MySQL性能调优
- 1. 数据库表设计
- 1.1 范式化设计
- 1.1.1 什么是范式?
- 1.1.2 第一范式(1NF)
- 1.1.2 第二范式(2NF)
- 1.1.3 第三范式(3NF)
- 1.2 反范式设计
- 1.2.1 什么叫反范式化设计
- 1.3 范式化和反范式总结
- 1.3.1 范式化设计优缺点
- 1.3.2 反范式化设计优缺点
- 1.3.3 性能提升-缓存和汇总
- 1.3.4 性能提升-计数器表
- 1.3.5 反范式设计-分库分表中的查询
- 2. 高性能索引
- 2.1 聚集索引/聚簇索引
- 2.2 辅助索引/二级索引
- 2.3 回表
- 2.4 MRR
- 2.5 联合索引/复合索引
- 2.6 自适应哈希索引
- 2.7 全文检索之倒排索引
- 2.8 MySQL中的全文索引
- 2.9 总结:MySQL有哪些索引类型
- 2.10 辨析覆盖索引/索引覆盖
- 2.11 深入思考索引在查询中的使用
本文是按照自己的理解进行笔记总结,如有不正确的地方,还望大佬多多指点纠正,勿喷。
本节课内容:
1.什么是表设计的第一、第二、第三范式?
2.什么叫反范式化设计?
3.工作中的反范式实践
4.InnoDB中的聚集索引和辅助索引
5.什么是回表和MRR?
6. InnoDB中的AHI自适应哈希索引
7. InnoDB中的全文索引
8.面试题:什么是密集索引和稀疏索引?
9.辨析覆盖索引/索引覆盖
10.高性能的索引创建策略
11.索引选择性和前缀索引
12.面试题:什么是三星索引?
13.高性能的索引维护实践
1. 数据库表设计
在数据库表设计上有个很重要的设计准则,称为范式设计。
1.1 范式化设计
1.1.1 什么是范式?
范式来自英文Normal Form,简称NF。MySQL是关系型数据库,但是要想设计—个好的关系,必须使关系满足一定的约束条件,此约束已经形成了规范,分成几个等级,一级比一级要求得严格。满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。反之则是乱七八糟,不仅给数据库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般来说,数据库只需满足第三范式(3NF)就行了。
1.1.2 第一范式(1NF)
1、每一列属性都是不可再分的属性值,确保每一列的原子性;
2、两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据;
3、单一属性的列为基本数据类型构成;
4、设计出来的表都是简单的二维表。
定义: 属于第一范式关系的所有属性都不可再分,即数据项不可分。
理解: 第一范式强调数据表的原子性,是其他范式的基础

只第一范式来规范表格是远远不够的,依然会存在数据冗余过大、删除异常、插入异常、修改异常的问题,此时就需要引入规范化概念,将其转化为更标准化的表格,减少数据依赖。
1.1.2 第二范式(2NF)
- 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
- 第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系
第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。通常在实现来说,需要为表加上一个列,以存储各个实例的惟一标识。例如员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是惟一的,因此每个员工可以被惟一区分。这个惟一属性列被称为主关键字或主键、主码。
也就是说要求表中只具有一个业务主键,而且第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性。
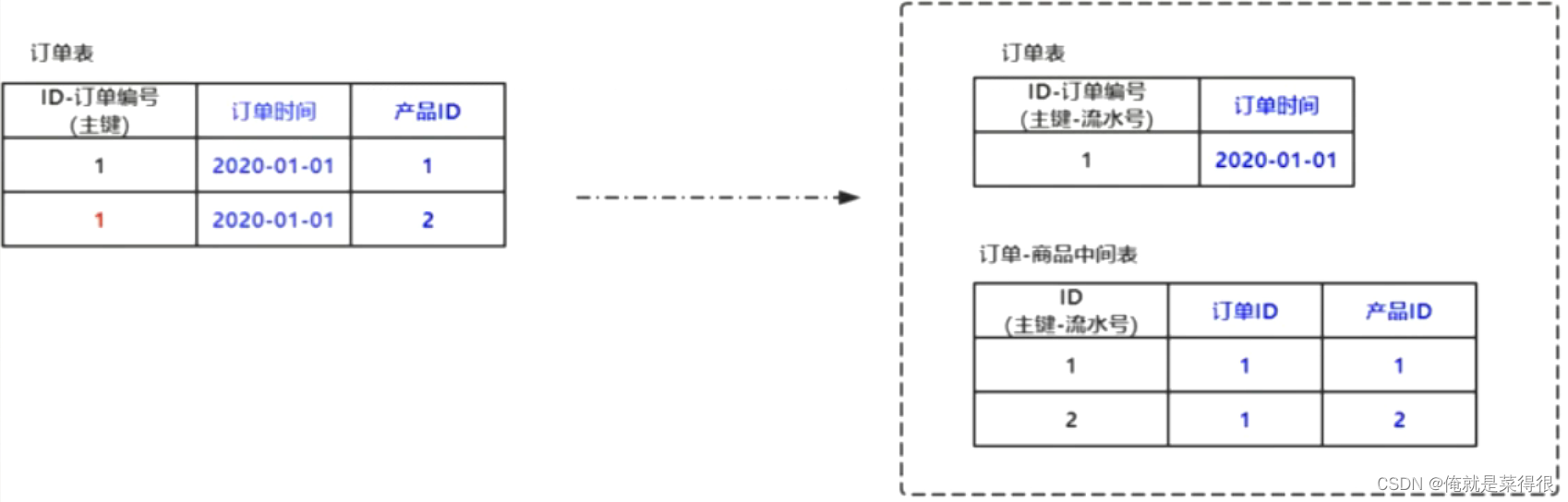
1.1.3 第三范式(3NF)
指每一个非主属性既不部分依赖于也不传递依赖于业务主键,也就是在第二范式的基础上消除了非主键对主键的传递依赖。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。
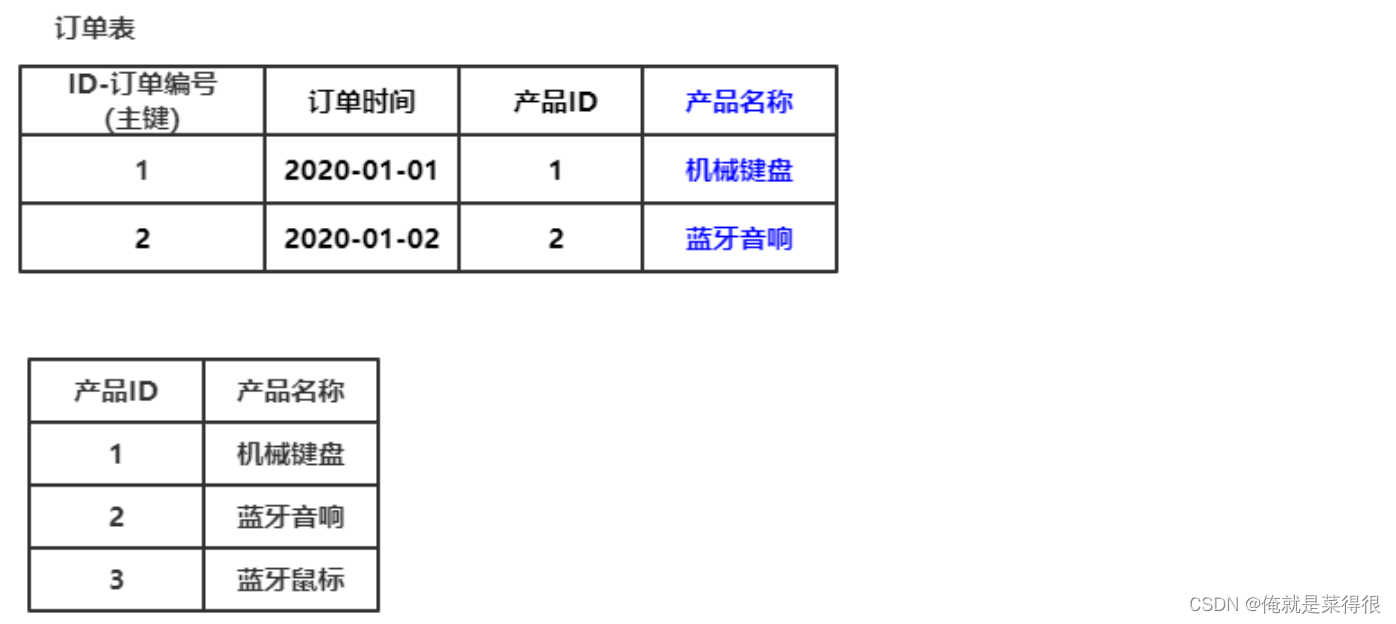
其中
产品 ID与订单编号存在关联关系
产品名称与订单编号存在关联关系
产品ID与产品名称存在关联关系
订单表里如果如果产品ID发生改变,同一个表里产品名称也要跟着改变,这样不符合第三范式,应该把产品名称这一列从订单表中删除。
范式说明
真正的数据库范式定义上,相当难懂,比如第二范式(2NF)的定义“若某关系R属于第一范式,且每一个非主属性完全函数依赖于任何一个候选码,则关系R属于第二范式。”,这里面有着大堆专业术语的堆叠,比如“函数依赖”、“码”、“非主属性”、与“完全函数依赖”等等,而且有完备的公式定义,需要仔细研究
1.2 反范式设计
1.2.1 什么叫反范式化设计
完全符合范式化的设计真的完美无缺吗?很明显在实际的业务查询中会大量存在着表的关联查询,而大量的表关联很多的时候非常影响查询的性能。
所谓得反范式化就是为了性能和读取效率得考虑而适当得对数据库设计范式得要求进行违反。允许存在少量得冗余,换句话来说反范式化就是使用空间来换取时间。
反范式设计-商品信息
下面是范式设计的商品信息表

商品信息和分类信息经常一起查询,所以把分类信息也放到商品表里面,冗余存放

1.3 范式化和反范式总结
1.3.1 范式化设计优缺点
1、范式化的更新操作通常比反范式化要快。
2、当数据较好地范式化时,就只有很少或者没有重复数据,所以只需要修改更少的数据。
3、范式化的表通常更小,可以更好地放在内存里,所以执行操作会更快。
4、很少有多余的数据意味着检索列表数据时更少需要DISTINCT或者GROUP BY语句。在非范式化的结构中必须使用DISTINCT或者GROUPBY才能获得一份唯一的列表,但是如果是一张单独的表,很可能则只需要简单的查询这张表就行了。
范式化设计的缺点是通常需要关联。稍微复杂一些的查询语句在符合范式的表上都可能需要至少一次关联,也许更多。这不但代价昂贵,也可能使一些索引策略无效。例如,范式化可能将列存放在不同的表中,而这些列如果在一个表中本可以属于同一个索引。
1.3.2 反范式化设计优缺点
1、反范式设计可以减少表的关联
2、可以更好的进行索引优化。
反范式设计缺点也很明显,
1、存在数据冗余及数据维护异常,
2、对数据的修改需要更多的成本。
实际工作中的反范式实现
冗余、缓存、汇总(实时还是定时,根据需求的实时性来)
计数器表(写热点的分散)
搜索引擎(新增 + 查询)
1.3.3 性能提升-缓存和汇总
范式化和反范式化的各有优劣,怎么选择最佳的设计?
而现实也是,完全的范式化和完全的反范式化设计都是实验室里才有的东西,在真实世界中很少会这么极端地使用。在实际应用中经常需要混用。
最常见的反范式化数据的方法是复制或者缓存,在不同的表中存储相同的特定列。
比如从父表冗余一些数据到子表的。前面我们看到的分类信息放到商品表里面进行冗余存放就是典型的例子。
缓存衍生值也是有用的。如果需要显示每个用户发了多少消息,可以每次执行一个对用户发送消息进行count的子查询来计算并显示它,也可以在user表用户中建一个消息发送数目的专门列,每当用户发新消息时更新这个值。
有需要时创建一张完全独立的汇总表或缓存表也是提升性能的好办法。
“缓存表”来表示存储那些可以比较简单地从其他表获取(但是每次获取的速度比较慢)数据的表(例如,逻辑上冗余的数据)。而“汇总表”时,则保存的是使用GROUP BY语句聚合数据的表。
在使用缓存表和汇总表时,有个关键点是如何维护缓存表和汇总表中的数据,常用的有两种方式,实时维护数据和定期重建,这个取决于应用程序,不过一般来说,缓存表用实时维护数据更多点,往往在一个事务中同时更新数据本表和缓存表,汇总表则用定期重建更多,使用定时任务对汇总表进行更新。
1.3.4 性能提升-计数器表
计数器表在Web应用中很常见。比如网站点击数、用户的朋友数、文件下载次数等。对于高并发下的处理,首先可以创建一张独立的表存储计数器,这样可使计数器表小且快,并且可以使用一些更高级的技巧。
比如假设有一个计数器表,只有一行数据,记录网站的点击次数,网站的每次点击都会导致对计数器进行更新,问题在于,对于任何想要更新这一行的事务来说,这条记录上都有一个全局的互斥锁(mutex)。这会使得这些事务只能串行执行,会严重限制系统的并发能力。
怎么改进呢?可以将计数器保存在多行中,每次随机选择一行进行更新。在具体实现上,可以增加一个槽(slot)字段,然后预先在这张表增加100行或者更多数据,当对计数器更新时,选择一个随机的槽(slot)进行更新即可。
这种解决思路其实就是写热点的分散,在JDK的JDK1.8中新的原子类LongAdder也是这种处理方式,而我们在实际的缓冲中间件Redis等的使用、架构设计中,可以采用这种写热点的分散的方式,当然架构设计中对于写热点还有削峰填谷的处理方式,这种在MySQL的实现中也有体现,我们后面会讲到。
1.3.5 反范式设计-分库分表中的查询
例如,用户购买了商品,需要将交易记录保存下来,那么如果按照买家的纬度分表,则每个买家的交易记录都被保存在同一表中, 我们可以很快、 很方便地査到某个买家的购买情况, 但是某个商品被购买的交易数据很有可能分布在多张表中, 査找起来比较麻烦 。 反之, 按照商品维度分表, 则可以很方便地査找到该商品的购买情况, 但若要査找到买家的交易记录, 则会比较麻烦 。
所以常见的解决方式如下。
( 1 ) 在多个分片表查询后合并数据集, 这种方式的效率很低。
( 2 ) 记录两份数据, 一份按照买家纬度分表, 一份按照商品维度分表,
( 3 ) 通过搜索引擎解决, 但如果实时性要求很高, 就需要实现实时搜索
在某电商交易平台下, 可能有买家査询自己在某一时间段的订单, 也可能有卖家査询自已在某一时间段的订单, 如果使用了分库分表方案, 则这两个需求是难以满足的, 因此, 通用的解决方案是, 在交易生成时生成一份按照买家分片的数据副本和一份按照卖家分片的数据副本,查询时分别满足之前的两个需求,因此,查询的数据和交易的数据可能是分别存储的,并从不同的系统提供接口。
总结经验
1.实际设计中,先按照3范式设计,尽可能去通过设计索引和优化sql,如果逐渐发现性能跟不上了,开始考虑做反范式化设计。也就是,尽可能遵循范式化设计,当范式化设计影响到性能的时候毫不犹豫启动反范式化设计。
2.反范式化的核心:空间换时间
2. 高性能索引
InnoDB中的索引是按照B+树来组织的,我们知道B+树的叶子节点用来放数据的,但是放什么数据呢?索引自然是要放的,因为B+树的作用本来就是为了快速检索数据而提出的一种数据结构,不放索引放什么呢?但是数据库中的表,数据才是我们真正需要的数据,索引只是辅助数据,甚至于一个表可以没有自定义索引。InnoDB中的数据到底是如何组织的?
2.1 聚集索引/聚簇索引
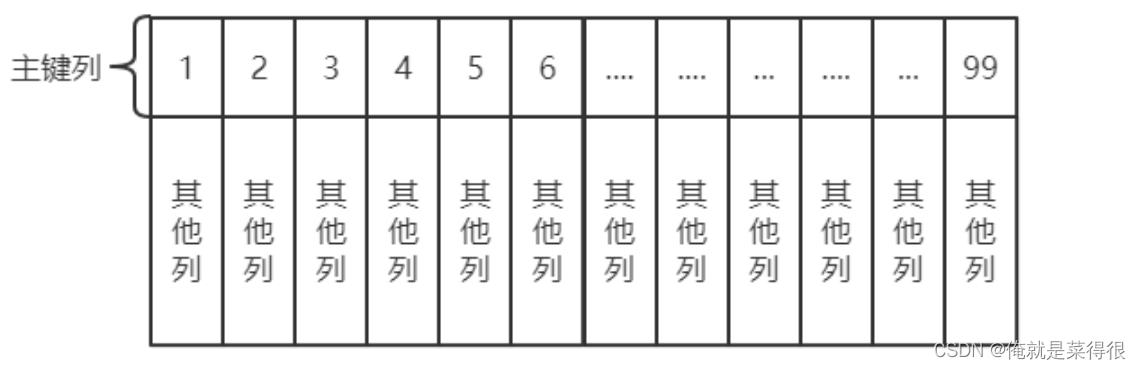
InnoDB中使用了聚集索引,就是将表的主键用来构造一棵B+树,并且将整张表的行记录数据存放在该B+树的叶子节点中。也就是所谓的索引即数据,数据即索引。由于聚集索引是利用表的主键构建的,所以每张表只能拥有一个聚集索引。
聚集索引的叶子节点就是数据页。换句话说,数据页上存放的是完整的每行记录。因此聚集索引的一个优点就是:通过过聚集索引能获取完整的整行数据。另一个优点是:对于主键的排序查找和范围查找速度非常快。
如果我们没有定义主键呢?MySQL会使用唯一性索引,没有唯一性索引,MySQL也会创建一个隐含列RowID来做主键,然后用这个主键来建立聚集索引。
2.2 辅助索引/二级索引
上边介绍的聚簇索引只能在搜索条件是主键值时才能发挥作用,因为B+树中的数据都是按照主键进行排序的,那如果我们想以别的列作为搜索条件怎么办?我们一般会建立多个索引,这些索引被称为辅助索引/二级索引。
对于辅助索引(Secondary Index,也称二级索引、非聚集索引),叶子节点并不包含行记录的全部数据。叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含了相应行数据的聚集索引键。
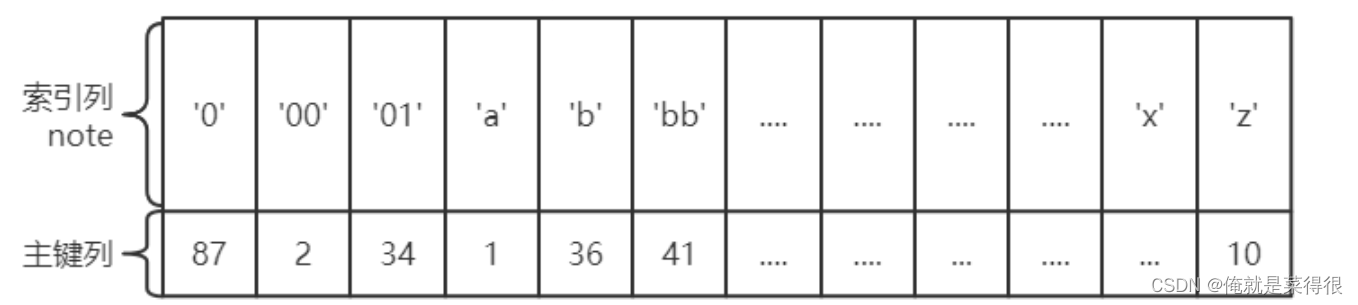
比如辅助索引index(node),那么叶子节点中包含的数据就包括了(主键、note)。
2.3 回表
辅助索引的存在并不影响数据在聚集索引中的组织,因此每张表上可以有多个辅助索引。当通过辅助索引来寻找数据时,InnoDB存储引擎会遍历辅助索引并通过叶级别的指针获得指向主键索引的主键,然后再通过主键索引(聚集索引)来找到一个完整的行记录。这个过程也被称为回表。也就是根据辅助索引的值查询一条完整的用户记录需要使用到2棵B+树----一次辅助索引,一次聚集索引。
为什么我们还需要一次回表操作呢?直接把完整的用户记录放到辅助索引d的叶子节点不就好了么?
如果把完整的用户记录放到叶子节点是可以不用回表,但是太占地方了,相当于每建立一棵B+树都需要把所有的用户记录再都拷贝一遍,这就有点太浪费存储空间了。而且每次对数据的变化要在所有包含数据的索引中全部都修改一次,性能也非常低下。
很明显,回表的记录越少,性能提升就越高,需要回表的记录越多,使用二级索引的性能就越低,甚至让某些查询宁愿使用全表扫描也不使用二级索引。
那什么时候采用全表扫描的方式,什么时候使用采用二级索引 + 回表的方式去执行查询呢?这个就是查询优化器做的工作,查询优化器会事先对表中的记录计算一些统计数据,然后再利用这些统计数据根据查询的条件来计算一下需要回表的记录数,需要回表的记录数越多,就越倾向于使用全表扫描,反之倾向于使用二级索引 + 回表的方式。
2.4 MRR
从上文可以看出,每次从二级索引中读取到一条记录后,就会根据该记录的主键值执行回表操作。而在某个扫描区间中的二级索引记录的主键值是无序的,也就是说这些二级索引记录对应的聚簇索引记录所在的页面的页号是无序的。
每次执行回表操作时都相当于要随机读取一个聚簇索引页面,而这些随机IO带来的性能开销比较大。MySQL中提出了一个名为Disk-Sweep Multi-Range Read (MRR,多范围读取)的优化措施,即先读取一部分二级索引记录,将它们的主键值排好序之后再统一执行回表操作。
相对于每读取一条二级索引记录就立即执行回表操作,这样会节省一些IO开销。使用这个 MRR优化措施的条件比较苛刻,所以我们直接认为每读取一条二级索引记录就立即执行回表操作。MRR的详细信息,可以查询官方文档。
2.5 联合索引/复合索引
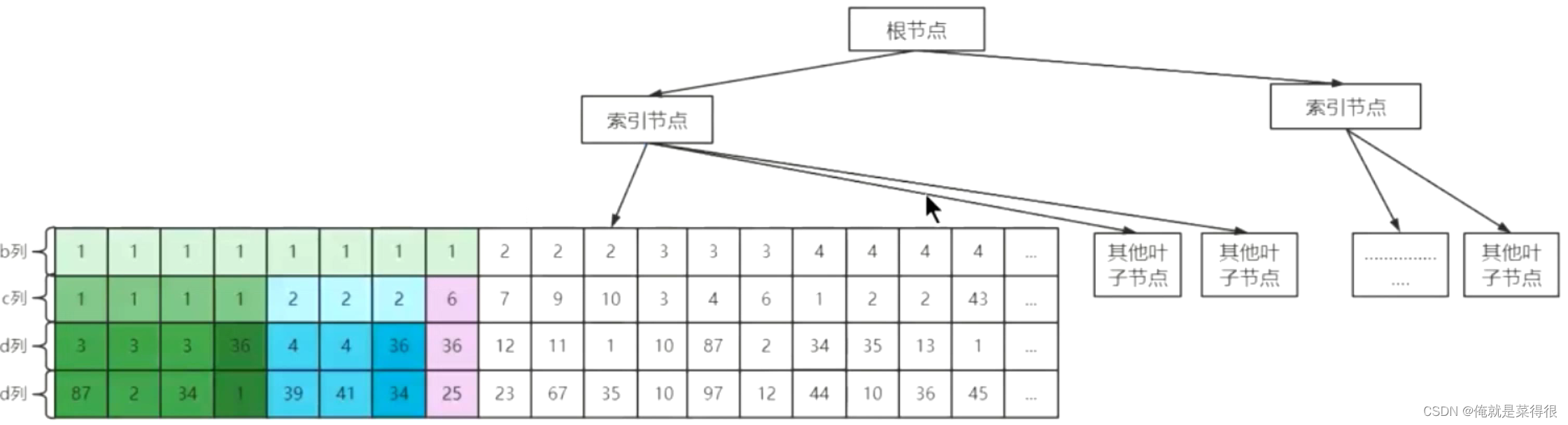
前面我们对索引的描述,隐含了一个条件,那就是构建索引的字段只有一个,但实践工作中构建索引的完全可以是多个字段。所以,将表上的多个列组合起来进行索引我们称之为联合索引或者复合索引,比如index(a,b)就是将a,b两个列组合起来构成一个索引。
千万要注意一点,建立联合索引只会建立1棵B+树,多个列分别建立索引会分别以每个列则建立B+树,有几个列就有几个B+树,比如,index(note)、index(b),就分别对note,b两个列各构建了一个索引。
index(note,b)在索引构建上,包含了两个意思:
1、先把各个记录按照note列进行排序。
2、在记录的note列相同的情况下,采用b列进行排序
2.6 自适应哈希索引
InnoDB存储引擎除了我们前面所说的各种索引,还有一种自适应哈希索引,我们知道B+树的查找次数,取决于B+树的高度,在生产环境中,B+树的高度一般为3-4层,故需要3~4次的IO查询。
所以在InnoDB存储引擎内部自己去监控索引表,如果监控到某个索引经常用,那么就认为是热数据,然后内部自己创建一个hash索引,称之为自适应哈希索引( Adaptive Hash Index,AHI),创建以后,如果下次又查询到这个索引,那么直接通过hash算法推导出记录的地址,直接一次就能查到数据,比重复去B+tree索引中查询三四次节点的效率高了不少。
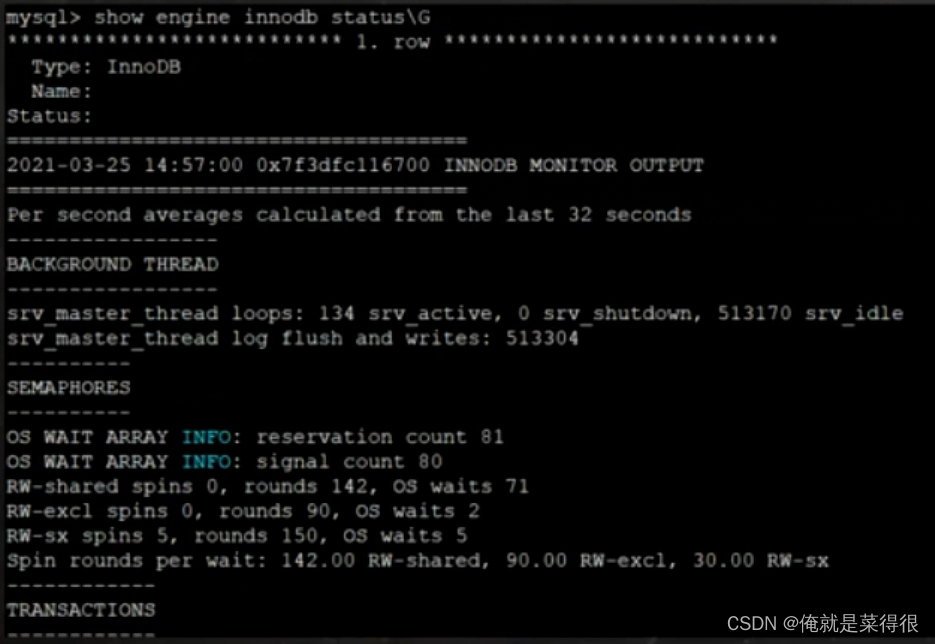
InnoDB存储引擎使用的哈希函数采用除法散列方式,其冲突机制采用链表方式。注意,对于自适应哈希索引仅是数据库自身创建并使用的,我们并不能对其进行干预。通过命令show engine innodb status\G可以看到当前自适应哈希索引的使用状况,如:
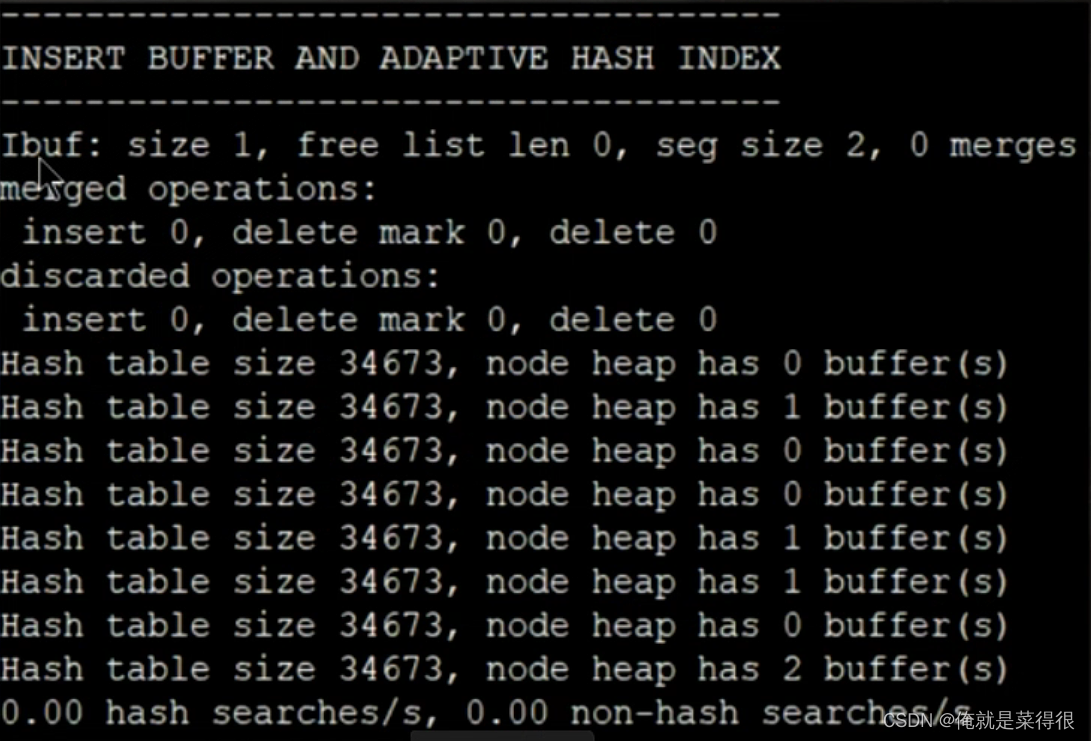
哈希索引只能用来搜索等值的查询,如 SELECT* FROM table WHERE index co=xxx。而对于其他查找类型,如范围查找,是不能使用哈希索引的,
因此这里会显示non- hash searches/s的统计情况。通过 hash searches: non-hash searches可以大概了解使用哈希索引后的效率。
由于AHI是由 InnoDB存储引擎控制的,因此这里的信息只供我们参考。不过我们可以通过观察SHOW ENGINE INNODB STATUS的结果及参数 innodb_adaptive_hash_index来考虑是禁用或启动此特性,默认AHI为开启状态。
什么时候需要禁用呢?如果发现监视索引查找和维护哈希索引结构的额外开销远远超过了自适应哈希索引带来的性能提升就需要关闭这个功能。
同时在MySQL 5.7中,自适应哈希索引搜索系统被分区。每个索引都绑定到一个特定的分区,每个分区都由一个单独的 latch 锁保护。分区由 innodb_adaptive_hash_index_parts 配置选项控制 。在早期版本中,自适应哈希索引搜索系统受到单个 latch 锁的保护,这可能成为繁重工作负载下的争用点。innodb_adaptive_hash_index_parts 默认情况下,该选项设置为8。最大设置为512。当然禁用或启动此特性和调整分区个数这个应该是DBA的工作,我们了解即可。
InnoDB引擎有三大特性(这个是面试的时候很容易被问到的。)
2.7 全文检索之倒排索引
什么是全文检索(Full-Text Search)?
它是将存储于数据库中的整本书或整篇文章中的任意内容信息查找出来的技术。它可以根据需要获得全文中有关章、节、段、句、词等信息,也可以进行各种统计和分析。我们比较熟知的Elasticsearch、Solr等就是全文检索引擎,底层都是基于Apache Lucene的。
举个例子,现在我们要保存唐宋诗词,数据库中我们们会怎么设计?诗词表我们可能的设计如下:
| 朝代 | 作者 | 诗词年代 | 标题 | 诗词全文 |
|---|---|---|---|---|
| 唐 | 李白 | 静夜思 | 床前明月光,疑是地上霜。 举头望明月,低头思故乡。 | |
| 宋 | 李清照 | 如梦令 | 常记溪亭日暮,沉醉不知归路,兴尽晚回舟,误入藕花深处。争渡,争渡,惊起一滩鸥鹭。 |
要根据朝代或者作者寻找诗,都很简单,比如"select 诗词全文 from 诗词表 where作者=‘李白’",如果数据很多,查询速度很慢,怎么办?
我们可以在对应的查询字段上建立索引加速查询。
但是如果我们现在有个需求:要求找到包含"望"字的诗词怎么办?
用“select 诗词全文 from 诗词表 where诗词全文 like’%望%’”,这个意味着要扫描库中的诗词全文字段,逐条比对,找出所有包含关键词"望"字的记录。基本上,数据库中一般的SQL优化手段都是用不上的。数量少,大概性能还能接受,如果数据量稍微大点,就完全无法接受了,更何况在互联网这种海量数据的情况下呢?怎么解决这个问题呢,用倒排索引。
比如现在有:
蜀道难(唐)李白 蜀道之难难于上青天,侧身西望长咨嗟。
静夜思(唐)李白 举头望明月,低头思故乡。
春台望(唐)李隆基 暇景属三春,高台聊四望。
鹤冲天(宋)柳永 黄金榜上,偶失龙头望。明代暂遗贤,如何向?未遂风云便,争不恣狂荡。何须论得丧?才子词人,自是白衣卿相。烟花巷陌,依约丹青屏障。幸有意中人,堪寻访。且恁偎红翠,风流事,平生畅。青春都一饷。忍把浮名,换了浅斟低唱!
都有望字,于是我们可以这么保存
| 序号 | 关键字 | 蜀道难 | 静夜思 | 春台望 | 鹤冲天 |
|---|---|---|---|---|---|
| 1 | 望 | 有 | 有 | 有 | 有 |
如果查哪个诗词中包含上,怎么办,上述的表格可以继续填入新的记录
| 序号 | 关键字 | 蜀道难 | 静夜思 | 春台望 | 鹤冲天 |
|---|---|---|---|---|---|
| 2 | 上 | 有 | 有 |
其实,上述诗词的中每个字都可以作为关键字,然后建立关键字和文档之间的对应关系,也就是标识关键字被哪些文档包含。
所以,倒排索引就是,将文档中包含的关键字全部提取处理,然后再将关键字和文档之间的对应关系保存起来,最后再对关键字本身做索引排序。用户在检索某一个关键字是,先对关键字的索引进行查找,再通过关键字与文档的对应关系找到所在文档。
在存储在关系型数据库中的数据,需要我们事先分析将数据拆分为不同的字段,而在es这类的存储中,需要应用程序根据规则自动提取关键字,并形成对应关系。
这些预先提取的关键字,在全文检索领域一般被称为term(词项),文档的词项提取在es中被称为文档分析,这是全文检索很核心的过程,必须要区分哪些是词项,哪些不是,比如很多场景下,apple和apples是同一个东西,望和看其实是同一个动作。
2.8 MySQL中的全文索引
MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引。从InnoDB 1.2.x版本开始,InnoDB存储引擎开始支持全文检索,对应的MySQL版本是5.6.x系列。
注意,不管什么引擎,只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
不过MySQL从设计之初就是关系型数据库,存储引擎虽然支持全文检索,整体架构上对全文检索支持并不好而且限制很多,比如每张表只能有一个全文检索的索引,不支持没有单词界定符( delimiter)的语言,如中文、日语、韩语等。
所以如果有大批量或者专门的全文检索需求,还是应该选择专门的全文检索引擎,毕竟Elastic靠着全文检索起家,然后产品化、公司化后依赖全文检索不断扩充产品线和应用场景,并推出商业版本的解决方案然后融资上市,现在的市值已达100亿美元。
具体如何使用InnoDB存储引擎的全文检索,只提供简单的使用说明,更多的详情请自行查阅相关官方文档或者书籍,官方文档路径:https://dev.mysql.com/doc/refman/8.0/en/fulltext-search.html
创建表时使用全文索引
创建表时创建全文索引
create table fulltext_test (
id int(11) NOT NULL AUTO_INCREMENT,
content text NOT NULL,
tag varchar(255),
PRIMARY KEY (id),
FULLTEXT KEY content_tag_fulltext(content,tag)
) DEFAULT CHARSET=utf8;
在已存在的表上创建全文索引
create fulltext index content_tag_fulltext
on fulltext_test(content,tag);
通过 SQL 语句 ALTER TABLE 创建全文索引
alter table fulltext_test
add fulltext index content_tag_fulltext(content,tag);
2.9 总结:MySQL有哪些索引类型
从数据结构角度可分为B+树索引、哈希索引、以及FULLTEXT索引(现在MyISAM和InnoDB引擎都支持了)和R-Tree索引(用于对GIS数据类型创建SPATIAL索引);
从物理存储角度可分为聚集索引(clustered index)、非聚集索引(non-clustered index);
从逻辑角度可分为主键索引、普通索引,或者单列索引、多列索引、唯一索引、非唯一索引等等。
面试题:Innodb存储引擎的三大特性:
自适应hash索引、双写缓存区、BufferPool
面试题:什么是密集索引和稀疏索引?
密集索引的定义:叶子节点保存的不只是键值,还保存了位于同一行记录里的其他列的信息,由于密集索引决定了表的物理排列顺序,一个表只有一个物理排列顺序,所以一个表只能创建一个密集索引。
稀疏索引:叶子节点仅保存了键位信息以及该行数据的地址,有的稀疏索引只保存了键位信息机器主键。
mysam存储引擎,不管是主键索引,唯一键索引还是普通索引都是稀疏索引,innodb存储引擎:有且只有一个密集索引。
所以,密集索引就是innodb存储引擎里的聚簇索引,稀疏索引就是innodb存储引擎里的普通二级索引。
2.10 辨析覆盖索引/索引覆盖
既然多个列可以组合起来构建为联合索引,那么辅助索引自然也可以由多个列组成。
覆盖索引也是我们经常见到的名词,InnoDB存储引擎支持覆盖索引(covering index,或称索引覆盖),即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。使用覆盖索引的一个好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作。所以记住,覆盖索引可以视为索引优化的一种方式,而并不是索引类型的一种。
除了覆盖索引这个概念外,在索引优化的范围内,还有前缀索引、三星索引等一系列概念,都会在后文补充。
覆盖索引不是真真正正的索引,属于索引优化的一种方式。把回表这个动作给去除了。

2.11 深入思考索引在查询中的使用
索引在查询中的作用到底是什么?在我们的查询中发挥着什么样的作用呢? 请记住:
1、一个索引就是一个B+树,索引让我们的查询可以快速定位和扫描到我们需要的数据记录上,加快查询的速度。
2、一个select查询语句在执行过程中一般最多能使用一个二级索引来加快查询,即使在where条件中用了多个二级索引。
索引的代价
世界上从来没有只有好处没有坏处的东西,如果你有,请你一定要告诉我,让我也感受一下。虽然索引是个好东西,在学习如何更好的使用索引之前先要了解一下使用它的代价,它在空间和时间上都会拖后腿。
空间上的代价
这个是显而易见的,每建立一个索引都要为它建立一棵B+树,每一棵B+树的每一个节点都是一个数据页,一个页默认会占用16KB的存储空间,一棵很大的B+树由许多数据页组成会占据很多的存储空间。
时间上的代价
每次对表中的数据进行增、删、改操作时,都需要去修改各个B+树索引。而且我们讲过,B+树每层节点都是按照索引列的值从小到大的顺序排序而组成了双向链表。不论是叶子节点中的记录,还是非叶子内节点中的记录都是按照索引列的值从小到大的顺序而形成了一个单向链表。
而增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需要额外的时间进行一些记录移位,页面分裂、页面回收的操作来维护好节点和记录的排序。如果我们建了许多索引,每个索引对应的B+树都要进行相关的维护操作,这必然会对性能造成影响。
既然索引这么有用,我们是不是创建越多越好?既然索引有代价,我们还是别创建了吧?当然不是!按照经验,一般来说,一张表6-7个索引以下都能够取得比较好的性能权衡。
那么创建索引的时候有什么好的策略让我们充分利用索引呢?