今天聊一个存储的实现细节,数据副本的并发写入。
存储的高可靠性和高可用,必须依赖于数据的冗余机制。比如 3 副本就是把用户数据复制成 3 份。然后把 3 份数据分发到不同的地方。这个写下去的动作是有讲究的,因为肯定不希望时延线性增加,你肯定希望的是虽然多写 2 份数据,但还只耗费 1 份时间。
换句话说,原则上数据虽然变多了,但是时间开销不能增加。那就只能并发写入喽!那这个动作怎么实现呢?带大家思考几个小问题:
-
副本冗余和并发写入的动作发生在哪里?姿势如何?
-
单次 IO 级别的并发和 IO 流的并发区别在哪里?

星型写入和链式写入

有两种最典型的姿势:星型写入和链式写入。
1 星型写入
副本复制的动作发生在客户端。这种方式实现简单,异常处理好控制。缺点主要是节点的扇出大,可能你的客户端网卡会是个瓶颈。这种方式数据分流分叉的决策点就是在客户端。
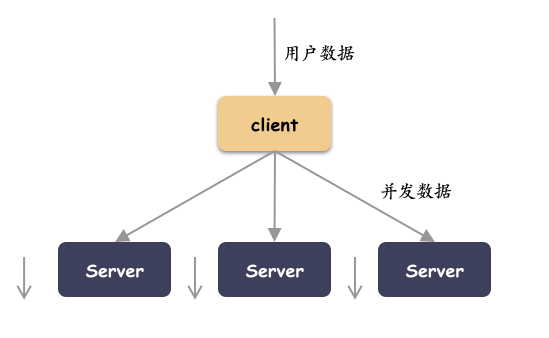
本篇就以这种方式举例。
2 链式写入
不得不提当然还有另外一种典型的写入方式:链式写入。客户端把数据交个副本的第一个节点,然后由第一个节点交给第二个节点,再由第二个节点交给第三个节点。这种写入方式对比星型写入,每个节点的扇入扇出都是一份数据,没有明显的瓶颈点。网络的传输上更加均衡。
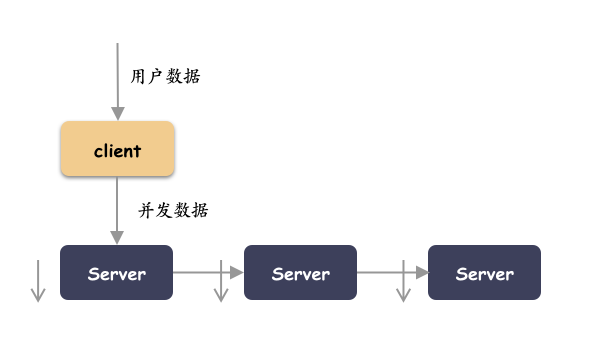

IO 级别的并发

什么是 IO 级别?
就是看到的操作主体是一次 IO ,也就是单次 IO 。最常见的就是块存储下来的 IO ,块存储的使用姿势一般是 open 出一个句柄之后,通过这个句柄下发 IO 。我们处理的是每一次下发的 IO ,把每一次下发 IO 的数据做冗余,写入做并发。如下伪代码,比如一份数据拷贝多份,写 2 次:
// 步骤一:获取到用户数据: buffer
// 步骤二:发往各个服务端节点
for i=0; i<2; i++ {
wn = write(/*网络句柄*/, /*buffer*/, /*buffer len*/)
}
// 等待响应,并且异常处理
循环调用 2 次发送即可。这种模式是 io 级别的,它处理的是这一笔 IO 。它的主要时延组成是两部分:网络 IO 的时延 + 磁盘 IO 的时延。
由于这个是单次 IO 级别的,buffer 可控的、较小的,网络传输的时延相比磁盘 IO ( 机械盘 )几乎可以忽略。

这里直接用循环来串行动作来进行网络发送主要还是因为整体时延都在磁盘 IO,而磁盘 IO 在不同的节点是并发的。
但是,存储介质现在越来越快(比如 nvme 盘,傲腾盘等),磁盘 IO 和网络 IO 的差距越来越小。这时候串行发送网络数据就不可取了。所以,网络传输的时延最好也是重叠的,把网络发送这部分也做成并发的。

网络 IO 做并行化和异步化处理之后,串行的时延只有客户端循环拷贝多份内存了,内存拷贝这部分占比还是极低的,对比网络 IO 和磁盘 IO 可以忽略。当然,如果还要更极致一点,这部分时延也可以重叠起来。此处不表。

IO 流的并发

单次 IO 的冗余和并发都是很容易理解。冗余嘛,就是把一份 buffer 拷贝出多份,并发嘛,就是把这多份数据并发的发送出去。这个都是很简单的 io 的操作调用。
Go 的 IO 不一样!Go 的 IO 抽象了所谓的 io.Reader , io.Writer 出来。如果童鞋写过 Go 的 IO 相关的程序就很容易理解。这是一个典型的 IO 流的操作。IO 流的操作包含了成千上万次的 IO 调用。一般使用 io.Copy 这种函数来操作。io.Copy 的定义,接受一个读流、一个写流 :
func Copy(dst Writer, src Reader) (written int64, err error) {
return copyBuffer(dst, src, nil)
}
io.Copy 的结束是要么读到 EOF 或者错误才算结束。所以这种情况如果对两个流用 io.Copy 操作,这个函数调用完,流也完成了。一次 io.Copy 并不是一次简单的 io 调用,一次 io.Copy 的函数调用里包含了成千上万次的 单次的 IO 操作 。
这种就不能简单的用 for 循环来操作多次 io.Copy 了。用 for 循环那么 IO 的写入时延就无法叠加了,就是一个串行的时延。
for i=0; i<2; i++ {
// 时延纯线性增长,凉凉。。。。
io.Copy(//)
}
那该怎么办呢?把 IO 流一份为二或者一分为多?那么怎么才能把这个写入变成多份,并且写入的时间最好是重叠起来,只消耗 1 份时间呢?
在 Go 里,怎么做呢?奇伢先说步骤:
-
需要一个 teeReader 来分流
-
需要一个 Pipe 写转读
-
需要两个 goroutine 做并发
1 IO 流并发实战
首先,需要一个 TeeReader ,这个组件主要是用来分流的,把一个读流分叉出一股数据流出去:
func TeeReader(r Reader, w Writer) Reader {
return &teeReader{r, w}
}
func (t *teeReader) Read(p []byte) (n int, err error) {
n, err = t.r.Read(p)
if n > 0 {
// 把读到的每一次数据都输入到 Writer 里去.
// 分一股数据流出去
if n, err := t.w.Write(p[:n]); err != nil {
return n, err
}
}
return
}
如上,TeeReader 实现分流的原理也很简单,就是在每一次 Read 的调用中,都把数据写一份出去。好,现在我们流分叉有了,但是分出来的是一个写流。
这个好像不大对呢?能否有两个 Reader ,这两个读流里面流淌的是相同的数据。咋办?
这时候就需要另外一个组件:Pipe 。调用 io.Pipe 会产生一个 Reader 和 Writer ,把数据写到 Writer 里,就能从 Reader 里原封不动的读出来。这可太适合写转读了。
刚好,就可以把 TeeReader 接着分出来的数据流用 Pipe 接着,于是乎你就有了两个相同的 Reader 数据流,接下来只需要把它们放在不同的 goroutine 去操作,那么这个 IO 流就是并发的。
Go 实战栗子 :
注意,为了简单,省略一些异常处理:
func ConcurrencyWrtie(src io.Reader, dest [2]io.Writer) (err error) {
errCh := make(chan error, 1)
// 管道,主要是用来写、读流转化
pr, pw := io.Pipe()
// teeReader ,主要是用来 IO 流分叉
wr := io.TeeReader(src, pw)
// 并发写入
go func() {
var _err error
defer func() {
pr.CloseWithError(_err)
errCh <- _err
}()
_, _err = io.Copy(dest[1], pr)
}()
defer func() {
// TODO:异常处理
pw.Close()
_err := <-errCh
_ = _err
}()
// 数据写入
_, err = io.Copy(dest[0], wr)
return err
}
其实,奇伢个人觉得:IO 流的并发其实更适合用链式的写入方式。这个观点以后有机会分享。
总结
-
IO 级别的并发很简单,客户端用 for 循环发就行了,大部分时间是重叠的( 网络 IO & 磁盘 IO ),那么就是并发的;
-
流式 IO 的并发也有套路,用 teeReader 分流,用 Pipe 把分出来的写流转成读流,然后用不同的 goroutine 操作即可实现 IO 流的并发;
-
无论是什么样的并发,或多或少都会有串行的部分。只要你把这部分的时间比例调整到极小,那整体就还是并发的效果;