概述
LF Edge eKuiper 是 Golang 实现的轻量级物联网边缘分析、流式处理开源软件,可以运行在各类资源受限的边缘设备上。eKuiper 的主要目标是在边缘端提供一个流媒体软件框架。其规则引擎允许用户提供基于SQL 或基于图形(类似于 Node-RED)的规则,在几分钟内创建物联网边缘分析应用。
本文中,我们将以源码为脉络,阐述一条 SQL 从被 eKuiper 接收后,是如何从一条文本变成一个可执行的处理过程。通过本文,你可以了解到以下内容:
- 一个 SQL 计算引擎基本的处理流程
- eKuiper 在每个处理流程中的具体代码节点
准备
为了更加直观地了解到 eKuiper 内部的代码运行逻辑,在讲解 eKuiper 规则引擎的处理过程中,我们会涉及到 eKuiper 中的一部分代码,并对其中的关键部分进行较为详细的讲解。
为了更好地理解之后的内容,你需要了解:
- eKuiper 项目:https://github.com/lf-edge/ekuiper
- Golang 的基础用法
框架
从 eKuiper 接收到 SQL 的文本,到最终根据这个 SQL 的语义去做出相应的读取与计算工作。eKuiper 内部的 SQL 计算引擎在其中承担了解析、构造、优化与运行这总共 4 部分工作,即我们之后将重点关注 SQL 处理过程中的以下几个环节:
- SQL Parser 将 SQL 文本转换为 AST 对象
- 基于 AST 对象生成逻辑计划
- 优化逻辑计划并生成执行算子
- 运行执行算子,开始读取数据与计算并最终将结果写入到下游
从 SQL 文本到执行算子树
从这一节开始,我们将开始根据 eKuiper 中的代码节点,来理解一条 SQL 文本是如何一步步被最终转换为一个可以被实际执行的算子树。
以下代码实际展示了 eKuiper 代码中解析文本、优化计划、构造执行算子这几个处理流程,我们将一一进行展开了解。
func PlanSQLWithSourcesAndSinks(rule *api.Rule, sources []*node.SourceNode, sinks []*node.SinkNode) (*topo.Topo, error) {
sql := rule.Sql
conf.Log.Infof("Init rule with options %+v", rule.Options)
stmt, err := xsql.GetStatementFromSql(sql)
if err != nil {
return nil, err
}
......
// Create logical plan and optimize. Logical plans are a linked list
lp, err := createLogicalPlan(stmt, rule.Options, store)
if err != nil {
return nil, err
}
tp, err := createTopo(rule, lp, sources, sinks, streamsFromStmt)
if err != nil {
return nil, err
}
return tp, nil
}
解析 SQL 文本
通过以下函数,我们将一个 SQL 文本解析为了 AST 对象
func GetStatementFromSql(sql string) (*ast.SelectStatement, error) {
本文中我们暂时先不涉及 SQL 解析器中的具体实现细节,相关内容将在之后的 eKuiper 源码阅读中进行讲解。感兴趣的朋友可以通过以下函数作为入口进行了解:
func (p *Parser) Parse() (*ast.SelectStatement, error) {
值得一提的是,在 SQL Parser的具体实现上,也有一些其他 well-known 的数据库实现使用了 yacc 的方案来直接生成 SQL Parser。eKuiper 之所以选择自己实现 SQL Parser,一个非常重要的原因是对于一个运行在边缘端的应用而言,binary size 是一个非常重要的指标。自己实现 SQL Parser 而非使用 yacc 这类的 Parser Generator 的技术,有助于控制和降低 eKuiper 编译后整体的 binary size 的大小。
构造与优化逻辑计划
当 SQL 文本还解析为 AST 对象后,我们需要将该 AST 对象转换为一个可以用来描述该 SQL 应当被计算引擎如何执行的逻辑计划。这一步骤被封装在了以下代码函数入口中:
func createLogicalPlan(stmt *ast.SelectStatement, opt *api.RuleOption, store kv.KeyValue) (LogicalPlan, error) {
在 createLogicalPlan 函数中,它接收一个 AST 树对象,并返还一个逻辑计划树对象,在整个函数过程中,它总共做了以下 3 件事情:
- 抽取 SQL 中的各类信息,并将其与实际的表达式或者是 schema 信息进行绑定。
- 根据 AST 对象构造最初的逻辑计划。
- 根据最初的逻辑计划进行逻辑优化。
在一条 SQL 中,它所带的信息里包含了一些原本注册计算引擎中的信息,比如流、表的定义,也包含了一些临时声明的信息,比如列或者表达式的 alias name。在以下代码函数入口中,eKuiper 会从 AST 树对象中抽取出以下信息,并进行响应的绑定:
func decorateStmt(s *ast.SelectStatement, store kv.KeyValue) ([]streamInfo, []*ast.Call, error) {
- 从 AST 树对象中抽取出流与表的 AST 对象,并从 eKuiper 的存储中取出预先设置好的流、表的定义,并将这些 schema 信息绑定到 ast 对象中。
- 从 AST 对象中将查询中的 filed 与各个流、表进行绑定
当我们处理好 AST 树对象中的各个节点的信息绑定后,我们就可以根据 AST 树对象来构造一个最初的逻辑计划。以下代码显示了在 eKuiper 中是如何根据自底向上的构建逻辑计划。从最底层的 DataSource 算子,一路向上 build 逻辑算子,直至整个逻辑算子树构造完毕。
func createLogicalPlan(stmt *ast.SelectStatement, opt *api.RuleOption, store kv.KeyValue) (LogicalPlan, error) {
// 1. build Datasource
// 2. build Window
// 3. Buld JoinAlign / Join
// 4. Build Filter
// 5. Build Agg
// 6. Build Having
// 7. Build Sort
// 8. Build Proj
}
当我们获得了最原始的逻辑计划树以后,我们需要对逻辑计划进行逻辑优化。逻辑优化阶段会对原本的计划进行优化。逻辑优化阶段,简单来说就是对一个逻辑算子树进行等价的变换,这个变换并不会影响最终的计算结果,但是可以让计算过程减少更多不必要的计算量。
举一个简单的例子,对于 select * from t1 join t2 on [t1.](http://t1.id)a = t2.a where t1.b > 10 这条 SQL 来说,其原本的逻辑计划如下:
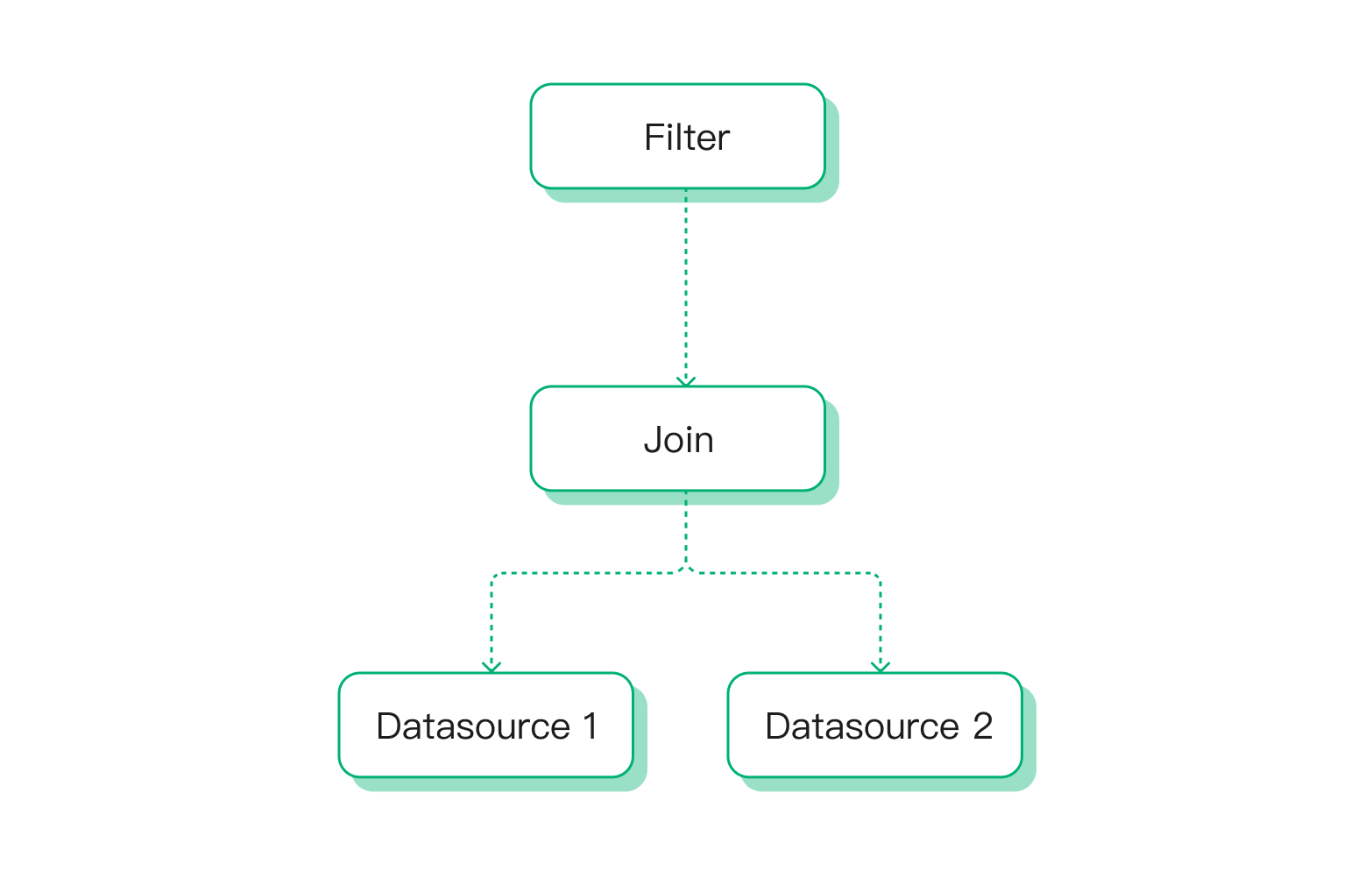
然后在逻辑优化阶段,我们可以将 Filter 算子进行下推至 Join 算子之下,从而让参与 Join 算子的数据量被提前过滤一部分,来减少整个计算过程中所涉及到的计算量。
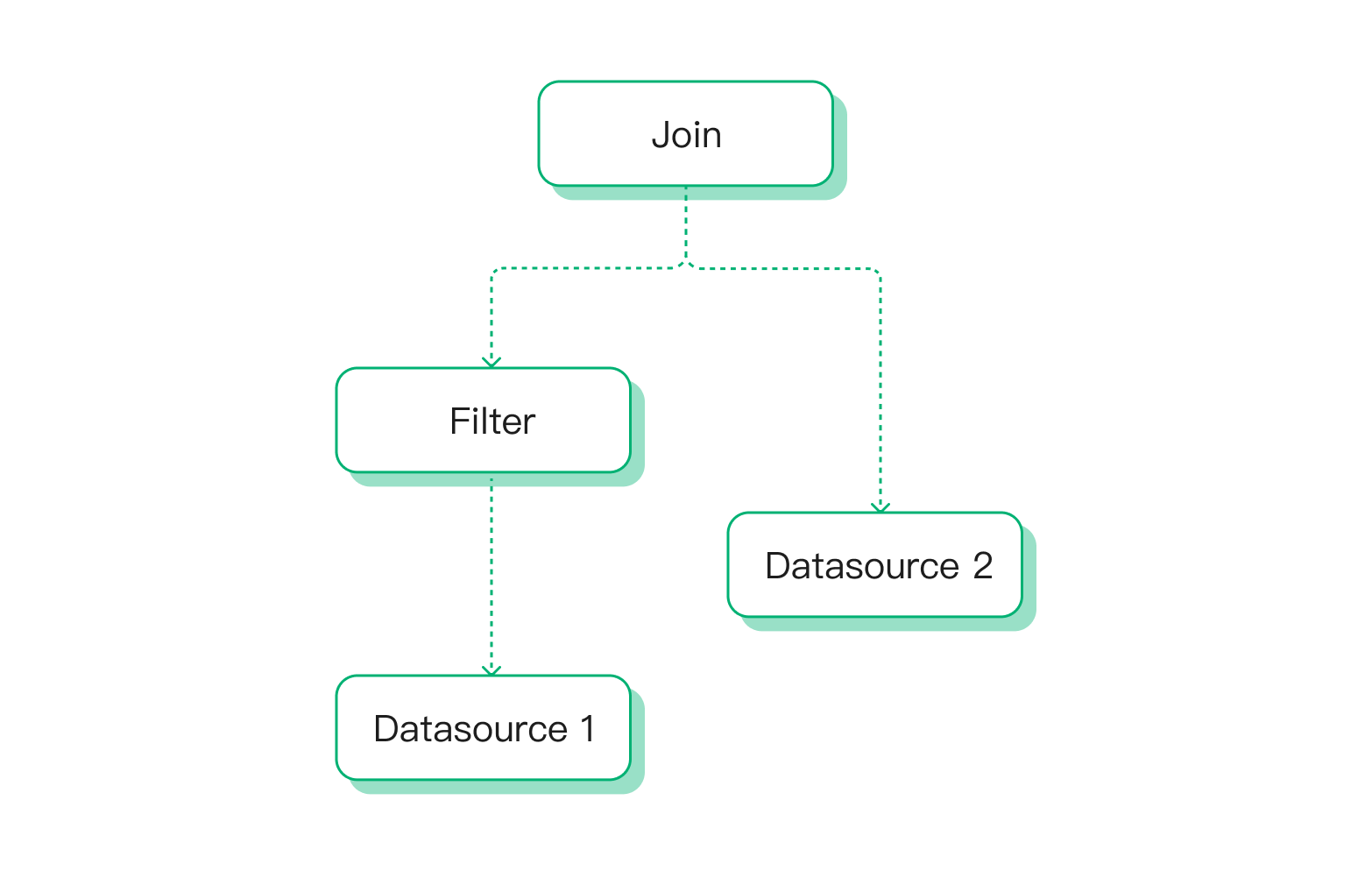
以下代码展示了 eKuiper 中是如何进行逻辑优化的:
var optRuleList = []logicalOptRule{
&columnPruner{},
&predicatePushDown{},
}
func optimize(p LogicalPlan) (LogicalPlan, error) {
var err error
for _, rule := range optRuleList {
p, err = rule.optimize(p)
if err != nil {
return nil, err
}
}
return p, err
}
在随后的系列当中我们会比较详细地介绍目前 eKuiper 中的逻辑优化环节中的代码细节。
当我们的逻辑计划优化完毕以后,我们需要根据逻辑计划来构造具体的执行算子。在 eKuiper 中,我们通过 Topo 结构来维护整个执行算子的上下文环境。
以下代码展示了构建执行算子的函数入口:
func createTopo(rule *api.Rule, lp LogicalPlan, sources []*node.SourceNode, sinks []*node.SinkNode, streamsFromStmt []string) (*topo.Topo, error) {
type Topo struct {
......
sources []node.DataSourceNode
sinks []*node.SinkNode
ops []node.OperatorNode
......
}
Topo 作为执行算子 Context,会将逻辑计划中的 DataSource 算子放在 sources 中,将其他算子放在 ops 中,而最终的 SQL 结果会汇总到 sinks 中。 在这里我们重点关注算子是如何构造的:
以下代码展示了 eKuiper 中是如何根据逻辑算子构造执行算子的:
func buildOps(lp LogicalPlan, tp *topo.Topo, options *api.RuleOption, sources []*node.SourceNode, streamsFromStmt []string, index int) (api.Emitter, int, error) {
var inputs []api.Emitter
newIndex := index
for _, c := range lp.Children() {
input, ni, err := buildOps(c, tp, options, sources, streamsFromStmt, newIndex)
.......
}
......
switch t := lp.(type) {
case *DataSourcePlan:
isSchemaless := t.isSchemaless
switch t.streamStmt.StreamType {
case ast.TypeStream:
......
op = srcNode
......
case *ProjectPlan:
op = Transform(&operator.ProjectOp{ColNames: t.colNames, AliasNames: t.aliasNames, AliasFields: t.aliasFields, ExprFields: t.exprFields, IsAggregate: t.isAggregate, AllWildcard: t.allWildcard, WildcardEmitters: t.wildcardEmitters, ExprNames: t.exprNames, SendMeta: t.sendMeta}, fmt.Sprintf("%d_project", newIndex), options)
default:
return nil, 0, fmt.Errorf("unknown logical plan %v", t)
}
......
if onode, ok := op.(node.OperatorNode); ok {
tp.AddOperator(inputs, onode)
}
return op, newIndex, nil
}
在构造算子的过程中,我们主要关注 2 个问题:
- buildOps 是如何遍历整个逻辑算子树,将每个逻辑算子转换为执行算子
- buildOps 是如何串联起整个执行算子的树形结构,将下层算子的 Ouput 结果传递给上层算子的 Input 来源。
在 buildOps 过程中,通过递归的方式,以自底向上的方式遍历整个逻辑算子树来构造执行算子。当下层算子构造完毕以后,我们在以下代码中会将下层算子的 Ouput 作为结果参数传递给上层算子的构造过程中,将下层算子的 Output 和上层算子的 Input 连接起来
if onode, ok := op.(node.OperatorNode); ok {
tp.AddOperator(inputs, onode)
}
当执行算子树被创建完毕以后,我们会将顶层算子的 Output 和这条 SQL 的 sink 连接起来,从而使得 eKuiper 会将 SQL 计算的结果写入到下游的 sink 中。
func createTopo(rule *api.Rule, lp LogicalPlan, sources []*node.SourceNode, sinks []*node.SinkNode, streamsFromStmt []string) (*topo.Topo, error) {
......
input, _, err := buildOps(lp, tp, rule.Options, sources, streamsFromStmt, 0)
if err != nil {
return nil, err
}
inputs := []api.Emitter{input}
......
for _, sink := range sinks {
tp.AddSink(inputs, sink)
}
......
return tp, nil
}
启动执行算子树
当执行算子树被构造完毕后,我们就需要启动执行算子树来真正执行这条 SQL,在以下的代码中展示了 eKuiper 启动执行算子的代码入口:
func (s *Topo) Open() <-chan error {
......
for _, snk := range s.sinks {
snk.Open(s.ctx.WithMeta(s.name, snk.GetName(), s.store), s.drain)
}
//apply operators, if err bail
for _, op := range s.ops {
op.Exec(s.ctx.WithMeta(s.name, op.GetName(), s.store), s.drain)
}
// open source, if err bail
for _, source := range s.sources {
source.Open(s.ctx.WithMeta(s.name, source.GetName(), s.store), s.drain)
}
.......
}
我们会以 sink / 执行算子 / source 的顺序,开始启动每个环节的算子。在这里,我们以单个算子运行为例,来了解执行算子的运行过程中的大致逻辑。
在以下的代码中展示了,对于单个算子而言,是如何读取下层算子的数据,进行计算,然后交付给上层算子进行处理。
func (o *UnaryOperator) doOp(ctx api.StreamContext, errCh chan<- error) {
......
for {
select {
// process incoming item
case item := <-o.input:
......
result := o.op.Apply(exeCtx, item, fv, afv)
switch val := result.(type) {
default:
.......
o.Broadcast(val)
}
// is cancelling
case <-ctx.Done():
return
}
}
}
每个执行算子会从自己的 input channel 中取出下层算子交付的数据,对于 UnaryOperator 而言,会通过 Apply 行为来将数据进行计算,将计算后的结果通过 Broadcast 转交给上层算子进行处理。
总结
在本篇文章中,我们以梳理关键代码节点的方式了解了 eKuiper 的 SQL 计算引擎中是如何解析、处理,并最终执行这条 SQL 得到相应的结果。对于整个计算引擎关键处理节点里,我们了解了每个环节的代码大致是如何运行的。
在后续的分享中,我们将以具体 SQL 为例,深入到各个环节、算子的内部执行的代码逻辑,从而让大家更好地理解 eKuiper 是如何在边缘端接受数据、处理计算并最终写入下游的整体流程。敬请期待。
版权声明: 本文为 EMQ 原创,转载请注明出处。
原文链接:https://www.emqx.com/zh/blog/ekuiper-source-code-interpretation