真实占用的字节数比较小,L 用 1 个字节 (8 个 bit 位) 就可以表示,但是如果 varchar 真实占用的字节数比较多,L 可能就需要用 2 个字节 (16 个 bit 位) 来表示。到底 varchar 能存多少字节呢?继续往下看。
3.3 varchar (M) 能存多少个字符,为什么提示最大 16383?
首先要理解 varchar (M) 的 M 是说字符个数,而不是字节。
为什么不能 varchar (20000) 之类的,是 20000 个字符放不下吗?
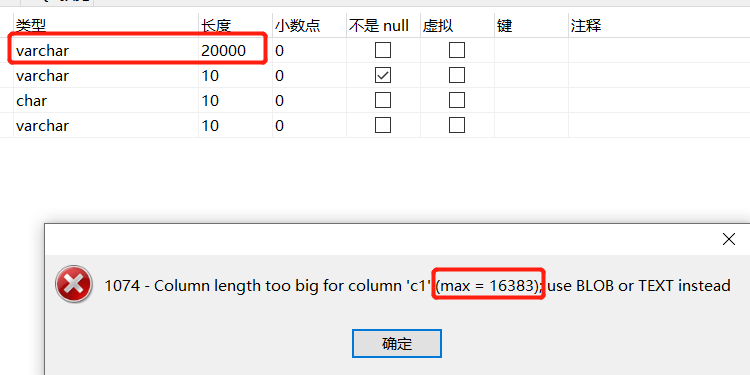
为什么提示只能最大 16383 个字符呢?这个数字是怎么算出来的?
这个我就得和你好好唠嗑了!
varchar 是变长的,varchar(64) 能存放 0~64 个字符不等,并不一定是存了最大 64 个字符,谁知道这个类型到底存了几个字符呢?innodb 设计的时候,就已经考虑到了,不过是用字节作为单位,后续我们可以根据对应字符集转变为字符来理解,innodb 必须记录变长字段 varchar 真实占用的字节数 L。前面说过了,innodb 最多分配 2 个字节 (16 个 bit 位) 的空间去记录这个 L。
InnoDB 有它的一套规则,我们引入 W、M 和 L 这几个符号:
1. 假设某个字符集中最多需要 W 字节来表示一个字符
- utf8mb4 字符集中的 W 就是 4
- utf8 字符集中 W 就是 3
- gbk 字符集中的 W 就是 2
- ascii 字符集中的 W 就是 1。
2. 对于变长类型 VARCHAR (M) 来说,这种类型表示能存储最多 M 个字符(注意是字符不是字节)
所以这个类型能表示的字符串最多占用的字节数就是 M × W。
3. 假设它实际存储的字符串占用的字节数是 L。
来看极限边界情况,innodb 为了记录一下 varchar 真实存储多少个字节,最多分配 2 个字节的空间去记录,2 个字节 16 个比特位,全部为 1,最大能记录的数字是 2^16-1 是 65535 个,innodb 最大能记录 varchar 占用的字节数就是 65535 个,utf8mb4 字符集一个字符是最大是 4 个字节,65535 / 4 = 16383.75,只要 varchar 字符数不超过 16383 个,innodb 就可以记录真实占用的长度 L,再多就记录不了了!所以就能解释刚刚的图了,varchar (20000) 不行,最大也就 16383 个字符
但是!这里强调是有但是的!
行最大长度是 65535 字节,行里面有很多东西,包括变长字段列表、NULL 值列表、记录头信息。你得考虑该字段如果允许为 NULL,NULL 值列表会占用一个字节 (只要没超过 8 个字段),每一列字段的变长字段实际长度会花费 1~2 个字节,如果该字段的数据太大,会变成溢出列,该字段的数据会分成很多行存储(后面会讲,你可以看完 NULL 值列表和溢出列后再回来看这个例子)。所以即便提示 16383 个字符,你也绝对不可能存到 16383。
我做了个测试
create table t2 ( name varchar(16383))charset=utf8mb4;
不断往这个字段添加字符保存测试,最后发现,这些字符总长度到极限也就是 48545 字节。
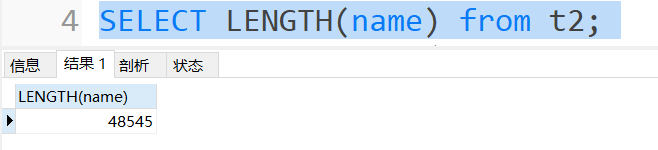
如果超过就会报错
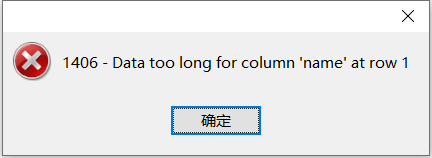
这里 48545 个字节,再多一个字符就会报错,远不到 65535 字节,差了 1W 多字节。主要是因为溢出列的原因,数据分散在不同的行中,所以,很长的数据,建议往 text 类型考虑。这个现象可以看出,varchar (M) 的 M 很大,实际是达不到 M 这个边界值的。
我使用的是英文字母测试而不是中文字符,大部分不是 4 字节的,所以能够存储更多的字符。如果考虑到额外的元数据,实际能够存储的 VARCHAR 字符数会更少,关于影响每行的实际可用空间有哪些因素,请接着往下看后面小节。
下面说明一下规则 (讲解中字符集用 utf8mb4,W=4)
规则一:如果允许存储的最大字节数 M × W <= 255,varchar 占用的真实字节数 L 只分配 1 个字节来表示。
有人说,允许存储的最大字节数 M × W <= 255,即允许存储的最大字符数 <= ⌊255 / 4⌋ = 63 个时,varchar 占用的真实字节数 L 仅分配 1 个字节就能表示。这个结论正确吗?
显然错误,因为这里 255 / 4,你怎么知道每个存储的一个字符是 4 个字节呢?难道全部存的 emoji 表情?不存字母汉字啥的?
实际上不是所有的字符都会占用 W 个字节。例如,在 utf8mb4 字符集中,一个英文字母只占用 1 个字节,而一个 emoji 表情符号会占用 4 个字节。因此,“最多 M 个字符” 并不意味着总是需要 M × W 个字节。
InnoDB 在读记录的变长字段长度列表时先查看表结构,如果某个变长字段允许存储的最大字节数不大于 255 时,只用 1 个字节来表示真实数据占用的字节。
规则二:如果允许存储的最大字节数 M × W > 255,则分为两种情况:
如果实际存储字节 L <= 127,varchar 占用的真实字节数 L 仅分配 1 个字节就能表示。(⌊ … ⌋表示向下取整)
有人说,实际存储字节 L <= 127,即实际存储字符 <= ⌊127 / 4⌋ = 31 个时,varchar 占用的真实字节数 L 仅分配 1 个字节就能表示。这个结论正确吗?
还是错误,道理和上面一样。
如果实际存储字节 L > 127,varchar 占用的真实字节数 L 需要分配 2 个字节才能表示。
另外需要注意的是,变长字段列表只存储非 NULL 的列的长度。
表记录是这样的
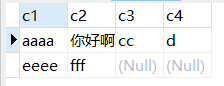
对于第二条记录,c4 列值为 NULL,所以只存储 c1 和 c2 列即可。
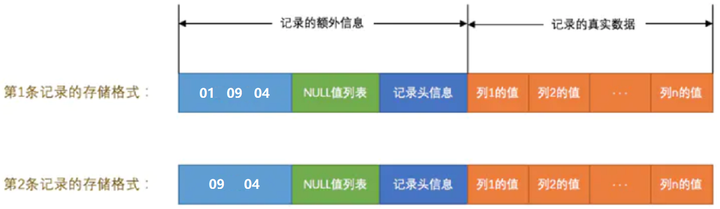
第一条记录的变长字段长度列表部分占用 3 字节空间,因为有 c1、c2、c4 列,且内容都很少,每列真实占用字节数用 1 个字节可以表示,加起来就是 3 个字节,第二条记录变长字段长度列表部分占用 2 字节。
当然,并不是所有记录都有这个变长字段长度列表部分,比方说表中所有的列都不是变长的数据类型或者 所有列的值都是 NULL 的话,这一部分就不需要有。实际业务开发中,几乎没有不使用 varchar 的,所以实际开发中的记录都会有变长字段长度列表部分
3.4 记录为 NULL,innodb 如何处理?——NULL 值列表
能仔细看到这里,你肯定是个高手了。如果你和我一样开发规范中不推荐 NULL,一般都写 NOT NULL,其实记录中就不存在 NULL 值列表了,也节省了空间。
如果表中的某些列可能存储 NULL 值,把这些 NULL 值都放到记录的真实数据中存储会很占地方,所以 dynamic 行格式把这些值为 NULL 的列统一管理起来,存储到 NULL 值列表中,它的处理过程是这样的:
1. 统计表中允许存储 NULL 的列有哪些。
主键列、被 NOT NULL 修饰的列都是不可以存储 NULL 值的,所以在统计的时候不会把这些列算进去。比方说表 test 的 3 个列 c1、c3、c4 都是允许存储 NULL 值的,而 c2 列是被 NOT NULL 修饰,不允许存储 NULL 值。
2. 如果表中没有允许存储 NULL 的列,则 NULL 值列表也不存在了,否则将每个允许存储 NULL 的列对应一个二进制位,二进制位按照列的顺序逆序排列。二进制位的值为 1 时,代表该列的值为 NULL,为 0 时,代表该列的值不为 NULL。因为表 test 的 c1、c3、c4 都是允许存储 NULL 值的允许为 NULL 的列,所以这 3 个列和二进制位的对应关系就是这样:
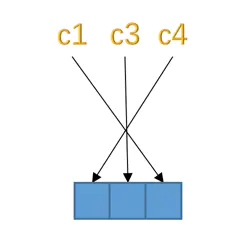
3.NULL 值列表必须用整数个字节的位表示,如果使用的二进制位个数不是整数个字节,则在字节的高位补 0。
也就是说,表 test 只有 3 个字段允许为 NULL,对应 3 个二进制位,不足 1 字节,那么就在高位补 0 即可。
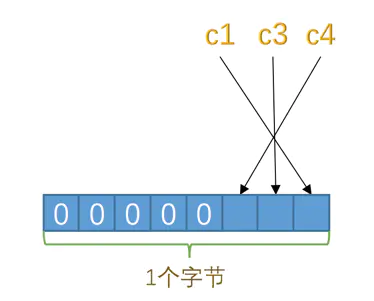
以此类推,如果表中有 9 个字段都允许为 NULL,那么这个记录的 NULL 值列表就需要 2 个字节来表示,高字节高位补 0。
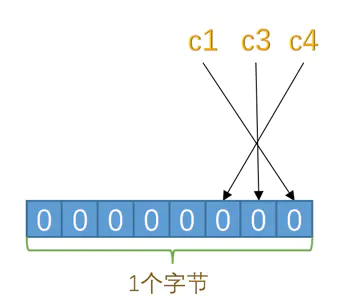
对于第一条记录,c1、c3、c4 都不为 NULL,对应的为进制位为 0,十六进制表示就是 0x00
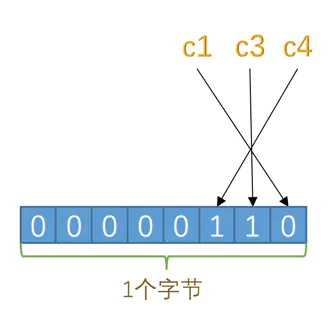
对于第二条记录,c3、c4 都是 NULL,对应的二进制位为 1,十六进制表示就是 0x06
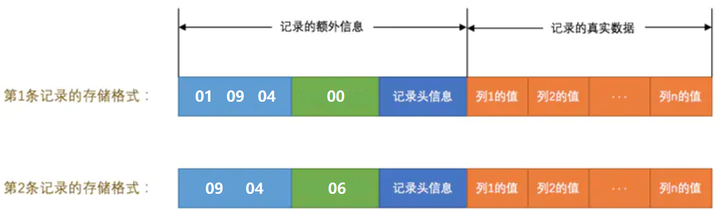
这两条记录在填充了 NULL 值列表后示意图如下:
3.5 为什么 varchar (16383) 存不到理论字符 16383,影响每行实际可用空间的因素有哪些?
在 utf8mb4 字符集下,VARCHAR (16383) 代表的是最多可以存储 16383 个字符。由于 utf8mb4 编码下,一个字符最多占用 4 个字节,所以理论上 VARCHAR (16383) 最多可以占用 16383 * 4 = 65532 字节。但是还需要考虑到 InnoDB 的元数据和内部碎片等空间,由于这些额外的开销,无法在一个 VARCHAR (16383) 字段中存储 16383 个字符。
内部碎片:内部碎片主要是由于数据库页(Page)或块(Block)的固定大小导致的。InnoDB 的页大小通常设置为 16KB,每一页中包含了多行数据以及额外的页级元数据。如果一页中的数据没有完全填满这个空间,那么剩余的空间就会成为内部碎片,不能被其他行使用。
内部碎片通常在以下情况中出现:
- 固定大小的数据页 / 块:数据库通常使用固定大小的数据页(例如,在 InnoDB 中,页的大小通常为 16KB)来存储数据。如果一页中的数据没有完全填满这个空间,剩下的空间就会成为内部碎片。
- 数据更新:当一个字段的值被更新为一个更小的值时,剩下的空间可能会成为内部碎片。数据库可能会保留这个空间,以便在未来这个字段的值再次增大时使用。
- 预留空间:为了提高性能,数据库可能会预留一些空间,使得数据的插入和更新操作不需要立即重新分配空间。这些预留的空间也会成为内部碎片。
举个例子:
我们创建一个包含 VARCHAR 字段的表:
CREATE TABLE test (
id INT AUTO_INCREMENT PRIMARY KEY,
data VARCHAR(100)
);然后我们插入一行数据,其中 data 字段填充了 100 个字符:
INSERT INTO test (data) VALUES (REPEAT('a', 100));接下来我们更新这行数据,将 data 字段的值改为只有 10 个字符:
UPDATE test SET data = REPEAT('a', 10) WHERE id = 1;在这个例子中,当我们更新 data 字段的值时,原来占用的 100 个字符的空间并不会立即被收缩,即使新的值只有 10 个字符。这就产生了内部碎片,即那些不再使用但还未被回收的空间。
这种内部碎片化的影响在实际操作中可能并不那么明显,因为数据库系统会尽可能地重用这些空间。如果后续有新的数据需要更多的空间,这些内部碎片的空间就可能会被利用起来。但是如果后续数据主要进行读操作而很少进行写操作的情况下,内部碎片可能会成为影响数据库性能的一个因素。
假设我们有一个包含大量数据的表,这个表目前主要进行读操作,而写操作则相对较少。如果这个表存在大量的内部碎片化(可能是由过去的写操作留下的,例如更新和删除),那么实际存储的数据可能只占用了可用空间的一小部分,大量的空间被内部碎片占用。这种情况下,数据库需要加载更多的页到内存中来获取相同量的数据,这会增加 I/O 操作,从而降低读操作的性能。
除了内部碎片之外,影响每行实际可用空间的其他因素可能包括以下几个:
- 元数据:前文已经介绍,每行的元数据(包括记录头信息、NULL 值列表和变长字段长度列表)都会占用一部分空间。
- 行格式:InnoDB 的行格式(COMPACT,DYNAMIC 或 REDUNDANT)会影响每行的实际可用空间。例如,COMPACT 格式会更紧凑,因此可能会提供更多的可用空间。
- 溢出页:对于非常大的字段(如 BLOB 和 TEXT 类型),InnoDB 可能会将数据存储在单独的溢出页中,而不是直接在数据行中。这可以使得数据行保持较小的大小,但也会增加存储和检索这些字段的复杂性。
以下是一些主要的元数据:
- 记录头信息:每一行记录在 InnoDB 中都有一个记录头,包含了一些元数据,如记录类型、下一个记录的位置等。记录头的大小通常为 5-7 字节。
- NULL 值列表:如果表中的字段允许 NULL 值,InnoDB 会为每一行记录维护一个 NULL 值列表,用于标记哪些字段的值为 NULL。每一个可以为 NULL 的字段会在这个列表中占用 1 位(不是 1 字节)。所以,如果有 n 个字段可以为 NULL,那么 NULL 值列表就需要 n 位,即⌈n/8⌉字节(向上取整)。
- 变长字段长度列表:对于变长字段(如 VARCHAR、VARBINARY、TEXT 和 BLOB 类型),InnoDB 需要存储每个字段实际值的长度。如果字段的最大可能长度不超过 255 字节,那么这个长度值会占用 1 个字节;如果字段的最大可能长度超过 255 字节,那么长度值可能会占用 1 个字节(如果实际长度不超过 127 字节)或 2 个字节(如果实际长度超过 127 字节)。
通常来说,内部碎片和元数据可能会对每行的实际可用空间产生最大的影响。
注意:CHAR 类型和 VARCHAR 类型在元数据和内部碎片方面有些不同:
- 元数据:由于 CHAR 类型是固定长度的,所以它不需要像 VARCHAR 类型那样存储额外的元数据来表示实际的长度。这意味着对于同样长度的字符串,CHAR 类型会使用更少的空间来存储元数据。
- 内部碎片:CHAR 类型由于是固定长度的,可能会产生内部碎片。比如,如果定义了一个 CHAR (100) 字段,但实际上只存储了 10 个字符的字符串,那么剩下的 90 个字符的空间就会被浪费,这就是内部碎片。另一方面,VARCHAR 类型只会使用实际所需的空间,因此内部碎片会较少。
所以,尽管 CHAR 类型不需要存储长度的元数据,但它可能会因为固定长度的特性而产生更多的内部碎片。
在 MySQL 中,任何类型的列都可以被声明为 NULL 或 NOT NULL,所以 CHAR 类型也可以有 NULL 值列表。
3.6 某个列数据占用的字节数非常多怎么办?——dynamic 行格式的溢出列
在 MySQL 5.7 及之后的版本中,默认的行格式是 DYNAMIC。在 DYNAMIC 行格式中,如果一个字段的大小超过了页面的可用空间,该字段就会被存储为溢出列。
这里是一个例子:
CREATE TABLE `big_data` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`data` longblob,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC;在这个表中,data 列的类型是 longblob,这意味着它可以存储的数据长度最大达到 4GB。如果你插入一个大于 16KB 的数据到这个表,那么 data 列的数据就会被作为溢出列处理。
INSERT INTO big_data (data) VALUES (REPEAT('a', 17000));在这个例子中,插入的数据长度超过了 16KB,所以 data 列的数据会被作为溢出列处理。在原始的表中,data 列只会存储一个 20 字节的指针,这个指针指向实际数据的存储位置。
这样的设计可以确保每个页内的数据都保持在合理的大小范围内,避免了由于单个字段数据过大导致的页分裂等问题,从而提高了整体的存储效率和查询性能。同时,对于读取溢出列的数据,虽然可能需要额外的磁盘 I/O,但只要数据的访问是顺序的,通常这个开销并不会太大。