大家好,我是易安!
今天我们开始每日一算的篇章,今天带来的是选择算法。
选择排序是一种简单而高效的排序算法,它通过从列表的未排序部分中重复选择最小(或最大)元素并将其移动到列表的已排序部分来工作。该算法反复从列表的未排序部分中选择最小(或最大)的元素,并将其与未排序部分的第一个元素交换。对列表中剩余的未排序部分重复此过程,直到整个列表排序完毕。选择排序的一种变体称为“双向选择排序”,它通过在最小元素和最大元素之间交替遍历元素列表,这种方式在某些情况下可以更快。

选择排序算法
该算法在给定数组中维护两个子数组。
已经排序的子数组。 剩余的子数组未排序。 在选择排序的每次迭代中,从未排序的子数组中选取最小元素(考虑升序)并将其移动到已排序子数组的开头。
每次迭代后,已排序的子数组大小增加一,未排序的子数组大小减少一。
在 N(数组的大小)次迭代之后,我们将得到一个排序的数组。
选择排序流程图:
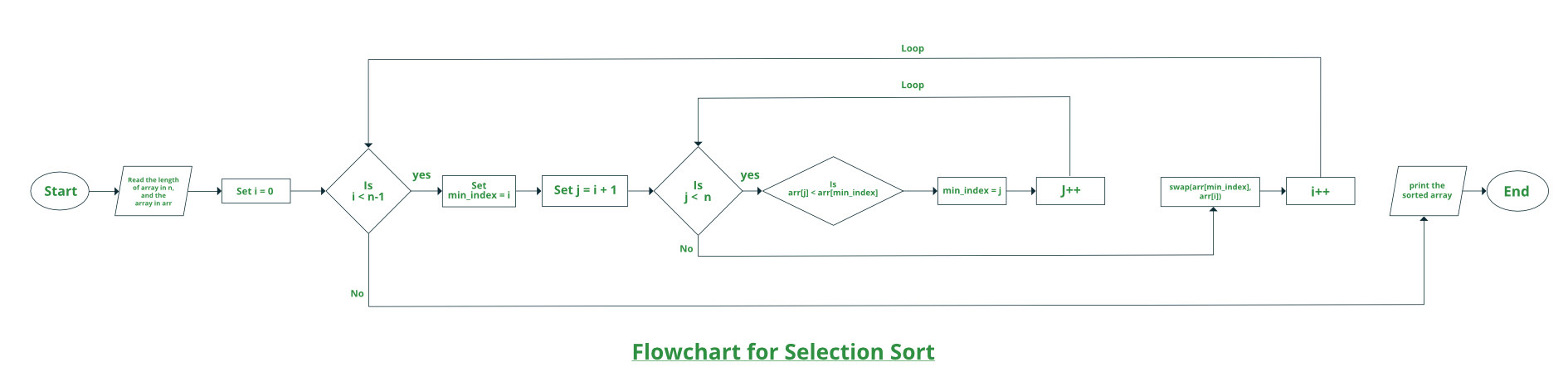
选择排序原理?
让我们以下面的数组为例:arr[] = {64, 25, 12, 22, 11}
第一步:
对于排序数组中的第一个位置,整个数组从索引 0 到 4 依次遍历。 当前存放64的第一个位置,遍历整个数组后显然 11是最低值。
64 25 12 22 11
因此,将 64 替换为11。经过一次迭代后,恰好是数组中最小值的 11 往往会出现在排序列表的第一个位置。
11 25 12 22 64 第二步:
对于存在 25 的第二个位置,再次按顺序遍历数组的其余部分。
11 25 12 22 64
遍历后发现 12是数组中倒数第二的值,应该出现在数组的第二位,因此交换这些值。
11 12 25 22 64 第三步:
现在,对于第三位,再次出现 25 的地方遍历数组的其余部分并找到数组中第三小的值。
11 12 25 22 64
遍历时, 22是第三小的值,它应该出现在数组的第三位,因此将 22与第三位的元素交换。
11 12 22 25 64 第四步:
同样,对于第四个位置,遍历数组的其余部分,找到数组中第四小的元素 由于 25是第四低的值,因此它将排在第四位。
11 12 22 25 64 第五步:
最后,数组中存在的最大值自动放置在数组的最后一个位置 结果数组是排序后的数组。
11 12 22 25 64
实战演练
请按照以下步骤实现代码:
-
将最小值 ( min_idx ) 初始化为位置 0。 -
遍历数组,找到数组中的最小元素。 -
在遍历时,如果找到任何小于 min_idx 的元素,则交换两个值。 -
然后,递增 min_idx以指向下一个元素。 -
重复直到数组被排序。
下面是上述方法的实现:
-
java版本
import java.io.*;
public class SelectionSort
{
void sort(int arr[])
{
int n = arr.length;
// 逐步移动未排序数组的边界
for (int i = 0; i < n-1; i++)
{
//查找未排序数组中的最小元素
int min_idx = i;
for (int j = i+1; j < n; j++)
if (arr[j] < arr[min_idx])
min_idx = j;
// 将找到的最小元素与第一个元素进行交换
int temp = arr[min_idx];
arr[min_idx] = arr[i];
arr[i] = temp;
}
}
// 打印排序后的数组结果
void printArray(int arr[])
{
int n = arr.length;
for (int i=0; i<n; ++i)
System.out.print(arr[i]+" ");
System.out.println();
}
public static void main(String args[])
{
SelectionSort ob = new SelectionSort();
int arr[] = {64,25,12,22,11};
ob.sort(arr);
System.out.println("Sorted array");
ob.printArray(arr);
}
}
输出
排序数组:
11 12 22 25 64
选择排序的复杂度分析:
时间复杂度:选择排序的时间复杂度为 O(N 2 ),因为有两个嵌套循环:
-
一个循环一个一个地选择Array的一个元素= O(N) -
将该元素与每个其他数组元素进行比较的另一个循环 = O(N)
因此整体复杂度 = O(N) * O(N) = O(N*N) = O(N 2 )
辅助空间: O(1) 作为唯一使用的额外内存用于临时变量,同时交换数组中的两个值。选择排序永远不会进行超过 O(N) 次交换,并且在内存写入是一项代价高昂的操作时非常有用。
选择排序算法是否稳定?
稳定性:默认实现不稳定。然而,它可以变得稳定。这个后续再讲。
选择排序算法的优点:
-
简单易懂。 -
保留具有相同键的项目的相对顺序,这意味着它是稳定的。 -
适用于小型数据集。 -
它适用于各种类型的数据类型。 -
选择排序是一种就地排序算法,这意味着它不需要任何额外的内存来对列表进行排序。 -
它具有 O(n^2) 的最佳情况和平均情况时间复杂度,使其对于小型数据集非常有效。 -
很容易修改为按升序或降序排序。 -
它可以很容易地在硬件中实现,使其适用于实时应用。 -
它也可以用作更有效的排序算法中的子程序。 -
它不需要任何特殊的内存或辅助数据结构,使其成为轻量级解决方案。 -
该算法可以轻松并行,允许在多核处理器上进行高效排序。 -
它可以在有限的内存环境中使用,因为它需要最少的额外内存。 -
它易于理解,使其成为教学目的的热门选择。 -
它适用于对唯一键很少的数据进行排序,因为它在这种情况下表现良好。
选择排序算法的缺点:
-
选择排序在最坏和平均情况下的时间复杂度为 O(n^2)。 -
在大型数据集上效果不佳。 -
选择排序算法需要多次迭代列表,因此会导致不平衡分支。 -
选择排序的缓存性能很差,因此对缓存不友好。 -
不是自适应的,这意味着它没有利用列表可能已经排序或部分排序的事实 -
对于具有慢速随机存取存储器 (RAM) 的大型数据集来说不是一个好的选择 -
它不是比较排序,也没有像合并排序或快速排序那样的任何性能保证。 -
它的缓存性能很差 -
由于其高分支预测错误率,它可能导致分支预测不佳 -
它有很多写操作,导致在存储速度慢的系统上性能不佳。 -
它不是可并行算法,这意味着它不能轻易拆分以在多个处理器或内核上运行。 -
它不能很好地处理具有许多重复项的数据,因为它会进行许多不必要的交换。 -
在大多数情况下,它可以被其他算法(如快速排序和堆排序)超越。
总结:
-
选择排序是一种简单易懂的排序算法,其工作原理是从列表的未排序部分重复选择最小(或最大)的元素并将其移动到列表的已排序部分。 -
对列表中剩余的未排序部分重复此过程,直到整个列表排序完毕。 -
在最坏和平均情况下,它的时间复杂度为 O(n^2),这使得它对于大型数据集的效率较低。 -
选择排序是一种稳定的排序算法。 -
它可用于对不同类型的数据进行排序。 -
它在特定应用程序中很有用,例如小型数据集和内存受限系统。
本文由 mdnice 多平台发布