这个系列代码被封装的非常的精致,对二次开发不太友好,虽然也还是可以做些调节
模型的导出
有三种方式试过,都可以导出onnx的模型
1. 用yolov8
源码来自:ultralytics\yolo\engine\exporter.py
(不固定尺寸)
yolo export model=path/to/best.pt format=onnx dynamic=True
2. 用yolov5 里 export.py
但是attempt_load_weights这一步,要用yolo v8
3. 直接用 torch
class Demo(nn.Module):
def __init__(self, model=None):
super(Demo, self).__init__()
self.model = YOUR_PROCESS(model, 0, 255, False)
def forward(self, img):
return self.model(img)[0]
from ultralytics.nn.tasks import attempt_load_weights
model = attempt_load_weights(weights, device=0, inplace=True, fuse=True)
model = Demo(model)
model.to(device).eval()
#......(过程省略)
torch.onnx.export(self.model, img, output_path, verbose=False, opset_version=11, input_names=['images'],
output_names=['output'],
dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}})
- 这里的Demo和YOUR_PROCESS都需要基于
nn.Module,在YOUR_PROCESS用于包含一些模型额外的处理。- YOUR_PROCESS 中的内容,如果是用于前处理,记得不要进行梯度计算,并对运算过程和整个层做梯度忽略。如下:
with torch.no_grad():
# 在这个代码块中执行的操作不会被记录用于自动求导
output = model(input)
self.conv_xx.eval()
# 对于self.conv_xx层以及与其相关的层,将启用评估模式的行为
output = self.conv_xx(input)
- attempt_load_weights这一步,要用yolo v8的
multi-scale
def preprocess_batch(self, batch, imgsz_train, gs):
"""
Allows custom preprocessing model inputs and ground truths depending on task type.
"""
sz = random.randrange(int(self.args.imgsz * 0.5), int(self.args.imgsz * 1.5) + self.gs) // self.gs * self.gs # size
sf = sz / max(batch['img'].shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / self.gs) * self.gs for x in batch['img'].shape[2:]] # new shape (stretched to gs-multiple)
batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255
batch['img'] = nn.functional.interpolate(batch['img'], size=ns, mode='bilinear', align_corners=False)
return batch
Loss
Yolo V8 只有两个 loss, 因为是anchor-free 了,所以不需要objective loss, 直接看分类和预测出来的框的两个内容。
-
Yolo v5 使用 CIOU 去算的loss, 而 Yolo v8 加入了更符合anchor-free的 loss 。所以这一步,用了两个loss一起帮助优化IOU。
CIOU loss + DFL来自Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection这篇论文(DFL论文)- VFL 在 yolo v8中也implement了,但是没有用上,这个loss 也是针对 anchor-free 的, 来自arifocalNet: An IoU-aware Dense Object Detector这篇论文(VFL论文)。
-
对分类loss, yolo v5 使用Focal loss(由BCE为基础), Yolo v8 沿用
BCEWithLogitsLoss
# cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
# bbox loss
if fg_mask.sum():
loss[0], loss[2] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores,
target_scores_sum, fg_mask)
loss[0] *= self.hyp.box # box gain
loss[1] *= self.hyp.cls # cls gain
loss[2] *= self.hyp.dfl # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
VFL
class VarifocalLoss(nn.Module):
"""Varifocal loss by Zhang et al. https://arxiv.org/abs/2008.13367."""
def __init__(self):
"""Initialize the VarifocalLoss class."""
super().__init__()
def forward(self, pred_score, gt_score, label, alpha=0.75, gamma=2.0):
"""Computes varfocal loss."""
weight = alpha * pred_score.sigmoid().pow(gamma) * (1 - label) + gt_score * label
with torch.cuda.amp.autocast(enabled=False):
loss = (F.binary_cross_entropy_with_logits(pred_score.float(), gt_score.float(), reduction='none') *
weight).sum()
return loss
DFL
(感谢大白话 Generalized Focal Loss)
DFL 来自于GFL (Generalised focal loss)
GFL 主要解决了两个大的问题:
- classification score 和 IoU/centerness score 训练测试不一致
- bbox regression 采用的表示不够灵活,没有办法建模复杂场景下的uncertainty
class BboxLoss(nn.Module):
def __init__(self, reg_max, use_dfl=False):
"""Initialize the BboxLoss module with regularization maximum and DFL settings."""
super().__init__()
self.reg_max = reg_max
self.use_dfl = use_dfl
def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):
"""IoU loss."""
weight = torch.masked_select(target_scores.sum(-1), fg_mask).unsqueeze(-1)
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
# DFL loss
if self.use_dfl:
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl
@staticmethod
def _df_loss(pred_dist, target):
"""Return sum of left and right DFL losses."""
# Distribution Focal Loss (DFL) proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391
tl = target.long() # target left
tr = tl + 1 # target right
wl = tr - target # weight left
wr = 1 - wl # weight right
return (F.cross_entropy(pred_dist, tl.view(-1), reduction='none').view(tl.shape) * wl +
F.cross_entropy(pred_dist, tr.view(-1), reduction='none').view(tl.shape) * wr).mean(-1, keepdim=True)
问题1
不一致有两方面:
方面1 分类,objective 和 IOU 都是各自训练自己的这部分,比如Fcos(论文里提到). 查看了Fcos 的loss 计算,看到和YOLO的方式类似。
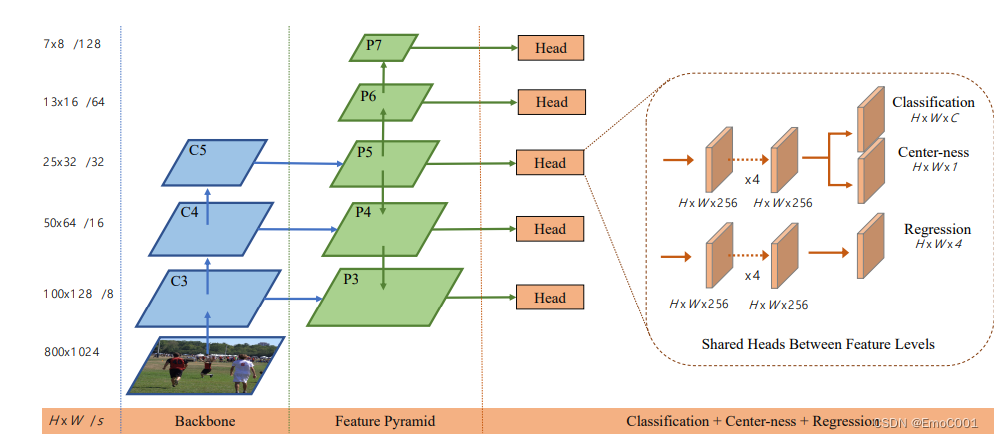

以上的loss 计算,在GFL一文中,作者不认可,他认为这个不够End-to-End
方面2 归功于focal loss,分类的计算,能帮助平衡样本类别imbalance的情况。但是IOU的计算这里,没有考虑到样本imbalance的情况。如果将不公平的IOU分数乘上还算公平的分类分数,那么可能导致这个结果有水分(因为我们希望IOU和分类都够好的,排到前面,作为正样本)。
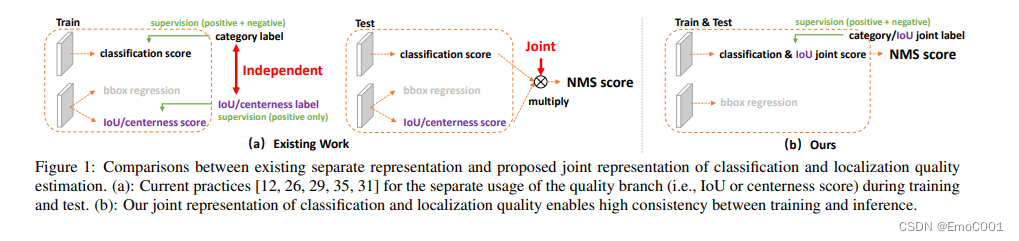
问题2
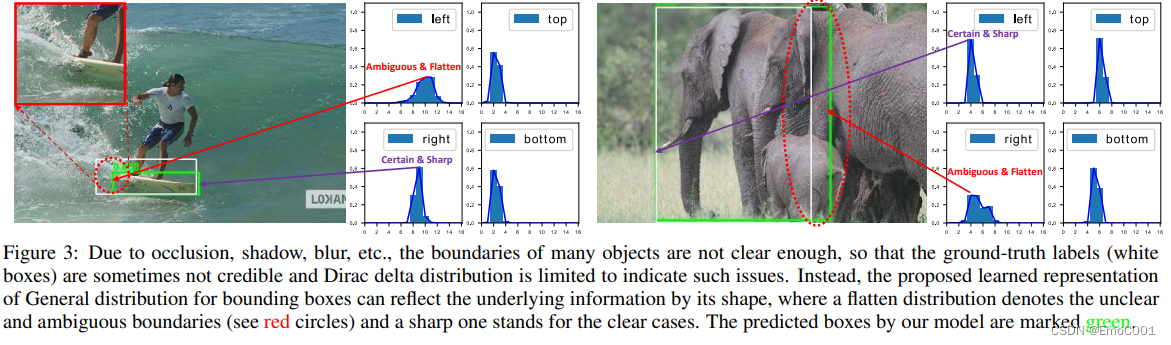
作者认为对于训练中IOU形成的Dirac delta distribution 或者预先做Gaussian分布的假设不足以用于general purpose 的场景。所以作者提出的新distribution, 可以让分布有形状上的明显特征。
确定为锐利区域的是紫色箭头所指,模棱两可为平滑区域的为红色箭头所指。从图上看,当遇到模棱两可的情况时,predict 的结果离 ground truth 有点多。
问题1 solution
针对方面1的问题,在QFL中用了classification-IoU joint representation(作为NMS score,而不像之前的做法是把两者相乘)。针对方面2,将Focal loss 运用进了 loss 公式。
问题2 solution
第二个问题使用general 分布解决,虽然数据也会有正负样本imbalance问题,但我们做的是目标检测,只有是正样本的时候,我们才在意它的IOU,因此作者决定只考虑正样本的情况,所以DFL仅用了cross entropy。
它之所以也叫focal,应该是因为它通过增加两个y labels(
y
i
y_i
yi ,
y
i
+
1
y_{i+1}
yi+1)的结果,来快速定位到正确的label y.
y
i
<
=
y
<
=
y
i
+
1
y_i <= y <= y_{i+1}
yi<=y<=yi+1
Finally
总的来说,作者靠QFL & DFL 解决了以上所有问题。但是一直强调的GFL呢?
在论文中,作者将QFL 与 DFL 做了 unified, GFL 就融合QFL 与 DFL的思想:
https://crossminds.ai/video/generalized-focal-loss-learning-qualified-and-distributed-bounding-boxes-for-dense-object-detection-606fdcaef43a7f2f827bf6f1/
https://paperswithcode.com/method/generalized-focal-loss
https://github.com/implus/GFocal
https://zhuanlan.zhihu.com/p/147691786
OTA
Distillation
DAMO-YOLO 用了KD, yolo v6 用了 self-distillation.
https://www.youtube.com/watch?v=MvM9J1lj1a8
https://openaccess.thecvf.com/content_ICCV_2019/papers/Zhang_Be_Your_Own_Teacher_Improve_the_Performance_of_Convolutional_Neural_ICCV_2019_paper.pdf
https://crossminds.ai/video/generalized-focal-loss-learning-qualified-and-distributed-bounding-boxes-for-dense-object-detection-606fdcaef43a7f2f827bf6f1/










![[Java基础]基本概念(上)(标识符,关键字,基本数据类型)](https://img-blog.csdnimg.cn/bea8808e05e64be3b4b30446c351948c.png)
