目录
一.引言
二.增加 _SUCCESS 标识
1.SparkContext 生成
2.FileSystem 生成
3.Hadoop 生成
三.获取最新文件
1.获取 SparkContext
2.按照时间排序
3.遍历生成 Input
四.总结
一.引言
有任务需要每小时生成多个 split 文件分片,为了保证线上任务读取最新的 SUCCESS 文件,需要在文件生成后增加 _SUCCESS 标识供线上文件判断当前文件路径是否可用。
最终效果:
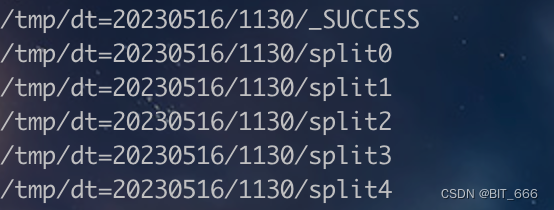
其中 split 为文件夹 (dir),_SUCCESS 为文件 (file)。
二.增加 _SUCCESS 标识
根据使用场景与文件类型与位置的不同,下面提供三种方案供大家使用。
1.SparkContext 生成
val spark = SparkSession
.builder
.config(conf)
.getOrCreate()
val sc = spark.sparkContext
sc.hadoopConfiguration.set("mapreduce.fileoutputcommitter.marksuccessfuljobs", "true")
直接设置 marksuccessfuljobs = true,即可在 saveAsTextFile 的对应路径生成 _SUCCESS 标识。
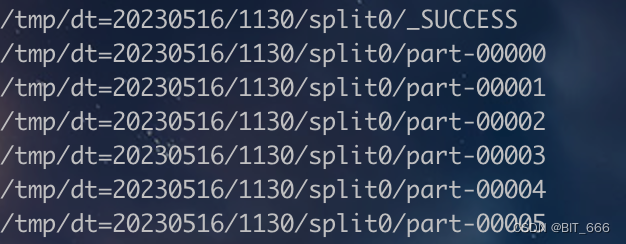
由于每个 split 都是调用 saveAsTextFile 生成的文件夹 (dir),所以每个 split 文件夹下都存在一个 _SUCCESS 标识当前 split 生成。
2.FileSystem 生成
上面的方法可以在 saveAsTextFile 时生成 _SUCCESS 标识,但是 split 的上级父目录无法标识 _SUCCESS,我们想要在 split 全部成功生成结束后,为父目录也增加一个 _SUCCESS 标识,此时需要 FileSystem 大显身手。
val spark = SparkSession
.builder
.config(conf)
.getOrCreate()
val sc = spark.sparkContext
val fileSystem = new Path("/user/...").getFileSystem(sc.hadoopConfiguration)
fileSystem.create(new Path(s"$output/_SUCCESS"))通过 HDFS 的 "/user/xxx" 路径生成对应文件系统 FileSystem 类,随后调用 create 方法,其中 output 为对应父目录地址。
3.Hadoop 生成
如果不想在程序内生成 _SUCCESS 标识,或者希望获取到 Spark APP 正常退出后再生成子/父目录的标识,则可以直接使用 touchz 实现。
hadoop fs -touchz /user/xxx/tmp/dt=20230516/1130/_SUCCESS直接调用 hadoop 生成空文件即可。判断程序是否正常运行可以调用下面的 Shell 代码:
if [ "$?" -ne 0 ];
then echo "Application Failed";
sh ./sendMail.sh '任务异常'
else
echo "success"
sh ./sendMail.sh '任务成功'
hadoop fs -touchz /user/xxx/tmp/dt=20230516/1130/_SUCCESS
fi
将代码放到 Spark-Submit 脚本的后面,即可实现任务正常退出生成 _SUCCESS。"$?" 可以看作是检查任务是否 System.exit(0) 正常退出。
三.获取最新文件
1.获取 SparkContext
val conf = new SparkConf().setAppName("GetInputPath")
val spark = SparkSession
.builder
.config(conf)
.getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("error")
// 1.获取 FileSystem
val baseDirPath = new Path("/user_ext/...")
val fs = baseDirPath.getFileSystem(spark.sparkContext.hadoopConfiguration)通过 HDFS 文件系统路径与 SC 获取 FileSystem。
2.按照时间排序
// 2.按最新时间排序文件夹
val satisfiedPath = fs.listStatus(baseDirPath).filter(dir => {
dir.isDirectory && fs.listStatus(dir.getPath).length == 5
}).sortWith { case (dir1, dir2) =>
dir1.getModificationTime > dir2.getModificationTime
}.iteratordir.isDirectory 判断是否为文件,fs.listStatus 判断文件夹个数,因为生成了 1 个 _SUCCESS File + 5 个 split Dir,所以长度判断为 5,最后通过 getModificationTime 获取调整时间并排序。
3.遍历生成 Input
// 3.遍历寻找合规文件夹
var state = true
var inputPath = ""
while (state && satisfiedPath.hasNext) {
// dir + file.getName 构成完整的 file path
val path = new Path(baseDirPath + File.separator + satisfiedPath.next().getPath.getName)
// 检查文件大小 1024-KB 1024x1024-MB 1024x1024x1024-GB
val capacity = fs.getContentSummary(path).getLength / (1024 * 1024 * 1024.0)
// 检查是否包含 SUCCESS
val allFileName = fs.listStatus(path).map(_.getPath.getName)
var isSuccess = false
allFileName.foreach(fileName => {
if (fileName.contains("_SUCCESS")) isSuccess = true
})
// 判断文件合规
if (capacity >= 100 && isSuccess) {
inputPath = path.toString
state = false
}
}getContentSummary.getLength 可以获取对应 Path 地址的 byte 大小,可以根据自己的场景进行单位转化,例如 K、M、G 等,而 listStatus.map(_.getPath.getName) 则是遍历我们的 File,判断是否有 _SUCCESS 标识。最后合规的输入路径需要容量达到指定要求且存在 _SUCCESS 才可以,否则继续 iterator 迭代,直到找到合规的文件路径。
四.总结
上述方法适用于在频繁生成的文件中添加 _SUCCESS 标识,并在对应读取的程序中获取最新的可用路径。除此之外,FileSystem 还有很多 API,除了 listStatus 方法外,大家也可以使用 fs.globStatus 方法获取全局的匹配路径文件,再依次处理。

![[Java基础]基本概念(上)(标识符,关键字,基本数据类型)](https://img-blog.csdnimg.cn/bea8808e05e64be3b4b30446c351948c.png)