最近大火的chatgpt,老板说让我看看能不能用自己的数据,回答专业一些,所以做了一些调研,最近用这个倒是成功推理了自己的数据,模型也开源了,之后有机会也训练一下自己的数据。
使用国产chatglm推理自己的数据文件_闻达
- 1.本机部署
- 1.1环境部署
- 1.2 配置参数
- 1.3. 推理
- 2.云服务器部署
1.本机部署
因为电脑配置不行,所以用了rwkv模型。
1.1环境部署
1.1双击打开anconda prompt创建虚拟环境
Conda create –n chatglm python#(创建名叫chatglm的虚拟python环境)
Conda activate chatglm#(激活环境)
1.2下载pytorch(这里要根据自己的电脑版本下载)都在虚拟环境里操作
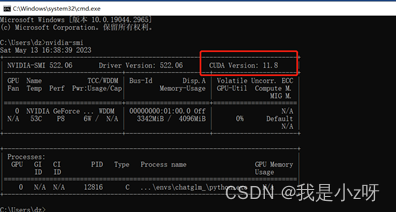
nvidia-smi#(查看自己cuda版本)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118#(下载符合自己配置的torch,可以在官网https://pytorch.org/查看命令)
1.3在官网https://download.pytorch.org/whl/torch_stable.html下载对应的cuda版本的torch和torchvision,然后pip install即可
这时gpu版的torch就下载成功:,验证方法如图:

1.4安装依赖库
cd C:\Users\dz\Desktop\AIGC\wenda\wd-git\wenda\requirements#(进入工具包的simple目录下)
pip install –r .\requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install protobuf flatbuffers termcolor#(根据提示下载需要的包和自己的模型requirements.txt文件)
1.2 配置参数
- 配模型:下载对应的模型权重文件,放到model文件夹下面,这里我用的是RWKV:
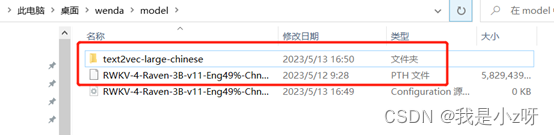
- 配数据:自己的文本数据放到txt文件夹下面:

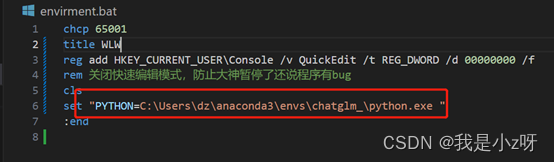
3.配环境:在environment里面把环境配成自己刚刚创建的虚拟环境
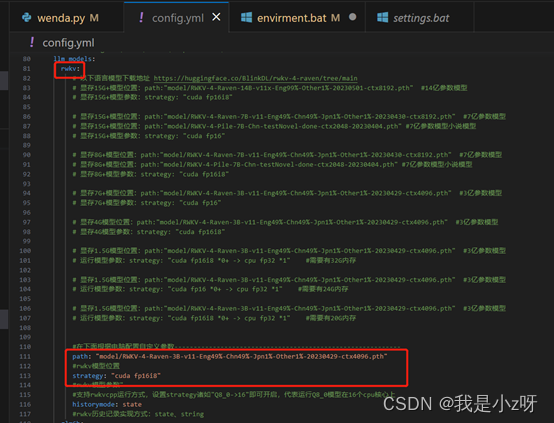
在config里面把权重文件的地址和配置改成自己的
1.3. 推理
- 双击step.2本地数据库建库.bat建本地数据库
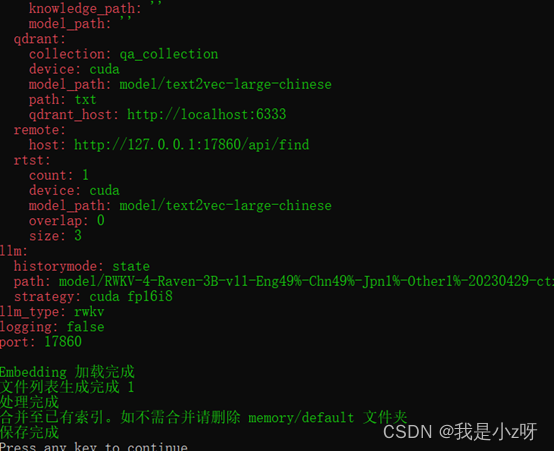
- 双击run_rwkv-点击运行.bat运行这个模型,然后浏览器打开http://127.0.0.1:17860/
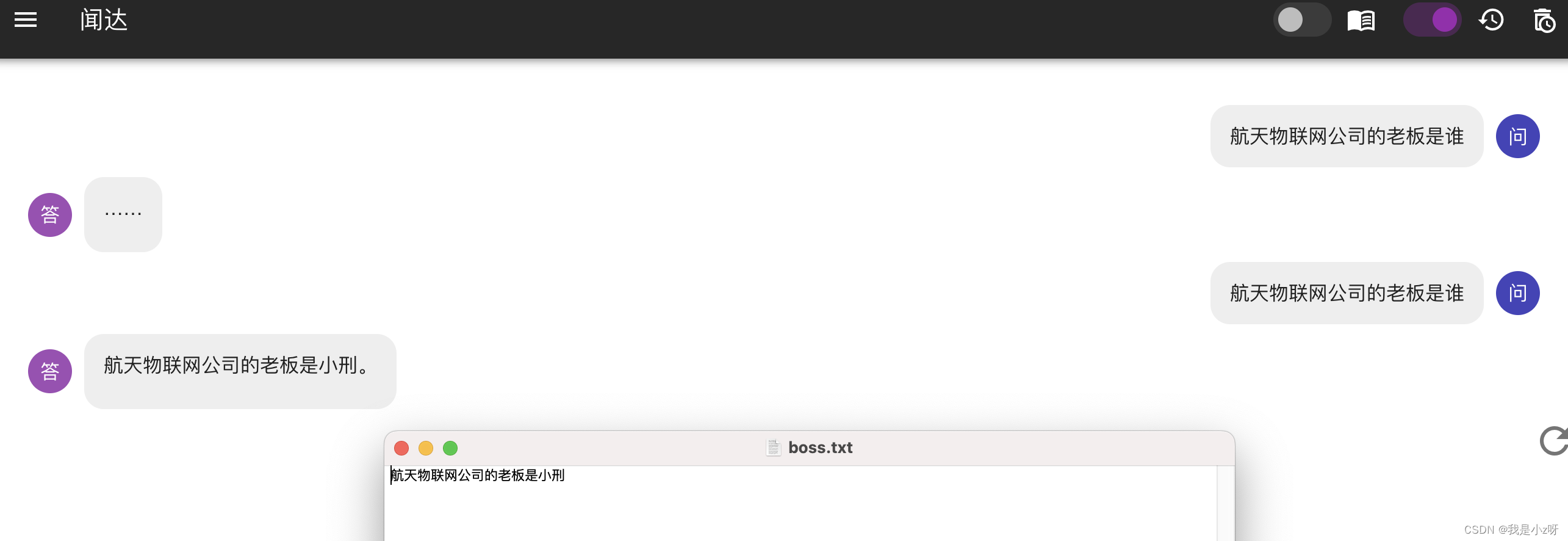
首先测试是否检测到本地数据库
问答功能
2.云服务器部署
电脑跑起来不行,所以在云服务器上搞了一个,本来是git源码的,但是源码git下来运行有问题,所以我还是把本地文件放到自己仓库,重新git了一下,云服务器租环境,就租wenda环境,然后
git clone https://github.com/Turing-dz/wenda_zoe_test.git
修改example.config.xml文件里的模型地址,然后就可以推理自己的数据了。
python pluges/gen_data_st.py#运行本地数据库
python wenda.py -t glm6b -p 6006#云上规定用6006映射
然后打开链接,打开知识库按钮,就会推理自己的数据文件了。